In this section, we will review and analyze the literature, gaps in the existing literature, and conceptual models for predicting investment risks in the stock market, which is dynamic and sensitive to extreme fluctuations.
4.1. Literature Analysis
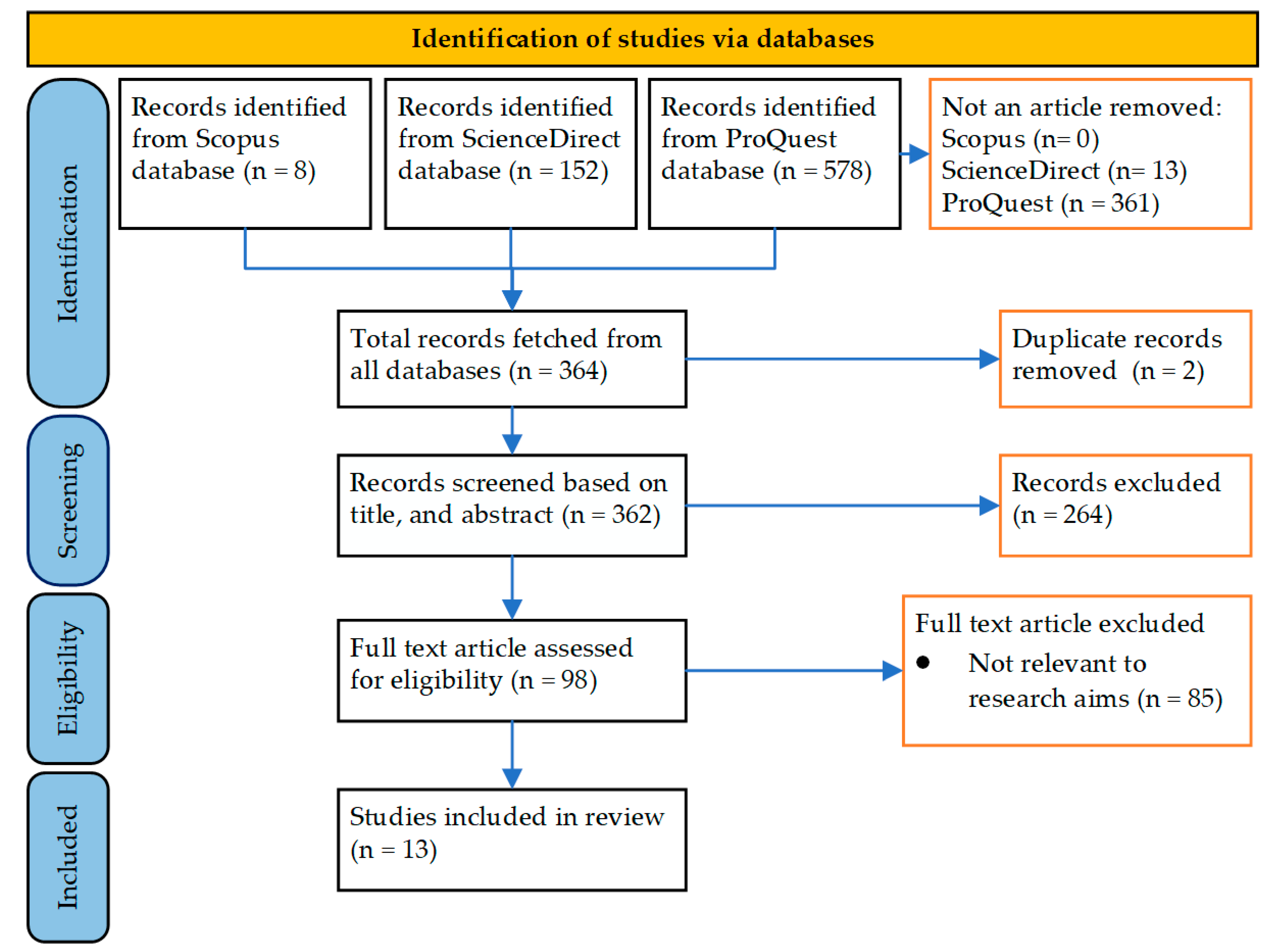
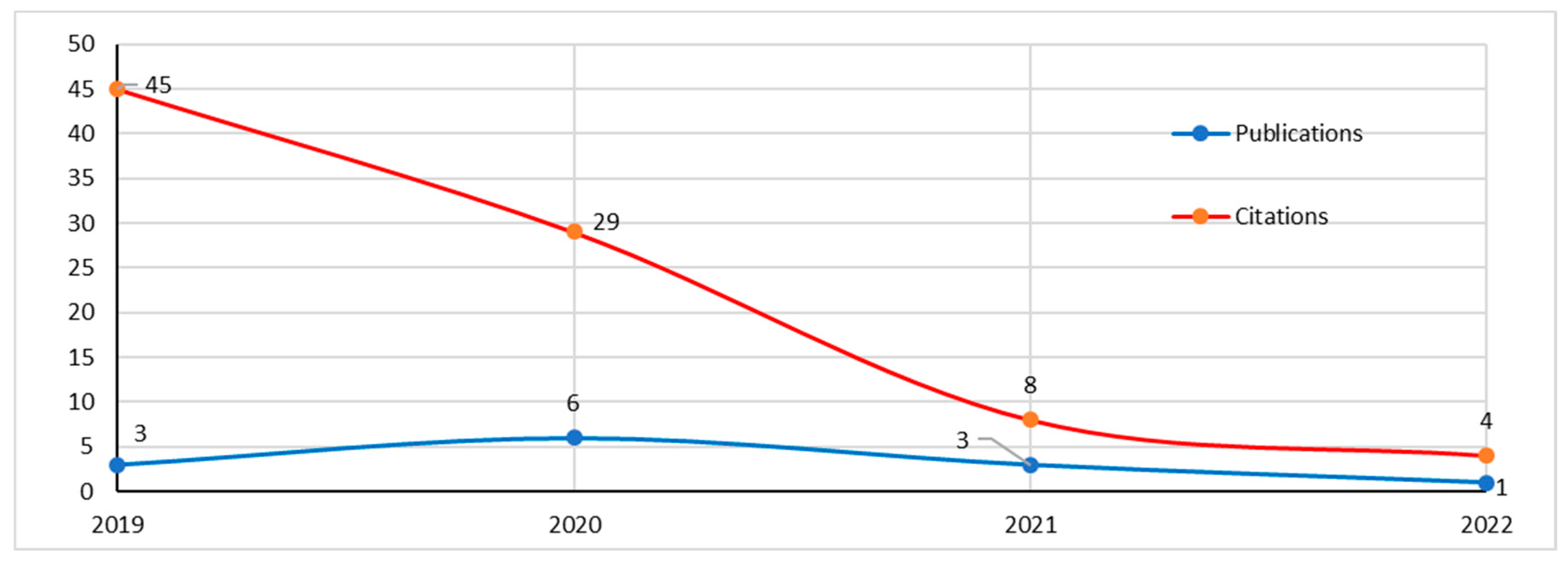
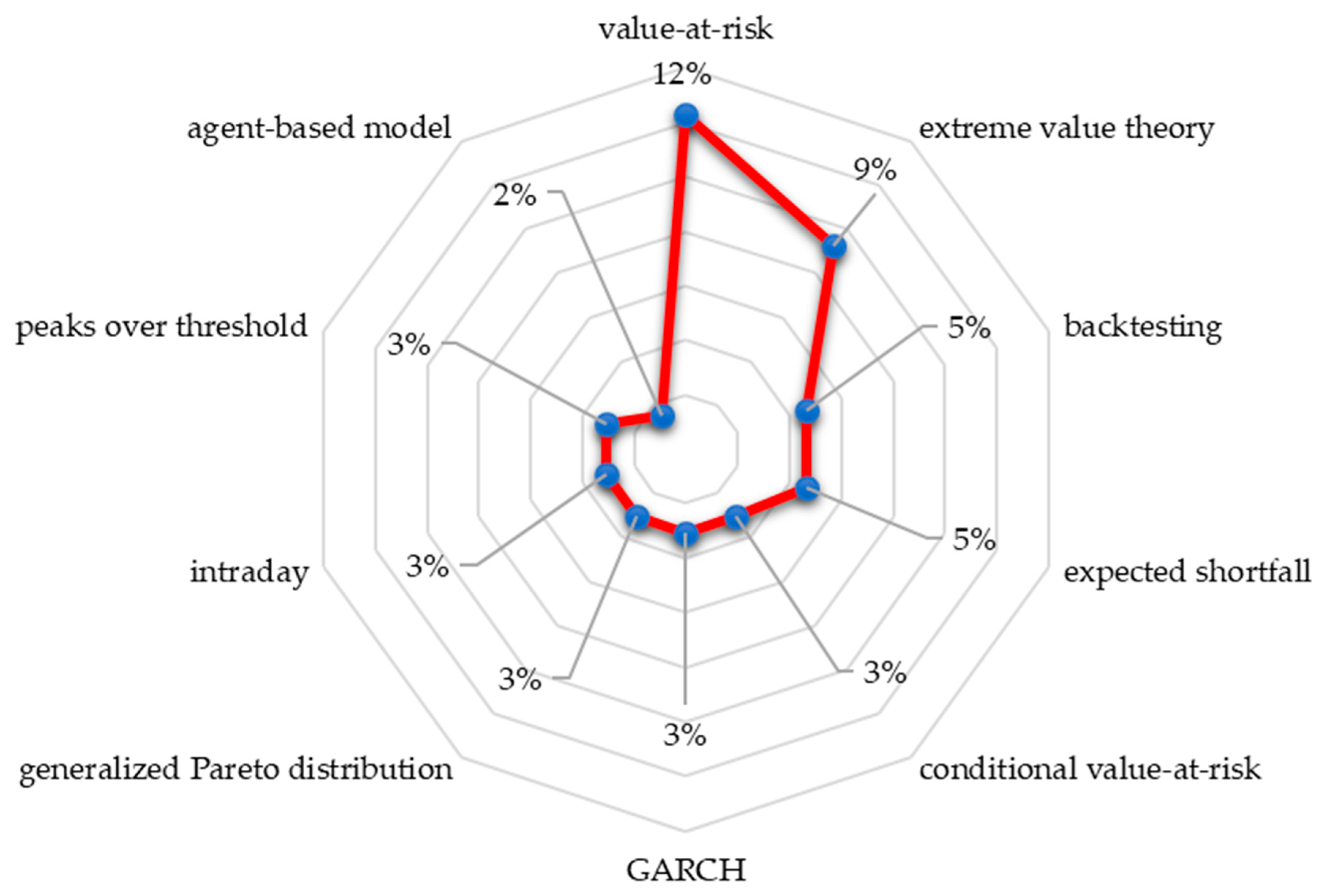
Predicting the level of investment risk in the stock market is an interesting challenge. Moreover, the pandemic caused turmoil and disruption in the economic sector, especially the stock market. However, research on this topic is scant; only 13 studies were selected and used in this S-SLR. The VaR method was used to estimate investment risk here. However, in reality, data related to the financial sector often contain extreme values; to overcome this, an EVT approach is needed. In identifying and detecting movements in extreme values, two methods can be used, namely block maxima (BM) and peaks over threshold (POT) (
Chen and Yu 2020).
The BM method identifies extreme values through the maximum value of data observations entered into a particular block or period. This approach produces only one extreme value in each block. Generalized extreme value (GEV) parameter estimation uses the maximum likelihood estimation (MLE) method when the closed form is produced by the parameter’s maximum value of the likelihood function, and it can be solved by using Newton’s technique. The goal is to obtain the location parameter (μ), the scale parameter (σ), and the shape parameter (ξ). According to
Chebbi and Hedhli (
2022), this method is inefficient because it identifies only one extreme value and ignores other extreme values; this method focuses only on events with a larger magnitude. The BM method largely removes data because only one extreme value from each block is used; thus, in practice, it is increasingly being replaced by methods based on peaks over threshold (POT), where all the data representing extreme values are used.
One well-known EVT model is the POT, which assumes that extreme risks are independently and identically distributed from the generalized Pareto distribution (GPD) (
Ji et al. 2020). The POT method is preferred over the BM method (
Song et al. 2021). This can be seen from the literature used in this study, in which the POT method was used to identify extreme values. The POT method is generally used because of its efficiency when data on extreme events are limited (
Chen and Yu 2020). According to
Ji et al. (
2019), the GPD assumes a flexible structure by changing the shape parameter to accommodate various tail behaviors in the general framework of the EVT. Research by
Bień-Barkowska (
2020) concluded that the POT method is more efficient for practical applications because it uses all large realizations of variables, provided that they exceed a sufficiently high threshold.
The POT method is one way of identifying extreme data behavior patterns by determining the extreme threshold value. Data that exceed the threshold are extreme values (
Saputra et al. 2022). The threshold value
is determined as optimally as possible, resulting in a minimum error rate. Let
be a sequence of independent and identically distributed random variables, with a common distribution function,
. The POT model approach focuses on estimating the distribution function,
, of values of
above a high
. The distribution of excesses over a high
is defined as follows:
for
, where
is the right endpoint of
.
As shown by
Balkema and Haan (
1974) and
Pickands (
1975), for a large class of underlying distribution functions,
, the conditional excess distribution function,
, for a large
is accurately approximated by
as
:
where
is the GPD given by
Singvejsakul et al. (
2021).
where
,
for
and
when
. Parameter
is a scale parameter, and
is a shape parameter. If
, then
is a reparametrized version of the classical GPD. If
, then
is an exponential distribution, and if
, then
is known as a Pareto type-II distribution. GPD parameter estimation uses the MLE method to obtain the scale parameter (
) and shape parameters
(
Chebbi and Hedhli 2022).
When letting
, an approximation of
, for
, can be obtained from Equation (1), as follows:
The function
can be estimated nonparametrically by using the empirical distribution function as an estimate of the cumulative distribution function (
Omari et al. 2020):
where
is the total number of observations and
is the number of observations that exceed the threshold. By substituting Equation (3) and Equation (5) into Equation (4), an estimate for
can be obtained as follows:
The high quantile estimator, or the VaR, for
can be obtained from inverting Equation (6), as follows:
where
is the confidence level of VaR,
is the observations that exceed the threshold,
is the number of observations,
is the scale parameter, and
is the shape parameter.
The conditional expected loss under the assumption that it surpasses VaR is referred to as CVaR. Contrary to VaR, CVaR always returns a bigger magnitude for risk because it measures the average loss in the very tail of the distribution. VaR can be derived as follows (
Long et al. 2020):
The combination of EVT with other models yields better forecasting accuracy, as shown in research conducted by
Chaiboonsri and Wannapan (
2021), which aimed to methodically devise a quantum-wave distribution (QWD) to better analyze risks and returns for stock markets in ASEAN countries, especially in extreme value predictions of VaR and ES, as based on quantum mechanics (QM). The scope of the research process starts from observation and screening data; next, the raw data are modified by a Gaussian–random-walk distributional set and QWD. Afterward, two values are inserted into the function of the GPD extreme value analysis. By setting the prior density for parameters at the Bayesian estimation
, heavy loss tails are clarified and evaluated. Bayesian simulations and statistics are applied to the present estimation outputs. Bayesian inference for calculating risks and the ES predictions are both compatible with the distribution produced by the QM carried out in the wave equation. Quantum distributions are empirically notable for generating genuine distributions, and they may be able to close the information gap in data analyses.
Ghourabi et al. (
2021) conducted research that aimed to evaluate the estimation ability of the generalized autoregressive score model to calculate risk scores by applying EVT. The generalized autoregressive score section is responsible for capturing the dynamics of transient volatility. EVT provides a model of extreme tail behavior. This method produces much-more-accurate VaR predictions. In research performed by
Chen and Yu (
2020), the authors proposed an asymmetric power autoregressive conditional heteroscedasticity model with the generalized Pareto distribution, aiming to determine the optimal margin level. Estimations of VaR were measured by using Equation (11). The residual tail distribution of the APARCH model was estimated by using the generalized Pareto distribution, based on EVT, by using Equation (3). The result was that the proposed model offered better 1-day forecasts than the other models did. Research by
Ji et al. (
2020) introduced a general framework of a SEPP with a truncated the generalized Pareto distribution to measure extreme risk in the stock market below price limits. Similar to GARCH modeling, where the variance is a function of past shocks and where the variance in the sign distribution depends on previous events through intensity, the flexible, truncated, generalized Pareto distribution works to accommodate price constraints. The measurement results showed that the proposed process can accurately explain the empirical data. Research conducted by
Ji et al. (
2019) focused on investigating the extreme risk of returning financial assets by using the agent-based model. The spread of extreme risk is caused by two important mechanisms that contribute to fact style, namely panic aggregation and market fraction movements. Extreme risks above a certain threshold can be independent and identically distributed by the generalized Pareto distribution by using Equation (3). A Monte Carlo simulation was performed for the VaR estimation. The results showed that the proposed model had good performance in predicting VaR.
Tabasi et al. (
2019) conducted research to calculate market risk in Iran’s largest stock exchange, by estimating the CVaR. This research applied the GARCH model, in combination with the POT model, assuming
t-distributions or normal for the RV. The GARCH procedure described the random variable’s volatility, and then used the EVT, to model the residuals. After the estimation of the VaR and the ES, the validity of these estimations needed to be investigated by the back-testing models. The results of the study showed that utilizing the POT model had a positive impact on the models and on the estimation of risk in the financial market.
Predicting VaR by taking only the EVT approach identifies the limitations of this model in predicting dynamic VaR. The GARCH approach allows the model to dynamically capture the volatility characteristics of financial time series. Predicting the VaR of financial markets by accounting for the volatility in the extreme value approach is predominant in the literature. A good model uses several combinations with complementary goals, such as the research by
Karmakar and Paul (
2019), employing the CGARCH–EVT-Copula model to predict intraday VaR and ES or CVaR portfolios by using high-frequency data. EVT focuses directly on the tails and could therefore yield better estimates and forecasts of risk. EVT is not independently and identically distributed, and the GARCH model is used to fit the return series. The GARCH–EVT model is used to draw the marginal distributions, and the multivariate dependence structure between markets is modeled by a parametric family of extreme value copulas that are perfectly suitable for non-normal distributions and nonlinear dependence. The combined GARCH–EVT-Copula model becomes the natural choice for estimating the portfolio of VaR, as well as that of ES or CVaR.
A POT approach using Equation (3) managed to catch the extreme values and was successful during the research. VaR was estimated by using Equation (11). Back-testing evidence showed that the employed model showed relatively better performance than the other models. A study by
Banerjee and Paul (
2020) explored the MCS-GARCH model’s forecasting intraday VaR and ES for both developed and emerging markets.
This study proposes the MCS-GARCH model for superior volatility estimation because it expresses the intraday conditional variance in prices as a product of three components: the daily variance component, the intraday variance component, and the diurnal variance pattern. The results show that the combined conditional-EVT model performs much better than the standalone GARCH model.
In research conducted by
Miloš (
2020), procedures were developed to assess tail risk portfolios on the basis of using EVT, without the need to use multivariate constraining relationships. This study overcame the main drawback of EVT against multivariate cases by combining the simplicity of univariate EVT and orthogonal generalized autoregressive conditional heteroskedasticity while capturing tail correlations and extreme comovements. Research conducted by
Song et al. (
2021) proposed an intraday-return-based VaR dynamic conditional score with a GPD sensor based on high-frequency data, such as intraday returns, contributing to the estimation of the tail risk of daily returns. This model added several types of realized volatility to the peaks-over-threshold model to better estimate daily returns. This model performed better at estimating the risk of extreme tail returns, as evidenced by several back-testing methods.
Highlights of the results are as follows:
All the above studies used one input variable in the model, namely daily returns.
All the studies in the literature used the POT method, based on GPD.
Predicting VaR using only the EVT approach identified the limitations of this model in predicting dynamic VaR.
The above research illustrates that the EVT approach is better if it uses a hybrid method and works well in univariate cases or when using one input variable.
The EVT method shows difficulties in multivariate cases.
4.2. Gaps in the Existing Literature
The results of this study indicate an interesting area to study. Input variables are very important parts of a model. In general, the investment-risk-prediction model with the EVT approach uses only one input data variable, namely daily stock data. This model is rigid and static (
Ibn Musah et al. 2018). As in the research conducted by
Karmakar and Paul (
2019), if an explosion or crisis is encountered in the future, the possibility of a fat tail error is unlimited, which illustrates that the VaR model with the EVT approach is static and insensitive to extreme changes. This model works in the univariate case; there is no definite way to apply it in the multivariate case. This is in line with research conducted by
Miloš (
2020), and although EVT is a natural choice for modeling tail risk, its main drawback is the complexity of expanding multivariate cases (
Miloš 2020). This illustrates that this method will experience difficulties when dealing with multivariate cases.
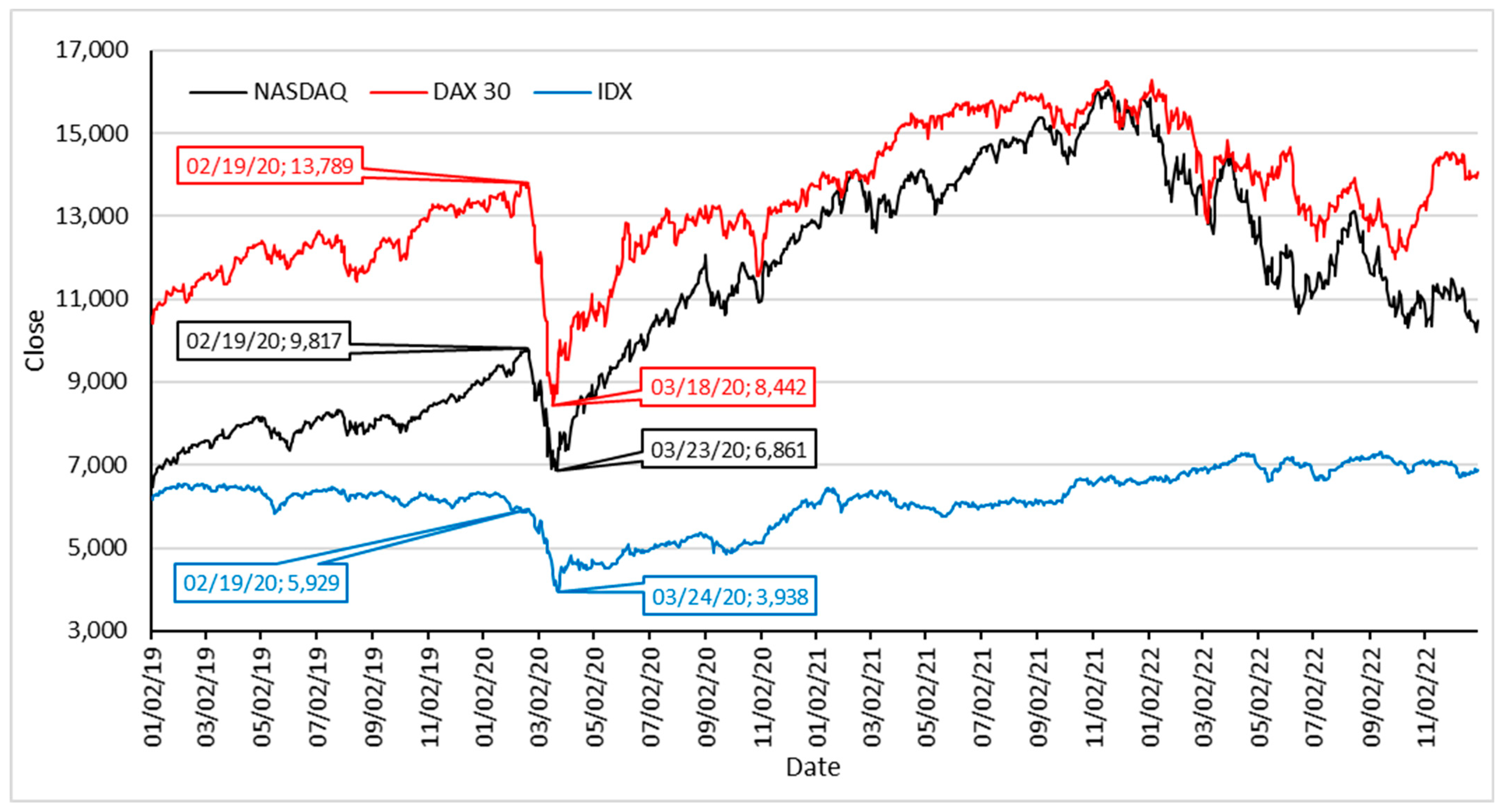
Stock return is the level of yield or profit from stock investment activities; thus, stock returns are closely related to fluctuations in stock prices. Stock price fluctuations are influenced by many factors (
Wu and Duan 2017), including the closing price of shares, currency exchange rates, global oil prices, inflation rates, internal stock factors, and external stock factors. In addition to these factors, stock price fluctuations are influenced by extreme events that cause the stock market to fluctuate, such as the pandemic. Information about the severity of COVID-19 rapidly spread throughout the world thanks to the sophistication of communication, information, and social media technologies. Many variables have arisen as a result of the pandemic, which have had a considerable effect on stock price fluctuations, such as panic, the number of infected cases, the number of deaths, the level of vaccine attainment, the level of government efforts in tackling the pandemic, trends in COVID-19, and the outcry on social media. These variables are called X-variable factors (X-FV), which are variables that occur as a result of extraordinary events and that have a major impact on the stock market. For example, the pandemic occurred in the period from 2019 to 2022. However, in the literature published during the pandemic period, no studies used this variable as input data in the model. Most investment-risk prediction models use only one data input, namely daily stock returns. The results generally conclude that the designed models fail to anticipate the effects of extraordinary events such as the pandemic. This is reflected in the disruption of the financial sector during the pandemic. For the model to be dynamic and sensitive to extreme fluctuations, multivariable input data, including X-FV, must be considered as model input data. The common theme that can be found is the importance of investment-risk-prediction models in a stock market that are dynamic and sensitive to extreme fluctuations, and they can be made as such by including X-VF in their input variables.
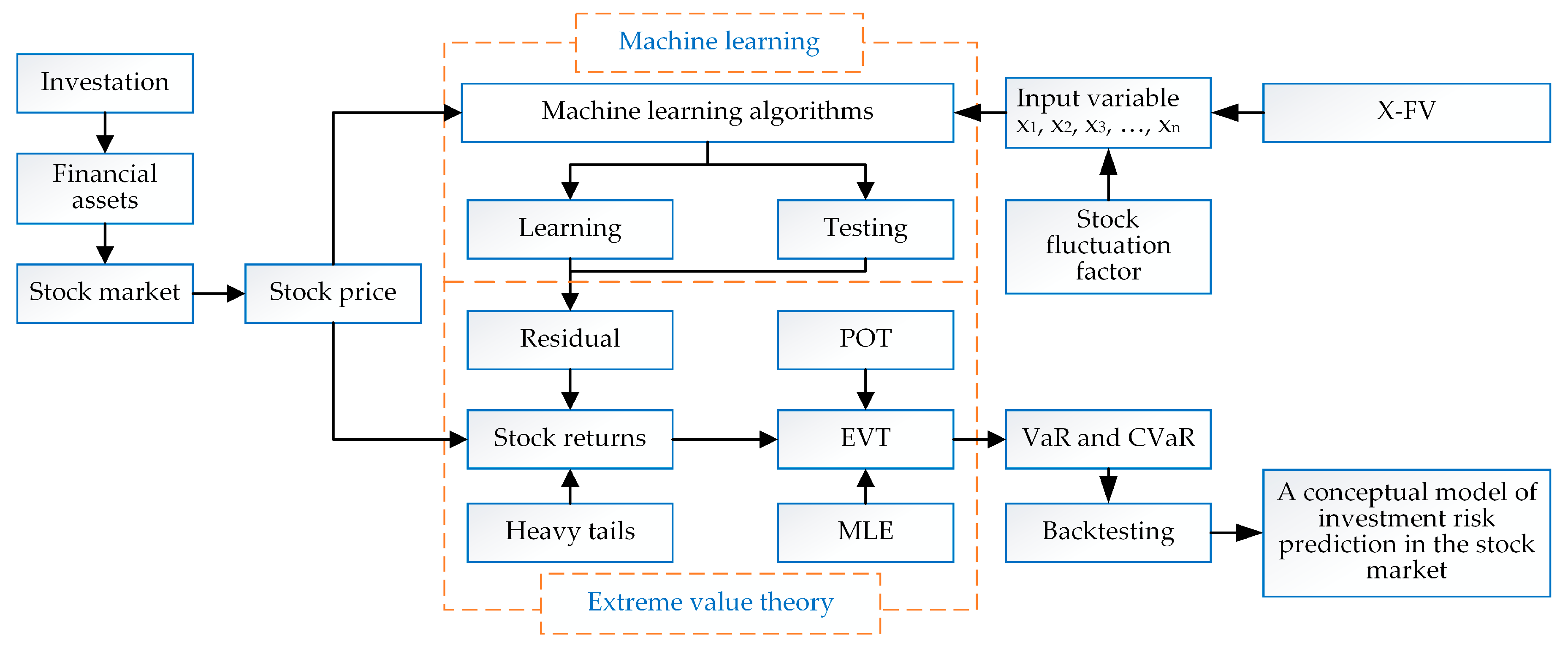
4.3. Conceptual Model
The research gap shows that models used in the literature have focused only on one variable and have ignored X-FV, which means that a model following the EVT approach will not consider variables that arise from extraordinary events that make the stock market fluctuate. It is thus necessary to develop a conceptual model of investment-risk prediction for a stock market that is dynamic and sensitive to extreme fluctuations. The model framework uses VaR–EVT methods with machine learning; therefore, this model is dynamic and capable of handling multivariate cases. The combination of EVT and machine learning makes the models complementary. This model is based on machine-learning algorithms that have the unique advantage of handling large numbers of data, such as financial market data (
Chen et al. 2020). Machine-learning algorithms show extraordinary abilities in approaching nonlinear systems and extracting meaningful features from high-dimensional data; because of these abilities, machine-learning algorithms can assist or replace traditional forecasting methods (
Buizza et al. 2022) when modern investors face high-dimensional prediction problems, with high data frequency and thousands of observed variables potentially relevant for forecasting (
Martin and Nagel 2022).
Machine-learning algorithms are grouped into three categories, namely supervised-learning algorithms, reinforcement-learning algorithms, and unsupervised-learning algorithms (
Fausett 1994). K-near neighbors, linear regression, ANNs, SVMs, decision trees, and random forests comprise supervised-learning algorithms. Examples of unsupervised-learning algorithms are the k-means algorithm, hierarchical cluster analysis, a priori, PCA kernel, and
t-distributed.
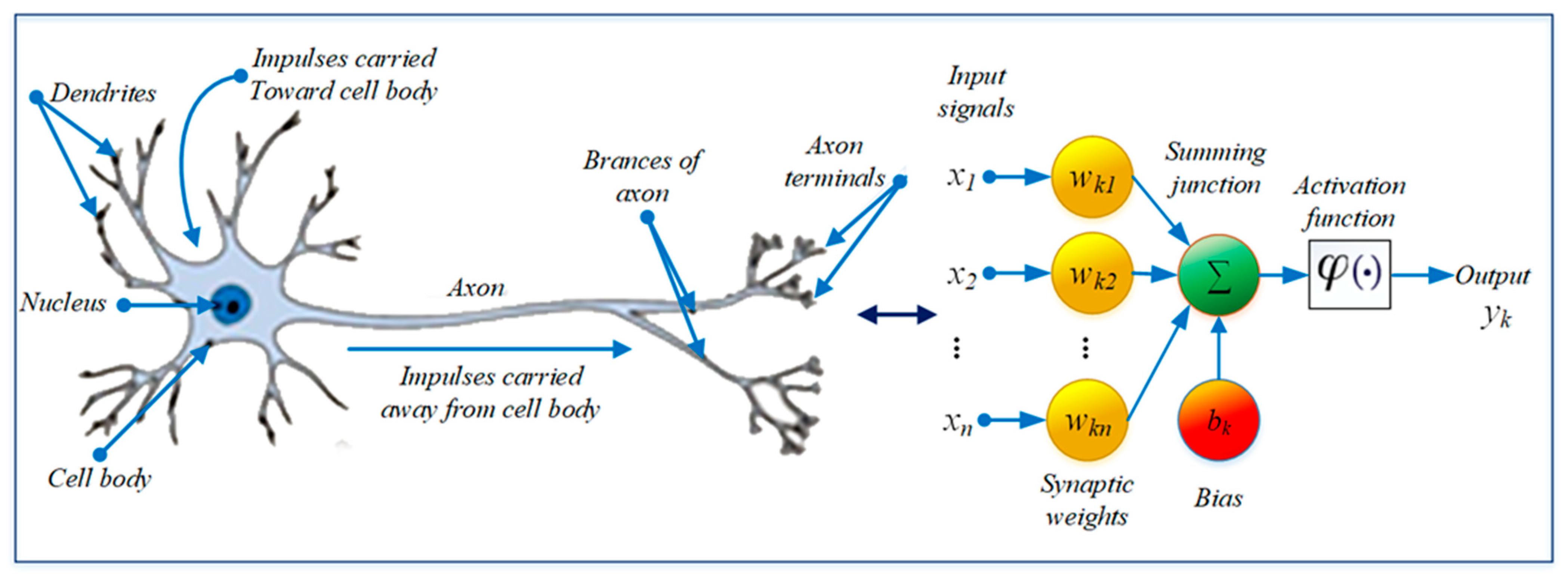
The conceptual model of an investment-risk-prediction EVT machine-learning-based approach was developed by using ANN-supervised-learning algorithms. An ANN was chosen because the ability of this algorithm is very good in forecasting (
Qiu and Song 2016). ANNs are the types of adaptive computational models that are inspired by the biological human or animal brain system.
Figure 9 shows the neural network concepts.
An ANN accommodates multivariable input data; thus, it is reliable in multivariate cases. Let
be the input variables and
be the weights on k neurons; next, the neurons will calculate all the inputs, as shown in Equation (13) (
Haykin 2009):
The
parameter is biased, in that it has the effect of increasing or decreasing the network input of the activation function φ(.). The result of Equation (13) is later changed to be nonlinear by the activation function, before it becomes a neuron output signal, as shown in Equation (14):
The values of the parameters
and
are obtained as a result of learning from the input variables. The value of the weight is often limited to prevent it from becoming too large; this is generally achieved through the decay parameter, which is usually set to a value of 0.1. Next, the weights take random values, which are updated using the observed data, thus indicating the presence of nonlinear elements in the forecasts generated by this machine learning. The output of this model is a prediction based on the results of learning and testing variables that affect stock fluctuations, including X-FV, where the lowest error rate is based on two measured metrics: mean-square error and RMSE (
Bakar et al. 2021).
Furthermore, the EVT method will identify extreme values of the machine-learning output by using Equation (3), to obtain the parameters
and
. These parameters will later be used to obtain a 1-day-ahead estimate of investment risk by using Equation (11). Back testing was performed to validate the model (
Berger and Moys 2021).
Figure 10 shows the framework for the conceptual model of the stock market.
This model will continuously predict short-term investment risk. The purpose of this short-term prediction is that the output of the model will follow the dynamics of the variables that affect the stock market ecosystem. Variable changes that occur every day will be the input data for the next prediction; thus, this model is dynamic and sensitive to extreme fluctuations.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}