
Automatic Segmentation of Retinal Fluid and Photoreceptor Layer from Optical Coherence Tomography Images of Diabetic Macular Edema Patients Using Deep Learning and Associations with Visual Acuity

 , , , ,
, , , ,
Abstract
:
1. Introduction
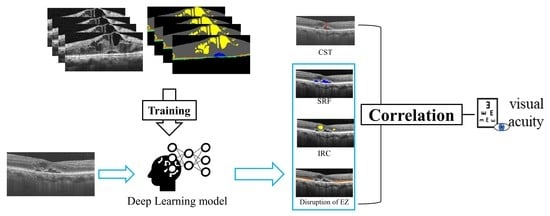
2. Materials and Methods
2.1. Ethical Approval and Data Collection
2.2. Labeling of Retinal Features
2.3. Network Architectures
2.4. Experimental Setup
2.5. Ablation Study
2.6. Quantification of Biomarkers
2.7. Statistical Evaluation
3. Results
3.1. Segmentation of Retinal OCT Images
3.2. Detection of Fluid and EZ Disruption
3.3. Associations with logMAR-BCVA
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moss, S.E.; Klein, R.; Klein, B.E. The 14-year incidence of visual loss in a diabetic population. Ophthalmology 1998, 105, 998–1003. [Google Scholar] [CrossRef]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, T.Y.; Sun, J.; Kawasaki, R.; Ruamviboonsuk, P.; Gupta, N.; Lansingh, V.C.; Maia, M.; Mathenge, W.; Moreker, S.; Muqit, M.M. Guidelines on diabetic eye care: The international council of ophthalmology recommendations for screening, follow-up, referral, and treatment based on resource settings. Ophthalmology 2018, 125, 1608–1622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alasil, T.; Keane, P.A.; Updike, J.F.; Dustin, L.; Ouyang, Y.; Walsh, A.C.; Sadda, S.R. Relationship between optical coherence tomography retinal parameters and visual acuity in diabetic macular edema. Ophthalmology 2010, 117, 2379–2386. [Google Scholar] [CrossRef] [PubMed]
- Otani, T.; Yamaguchi, Y.; Kishi, S. Correlation between visual acuity and foveal microstructural changes in diabetic macular edema. Retina 2010, 30, 774–780. [Google Scholar] [CrossRef] [PubMed]
- Kafieh, R.; Rabbani, H.; Kermani, S. A review of algorithms for segmentation of optical coherence tomography from retina. J. Med. Signals Sens. 2013, 3, 45. [Google Scholar]
- Hwang, D.-K.; Hsu, C.-C.; Chang, K.-J.; Chao, D.; Sun, C.-H.; Jheng, Y.-C.; Yarmishyn, A.A.; Wu, J.-C.; Tsai, C.-Y.; Wang, M.-L. Artificial intelligence-based decision-making for age-related macular degeneration. Theranostics 2019, 9, 232. [Google Scholar] [CrossRef]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131.e1129. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y.; Kim, H.K. Feasibility study to improve deep learning in OCT diagnosis of rare retinal diseases with few-shot classification. Med. Biol. Eng. Comput. 2021, 59, 401–415. [Google Scholar] [CrossRef]
- Arsalan, M.; Haider, A.; Lee, Y.W.; Park, K.R. Detecting retinal vasculature as a key biomarker for deep Learning-based intelligent screening and analysis of diabetic and hypertensive retinopathy. Expert Syst. Appl. 2022, 200, 117009. [Google Scholar] [CrossRef]
- Cheung, C.Y.; Xu, D.; Cheng, C.-Y.; Sabanayagam, C.; Tham, Y.-C.; Yu, M.; Rim, T.H.; Chai, C.Y.; Gopinath, B.; Mitchell, P. A deep-learning system for the assessment of cardiovascular disease risk via the measurement of retinal-vessel calibre. Nat. Biomed. Eng. 2021, 5, 498–508. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Liu, X.; Xu, J.; Yuan, J.; Cai, W.; Chen, T.; Wang, K.; Gao, Y.; Nie, S.; Xu, X. Deep-learning models for the detection and incidence prediction of chronic kidney disease and type 2 diabetes from retinal fundus images. Nat. Biomed. Eng. 2021, 5, 533–545. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In MICCAI 2015: Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science book series; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kugelman, J.; Alonso-Caneiro, D.; Read, S.A.; Vincent, S.J.; Collins, M.J. Automatic segmentation of OCT retinal boundaries using recurrent neural networks and graph search. Biomed. Opt. Express 2018, 9, 5759–5777. [Google Scholar] [CrossRef] [Green Version]
- Tennakoon, R.; Gostar, A.K.; Hoseinnezhad, R.; Bab-Hadiashar, A. Retinal fluid segmentation and classification in OCT images using adversarial loss based CNN. In Proceedings of the MICCAI Retinal OCT Fluid Challenge (RETOUCH), Quebec City, QC, Canada, 10–14 September 2017; pp. 30–37. [Google Scholar]
- Pekala, M.; Joshi, N.; Liu, T.A.; Bressler, N.M.; DeBuc, D.C.; Burlina, P. Deep learning based retinal OCT segmentation. Comput. Biol. Med. 2019, 114, 103445. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 2017, 8, 3627–3642. [Google Scholar] [CrossRef]
- Schlegl, T.; Waldstein, S.M.; Bogunovic, H.; Endstrasser, F.; Sadeghipour, A.; Philip, A.M.; Podkowinski, D.; Gerendas, B.S.; Langs, G.; Schmidt-Erfurth, U. Fully Automated Detection and Quantification of Macular Fluid in OCT Using Deep Learning. Ophthalmology 2018, 125, 549–558. [Google Scholar] [CrossRef] [Green Version]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D.; et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef]
- Hassan, B.; Qin, S.; Ahmed, R. SEADNet: Deep learning driven segmentation and extraction of macular fluids in 3D retinal OCT scans. In Proceedings of the 2020 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Louisville, KY, USA, 9–11 December 2020; pp. 1–6. [Google Scholar]
- Schmidt-Erfurth, U.; Mulyukov, Z.; Gerendas, B.S.; Reiter, G.S.; Lorand, D.; Weissgerber, G.; Bogunović, H. Therapeutic response in the HAWK and HARRIER trials using deep learning in retinal fluid volume and compartment analysis. Eye 2022, 1–10. [Google Scholar] [CrossRef]
- Roberts, P.K.; Vogl, W.D.; Gerendas, B.S.; Glassman, A.R.; Bogunovic, H.; Jampol, L.M.; Schmidt-Erfurth, U.M. Quantification of Fluid Resolution and Visual Acuity Gain in Patients With Diabetic Macular Edema Using Deep Learning: A Post Hoc Analysis of a Randomized Clinical Trial. JAMA Ophthalmol. 2020, 138, 945–953. [Google Scholar] [CrossRef]
- Ma, R.; Liu, Y.; Tao, Y.; Alawa, K.A.; Shyu, M.-L.; Lee, R.K. Deep Learning–Based Retinal Nerve Fiber Layer Thickness Measurement of Murine Eyes. Transl. Vis. Sci. Technol. 2021, 10, 21. [Google Scholar] [CrossRef] [PubMed]
- Orlando, J.I.; Breger, A.; Bogunović, H.; Riedl, S.; Gerendas, B.S.; Ehler, M.; Schmidt-Erfurth, U. An amplified-target loss approach for photoreceptor layer segmentation in pathological OCT scans. In Proceedings of the International Workshop on Ophthalmic Medical Image Analysis, Shenzhen, China, 17 October 2019; pp. 26–34. [Google Scholar]
- Orlando, J.I.; Seeböck, P.; Bogunović, H.; Klimscha, S.; Grechenig, C.; Waldstein, S.; Gerendas, B.S.; Schmidt-Erfurth, U. U2-net: A bayesian u-net model with epistemic uncertainty feedback for photoreceptor layer segmentation in pathological oct scans. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1441–1445. [Google Scholar]
- De Silva, T.; Jayakar, G.; Grisso, P.; Hotaling, N.; Chew, E.Y.; Cukras, C.A. Deep Learning-Based Automatic Detection of Ellipsoid Zone Loss in Spectral-Domain OCT for Hydroxychloroquine Retinal Toxicity Screening. Ophthalmol. Sci. 2021, 1, 100060. [Google Scholar] [CrossRef]
- Yakubovskiy, P. Segmentation Models; GitHub: San Francisco, CA, USA, 2019. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 fourth international conference on 3D vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Lu, D.; Heisler, M.; Lee, S.; Ding, G.; Sarunic, M.V.; Beg, M.F. Retinal fluid segmentation and detection in optical coherence tomography images using fully convolutional neural network. arXiv 2017, arXiv:1710.04778. [Google Scholar]
- Jaffe, G.J.; Ying, G.-S.; Toth, C.A.; Daniel, E.; Grunwald, J.E.; Martin, D.F.; Maguire, M.G.; Comparison of Age-Related Macular Degeneration Treatments Trials Research Group. Macular morphology and visual acuity in year five of the comparison of age-related macular degeneration treatments trials. Ophthalmology 2019, 126, 252–260. [Google Scholar] [CrossRef]
- Guymer, R.H.; Markey, C.M.; McAllister, I.L.; Gillies, M.C.; Hunyor, A.P.; Arnold, J.J.; FLUID Investigators. Tolerating Subretinal Fluid in Neovascular Age-Related Macular Degeneration Treated with Ranibizumab Using a Treat-and-Extend Regimen: FLUID Study 24-Month Results. Ophthalmology 2019, 126, 723–734. [Google Scholar] [CrossRef]
- Lee, C.S.; Tyring, A.J.; Deruyter, N.P.; Wu, Y.; Rokem, A.; Lee, A.Y. Deep-learning based, automated segmentation of macular edema in optical coherence tomography. Biomed. Opt. Express 2017, 8, 3440–3448. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| U-Net [14] | Proposed | |
|---|---|---|
| Encoder | 8 convolution layers with 4 max pooling layers | EfficientNet-B5 [30] (7 blocks) 1 |
| Decoder | 8 convolution layers with 4 up-convolution layers | 8 convolution layers with 4 up-convolution layers |
| Hyperparameter | Selected Value |
|---|---|
| Backbone of encoder | EfficientNet-B5 |
| Loss function | Loss of averaged Dice coefficient |
| Optimizer | Adam [31] |
| Learning rate | 1 × 10−4 |
| Batch size | 10 |
| Epoch | 50 |
| Retinal Features | Dice Coefficient | |
|---|---|---|
| U-Net | Proposed | |
| Neurosensory retina | 0.98 ± 0.02 | 0.98 ± 0.01 |
| EZ 1 | 0.80 ± 0.09 | 0.81 ± 0.08 |
| RPE 2 | 0.83 ± 0.04 | 0.82 ± 0.04 |
| IRC 3 | 0.61 ± 0.22 | 0.80 ± 0.08 |
| SRF 4 | 0.9 ± 0.02 | 0.89 ± 0.04 |
| Average | 0.84 ± 0.15 | 0.86 ± 0.09 |
| Features | Univariable | Multivariable | ||||
|---|---|---|---|---|---|---|
| β | SE | p-Value | β | SE | p-Value | |
| Disruption of EZ 1 | 0.428 | 0.016 | <0.001 | 0.413 | 0.021 | <0.001 |
| IRC 2 | 0.240 | 0.017 | <0.001 | 0.083 | 0.022 | <0.001 |
| SRF 3 | 0.031 | 0.018 | 0.088 | −0.064 | 0.016 | <0.001 |
| CST 4 | 0.181 | 0.018 | <0.001 | 0.110 | 0.022 | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, H.-Y.; Chou, Y.-B.; Jheng, Y.-C.; Kao, Z.-K.; Huang, H.-Y.; Chen, H.-R.; Hwang, D.-K.; Chen, S.-J.; Chiou, S.-H.; Wu, Y.-T. Automatic Segmentation of Retinal Fluid and Photoreceptor Layer from Optical Coherence Tomography Images of Diabetic Macular Edema Patients Using Deep Learning and Associations with Visual Acuity. Biomedicines 2022, 10, 1269. https://doi.org/10.3390/biomedicines10061269
Hsu H-Y, Chou Y-B, Jheng Y-C, Kao Z-K, Huang H-Y, Chen H-R, Hwang D-K, Chen S-J, Chiou S-H, Wu Y-T. Automatic Segmentation of Retinal Fluid and Photoreceptor Layer from Optical Coherence Tomography Images of Diabetic Macular Edema Patients Using Deep Learning and Associations with Visual Acuity. Biomedicines. 2022; 10(6):1269. https://doi.org/10.3390/biomedicines10061269
Chicago/Turabian StyleHsu, Huan-Yu, Yu-Bai Chou, Ying-Chun Jheng, Zih-Kai Kao, Hsin-Yi Huang, Hung-Ruei Chen, De-Kuang Hwang, Shih-Jen Chen, Shih-Hwa Chiou, and Yu-Te Wu. 2022. "Automatic Segmentation of Retinal Fluid and Photoreceptor Layer from Optical Coherence Tomography Images of Diabetic Macular Edema Patients Using Deep Learning and Associations with Visual Acuity" Biomedicines 10, no. 6: 1269. https://doi.org/10.3390/biomedicines10061269