
Ensemble Learning for Disease Prediction: A Review



Abstract
:1. Introduction
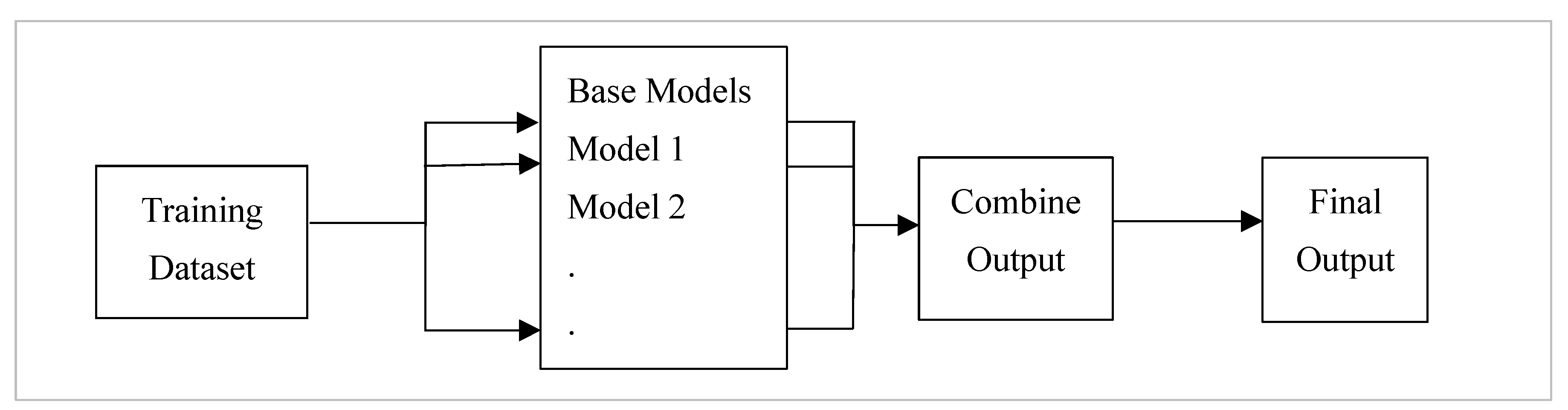
2. Ensemble Learning
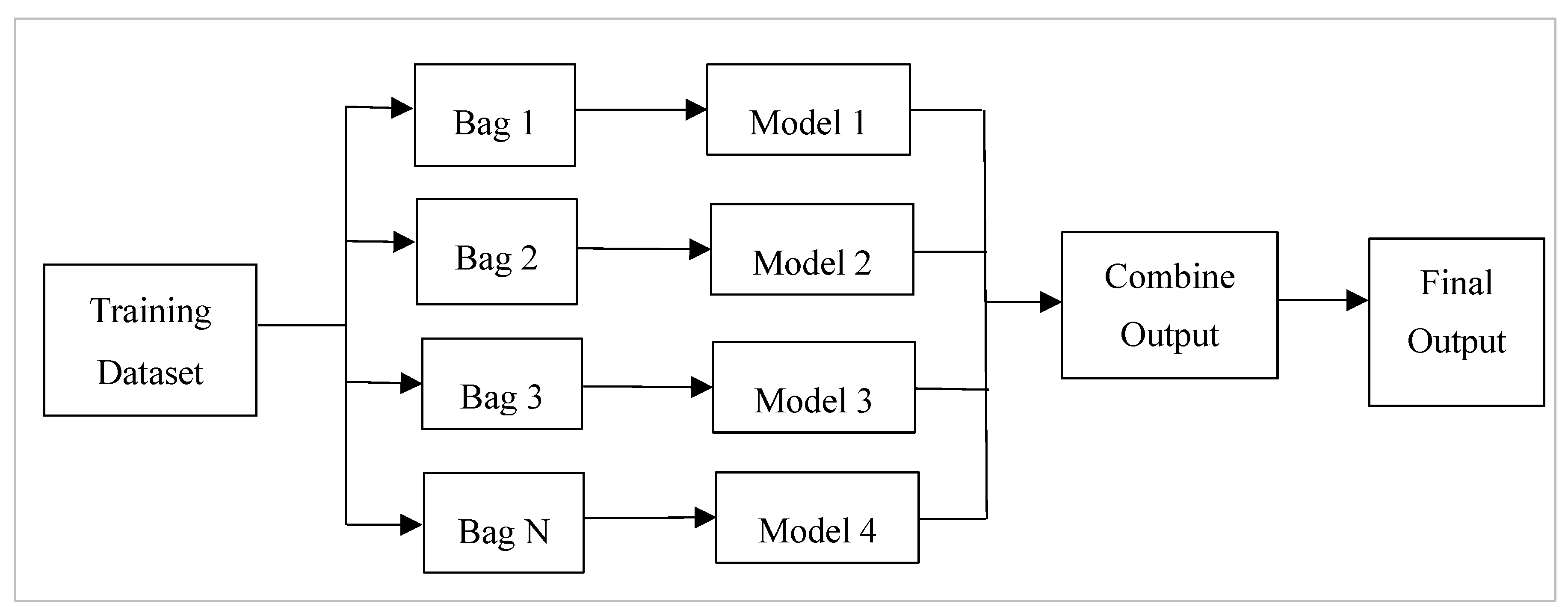
2.1. Bagging
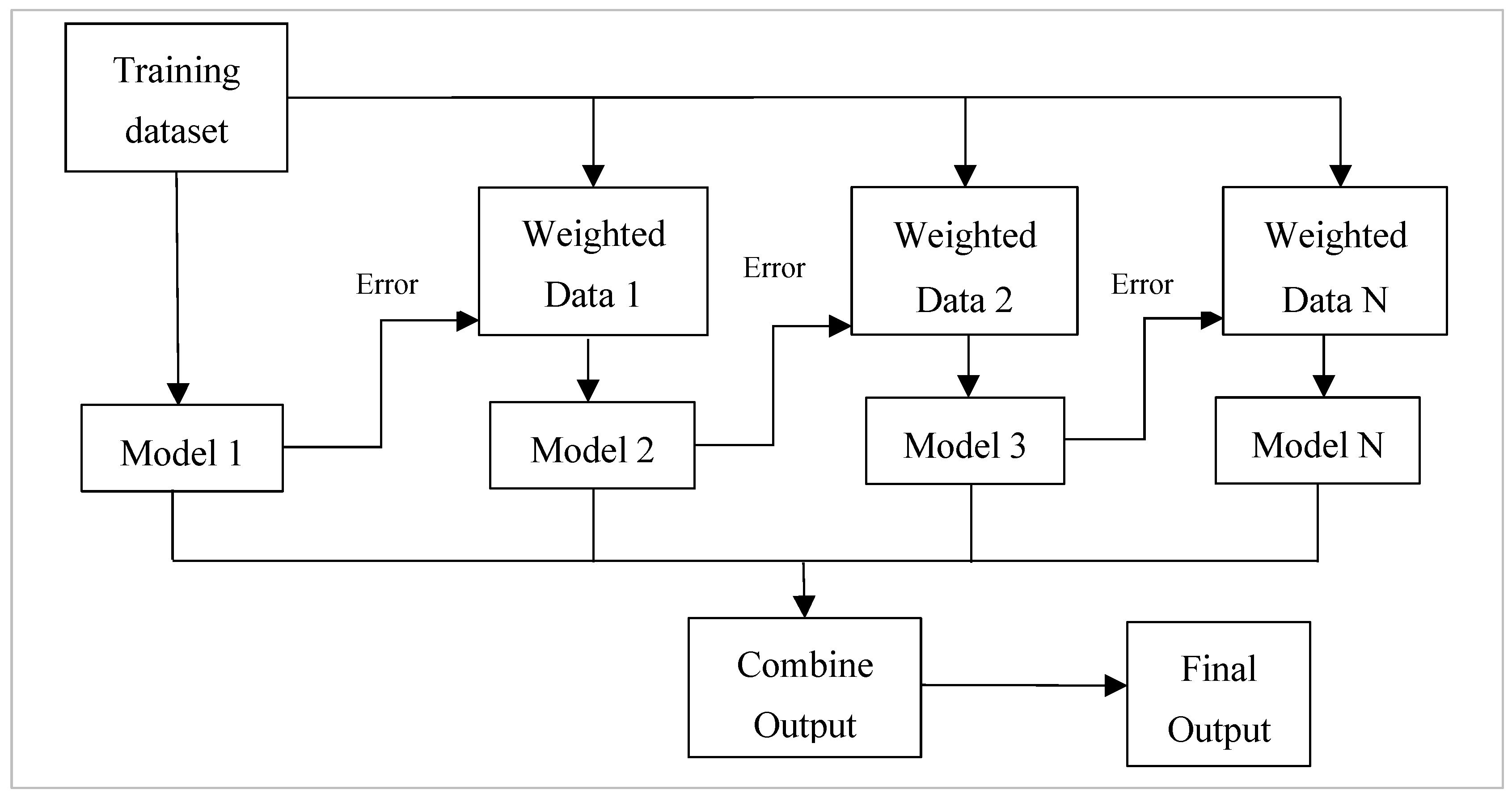
2.2. Boosting
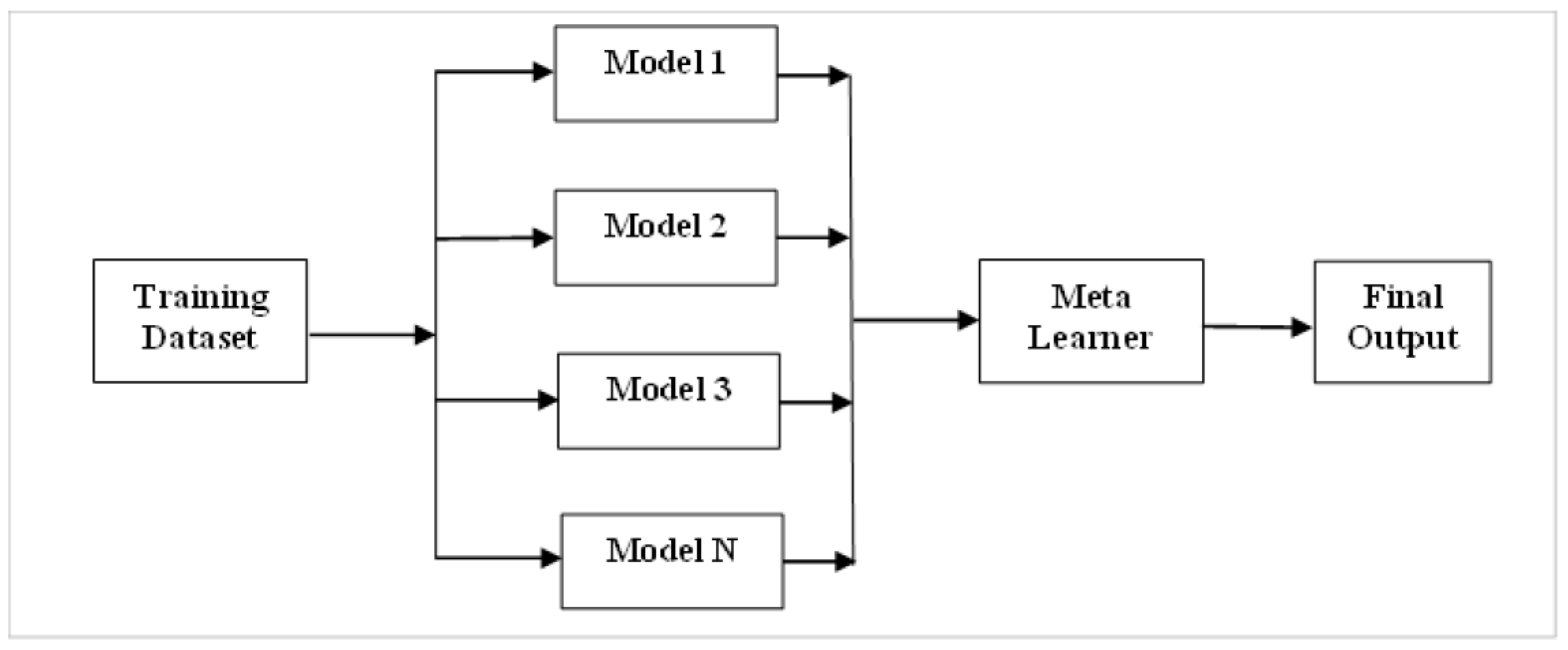
2.3. Stacking
2.4. Voting
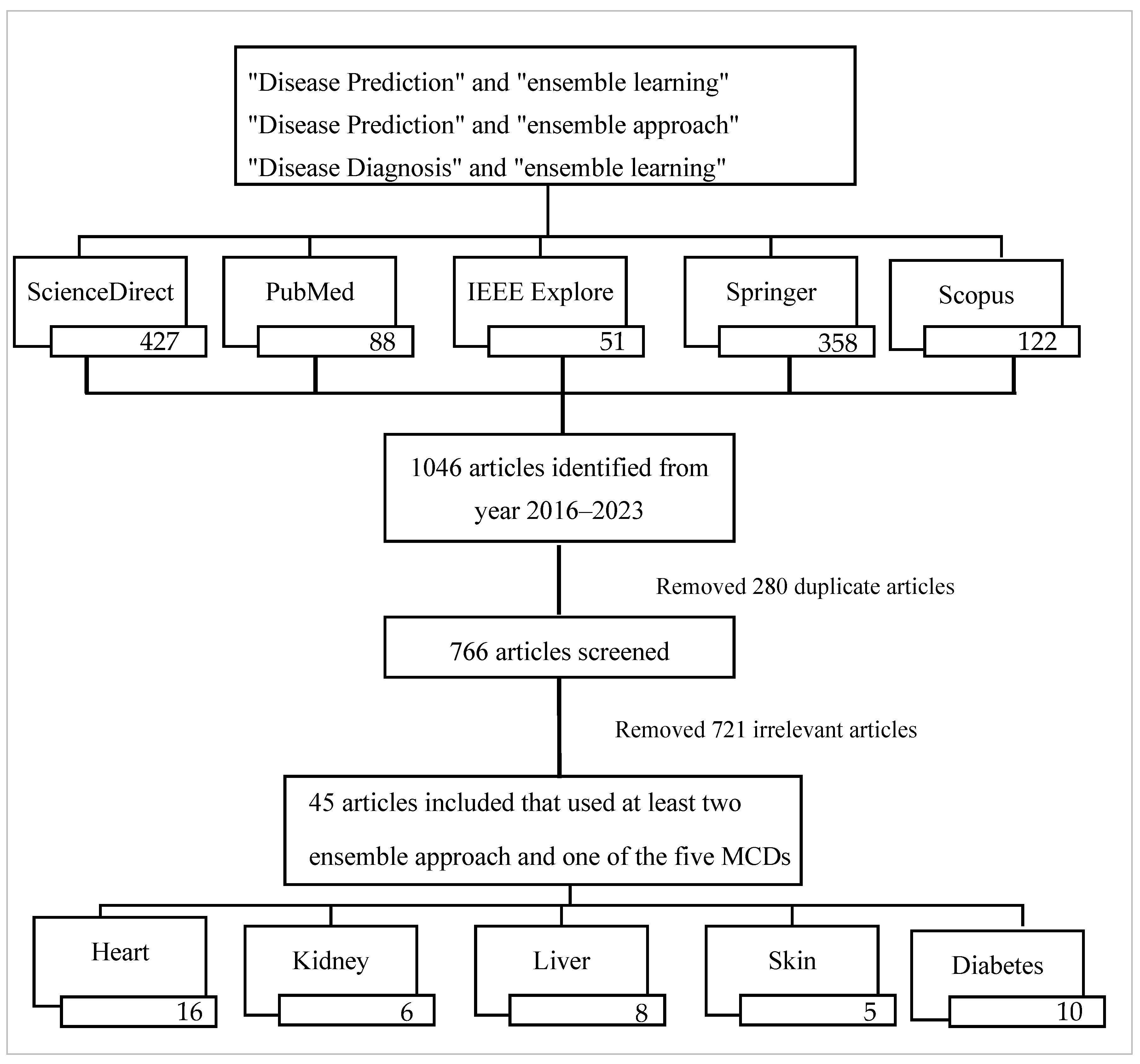
3. Methods
- “Disease prediction” and “ensemble method”
- “Disease prediction” and “ensemble machine learning”
- “Disease diagnosis” and “ensemble machine learning”
- “Disease diagnosis” and “ensemble learning”
4. Results
4.1. Advantages and Limitations
4.2. Frequency and Accuracy Comparison
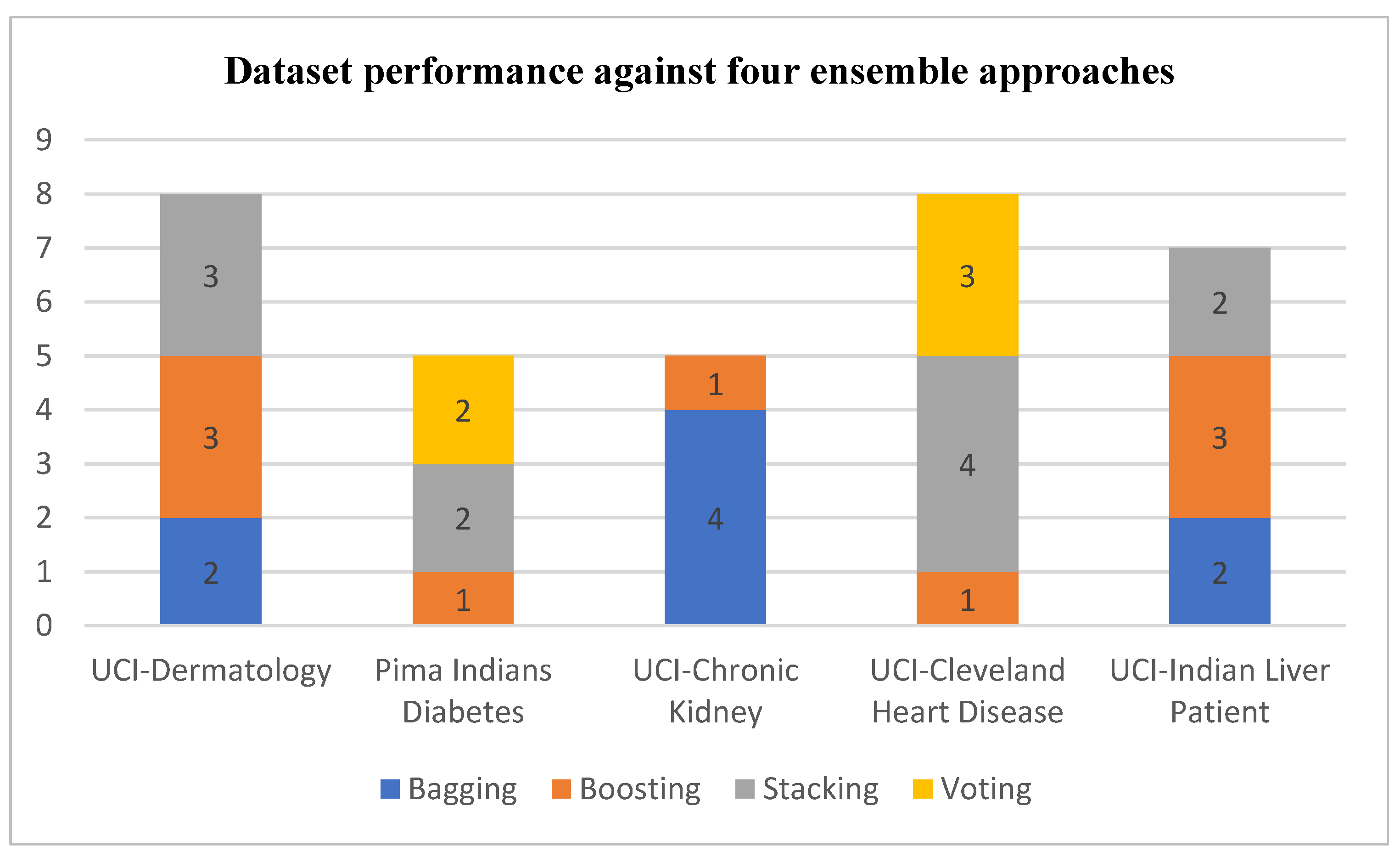
4.3. Ensemble Performance against Datasets
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Networks |
| CART | Classification and Regression Tree |
| CAFL | Chaos Firefly Attribute Reduction and Fuzzy Logic |
| DT | Decision Tree |
| DS | Data Science |
| ETC | Extra Tree Classifier |
| GBC | Gradient Boosting Classifier |
| G-NB | Gaussian Naive Bayes |
| KFUH | King Fahad University Hospital |
| KNN | K-Nearest Neighbour |
| LR | Logistic Regression |
| LDA | Linear Discriminant Analysis |
| MLP | Multilayer Perceptron |
| MLR | Multi-linear Response |
| NB | Naive Bayes |
| NHANES | National Health and Nutrition Examination Survey |
| NN | Neural Network |
| PART | Projective Adaptive Resonance Theory |
| PCA | Principal Component Analysis |
| QDA | Quadratic Discriminant Analysis |
| RF | Random Forest |
| SCRL | Spatially Consistent Representation Learning |
| SGD | Stochastic Gradient Classifier |
| SMO | Sequential Minimal Optimisation |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVC | Support Vector Classifier |
| SVM | Support Vector Machine |
References
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; De Silva, S. Deep learning ensemble methods for skin lesion analysis towards melanoma detection. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 311–316. [Google Scholar]
- Zubair Hasan, K.; Hasan, Z. Performance evaluation of ensemble-based machine learning techniques for prediction of chronic kidney disease. In Emerging Research in Computing, Information, Communication and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 415–426. [Google Scholar]
- Nahar, N.; Ara, F.; Neloy, M.A.I.; Barua, V.; Hossain, M.S.; Andersson, K. A comparative analysis of the ensemble method for liver disease prediction. In Proceedings of the 2019 2nd International Conference on Innovation in Engineering and Technology (ICIET), Dhaka, Bangladesh, 23–24 December 2019; pp. 1–6. [Google Scholar]
- Lakshmanarao, A.; Srisaila, A.; Kiran, T.S.R. Heart disease prediction using feature selection and ensemble learning techniques. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 994–998. [Google Scholar]
- Shorewala, V. Early detection of coronary heart disease using ensemble techniques. Inform. Med. Unlocked 2021, 26, 100655. [Google Scholar] [CrossRef]
- Kumari, S.; Kumar, D.; Mittal, M. An ensemble approach for classification and prediction of diabetes mellitus using soft voting classifier. Int. J. Cogn. Comput. Eng. 2021, 2, 40–46. [Google Scholar] [CrossRef]
- Latha, C.B.C.; Jeeva, S.C. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 2019, 16, 100203. [Google Scholar] [CrossRef]
- Igodan, E.C.; Thompson, A.F.-B.; Obe, O.; Owolafe, O. Erythemato Squamous Disease Prediction using Ensemble Multi-Feature Selection Approach. Int. J. Comput. Sci. Inf. Secur. IJCSIS 2022, 20, 95–106. [Google Scholar]
- Tanuku, S.R.; Kumar, A.A.; Somaraju, S.R.; Dattuluri, R.; Reddy, M.V.K.; Jain, S. Liver Disease Prediction Using Ensemble Technique. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; pp. 1522–1525. [Google Scholar]
- Ramesh, D.; Katheria, Y.S. Ensemble method based predictive model for analyzing disease datasets: A predictive analysis approach. Health Technol. 2019, 9, 533–545. [Google Scholar] [CrossRef]
- Sisodia, D.S.; Verma, A. Prediction performance of individual and ensemble learners for chronic kidney disease. In Proceedings of the 2017 International Conference on Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 1027–1031. [Google Scholar]
- Jongbo, O.A.; Adetunmbi, A.O.; Ogunrinde, R.B.; Badeji-Ajisafe, B. Development of an ensemble approach to chronic kidney disease diagnosis. Sci. Afr. 2020, 8, e00456. [Google Scholar] [CrossRef]
- Basar, M.D.; Akan, A. Detection of chronic kidney disease by using ensemble classifiers. In Proceedings of the 2017 10th international conference on electrical and electronics engineering (ELECO), Bursa, Turkey, 30 November–2 December 2017; pp. 544–547. [Google Scholar]
- Muflikhah, L.; Widodo, N.; Mahmudy, W.F. Prediction of Liver Cancer Based on DNA Sequence Using Ensemble Method. In Proceedings of the 2020 3rd International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 10–11 December 2020; pp. 37–41. [Google Scholar]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Verma, A.K.; Pal, S.; Kumar, S. Comparison of skin disease prediction by feature selection using ensemble data mining techniques. Inform. Med. Unlocked 2019, 16, 100202. [Google Scholar] [CrossRef]
- Singh, N.; Singh, P. A stacked generalization approach for diagnosis and prediction of type 2 diabetes mellitus. In Computational Intelligence in Data Mining; Springer: Berlin/Heidelberg, Germany, 2020; pp. 559–570. [Google Scholar]
- Pal, M.; Roy, B.R. Evaluating and Enhancing the Performance of Skin Disease Classification Based on Ensemble Methods. In Proceedings of the 2020 2nd International Conference on Advanced Information and Communication Technology (ICAICT), Dhaka, Bangladesh, 28–29 November 2020; pp. 439–443. [Google Scholar]
- Jani, R.; Shanto, M.S.I.; Kabir, M.M.; Rahman, M.S.; Mridha, M. Heart Disease Prediction and Analysis Using Ensemble Architecture. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 1386–1390. [Google Scholar]
- Ashri, S.E.; El-Gayar, M.M.; El-Daydamony, E.M. HDPF: Heart Disease Prediction Framework Based on Hybrid Classifiers and Genetic Algorithm. IEEE Access 2021, 9, 146797–146809. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. CSUR 2016, 49, 1–50. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, A.; Ali, M.; Manhas, J.; Sharma, V. Diagnosis of diabetes type-II using hybrid machine learning based ensemble model. Int. J. Inf. Technol. 2020, 12, 419–428. [Google Scholar] [CrossRef]
- Australian Institute of Health and Welfare. Chronic Kidney Disease; Australian Institute of Health and Welfare: Canberra, Australia, 2020. [Google Scholar]
- Bertram, M.Y.; Sweeny, K.; Lauer, J.A.; Chisholm, D.; Sheehan, P.; Rasmussen, B.; Upreti, S.R.; Dixit, L.P.; George, K.; Deane, S. Investing in non-communicable diseases: An estimation of the return on investment for prevention and treatment services. Lancet 2018, 391, 2071–2078. [Google Scholar] [CrossRef]
- Falagas, M.E.; Pitsouni, E.I.; Malietzis, G.A.; Pappas, G. Comparison of PubMed, Scopus, web of science, and Google scholar: Strengths and weaknesses. FASEB J. 2008, 22, 338–342. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Gupta, P.; Seth, D. Improving the Prediction of Heart Disease Using Ensemble Learning and Feature Selection. Int. J. Adv. Soft Compu. Appl. 2022, 14, 36–48. [Google Scholar] [CrossRef]
- Karadeniz, T.; Tokdemir, G.; Maraş, H.H. Ensemble methods for heart disease prediction. New Gener. Comput. 2021, 39, 569–581. [Google Scholar] [CrossRef]
- Ripon, S.H. Rule induction and prediction of chronic kidney disease using boosting classifiers, Ant-Miner and J48 Decision Tree. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Eroğlu, K.; Palabaş, T. The impact on the classification performance of the combined use of different classification methods and different ensemble algorithms in chronic kidney disease detection. In Proceedings of the 2016 National Conference on Electrical, Electronics and Biomedical Engineering (ELECO), Bursa, Turkey, 1–3 December 2016; pp. 512–516. [Google Scholar]
- Verma, A.K.; Pal, S.; Tiwari, B. Skin disease prediction using ensemble methods and a new hybrid feature selection technique. Iran J. Comput. Sci. 2020, 3, 207–216. [Google Scholar] [CrossRef]
- Rehman, M.U.; Najam, S.; Khalid, S.; Shafique, A.; Alqahtani, F.; Baothman, F.; Shah, S.Y.; Abbasi, Q.H.; Imran, M.A.; Ahmad, J. Infrared sensing based non-invasive initial diagnosis of chronic liver disease using ensemble learning. IEEE Sens. J. 2021, 21, 19395–19406. [Google Scholar] [CrossRef]
- Singh, V.; Gourisaria, M.K.; Das, H. Performance Analysis of Machine Learning Algorithms for Prediction of Liver Disease. In Proceedings of the 2021 IEEE 4th International Conference on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, 24–26 September 2021; pp. 1–7. [Google Scholar]
- Abdollahi, J.; Nouri-Moghaddam, B. Hybrid stacked ensemble combined with genetic algorithms for diabetes prediction. Iran J. Comput. Sci. 2022, 5, 205–220. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y.; Wang, Z. An improved ensemble learning approach for the prediction of heart disease risk. Inform. Med. Unlocked 2020, 20, 100402. [Google Scholar] [CrossRef]
- Ali, L.; Niamat, A.; Khan, J.A.; Golilarz, N.A.; Xingzhong, X.; Noor, A.; Nour, R.; Bukhari, S.A.C. An optimized stacked support vector machines based expert system for the effective prediction of heart failure. IEEE Access 2019, 7, 54007–54014. [Google Scholar] [CrossRef]
- Almulihi, A.; Saleh, H.; Hussien, A.M.; Mostafa, S.; El-Sappagh, S.; Alnowaiser, K.; Ali, A.A.; Refaat Hassan, M. Ensemble Learning Based on Hybrid Deep Learning Model for Heart Disease Early Prediction. Diagnostics 2022, 12, 3215. [Google Scholar] [CrossRef]
- Dinh, A.; Miertschin, S.; Young, A.; Mohanty, S.D. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inf. Decis. Mak. 2019, 19, 211. [Google Scholar] [CrossRef] [Green Version]
- Alqahtani, A.; Alsubai, S.; Sha, M.; Vilcekova, L.; Javed, T. Cardiovascular Disease Detection using Ensemble Learning. Comput. Intell. Neurosci. 2022, 2022, 5267498. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the prediction of heart failure patients’ survival using SMOTE and effective data mining techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar] [CrossRef]
- Nikookar, E.; Naderi, E. Hybrid ensemble framework for heart disease detection and prediction. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 243–248. [Google Scholar] [CrossRef] [Green Version]
- Asadi, S.; Roshan, S.; Kattan, M.W. Random forest swarm optimization-based for heart diseases diagnosis. J. Biomed. Inform. 2021, 115, 103690. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, A.; Chugh, A.; Sharma, A. Ensemble framework for cardiovascular disease prediction. Comput. Biol. Med. 2022, 146, 105624. [Google Scholar] [CrossRef] [PubMed]
- Pouriyeh, S.; Vahid, S.; Sannino, G.; De Pietro, G.; Arabnia, H.; Gutierrez, J. A comprehensive investigation and comparison of machine learning techniques in the domain of heart disease. In Proceedings of the 2017 IEEE symposium on computers and communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 204–207. [Google Scholar]
- Kazemi, Y.; Mirroshandel, S.A. A novel method for predicting kidney stone type using ensemble learning. Artif. Intell. Med. 2018, 84, 117–126. [Google Scholar] [CrossRef]
- Ali, S.I.; Bilal, H.S.M.; Hussain, M.; Hussain, J.; Satti, F.A.; Hussain, M.; Park, G.H.; Chung, T.; Lee, S. Ensemble feature ranking for cost-based non-overlapping groups: A case study of chronic kidney disease diagnosis in developing countries. IEEE Access 2020, 8, 215623–215648. [Google Scholar] [CrossRef]
- Chaurasia, V.; Pandey, M.K.; Pal, S. Chronic kidney disease: A prediction and comparison of ensemble and basic classifiers performance. Hum.-Intell. Syst. Integr. 2022, 4, 1–10. [Google Scholar] [CrossRef]
- Elsayad, A.M.; Al-Dhaifallah, M.; Nassef, A.M. Analysis and diagnosis of erythemato-squamous diseases using CHAID decision trees. In Proceedings of the 2018 15th International Multi-Conference on Systems, Signals & Devices (SSD), Yasmine Hammamet, Tunisia, 19–22 March 2018; pp. 252–262. [Google Scholar]
- Sahu, B.; Agrawal, S.; Dey, H.; Raj, C. Performance Analysis of State-of-the-Art Classifiers and Stack Ensemble Model for Liver Disease Diagnosis. In Biologically Inspired Techniques in Many Criteria Decision Making; Springer: Berlin/Heidelberg, Germany, 2022; pp. 95–105. [Google Scholar]
- Tajmen, S.; Karim, A.; Hasan Mridul, A.; Azam, S.; Ghosh, P.; Dhaly, A.-A.; Hossain, M.N. A Machine Learning based Proposition for Automated and Methodical Prediction of Liver Disease. In Proceedings of the 10th International Conference on Computer and Communications Management, Okayama, Japan, 29–31 July 2022; pp. 46–53. [Google Scholar]
- Kuzhippallil, M.A.; Joseph, C.; Kannan, A. Comparative analysis of machine learning techniques for indian liver disease patients. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Tamil Nadu, India, 6–7 March 2020; pp. 778–782. [Google Scholar]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. Development of disease prediction model based on ensemble learning approach for diabetes and hypertension. IEEE Access 2019, 7, 144777–144789. [Google Scholar] [CrossRef]
- Gollapalli, M.; Alansari, A.; Alkhorasani, H.; Alsubaii, M.; Sakloua, R.; Alzahrani, R.; Al-Hariri, M.; Alfares, M.; AlKhafaji, D.; Al Argan, R. A novel stacking ensemble for detecting three types of diabetes mellitus using a Saudi Arabian dataset: Pre-diabetes, T1DM, and T2DM. Comput. Biol. Med. 2022, 147, 105757. [Google Scholar] [CrossRef] [PubMed]
- Liza, F.R.; Samsuzzaman, M.; Azim, R.; Mahmud, M.Z.; Bepery, C.; Masud, M.A.; Taha, B. An Ensemble Approach of Supervised Learning Algorithms and Artificial Neural Network for Early Prediction of Diabetes. In Proceedings of the 2021 3rd International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 18–19 December 2021; pp. 1–6. [Google Scholar]
- Qin, Y.; Wu, J.; Xiao, W.; Wang, K.; Huang, A.; Liu, B.; Yu, J.; Li, C.; Yu, F.; Ren, Z. Machine Learning Models for Data-Driven Prediction of Diabetes by Lifestyle Type. Int. J. Environ. Res. Public Health 2022, 19, 5027. [Google Scholar] [CrossRef] [PubMed]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- UCI Cleveland Heart Disease. Available online: https://www.kaggle.com/datasets/cherngs/heart-disease-cleveland-uci (accessed on 12 January 2023).
- UCI Chronic Kidney. Available online: https://www.kaggle.com/datasets/mansoordaku/ckdisease (accessed on 12 January 2023).
- UCI Dermatology. Available online: https://www.kaggle.com/datasets/syslogg/dermatology-dataset (accessed on 12 January 2023).
- UCI Indian Liver Patient. Available online: https://www.kaggle.com/datasets/uciml/indian-liver-patient-records (accessed on 12 January 2023).
- Pima Indians Diabetes. Available online: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database (accessed on 12 January 2023).
- Browne, M.W. Cross-validation methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.; Chen, M.; Zhou, P.; Zhao, T.; Lee, J.; Kakade, S.; Wang, H.; Xiong, C. How important is the train-validation split in meta-learning? In Proceedings of Machine Learning Research, Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021. [Google Scholar]
- Turner, C.R.; Fuggetta, A.; Lavazza, L.; Wolf, A.L. A conceptual basis for feature engineering. J. Syst. Softw. 1999, 49, 3–15. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Ribeiro, M.H.D.M.; Nied, A.; Yow, K.-C.; Mariani, V.C.; dos Santos Coelho, L.; Seman, L.O. Time series forecasting using ensemble learning methods for emergency prevention in hydroelectric power plants with dam. Electr. Power Syst. Res. 2022, 202, 107584. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, G.; Liu, X.; Gao, G.; Zhu, M. Ensemble learning-based modeling and short-term forecasting algorithm for time series with small sample. Eng. Rep. 2022, 4, e12486. [Google Scholar] [CrossRef]
- Jin, L.-P.; Dong, J. Ensemble deep learning for biomedical time series classification. Comput. Intell. Neurosci. 2016, 2016, 6212684. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Base Learner Models | Ensemble Model | Data Type | Preprocessing Technique | Positive/Negative Cases | Dataset | Attributes/Instances | Accuracy | Best Model |
|---|---|---|---|---|---|---|---|---|---|
| [35] | KNN, LR, SVM, RF, CART, LDA | Gradient Boost, RF | Clinical | 139/164 | UCI Cleveland Heart Disease | 14/303 | Bagging (RF) = 83%, Boosting (Gradient) = 81% | Boosting | |
| [4] | LR | RF, AdaBoost, Voting, Stacking | Random oversampling | 644/3594 | Kaggle Chronic Heart Disease | 16/4238 | Bagging (RF) = 96%, AdaBoost = 64%, Voting = 76%, Stacking = 99% | Stacking | |
| [36] | SVM | AdaBoost, Stacking, RF | Clinical | Feature selection | 139/164 | UCI Cleveland Heart Disease | 14/303 | Bagging (RF) = 88.0%, Boosting (AdaBoost) = 88.0%, Stacking = 92.2% | Stacking |
| [37] | SVM | Stacking, RF | Clinical | Feature selection, Optimisation | 139/164 | UCI Cleveland Heart Disease | 14/303 | Stacking = 91.2%, Bagging (RF) = 82.9% | Stacking |
| [19] | XGB, LR, RF, KNN | Majority Voting, XGBoost, RF | Clinical | Feature selection | 139/164 | UCI Cleveland Heart Disease | 14/303 | Voting = 94%, Bagging (RF) = 92%, Boosting (XGBoost) = 87% | Voting |
| [38] | LR, SVM | RF, XGBoost | Clinical | Feature Selection, | 1447/7012 | Cardiovascular disease | 131/8459 | Bagging (RF) = 83.6%, Boosting (XGBoost) = 83.8% | Boosting |
| [39] | XGB, DT, KNN | Stacking, RF, XGB, DT | Eliminating outliers, Scaling | Kaggle Cardiovascular | 13/7000 | Stacking = 86.4%, Bagging (RF) = 88.6%, Boosting (XGBoost) = 88.1%, Bagging (DT) = 86.3% | Bagging | ||
| [40] | DT, AdaBoost, LR, SGD, RF, SVM, GBM, ETC, G-NB | DT, AdaBoost, RF, GBM | Clinical | Oversampling | UCI Heart Failure | 13/299 | Bagging (DT) = 87.7%, Boosting (AdaBoost) = 88.5%, Bagging (RF) = 91.8%, Boosting (GBM) = 88.5% | Bagging | |
| [20] | LR, SVM, KNN, DT, RF | Majority Voting, RF, DT | Clinical | Handled missing values, imputation, normalisation | 139/164 | UCI Cleveland Heart Disease | 14/303 | Voting = 98.18%, Bagging (DT) = 93.1%, Bagging (RF) = 94.4% | Voting |
| [41] | NB, KNN, RT, SVM, BN | AdaBoost, LogitBoost, RF | Clinical | UCI SPECT heart disease | 22 | Bagging (RF) = 90%, Boosting (AdaBoost) = 85%, Boosting (LogitBoost) = 93% | Boosting | ||
| [7] | NB, RF, MLP, BN, C4.5, PART | Bagging, Boosting, and Stacking, | Clinical | Handled missing values | 139/164 | UCI Cleveland Heart Disease | 14/303 | Bagging = 79.87%, Boosting = 75.9% Stacking = 80.21%, Voting = 85.48% | Voting |
| [42] | KNN, SVM, NB, LR, QDA, C4.5, NN | Bagging, AdaBoost, and Stacking | Clinical | 139/164 | UCI Cleveland Heart Disease | 14/303 | Bagging = 77.9%, Boosting (AdaBoost) = 64.3%, Stacking = 82.5% | Stacking | |
| [5] | LR, KNN, SVM, DT, NB, MLP | Bagging, Boosting, and Stacking | Equal | Kaggle Cardiovascular Disease | 12/- | Bagging = 74.42%, Boosting = 73.4%, Stacking = 75.1% | Stacking | ||
| [43] | RF, ET, XGBoost, GB | AdaBoost, GBM, Stacking | Eliminated outliers | IEEE Data Port | 11/1190 | Boosting (GBM) = 84.2%, Boosting (AdaBoost) = 83.4%, Stacking = 92.3% | Stacking | ||
| [44] | MLP, SCRL, SVM | Bagging, Boosting, and Stacking | Clinical | 139/164 | UCI Cleveland Heart Disease | 14/303 | Bagging = 80.5%, Boosting = 81.1%, Stacking = 84.1% | Stacking | |
| [28] | DT, CNN, NB, ANN, SVM, CAFL | Bagging, Boosting | Data distribution | Eric | 7/210 | Bagging = 73.2%, Boosting (AdaBoost) = 65.1%, Stacking = 79.4% | Stacking |
| Ref. | Base Learner Models | Ensemble Model | Data Type | Preprocessing Technique | Positive/Negative Cases | Dataset | Attributes/Instances | Accuracy | Best Model |
|---|---|---|---|---|---|---|---|---|---|
| [45] | NB, LR, MLP, SVM, DS, RT | AdaBoost, Bagging, Voting, Stacking | Clinical | Handled missing values, feature selection, and sample filtering | Razi Hospital | 42/936 | Bagging = 99.1%, Boosting (AdaBoost) = 99.1%, Voting = 96.6%, Stacking = 97.1% | Boosting Bagging | |
| [46] | NB, LR, ANN, CART, SVM | Gradient Boosting, RF | Clinical | Feature selection, handling missing values, and imputation | 250/150 | UCI Chronic Kidney | 25/400 | Bagging (RF) = 96.5%, Boosting (Gradient Boosting) = 90.4% | Bagging |
| [2] | - | AdaBoost, RF, ETC bagging, Gradient boosting | Clinical | Feature engineering | 250/150 | UCI Chronic Kidney | 25/400 | Bagging (Extra trees) = 98%, Bagging = 96%, Bagging (RF) = 95%, Boosting (AdaBoost) = 99%, Boosting (Gradient) = 97% | Boosting |
| [47] | LR, KNN, SVC | Gradient Boosting, RF | Clinical | Handled missing values | 250/150 | UCI Chronic Kidney | 25/400 | Bagging (RF) = 99%, Boosting (Gradient) = 98.7% | Bagging |
| [13] | - | AdaBoost, Bagging and Random Subspaces | Clinical | Feature extraction | 250/150 | UCI Chronic Kidney | 25/400 | AdaBoost = 99.25%, Bagging = 98.5%, Bagging (Random Subspace) = 99.5% | Bagging |
| [11] | NB, SMO, J48, RF | Bagging, AdaBoost | Feature selection and handling missing values | 250/150 | UCI Chronic Kidney | 25/400 | Bagging = 98%, Bagging (RF) = 100%, Boosting (AdaBoost) = 99% | Bagging |
| Ref. | Base Learner Algorithm | Ensemble Approach | Data Type | Preprocessing Technique | Positive/Negative Cases | Dataset | Attributes/Instances | Accuracy | Best One |
|---|---|---|---|---|---|---|---|---|---|
| [18] | NB, RF KNN, SVM, and MLP | Bagging, Boosting, and Stacking | Clinical | Handled missing values | [20–112]/[254–346] | UCI Dermatology | 34/366 | Bagging = 96%, Boosting = 97%, Stacking = 100% | Stacking |
| [8] | DT, LR | Bagging, AdaBoost, and Stacking | Clinical | Feature selection | [20–112]/[254–346] | UCI Dermatology | 34/366 | Bagging = 92.8%, Boosting (AdaBoost) = 92.8%, Stacking = 92.8% | Bagging Boosting Stacking |
| [48] | LR, CHAID DT | Bagging, Boosting | Clinical | Handled missing values, data distribution, and balancing, | [20–112]/[254–346] | UCI Dermatology | 34/366 | Bagging = 100%, Boosting = 100% | Bagging Boosting |
| [31] | NB, KNN, DT, SVM, RF, MLP | Bagging, Boosting, and Stacking | Clinical | Hybrid Feature selection, information gain, and PCA | [20–112]/[254–346] | UCI Dermatology | 12/366 | Bagging = 95.94%, Boosting = 97.70%, Stacking = 99.67% | Stacking |
| [16] | PAC, LDA, RNC, BNB, NB, ETC | Bagging, AdaBoost, Gradient Boosting | Clinical | Feature Selection | [20–112]/[254–346] | UCI Dermatology | 34/366 | Bagging = 97.35%, AdaBoost = 98.21%, Gradient Boosting = 99.46% | Boosting |
| Ref. | Base Learner Models | Ensemble Model | Data Type | Preprocessing Technique | Positive/Negative Cases | Dataset | Attributes/Instances | Accuracy | Best Model |
|---|---|---|---|---|---|---|---|---|---|
| [3] | BeggRep, BeggJ48, AdaBoost, LogitBoost, RF | Bagging, Boosting | Clinical | 416/167 | UCI Indian Liver Patient | 10/583 | Boosting(AdaBoost) = 70.2%, Boosting(LogitBoost) = 70.53%, Bagging (RF) = 69.2% | Boosting | |
| [49] | NB, SVM, KNN, LR, DT, MLP | Stacking, DT | Clinical | Feature Selection PCA | 416/167 | UCI Indian Liver Patient | 10/583 | Bagging (DT) = 69.40% Stacking = 71.18% | Stacking |
| [50] | KNN | RF, Gradient Boosting, AdaBoost, Stacking | Clinical | 416/167 | UCI Indian Liver Patient | 10/583 | Bagging (RF) = 96.5%, Boosting(Gradient) = 91%, Boosting(AdaBoost) = 94%, Stacking = 97% | Stacking | |
| [33] | DT, NB, KNN, LR, SVM, AdaBoost, CatBoost | XGBoost, Light GBM, RF | Clinical | Handled missing values | 416/167 | UCI Indian Liver Patient | 10/583 | Bagging (RF) = 88.5% Boosting(XGBoost) = 86.7% Boosting (LightGBM) = 84.3% | Bagging |
| [32] | SVM, KNN, NN, LR, CART, ANN, PCA, LDA | Bagging, Stacking | Clinical | Handled missing values, feature selection, PCA | 453/426 | Iris And Physiological | 22/879 | Bagging (RF) = 85%, Stacking = 98% | Stacking |
| [9] | KNN, SVM, RF, LR, CNN | RF, XGBoost, Gradient Boost | Handled missing values, scaling, and feature selection | Image | 11/10,000 | Bagging (RF) = 83% Boosting (XGBoost) = 82% Boosting (Gradient) = 85% | Boosting | ||
| [51] | LR, DT, RF KNN, MLP | AdaBoost, XGBoost, Stacking | Clinical | Data Imputation, label encoding, resampling, eliminating duplicate values and outliers | 416/167 | UCI Indian Liver Patient | 10/583 | Boosting (AdaBoost) = 83% Boosting (XGBoost) = 86% Stacking = 85% | Boosting |
| [10] | DT, KNN, SVM, NB | Bagging, Boosting, RF | Clinical | Discretisation, resampling, PCA | 416/167 | UCI Indian Liver Patient | 10/583 | Bagging (RF) = 88.6%, Bagging = 89%, Boosting = 89% | Bagging Boosting |
| Ref. | Base Learner Models | Ensemble Model | Data Type | Preprocessing Technique | Positive/Negative Cases | Dataset | Attributes/Instances | Accuracy | Best Model |
|---|---|---|---|---|---|---|---|---|---|
| [52] | MLP, SVM, DT, LR | RF, Stacking | Outlier detection and elimination, SMOTE Tomek for imbalanced data | 73/330 | Type 2 Diabetes | 19/403 | Bagging (RF) = 92.5% Stacking = 96.7% | Stacking | |
| [6] | RF, LR, NB | Soft voting classifier, AdaBoost, Bagging, XGBoost, | Clinical | Min–max normalisation, label encoding, handled missing values | 268/500 | Pima Indians Diabetes | 9/768 | Bagging = 74.8%, Boosting(AdaBoost) = 75.3%, Boosting (XGBoost) = 75.7%, Voting = 79.0% | Voting |
| [53] | SVM, KNN, DT | Bagging, Stacking | Clinical | SMOTE, k-fold cross validation | KFUH Diabetes | 10/897 | Bagging = 94.1%, Stacking = 94.4% | Stacking | |
| [54] | KNN, LR, MLP | AdaBoost, Stacking | Feature selection, handling missing values | 60/330 | Vanderbilt University’s Biostatistics program | 18/390 | Boosting (AdaBoost) = 91.3%, Stacking = 93.2% | Stacking | |
| [55] | XGB, CGB, SVM, RF, LR | XGBoost, RF, CatBoost | Missing values eliminated, class imbalance handling, feature selection | 33,332/73,656 | NHANES | 18/124,821 | Boosting(XGBoost) = 70.8%, Bagging(RF) = 78.4%, Boosting(CatBoost) = 82.1% | Boosting | |
| [38] | LR, SVM | RF, XGBoost | Clinical | feature Selection | 5532/15,599 | Cardiovascular disease | 123/21,131 | Bagging (RF) = 85.5%, Boosting (XGBoost) = 86.2% | Boosting |
| [17] | SVM | Majority voting, stacking | Clinical | Cross-validation | 268/500 | Pima Indians Diabetes | 9/768 | Stacking = 79%, Voting = 65.10% | Stacking |
| [22] | ANN, SVM, KNN, NB | Bagging, RF, Majority Voting | Clinical | 268/500 | Pima Indians Diabetes | 9/768 | Bagging(RF) = 90.97%, Bagging = 89.69%, Voting = 98.60%, | Voting | |
| [34] | KNN, RF, DT, SVM, MLP, GB | RF, AdaBoost, Stacking | Clinical | Feature selection with genetic algorithm | 268/500 | Pima Indians Diabetes | 9/768 | Bagging (RF) = 93%, Boosting (GBC) = 95%, Stacking = 98.8% | Stacking |
| [10] | DT, KNN, SVM | Bagging, Boosting, RF | Clinical | Discretisation, resampling, PCA | 268/500 | Pima Indians Diabetes | 9/768 | Bagging (RF) = 89.7%, Bagging = 89.5%, Boosting = 90.1% | Boosting |
| Ensemble Approach | Advantages | Limitations |
|---|---|---|
| Bagging |
|
|
| Boosting |
| |
| Stacking |
|
|
| Voting |
|
|
| Ensemble Approach | Number of Published Articles Used This Algorithm | Number of Times This Algorithm Showed the Best Performance (%) |
|---|---|---|
| Bagging | 41 | 11 (26.8%) |
| Boosting | 37 | 15 (40.5%) |
| Stacking | 23 | 19 (82.6%) |
| Voting | 7 | 5 (71.4%) |
| Disease Name | Total Reviewed Article | Bagging | Boosting | Stacking | Voting | ||||
|---|---|---|---|---|---|---|---|---|---|
| Usage Frequency | Best Performance | Usage Frequency | Best Performance | Usage Frequency | Best Performance | Usage Frequency | Best Performance | ||
| Heart disease | 16 | 15 | 2 (13.4%) | 14 | 3 (21.4%) | 10 | 8 (80%) | 4 | 3 (75%) |
| Kidney disease | 6 | 6 | 5 (83.4%) | 6 | 2 (33.4%) | 1 | 0 (0%) | 0 | 0 (0%) |
| Skin Cancer | 5 | 5 | 2 (40%) | 5 | 3 (60%) | 3 | 3 (100%) | 0 | 0 (0%) |
| Liver disease | 8 | 7 | 2 (28.5%) | 6 | 4 (66.7%) | 4 | 3 (75%) | 0 | 0 (0%) |
| Diabetes disease | 10 | 8 | 0 (0%) | 6 | 3 (50%) | 5 | 5 (100%) | 3 | 2 (66.7%) |
| Total | 45 | 41 | 11 (26.8%) | 37 | 15 (40.5%) | 23 | 19 (82.6%) | 7 | 5 (71.4%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahajan, P.; Uddin, S.; Hajati, F.; Moni, M.A. Ensemble Learning for Disease Prediction: A Review. Healthcare 2023, 11, 1808. https://doi.org/10.3390/healthcare11121808
Mahajan P, Uddin S, Hajati F, Moni MA. Ensemble Learning for Disease Prediction: A Review. Healthcare. 2023; 11(12):1808. https://doi.org/10.3390/healthcare11121808
Chicago/Turabian StyleMahajan, Palak, Shahadat Uddin, Farshid Hajati, and Mohammad Ali Moni. 2023. "Ensemble Learning for Disease Prediction: A Review" Healthcare 11, no. 12: 1808. https://doi.org/10.3390/healthcare11121808