
Reinforcement Learning in Education: A Literature Review

Abstract
:1. Introduction
2. Review Planning and Methodology
- RQ1:
- Does RL actually help in the education field?
- RQ2:
- If so, what are the applications, and where might we anticipate it being most useful?
- RQ3:
- What are the considerations, challenges, and future directions of RL in education?
3. Literature Review
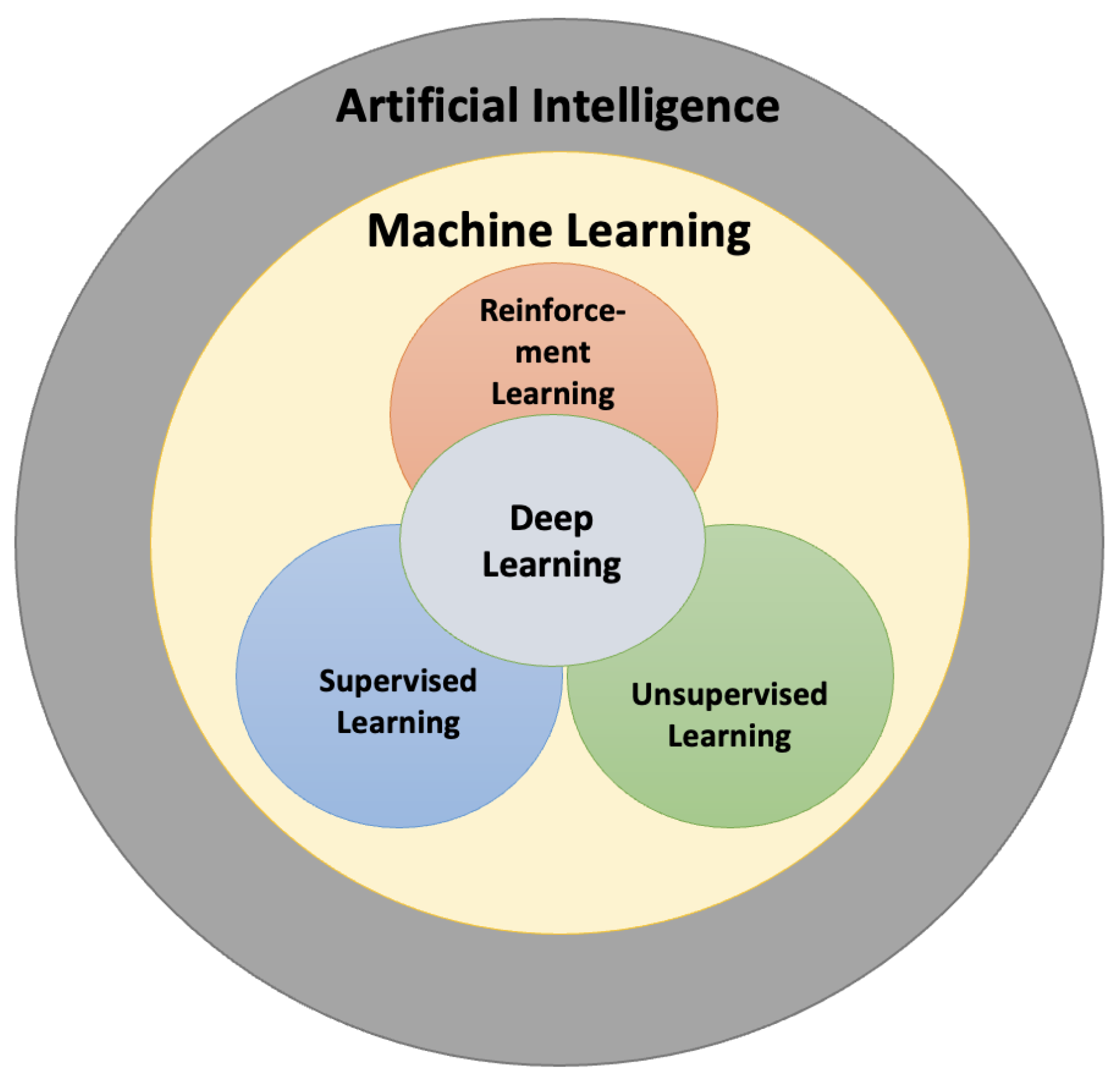
3.1. RL Techniques in the Educational Domain
3.1.1. Markov Decision Process
3.1.2. Partially Observable Markov Decision Process (POMDP)
3.1.3. Deep RL Framework
3.1.4. Markov Chain
3.2. RL Research Directions in the Education Application
3.2.1. RL Techniques for the Teacher–Student Framework
3.2.2. RL Techniques to Provide Hints and Quizzing
3.2.3. RL Techniques for Adaptive Experimentation in Educational Platforms
3.2.4. RL Techniques for Instructional Sequencing in Education
3.2.5. RL Techniques for Modeling Students
3.2.6. RL Techniques for Generating Educational Content
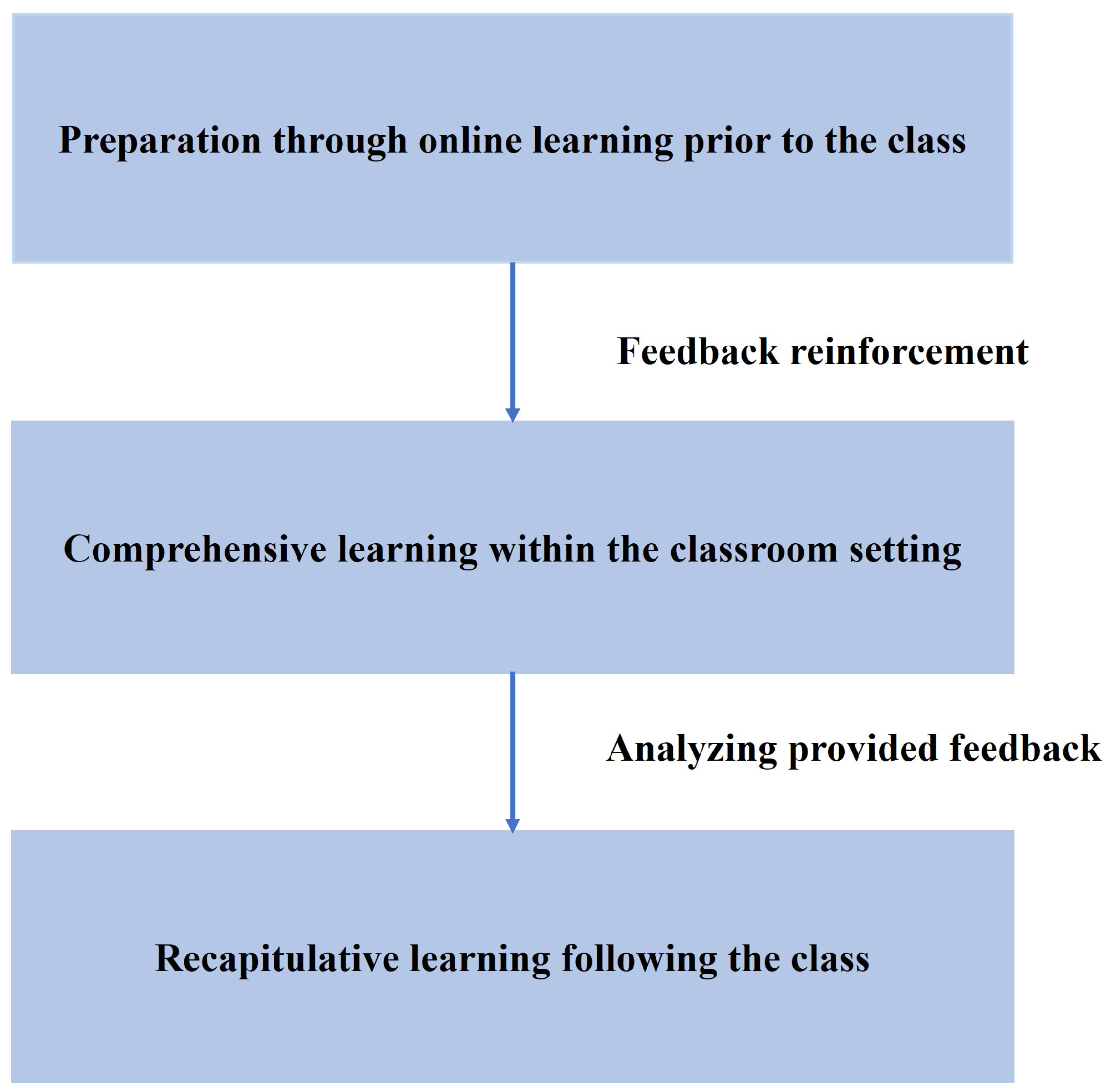
3.2.7. RL Techniques for Personalized Education through E-Learning
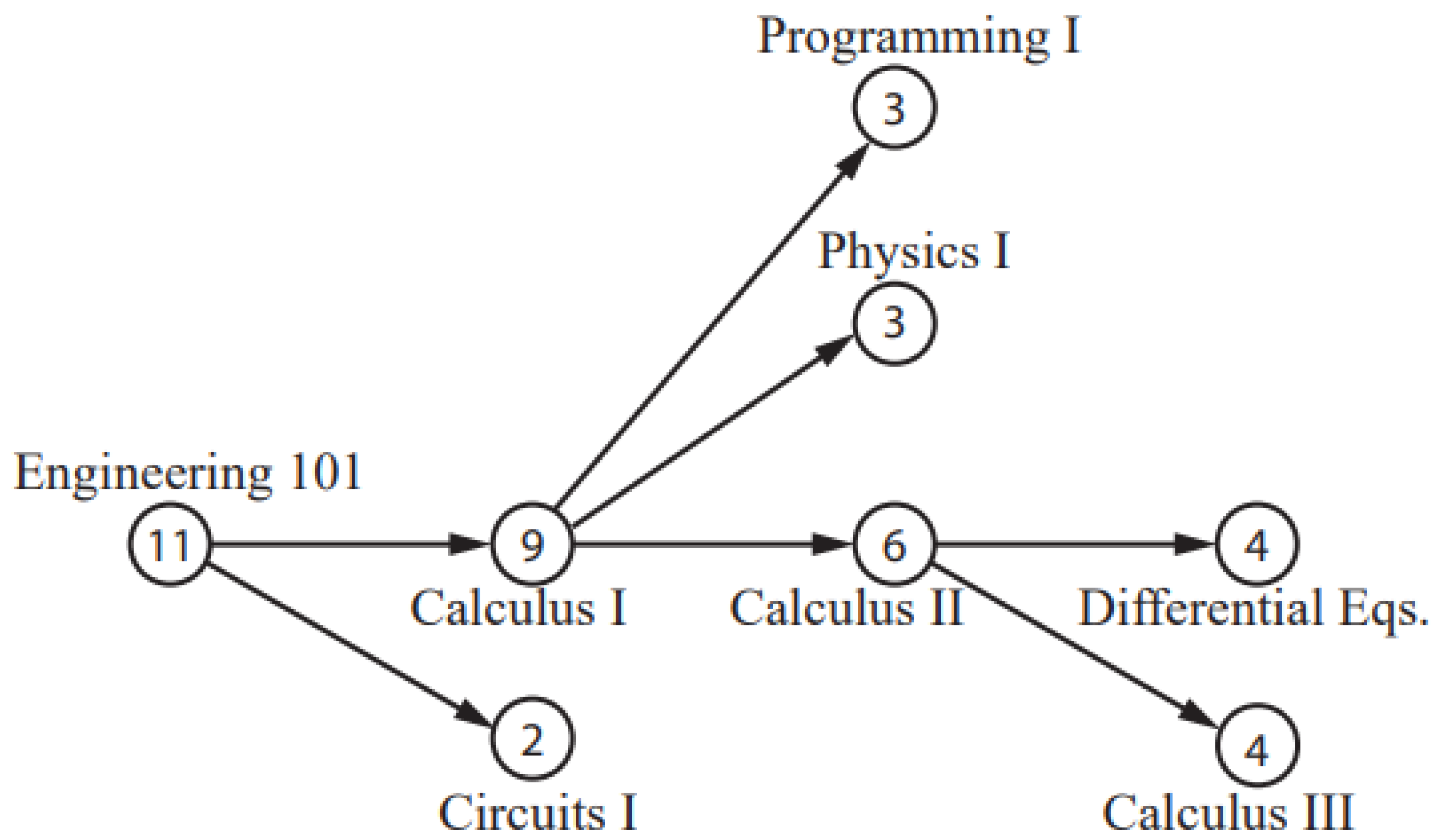
3.2.8. RL Techniques for Personalizing a Curriculum
Characterizing the Complexity of Curricular Patterns in Engineering Programs
Network Analysis of University Courses
4. Considerations in the Design of Reinforcement Learning
5. Challenges of Artificial Intelligence in Education and Future Research Directions
- Insufficient pertinent learning resources for personalized or adaptive learning: Instructors have complained that the suggested pedagogies and learning materials of the personalized or adaptive learning platform are overly uniform. Learning objects are any standardized and reusable digital instructional resources that can be easily reused and customized to meet a learning purpose in a number of scenarios, according to the recommendations made by AI agents [94]. More research is required to better understand how learning objects should be used in customized and adaptive learning, as well as how they might be created.
- Lack of perspectives on education in AIEd research: The majority of AIEd researchers come from a strong engineering background; they frequently concentrate on technology design and development and approach AIEd research from an engineering perspective. The opinions of educational researchers and instructors are not adequately represented by this strategy. Future studies should look for innovative research techniques for diverse disciplines of AIEd that can directly involve educators, researchers, and students, as AI is an interdisciplinary field [95].
- Data selection for AI predictive models: The organized student information now utilized in linear regressions, a type of classical predictive model, is not necessarily suitable for nascent AI technology. An extensive collection of unstructured and structured student information is necessary for an efficient AI predictive model, which poses significant privacy concerns. The efficiency of AI technology must be balanced with ethical limitations because AIEd frequently targets young learners. Additional investigation is required on the types of information that should be used in AI models while taking ethical considerations very seriously [96].
- Socio-emotional factors are understudied in AIEd research: The majority of AIEd studies have focused on cognitive results and adaptive learning, whereas very few have looked at socio-emotional effects [97]. AIEd has been linked to risks and unfavorable outcomes, and both teachers and students are conscious of the moral issues involved [98,99,100,101,102]. The ethical implications of applying AI to the fields of social science, engineering, and law have not yet been thoroughly examined. Therefore, more investigation is required on the ethical problems surrounding AIEd.
- Teachers lack sufficient expertise in AI technologies: The majority of teachers have been instructing in a black box since they are unable to comprehend how AI technologies operate (for example, the guiding principles or algorithms for resource recommendations). Therefore, they cannot fully utilize the technologies for learning, teaching, and assessment, as well as respond to students’ questions regarding AIEd (such as why particular learning resources were chosen by the AI platforms). Therefore, future studies should take into account the requirement for instructors to understand AI and its use in education [93].
- Potential ethical and social issues: In [103], four themes—privacy, replacing people, consequences for children, and responsibility—were used to analyze the ethical implications of deploying (humanoid) robots in the classroom. The nature of intelligence, how to balance the interests of individuals and the general public, how to deal with moral conundrums, and how automation will affect the labor market are just a few of the fundamental concerns surrounding AI that cannot be fully addressed by technology. These issues necessitate interdisciplinary methods, which change the purpose and nature of educational programs.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Johri, A. Artificial intelligence and engineering education. JEE 2020, 109, 358–361. [Google Scholar] [CrossRef]
- Besterfield-Sacre, M.; Shuman, L.J.; Wolfe, H.; Clark, R.M.; Yildirim, P. Development of a work sampling methodology for behavioral observations: Application to teamwork. J. Eng. Educ. 2007, 96, 347–357. [Google Scholar] [CrossRef]
- Butz, B.P. The learning mechanism of the interactive multimedia intelligent tutoring system (IMITS). J. Eng. Educ. 2001, 90, 543–548. [Google Scholar] [CrossRef]
- Fahd, K.; Venkatraman, S.; Miah, S.; Ahmed, K. Application of machine learning in higher education to assess student academic performance, at-risk, and attrition: A meta-analysis of literature. Educ. Inf. Technol. 2022, 27, 1–33. [Google Scholar] [CrossRef]
- Qazdar, A.; Er-Raha, B.; Cherkaoui, C.; Mammass, D. A machine learning algorithm framework for predicting students performance: A case study of baccalaureate students in Morocco. Educ. Inf. Technol. 2019, 24, 3577–3589. [Google Scholar] [CrossRef]
- Liu, X.; Ardakani, S. A machine learning enabled affective E-learning system model. Educ. Inf. Technol. 2022, 27, 9913–9934. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Mothanna, Y.; Hewahi, N. Review on Reinforcement Learning in CartPole Game. In Proceedings of the 2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakheer, Bahrain, 20–21 November 2022; pp. 344–349. [Google Scholar] [CrossRef]
- Souchleris, K.; Sidiropoulos, G.K.; Papakostas, G.A. Reinforcement Learning in Game Industry—Review, Prospects and Challenges. Appl. Sci. 2023, 13, 2443. [Google Scholar] [CrossRef]
- Whitehill, J.; Movellan, J. Approximately optimal teaching of approximately optimal learners. IEEE Trans. Learn. Technol. 2017, 11, 152–164. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Learning teaching strategies in an adaptive and intelligent educational system through reinforcement learning. Appl. Intell. 2009, 31, 89–106. [Google Scholar] [CrossRef]
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Reinforcement learning of pedagogical policies in adaptive and intelligent educational systems. Knowl.-Based Syst. 2009, 22, 266–270. [Google Scholar] [CrossRef]
- Iglesias, A.; Martinez, P.; Fernández, F. An experience applying reinforcement learning in a web-based adaptive and intelligent educational system. Inform. Educ. 2003, 2, 223–240. [Google Scholar] [CrossRef]
- Martin, K.N.; Arroyo, I. AgentX: Using reinforcement learning to improve the effectiveness of intelligent tutoring systems. In Proceedings of the International Conference on Intelligent Tutoring Systems, Maceió, Brazil, 30 August–3 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 564–572. [Google Scholar]
- Chi, M.; VanLehn, K.; Litman, D.; Jordan, P. Empirically evaluating the application of reinforcement learning to the induction of effective and adaptive pedagogical strategies. User Model. User-Adapt. Interact. 2011, 21, 137–180. [Google Scholar] [CrossRef]
- Jaakkola, T.; Singh, S.; Jordan, M. Reinforcement learning algorithm for partially observable Markov decision problems. Adv. Neural Inf. Process. Syst. 1994, 7, 345–352. [Google Scholar]
- Koenig, S.; Simmons, R. Xavier: A robot navigation architecture based on partially observable markov decision process models. In Artificial Intelligence Based Mobile Robotics: Case Studies of Successful Robot Systems; MIT Press: Cambridge, MA, USA, 1998; pp. 91–122. [Google Scholar]
- Mandel, T.; Liu, Y.E.; Levine, S.; Brunskill, E.; Popovic, Z. Offline policy evaluation across representations with applications to educational games. In Proceedings of the AAMAS, Paris, France, 5–9 May 2014; Volume 1077. [Google Scholar]
- Rafferty, A.N.; Brunskill, E.; Griffiths, T.L.; Shafto, P. Faster teaching via pomdp planning. Cogn. Sci. 2016, 40, 1290–1332. [Google Scholar] [CrossRef]
- Clement, B.; Oudeyer, P.Y.; Lopes, M. A Comparison of Automatic Teaching Strategies for Heterogeneous Student Populations. In Proceedings of the International Educational Data Mining Society, Raleigh, North Carolina, 29 June–2 July 2016. [Google Scholar]
- Wang, P.; Rowe, J.P.; Min, W.; Mott, B.W.; Lester, J.C. Interactive Narrative Personalization with Deep Reinforcement Learning. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3852–3858. [Google Scholar]
- Luo, M. Application of AHP-DEA-FCE model in college English teaching quality evaluation. Int. J. Appl. Math. Stat. 2013, 51, 101–108. [Google Scholar]
- Yuan, T. Algorithm of classroom teaching quality evaluation based on Markov chain. Complexity 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Anand, D.; Gupta, V.; Paruchuri, P.; Ravindran, B. An enhanced advising model in teacher-student framework using state categorization. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 6653–6660. [Google Scholar]
- Zimmer, M.; Viappiani, P.; Weng, P. Teacher-student framework: A reinforcement learning approach. In Proceedings of the AAMAS Workshop Autonomous Robots and Multirobot Systems, Paris, France, 5–9 May 2014. [Google Scholar]
- Li, X.; Xu, H.; Zhang, J.; Chang, H.h. Deep reinforcement learning for adaptive learning systems. J. Educ. Behav. Stat. 2023, 48, 220–243. [Google Scholar] [CrossRef]
- Tárraga-Sánchez, M.d.l.Á.; Ballesteros-García, M.d.M.; Migallón, H. Teacher-Developed Computer Games for Classroom and Online Reinforcement Learning for Early Childhood. Educ. Sci. 2023, 13, 108. [Google Scholar] [CrossRef]
- Tang, X.; Chen, Y.; Li, X.; Liu, J.; Ying, Z. A reinforcement learning approach to personalized learning recommendation systems. Br. J. Math. Stat. Psychol. 2019, 72, 108–135. [Google Scholar] [CrossRef]
- Aleven, V.; McLaughlin, E.A.; Glenn, R.A.; Koedinger, K.R. Instruction based on adaptive learning technologies. In Handbook of Research on Learning and Instruction; Routledge: New York, NY, USA, 2016; pp. 522–560. [Google Scholar]
- Williams, J.J.; Kim, J.; Rafferty, A.; Maldonado, S.; Gajos, K.Z.; Lasecki, W.S.; Heffernan, N. Axis: Generating explanations at scale with learnersourcing and machine learning. In Proceedings of the Third (2016) ACM Conference on Learning@ Scale, Edinburgh, UK, 25–26 April 2016; pp. 379–388. [Google Scholar]
- Patikorn, T.; Heffernan, N.T. Effectiveness of crowd-sourcing on-demand assistance from teachers in online learning platforms. In Proceedings of the Seventh ACM Conference on Learning@ Scale, Virtual, USA, 12–14 August 2020; pp. 115–124. [Google Scholar]
- Erickson, J.A.; Botelho, A.F.; McAteer, S.; Varatharaj, A.; Heffernan, N.T. The automated grading of student open responses in mathematics. In Proceedings of the Tenth International Conference on Learning Analytics &, Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 615–624. [Google Scholar]
- Barnes, T.; Stamper, J. Toward automatic hint generation for logic proof tutoring using historical student data. In Proceedings of the International Conference on Intelligent Tutoring Systems, Montreal, QC, Canada, 23–27 June 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 373–382. [Google Scholar]
- Efremov, A.; Ghosh, A.; Singla, A. Zero-shot learning of hint policy via reinforcement learning and program synthesis. In Proceedings of the EDM, Virtual, 10–13 July 2020. [Google Scholar]
- He-Yueya, J.; Singla, A. Quizzing Policy Using Reinforcement Learning for Inferring the Student Knowledge State. Int. Educ. Data Min. Soc. 2021, 533–539. [Google Scholar]
- Liu, Y.E.; Mandel, T.; Brunskill, E.; Popovic, Z. Trading Off Scientific Knowledge and User Learning with Multi-Armed Bandits. In Proceedings of the EDM, London, UK, 4–7 July 2014; pp. 161–168. [Google Scholar]
- Williams, J.J.; Rafferty, A.N.; Tingley, D.; Ang, A.; Lasecki, W.S.; Kim, J. Enhancing online problems through instructor-centered tools for randomized experiments. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Rafferty, A.N.; Ying, H.; Williams, J.J. Bandit assignment for educational experiments: Benefits to students versus statistical power. In Proceedings of the International Conference on Artificial Intelligence in Education, London, UK, 27–30 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 286–290. [Google Scholar]
- Rafferty, A.; Ying, H.; Williams, J. Statistical consequences of using multi-armed bandits to conduct adaptive educational experiments. J. Educ. Data Min. 2019, 11, 47–79. [Google Scholar]
- Howard, R.A. Dynamic Programming and Markov Processes; MIT Press: Cambridge, MA, USA, 1960. [Google Scholar]
- Ritter, F.E.; Nerb, J.; Lehtinen, E.; O’Shea, T.M. In Order to Learn: How the Sequence of Topics Influences Learning; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Atkinson, R.C. Ingredients for a theory of instruction. Am. Psychol. 1972, 27, 921. [Google Scholar] [CrossRef]
- Atkinson, R.C. Optimizing the learning of a second-language vocabulary. J. Exp. Psychol. 1972, 96, 124. [Google Scholar] [CrossRef]
- Sondik, E.J. The Optimal Control of Partially Observable Markov Processes; Stanford University: Stanford, CA, USA, 1971. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- Corbett, A. Cognitive mastery learning in the act programming tutor. In Proceedings of the Adaptive User Interfaces. AAAI SS-00-01. 2000. Available online: https://api.semanticscholar.org/CorpusID:16877673 (accessed on 14 February 2023).
- Welch, L.R. Hidden Markov models and the Baum-Welch algorithm. IEEE Inf. Theory Soc. Newsl. 2003, 53, 10–13. [Google Scholar]
- Hsu, D.; Kakade, S.M.; Zhang, T. A spectral algorithm for learning hidden Markov models. J. Comput. Syst. Sci. 2012, 78, 1460–1480. [Google Scholar] [CrossRef]
- Falakmasir, M.H.; Pardos, Z.A.; Gordon, G.J.; Brusilovsky, P. A Spectral Learning Approach to Knowledge Tracing. In Proceedings of the EDM, Memphis, TN, USA, 6–9 July 2013; pp. 28–34. [Google Scholar]
- Baker, R.S.d.; Corbett, A.T.; Gowda, S.M.; Wagner, A.Z.; MacLaren, B.A.; Kauffman, L.R.; Mitchell, A.P.; Giguere, S. Contextual slip and prediction of student performance after use of an intelligent tutor. In Proceedings of the User Modeling, Adaptation, and Personalization: 18th International Conference, UMAP 2010, Big Island, HI, USA, 20–24 June 2010; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2010; pp. 52–63. [Google Scholar]
- VanLehn, K. The behavior of tutoring systems. Int. J. Artif. Intell. Educ. 2006, 16, 227–265. [Google Scholar]
- VanLehn, K. Regulative loops, step loops and task loops. Int. J. Artif. Intell. Educ. 2016, 26, 107–112. [Google Scholar] [CrossRef]
- Chi, M.; Jordan, P.W.; Vanlehn, K.; Litman, D.J. To elicit or to tell: Does it matter? In Proceedings of the Aied, Brighton, UK, 6–10 July 2009; pp. 197–204. [Google Scholar]
- Bassen, J.; Balaji, B.; Schaarschmidt, M.; Thille, C.; Painter, J.; Zimmaro, D.; Games, A.; Fast, E.; Mitchell, J.C. Reinforcement learning for the adaptive scheduling of educational activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Yang, X.; Zhou, G.; Taub, M.; Azevedo, R.; Chi, M. Student Subtyping via EM-Inverse Reinforcement Learning. Int. Educ. Data Min. Soc. 2020, 269–279. [Google Scholar]
- Zhu, X.; Singla, A.; Zilles, S.; Rafferty, A.N. An overview of machine teaching. arXiv 2018, arXiv:1801.05927. [Google Scholar]
- Haug, L.; Tschiatschek, S.; Singla, A. Teaching inverse reinforcement learners via features and demonstrations. Adv. Neural Inf. Process. Syst. 2018, 31, 8464–8473. [Google Scholar]
- Tschiatschek, S.; Ghosh, A.; Haug, L.; Devidze, R.; Singla, A. Learner-aware teaching: Inverse reinforcement learning with preferences and constraints. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper_files/paper/2019/hash/3de568f8597b94bda53149c7d7f5958c-Abstract.html (accessed on 14 February 2023).
- Kamalaruban, P.; Devidze, R.; Cevher, V.; Singla, A. Interactive teaching algorithms for inverse reinforcement learning. arXiv 2019, arXiv:1905.11867. [Google Scholar]
- Rakhsha, A.; Radanovic, G.; Devidze, R.; Zhu, X.; Singla, A. Policy teaching via environment poisoning: Training-time adversarial attacks against reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 7974–7984. [Google Scholar]
- Gisslén, L.; Eakins, A.; Gordillo, C.; Bergdahl, J.; Tollmar, K. Adversarial reinforcement learning for procedural content generation. In Proceedings of the 2021 IEEE Conference on Games (CoG), Copenhagen, Denmark, 17–20 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Khalifa, A.; Bontrager, P.; Earle, S.; Togelius, J. Pcgrl: Procedural content generation via reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Virtual, 19–23 October 2020; Volume 16, pp. 95–101. [Google Scholar]
- Kartal, B.; Sohre, N.; Guy, S.J. Data driven Sokoban puzzle generation with Monte Carlo tree search. In Proceedings of the Twelfth Artificial Intelligence and Interactive Digital Entertainment Conference, Burlingame, CA, USA, 8–12 October 2016. [Google Scholar]
- Minoofam, S.A.H.; Bastanfard, A.; Keyvanpour, M.R. RALF: An adaptive reinforcement learning framework for teaching dyslexic students. Multimed. Tools Appl. 2022, 81, 6389–6412. [Google Scholar] [CrossRef]
- Fok, A.W.P.; Ip, H.H. Personalized Education (PE) œ Technology Integration for Individual Learning. 2004. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=0e4d60d16aec5ca0202f59957161c9a91a50d56a (accessed on 2 February 2023).
- Ackerman, P.L. Traits and Knowledge as Determinants of Learning and Individual Differences: Putting It All Together; American Psychological Association: Washington, DC, USA, 1999. [Google Scholar]
- Fok, A.W.; Wong, H.S.; Chen, Y. Hidden Markov model based characterization of content access patterns in an e-learning environment. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–9 July 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 201–204. [Google Scholar]
- Wu, D.; Wang, S.; Liu, Q.; Abualigah, L.; Jia, H. An improved teaching-learning-based optimization algorithm with reinforcement learning strategy for solving optimization problems. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef] [PubMed]
- Durik, A.M.; Hulleman, C.S.; Harackiewicz, J.M. One size fits some: Instructional enhancements to promote interest. In Interest in Mathematics and Science Learning; American Educational Research Association location: Washington, DC, USA, 2015; pp. 49–62. [Google Scholar]
- Slim, A.; Al Yusuf, H.; Abbas, N.; Abdallah, C.T.; Heileman, G.L.; Slim, A. A Markov Decision Processes Modeling for Curricular Analytics. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtually Online, 13–15 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 415–421. [Google Scholar]
- Slim, A. Curricular Analytics in Higher Education. Ph.D. Thesis, The University of New Mexico, Albuquerque, NM, USA, 2016. [Google Scholar]
- Venezia, A.; Callan, P.M.; Finney, J.E.; Kirst, M.W.; Usdan, M.D. The Governance Divide: A Report on a Four-State Study on Improving College Readiness and Success. National Center Report# 05-3. National Center for Public Policy and Higher Education 2005. 2005. Available online: https://eric.ed.gov/?id=ED508097 (accessed on 10 February 2023).
- Whitt, E.J.; Schuh, J.H.; Kinzie, J.; Kuh, G.D. Student Success in College: Creating Conditions That Matter; Jossey-Bass: Hoboken, NJ, USA, 2013. [Google Scholar]
- Tinto, V. Leaving College: Rethinking the Causes and Cures of Student Attrition; University of Chicago Press: Chicago, IL, USA, 2012. [Google Scholar]
- Heileman, G.L.; Hickman, M.; Slim, A.; Abdallah, C.T. Characterizing the complexity of curricular patterns in engineering programs. In Proceedings of the 2017 ASEE Annual Conference & Exposition, Columbus, OH, USA, 25–28 June 2017. [Google Scholar]
- Slim, A.; Kozlick, J.; Heileman, G.L.; Wigdahl, J.; Abdallah, C.T. Network analysis of university courses. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; pp. 713–718. [Google Scholar]
- Yan, H.; Yu, C. Repair of full-thickness cartilage defects with cells of different origin in a rabbit model. Arthrosc. J. Arthrosc. Relat. Surg. 2007, 23, 178–187. [Google Scholar] [CrossRef] [PubMed]
- Ekinci, Y.; Ülengin, F.; Uray, N.; Ülengin, B. Analysis of customer lifetime value and marketing expenditure decisions through a Markovian-based model. Eur. J. Oper. Res. 2014, 237, 278–288. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Lindsey, R.V.; Mozer, M.C.; Huggins, W.J.; Pashler, H. Optimizing instructional policies. Adv. Neural Inf. Process. Syst. 2013, 26, 2778–2786. [Google Scholar]
- Clement, B.; Roy, D.; Oudeyer, P.Y.; Lopes, M. Multi-armed bandits for intelligent tutoring systems. arXiv 2013, arXiv:1310.3174. [Google Scholar]
- Segal, A.; Ben David, Y.; Williams, J.J.; Gal, K.; Shalom, Y. Combining difficulty ranking with multi-armed bandits to sequence educational content. In Proceedings of the Artificial Intelligence in Education: 19th International Conference, AIED 2018, London, UK, 27–30 June 2018; Proceedings, Part II 19. Springer: Berlin/Heidelberg, Germany, 2018; pp. 317–321. [Google Scholar]
- Matheson, J.E. Optimum Teaching Procedures Derived from Mathematical Learning Models; Stanford University, Institute in Engineering-Economic Systems: Stanford, CA, USA, 1964. [Google Scholar]
- Xia, Q.; Chiu, T.K.; Zhou, X.; Chai, C.S.; Cheng, M. Systematic literature review on opportunities, challenges, and future research recommendations of artificial intelligence in education. Comput. Educ. Artif. Intell. 2022, 100118. [Google Scholar] [CrossRef]
- Cao, J.; Yang, T.; Lai, I.K.W.; Wu, J. Student acceptance of intelligent tutoring systems during COVID-19: The effect of political influence. Int. J. Electr. Eng. Educ. 2021. [Google Scholar] [CrossRef]
- Holstein, K.; McLaren, B.M.; Aleven, V. Co-designing a real-time classroom orchestration tool to support teacher-AI complementarity. Grantee Submiss. 2019. [Google Scholar] [CrossRef]
- Sharma, K.; Papamitsiou, Z.; Giannakos, M. Building pipelines for educational data using AI and multimodal analytics: A “grey-box” approach. Br. J. Educ. Technol. 2019, 50, 3004–3031. [Google Scholar] [CrossRef]
- Salas-Pilco, S.Z. The impact of AI and robotics on physical, social-emotional and intellectual learning outcomes: An integrated analytical framework. Br. J. Educ. Technol. 2020, 51, 1808–1825. [Google Scholar] [CrossRef]
- Wood, E.A.; Ange, B.L.; Miller, D.D. Are we ready to integrate artificial intelligence literacy into medical school curriculum: Students and faculty survey. J. Med. Educ. Curric. Dev. 2021, 8, 23821205211024078. [Google Scholar] [CrossRef] [PubMed]
- Kahn, K.; Winters, N. Constructionism and AI: A history and possible futures. Br. J. Educ. Technol. 2021, 52, 1130–1142. [Google Scholar] [CrossRef]
- Banerjee, M.; Chiew, D.; Patel, K.T.; Johns, I.; Chappell, D.; Linton, N.; Cole, G.D.; Francis, D.P.; Szram, J.; Ross, J.; et al. The impact of artificial intelligence on clinical education: Perceptions of postgraduate trainee doctors in London (UK) and recommendations for trainers. BMC Med. Educ. 2021, 21, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Haseski, H.I. What Do Turkish Pre-Service Teachers Think About Artificial Intelligence? Int. J. Comput. Sci. Educ. Sch. 2019, 3, 3–23. [Google Scholar] [CrossRef]
- Parapadakis, D. Can Artificial Intelligence Help Predict a Learner’s Needs? Lessons from Predicting Student Satisfaction. Lond. Rev. Educ. 2020, 18, 178–195. [Google Scholar] [CrossRef]
- Serholt, S.; Barendregt, W.; Vasalou, A.; Alves-Oliveira, P.; Jones, A.; Petisca, S.; Paiva, A. The case of classroom robots: Teachers’ deliberations on the ethical tensions. AI Soc. 2017, 32, 613–631. [Google Scholar] [CrossRef]
- Bostrom, N. The control problem. Excerpts from superintelligence: Paths, dangers, strategies. In Science Fiction and Philosophy: From Time Travel to Superintelligence; Wiley-Blackwell: Hoboken, NJ, USA, 2016; pp. 308–330. [Google Scholar]
- Parasuraman, R.; Riley, V. Humans and automation: Use, misuse, disuse, abuse. Hum. Factors 1997, 39, 230–253. [Google Scholar] [CrossRef]
- Dignum, V. The role and challenges of education for responsible AI. Lond. Rev. Educ. 2021, 19, 1–11. [Google Scholar] [CrossRef]
- Dignum, V. Responsible Artificial Intelligence: How to Develop and Use AI in a Responsible Way; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Dignum, V. AI is multidisciplinary. AI Matters 2020, 5, 18–21. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RL Applications | RL Technique | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ref. | PC | TSF | H&Q | AE | IS | MS | GEC | PE | MDP | POMDP | DRL | MC |
| [78] | ✓ | ✓ | ||||||||||
| [9] | ✓ | |||||||||||
| [11,12,13,14,30] | ✓ | |||||||||||
| [79] | ✓ | ✓ | ||||||||||
| [33,34] | ✓ | |||||||||||
| [38] | ✓ | ✓ | ||||||||||
| [39,40,41,43,44] | ✓ | |||||||||||
| [42] | ✓ | ✓ | ||||||||||
| [45,46,48] | ✓ | |||||||||||
| [47] | ✓ | ✓ | ✓ | |||||||||
| [17] | ✓ | ✓ | ||||||||||
| [18,49,86,87] | ✓ | ✓ | ||||||||||
| [50,51,52,60,61,62,63,69,88] | ✓ | |||||||||||
| [19] | ✓ | |||||||||||
| [53,54,55,59] | ✓ | ✓ | ||||||||||
| [56,57] | ✓ | |||||||||||
| [64,65,66,67,68] | ✓ | |||||||||||
| [70,71,72] | ✓ | |||||||||||
| [74,75,76] | ✓ | |||||||||||
| [31,32] | ✓ | |||||||||||
| [20,21,22,23,24] | ✓ | |||||||||||
| [25,26,27,28,29] | ✓ | |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fahad Mon, B.; Wasfi, A.; Hayajneh, M.; Slim, A.; Abu Ali, N. Reinforcement Learning in Education: A Literature Review. Informatics 2023, 10, 74. https://doi.org/10.3390/informatics10030074
Fahad Mon B, Wasfi A, Hayajneh M, Slim A, Abu Ali N. Reinforcement Learning in Education: A Literature Review. Informatics. 2023; 10(3):74. https://doi.org/10.3390/informatics10030074
Chicago/Turabian StyleFahad Mon, Bisni, Asma Wasfi, Mohammad Hayajneh, Ahmad Slim, and Najah Abu Ali. 2023. "Reinforcement Learning in Education: A Literature Review" Informatics 10, no. 3: 74. https://doi.org/10.3390/informatics10030074