
Loss Weightings for Improving Imbalanced Brain Structure Segmentation Using Fully Convolutional Networks

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
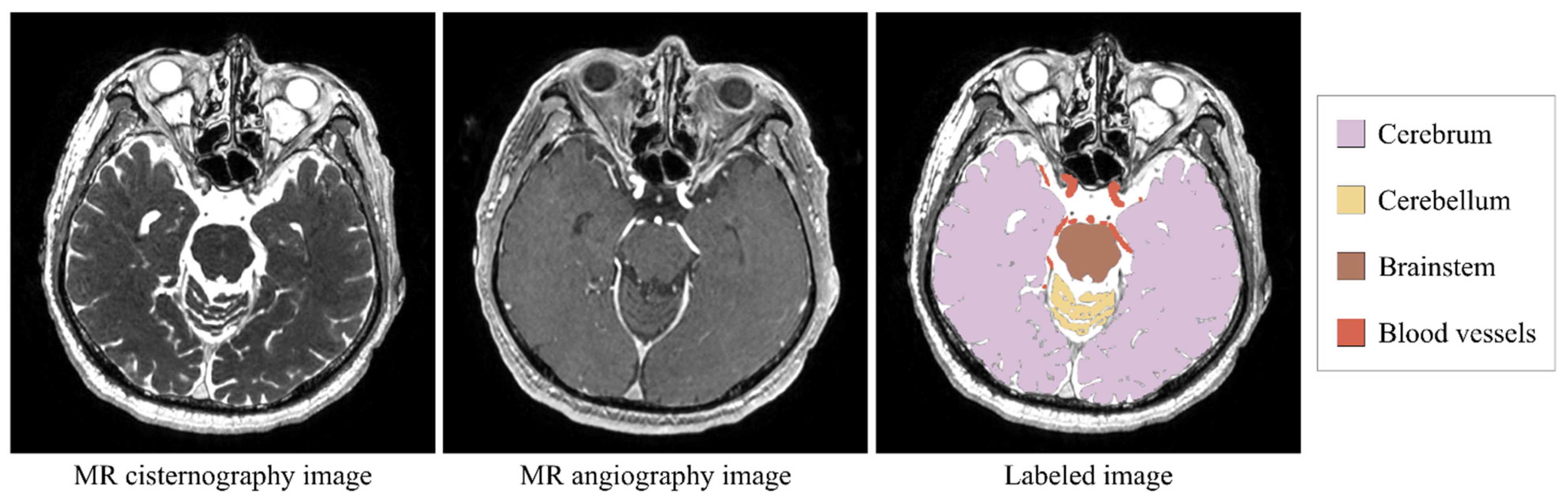
2.1. Segmentation Target
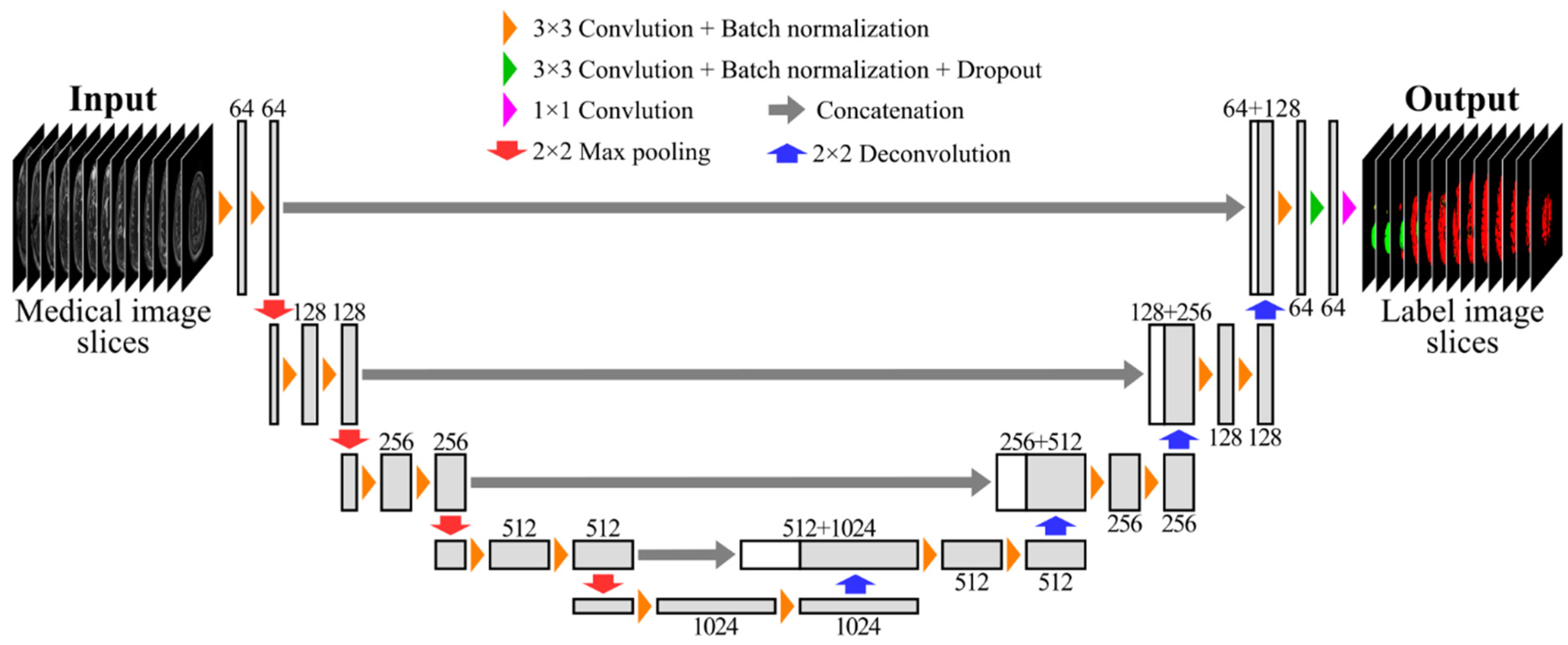
2.2. Network Architecture
2.3. Loss Functions
2.4. Loss Weighting Strategies
2.4.1. Inverse Frequency Weighting
2.4.2. Inverse Median Frequency Weighting
2.4.3. Focal Weighting
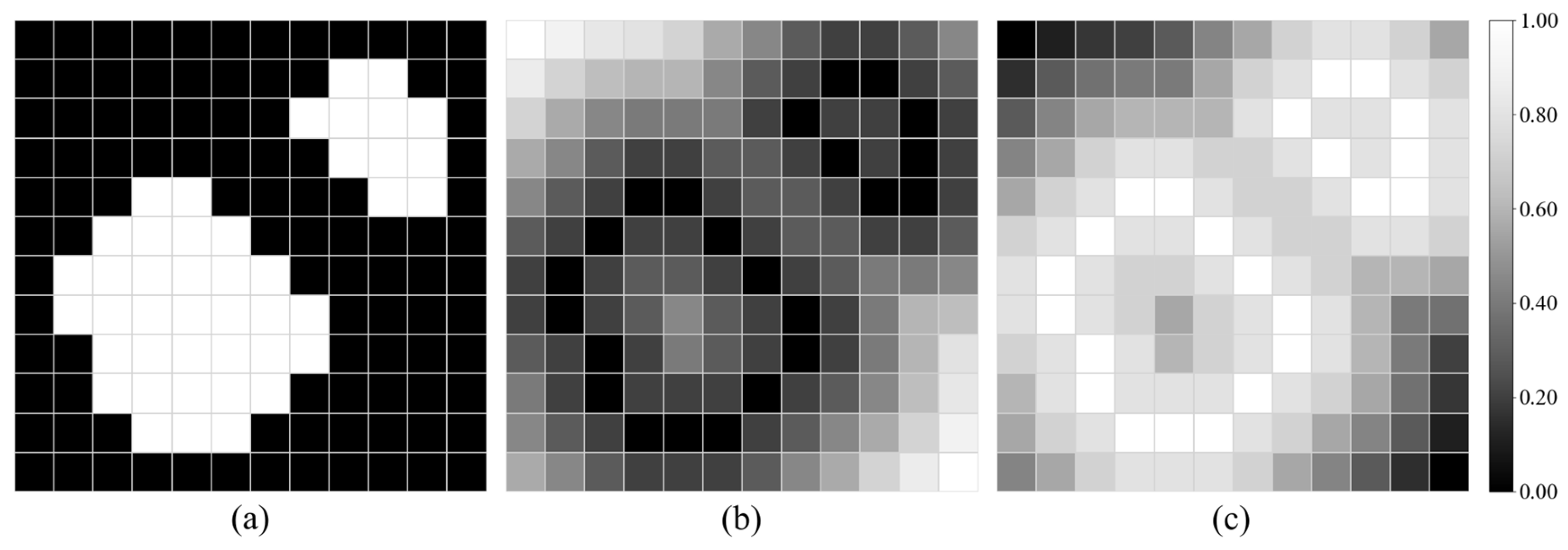
2.4.4. Distance Transform Map-Based Weighting
2.4.5. Distance Penalty Term-Based Weighting
2.5. Evaluation of Loss Weighting Strategies
2.5.1. Dataset
2.5.2. Segmentation Tasks
2.5.3. Network Training Procedure
2.5.4. Evaluation Metrics
- Step 1.
- Performance assessment per case: compute metrics of all loss functions for all classes in all test cases , where and are the number of metrics and classes, respectively. Note that in this case, we used four metrics and a total of twelve loss functions, including cross-entropy and Dice loss functions with no weighting, Inverse, Median, Focal, DTM, and DPT weightings.
- Step 2.
- Statistical tests: perform Wilcoxon signed-rank pairwise statistical tests between all loss functions with the values .
- Step 3.
- Significance scoring: compute a significance score for loss functions , classes , and metrics . equals the number of loss functions performing significantly worse than according to the statistical tests (, not adjusted for multiplicity).
- Step 4.
- Rank score computing: compute the final rank score of each loss function from the mean significance score of all classes and metrics in each of the binary- and multi-class segmentation tasks by the following equation:
3. Results
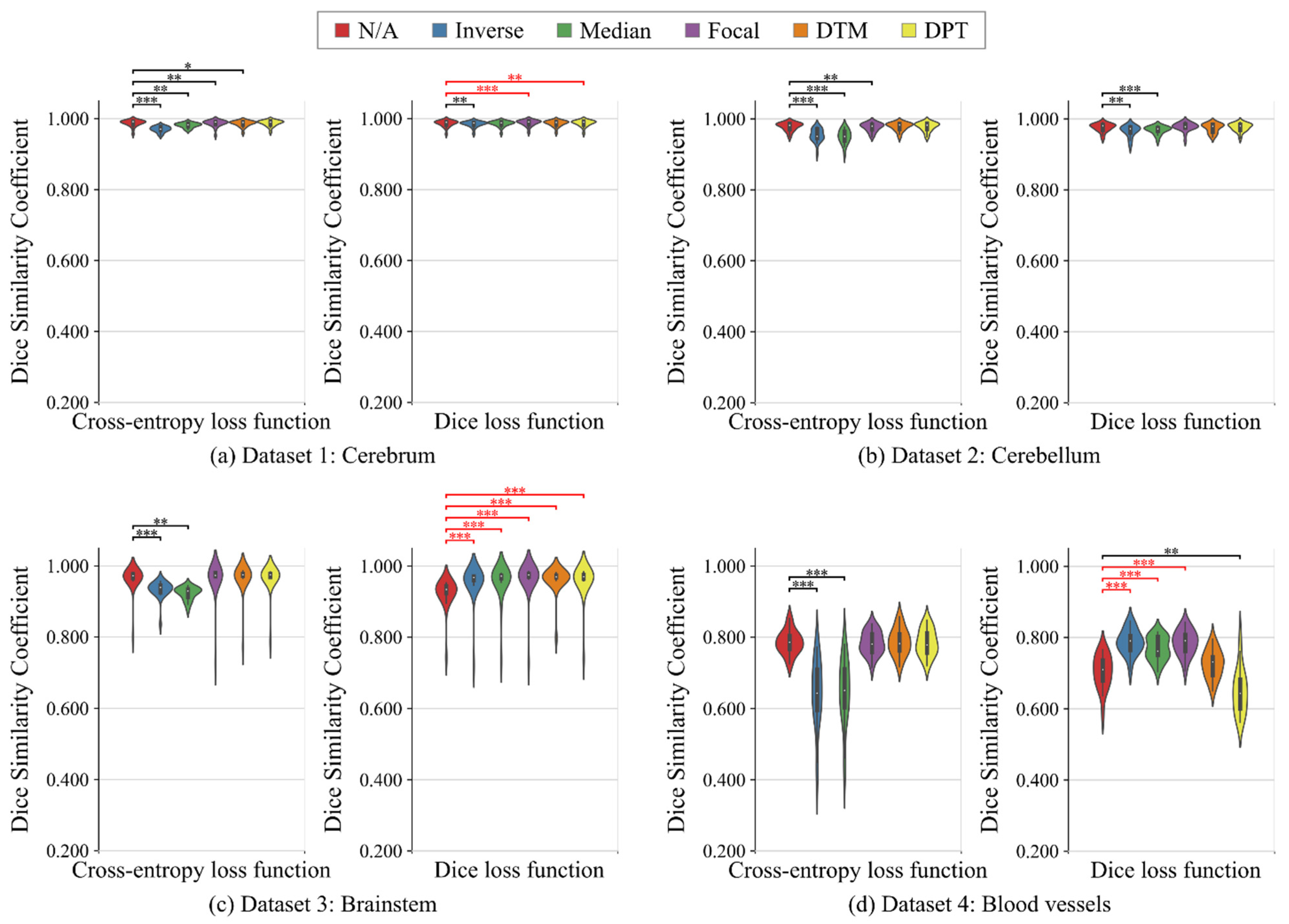
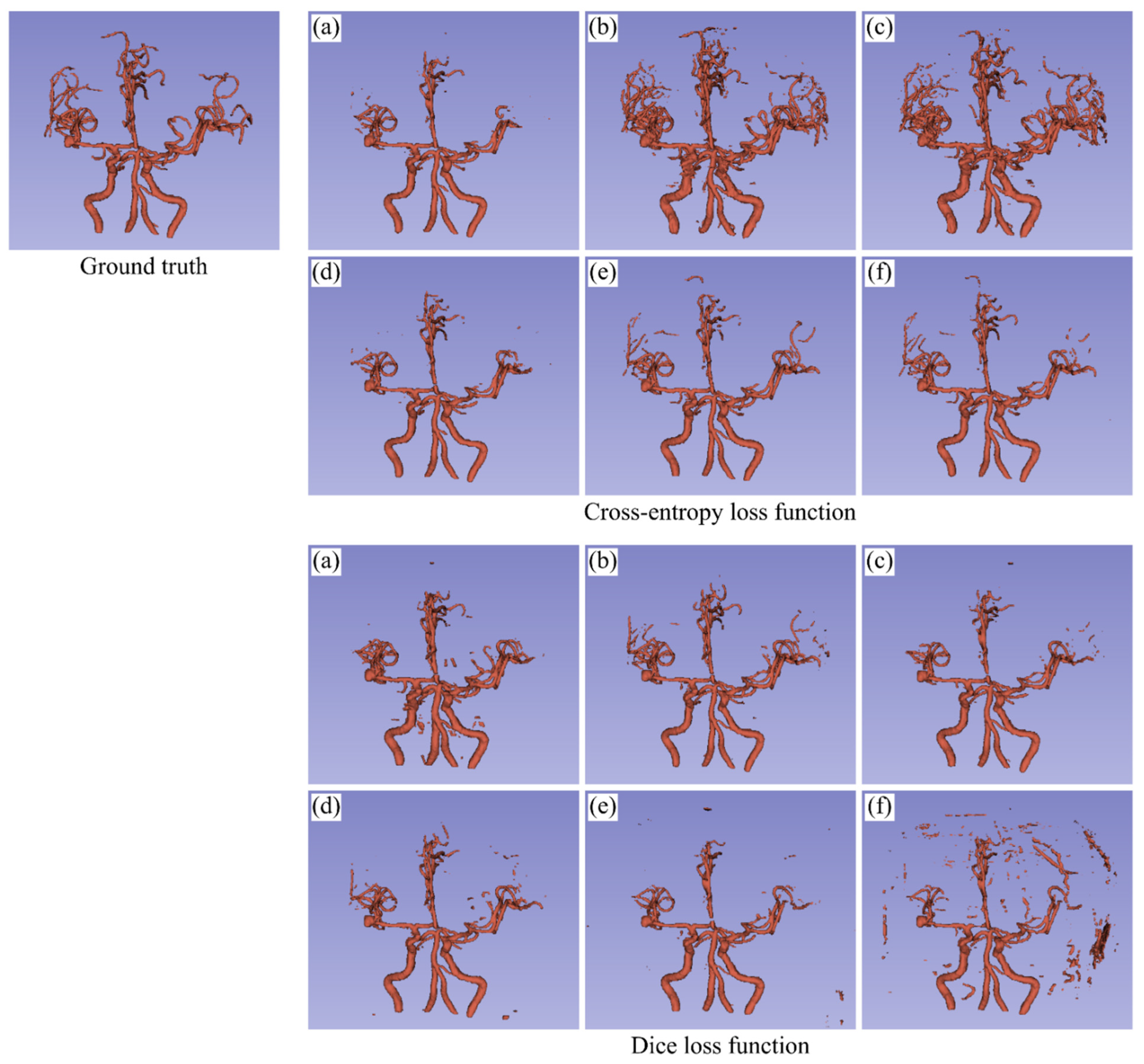
3.1. Binary-Class Segmentation Tasks
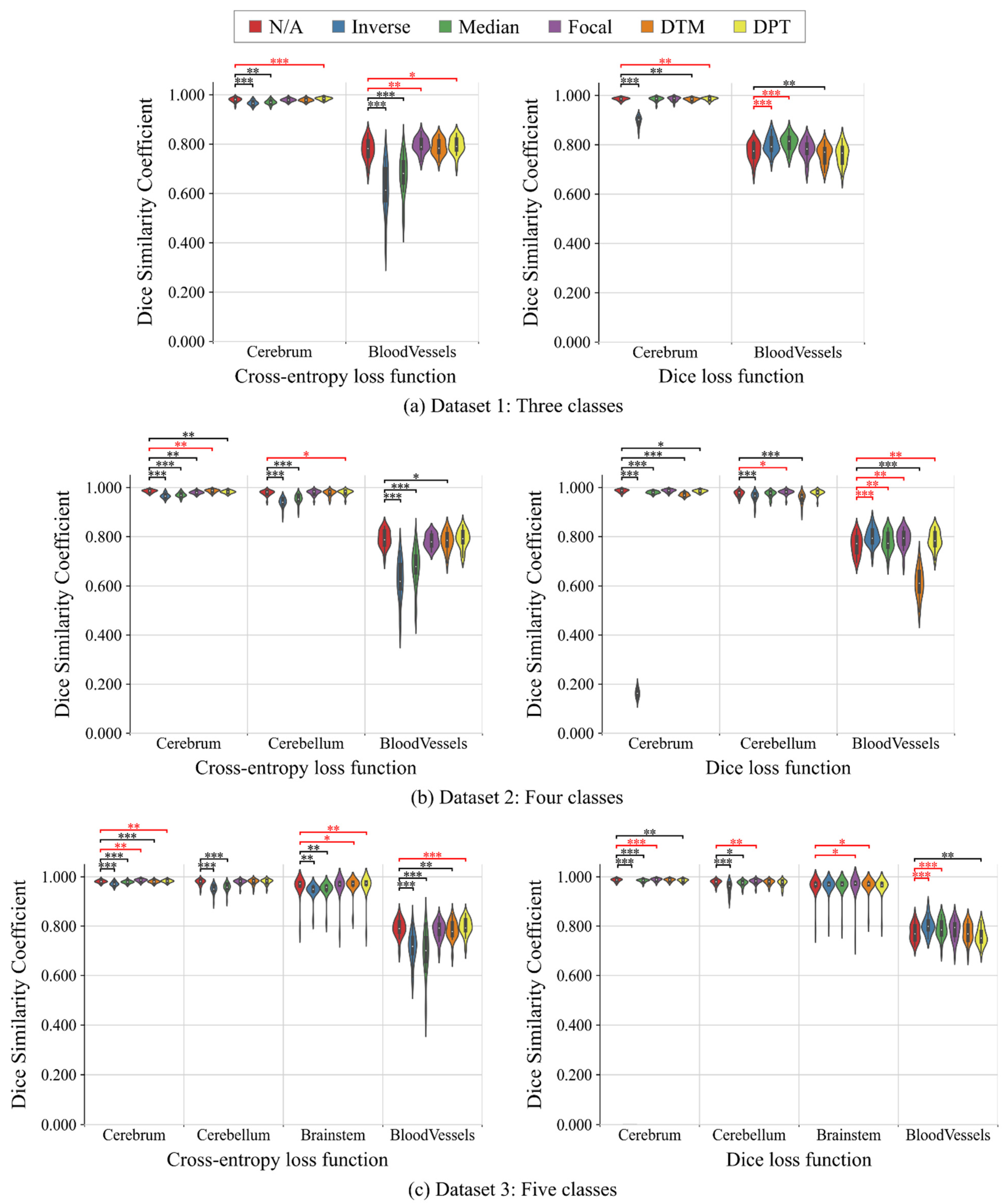
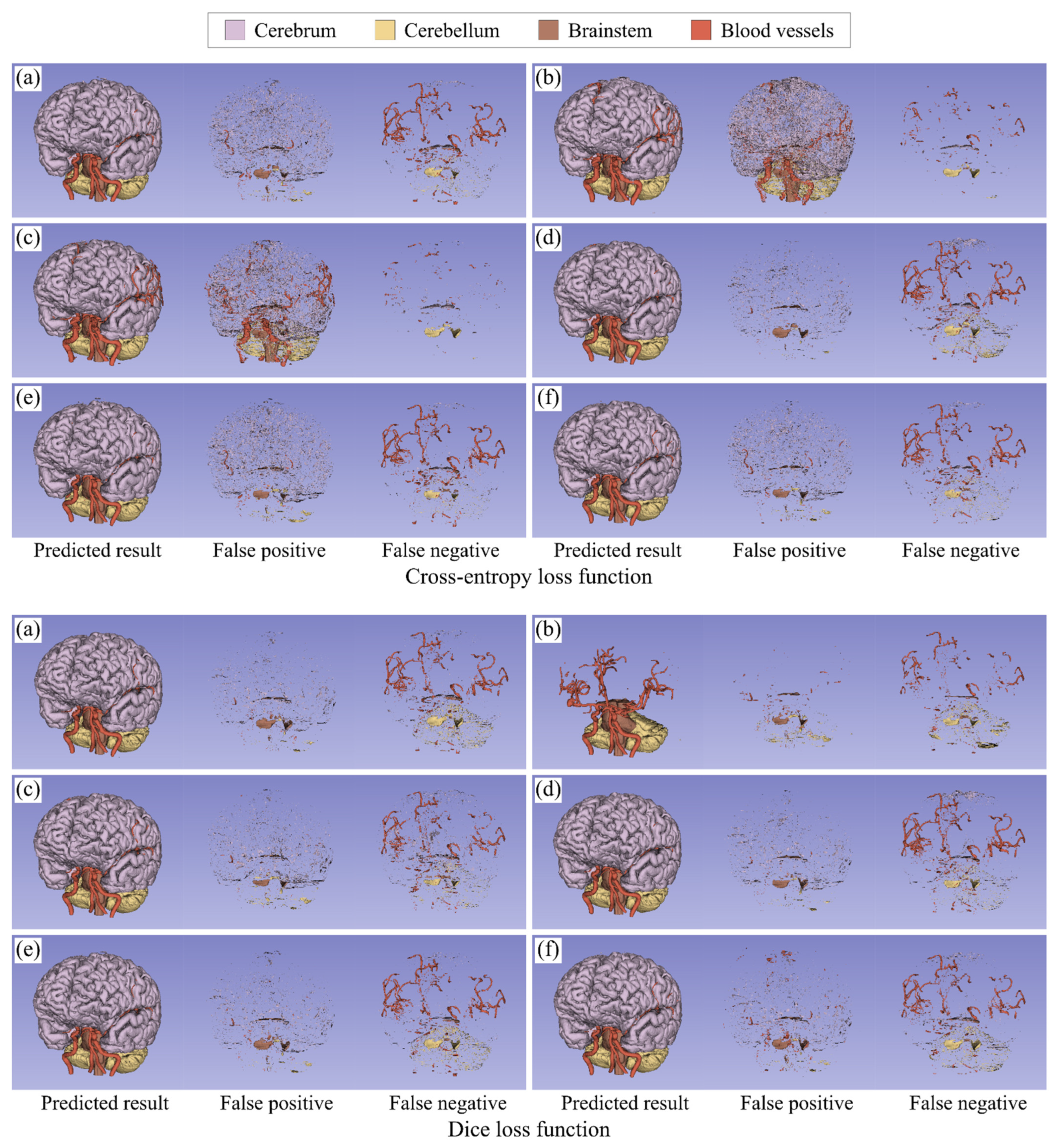
3.2. Multi-Class Segmentation Tasks
3.3. Rank Scoring
4. Discussion
4.1. Binary-Class Segmentation Tasks
4.2. Multi-Class Segmentation Tasks
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- González-Villà, S.; Oliver, A.; Valverde, S.; Wang, L.; Zwiggelaar, R.; Lladó, X. A review on brain structures segmentation in magnetic resonance imaging. Artif. Intell. Med. 2016, 73, 45–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Despotovic, I.; Goossens, B.; Philips, W. MRI segmentation of the human brain: Challenges, methods, and applications. Comput. Math. Methods Med. 2015, 2015, 450341. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Comput Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: NW Washington, DC, USA, 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; LNCS 9351. pp. 234–241. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17-21 October 2016; LNCS 9351. pp. 424–432. [Google Scholar]
- Bernal, J.; Kushibar, K.; Asfaw, D.S.; Valverde, S.; Oliver, A.; Marti, R.; Lladó, X. Deep convolutional neural networks for brain image analysis networks for brain image analysis on magnetic resonance imaging: A review. Artif. Intell. Med. 2019, 95, 64–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buda, M.; Maki, A.; Mazuroqski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, T.; Ruan, S.; Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array 2019, 3, 100004. [Google Scholar] [CrossRef]
- Jang, J.; Eo, T.J.; Kim, M.; Choi, N.; Han, D.; Kim, D.; Hwang, D. Medical image matching using variable randomized undersampling probability pattern in data acquisition. In Proceedings of the 2014 International Conference on Electronics, Information and Communications, Kota Kinabalu, Malaysia, 15–18 January 2014; pp. 1–2. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; IEEE: NW Washington, DC, USA, 2016; pp. 566–571. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The importance of skip connections in biomedical image segmentation. In Deep Learning and Data Labeling for Medical Applications; Springer: Cham, Switzerland, 2016; LNCS 10008; pp. 179–187. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; LNCS 10072. pp. 234–244. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4413–4421. [Google Scholar]
- Wong, K.C.L.; Moradi, M.; Tang, H.; Syeda-Mahmood, T. 3D segmentation with exponential logarithmic loss for highly unbalanced object sizes. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; LNCS 11072. pp. 612–619. [Google Scholar]
- Kervadec, H.; Bouchtiba, J.; Desrosiers, C.; Granger, E.; Dolz, J.; Ayed, I.B. Boundary loss for highly unbalanced segmentation. Med. Image Anal. 2019, 67, 101851. [Google Scholar] [CrossRef] [PubMed]
- Karimi, D.; Salcudean, S.E. Reducing the Hausdorff distance in medical image segmentation with convolutional neural networks. IEEE Trans. Med. Imaging 2020, 39, 499–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eigen, D.; Fergus, R. Predicting depth, surface normal and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: NW Washington, DC, USA, 2015; pp. 2650–2658. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: NW Washington, DC, USA, 2017; pp. 2980–2988. [Google Scholar]
- Caliva, F.; Iriondo, C.; Martinez, A.M.; Majumdar, S.; Pedoia, V. Distance map loss penalty term for semantic segmentation. In Proceedings of the 2nd International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019; pp. 1–5. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; LNCS 10541. pp. 379–387. [Google Scholar]
- Hashemi, S.R.; Salehi, S.S.M.; Erdogmus, D.; Prabhu, S.P.; Warfield, S.K.; Gholipour, A. Asymmetric loss functions and deep densely-connected networks for highly-imbalanced medical image segmentation: Application to multiple sclerosis lesion detection. IEEE Access 2018, 7, 1721–1735. [Google Scholar] [CrossRef] [PubMed]
- Guerrero-Pena, F.A.; Fernandez, P.D.M.; Ren, T.I.; Yui, M.; Rothenberg, E.; Cunha, A. Multiclass weighted loss for instance segmentation of cluttered cells. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2451–2455. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised Dice overlap as a deep learning loss function for highly unbalanced segmentations. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Québec City, QC, Canada, 14 September 2017; Springer: Cham, Switzerland, 2017. LNCS 10553. pp. 240–248. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 465–476. [Google Scholar]
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A.L. Loss odyssey in medical image segmentation. Med. Image Anal. 2021, 71, 102035. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Wei, Z.; Zhang, Y.; Wang, Y.; Lv, R.; Zhu, C.; Chen, G.; Liu, J.; Peng, C.; Wang, L.; et al. How distance transform maps boost segmentation CNNs: An empirical study. Med. Imaging Deep Learn. 2020, 121, 479–492. [Google Scholar]
- Yeung, M.; Sala, E.; Schönlieb, C.B.; Rundo, L. Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medical image segmentation. arXiv 2021, arXiv:2102.04525, Preprint. [Google Scholar]
- Huo, Y.; Xu, Z.; Xiong, Y.; Aboud, K.; Parvathaneni, P.; Bao, S.; Bermudez, C.; Resnick, S.M.; Cutting, L.E.; Landman, B.A. 3D whole brain segmentation using spatially localized atlas network tiles. NeuroImage 2019, 194, 105–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taghanaki, S.A.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo loss: Handling input and output imbalance in multi-organ segmentation. Comput. Med. Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, W.; Huang, Y.; Zeng, L.; Chen, X.; Liu, Y.; Qian, Z.; Du, N.; Fan, W.; Xie, X. AnatomyNet: Deep learning for fast and fully automated whole-volume segmentation of head and neck anatomy. Med. Phys. 2018, 46, 576–589. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xue, Y.; Tang, H.; Qiao, Z.; Gong, G.; Yin, Y.; Qian, Z.; Huang, X. Shape-aware organ segmentation by predicting signed distance maps. AAAI Conf. Artif. Intell. 2020, 34, 12565–12572. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980, Preprint. [Google Scholar]
- Nikolov, S.; Blackwell, S.; Zverovitch, A.; Mendes, R.; Livne, M.; De Fauw, J.; Patel, Y.; Meyer, C.; Askham, H.; Romera-Paredes, B.; et al. Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy. arXiv 2018, arXiv:1809.04430, Preprint. [Google Scholar]
- DeepMind. Github: Library to Compute Surface Distance Based Performance Metrics for Segmentation Tasks. Available online: https://github.com/deepmind/surface-distance (accessed on 28 April 2021).
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M.; et al. The Medical Segmentation Decathlon. arXiv 2021, arXiv:2106.05735, Preprint. [Google Scholar]
- Conti, V.; Militello, C.; Rundo, L.; Vitabile, S. A novel bio-inspired approach for high-performance management in service-oriented networks. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline Loss Functions | Weighting Strategies | Weighted Loss Functions | |
|---|---|---|---|
| Cross-entropy loss function | Class frequency-based weighting | Inverse frequency weighting | |
| Inverse median weighting | |||
| Predictive probability-based weighting | Focal weighting | ||
| Distance map-based weighting | Distance transform map-based weighting | ||
| Distance penalty term-based weighting | |||
| Dice loss function | Class frequency-based weighting | Inverse frequency weighting | |
| Inverse median weighting | |||
| Predictive probability-based weighting | Focal weighting | ||
| Distance map-based weighting | Distance transform map-based weighting | ||
| Distance penalty term-based weighting | |||
| Cerebrum | Cerebellum | Brainstem | Blood Vessels | |
|---|---|---|---|---|
| Frequency | 0.096 | 0.012 | 0.003 | 0.001 |
| Dataset | Ratio 1 |
|---|---|
| Binary-class segmentation tasks | |
| Dataset 1: Cerebrum | |
| Dataset 2: Cerebellum | |
| Dataset 3: Brainstem | |
| Dataset 4: Blood vessels | |
| Multi-class segmentation tasks | |
| Dataset 1: Three classes | |
| Dataset 2: Four classes | |
| Dataset 3: Five classes |
| Loss Function | Weighting | DSC | SDSC | ASD | 95HD |
|---|---|---|---|---|---|
| (a) Dataset 1: Cerebrum | |||||
| Cross entropy | N/A | 0.987 | 0.991 | 0.064 | 0.287 |
| Inverse | 0.970 | 0.941 | 0.424 | 3.504 | |
| Median | 0.981 | 0.983 | 0.135 | 0.565 | |
| Focal | 0.986 | 0.989 | 0.073 | 0.397 | |
| DTM | 0.986 | 0.990 | 0.069 | 0.378 | |
| DPT | 0.987 | 0.992 | 0.059 | 0.328 | |
| Dice | N/A | 0.986 | 0.988 | 0.102 | 0.381 |
| Inverse | 0.984 | 0.986 | 0.275 | 0.495 | |
| Median | 0.985 | 0.990 | 0.234 | 0.425 | |
| Focal | 0.988 | 0.993 | 0.054 | 0.308 | |
| DTM | 0.987 | 0.991 | 0.061 | 0.364 | |
| DPT | 0.987 | 0.992 | 0.066 | 0.341 | |
| (b) Dataset 2: Cerebellum | |||||
| Cross entropy | N/A | 0.978 | 0.981 | 0.088 | 0.669 |
| Inverse | 0.954 | 0.922 | 0.411 | 1.755 | |
| Median | 0.950 | 0.904 | 0.525 | 2.539 | |
| Focal | 0.976 | 0.976 | 0.166 | 2.430 | |
| DTM | 0.978 | 0.978 | 0.104 | 0.729 | |
| DPT | 0.978 | 0.980 | 0.089 | 0.713 | |
| Dice | N/A | 0.976 | 0.973 | 0.221 | 1.048 |
| Inverse | 0.965 | 0.940 | 1.934 | 1.975 | |
| Median | 0.968 | 0.950 | 2.037 | 4.568 | |
| Focal | 0.977 | 0.980 | 0.101 | 0.686 | |
| DTM | 0.974 | 0.972 | 0.153 | 0.878 | |
| DPT | 0.976 | 0.975 | 0.184 | 2.331 | |
| (c) Dataset 3: Brainstem | |||||
| Cross entropy | N/A | 0.963 | 0.940 | 0.501 | 4.676 |
| Inverse | 0.933 | 0.874 | 1.024 | 8.518 | |
| Median | 0.922 | 0.849 | 0.849 | 6.510 | |
| Focal | 0.962 | 0.947 | 0.239 | 1.362 | |
| DTM | 0.965 | 0.951 | 0.280 | 1.204 | |
| DPT | 0.965 | 0.946 | 0.425 | 3.478 | |
| Dice | N/A | 0.923 | 0.824 | 8.880 | 156.912 |
| Inverse | 0.953 | 0.921 | 0.476 | 4.770 | |
| Median | 0.954 | 0.926 | 0.421 | 3.365 | |
| Focal | 0.963 | 0.949 | 0.241 | 1.905 | |
| DTM | 0.961 | 0.939 | 0.332 | 4.268 | |
| DPT | 0.957 | 0.936 | 0.318 | 1.646 | |
| (d) Dataset 4: Blood vessels | |||||
| Cross entropy | N/A | 0.785 | 0.809 | 1.415 | 12.947 |
| Inverse | 0.642 | 0.700 | 2.008 | 16.978 | |
| Median | 0.647 | 0.690 | 2.222 | 18.620 | |
| Focal | 0.783 | 0.812 | 1.351 | 12.353 | |
| DTM | 0.786 | 0.821 | 1.419 | 12.243 | |
| DPT | 0.784 | 0.824 | 1.361 | 12.340 | |
| Dice | N/A | 0.704 | 0.767 | 1.996 | 16.026 |
| Inverse | 0.786 | 0.826 | 1.385 | 13.364 | |
| Median | 0.768 | 0.794 | 1.627 | 14.597 | |
| Focal | 0.785 | 0.812 | 1.518 | 13.104 | |
| DTM | 0.725 | 0.754 | 2.400 | 19.281 | |
| DPT | 0.648 | 0.627 | 5.999 | 40.077 | |
| (a) Dataset 1: Three Classes | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loss Function | Weighting | Cerebrum | Blood Vessels | ||||||||||
| DSC | SDSC | ASD | 95HD | DSC | SDSC | ASD | 95HD | ||||||
| Cross entropy | N/A | 0.979 | 0.965 | 0.507 | 5.635 | 0.778 | 0.810 | 1.926 | 17.142 | ||||
| Inverse | 0.967 | 0.956 | 0.265 | 1.256 | 0.618 | 0.662 | 2.448 | 20.272 | |||||
| Median | 0.970 | 0.969 | 0.239 | 1.273 | 0.675 | 0.740 | 1.901 | 17.298 | |||||
| Focal | 0.979 | 0.989 | 0.093 | 0.585 | 0.796 | 0.843 | 1.195 | 12.933 | |||||
| DTM | 0.979 | 0.989 | 0.092 | 0.585 | 0.788 | 0.848 | 1.097 | 10.539 | |||||
| DPT | 0.984 | 0.992 | 0.069 | 0.492 | 0.795 | 0.836 | 1.198 | 11.321 | |||||
| Dice | N/A | 0.985 | 0.990 | 0.266 | 0.445 | 0.771 | 0.833 | 1.225 | 11.276 | ||||
| Inverse | 0.896 | 0.634 | 2.290 | 17.436 | 0.800 | 0.842 | 1.177 | 11.325 | |||||
| Median | 0.985 | 0.986 | 0.109 | 0.479 | 0.809 | 0.848 | 1.172 | 11.654 | |||||
| Focal | 0.985 | 0.984 | 0.147 | 0.415 | 0.780 | 0.821 | 1.525 | 14.393 | |||||
| DTM | 0.984 | 0.991 | 0.068 | 0.492 | 0.760 | 0.817 | 1.354 | 11.769 | |||||
| DPT | 0.986 | 0.992 | 0.245 | 0.408 | 0.759 | 0.816 | 1.346 | 12.316 | |||||
| (b) Dataset 2: Four classes | |||||||||||||
| Loss Function | Weighting | Cerebrum | Cerebellum | Blood Vessels | |||||||||
| DSC | SDSC | ASD | 95HD | DSC | SDSC | ASD | 95HD | DSC | SDSC | ASD | 95HD | ||
| Cross entropy | N/A | 0.985 | 0.994 | 0.057 | 0.469 | 0.978 | 0.981 | 0.082 | 0.670 | 0.792 | 0.834 | 1.209 | 11.215 |
| Inverse | 0.966 | 0.963 | 0.221 | 1.015 | 0.939 | 0.890 | 0.472 | 1.911 | 0.623 | 0.668 | 2.375 | 19.928 | |
| Median | 0.970 | 0.968 | 0.221 | 1.009 | 0.954 | 0.938 | 0.279 | 1.397 | 0.674 | 0.738 | 1.860 | 17.051 | |
| Focal | 0.980 | 0.990 | 0.087 | 0.575 | 0.979 | 0.982 | 0.082 | 0.635 | 0.783 | 0.836 | 1.168 | 11.228 | |
| DTM | 0.986 | 0.994 | 0.059 | 0.408 | 0.977 | 0.979 | 0.142 | 2.019 | 0.781 | 0.827 | 1.247 | 11.639 | |
| DPT | 0.982 | 0.992 | 0.069 | 0.505 | 0.980 | 0.986 | 0.065 | 0.579 | 0.791 | 0.842 | 1.138 | 11.197 | |
| Dice | N/A | 0.986 | 0.993 | 0.060 | 0.338 | 0.975 | 0.971 | 0.329 | 2.370 | 0.766 | 0.821 | 1.246 | 11.110 |
| Inverse | 0.163 | 0.066 | 18.575 | 81.644 | 0.960 | 0.949 | 0.314 | 3.939 | 0.799 | 0.840 | 1.192 | 12.014 | |
| Median | 0.980 | 0.984 | 0.155 | 0.524 | 0.973 | 0.972 | 0.234 | 2.578 | 0.780 | 0.818 | 1.306 | 12.029 | |
| Focal | 0.987 | 0.994 | 0.052 | 0.352 | 0.980 | 0.986 | 0.067 | 0.543 | 0.791 | 0.834 | 1.233 | 11.518 | |
| DTM | 0.971 | 0.963 | 0.198 | 1.061 | 0.956 | 0.933 | 0.449 | 3.654 | 0.610 | 0.630 | 5.309 | 34.425 | |
| DPT | 0.985 | 0.992 | 0.064 | 0.505 | 0.978 | 0.981 | 0.085 | 0.593 | 0.786 | 0.827 | 1.289 | 12.360 | |
| (c) Dataset 3: Five classes | |||||||||||||
| Loss Function | Weighting | Cerebrum | Cerebellum | ||||||||||
| DSC | SDSC | ASD | 95HD | DSC | SDSC | ASD | 95HD | ||||||
| Cross entropy | N/A | 0.981 | 0.991 | 0.083 | 0.552 | 0.977 | 0.980 | 0.127 | 0.855 | ||||
| Inverse | 0.971 | 0.973 | 0.179 | 0.846 | 0.950 | 0.926 | 0.346 | 1.492 | |||||
| Median | 0.979 | 0.987 | 0.104 | 0.609 | 0.958 | 0.949 | 0.253 | 1.252 | |||||
| Focal | 0.985 | 0.993 | 0.060 | 0.469 | 0.979 | 0.984 | 0.107 | 0.634 | |||||
| DTM | 0.980 | 0.990 | 0.085 | 0.552 | 0.979 | 0.982 | 0.093 | 0.898 | |||||
| DPT | 0.982 | 0.993 | 0.069 | 0.502 | 0.980 | 0.985 | 0.070 | 0.624 | |||||
| Dice | N/A | 0.986 | 0.993 | 0.074 | 0.338 | 0.977 | 0.982 | 0.084 | 0.618 | ||||
| Inverse | 0.000 | 0.000 | - | - | 0.955 | 0.946 | 0.221 | 1.405 | |||||
| Median | 0.984 | 0.988 | 0.107 | 0.502 | 0.974 | 0.975 | 0.171 | 1.164 | |||||
| Focal | 0.987 | 0.995 | 0.052 | 0.291 | 0.980 | 0.986 | 0.065 | 0.567 | |||||
| DTM | 0.986 | 0.993 | 0.068 | 0.361 | 0.978 | 0.983 | 0.082 | 0.608 | |||||
| DPT | 0.985 | 0.992 | 0.098 | 0.445 | 0.974 | 0.977 | 0.095 | 0.747 | |||||
| Loss Function | Weighting | Brainstem | Blood Vessels | ||||||||||
| DSC | SDSC | ASD | 95HD | DSC | SDSC | ASD | 95HD | ||||||
| Cross entropy | N/A | 0.961 | 0.942 | 0.266 | 2.083 | 0.790 | 0.846 | 1.084 | 10.471 | ||||
| Inverse | 0.944 | 0.937 | 0.371 | 1.302 | 0.712 | 0.778 | 1.524 | 14.184 | |||||
| Median | 0.949 | 0.928 | 0.415 | 1.528 | 0.686 | 0.721 | 1.920 | 17.233 | |||||
| Focal | 0.962 | 0.947 | 0.267 | 1.495 | 0.782 | 0.830 | 1.263 | 12.068 | |||||
| DTM | 0.966 | 0.946 | 0.291 | 2.362 | 0.783 | 0.840 | 1.163 | 11.097 | |||||
| DPT | 0.964 | 0.952 | 0.203 | 1.343 | 0.797 | 0.855 | 1.059 | 10.703 | |||||
| Dice | N/A | 0.960 | 0.934 | 0.389 | 2.174 | 0.774 | 0.828 | 1.234 | 11.574 | ||||
| Inverse | 0.961 | 0.941 | 0.391 | 2.374 | 0.801 | 0.836 | 1.196 | 12.002 | |||||
| Median | 0.962 | 0.941 | 0.344 | 2.329 | 0.788 | 0.829 | 1.200 | 10.648 | |||||
| Focal | 0.963 | 0.952 | 0.235 | 1.262 | 0.783 | 0.828 | 1.300 | 12.835 | |||||
| DTM | 0.964 | 0.944 | 0.217 | 1.288 | 0.773 | 0.831 | 1.221 | 11.280 | |||||
| DPT | 0.960 | 0.929 | 0.394 | 3.759 | 0.757 | 0.801 | 1.869 | 18.269 | |||||
| (a) Binary-Class Segmentation Tasks | |||||||
|---|---|---|---|---|---|---|---|
| Loss Function | Weighting | Rank Score | Rank | ||||
| Dataset 1: Cerebrum | Dataset 2: Cerebellum | Dataset 3: Brainstem | Dataset 4: Blood Vessels | All | |||
| Cross entropy | N/A | 5.25 | 7.25 | 3.25 | 6.00 | 5.44 | 4 |
| Inverse | 0.00 | 2.25 | 1.25 | 1.25 | 1.19 | 11 | |
| Median | 1.50 | 0.75 | 0.50 | 0.75 | 0.88 | 12 | |
| Focal | 3.50 | 4.00 | 6.00 | 6.00 | 4.88 | 5 | |
| DTM | 4.25 | 6.25 | 6.50 | 6.00 | 5.75 | 2 | |
| DPT | 5.5 | 6.25 | 4.50 | 6.00 | 5.56 | 3 | |
| Dice | N/A | 2.75 | 4.00 | 0.00 | 2.50 | 2.31 | 10 |
| Inverse | 1.75 | 1.50 | 3.00 | 5.50 | 2.94 | 8 | |
| Median | 1.75 | 1.00 | 3.50 | 3.75 | 2.50 | 9 | |
| Focal | 8.5 | 4.50 | 6.50 | 4.75 | 6.06 | 1 | |
| DTM | 4.5 | 4.25 | 4.25 | 1.75 | 3.69 | 6 | |
| DPT | 5.25 | 4.00 | 4.00 | 0.00 | 3.31 | 7 | |
| (b) Multi-class segmentation tasks | |||||||
| Loss Function | Weighting | Rank Score | Rank | ||||
| Dataset 1: Three Classes | Dataset 2: Four Classes | Dataset 3: Five Classes | All | ||||
| Cross entropy | N/A | 1.50 | 5.75 | 4.13 | 4.08 | 6 | |
| Inverse | 0.63 | 0.83 | 0.81 | 0.78 | 12 | ||
| Median | 1.25 | 1.92 | 0.81 | 1.28 | 11 | ||
| Focal | 4.88 | 4.67 | 4.19 | 4.50 | 4 | ||
| DTM | 5.63 | 5.25 | 3.69 | 4.64 | 3 | ||
| DPT | 6.75 | 6.17 | 6.63 | 6.50 | 1 | ||
| Dice | N/A | 4.63 | 4.58 | 3.69 | 4.19 | 5 | |
| Inverse | 2.88 | 2.17 | 1.38 | 1.97 | 10 | ||
| Median | 6.00 | 3.67 | 2.56 | 3.69 | 8 | ||
| Focal | 3.63 | 7.50 | 6.75 | 6.31 | 2 | ||
| DTM | 4.63 | 0.67 | 4.75 | 3.36 | 9 | ||
| DPT | 4.88 | 4.67 | 2.44 | 3.72 | 7 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sugino, T.; Kawase, T.; Onogi, S.; Kin, T.; Saito, N.; Nakajima, Y. Loss Weightings for Improving Imbalanced Brain Structure Segmentation Using Fully Convolutional Networks. Healthcare 2021, 9, 938. https://doi.org/10.3390/healthcare9080938
Sugino T, Kawase T, Onogi S, Kin T, Saito N, Nakajima Y. Loss Weightings for Improving Imbalanced Brain Structure Segmentation Using Fully Convolutional Networks. Healthcare. 2021; 9(8):938. https://doi.org/10.3390/healthcare9080938
Chicago/Turabian StyleSugino, Takaaki, Toshihiro Kawase, Shinya Onogi, Taichi Kin, Nobuhito Saito, and Yoshikazu Nakajima. 2021. "Loss Weightings for Improving Imbalanced Brain Structure Segmentation Using Fully Convolutional Networks" Healthcare 9, no. 8: 938. https://doi.org/10.3390/healthcare9080938