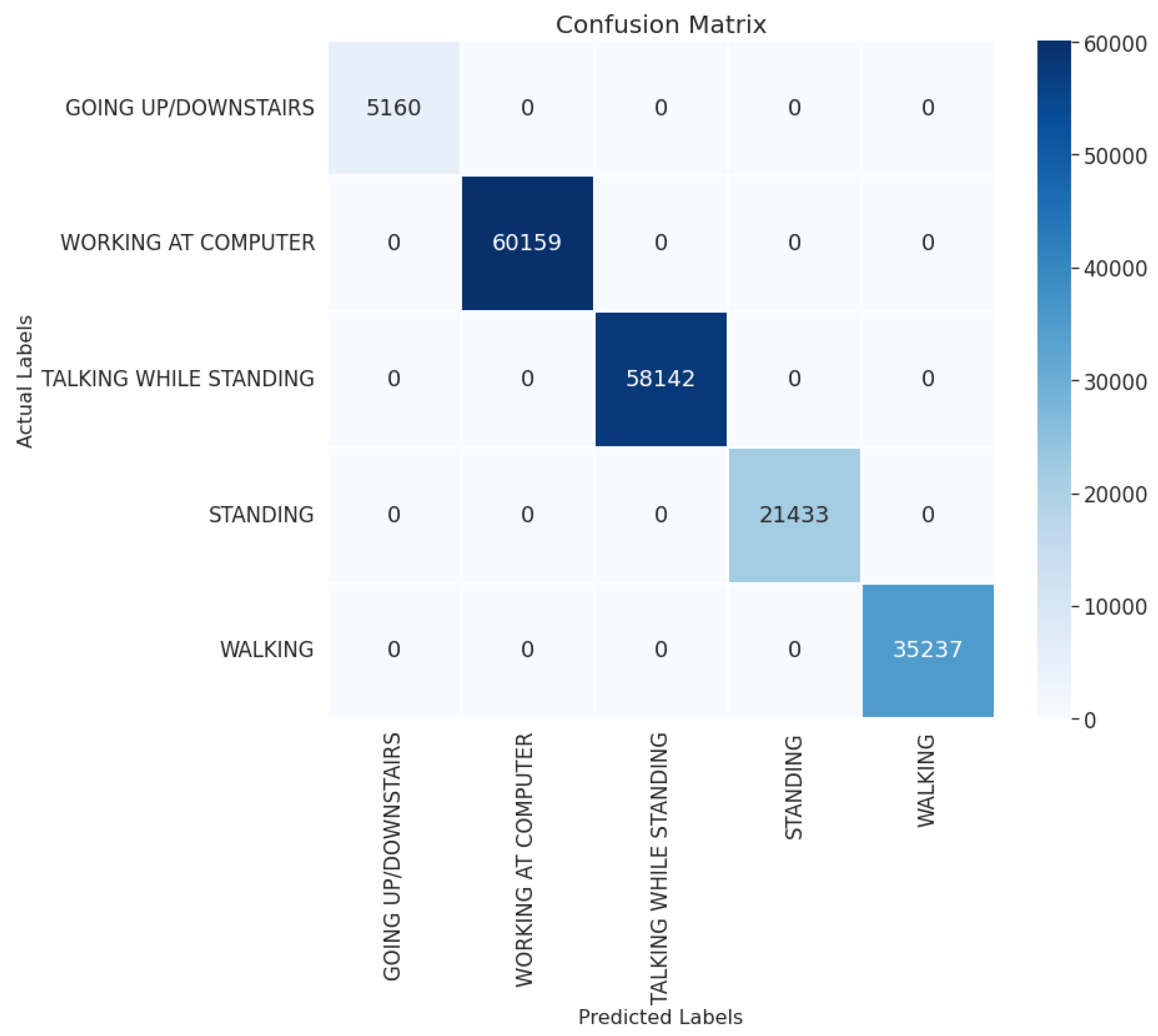
4. Datasets
Three publicly available datasets are used in the performance evaluation of the proposed 1D-CNN-BiLSTM for human activity recognition, namely the the UCI-HAR dataset [
21], the Motion Sense dataset [
22] and the Single Accelerometer dataset [
23].
Author Contributions
Conceptualization, Y.J.L. and C.P.L.; methodology, Y.J.L. and C.P.L.; software, Y.J.L. and C.P.L.; validation, Y.J.L. and C.P.L.; formal analysis, Y.J.L.; investigation, Y.J.L.; resources, Y.J.L.; data curation, Y.J.L. and C.P.L.; writing—original draft preparation, Y.J.L.; writing—review and editing, C.P.L. and K.M.L.; visualization, Y.J.L. and C.P.L.; supervision, C.P.L. and K.M.L.; project administration, C.P.L.; funding acquisition, C.P.L. All authors have read and agreed to the published version of the manuscript.
Funding
The research in this work was supported by the Fundamental Research Grant Scheme of the Ministry of Higher Education under award number FRGS/1/2021/ICT02/MMU/02/4 and Multimedia University Internal Research Grant with award number MMUI/220021.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ranasinghe, S.; Al Machot, F.; Mayr, H.C. A review on applications of activity recognition systems with regard to performance and evaluation. Int. J. Distrib. Sens. Netw. 2016, 12, 1550147716665520. [Google Scholar] [CrossRef] [Green Version]
- Tan, P.S.; Lim, K.M.; Lee, C.P. Human action recognition with sparse autoencoder and histogram of oriented gradients. In Proceedings of the 2020 IEEE 2nd International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 26–27 September 2020; pp. 1–5. [Google Scholar]
- Irvine, N.; Nugent, C.; Zhang, S.; Wang, H.; Ng, W.W. Neural network ensembles for sensor-based human activity recognition within smart environments. Sensors 2019, 20, 216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neili Boualia, S.; Essoukri Ben Amara, N. Deep full-body HPE for activity recognition from RGB frames only. Informatics 2021, 8, 2. [Google Scholar] [CrossRef]
- Dobbins, C.; Rawassizadeh, R. Towards clustering of mobile and smartwatch accelerometer data for physical activity recognition. Informatics 2018, 5, 29. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.P.; Lim, K.M.; Woon, W.L. Statistical and entropy based multi purpose human motion analysis. In Proceedings of the 2010 2nd International Conference on Signal Processing Systems, Dalian, China, 5–7 July 2010; Volume 1, p. V1-734. [Google Scholar]
- Saez, Y.; Baldominos, A.; Isasi, P. A comparison study of classifier algorithms for cross-person physical activity recognition. Sensors 2016, 17, 66. [Google Scholar] [CrossRef] [PubMed]
- Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable sensor-based human activity recognition with transformer model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [Green Version]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Moya Rueda, F.; Grzeszick, R.; Fink, G.A.; Feldhorst, S.; Ten Hompel, M. Convolutional neural networks for human activity recognition using body-worn sensors. Informatics 2018, 5, 26. [Google Scholar] [CrossRef] [Green Version]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. Hand-crafted features vs residual networks for human activities recognition using accelerometer. In Proceedings of the 2019 IEEE 23rd International Symposium on Consumer Technologies (ISCT), Ancona, Italy, 19–21 June 2019; pp. 153–156. [Google Scholar]
- Ragab, M.G.; Abdulkadir, S.J.; Aziz, N. Random search one dimensional CNN for human activity recognition. In Proceedings of the 2020 International Conference on Computational Intelligence (ICCI), Bandar Seri Iskandar, Malaysia, 8–9 October 2020; pp. 86–91. [Google Scholar]
- Zhao, Y.; Yang, R.; Chevalier, G.; Xu, X.; Zhang, Z. Deep residual bidir-LSTM for human activity recognition using wearable sensors. Math. Probl. Eng. 2018, 2018, 7316954. [Google Scholar] [CrossRef]
- Mutegeki, R.; Han, D.S. A CNN-LSTM approach to human activity recognition. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 362–366. [Google Scholar]
- Ni, Q.; Fan, Z.; Zhang, L.; Nugent, C.D.; Cleland, I.; Zhang, Y.; Zhou, N. Leveraging wearable sensors for human daily activity recognition with stacked denoising autoencoders. Sensors 2020, 20, 5114. [Google Scholar] [CrossRef] [PubMed]
- Goh, J.X.; Lim, K.M.; Lee, C.P. 1D Convolutional Neural Network with Long Short-Term Memory for Human Activity Recognition. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 13–15 September 2021; pp. 1–6. [Google Scholar]
- Erdaş, Ç.B.; Güney, S. Human activity recognition by using different deep learning approaches for wearable sensors. Neural Process. Lett. 2021, 53, 1795–1809. [Google Scholar] [CrossRef]
- Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint learning of temporal models to handle imbalanced data for human activity recognition. Appl. Sci. 2020, 10, 5293. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra Perez, X.; Reyes Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Mobile sensor data anonymization. In Proceedings of the International Conference on Internet of Things Design and Implementation, Montreal, QC, Canada, 15–18 April 2019; pp. 49–58. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Personalization and user verification in wearable systems using biometric walking patterns. Pers. Ubiquitous Comput. 2012, 16, 563–580. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A fast and robust deep convolutional neural networks for complex human activity recognition using smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Roobini, M.S.; Naomi, M.J.F. Smartphone sensor based human activity recognition using deep learning models. Int. J. Recent Technol. Eng. 2019, 8, 2740–2748. [Google Scholar]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef] [Green Version]
- Haresamudram, H.; Beedu, A.; Agrawal, V.; Grady, P.L.; Essa, I.; Hoffman, J.; Plötz, T. Masked reconstruction based self-supervision for human activity recognition. In Proceedings of the 2020 International Symposium on Wearable Computers, Virtual Event, 12–16 September 2020; pp. 45–49. [Google Scholar]
- Haresamudram, H.; Anderson, D.V.; Plötz, T. On the role of features in human activity recognition. In Proceedings of the 23rd International Symposium on Wearable Computers, London, UK, 9–13 September 2019; pp. 78–88. [Google Scholar]
- Saeed, A.; Ozcelebi, T.; Lukkien, J. Multi-task self-supervised learning for human activity detection. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, J.; Carvalho, E.; Ferreira, B.V.; de Souza, C.; Suhara, Y.; Pentland, A.; Pessin, G. Driver behavior profiling: An investigation with different smartphone sensors and machine learning. PLoS ONE 2017, 12, e0174959. [Google Scholar]
- Ilisei, D.; Suciu, D.M. Human-activity recognition with smartphone sensors. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2019; pp. 179–188. [Google Scholar]
- Haresamudram, H.; Essa, I.; Plötz, T. Contrastive predictive coding for human activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–26. [Google Scholar] [CrossRef]
- Erdaş, Ç.B.; Atasoy, I.; Açıcı, K.; Oğul, H. Integrating features for accelerometer-based activity recognition. Procedia Comput. Sci. 2016, 98, 522–527. [Google Scholar] [CrossRef] [Green Version]
- Hossain, T.; Inoue, S. A Comparative study on missing data handling using machine learning for human activity recognition. In Proceedings of the 2019 Joint 8th International Conference on Informatics, Electronics & Vision (ICIEV) and 2019 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Spokane, WA, USA, 30 May–2 June 2019; pp. 124–129. [Google Scholar]
- Güney, S.; Erdaş, Ç.B. A deep LSTM approach for activity recognition. In Proceedings of the 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; pp. 294–297. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}