
Two-Population Mortality Forecasting: An Approach Based on Model Averaging


Abstract
:1. Introduction
2. Two-Population Mortality Models
2.1. Model Estimation
2.2. Stochastic Factor Assumptions
3. Model-Averaging Approaches
- Equal weights (EW):
- Weights based on the the softmax function (SM):The concept is similar to the proportional weights model-averaging approach, but here we penalise less the models with poor performance in the validation period and reward less the models with good performance. See also Benchimol et al. (2016) for a similar formulation.
- Weights based on trimming (TR):where the best models are determined in terms of the measure ; see Samuels and Sekkel (2017) and Shang (2012). With this method, we reward only the models that have the best performance in the validation period, assigning the same weight () for each one of them. In the following, we set equal to 3.
4. Data
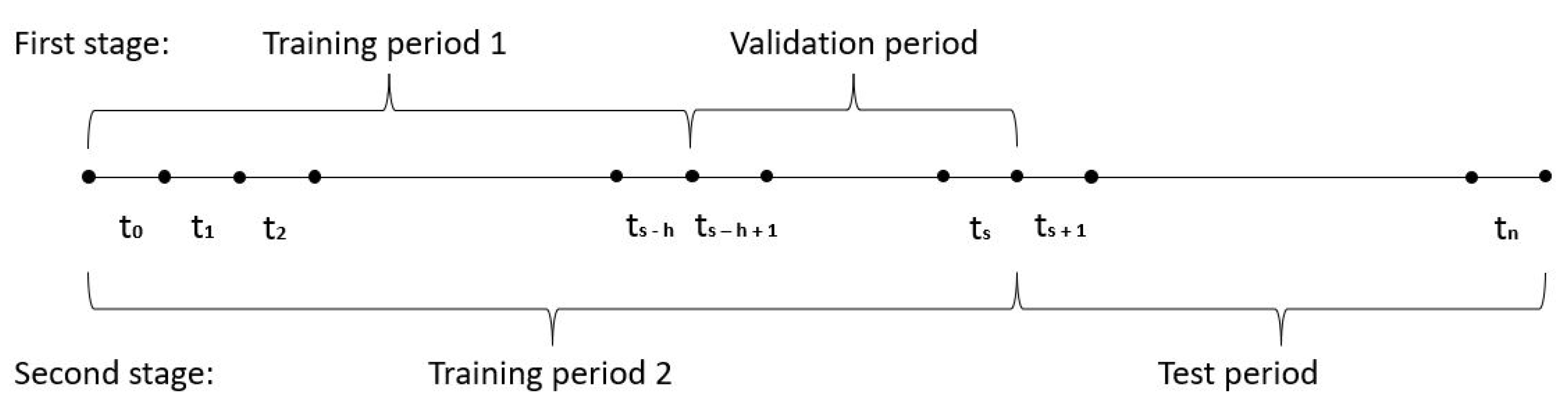
5. Implementation
Step-By-Step Procedure
- First stage
- 1.1
- We fit the two-population models (LC, RH, CBD, PLAT, M6, M7, M8, CF, and ACF) on the period (training period 1) using the StMoMo package; see Villegas et al. (2018). Notice that this implies h, i.e., the length of the validation period, is set equal to 10.
- 1.2
- We simulate mortality rates for the period (validation period) using the models fitted in 1.1.
- 1.3
- 1.4
- We repeat steps 1.2 and 1.3 1000 times, and we obtain the forecasted truncated life expectancy and Gini index as the average of these for each model.
- 1.5
- We calculate the MAFE as the difference between forecasted truncated life expectancy and Gini index calculated in 1.4 and the historical ones (Formula (10)) for each model.
- 1.6
- Second stage
- 2.1
- We repeat step 1.1 using the period (training period 2) instead of .
- 2.2
- We repeat steps 1.2 and 1.3 using the period (test period) instead of .
- 2.3
- We repeat step 2.2 10,000 times4 and we obtain the forecasted truncated average life expectancy and Gini index as the average of these for each model.
- 2.4
- For each model-averaging approach, we carry out 1 simulation from a multinomial distribution with parameters equal to 10,000, 9, and the vector of the weights obtained in 1.6. The result of this simulation will be a vector with 9 elements, which sum to 10,000, that represent the number of truncated life expectancy and Gini index trajectories that are considered in the model-averaging approach from the 9 two-population models.
- 2.5
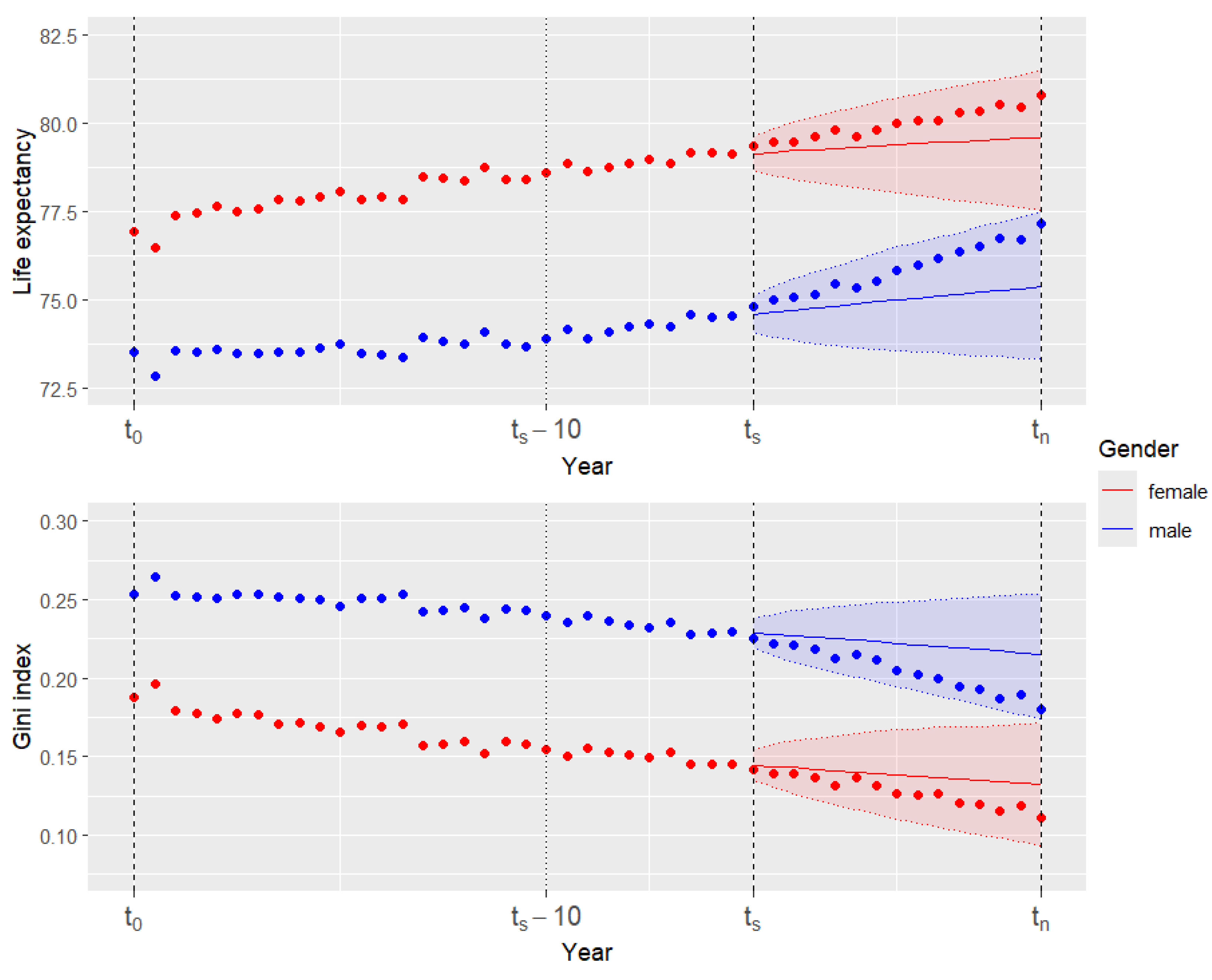
- Using the results of the simulation at point 2.4 as parameters, we resample by bootstrapping from the truncated life expectancy and Gini index trajectories obtained in step 2.3, and we average them using Formula (5) obtaining the forecasted truncated life expectancy and Gini index for all the model-averaging approaches. Similarly, we take the 5th and 95th percentile to build the 90% confidence forecasting intervals for the two metrics. See Figure 2 for an example of forecasted life expectancy and Gini index using the model-averaging approach with equal weights.
- 2.6
- We calculate the MAFE as the difference between the forecasted truncated life expectancy and the Gini index calculated in 2.3 and 2.5 with the observed ones. Similarly, we compare the confidence forecasting intervals of the two metrics with the observed values in order to obtain the interval forecast accuracy that represents the proportion of times in which the observed truncated life expectancy and Gini index fall within the respective prediction intervals.
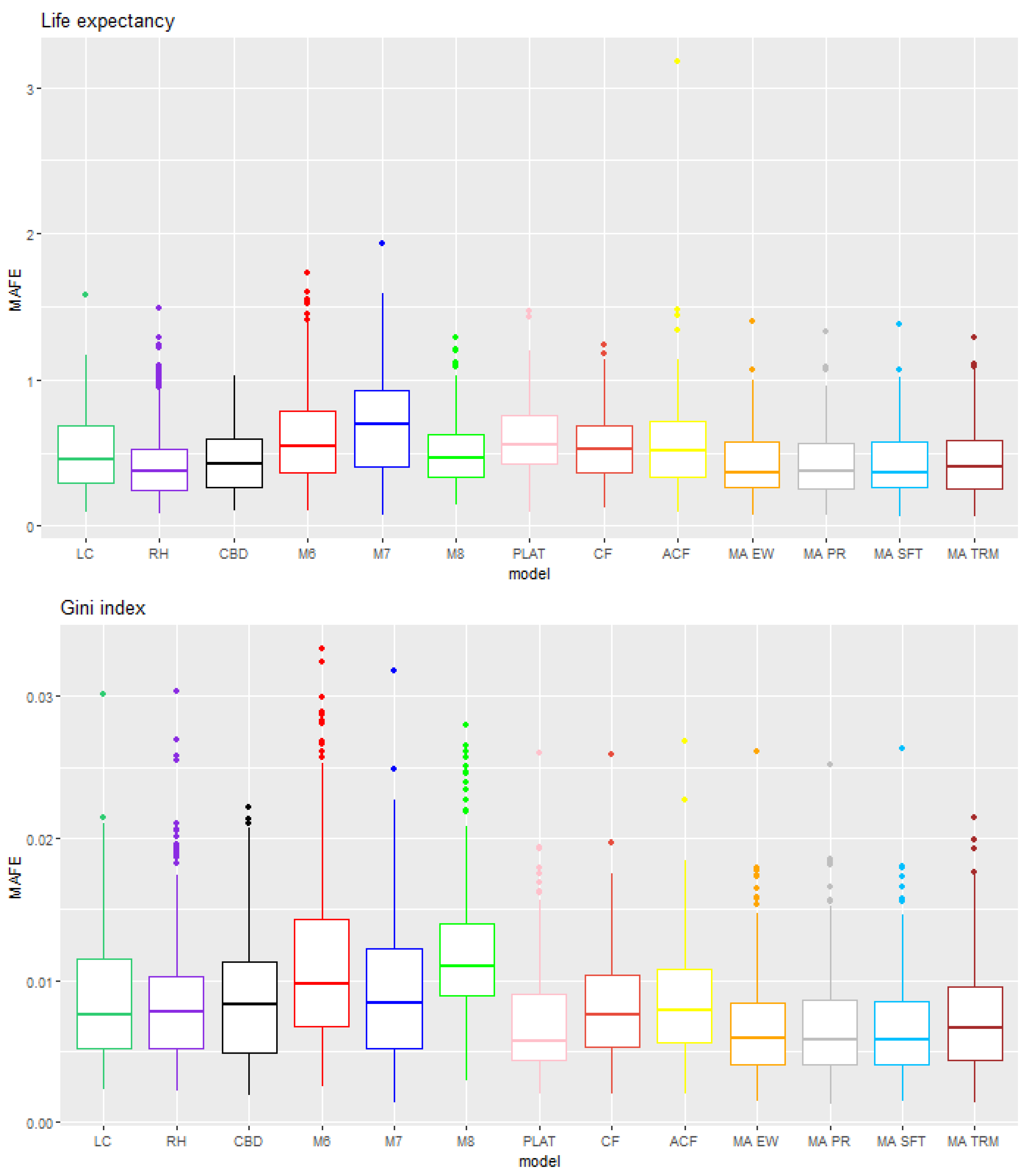
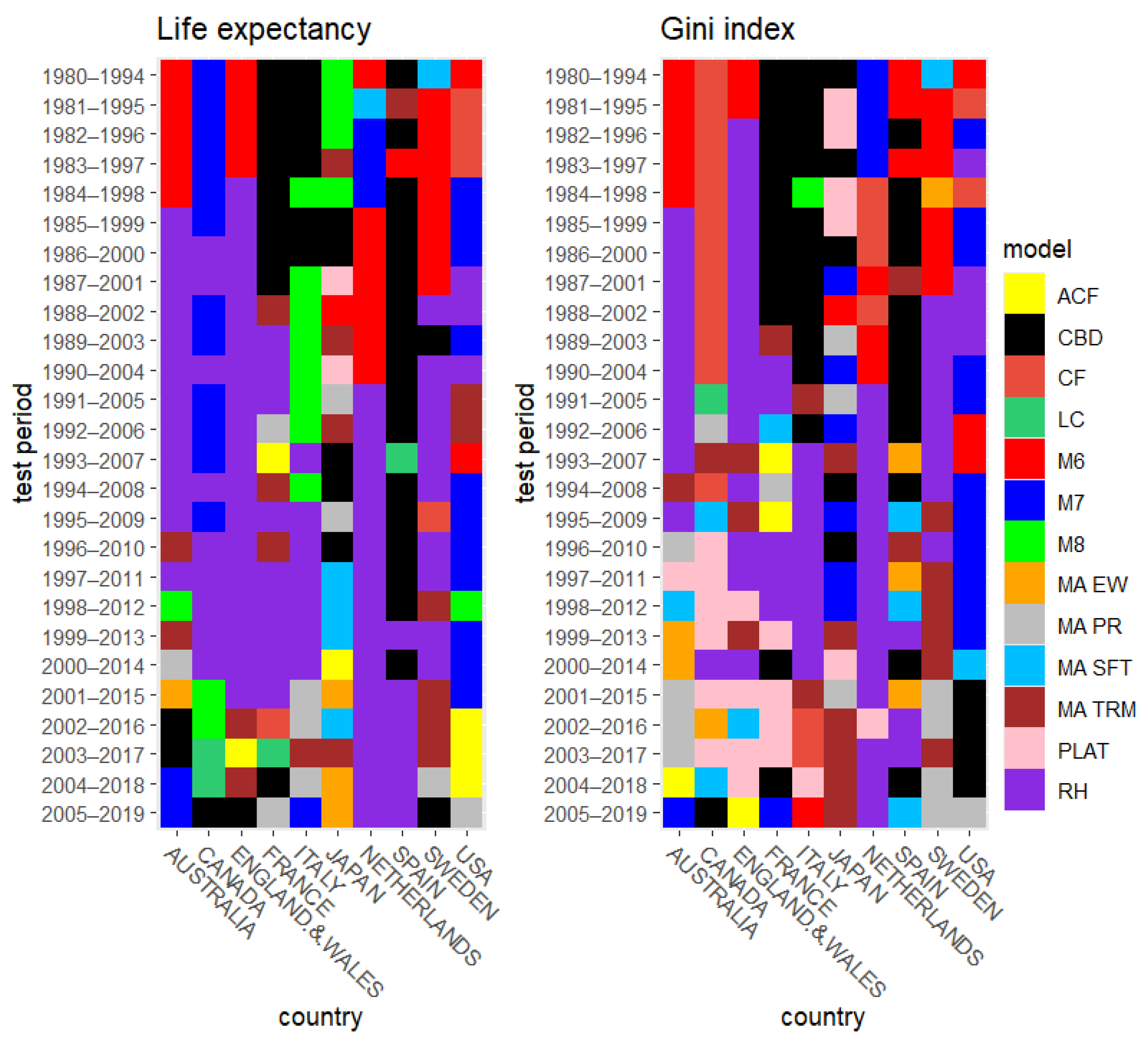
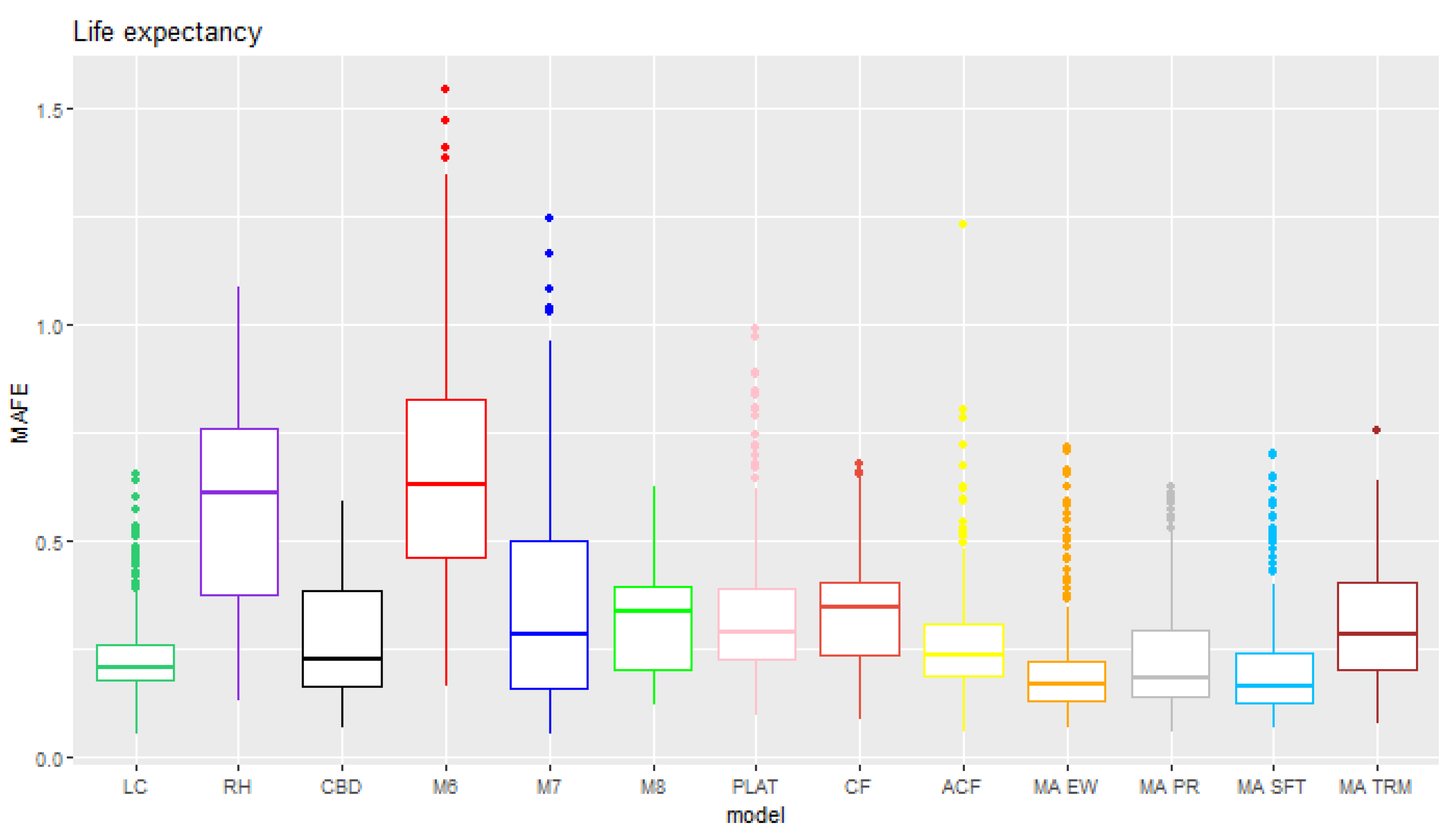
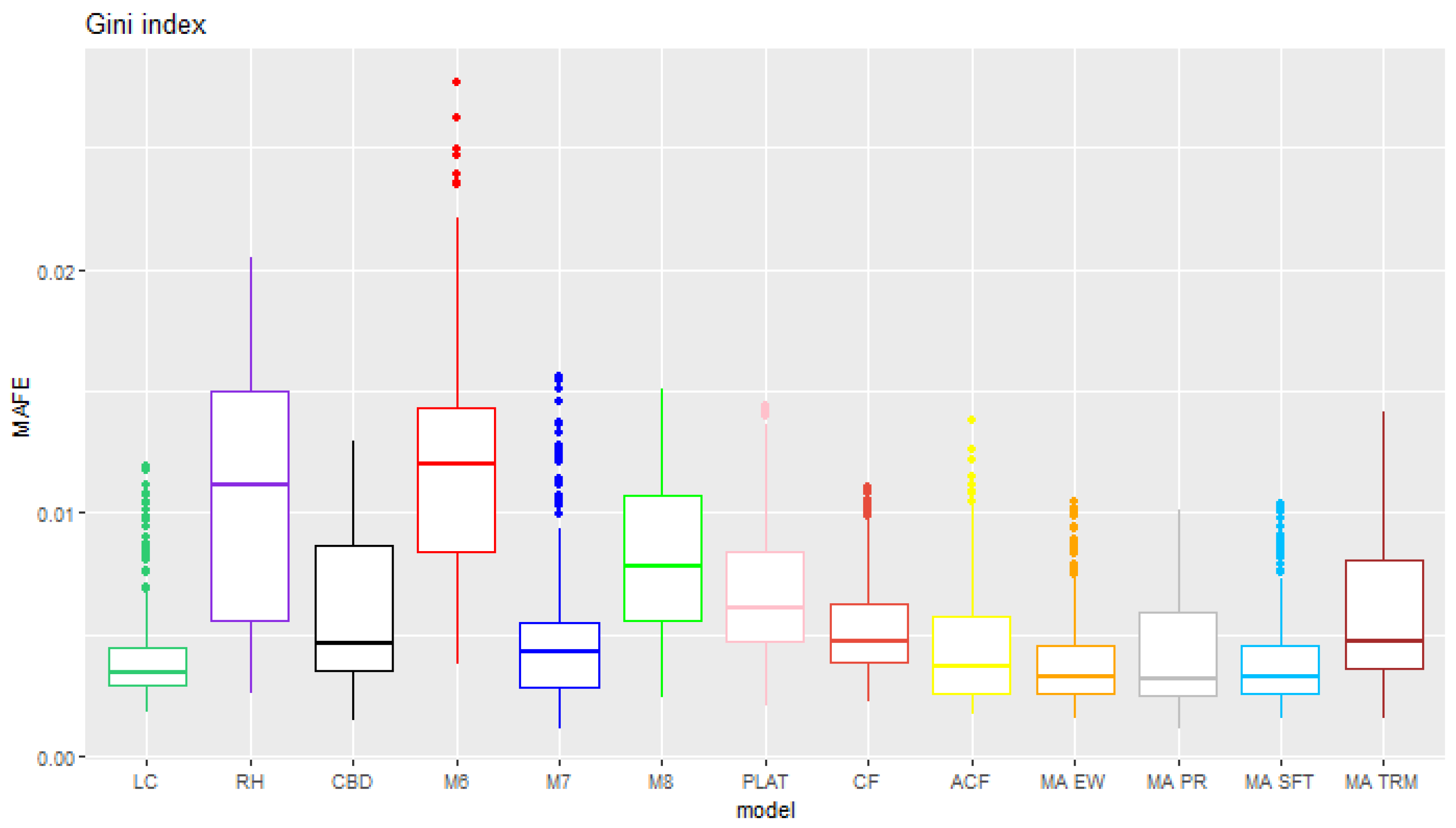
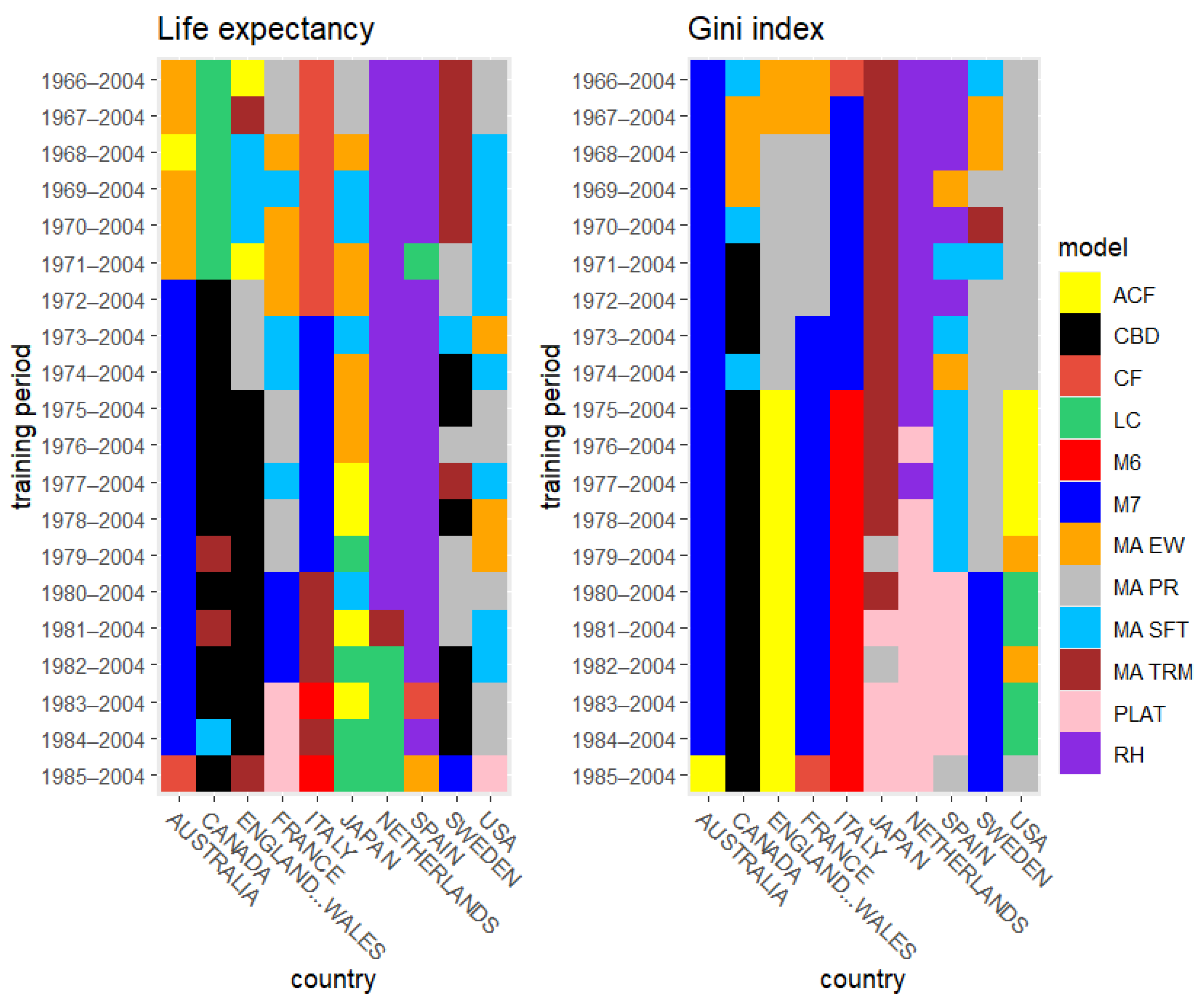
6. Results
6.1. Rolling Test Period
6.2. Fixed Test Period
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | Probabilities of death can be calculated from the corresponding mortality rates by using the relation , and vice versa, . |
| 2 | For consistency, we use the Poisson distribution assumption coupled with the log-link function and mortality rates for models such as M6, M7, and M8, which usually are presented under a binomial assumption coupled with the logit-link function and probabilities of death. |
| 3 | The formula used here is an approximation for the Gini index at age 55, truncated at age 90, which includes an additional term accounting for the survival past age 90. |
| 4 | We carry out more simulations than in the first stage since here we consider the interval forecast accuracy in addition to the MAFE. |
| 5 | These percentages have been calculated as the ratio of the number of cases in which each model is the best over the total number of cases considered (260). |
| 6 | These percentages have been calculated as the ratio of the number of cases in which each model is the best over the total number of cases considered (200). |
References
- Benchimol, Andrés Gustavo, Pablo J. Alonso, Juan Miguel Marín Díazaraque, and Irene Albarrán Lozano. 2016. Model Uncertainty Approach in Mortality Projection with Model Assembling Methodologies. Available online: https://e-archivo.uc3m.es/rest/api/core/bitstreams/cd474c81-da11-4ee0-92f2-04be244fc37e/content (accessed on 8 March 2024).
- Cairns, Andrew J. G., David Blake, and Kevin Dowd. 2006. A two-factor model for stochastic mortality with parameter uncertainty: Theory and calibration. Journal of Risk and Insurance 73: 687–718. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., David Blake, Kevin Dowd, Guy D. Coughlan, David Epstein, Alen Ong, and Igor Balevich. 2009. A quantitative comparison of stochastic mortality models using data from England and Wales and the United States. North American Actuarial Journal 13: 1–35. [Google Scholar] [CrossRef]
- Dickson, David C. M., Mary R. Hardy, and Howard R. Waters. 2019. Actuarial Mathematics for Life Contingent Risks. Cambridge: Cambridge University Press. [Google Scholar]
- Djeundje, Viani B., Steven Haberman, Madhavi Bajekal, and Joseph Lu. 2022. The slowdown in mortality improvement rates 2011–2017: A multi-country analysis. European Actuarial Journal 12: 839–78. [Google Scholar] [CrossRef]
- Dowd, Kevin, Andrew J. G. Cairns, David Blake, Guy D. Coughlan, David Epstein, and Marwa Khalaf-Allah. 2010. Evaluating the goodness of fit of stochastic mortality models. Insurance: Mathematics and Economics 47: 255–65. [Google Scholar] [CrossRef]
- Dowd, Kevin, Andrew J. G. Cairns, David Blake, Guy D. Coughlan, and Marwa Khalaf-Allah. 2011. A gravity model of mortality rates for two related populations. North American Actuarial Journal 15: 334–56. [Google Scholar] [CrossRef]
- Enchev, Vasil, Torsten Kleinow, and Andrew J. G. Cairns. 2017. Multi-population mortality models: Fitting, forecasting and comparisons. Scandinavian Actuarial Journal 2017: 319–42. [Google Scholar] [CrossRef]
- Fletcher, David. 2018. Model Averaging. Berlin/Heidelberg: Springer. [Google Scholar]
- Hinne, Max, Quentin F. Gronau, Don van den Bergh, and Eric-Jan Wagenmakers. 2020. A conceptual introduction to Bayesian model averaging. Advances in Methods and Practices in Psychological Science 3: 200–15. [Google Scholar] [CrossRef]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modeling and forecasting US mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar]
- Li, Jackie. 2013. A Poisson common factor model for projecting mortality and life expectancy jointly for females and males. Population Studies 67: 111–26. [Google Scholar] [CrossRef]
- Li, Johnny Siu-Hang, Rui Zhou, and Mary Hardy. 2015. A step-by-step guide to building two-population stochastic mortality models. Insurance: Mathematics and Economics 63: 121–34. [Google Scholar] [CrossRef]
- Li, Nan, and Ronald Lee. 2005. Coherent mortality forecasts for a group of populations: An extension of the Lee–Carter method. Demography 42: 575–94. [Google Scholar] [CrossRef] [PubMed]
- Plat, Richard. 2009. On stochastic mortality modeling. Insurance: Mathematics and Economics 45: 393–404. [Google Scholar]
- Renshaw, Arthur E., and Steven Haberman. 2006. A cohort-based extension to the Lee–Carter model for mortality reduction factors. Insurance: Mathematics and Economics 38: 556–70. [Google Scholar] [CrossRef]
- Samuels, Jon D., and Rodrigo M. Sekkel. 2017. Model confidence sets and forecast combination. International Journal of Forecasting 33: 48–60. [Google Scholar] [CrossRef]
- Shang, Han Lin. 2012. Point and interval forecasts of age-specific life expectancies: A model averaging approach. Demographic Research 27: 593–644. [Google Scholar] [CrossRef]
- Shang, Han Lin, Heather Booth, and Rob J. Hyndman. 2011. Point and interval forecasts of mortality rates and life expectancy: A comparison of ten principal component methods. Demographic Research 25: 173–214. [Google Scholar] [CrossRef]
- Shang, Han Lin, Steven Haberman, and Ruofan Xu. 2022. Multi-population modelling and forecasting life-table death counts. Insurance: Mathematics and Economics 106: 239–53. [Google Scholar] [CrossRef]
- Shkolnikov, Vladimir M., Evgueni E. Andreev, and Alexander Z. Begun. 2003. Gini coefficient as a life table function: Computation from discrete data, decomposition of differences and empirical examples. Demographic Research 8: 305–58. [Google Scholar] [CrossRef]
- Villegas, Andrés, Pietro Millossovich, and Vladimir Kaishev. 2018. StMoMo: Stochastic mortality modeling in R. Journal of Statistical Software 84: 1–38. [Google Scholar] [CrossRef]
- Villegas, Andrés M., Steven Haberman, Vladimir Kaishev, and Pietro Millossovich. 2017. A comparative study of two-population models for the assessment of basis risk in longevity hedges. ASTIN Bulletin: The Journal of the IAA 47: 631–79. [Google Scholar] [CrossRef]
- Yang, Bowen, Jackie Li, and Uditha Balasooriya. 2016. Cohort extensions of the Poisson common factor model for modelling both genders jointly. Scandinavian Actuarial Journal 2016: 93–112. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | |
| 1. Lee–Carter model (LC) | |
| 2. Renshaw–Haberman model (RH) | |
| 3. Cairns–Blake–Dowd model (CBD) | |
| 4. CBD Model with a cohort effect (M6) | |
| 5. CBD Model with quadratic and cohort effects (M7) | |
| 6. CBD Model with an age-dependent cohort effect (M8) | |
| 7. Plat model (PLAT) | |
| 8. Common Factor Model (CF) | |
| 9. Augmented Common Factor Model (ACF) |
| Training Period | Test Period | LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1950–1979 | 1980–1994 | 83% | 84% | 95% | 84% | 77% | 95% | 71% | 82% | 91% | 100% | 98% | 100% | 96% |
| 1951–1980 | 1981–1995 | 82% | 89% | 95% | 83% | 81% | 91% | 71% | 81% | 86% | 99% | 98% | 99% | 96% |
| 1952–1981 | 1982–1996 | 83% | 87% | 90% | 79% | 81% | 88% | 72% | 81% | 86% | 99% | 98% | 99% | 97% |
| 1953–1982 | 1983–1997 | 81% | 84% | 91% | 83% | 79% | 86% | 81% | 84% | 84% | 99% | 98% | 98% | 96% |
| 1954–1983 | 1984–1998 | 75% | 81% | 87% | 75% | 76% | 82% | 77% | 77% | 79% | 98% | 97% | 97% | 95% |
| 1955–1984 | 1985–1999 | 86% | 87% | 92% | 83% | 84% | 92% | 87% | 88% | 86% | 99% | 98% | 99% | 97% |
| 1956–1985 | 1986–2000 | 80% | 82% | 83% | 77% | 80% | 78% | 86% | 75% | 76% | 98% | 98% | 98% | 95% |
| 1957–1986 | 1987–2001 | 81% | 82% | 85% | 80% | 80% | 84% | 88% | 77% | 76% | 98% | 97% | 98% | 96% |
| 1958–1987 | 1988–2002 | 82% | 83% | 87% | 77% | 83% | 82% | 92% | 82% | 80% | 98% | 97% | 98% | 95% |
| 1959–1988 | 1989–2003 | 79% | 80% | 76% | 74% | 81% | 74% | 90% | 75% | 75% | 96% | 95% | 96% | 92% |
| 1960–1989 | 1990–2004 | 78% | 84% | 85% | 76% | 80% | 80% | 95% | 77% | 74% | 97% | 97% | 97% | 91% |
| 1961–1990 | 1991–2005 | 86% | 88% | 79% | 75% | 89% | 82% | 89% | 81% | 81% | 97% | 97% | 97% | 96% |
| 1962–1991 | 1992–2006 | 85% | 89% | 81% | 75% | 85% | 82% | 87% | 79% | 78% | 96% | 97% | 97% | 96% |
| 1963–1992 | 1993–2007 | 86% | 85% | 79% | 75% | 83% | 81% | 84% | 76% | 82% | 98% | 97% | 97% | 90% |
| 1964–1993 | 1994–2008 | 76% | 79% | 61% | 59% | 83% | 63% | 86% | 66% | 73% | 91% | 92% | 92% | 86% |
| 1965–1994 | 1995–2009 | 84% | 86% | 70% | 70% | 82% | 75% | 87% | 71% | 81% | 99% | 99% | 99% | 95% |
| 1966–1995 | 1996–2010 | 82% | 85% | 60% | 60% | 84% | 65% | 90% | 70% | 76% | 97% | 97% | 97% | 87% |
| 1967–1996 | 1997–2011 | 81% | 82% | 61% | 60% | 81% | 66% | 90% | 67% | 76% | 97% | 98% | 98% | 96% |
| 1968–1997 | 1998–2012 | 85% | 81% | 60% | 62% | 79% | 72% | 89% | 70% | 79% | 98% | 98% | 98% | 93% |
| 1969–1998 | 1999–2013 | 82% | 79% | 53% | 59% | 74% | 66% | 88% | 68% | 76% | 96% | 95% | 96% | 89% |
| 1970–1999 | 2000–2014 | 74% | 75% | 33% | 41% | 73% | 54% | 86% | 61% | 73% | 94% | 95% | 95% | 88% |
| 1971–2000 | 2001–2015 | 88% | 83% | 45% | 59% | 77% | 68% | 72% | 65% | 80% | 96% | 94% | 96% | 91% |
| 1972–2001 | 2002–2016 | 90% | 86% | 49% | 70% | 79% | 68% | 62% | 64% | 86% | 98% | 98% | 98% | 94% |
| 1973–2002 | 2003–2017 | 87% | 82% | 35% | 63% | 74% | 67% | 70% | 62% | 85% | 95% | 94% | 95% | 78% |
| 1974–2003 | 2004–2018 | 75% | 82% | 25% | 52% | 68% | 56% | 61% | 59% | 79% | 92% | 90% | 92% | 82% |
| 1975–2004 | 2005–2019 | 90% | 77% | 51% | 83% | 77% | 83% | 41% | 68% | 87% | 99% | 99% | 98% | 95% |
| Average | 82% | 83% | 70% | 71% | 80% | 76% | 81% | 73% | 80% | 97% | 97% | 97% | 93% | |
| LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUSTRALIA | 90% | 94% | 82% | 95% | 96% | 84% | 91% | 92% | 91% | 99% | 99% | 99% | 97% |
| CANADA | 61% | 62% | 49% | 78% | 59% | 54% | 58% | 62% | 52% | 99% | 96% | 99% | 78% |
| ENGLAND AND WALES | 74% | 75% | 78% | 69% | 71% | 70% | 89% | 63% | 75% | 99% | 99% | 99% | 99% |
| FRANCE | 97% | 96% | 34% | 63% | 89% | 80% | 88% | 87% | 97% | 100% | 99% | 100% | 97% |
| ITALY | 84% | 88% | 70% | 59% | 88% | 76% | 83% | 88% | 85% | 97% | 97% | 98% | 95% |
| JAPAN | 99% | 87% | 87% | 62% | 75% | 96% | 80% | 50% | 99% | 100% | 100% | 100% | 96% |
| NETHERLANDS | 56% | 61% | 77% | 71% | 57% | 76% | 80% | 67% | 58% | 86% | 87% | 87% | 86% |
| SPAIN | 98% | 98% | 85% | 70% | 95% | 94% | 95% | 88% | 99% | 100% | 100% | 100% | 95% |
| SWEDEN | 73% | 80% | 62% | 42% | 78% | 65% | 71% | 69% | 66% | 91% | 88% | 90% | 84% |
| USA | 91% | 92% | 71% | 96% | 89% | 67% | 71% | 67% | 80% | 100% | 100% | 100% | 98% |
| Average | 82% | 83% | 70% | 71% | 80% | 76% | 81% | 73% | 80% | 97% | 97% | 97% | 93% |
| Training Period | Test Period | LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1950–1979 | 1980–1994 | 92% | 81% | 97% | 96% | 74% | 95% | 79% | 90% | 91% | 100% | 100% | 100% | 98% |
| 1951–1980 | 1981–1995 | 89% | 88% | 97% | 96% | 74% | 95% | 79% | 86% | 86% | 99% | 99% | 99% | 99% |
| 1952–1981 | 1982–1996 | 90% | 82% | 92% | 93% | 73% | 94% | 79% | 85% | 86% | 99% | 99% | 99% | 97% |
| 1953–1982 | 1983–1997 | 89% | 77% | 97% | 98% | 71% | 93% | 86% | 88% | 87% | 99% | 99% | 100% | 98% |
| 1954–1983 | 1984–1998 | 81% | 76% | 87% | 86% | 68% | 96% | 83% | 80% | 76% | 98% | 97% | 97% | 95% |
| 1955–1984 | 1985–1999 | 92% | 83% | 94% | 96% | 73% | 100% | 89% | 90% | 89% | 100% | 100% | 100% | 99% |
| 1956–1985 | 1986–2000 | 85% | 78% | 85% | 95% | 72% | 97% | 87% | 78% | 78% | 98% | 97% | 98% | 93% |
| 1957–1986 | 1987–2001 | 86% | 79% | 85% | 95% | 69% | 98% | 90% | 81% | 78% | 99% | 99% | 99% | 97% |
| 1958–1987 | 1988–2002 | 86% | 79% | 91% | 95% | 66% | 98% | 92% | 86% | 81% | 99% | 98% | 98% | 96% |
| 1959–1988 | 1989–2003 | 84% | 79% | 82% | 91% | 72% | 95% | 90% | 77% | 74% | 96% | 96% | 96% | 94% |
| 1960–1989 | 1990–2004 | 84% | 75% | 87% | 93% | 61% | 97% | 94% | 79% | 76% | 99% | 99% | 99% | 94% |
| 1961–1990 | 1991–2005 | 90% | 84% | 85% | 93% | 68% | 95% | 88% | 75% | 84% | 98% | 98% | 98% | 96% |
| 1962–1991 | 1992–2006 | 87% | 83% | 88% | 93% | 63% | 93% | 84% | 75% | 81% | 98% | 98% | 98% | 95% |
| 1963–1992 | 1993–2007 | 84% | 81% | 85% | 90% | 58% | 89% | 82% | 74% | 76% | 95% | 94% | 95% | 91% |
| 1964–1993 | 1994–2008 | 78% | 82% | 69% | 81% | 63% | 91% | 87% | 68% | 67% | 95% | 95% | 96% | 90% |
| 1965–1994 | 1995–2009 | 90% | 83% | 79% | 96% | 62% | 93% | 83% | 74% | 78% | 99% | 99% | 99% | 96% |
| 1966–1995 | 1996–2010 | 82% | 83% | 69% | 87% | 64% | 93% | 89% | 75% | 68% | 100% | 99% | 100% | 94% |
| 1967–1996 | 1997–2011 | 85% | 81% | 71% | 86% | 63% | 92% | 88% | 71% | 69% | 99% | 98% | 99% | 95% |
| 1968–1997 | 1998–2012 | 86% | 81% | 70% | 86% | 59% | 90% | 84% | 74% | 77% | 99% | 98% | 99% | 96% |
| 1969–1998 | 1999–2013 | 84% | 78% | 64% | 81% | 59% | 91% | 86% | 69% | 72% | 97% | 97% | 97% | 95% |
| 1970–1999 | 2000–2014 | 74% | 81% | 42% | 67% | 63% | 88% | 87% | 59% | 58% | 97% | 96% | 97% | 90% |
| 1971–2000 | 2001–2015 | 86% | 82% | 58% | 87% | 66% | 86% | 72% | 66% | 73% | 97% | 96% | 97% | 91% |
| 1972–2001 | 2002–2016 | 89% | 80% | 60% | 91% | 67% | 85% | 58% | 67% | 83% | 100% | 100% | 100% | 91% |
| 1973–2002 | 2003–2017 | 82% | 79% | 49% | 85% | 68% | 89% | 70% | 60% | 76% | 95% | 95% | 95% | 85% |
| 1974–2003 | 2004–2018 | 73% | 86% | 38% | 69% | 63% | 86% | 64% | 55% | 67% | 95% | 95% | 95% | 83% |
| 1975–2004 | 2005–2019 | 89% | 72% | 61% | 95% | 64% | 72% | 40% | 73% | 84% | 100% | 100% | 100% | 93% |
| Average | 85% | 81% | 76% | 89% | 66% | 92% | 81% | 75% | 77% | 98% | 98% | 98% | 94% | |
| LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUSTRALIA | 93% | 97% | 83% | 99% | 95% | 89% | 90% | 90% | 85% | 100% | 100% | 100% | 97% |
| CANADA | 69% | 51% | 61% | 78% | 38% | 80% | 55% | 67% | 57% | 100% | 98% | 100% | 82% |
| ENGLAND AND WALES | 83% | 75% | 78% | 84% | 84% | 94% | 88% | 64% | 67% | 100% | 100% | 100% | 96% |
| FRANCE | 94% | 89% | 42% | 92% | 68% | 97% | 86% | 86% | 92% | 100% | 100% | 100% | 97% |
| ITALY | 88% | 95% | 84% | 91% | 78% | 95% | 82% | 87% | 79% | 99% | 99% | 99% | 98% |
| JAPAN | 93% | 83% | 89% | 96% | 56% | 98% | 84% | 46% | 88% | 100% | 100% | 100% | 100% |
| NETHERLANDS | 59% | 56% | 80% | 83% | 47% | 91% | 82% | 75% | 66% | 91% | 90% | 91% | 85% |
| SPAIN | 98% | 98% | 88% | 92% | 71% | 97% | 95% | 91% | 97% | 100% | 100% | 100% | 100% |
| SWEDEN | 81% | 82% | 78% | 79% | 59% | 89% | 80% | 75% | 66% | 93% | 92% | 93% | 89% |
| USA | 93% | 82% | 79% | 98% | 67% | 89% | 70% | 72% | 78% | 99% | 99% | 99% | 95% |
| Average | 85% | 81% | 76% | 89% | 66% | 92% | 81% | 75% | 77% | 98% | 98% | 98% | 94% |
| Training Period | Test Period | LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1966–2004 | 2005–2019 | 91% | 84% | 48% | 62% | 83% | 78% | 62% | 69% | 84% | 98% | 99% | 97% | 93% |
| 1967–2004 | 2005–2019 | 91% | 84% | 49% | 63% | 82% | 77% | 59% | 70% | 85% | 97% | 99% | 98% | 93% |
| 1968–2004 | 2005–2019 | 91% | 82% | 52% | 67% | 80% | 79% | 55% | 71% | 88% | 96% | 97% | 97% | 92% |
| 1969–2004 | 2005–2019 | 90% | 81% | 52% | 72% | 79% | 80% | 54% | 71% | 88% | 97% | 99% | 99% | 93% |
| 1970–2004 | 2005–2019 | 91% | 81% | 50% | 70% | 79% | 79% | 50% | 70% | 88% | 98% | 99% | 98% | 94% |
| 1971–2004 | 2005–2019 | 91% | 80% | 49% | 75% | 79% | 79% | 47% | 69% | 88% | 99% | 99% | 99% | 94% |
| 1972–2004 | 2005–2019 | 91% | 80% | 47% | 75% | 78% | 78% | 45% | 66% | 87% | 99% | 99% | 99% | 93% |
| 1973–2004 | 2005–2019 | 91% | 78% | 50% | 78% | 77% | 81% | 43% | 68% | 88% | 98% | 99% | 98% | 89% |
| 1974–2004 | 2005–2019 | 91% | 79% | 51% | 81% | 78% | 82% | 44% | 68% | 88% | 99% | 98% | 98% | 90% |
| 1975–2004 | 2005–2019 | 90% | 77% | 50% | 83% | 78% | 84% | 40% | 69% | 87% | 97% | 99% | 99% | 94% |
| 1976–2004 | 2005–2019 | 90% | 78% | 52% | 86% | 78% | 85% | 39% | 70% | 88% | 99% | 98% | 98% | 95% |
| 1977–2004 | 2005–2019 | 91% | 79% | 49% | 85% | 77% | 84% | 40% | 72% | 89% | 96% | 98% | 97% | 94% |
| 1978–2004 | 2005–2019 | 90% | 79% | 51% | 87% | 78% | 85% | 37% | 75% | 90% | 97% | 98% | 97% | 96% |
| 1979–2004 | 2005–2019 | 90% | 81% | 49% | 89% | 78% | 84% | 37% | 76% | 90% | 97% | 98% | 98% | 94% |
| 1980–2004 | 2005–2019 | 89% | 79% | 52% | 89% | 77% | 85% | 35% | 73% | 88% | 98% | 98% | 97% | 99% |
| 1981–2004 | 2005–2019 | 89% | 79% | 53% | 91% | 77% | 85% | 35% | 74% | 88% | 98% | 98% | 98% | 100% |
| 1982–2004 | 2005–2019 | 89% | 80% | 56% | 90% | 78% | 84% | 36% | 75% | 88% | 98% | 98% | 98% | 98% |
| 1983–2004 | 2005–2019 | 86% | 80% | 57% | 90% | 77% | 82% | 33% | 76% | 86% | 99% | 99% | 99% | 95% |
| 1984–2004 | 2005–2019 | 86% | 82% | 57% | 93% | 78% | 86% | 34% | 76% | 87% | 99% | 99% | 99% | 97% |
| 1985–2004 | 2005–2019 | 82% | 78% | 62% | 93% | 80% | 85% | 34% | 75% | 85% | 99% | 99% | 99% | 94% |
| Average | 90% | 80% | 52% | 81% | 79% | 82% | 43% | 72% | 87% | 98% | 98% | 98% | 94% | |
| LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Australia | 96% | 100% | 71% | 100% | 100% | 98% | 37% | 95% | 99% | 100% | 100% | 100% | 97% |
| Canada | 85% | 87% | 28% | 94% | 84% | 52% | 30% | 32% | 65% | 99% | 98% | 99% | 84% |
| England and Wales | 99% | 100% | 66% | 100% | 98% | 79% | 32% | 64% | 96% | 100% | 100% | 100% | 100% |
| France | 90% | 54% | 18% | 89% | 64% | 97% | 33% | 98% | 92% | 100% | 100% | 100% | 99% |
| Italy | 91% | 73% | 87% | 96% | 69% | 93% | 24% | 97% | 95% | 100% | 100% | 100% | 83% |
| Japan | 99% | 48% | 58% | 73% | 50% | 100% | 53% | 60% | 100% | 100% | 100% | 100% | 100% |
| Netherlands | 55% | 62% | 47% | 45% | 58% | 50% | 80% | 48% | 51% | 80% | 87% | 82% | 97% |
| Spain | 100% | 90% | 39% | 65% | 77% | 93% | 99% | 84% | 100% | 100% | 100% | 100% | 92% |
| Sweden | 100% | 100% | 52% | 81% | 100% | 89% | 21% | 93% | 99% | 100% | 100% | 100% | 100% |
| USA | 82% | 88% | 48% | 66% | 87% | 71% | 21% | 46% | 79% | 100% | 100% | 100% | 92% |
| Average | 90% | 80% | 52% | 81% | 79% | 82% | 43% | 72% | 87% | 98% | 98% | 98% | 94% |
| Training Period | Test Period | LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1966–2004 | 2005–2019 | 91% | 80% | 60% | 88% | 64% | 85% | 62% | 73% | 87% | 99% | 100% | 99% | 93% |
| 1967–2004 | 2005–2019 | 91% | 78% | 62% | 91% | 67% | 85% | 61% | 73% | 87% | 99% | 100% | 99% | 93% |
| 1968–2004 | 2005–2019 | 91% | 75% | 63% | 91% | 59% | 80% | 56% | 73% | 87% | 99% | 100% | 99% | 94% |
| 1969–2004 | 2005–2019 | 91% | 74% | 62% | 92% | 62% | 80% | 56% | 73% | 87% | 99% | 100% | 99% | 91% |
| 1970–2004 | 2005–2019 | 91% | 76% | 61% | 92% | 62% | 81% | 51% | 72% | 87% | 99% | 99% | 99% | 91% |
| 1971–2004 | 2005–2019 | 90% | 74% | 60% | 93% | 62% | 82% | 50% | 73% | 87% | 99% | 100% | 99% | 92% |
| 1972–2004 | 2005–2019 | 91% | 76% | 57% | 93% | 60% | 77% | 47% | 72% | 88% | 100% | 100% | 100% | 93% |
| 1973–2004 | 2005–2019 | 90% | 71% | 61% | 93% | 61% | 75% | 43% | 72% | 85% | 99% | 99% | 99% | 94% |
| 1974–2004 | 2005–2019 | 90% | 72% | 60% | 94% | 60% | 73% | 44% | 73% | 85% | 100% | 100% | 100% | 96% |
| 1975–2004 | 2005–2019 | 89% | 73% | 60% | 95% | 66% | 73% | 41% | 73% | 84% | 100% | 100% | 100% | 93% |
| 1976–2004 | 2005–2019 | 89% | 75% | 60% | 94% | 62% | 68% | 40% | 74% | 84% | 100% | 100% | 100% | 94% |
| 1977–2004 | 2005–2019 | 88% | 73% | 59% | 92% | 64% | 72% | 38% | 73% | 83% | 99% | 99% | 99% | 91% |
| 1978–2004 | 2005–2019 | 88% | 72% | 61% | 91% | 67% | 70% | 36% | 75% | 82% | 99% | 99% | 99% | 93% |
| 1979–2004 | 2005–2019 | 88% | 75% | 56% | 91% | 70% | 73% | 37% | 74% | 83% | 99% | 99% | 99% | 92% |
| 1980–2004 | 2005–2019 | 88% | 72% | 60% | 89% | 67% | 69% | 35% | 74% | 83% | 99% | 99% | 99% | 94% |
| 1981–2004 | 2005–2019 | 88% | 74% | 61% | 89% | 68% | 71% | 35% | 74% | 82% | 99% | 99% | 99% | 93% |
| 1982–2004 | 2005–2019 | 88% | 75% | 60% | 90% | 71% | 71% | 36% | 74% | 83% | 99% | 100% | 99% | 95% |
| 1983–2004 | 2005–2019 | 84% | 71% | 62% | 85% | 71% | 66% | 35% | 71% | 78% | 98% | 97% | 98% | 88% |
| 1984–2004 | 2005–2019 | 85% | 73% | 62% | 90% | 73% | 68% | 38% | 72% | 80% | 99% | 99% | 99% | 93% |
| 1985–2004 | 2005–2019 | 81% | 71% | 66% | 88% | 68% | 62% | 37% | 70% | 77% | 98% | 98% | 98% | 86% |
| Average | 89% | 74% | 61% | 91% | 65% | 74% | 44% | 73% | 84% | 99% | 99% | 99% | 93% | |
| LC | CBD | M6 | M7 | M8 | PLAT | RH | CF | ACF | MA E.W | MA PR.W | MA S.M | MA TR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUSTRALIA | 99% | 100% | 77% | 100% | 84% | 32% | 37% | 96% | 97% | 100% | 100% | 100% | 75% |
| CANADA | 64% | 95% | 48% | 82% | 91% | 69% | 29% | 46% | 42% | 100% | 100% | 100% | 81% |
| ENGLAND AND WALES | 99% | 100% | 58% | 100% | 97% | 79% | 33% | 70% | 96% | 100% | 100% | 100% | 100% |
| FRANCE | 93% | 23% | 27% | 97% | 49% | 87% | 31% | 97% | 91% | 100% | 100% | 100% | 96% |
| ITALY | 84% | 54% | 96% | 93% | 50% | 43% | 22% | 85% | 81% | 97% | 98% | 98% | 89% |
| JAPAN | 99% | 37% | 84% | 84% | 27% | 96% | 67% | 46% | 98% | 99% | 100% | 99% | 99% |
| NETHERLANDS | 52% | 72% | 53% | 64% | 74% | 100% | 81% | 50% | 45% | 96% | 97% | 96% | 86% |
| SPAIN | 98% | 87% | 50% | 96% | 50% | 92% | 95% | 89% | 96% | 99% | 100% | 100% | 99% |
| SWEDEN | 100% | 94% | 62% | 98% | 58% | 74% | 21% | 93% | 99% | 100% | 100% | 100% | 100% |
| USA | 100% | 79% | 53% | 96% | 74% | 69% | 25% | 57% | 96% | 100% | 100% | 100% | 100% |
| Average | 89% | 74% | 61% | 91% | 65% | 74% | 44% | 73% | 84% | 99% | 99% | 99% | 93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Mori, L.; Millossovich, P.; Zhu, R.; Haberman, S. Two-Population Mortality Forecasting: An Approach Based on Model Averaging. Risks 2024, 12, 60. https://doi.org/10.3390/risks12040060
De Mori L, Millossovich P, Zhu R, Haberman S. Two-Population Mortality Forecasting: An Approach Based on Model Averaging. Risks. 2024; 12(4):60. https://doi.org/10.3390/risks12040060
Chicago/Turabian StyleDe Mori, Luca, Pietro Millossovich, Rui Zhu, and Steven Haberman. 2024. "Two-Population Mortality Forecasting: An Approach Based on Model Averaging" Risks 12, no. 4: 60. https://doi.org/10.3390/risks12040060