1. Introduction
External beam radiotherapy (EBRT) cancer treatment kills tumor cells by irradiating them [
1]. The delivery of the radiation dose is fractioned so as to spare healthy cells that might be found on the beam’s trajectory. Thus, the tumor is slowly destroyed while allowing surrounding healthy tissues to recover from damage over time. The treatment schedule aims to optimize two criteria [
2]:
the tumor control probability (TCP) is the probability that the tumor is destroyed after the treatment and it should be maximized.
the normal tissue complication probability (NTCP) is the probability that tissues and organs close to the tumor will suffer from side effects because of the treatment and it should be minimized.
To optimize these two criteria, a dosimetry step is performed prior to starting EBRT. Dose cartography is firstly optimized by the medical physician. Then, a treatment planning system splits the total dose into several fractions (with variable angles, energies, etc.). Even if daily fractions of equal dosage have been proven to produce good clinical results, recent studies claim that there could be an advantage in varying the fraction size during the treatment [
3].
Deep reinforcement learning (DRL) has been able to solve a large variety of complex sequential decision-making tasks, even from high-dimensional inputs [
4]. It has achieved super-human performance in many domains, such as in the game of Go [
5]. In this paper, we apply these techniques to automate the fractionation task for EBRT that lead to improvements in current practice, even when using less conventional fraction schedules. Several reward functions are studied through the objectives of (i) maximizing the number of tumor cells killed and (ii) minimizing the number of healthy cells killed. Different reinforcement learning algorithms are also developed in order to study the potential of the approach.
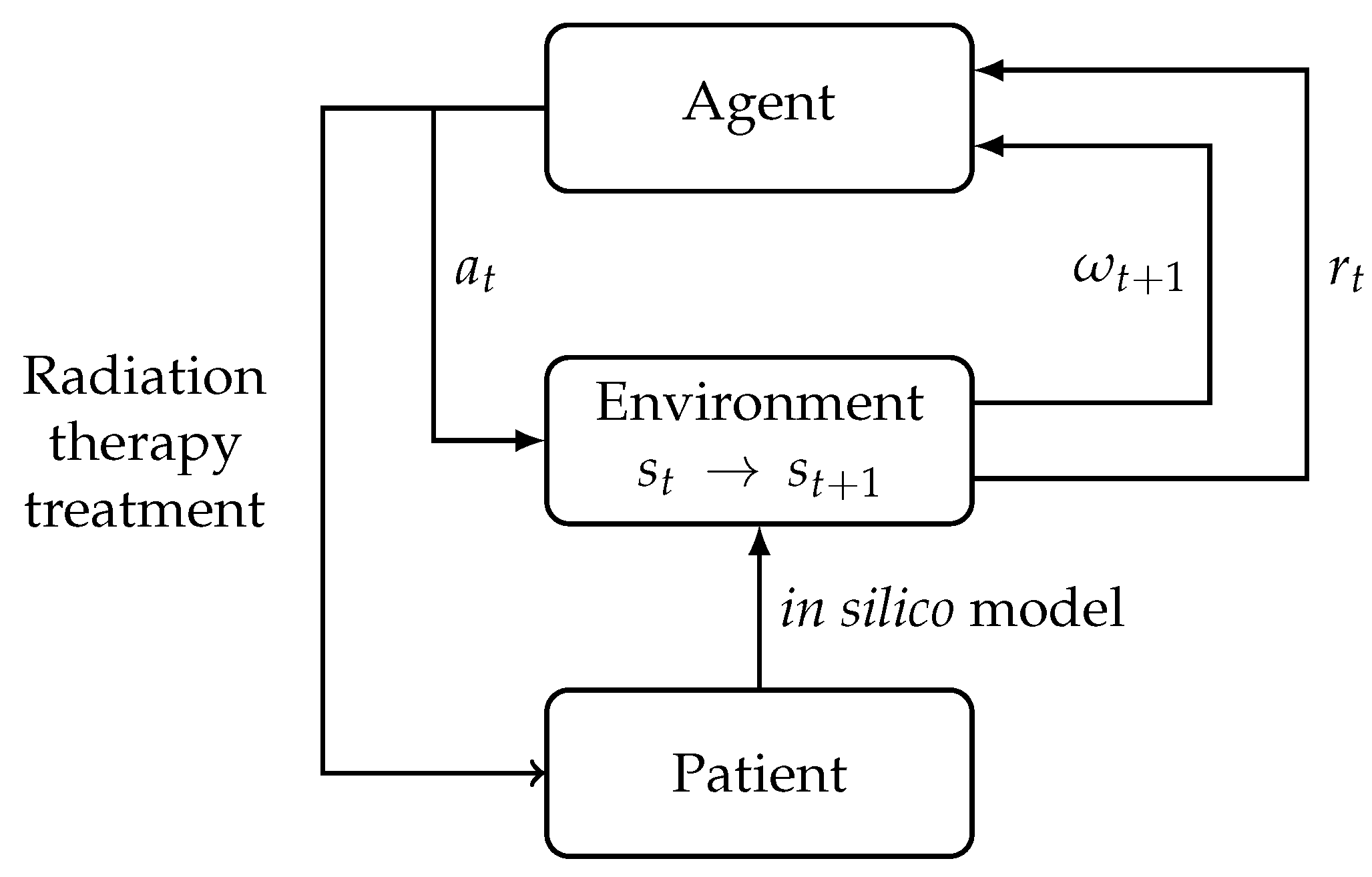
To be optimized, a DRL algorithm needs a large amount of data, and, therefore, a model for tumor development in a healthy environment is used as a proxy. (see
Figure 1). If the model is sufficiently accurate, the results can be used to modify fractionation schedules in clinical practice. Ultimately, we believe that this approach could be used in adaptive EBRT treatments for individual patients.
3. Materials and Methods
3.1. Tumor Growth Simulation
To simulate tumor development inside healthy tissue and the effect of radiation therapy, a lattice-gas cellular automaton was implemented. This simulation is based on a 2D 50-by-50 grid where each pixel of the grid contains:
The same cell cycle as in [
10] is used: eleven hours for G1, eight hours for S, four hours for G2, and one hour for M. Healthy cells also have the ability to enter the G0 phase if the quantity of a nutrient in the pixel is too low (
for glucose or
for oxygen) or the density of the patch formed by the pixel and its neighbors is greater than 1. The simulation is initialized with one tumor cell in the center of the grid and
nh_cells randomly placed healthy cells.
The cells need two nutrients to develop: glucose and dioxygen, reactants of the aerobic respiration producing ATP that fuels the cells. Initially, a quantity qg_ini glucose and qo_ini dioxygen are placed for each pixel. Nutrients spread uniformly to the neighborhood at a rate of 20% per hour. Each cell’s nutrient consumption is determined at the creation for healthy cells and varied every hour for cancer cells. These consumption rates are normally distributed based on averages (g_healthy, o_healthy, g_tumor, o_tumor) and standard deviation defined as a third of the average consumption. To generate nutrients during the simulation, nsources sources are randomly placed on pixels of the grid at the start of the simulation. Every hour, each of these sources will add qg mg of glucose and qo of dioxygen to the pixel on which they are placed. To simulate angiogenesis, the sources have a probability of moving to each adjacent pixel every simulated hour. They follow a random walk with a probability of moving towards the tumor’s center proportional to the number of cells forming this tumor, and a uniform probability of moving to any other adjacent pixel.
To represent the effect of radiation on cells during radiation therapy, the modified LQ model presented in Jalalimanesh et al. [
11] is used (see Equation (
2)). The dose is deposited using an accurate profile corresponding to the convolution product of a window function and a Gaussian. Thus, each cell is irradiated with a dose depending on its distance from the tumor’s center of mass, with cells one tumor radius away from this center receiving 95% of the total dose. The tumor’s current center of mass and radius are automatically computed after each irradiation.
In order to study first a simple environment for the RL algorithm, we built a toy environment where we collapsed the different elements of the grid to 0 dimensions. The same amounts of glucose and dioxygen distributed to the full grid initially and every hour in the 2D model are given to one pixel representing the whole environment. Initially, this pixel contains one tumor cell and healthy cells nh_cells. At each step, cells consume the nutrients to spread. During the treatment, the same dose of radiation will be applied to every cell in the simulation.
Table 1 presents the parameters used in our models.
3.2. Reinforcement Learning
Reinforcement learning (RL) is a branch of machine learning that aims to solve the problem of sequential decision-making. In this framework, an agent receives observations of the state of the environment in which it evolves and can choose actions to affect this environment. If we can assume that the problem is fully observable, then it can be formalized as a Markov Decision Problem (MDP), which is defined by the following elements:
States , where the state space is,
Actions , where the action space is,
Rewards , where is set to 1 by scaling the rewards,
A transition function that gives the probability of the next state s’ given the current state s and action a,
A discount factor .
At each time step, the agent observes the state of the environment and chooses an action. The effect of this action causes a transition of the environment to a new state and the agent receives a reward in the form of a scalar that indicates the quality of this transition. The agent’s goal is to maximize the sum of the rewards that it receives over time.
During its training, the agent will use trial and error to learn policies. The policy that an agent follows maps a state observed by the agent to the action that it should take (or to a distribution of actions).
The value of a state-action pair is the total amount of reward an agent can expect to accumulate over the future steps, starting from that state and taking this action according to the current policy. It can be defined mathematically with:
where
is the expected value corresponding to probabilities defined by the current policy
, the discount factor
determines how much the immediate reward should be favored over future rewards, and k is the number of timesteps away from the current state.
A common problem encountered during the training of RL agents is the exploration/exploitation dilemma. To maximize the sum of rewards that it receives, the agent should exploit the best solutions that it has already found, but should also keep exploring the state and action spaces in order potentially to discover better strategies. A common strategy to address this problem is the -greedy algorithm, in which at each time step, the agent has a given probability of taking a random action instead of the best estimated action.
3.2.1. Q-Learning
Value-based algorithms aim to solve the RL problem by learning an approximation of the optimal action-value function. This function has the form:
where
is the value of a state-action pair (
s,
a) under the current policy
and
is the value of this pair under an optimal policy. Therefore,
is the maximum discounted sum of rewards that could be expected under an optimal policy, assuming that the agent has just observed state
s and taken action
a. If the agent has access to this function, it can trivially reach optimal decision-making simply by choosing action
in each state s.
Tabular Q-learning uses a table containing an entry for each possible state-action pair to approximate
. This means that the algorithm requires the state-action space to be discrete and small to produce accurate estimations. At each time step, the agent observes the current state
s of the environment, chooses an action
a to take depending on its learning strategy, and receives a reward
r once the action has been applied. This process repeats at the next time steps when observing the new state
that was reached. It will then update recursively the entry in the table corresponding to the initial state and the action that was chosen with:
where
is the step-size parameter that can be decreased during the training once the estimations become more accurate.
In deep Q-learning, a neural network is used to approximate
. It receives observations of the environment’s state as inputs, and estimates the value of each possible action as an output. At each step in the training algorithm, the values given by the neural network
for state
s, action
a, and parameterized
are updated towards a target value given by the formula:
In DQNs [
16], two additions help with the stability of the training. First, a large buffer of past experiences is kept so that the agent can train on batches sampled randomly from this buffer instead of using only the most recent examples. This trick, called experience replay, ensures that training samples are more independent from each other. Second, the targets used to estimate the loss are computed using a second “target” network, to increase the stability of these targets. This network is obtained by cloning the main network once every
C training steps, where
C is usually at least of the order of
.
3.2.2. Deep Deterministic Policy Gradient
Policy-based algorithms aim instead to estimate the agent’s policy directly, and to improve it over time. The deep deterministic policy gradient (DDPG) algorithm trains two different networks [
17] simultaneously. The actor network approximates the function
, which defines the agent’s policy; it receives observations of the environment’s state as inputs, and outputs the action that the agent should take. The critic network approximates the function
, which is used to evaluate the actions chosen by the agent. It receives both an observation of the environment’s state, and the action that the agent chose in this state, and outputs an estimation of the expected return when taking this action in that state, while following
afterwards. Compared with DQN, DDPG has the possibility to work with a continuous action space.
The critic is trained to be increasingly accurate in its estimations of action-values. It uses a training target with the form:
The actor is trained with a policy gradient. This gradient uses the critic and has the form:
The policy will move towards actions that lead to higher values. As the actions are directly predicted by the actor, the action space is continuous and can be multi-dimensional. This algorithm is therefore more flexible than DQN.
Experience replay and target networks are also used to train the critic in DDPG to improve stability.
3.3. Integration with the Simulation
In order to use RL algorithms with the previously described models, the different elements of an MDP have to be defined in terms of these models.
Observations are used by the agent as the current state of the simulation. In the collapsed scalar model, this state is made out of a combination of the number of cancer cells and healthy cells after they have been discretized. The DRL algorithms used with the 2D model allow for richer observations. Here, they are 50-by-50 images, where each pixel’s value is either the number of cancer cells on this pixel on the grid, if there are any, or the number of healthy cells on this pixel.
Figure 2 shows such an observation.
The actions chosen by the agent define the EBRT treatment schedule applied to the simulation. For all algorithms, the agent will choose the dose with which to irradiate the tumor at each time step. This dose will be chosen in the interval [1–5] Gy. This domain is discrete for Q-learning algorithms, with steps of 1 Gy for tabular Q-learning and 0.5 Gy for DQN. It is continuous for DDPG. Furthermore, agents using the DDPG algorithm will also choose the time between the current fraction and the next fraction, in a domain of 12–72 h.
After the action chosen by the agent has been applied to the environment, it will receive a reward indicating the quality of this action. The agents have been trained to optimize two different reward functions: “killed” (K) and “killed and dose” (KD). On regular (non-terminal) time steps, agents will receive rewards of the form:
In the 2D model, the values of the constants x, y, and z are 5, 100,000, and 200, respectively.
On terminal steps, agents will receive rewards of -1 if the treatment was unsuccessful, or of the form:
In the 2D model, the values of the constants k and z are 3000 and 200, respectively. The first reward function “Killed” was designed to correspond to the objective of maximising damage to cancer cells while minimising the damage to healthy cells, while the second reward function, “Killed and dose”, adds a parameter, leading the agent to find treatments with smaller total doses, as long term effects related to this total dose are not modelled in the simulation. At positive terminal steps, rewards correspond to the state of healthy tissue after the tumor has been eliminated. Parameters x, y, z and k were chosen experimentally as they lead to better stability of the algorithms.
A simulated treatment is considered finished in three possible situations. First, the treatment will have succeeded if the tumor has been destroyed and no cancer cells are left in the model. Second, the treatment will have failed if the tumor has completely invaded healthy tissue, and there are fewer than 10 healthy cells in the model. Third, the treatment will have timed out if the two previous conditions are not reached after 1200 h of treatment.
3.4. Evaluation of Performances
For each combination of environment, algorithm, and reward function, 1000 test treatments are generated. The performances of each treatment are assessed using several indicators:
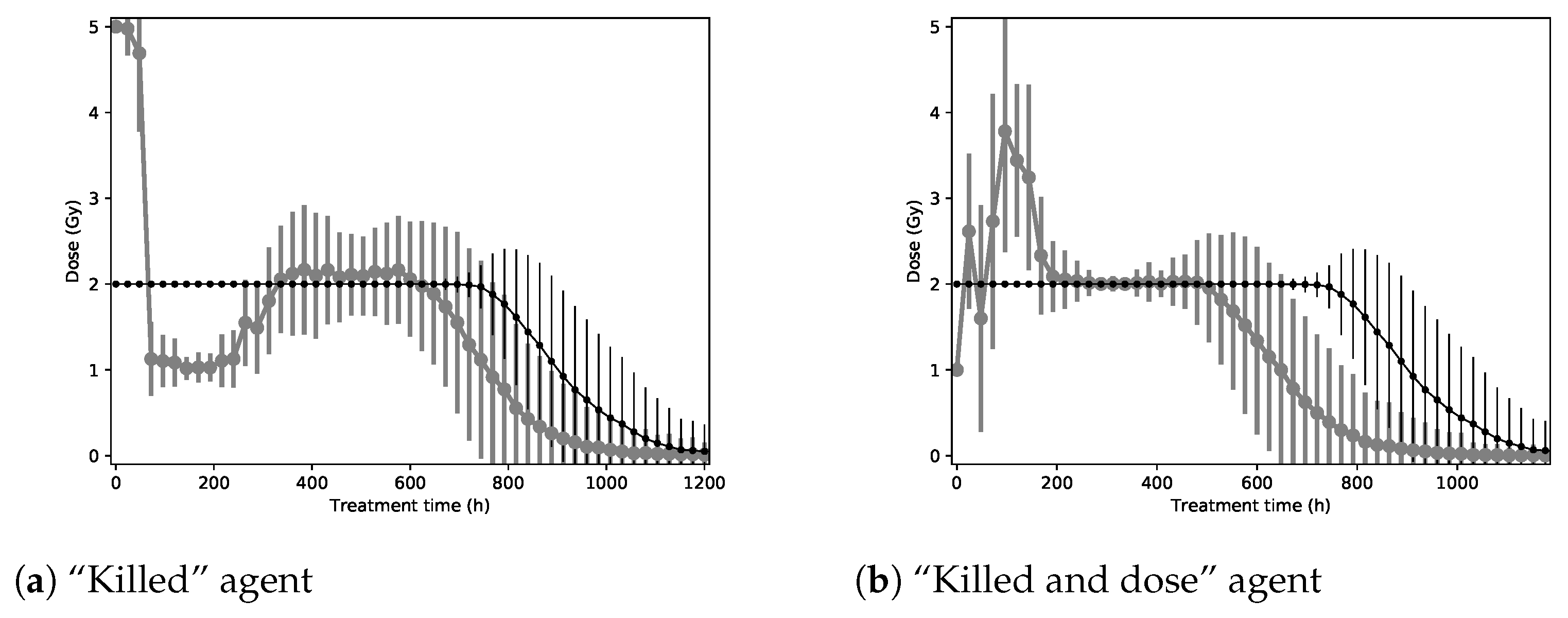
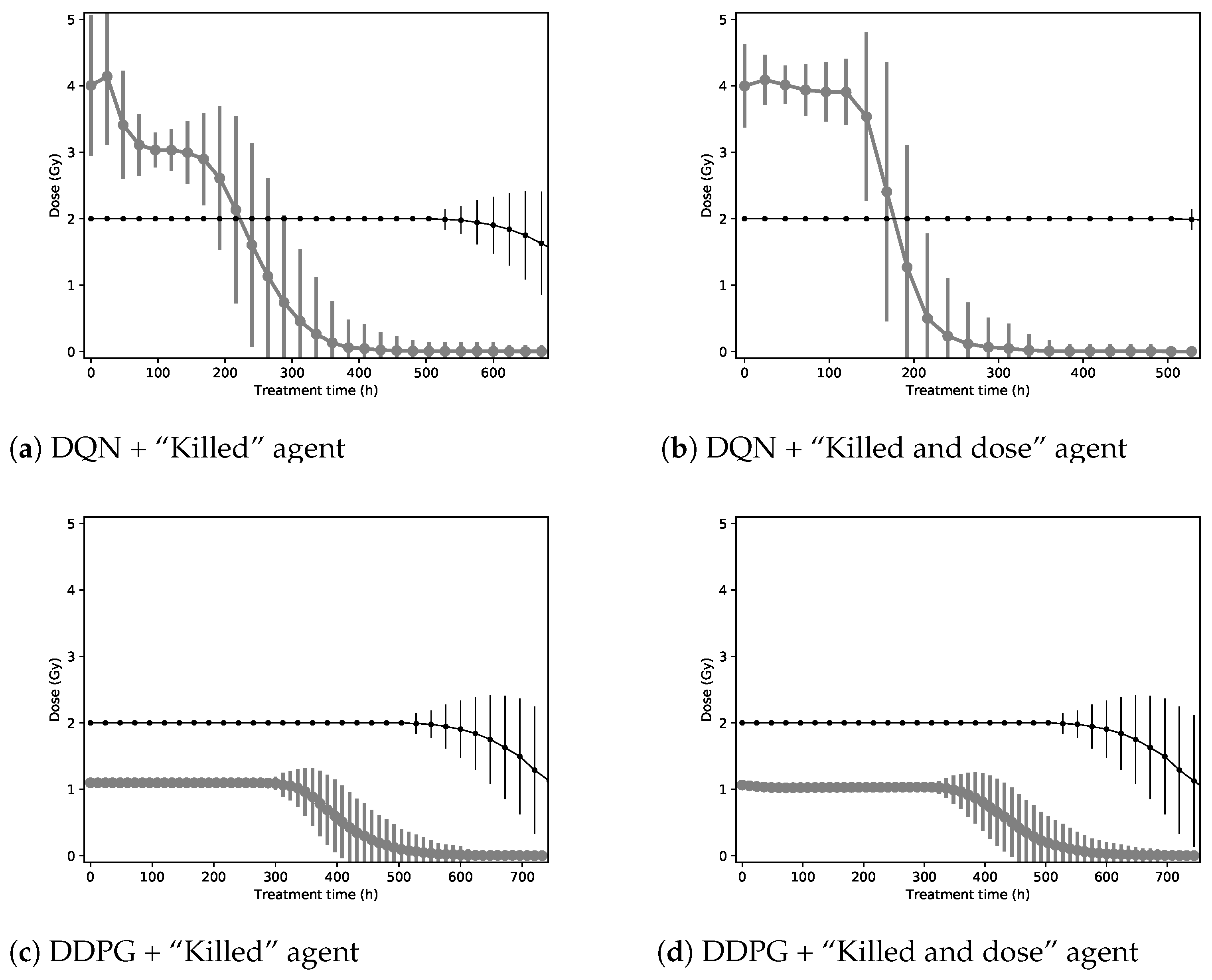
NTCP criteria are not included as a performance indicator because of the absence of organs at risk in the model, making the estimation of side effects impossible. To put these performance indicators into context, they will be compared with a baseline corresponding to a dose of 2 Gy every 24 h, as in a conventional RT treatment. The sample mean of each performance indicator is given along with its standard error when relevant. Furthermore, to illustrate the policies found by agents to optimize their reward functions, a graph will give the mean and standard deviations of the radiation dose prescribed at each step of the treatment.
5. Discussion
Our experiments have shown that using reinforcement learning is a promising option for the EBRT dose fractioning automation. As suggested by Jalalimanesh et al. [
11], a model simulation is a good alternative to model the tumor growth necessary for RL training. Because this kind of model is flexible, we chose to complexify it compared with the previous articles by studying the impact of both glucose and oxygen in the same model, and by modeling effects such as angiogenesis. Furthermore, we studied the performances of several RL algorithms (tabular Q-learning, DDPG and DQN). In particular, the different deep RL approaches allowed us to consider different action spaces, namely, (i) a fixed set of actions (DQN) and (ii) a continuous action space (DDPG).
It is necessary to specify that finding the optimal policy is difficult because of the model’s complexity, in particular, its high-dimensional state space, stochasticity, and nonlinear dynamics. The impact of several random parameters is also quite important (e.g., initial positions of healthy cells, nutrient consumption of cells, positions of daughter cells, probability of linear survival for large numbers, but not when only a few cancer cells remain, repair time in case of survival, and sources, positions and displacement). This point explains the significant standard deviation in our performance indicators. However, even despite this, our RL algorithms could converge.
Our deep RL agents are able to obtain better treatment schedules than a simple baseline with (i) improved TCP, (ii) shorter treatments, and (iii) lower overall radiations. The improvement is particularly important for the 2D environment. In our simulations, we have observed that starting with relatively high doses and decreasing the radiation doses through the treatment improves the cumulative rewards. We have also observed that hyper-fractionation might lead to better treatments. Further studies with an even more realistic in silico model or clinical trials would be of interest to validate these observations.
The two different reward functions produce slightly different results when measured with performance indicators. Indeed, the added dose factor in the “Killed and dose” reward function creates agents that suggest on average shorter treatments with a lower radiation dose and number of fractions than the “Killed” reward function. This effect is observed for the tabular Q-learning and DQN algorithms.
Agents trained with the DDPG algorithm reached the same treatment patterns while optimizing both reward functions. These treatments (sending close to 1 Gy every 12 h) always use actions very close to the minimum for each dimension of the action space. Different treatments might thus be found if the action space is extended below the current minimum.
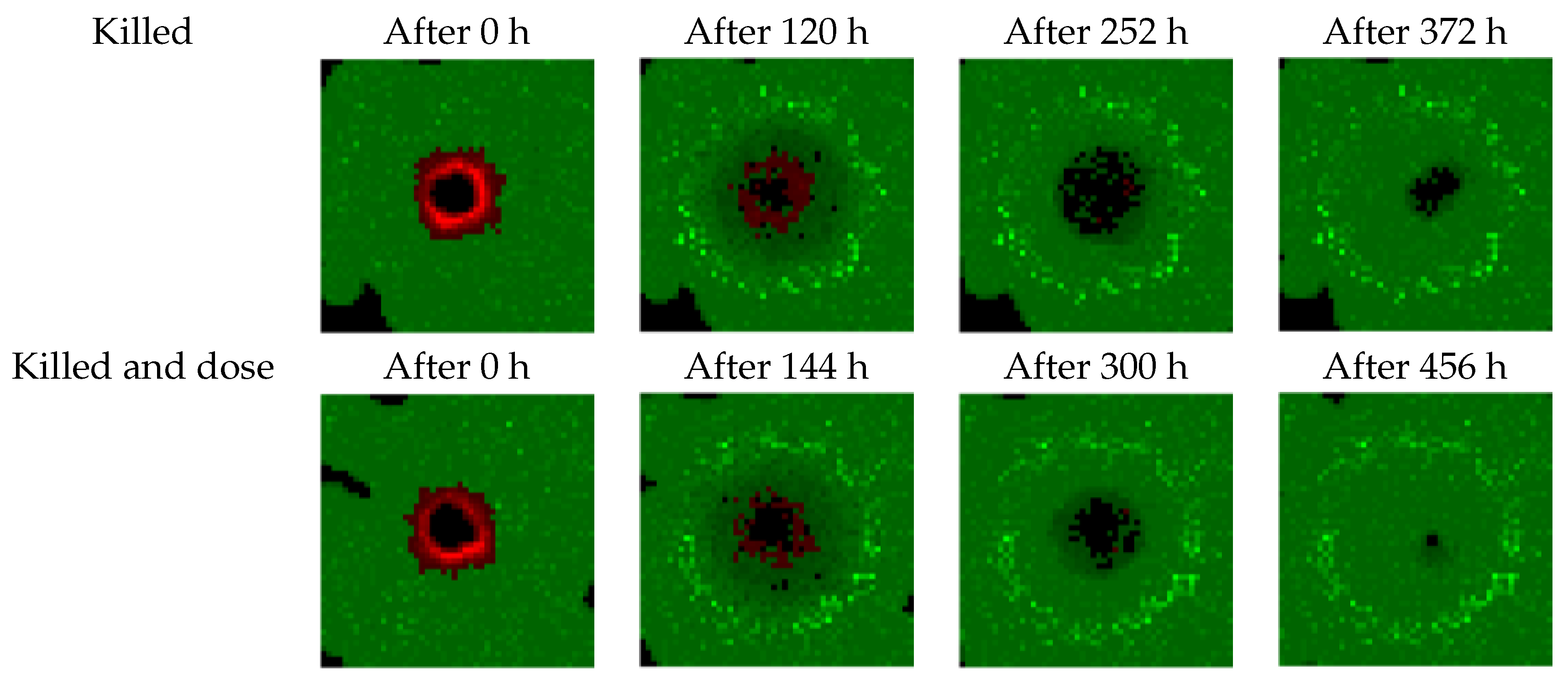
Our study has some limitations. The cellular model is not realistic enough and needs several improvements. For instance, as shown in
Figure 5 and
Figure 6, the model overestimates healthy tissue recovery. Another example is the lack of consideration of the acute tolerance (nausea, vomiting, dysphagia) according to the dose per fraction. The model neglects the chemosensitization and the revascularization as well. Moreover, the model instantly deletes cells that are considered to have been killed by radiation. We also used an “almost” perfect dose profile. The radiation beam is able to target tumor cells accurately while avoiding healthy cells.
Future work in several directions is needed to bring this research work closer to a useful software for the doctors: (i) The in silico model developed for this paper is rather generic and could benefit from an improved cell model that would take the specificities of the different organs and different tumor types into account. (ii) Medical doctors should help develop improved heuristics in terms of the rewards optimized through reinforcement learning, while data from clinical trials should ultimately allow for optimizing directly for the improvement in patient life expectancy. (iii) A transfer learning approach from CT scans to the in silico model should be developed in order to have personalized treatment planning in real time.
6. Conclusions
In this paper, we studied how the use of deep reinforcement learning can be used to simulate dose fractionation based on a tumor growth model. A dose planning algorithm applied to a mathematical model of healthy tissue and tumor growth took damage to both healthy tissue and the tumor into account in order to optimize the fractions. Two different deep RL algorithms were trained, each with two different preference functions. Compared with a baseline of current practice, the treatments found by the DRL agents outperformed in the selected study criteria.
The purpose of this work is to automate parts of treatment planning which are currently being designed by human experts. Thanks to radiomics features extracted from CT scans and a biological in silico model of radiation effects, an RL approach could pave the way to adaptive treatments that are able to take the specifics of each patient’s case (tumour shrinkage, deformations, etc.) into account.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}