
Non-Fatal Drowning Risk Prediction Based on Stacking Ensemble Algorithm
Abstract
:1. Introduction
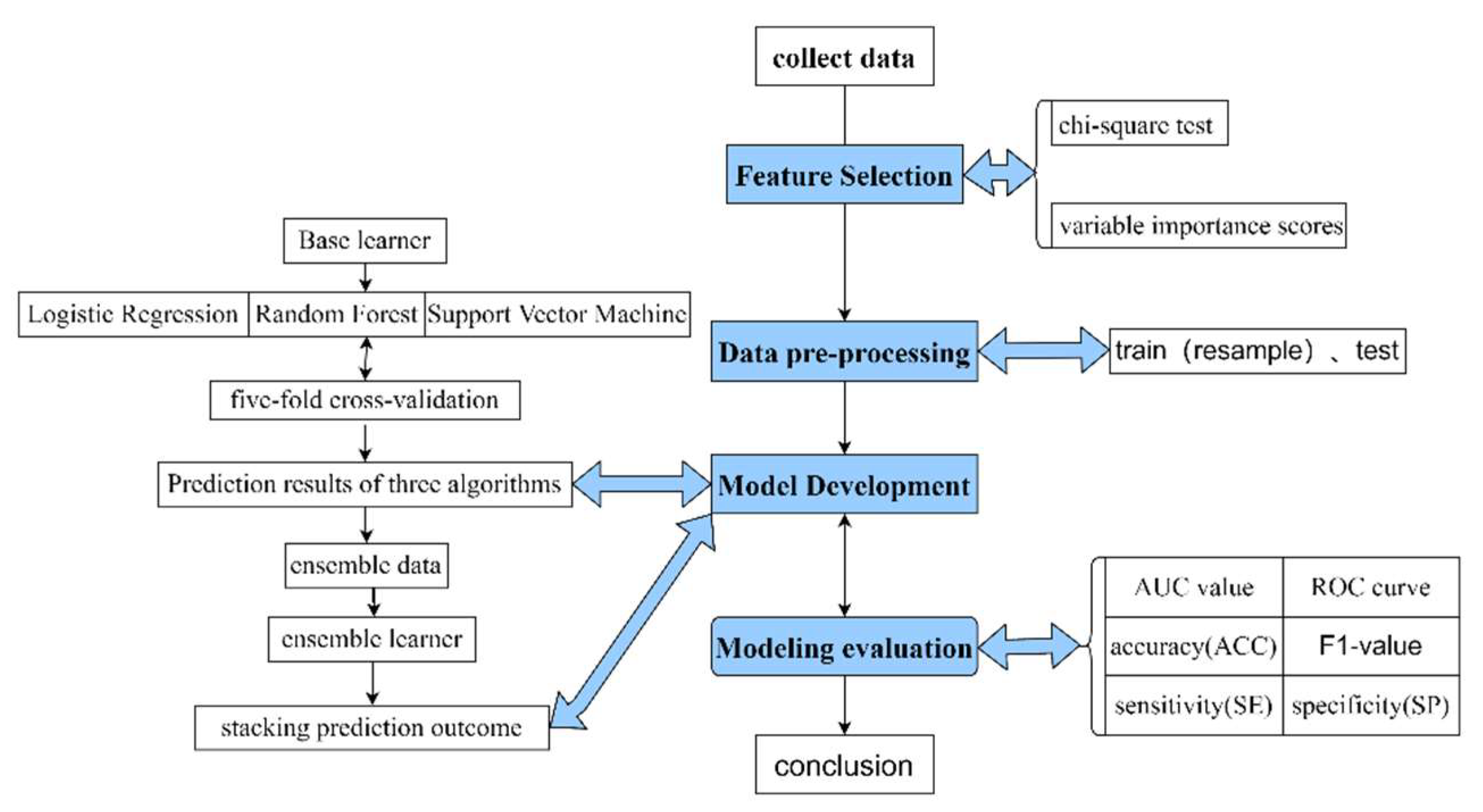
2. Methods
2.1. Study Site
2.2. Data Collection
2.3. Statistical Analysis
Data Pre-Processing and Variables Selection
2.4. Model Development
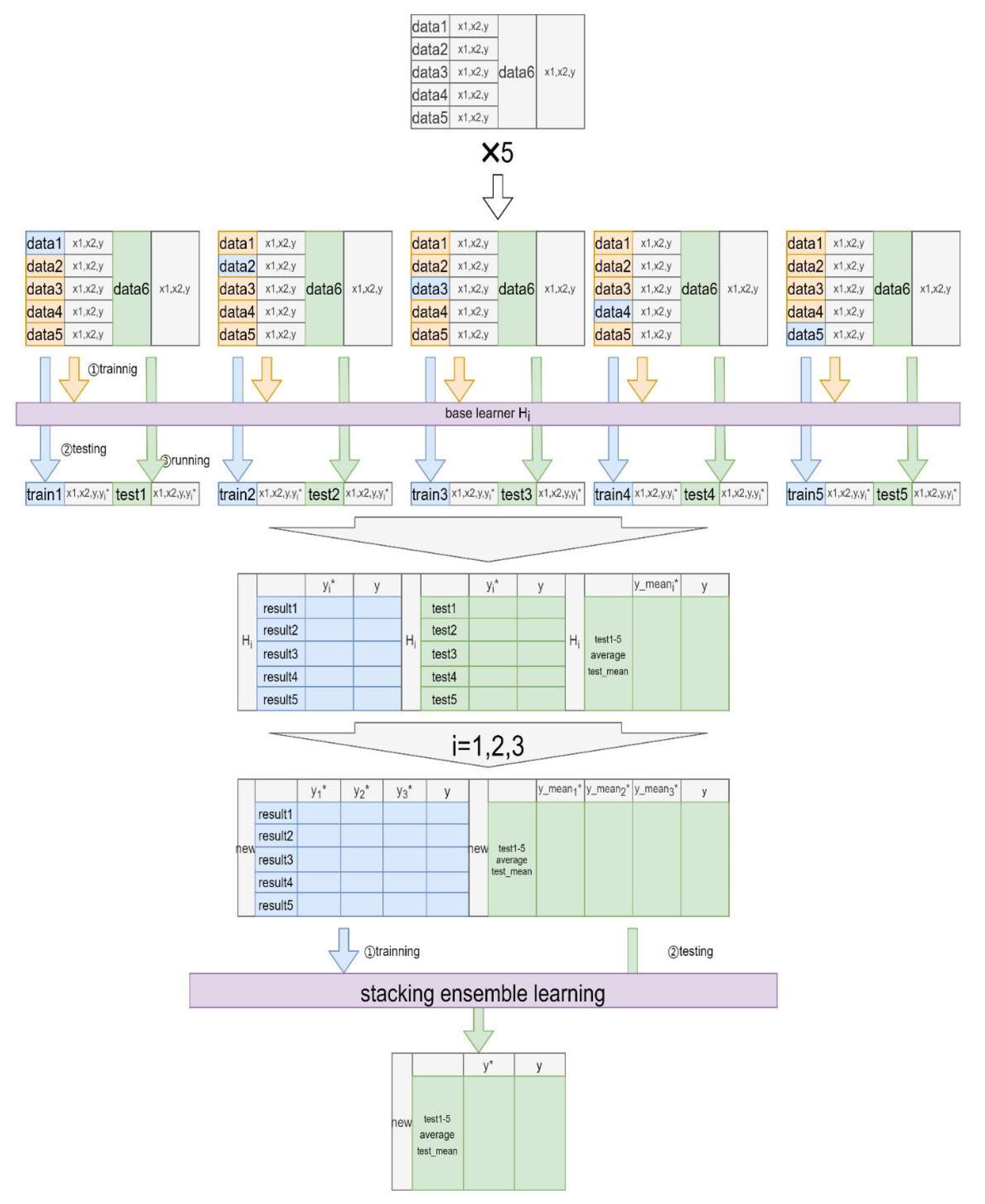
2.4.1. Develop Base Learners
2.4.2. Develop a Stacking Ensemble Model
2.5. Modeling Evaluation
- SE = TP/(TP + FN)
- SP = TN/(FP + TN)
- ACC = (TP + TN)/(TP + FN + FP + TN)
- F-value = 2 × TP/(2TP + FP + FN)
3. Results
3.1. Univariate Variables Selection
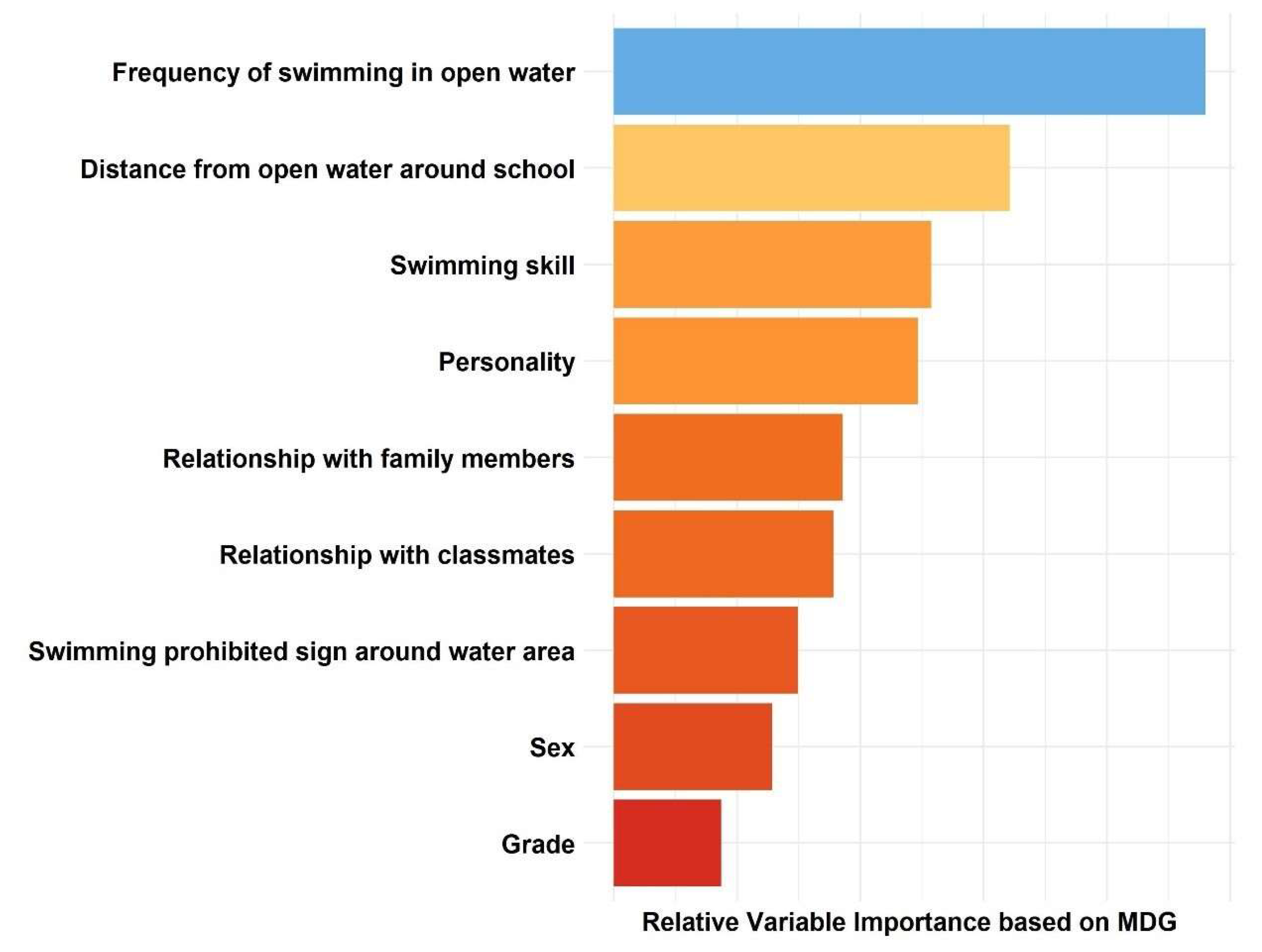
3.2. Feature Important
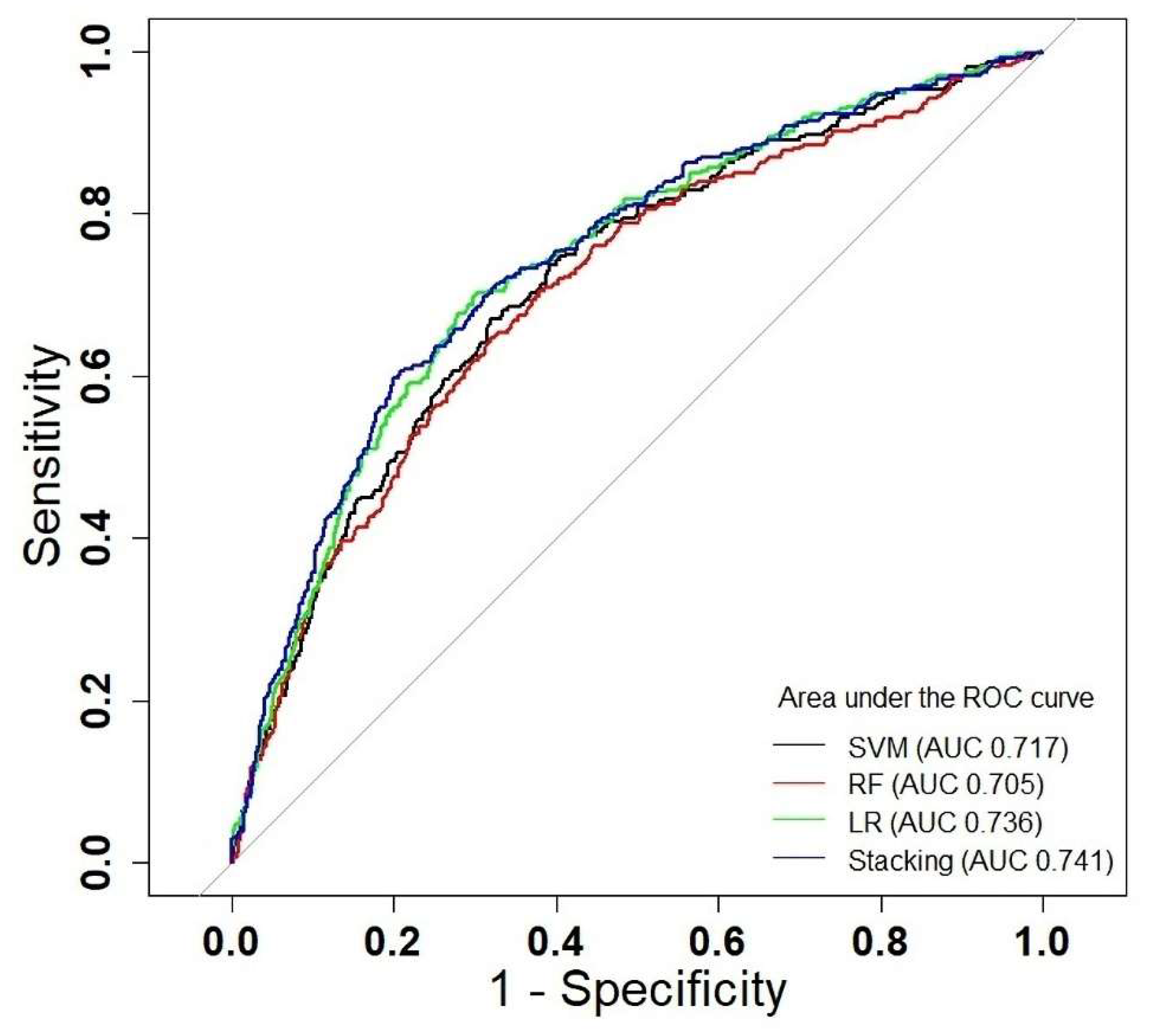
3.3. Evaluation of Various Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Drowning. Available online: http:www.who.int/news-room/fact-sheets/detail/drowning (accessed on 18 December 2021).
- Injuries and Violence: The Facts. Geneva World Health Organization. Available online: http:apps.who.int/iris/handle/10665/149798 (accessed on 18 April 2021).
- World Health Organization (WHO). Global Report on Drowning: Preventing a Leading Killer; WHO Press: Geneva, Switzerland, 2014. [Google Scholar]
- World Health Organization (WHO). Regional Status Report on Drowning in the Western Pacific. Available online: http:apps.who.int/iris/handle/10665/343073 (accessed on 18 December 2021).
- Chinese Center for Disease Control and Prevention. China Cause of Death Monitoring Dataset 2020; Beijing Shengtong Printing Co., Ltd. Press: Beijing, China, 2021. [Google Scholar]
- Franklin, R.C.; Peden, A.E.; Hamilton, E.B.; Bisignano, C.; Castle, C.D.; Dingels, Z.V.; Hay, S.I.; Liu, Z.; Mokdad, A.H.; Roberts, N.L.S.; et al. The burden of unintentional drowning: Global, regional and national estimates of mortality from the Global Burden of Disease 2017 Study. Inj. Prev. 2020, 26, i83–i95. [Google Scholar] [CrossRef] [PubMed]
- Borse, N.N.; Hyder, A.A.; Bishai, D.; Baker, T.; Arifeen, S.E. Potential Risk Estimation Drowning Index for Children (PREDIC): A pilot study from Matlab, Bangladesh. Accid. Anal. Prev. 2011, 43, 1901–1906. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Liu, Y.; Kang, L.; He, C.; Miao, L.; Huang, J.; He, X.; Zhu, J.; Liang, J.; Li, Q.; et al. Social and environmental risk factors for the accidental drowning of children under five in China. BMC Public Health 2020, 20, 1553. [Google Scholar] [CrossRef]
- Liu, Z.; Kong, F.; Yin, L.; Wang, A.; Xiong, L.; Xie, D.; Chen, L.; Sheng, X. Epidemiological characteristics and influencing factors of fatal drowning in children under 5 years old in Hunan Province, China: Case-control study. BMC Public Health 2019, 19, 955. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Yu, C.; Xiang, H.; Li, G.; Hu, S.; Tang, J. Age-Period-Cohort Analysis of Trends in Mortality from Drowning in China: Data from the Global Burden of Disease Study 2015. Sci. Rep. 2018, 8, 5829. [Google Scholar] [CrossRef]
- Yang, L.; Nong, Q.Q.; Li, C.L.; Feng, Q.M.; Lo, S.K. Risk factors for childhood drowning in rural regions of a developing country: A case-control study. Inj. Prev. J. Int. Soc. Child Adolesc. Inj. Prev. 2007, 13, 178–182. [Google Scholar] [CrossRef]
- Nguyen, H.; Ivers, R.Q.; Pham, C.; Jagnoor, J. Trends of drowning mortality in Vietnam: Evidence from the national injury mortality surveillance system. Inj. Prev. 2020, 26, 42–48. [Google Scholar] [CrossRef]
- Rahman, A.; Mashreky, S.R.; Chowdhury, S.M.; Giashuddin, M.S.; Uhaa, I.J.; Shafinaz, S.; Hossain, M.; Linnan, M.; Rahman, F. Analysis of the childhood fatal drowning situation in Bangladesh: Exploring prevention measures for low-income countries. Inj. Prev. 2009, 15, 75–79. [Google Scholar] [CrossRef]
- Raess, L.; Darms, A.; Meyer-Heim, A. Drowning in Children: Retrospective Analysis of Incident Characteristics, Predicting Parameters, and Long-Term Outcome. Children 2020, 7, 70. [Google Scholar] [CrossRef]
- Xu, H.; Zhu, X.; Zhou, Z.; Xu, Y.; Meng, R. An exploratory model for the non-fatal drowning risks in children in Guangdong, China. BMC Public Health 2019, 19, 599. [Google Scholar] [CrossRef] [Green Version]
- Hansen, K.B.; Borch, C. The absorption and multiplication of uncertainty in machine-learning-driven finance. Br. J. Sociol. 2021, 72, 1015–1029. [Google Scholar] [CrossRef] [PubMed]
- Kibbey, T.C.G.; Jabrzemski, R.; O’Carroll, D.M. Supervised machine learning for source allocation of per- and polyfluoroalkyl substances (PFAS) in environmental samples. Chemosphere 2020, 252, 126593. [Google Scholar] [CrossRef] [PubMed]
- Haro Alonso, D.; Wernick, M.N.; Yang, Y.; Germano, G.; Berman, D.S.; Slomka, P. Prediction of cardiac death after adenosine myocardial perfusion SPECT based on machine learning. J. Nucl. Cardiol. 2019, 26, 1746–1754. [Google Scholar] [CrossRef]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine Learning-Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef]
- van Beeck, E.F.; Branche, C.M.; Szpilman, D.; Modell, J.H.; Bierens, J.J. A new definition of drowning: Towards documentation and prevention of a global public health problem. Bull. World Health Organ. 2005, 83, 853–856. [Google Scholar] [PubMed]
- Szpilman, D.; Bierens, J.J.; Handley, A.J.; Orlowski, J.P. Drowning. N. Engl. J. Med. 2012, 366, 2102–2110. [Google Scholar] [CrossRef] [PubMed]
- Searle, S.R. Linear Models for Unbalanced Data; Wiley Press: New York, NY, USA, 1987. [Google Scholar]
- Cateni, S.; Colla, V.; Vannucci, M. A method for resampling imbalanced datasets in binary classification tasks for real-world problems. Neurocomputing 2014, 135, 32–41. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Cambridge, UK, 2012. [Google Scholar]
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Collaborators, G.V. Five insights from the Global Burden of Disease Study 2019. Lancet 2020, 396, 1135–1159. [Google Scholar] [CrossRef]
- Ma, W.J.; Nie, S.P.; Xu, H.F.; Xu, Y.J.; Song, X.L.; Guo, Q.Z.; Zhang, Y.R. An analysis of risk factors of non-fatal drowning among children in rural areas of Guangdong Province, China: A case-control study. BMC Public Health 2010, 10, 156. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Ye, P.; Tang, B.; Wang, S.; Guo, J.; Wu, J. Unintentional Injury Mortality Among Children Under Five Years-China, 2006–2017. China CDC Wkly. 2020, 2, 156–159. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization (WHO). Preventing Drowning: An Implementation Guide; World Health Organization Press: Geneva, Switzerland, 2017. [Google Scholar]
- Celis, A. Home drowning among preschool age Mexican children. Inj. Prev. 1997, 3, 252–256. [Google Scholar] [CrossRef]
- Steyerberg, E.W.; Vickers, A.J.; Cook, N.R.; Gerds, T.; Gonen, M.; Obuchowski, N.; Pencina, M.J.; Kattan, M.W. Assessing the performance of prediction models: A framework for traditional and novel measures. Epidemiology 2010, 21, 128–138. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, R.R.; Olubeko, O.; Sonthalia, H.; Kateera, F.; Nkurunziza, T.; Ashby, J.L.; Riviello, R.; Hedt-Gauthier, B. Application of Machine Learning to Prediction of Surgical Site Infection. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; Volume 2019, pp. 2234–2237. [Google Scholar] [CrossRef]
- Xiong, Y.; Ye, M.; Wu, C. Cancer Classification with a Cost-Sensitive Naive Bayes Stacking Ensemble. Comput. Math. Methods Med. 2021, 2021, 5556992. [Google Scholar] [CrossRef] [PubMed]
- Kwon, H.; Park, J.; Lee, Y. Stacking Ensemble Technique for Classifying Breast Cancer. Healthc. Inf. Res. 2019, 25, 283–288. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Fatal Drowning | χ2 | p | ||
|---|---|---|---|---|
| No (%) | Yes (%) | |||
| overall | 7307 (87.8) | 1013 (12.2) | ||
| Grade | 82.987 | <0.01 | ||
| grade 3–6 | 4457 (61.0) | 768 (75.81) | ||
| grade 7–8 | 2850 (39.0) | 245 (24.19) | ||
| Gender | 61.23 | <0.01 | ||
| Males | 3720 (50.91) | 649 (64.07) | ||
| Females | 3587 (49.09) | 346 (35.93) | ||
| Personality | 32.37 | <0.01 | ||
| Introvert | 1094 (14.97) | 193 (19.05) | ||
| Extrovert | 3836 (50.50) | 538 (53.11) | ||
| Mild | 1301 (17.80) | 116 (11.45) | ||
| Do not know | 1076 (14.73) | 166 (16.39) | ||
| Relationships with classmates | 58.092 | <0.01 | ||
| Very good | 3642 (49.84) | 467 (46.10) | ||
| Good | 3360 (45.98) | 449 (44.32) | ||
| Not good | 182 (2.49) | 53 (5.23) | ||
| Bad | 123 (1.68) | 44 (4.34) | ||
| Relationships with family members | 80.381 | <0.01 | ||
| Very good | 5158 (70.59) | 645 (63.67) | ||
| Good | 1908 (26.11) | 284 (28.04) | ||
| Not good | 187 (2.56) | 51 (5.03) | ||
| Bad | 54 (0.74) | 33 (3.26) | ||
| Number of siblings | 6.05 | 0.05 | ||
| One | 629 (8.61) | 106 (10.46) | ||
| Two | 3341 (45.72) | 478 (47.19) | ||
| Three or over | 3337 (45.67) | 429 (42.35) | ||
| Home ranking | 5.80 | 0.06 | ||
| First | 2835 (38.80) | 358 (35.34) | ||
| Second | 2422 (33.15) | 370 (36.53) | ||
| Third or over | 2050 (28.05) | 285 (28.13) | ||
| Is open water near home or school well protected? | 1.74 | 0.42 | ||
| Yes | 6091 (83.36) | 859 (84.80) | ||
| No | 806 (11.03) | 98 (9.67) | ||
| No open water | 410 (5.61) | 56 (5.53) | ||
| Would you like to swim in open water with a warning sign? | 260.23 | <0.01 | ||
| Yes | 229 (3.13) | 80 (7.90) | ||
| Probably | 420 (5.75) | 155 (15.30) | ||
| Probably not | 730 (9.99) | 170 (16.78) | ||
| Not | 5928 (81.13) | 608 (60.02) | ||
| Distance between the school and the surrounding open waters (Meters) | 13.75 | 0.008 | ||
| <100 | 1553 (21.25) | 259 (25.57) | ||
| 100–500 | 997 (13.65) | 137 (13.52) | ||
| 500 + | 1196 (16.37) | 170 (16.78) | ||
| Have no water area | 1202 (16.45) | 167 (16.49) | ||
| Do not know | 2359 (32.28) | 280 (27.64) | ||
| Distance from home to open water (Meters) | 3.97 | 0.41 | ||
| <100 | 1846 (25.26) | 241 (23.79) | ||
| 100–500 | 1356 (18.56) | 204 (20.14) | ||
| 500 + | 1158 (15.85) | 173 (17.08) | ||
| Have no water area | 1622 (22.20) | 208 (20.53) | ||
| Do not know | 1325 (18.13) | 187 (18.46) | ||
| Swimming skill (Meters) | 84.47 | <0.01 | ||
| ≥100 | 786 (10.67) | 189 (18.66) | ||
| 50–100 | 2101 (28.75) | 308 (30.40) | ||
| Over 500 | 1262 (17.27) | 203 (20.04) | ||
| Unable to swim | 3158 (43.22) | 313 (30.90) | ||
| Frequency of swimming in open water | 752 | <0.01 | ||
| ≥three times per month | 350 (4.79) | 175 (17.28) | ||
| Once or twice a month | 337 (4.61) | 150 (14.81) | ||
| Once or twice a season | 235 (3.22) | 104 (10.27) | ||
| Once or twice a year | 284 (3.88) | 117 (11.54) | ||
| Zero | 6101 (83.50) | 467 (46.10) | ||
| Outcome and Model | AUC | Sensitivity | F1 Value | Accuracy | Specificity |
|---|---|---|---|---|---|
| Logistic Regression | 0.736 | 0.605 | 0.352 | 0.740 | 0.758 |
| Random Forest | 0.705 | 0.667 | 0.311 | 0.655 | 0.654 |
| Support Vector Machine | 0.717 | 0.581 | 0.331 | 0.726 | 0.745 |
| Ensemble Learning | 0.741 | 0.625 | 0.359 | 0.739 | 0.754 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Li, Z.; Xu, H.; Peng, D.; Yin, L.; Meng, R.; Wu, W.; Ma, W.; Chen, Q. Non-Fatal Drowning Risk Prediction Based on Stacking Ensemble Algorithm. Children 2022, 9, 1383. https://doi.org/10.3390/children9091383
Xie X, Li Z, Xu H, Peng D, Yin L, Meng R, Wu W, Ma W, Chen Q. Non-Fatal Drowning Risk Prediction Based on Stacking Ensemble Algorithm. Children. 2022; 9(9):1383. https://doi.org/10.3390/children9091383
Chicago/Turabian StyleXie, Xinshan, Zhixing Li, Haofeng Xu, Dandan Peng, Lihua Yin, Ruilin Meng, Wei Wu, Wenjun Ma, and Qingsong Chen. 2022. "Non-Fatal Drowning Risk Prediction Based on Stacking Ensemble Algorithm" Children 9, no. 9: 1383. https://doi.org/10.3390/children9091383