
A Framework for Automatic Clustering of EHR Messages Using a Spatial Clustering Approach
 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
3. HL7 V2 Messages Machine Learning DBSCAN Clustering Model
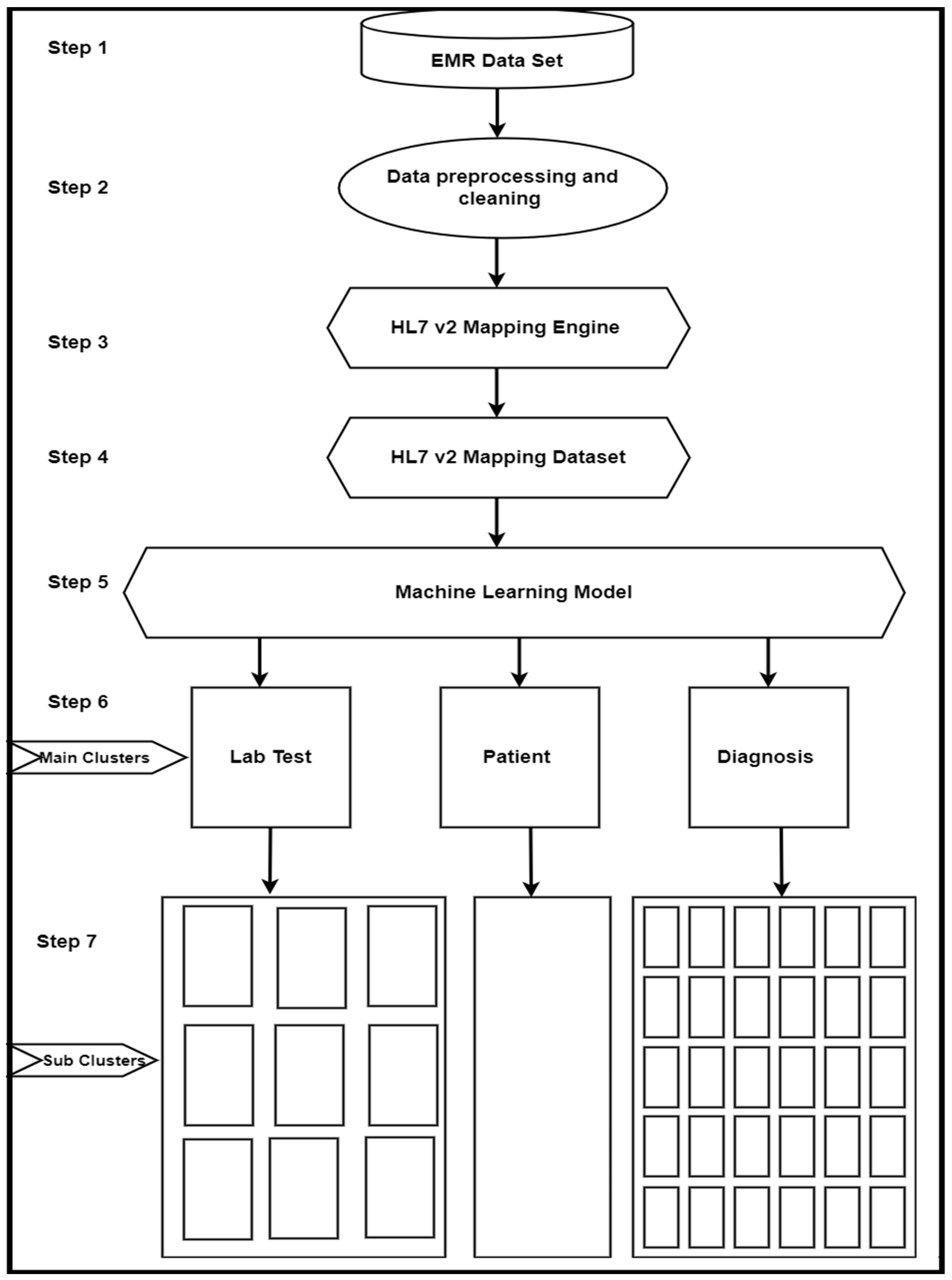
3.1. Framework Architecture
3.2. Methodology
3.2.1. Exploring the Dataset
3.2.2. Preprocessing Data
- (a)
- Data Extraction
- (b)
- Data Cleaning
3.2.3. Dataset Preparation
3.2.4. Algorithm Development
- Handling clusters of multiple sizes and structures (k-mean).
- Picking the correct value of k for clustering.
- Providing the best solutions.
3.2.5. Implementation, Experiments, and Results
3.3. Methodology Details
3.3.1. MIMIC-III Dataset
Dataset Description
3.3.2. Dataset Preprocessing
- (a)
- Data Extraction
- (b)
- Data Cleaning
3.3.3. Dataset Preparation
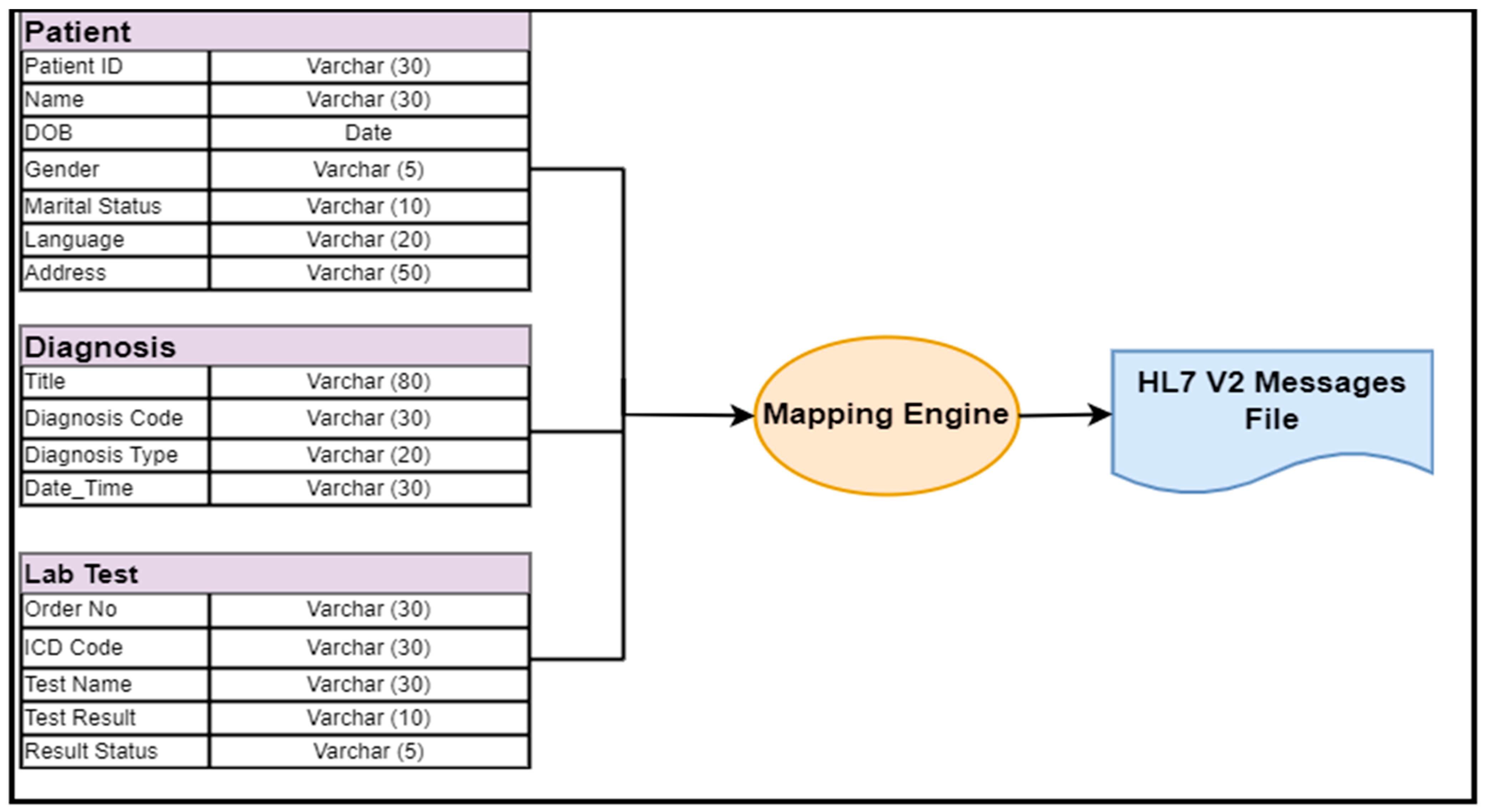
EMR Data Conversion to an HL7 V2 Message Dataset
4. Methods
4.1. Algorithms
| Algorithm 1 Parse HL7 v2 messages |
| 1: Function read_by_chunk (file) 2: Remove empty line from data file (if there is any) 3: Declared a variable name List 4: for each line of the file do 5: if line is not newline then 6: Remove/r from the line and appends to a List 7: else 8: Yield the concatenated List 9: end if 10: end for 11: return List 12: end function **read_by_chunk function** 13: **Read data from HL7 v2 messages segments and fields** 14: Function init_dataframe (file) 15: var File = read_by_chunk (file) 16: while (!EOF) do 17: Read chunk from File 18: Run chunk through HL7 parser 19: extract data from each category 20: create dataframe from the data extracted 21: dataframe.to_csv () // appends dataframe to csv file (resulting file) 22: end while 23: end function **init_dataframe function** |
4.2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- It works on global parameters and is not based on specific parameters.
- The users do not need to predict or specify the number of clusters in advance; hence, it is more realistic than all other clustering algorithms.
- It can identify outliers in the clusters, and the possibility of merging with other clusters exists if they are similar.
- The selection of attributes is always open to improvement in terms of temporal and spatial complexity.
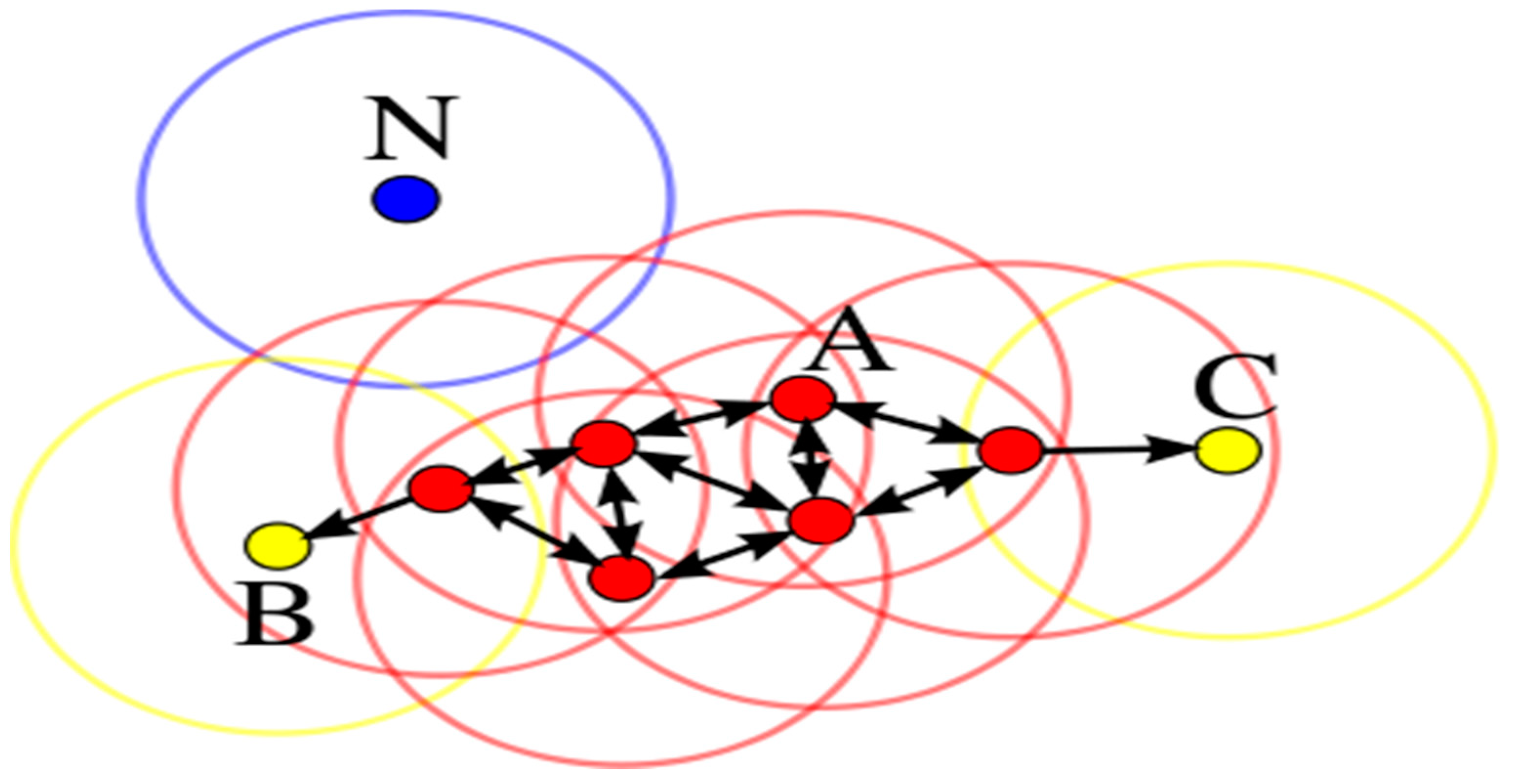
- Cluster: In a database with N given data points, e.g., D = {p1, p2, p3,..., pn,}, the process of splitting database D into smaller parts that follow similar formats, e.g., C = {c1, c2,..., ci}, is called clustering. There are a total of Cj clusters, where Cj ≤ D (j = 1, 2, 3. . . i).
- MinPts: The minimum points needed to form a dense region in a database are called MinPts. In Figure 3, there are a total of 4 MinPts.
- Eps: The Eps defines the radius of the neighborhood around a point “x”. This is called the ϵ-neighborhood of x.
- Neighborhood: A distance function for any two points p and q denoting dists (p, q) is called a neighborhood.
- Eps-neighborhood: The Eps-neighborhood (threshold distance) of a point p is defined by [q ∈ D | dist (p, q) ≤ Eps].
- Core point: A point p is a core point if at least MinPts points are within a distance ∈ of it, and those points are said to be directly reachable from p. In other words, a core point/object is a point in its neighborhood of a given radius (Eps) that has to contain at least a minimum number (MinPts) of other points. In Figure 3, point A and all other red color points are called core points/objects, while points B and C are not core objects.
- Border objects: An object p is called a border object if it is not a core object but a density accessible from another core object. In Figure 3, the green circle is called a border object.
- Noise: The points that are not reachable from any other points are called noise and are assigned to a cluster. In Figure 3, point N in blue is called noise (noise = {p ∈ D | ∀: p ∉ Ci}).
4.3. Algorithm Development
- Eps is a radius representing a neighborhood’s attributes around a particular point (say x).
- MinPts represents the minimum number of neighbors within the “Eps” radius.
| Algorithm 2 Machine learning model |
| 1: Input 2: Set Of Points: The input whole dataset/discovered cluster from the previous run 3: Eps & MinPts: The global density parameters 4: The MinPts is set to default values (5 in our case) 5: Eps is specified by the user (3 in our case) 6: Output 7: Clusters with their core objects and noise points as C = {c1, c2,...,} 8: Various statistics about the dataset, such as gender details, lab test descriptions, diagnosis Information, etc. 9: Method 10: Function Cluster (SetOfPoints, Eps) 11: var List = Read (Dataset) ** Read the dataset and stored in List variable** 12: **Encode the List using one hot encoding and set the encoder to auto** 13: var encode = OneHotEncoder (categories=’auto’) 14: var encode_data = encode.fit.transfered.List [1 :]) .toArray () 15: cluster = DBSCAN (encode_data, eps=eps) ** Clusters the encoded data** 16: Cluster_Split (cluster.labels, List) ** Split the input file according to the clusters* 17: Display all clusters **Display all clusters** 18: Calculate_Statistics () **Calculate various statistics** 19: end function **Cluster function** 20: **The most important function used in this algorithm to split the main cluster to various clus ters is Cluster_Split which is presented below** 21: Function Cluster_Split (clusterLabels, InputFileList) 22: clusters = [1, 2, 3, 4] 23: header = InputFileList[ 0 ] **Ignore the 1st row of input file, i.e., attributes names in input file** 24: InputFileList = InputFileList [1] **Read data from 2nd row of input file** 25: for each line of the clusterLabels do **From 1 to total no of records in input file** 26: if line not in cluster then 27: clusters.append(line) 28: end if 29: end for 30: for i = 1 to range (len (clusters)) do **within the cluster list** 31: with open (’cluster ’+str (i) +’.csv’, ’w’, newline=’’) as file **Create file for each cluster** 32: writer = csv.writer(file) ** initiate the writer for file** 33: writer.writerow(header) **Write the header to the cluster file** 34: for j = 0 to inputfilesize 10000 in range (len(clusterLabels)) do 35: if clusterLabels[ j ] == i then 36: writer.writerow(inputFileList[j]) //Write the data to the cluster 37: end if 38: end for 39: end for 40: end function **Cluster_Split function** 41: **In this algorithm the Calculate_Statistics function is used to calculate various statistics of our dataset, as described below** 42: Function Calculate_Statistics () 43: Open clusters files (csv) directory **Open directory that stored all clusters files** 44: Files_Count = Read (files from directory) 45: ** Run the loops through all .csv files in the directory** 46: while (!EOF) do **Read the Files_Count files** 47: Get cluster file column(s) 48: Calculate the number of entries in each file 49: Calculate each cluster percentage 50: Creates a DataFrame of all percentages and column entries 51: Outputs a .csv file with the DataFrame 52: end while 53: end function **Calulate_Statistics function** |
4.4. Algorithms Development and Analysis
4.5. Data Representation and Processing
4.6. Required Outcomes
5. Experiments, Evaluation Measures, and Results
5.1. Experimental Setup
5.2. Model Evaluation Measures
5.3. Results
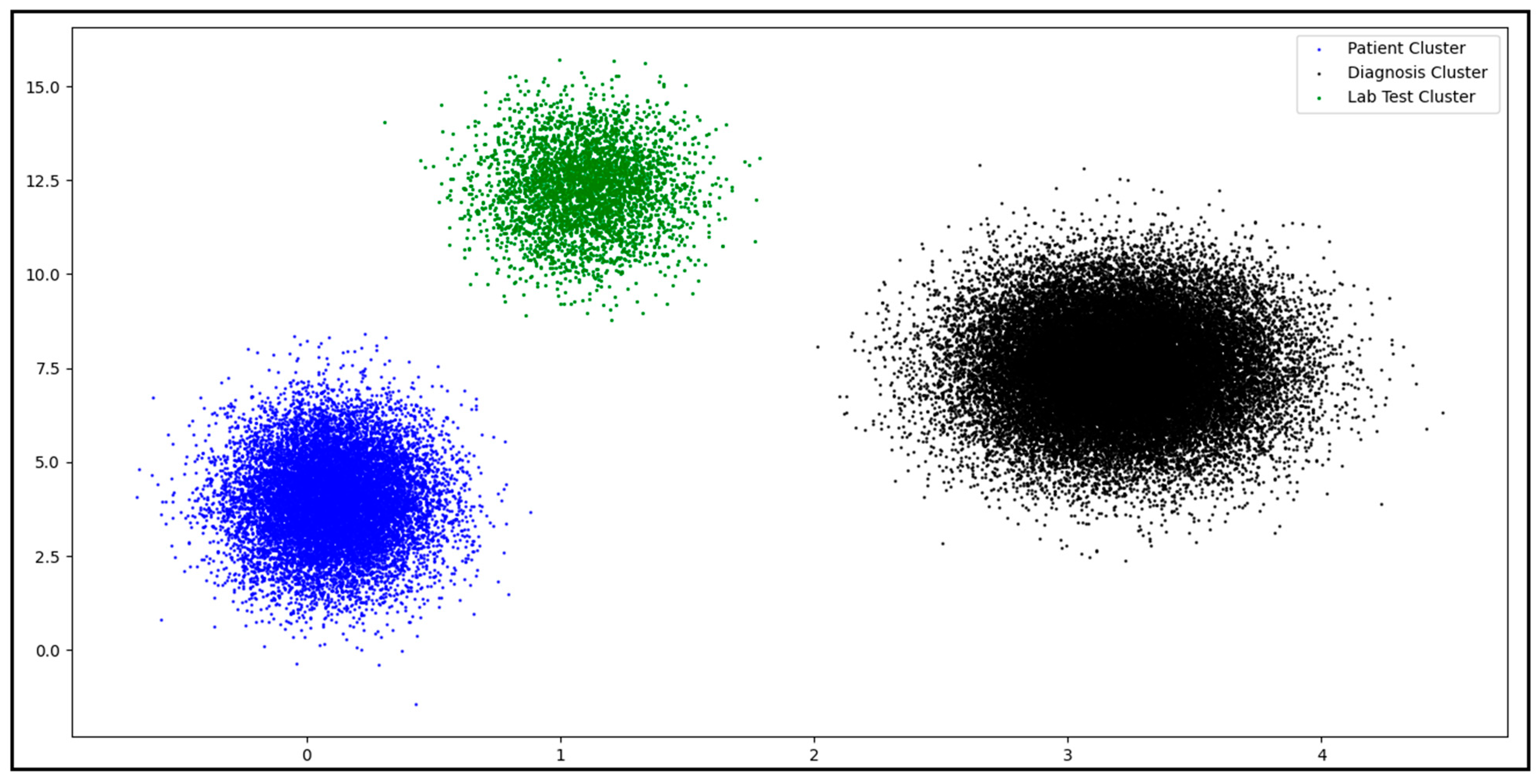
5.3.1. Clustering HL7 V2 Dataset
5.3.2. Dataset Subclustering
- (a)
- Lab Test Clustering Classification
- (b)
- Diagnosis Clustering Classification
5.4. Cohort Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Elgawad, Y.Z.A.; Youssef, M.I.; Nasser, T.M.; Almslmany, A.; Amar, A.S.I.; Mohamed, A.A.; Parchin, N.O.; Abd-Alhameed, R.A.; Mohamed, H.G.; Moussa, K.H. New Method to Implement and Analysis of Medical System in Real Time. Healthcare 2022, 10, 1357. [Google Scholar] [CrossRef]
- Jaleel, A.; Mahmood, T.; Hassan, M.A.; Bano, G.; Khurshid, S.K. Towards Medical Data Interoperability Through Collaboration of Healthcare Devices. IEEE Access 2020, 8, 132302–132319. [Google Scholar] [CrossRef]
- Markle Foundation. Connecting for Health: A public-Private Collaborative. The Data Standards Working Group. 2003. Available online: http://www.connectingforhealth.org/resources/dswg_report_6.5.03.pdf (accessed on 4 March 2010).
- Hersh, W.R. A stimulus to define informatics and health information technology. BMC Med. Inform. Decis. Mak. 2009, 9, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ayaz, M. Cloud Computing Base Electronic Health Record System Architecture for Disabled Children. Int. J. Multidiscip. Sci. Eng. 2017, 8, 24–28. [Google Scholar]
- Brooks, P. Standards and Interoperability in Healthcare Information Systems: Current Status, Problems, and Research Issues. In Proceedings of the Fifth Midwest Association for Information Systems Conference, Moorhead, MN, USA, 21–22 May 2010; p. 18. [Google Scholar]
- Congressional Budget Office. Research on the Comparative Effectiveness of Medical Treatments: Issues and Options for An Expanded Federal Role; The Congress of the United States O Congressional Budget Office: Washington, DC, USA, 2007. [Google Scholar]
- Ayaz, M. A Novel Model of Software Process Improvements for Small and Medium Scale Enterprises by using the Big Data Analytics Approach. Int. J. Multidiscip. Sci. Eng. 2017, 8, 1–10. Available online: www.ijmse.org (accessed on 15 April 2017).
- California Health Care Foundation. Clinical Data Standards in Health Care: Five Case Studies. 2005. Available online: https://www.chcf.org/publication/clinical-data-standards-in-health-care-five-case-studies/ (accessed on 4 March 2010).
- Ayaz, M.; Pasha, M.F.; Alzahrani, M.Y.; Budiarto, R.; Stiawan, D. The Fast Health Interoperability Resources (FHIR) Standard: Systematic Literature Review of Implementations, Applications, Challenges and Opportunities. JMIR Public Health Surveill. 2021, 9, e21929. [Google Scholar] [CrossRef]
- Reisman, M. EHRs: The Challenge of Making Electronic Data Usable and Interoperable. Pharm. Ther. 2017, 42, 572–575. [Google Scholar]
- Ayaz, M. A Seminal Hybrid Business Process Management Model. Int. J. Multidiscip. Sci. Eng. 2017, 8, 38–42. [Google Scholar]
- Breton, M.; Pineault, R.; Levesque, J.-F.; Roberge, D.; Da Silva, R.B.; Prud’Homme, A. Reforming healthcare systems on a locally integrated basis: Is there a potential for increasing collaborations in primary healthcare? BMC Health Serv. Res. 2013, 13, 262. [Google Scholar] [CrossRef] [Green Version]
- Supriya, M.; Deepa, A. Machine learning approach on healthcare big data: A review. Big Data Inf. Anal. 2020, 5, 58–75. [Google Scholar] [CrossRef]
- Cahan, E.M.; Hernandez-Boussard, T.; Thadaney-Israni, S.; Rubin, D.L. Putting the data before the algorithm in big data addressing personalized healthcare. npj Digit. Med. 2019, 2, 78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singal, A.G.; Mukherjee, A.; Elmunzer, B.J.; Higgins, P.D.R.; Lok, A.S.; Zhu, J.; Marrero, J.A.; Waljee, A.K. Machine Learning Algorithms Outperform Conventional Regression Models in Predicting Development of Hepatocellular Carcinoma. Am. J. Gastroenterol. 2013, 108, 1723–1730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef] [Green Version]
- Rabbi, F.; Ayaz, M.; Dayupay, J.P.; Oyebode, O.J.; Gido, N.G.; Adhikari, N.; Tabuena, A.C.; Ajibade, S.-S.M.; Bassey, M.A. Gaussian Map to Improve Firefly Algorithm Performance. In Proceedings of the 2022 IEEE 13th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 23–23 July 2022; pp. 88–92. [Google Scholar] [CrossRef]
- Ajibade, S.-S.M.; Ayaz, M.; Ngo-Hoang, D.-L.; Tabuena, A.C.; Rabbi, F.; Tilaye, G.F.; Bassey, M.A. Analysis of Improved Evolutionary Algorithms Using Students’ Datasets. In Proceedings of the 2022 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Shah Alam, Malaysia, 25 June 2022; pp. 180–185. [Google Scholar] [CrossRef]
- Goldstein, B.A.; Navar, A.M.; Pencina, M.J.; Ioannidis, J.P.A. Opportunities and challenges in developing risk prediction models with electronic health records data: A systematic review. J. Am. Med. Inform. Assoc. 2016, 24, 198–208. [Google Scholar] [CrossRef] [Green Version]
- Alouffi, B.; Hasnain, M.; Alharbi, A.; Alosaimi, W.; Alyami, H.; Ayaz, M. A Systematic Literature Review on Cloud Computing Security: Threats and Mitigation Strategies. IEEE Access 2021, 9, 57792–57807. [Google Scholar] [CrossRef]
- Wong, J.; Horwitz, M.M.; Zhou, L.; Toh, S. Using Machine Learning to Identify Health Outcomes from Electronic Health Record Data. Curr. Epidemiol. Rep. 2018, 5, 331–342. [Google Scholar] [CrossRef]
- Adkins, D.E. Machine Learning and Electronic Health Records: A Paradigm Shift. Am. J. Psychiatry 2017, 174, 93–94. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Lütz, E. Unsupervised machine learning to detect patient subgroups in electronic health records. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2019. [Google Scholar]
- Yan, J.; Linn, K.A.; Powers, B.W.; Zhu, J.; Jain, S.H.; Kowalski, J.L.; Navathe, A.S. Applying Machine Learning Algorithms to Segment High-Cost Patient Populations. J. Gen. Intern. Med. 2018, 34, 211–217. [Google Scholar] [CrossRef] [Green Version]
- Goga, N. Problems and Solutions for Interoperability of Medical Devices. IFAC Proc. Vol. 2007, 40, 187–194. [Google Scholar] [CrossRef]
- What are HL7 FHIR and openEHR. Available online: https://medrecord.io/what-are-hl7-fhir-and-openehr/ (accessed on 15 April 2017).
- Pedrera-Jiménez, M.; Kalra, D.; Beale, T.; Muñoz-Carrero, A.; Serrano-Balazote, P. Can OpenEHR, ISO 13606 and HL7 FHIR work together? An agnostic perspective for the selection and application of EHR standards from Spain. TechRxiv 2022. [Google Scholar] [CrossRef]
- Nachimuthu, S.K.; Lau, L.M. Practical issues in using SNOMED CT as a reference terminology. Stud. Health Technol. Inform. 2007, 129, 640. [Google Scholar] [PubMed]
- Merlin, J.K. Performance analysis of clustering algorithms on heart dataset. Int. J. Modern Comput. Sci. 2016, 5, 113–117. [Google Scholar]
- Nithya, R.; Manikandan, P.; Ramyachitra, D. Analysis of clustering technique for the diabetes dataset using the training set parameter. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 166–169. [Google Scholar] [CrossRef]
- Bruno, G.; Cerquitelli, T.; Chiusano, S.; Xiao, X. A Clustering-Based Approach to Analyse Examinations for Diabetic Patients. In Proceedings of the 2014 IEEE International Conference on Healthcare Informatics, Verona, Italy, 15–17 September 2014; pp. 45–50. [Google Scholar] [CrossRef]
- Paul, R.; Hoque, A.S.M.L. Clustering medical data to predict the likelihood of diseases. In Proceedings of the 2010 Fifth International Conference on Digital Information Management (ICDIM), Thunder Bay, ON, Canada, 5–8 July 2010; pp. 44–49. [Google Scholar] [CrossRef]
- Belciug, S. Patients length of stay grouping using the hierarchical clustering algorithm. Ann. Math. Comp. Sci. Ser 2009, 36, 79–84. Available online: http://inf.ucv.ro/~ami/index.php/ami/article/viewFile/288/279 (accessed on 15 April 2017).
- Belciug, S.; Salem, A.-B.; Gorunescu, F.; Gorunescu, M. Clustering-based approach for detecting breast cancer recurrence. In Proceedings of the 2010 10th International Conference on Intelligent Systems Design and Applications, Cairo, Egypt, 29 November–1 December 2010; pp. 533–538. [Google Scholar] [CrossRef]
- Lopez, C.; Tucker, S.; Salameh, T.; Tucker, C. An unsupervised machine learning method for discovering patient clusters based on genetic signatures. J. Biomed. Inform. 2018, 85, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Alashwal, H.; El Halaby, M.; Crouse, J.J.; Abdalla, A.; Moustafa, A.A. The Application of Unsupervised Clustering Methods to Alzheimer’s Disease. Front. Comput. Neurosci. 2019, 13, 31. [Google Scholar] [CrossRef]
- Estiri, H.; Klann, J.G.; Murphy, S.N. A clustering approach for detecting implausible observation values in electronic health records data. BMC Med. Inform. Decis. Mak. 2019, 19, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shea, A. Patient Clustering using Electronic Medical Records. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2020. [Google Scholar]
- Zhong, H.; Loukides, G.; Gwadera, R. Clustering datasets with demographics and diagnosis codes. J. Biomed. Inform. 2020, 102, 103360. [Google Scholar] [CrossRef]
- Elmisery, A.M.; Fu, H. Privacy Preserving Distributed Learning Clustering of HealthCare Data Using Cryptography Protocols. In Proceedings of the 2010 IEEE 34th Annual Computer Software and Applications Conference Workshops, Seoul, Republic of Korea, 19–23 July 2010; pp. 140–145. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Alshebami, A.; Alzahrani, M.Y. Soft Clustering for Enhancing the Diagnosis of Chronic Diseases over Machine Learning Algorithms. J. Health Eng. 2020, 2020, 4984967. [Google Scholar] [CrossRef]
- Elbattah, M.; Molloy, O. Clustering-aided approach for predicting patient outcomes with application to elderly healthcare in Ireland. AAAI Work.-Tech. Rep. 2017, WS-17-01, 533–541. [Google Scholar]
- Alsayat, A.; El-Sayed, H. Efficient genetic K-Means clustering for health care knowledge discovery. In Proceedings of the 2016 IEEE 14th International Conference on Software Engineering Research, Management and Applications (SERA), Towson, MD, USA, 8–10 June 2016; pp. 45–52. [Google Scholar] [CrossRef]
- Ogbuabor, G.; Ugwoke, F.N. Clustering Algorithm for a Healthcare Dataset Using Silhouette Score Value. Int. J. Comput. Sci. Inf. Technol. 2018, 10, 27–37. [Google Scholar] [CrossRef]
- Bose, E.; Radhakrishnan, K. Using Unsupervised Machine Learning to Identify Subgroups Among Home Health Patients With Heart Failure Using Telehealth. CIN Comput. Inform. Nurs. 2018, 36, 242–248. [Google Scholar] [CrossRef]
- Singh, S.P.; Karkare, S.; Baswan, S.M.; Singh, V.P. Agglomerative hierarchical clustering analysis of co/multi-morbidities. arXiv 2018, arXiv:1807.04325. [Google Scholar]
- Ambigavathi, M.; Sridharan, D. Analysis of Clustering Algorithms in Machine Learning for Healthcare Data. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Valletta, Malta, 24–25 April 2020; pp. 117–128. [Google Scholar] [CrossRef]
- Hurst, W.; Boddy, A.; Merabti, M.; Shone, N. Patient Privacy Violation Detection in Healthcare Critical Infrastructures: An Investigation Using Density-Based Benchmarking. Future Internet 2020, 12, 100. [Google Scholar] [CrossRef]
- Pasin, Ö.; Ankarali, H. Usage of Kernel K-Means and DBSCAN cluster algorıthms in health studies: An application. Clin. Res. Trials 2015, 1, 63–69. [Google Scholar] [CrossRef]
- Celebi, M.; Aslandogan, Y.; Bergstresser, P. Mining biomedical images with density-based clustering. In Proceedings of the International Conference on Information Technology: Coding and Computing (ITCC′05)-Volume II, Washington, DC, USA, 4–6 April 2005; Volume 1, pp. 163–168. [Google Scholar] [CrossRef]
- Hou, J.; Gao, H.; Li, X. DSets-DBSCAN: A Parameter-Free. IEEE Trans. Image Process. 2016, 25, 3182–3193. [Google Scholar] [CrossRef]
- Schulz, L.O.; Chaudhari, L.S. High-Risk Populations: The Pimas of Arizona and Mexico. Curr. Obes. Rep. 2015, 4, 92–98. [Google Scholar] [CrossRef] [Green Version]
- Ten Best Healthcare Data Sets with Examples. Available online: https://cprimestudios.com/blog/10-best-healthcare-data-sets-examples (accessed on 15 April 2017).
- MIMIC-III, a Freely Accessible Critical Care Database. Available online: https://www.nature.com/articles/sdata201635 (accessed on 15 April 2017).
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef]
- Available online: https://evanwill.github.io/openrefine-b/content/0-refine.html (accessed on 15 April 2017).
- Available online: https://www.vconnexservices.com/mirth-connect-best-hl7-interface-engine.html (accessed on 15 April 2017).
- Hemalatha, M.; Saranya, N.N. A Recent Survey on Knowledge Discovery in Spatial Data Mining. Int. J. Comput. Sci. Issues 2011, 8, 473–479. [Google Scholar]
- Zhou, A.; Zhou, S.; Cao, J.; Fan, Y.; Hu, Y. Approaches for scaling DBSCAN algorithm to large spatial databases. J. Comput. Sci. Technol. 2000, 15, 509–526. [Google Scholar] [CrossRef]
- Sharma, A.; Gupta, R.K.; Tiwari, A. Improved Density Based Spatial Clustering of Applications of Noise Clustering Algorithm for Knowledge Discovery in Spatial Data. Math. Probl. Eng. 2016, 2016, 1564516. [Google Scholar] [CrossRef]
- Zaiane, O.; Lee, C.-H. Clustering spatial data in the presence of obstacles: A density-based approach. In Proceedings of the International Database Engineering and Applications Symposium, Hong Kong, China, 16–18 July 2003. [Google Scholar] [CrossRef] [Green Version]
- Daszykowski, M.; Walczak, B. Density-Based Clustering Methods. In Chemistry, Molecular Sciences and Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2009; Volume 2, pp. 635–654. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSH|^~\&|MIRTH_CONNECT|Brown-HOSPITAL|RECEIVINGAPP|Blue-HOSPITAL|20211002035037||ADT^A04^ADT_A01|11742|T|2.5||||||||| EVN|A01|20211002035037||||| PID|||639B5FFC-B9E3-4C8D-8F62-BABE52E4F3B9||Irma^Cook||19920308|F|||3789 Dancing Dove Lane^^New York^New York^10013^US||347-594-6300^PRN^^~IrmaSCook@fleckens.hu^NET^^|||||||||||||||||||||||||| PV1|1|I|4E^IS^Lab^Brown Hospital||||Dr.John||||||||||||||||||||||||||||||||||||||||||||| AL1|1||PENICILLIN||PRODUCES HIVES~RASH|| DG1||I10|S82^ANKLE FRACTURE^I10|ANKLE FRACTURE|||||||||||||||||||||||||||||||| MSH|^~\&|SendingLabX-RayLab|Brown-HOSPITAL|RECEIVINGLab:LISLab|Blue-HOSPITAL|20211002043236||ORU^R01^ORU_R01|4084|T|2.5||||||||| PID|||639B5FFC-B9E3-4C8D-8F62-BABE52E4F3B9||Irma^Cook||19920308|F|||3789 Dancing Dove Lane^^New York^New York^10013^US||347-594-6300^PRN^^~IrmaSCook@fleckens.hu^NET^^|||||||||||||||||||||||||| ORC|NW|987654^EPIC|76543^EPC||Final||^^^20140418170014^^^^||20140418173314|1148^PATTERSON^JAMES^^^^||1173^MATTHEWS^JAMES^A^^^|1133^^^222^^^^^|(618)222-1122|| OBR|1||Order_NO_01|10180-8^METABOLIC:ALT/SGPT^LN||||20211002043236||||||||D001^DR.^Rivera^Charles||||||||||||||||||||||||||||||||| OBX|1|SN|14647-2^METABOLIC: CHLORIDE^I10 ||101.8|mmol/L|||||F|||199203141030|||||| OBX|2|NM|13457-7^Fasting Blood Glucose^I10||178|mg/dl|70-100 mg/dl|H|||F| ||199707281152|||||| |
| PID | DOB | Sex | Race | Primary Language | Marital Status | Test Name | Test Result | Unit of Measure | Collection Date and Time | Visit No | Diagnosis Code | Diagnosis Description |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2F78B50C-103A-427A-A75C-29A789501678 | 197512101450 | Male | Asian | English | Married | |||||||
| 915BC24E-8C44-4D33-A386-CEA965B83F32 | METABOLIC: ALT/SGPT | 17.8 | U/L | 194611261152 | ||||||||
| ED06DB81-3D87-4206-9A5B-65AD89E65267 | 1 | D20.0 | Benign neoplasm of soft tissue of the retroperitoneum | |||||||||
| 639B5FFC-B9E3-4C8D-8F62-BABE52E4F3B9 | METABOLIC: BILI TOTAL | 1 | mg/dL | 194902161152 | ||||||||
| AC6F9199-ACF0-4A45-924B-ECE5D3843A56 | 1 | M63.872 | Disorders of muscle in diseases classified elsewhere—left ankle and foot | |||||||||
| 108B06ED-347B-496F-AB3E-3D0F42906C69 | 197512121450 | Female | White | English | Married | |||||||
| A6ADB61A-6993-4D14-93C9-B3D46014C114 | CBC: WHITE BLOOD CELL COUNT | 8.6 | k/cumm | 196212231152 | ||||||||
| 98CC2D50-B848-48D1-8C63-2A7C2761FE59 | 1 | D43.3 | Neoplasm of uncertain behavior of the cranial nerves | |||||||||
| F4A580D8-E8C0-4432-B485-E1EED456118B | 197512191450 | Female | White | English | Separated | |||||||
| 3AB69ECE-65F4-4D04-9E87-54E73C2DB4A8 | 1 | C40.31 | Malignant neoplasm of short bones of the right lower limb | |||||||||
| 4DD3728F-0C48-43B7-B488-421C85A5E931 | METABOLIC: CHLORIDE | 98 | mmol/L | 199603211152 | ||||||||
| DF598997-15DE-4658-A4D4-48A4ABA08179 | 197512301450 | Male | White | Spanish | Single | |||||||
| 43556DC2-BCFC-45A8-84C3-1D3E4A11B02F | 1 | G31.83 | Dementia with Lewy bodies | |||||||||
| ED64D34E-8945-4073-871D-4B9AC166B0CD | CBC: MCHC | 36.1 | g/dL | 203909191152 | ||||||||
| 32EB8347-A355-4E49-A551-41C4DE28436A | Male | African American | Unknown | Divorced |
| Matric | Formula |
|---|---|
| Precision (P) | TP/(TP + FP) |
| Recall (R) | TP/(TP + FN) |
| F1-Score | 2 × (P×R)/(P + R) |
| Accuracy | (TP + TN)/(TP + TN + FP + FN) |
| No. of Clusters | Cluster Statistics | Execution Time in Seconds | Unclustered Instances | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | ||
|---|---|---|---|---|---|---|---|---|---|
| 3 | Clusters | No. of instances | Instances (%) | 51.4 | 27 | 99.95 | 98.41 | 99.31 | 98.93 |
| Cluster 0 | 3515 | 6.58 | |||||||
| Cluster 1 | 13743 | 25.74 | |||||||
| Cluster 2 | 36125 | 67.67 | |||||||
| No. of Clusters | Cluster Statistics | Execution Time in Seconds | Unclustered Instances | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | ||
|---|---|---|---|---|---|---|---|---|---|
| 9 | Clusters | No. of instances | Instances (%) | 0.4 | 13 | 99.63 | 99.12 | 98.91 | 98.72 |
| Cluster 0 | 390 | 11.13 | |||||||
| Cluster 1 | 289 | 8.24 | |||||||
| Cluster 2 | 105 | 2.99 | |||||||
| Cluster 3 | 527 | 15.03 | |||||||
| Cluster 4 | 1810 | 51.65 | |||||||
| Cluster 5 | 100 | 2.85 | |||||||
| Cluster 6 | 104 | 2.96 | |||||||
| Cluster 7 | 87 | 2.38 | |||||||
| Cluster 8 | 92 | 2.62 | |||||||
| No. of Clusters | Cluster Statistics | Execution Time in Seconds | Unclustered Instances | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | ||
|---|---|---|---|---|---|---|---|---|---|
| 2854 | Clusters | No. of instances | Instances (%) | 12.8 | 433 | 98.80 | 98.31 | 97.91 | 98.17 |
| Cluster 0 | 7 | 0.0192 | |||||||
| Cluster 1 | 12 | 0.0332 | |||||||
| Cluster 2 | 19 | 0.0526 | |||||||
| Cluster 3 | 11 | 0.0304 | |||||||
| Cluster 4 | 14 | 0.0387 | |||||||
| Cluster 5 | 19 | 0.0526 | |||||||
| Cluster 6 | 17 | 0.0470 | |||||||
| Cluster 7 | 10 | 0.0277 | |||||||
| Cluster 8 | 18 | 0.0498 | |||||||
| Cluster 9 | 12 | 0.0332 | |||||||
| Cluster 10 | 16 | 0.0443 | |||||||
| Cluster 11 | 13 | 0.0359 | |||||||
| ……… | ……… | ……… | |||||||
| ……… | ……… | ……… | |||||||
| Cluster 2854 | 2714 | 7.5084 | |||||||
| Gender | Total | Gender (%) | Marital Status | Total | Marital Status (%) | Race | Total | Race Percentage (%) |
|---|---|---|---|---|---|---|---|---|
| Male | 6609 | 48.08291 | Single | 4356 | 31.6841 | White | 6726 | 48.9252 |
| Female | 7136 | 51.9179 | Married | 6203 | 45.1190 | African American | 2059 | 14.9768 |
| Divorced | 1552 | 11.2882 | Asian | 3172 | 23.0722 | |||
| Separated | 685 | 4.9821 | Unknown | 1788 | 13.0051 | |||
| Widowed | 133 | 0.9672 | ||||||
| Unknown | 816 | 5.9353 |
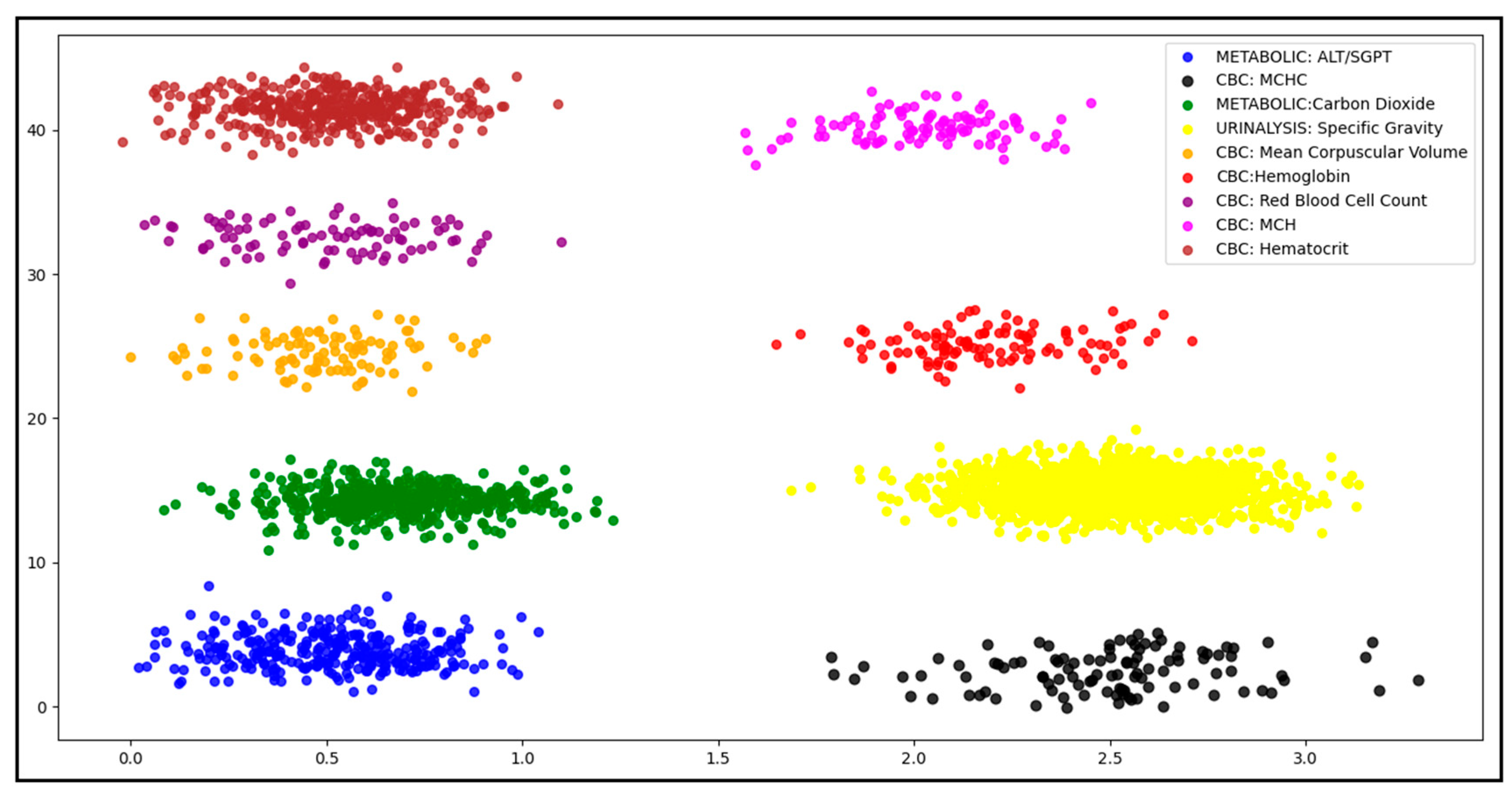
| No. | Test Name | No. of Tests | Tests Percentage (%) |
|---|---|---|---|
| 1 | CBC: Hematocrit/RDW/Absolute Neutrophils/Absolute Lymphocytes | 394 | 11.2027 |
| 2 | METABOLIC: ALT/SGPT/ALK PHOS | 289 | 8.2172 |
| 3 | CBC: MCHC | 105 | 2.9854 |
| 4 | METABOLIC: Carbon Dioxide/Anion Gap/Sodium/Chloride/Potassium | 527 | 14.9843 |
| 5 | CBC: Mean corpuscular volume | 100 | 2.8433 |
| 6 | CBC: Hemoglobin METABOLIC: Albumin/Total protein | 104 | 2.9570 |
| 7 | CBC: Red blood cell count | 87 | 2.4736 |
| 8 | CBC: MCH | 95 | 2.7011 |
| 9 | URINALYSIS: Specific Gravity/PH | 1817 | 51.5311 |
| No. | Diagnosis Code | Diagnosis Description | No. of Diagnosis | Diagnosis Percentage (%) |
|---|---|---|---|---|
| 1 | F98.21 | Rumination disorder of infancy | 7 | 0.0192 |
| 2 | G31.83 | Dementia with Lewy bodies | 12 | 0.0332 |
| 3 | O9A.12 | Malignant neoplasm complicating childbirth | 19 | 0.0526 |
| 4 | D89.81 | Malignant neoplasm of the bladder neck | 11 | 0.0304 |
| 5 | M84.561 | Pathological fracture in neoplastic disease, right tibia | 14 | 0.0387 |
| 6 | G52.3 | Disorders of the hypoglossal nerve | 19 | 0.0526 |
| 7 | C40.31 | Malignant neoplasm of the short bones of the right lower limb | 17 | 0.0470 |
| 8 | C67.5 | Malignant neoplasm of the bladder neck | 10 | 0.0277 |
| 9 | O98.612 | Protozoal diseases complicating pregnancy | 18 | 0.0498 |
| 10 | Z13.85 | Encounter for screening for nervous system disorders | 12 | 0.0332 |
| 11 | Y71 | Cardiovascular devices associated with adverse incidents | 16 | 0.0443 |
| 12 | C79.82 | Secondary malignant neoplasm of the genital organs | 13 | 0.0359 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayaz, M.; Pasha, M.F.; Le, T.Y.; Alahmadi, T.J.; Abdullah, N.N.B.; Alhababi, Z.A. A Framework for Automatic Clustering of EHR Messages Using a Spatial Clustering Approach. Healthcare 2023, 11, 390. https://doi.org/10.3390/healthcare11030390
Ayaz M, Pasha MF, Le TY, Alahmadi TJ, Abdullah NNB, Alhababi ZA. A Framework for Automatic Clustering of EHR Messages Using a Spatial Clustering Approach. Healthcare. 2023; 11(3):390. https://doi.org/10.3390/healthcare11030390
Chicago/Turabian StyleAyaz, Muhammad, Muhammad Fermi Pasha, Tham Yu Le, Tahani Jaser Alahmadi, Nik Nailah Binti Abdullah, and Zaid Ali Alhababi. 2023. "A Framework for Automatic Clustering of EHR Messages Using a Spatial Clustering Approach" Healthcare 11, no. 3: 390. https://doi.org/10.3390/healthcare11030390