
A Curriculum Batching Strategy for Automatic ICD Coding with Deep Multi-Label Classification Models

Abstract
:1. Introduction
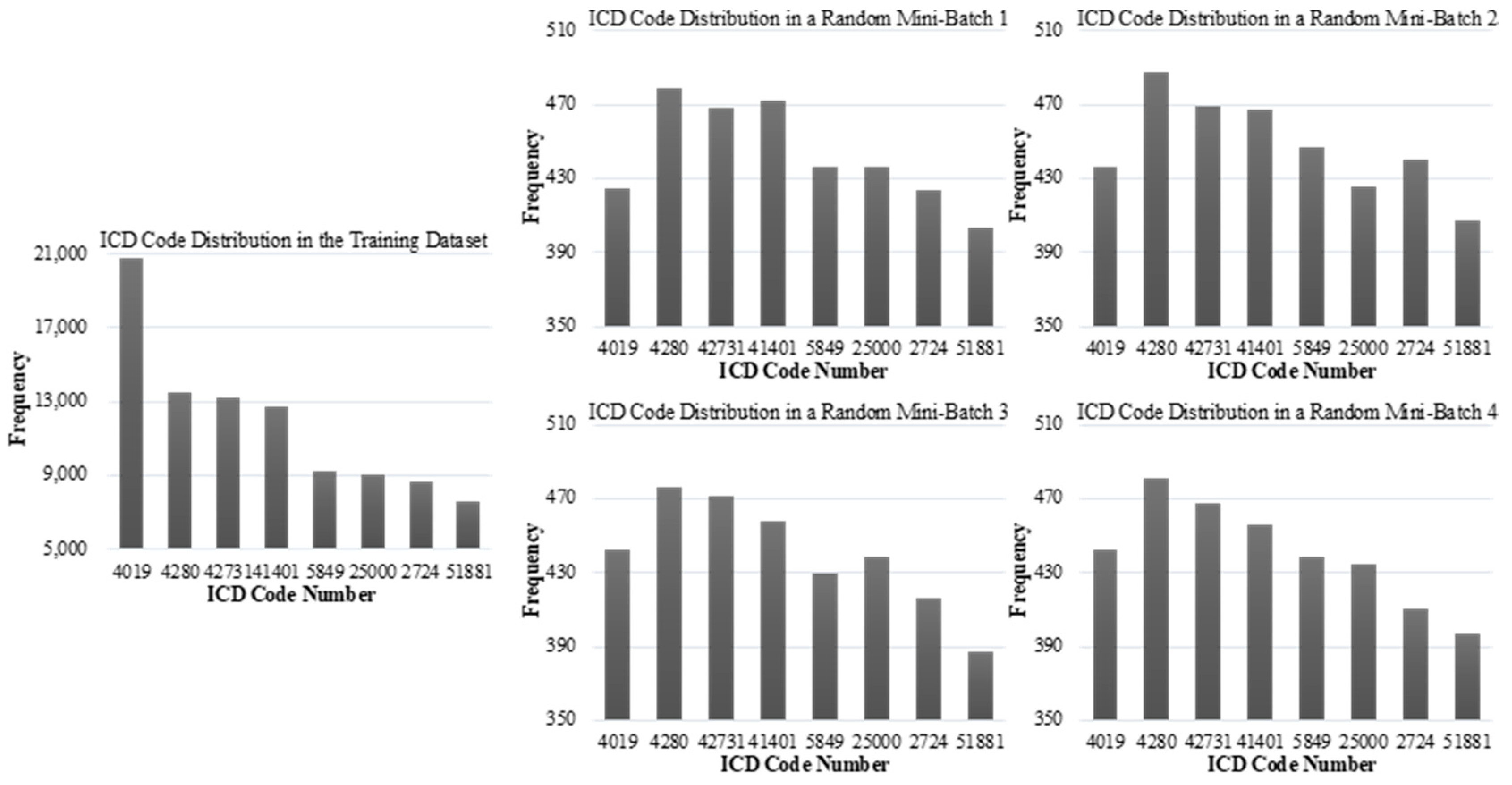
- This paper finds that the shuffling algorithm in the MBGD always causes the local data distribution of batches to be inconsistent with the global training data distribution, which hurts the model’s performance and generalizability;
- This paper alleviates the problems of poor generalization ability and low classification accuracy of the deep learning model in the field of ICD automatic coding;
- This paper greatly improves the learning ability of the automatic ICD coding model for data with long-tailed labels;
- This paper introduces the curriculum learning method into automatic ICD coding of deep multi-label classification model for the first time.
2. Related Work
2.1. Automatic ICD Coding
2.2. Mini-Batch Gradient Descent
2.3. Curriculum Learning
3. Methodology
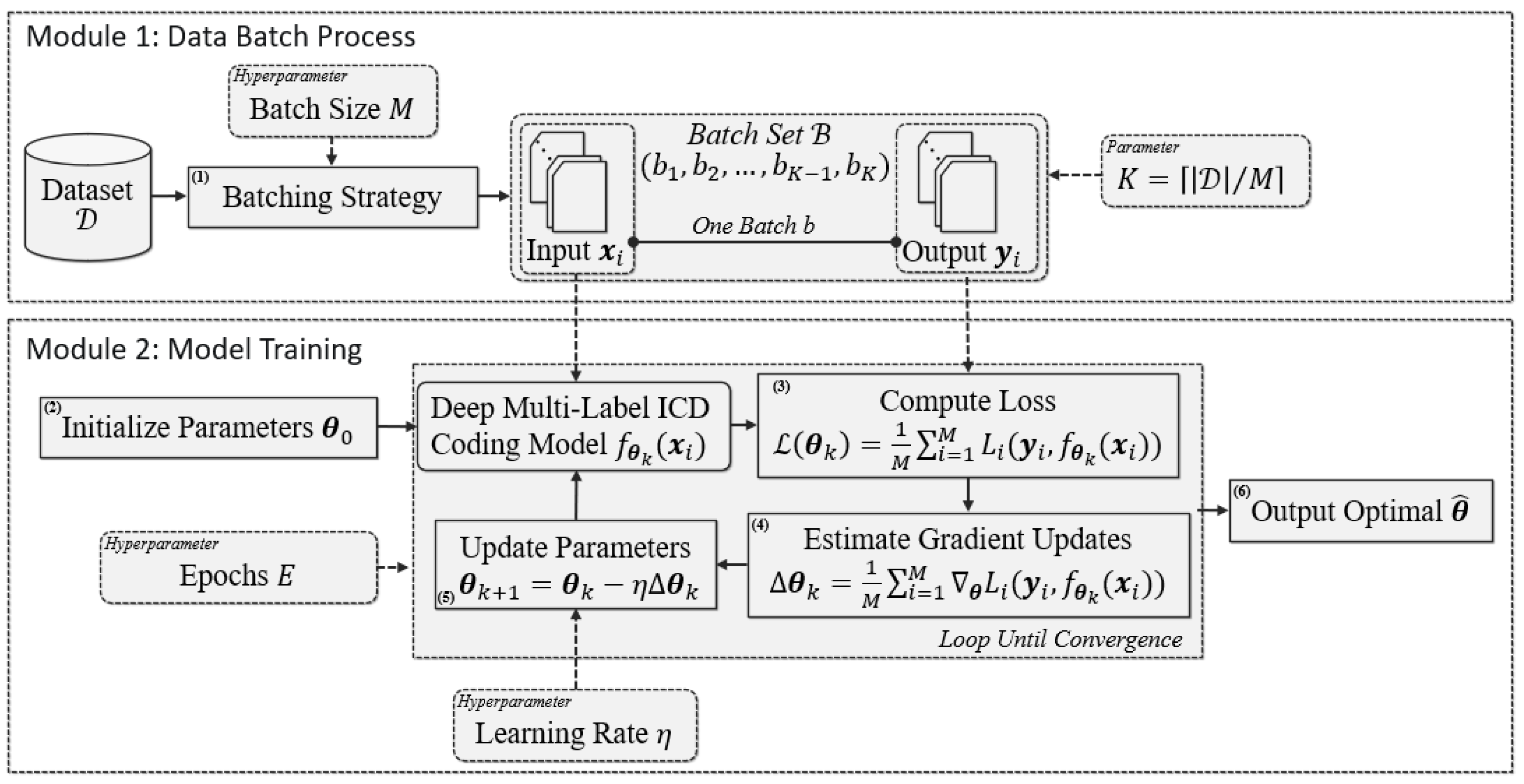
3.1. MBGD-Based Training Procedure
- Batching Strategy: In this data process, a shuffling algorithm is commonly applied [26]; firstly, each example in training data is randomly sorted to generate a list. Then, the batch set is formed by scanning the list with a sliding window with the size of , i.e., the batch size. Thus, , the number of batches in , equals . This data process sometimes may be performed more than once;
- Parameter Initialization: In this parameter process, are usually drawn randomly from a distribution (e.g., uniform) as the initialization parameters;
- Loss Computation: Many kinds of deep multi-label classification models for automatic ICD coding can be applied in this step, including TextCNN, TextRNN and TextRCNN, which are compared in this paper. We uniformly note them as . means that the model takes the example as the input with the th iteration’s parameter . The loss of the current th iteration, , is the mean of the loss values obtained based on examples in . A loss value obtained based on one example in is noted as ;
- Gradient Update Estimation: According to , and the examples in , the th iteration’s gradient updates, , can be estimated by the average of the gradients of the examples in , as shown in Figure 2;
- Parameter Update: The th iteration’s parameter, , is calculated, based on and with the hyperparameter learning rate ;
- Optimized Parameter Output: In general, the steps from 3 to 5 will loop E epochs until the model converges.
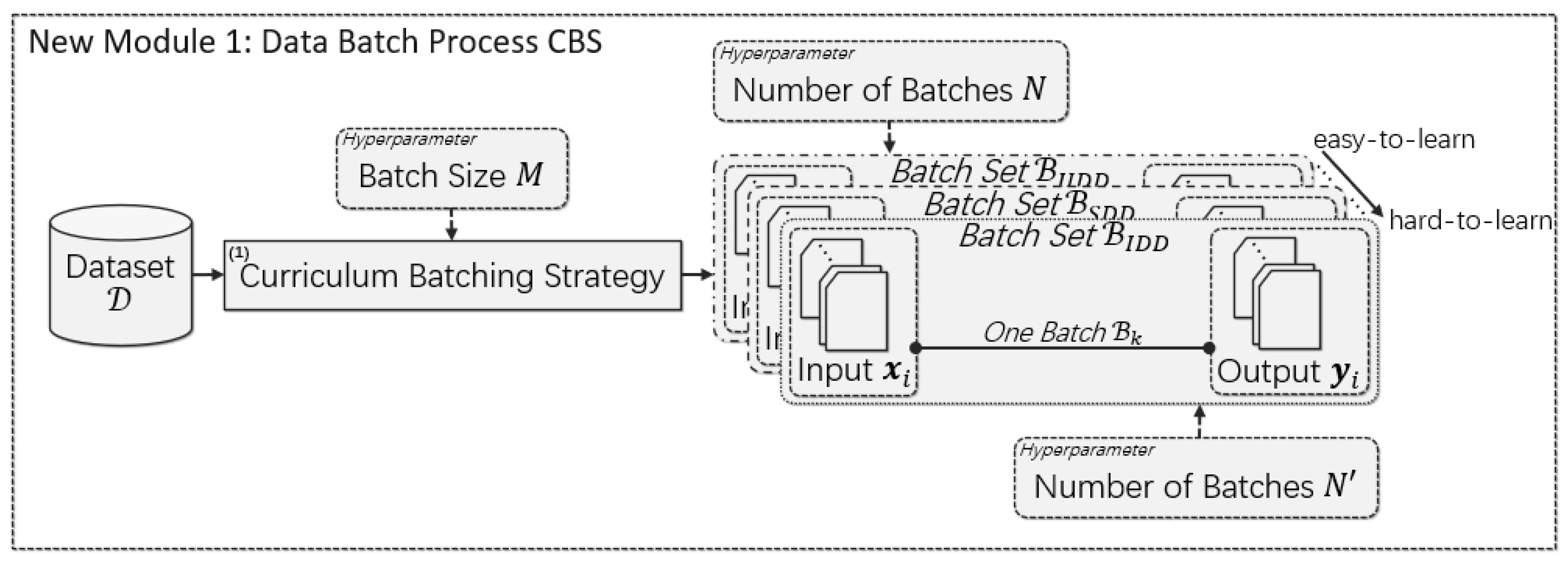
3.2. Curriculum-Batching Strategy
4. Experiments
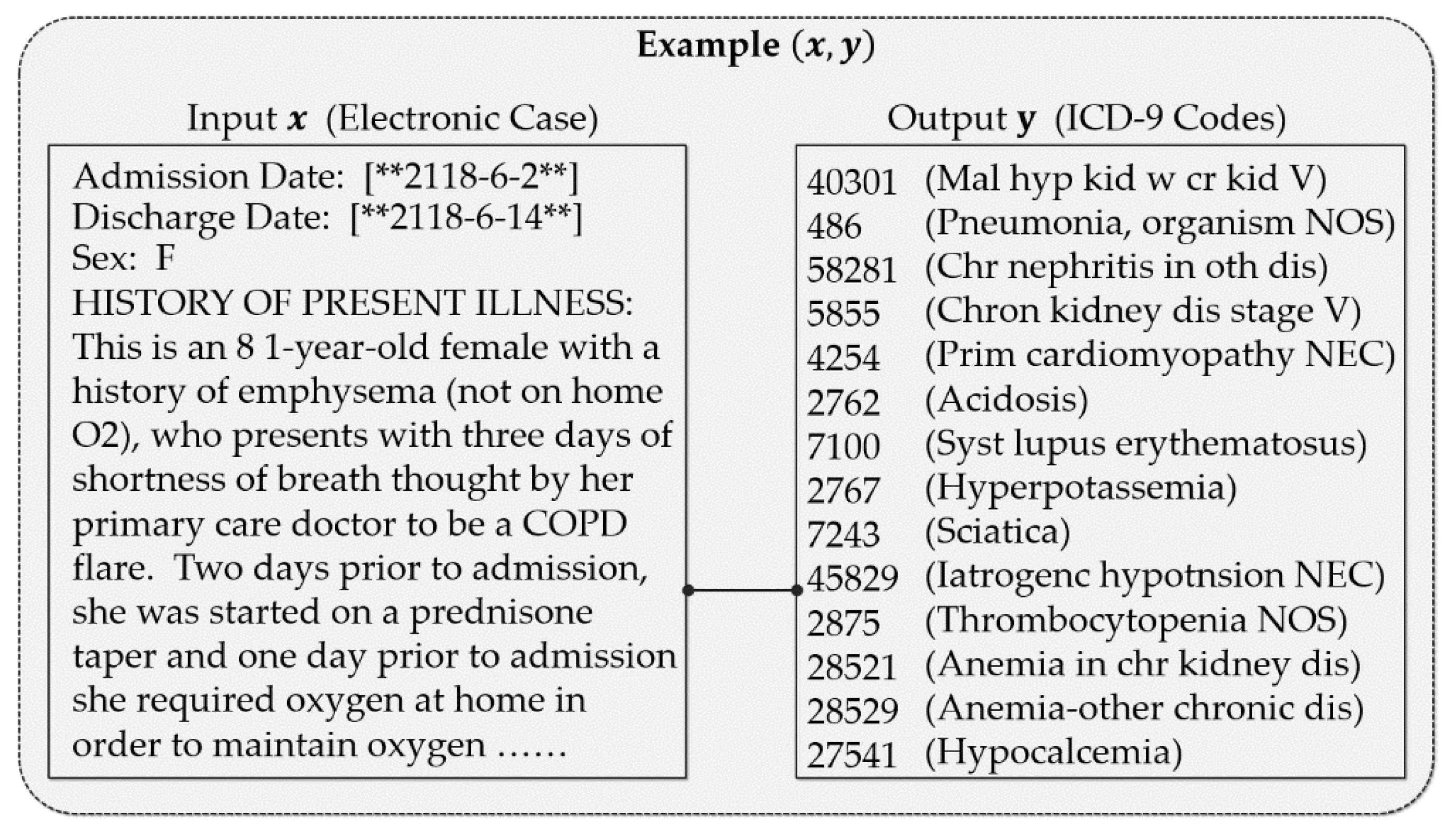
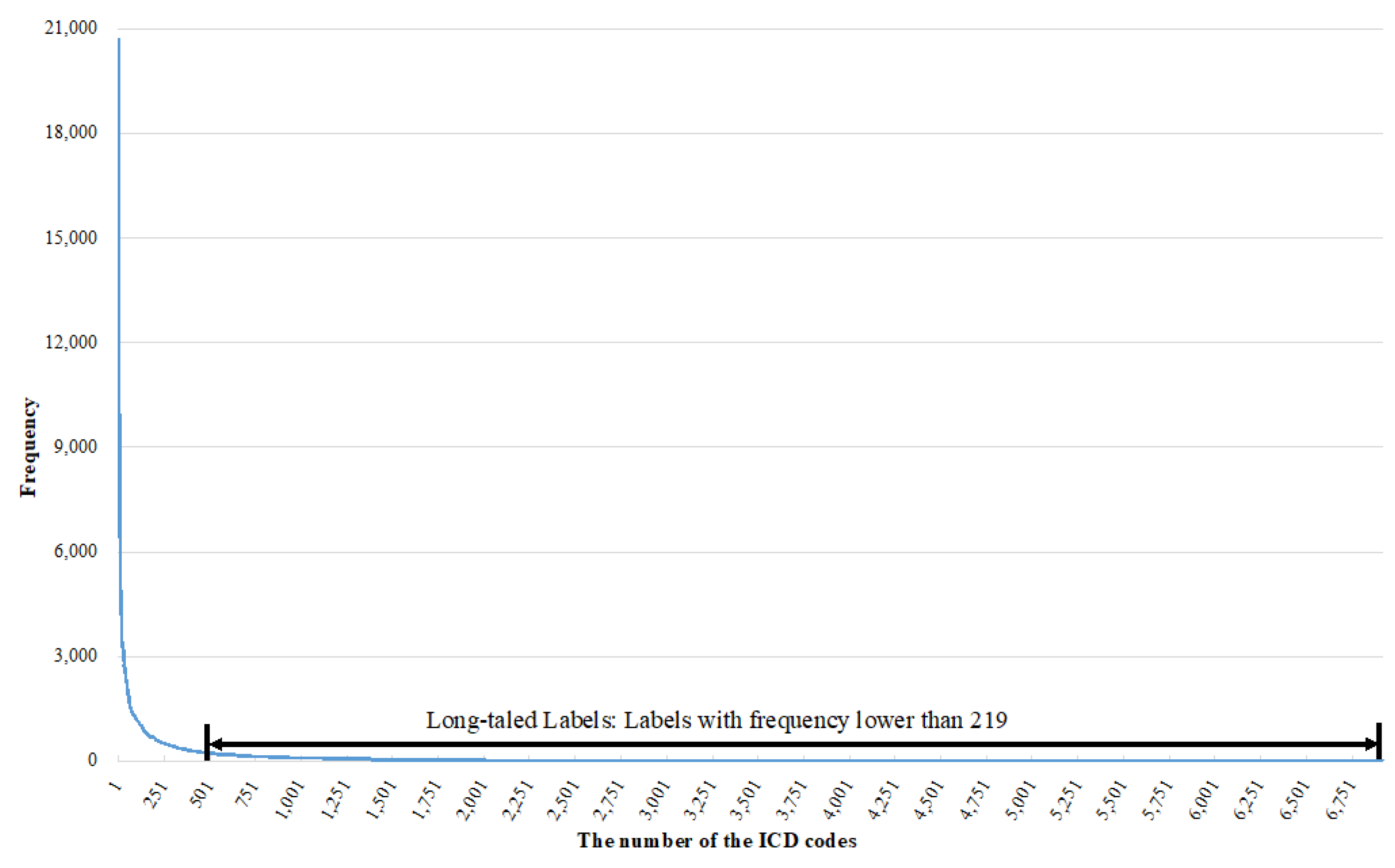
4.1. Experimental Dataset
- All the punctuation, numbers and stop words were removed from all the examples;
- The discharge summaries were segmented into tokens by using the space as the separator, and then we built a vocabulary based on these tokens;
- The TF-IDF values of each word in are calculated, based on all the examples, and only the top 10,000 words are kept to be used to build the final vocabulary .
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Overall Results
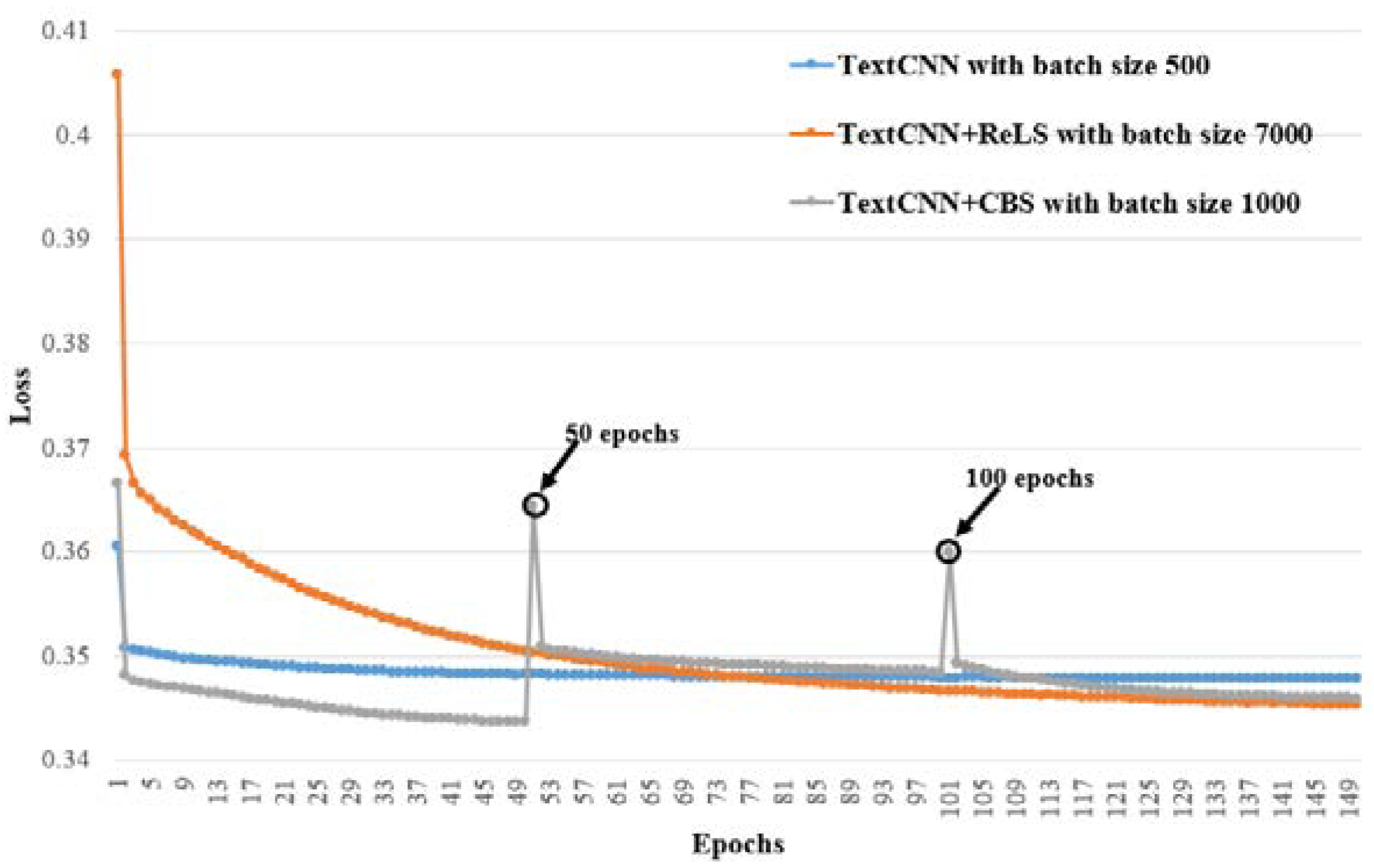
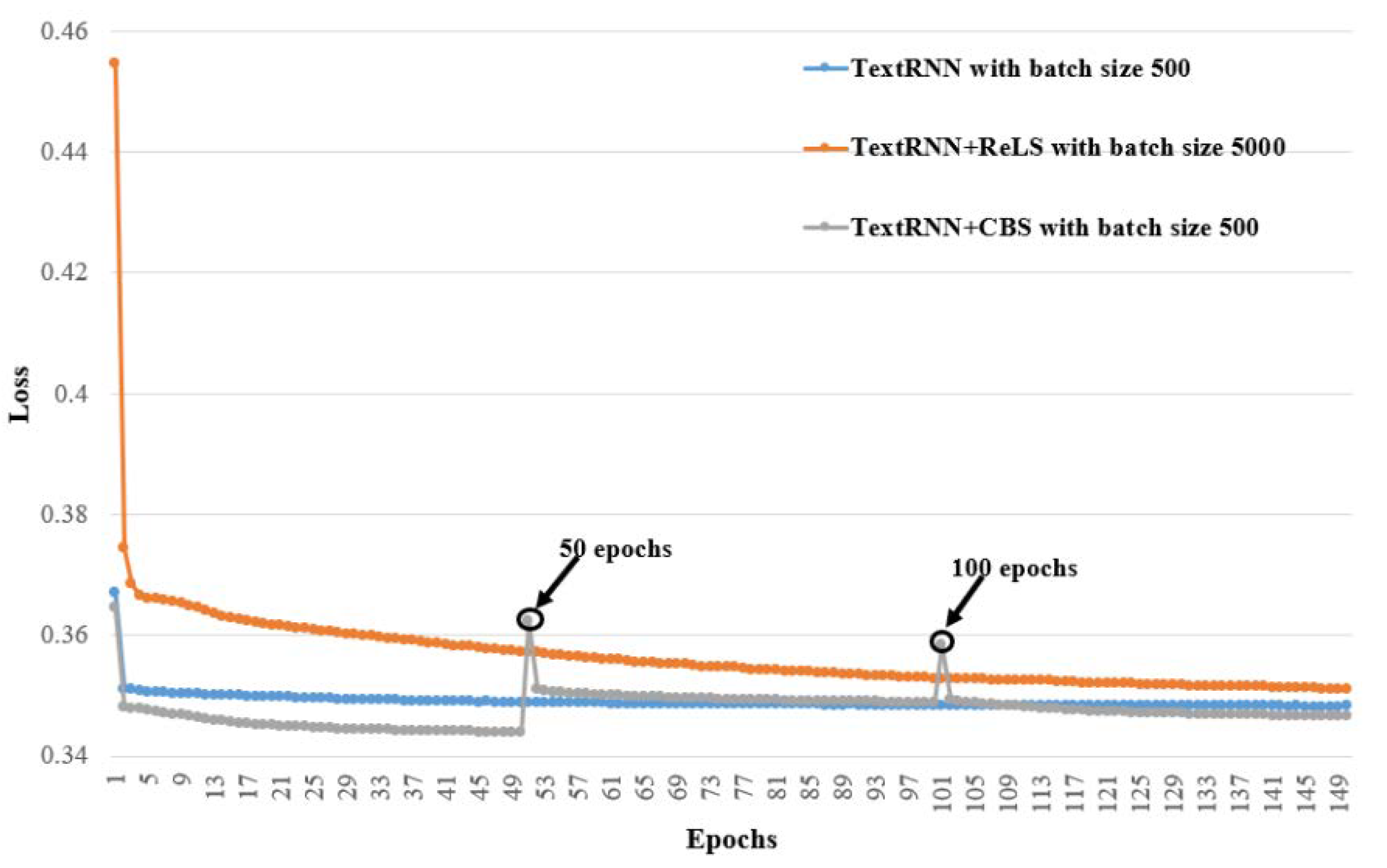
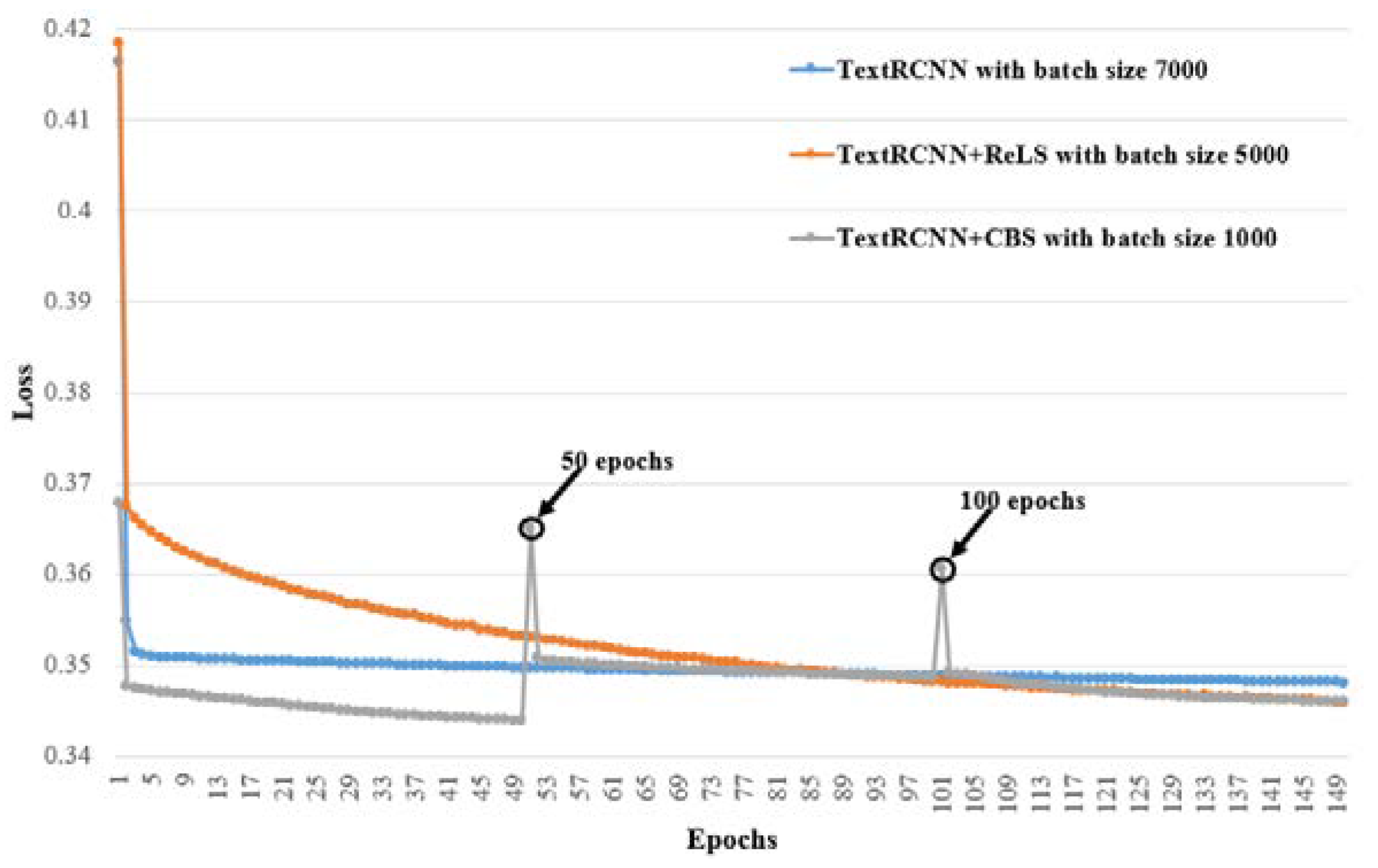
4.5. Detailed Analysis
4.6. Evaluating the Learning Difficulties of , and
4.7. Ablation Experiments of CBS
4.8. Evaluating the Long-Tailed Label Learning Performance
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. ICD-10: International Statistical Classification of Diseases and Related Health Problems: Tenth Revision. Volume 1: Tabular List; World Health Organization: Geneva, Switzerland, 2004.
- Yu, Y.; Li, M.; Liu, L.; Fei, Z.; Wu, F.-X.; Wang, J. Automatic ICD code assignment of Chinese clinical notes based on multilayer attention BiRNN. J. Biomed. Inform. 2019, 91, 103114. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, A.N.; Truran, D.; Kemp, M.; Koopman, B.; Conlan, D.; O’Dwyer, J.; Zhang, M.; Karimi, S.; Hassanzadeh, H.; Lawley, M.J.; et al. Computer-Assisted Diagnostic Coding: Effectiveness of an NLP-Based Approach Using SNOMED CT to ICD-10 Mappings. In Proceedings of the AMIA Annual Symposium Proceedings (AMIA 2018), San Francisco, CA, USA, 3–7 November 2018; pp. 807–816. [Google Scholar]
- O’Malley, K.J.; Cook, K.F.; Price, M.D.; Wildes, K.R.; Hurdle, J.F.; Ashton, C.M. Measuring Diagnoses: ICD Code Accuracy. Health Serv. Res. 2005, 40, 1620–1639. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a Health Knowledge Graph from Electronic Medical Records. Sci. Rep. 2017, 7, 5994. [Google Scholar] [CrossRef] [PubMed]
- Stanfill, M.H.; Williams, M.; Fenton, S.H.; Jenders, R.A.; Hersh, W. A systematic literature review of automated clinical coding and classification systems. J. Am. Med. Inform. Assoc. 2010, 17, 646–651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaur, R.; Ginige, J.A.; Obst, O. A Systematic Literature Review of Automated ICD Coding and Classification Systems Using Discharge Summaries. arXiv 2021, arXiv:2107.10652v1. [Google Scholar]
- Blanco, A.; Perez, A.; Casillas, A. Extreme Multi-Label ICD Classification: Sensitivity to Hospital Service and Time. IEEE Access 2020, 8, 183534–183545. [Google Scholar] [CrossRef]
- Vu, T.; Nguyen, D.Q.; Nguyen, A. A Label Attention Model for ICD Coding from Clinical Text. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2021; pp. 3335–3341. [Google Scholar]
- Blanco, A.; de Viñaspre, O.P.; Pérez, A.; Casillas, A. Boosting ICD multi-label classification of health records with contextual embeddings and label-granularity. Comput. Methods Programs Biomed. 2020, 188, 105264. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Zhang, S.; Sadoughi, N.; Xie, P.; Xing, E. Generalized Zero-Shot Text Classification for ICD Coding. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-PRICAI 2020), Yokohama, Japan, 7–15 January 2021; pp. 4018–4024. [Google Scholar]
- Smith, S.L.; Kindermans, P.-J.; Ying, C.; Le, Q.V. Don’t Decay the Learning Rate, Increase the Batch Size. In Proceedings of the Sixth International Conference on Learning Representations (ICLR 2018), Vacounver, Canada, 30 April–3 May 2018; pp. 1–11. [Google Scholar]
- Wu, Y.; Johnson, J. Rethinking “Batch” in BatchNorm. arXiv 2021, arXiv:2105.07576v1. [Google Scholar]
- de Lima, L.R.S.; Laender, A.H.F.; Ribeiro-Neto, B.A. A Hierarchical Approach to the Automatic Categorization of Medical Documents. In Proceedings of the Seventh International Conference on Information and Knowledge Management (CIKM 1998), Bethesda, MD, USA, 2–7 November 1998; pp. 132–139. [Google Scholar]
- Perotte, A.; Pivovarov, R.; Natarajan, K.; Weiskopf, N.; Wood, F.; Elhadad, N. Diagnosis Code Assignment: Models and Evaluation Metrics. J. Am. Med. Inform. Assoc. 2014, 21, 231–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, F.; Yu, H. ICD Coding from Clinical Text Using Multi-Filter Residual Convolutional Neural Network. Proc. Conf. AAAI Artif. Intell. 2020, 34, 8180–8187. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Xiong, Y.; Yu, P.S.; Zhu, Y. EHR Coding with Multi-scale Feature Attention and Structured Knowledge Graph Propagation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM 2019), Beijing, China, 3–7 November 2019; pp. 649–658. [Google Scholar]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable prediction of medical codes from clinical text. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2018), New Orleans, Louisiana, 1-6 June 2018; pp. 1101–1111. [Google Scholar]
- Sadoughi, N.; Finley, G.P.; Fone, J.; Murali, V.; Korenevski, M.; Baryshnikov, S.; Axtmann, N.; Miller, M.; Suendermann-Oeft, D. Medical code prediction with multi-view convolution and description-regularized label-dependent attention. arXiv 2018, preprint. arXiv:1811.01468. [Google Scholar]
- Bhutto, S.R.; Wu, Y.; Yu, Y.; Jalbani, A.H.; Li, M. A Hybrid Pooling Based Deep Learning Framework for Automated ICD Coding. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Online, 9–12 December 2021; pp. 823–828. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2017, arXiv:1609.04747v2. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Extrapolation for Large-batch Training in Deep Learning. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; pp. 6094–6104. [Google Scholar]
- Masters, D.; Luschi, C. Revisiting Small Batch Training for Deep Neural Networks. arXiv 2018, arXiv:1804.07612v1. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Montavon, G.; Orr, G.B.; Müller, K.-R. Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Elman, J.L. Learning and development in neural networks: The importance of starting small. Cognition 1993, 48, 71–99. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the 26th Annual International Conference on Machine Learning (ICML 2009), Montreal, QB, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A Survey of Predictive Modeling on Imbalanced Domains. ACM Comput. Surv. 2016, 49, 31. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Krysi´nska, I.; Morzy, M.; Kajdanowicz, T. Curriculum Learning Revis-ited: Incremental Batch Learning with Instance Typicality Ranking. In Proceedings of the 30th International Conference on Artificial Neural Networks (ICANN 2021), Bratislava, Slovakia, 14—17 September 2021; pp. 279–291. [Google Scholar]
- Liu, W.; Qian, H.; Zhang, C.; Shen, Z.; Xie, J.; Zheng, N. Accelerating Stratified Sampling SGD by Reconstructing Strata. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI 2020), Yokohama, Japan, 7–15 January 2021; pp. 2725–2731. [Google Scholar]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Mu, F.; Li, P.; Mu, X.; Tang, J.; Ai, X.; Fu, R.; Wang, L.; Zhou, X. NeuralClassifier: An open-source neural hierarchical multi-label text classification toolkit. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Florence, Italy, 2 July–2 August 2019; pp. 87–92. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | TextCNN | TextRNN | TextRCNN |
|---|---|---|---|
| on Training Data | 0.695 | 0.789 | 0.624 |
| on Test Data | 0.325 | 0.282 | 0.317 |
| Unique Labels | Avg. Words per Example | Max Words in Examples | |
|---|---|---|---|
| 55,177 | 6918 | 898 | 4604 |
| Min Words in Examples | Avg. Labels per Example | Max Labels per Example | Min Labels per Example |
| 2 | 11 | 39 | 1 |
| Batch Size | TextCNN | TextRNN | TextRCNN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 0.5365 | 0.2341 | 0.3254 | 0.0237 | 0.4725 | 0.2005 | 0.2815 | 0.0243 | 0.4867 | 0.2324 | 0.3146 | 0.0302 |
| 1000 | 0.5456 | 0.2311 | 0.3246 | 0.0222 | 0.5084 | 0.1814 | 0.2674 | 0.0192 | 0.5021 | 0.2265 | 0.3121 | 0.0264 |
| 2000 | 0.5397 | 0.2260 | 0.3186 | 0.0216 | 0.4769 | 0.1761 | 0.2572 | 0.0183 | 0.4945 | 0.2250 | 0.3092 | 0.0261 |
| 5000 | 0.5578 | 0.2207 | 0.3163 | 0.0197 | 0.4941 | 0.1644 | 0.2467 | 0.0162 | 0.4677 | 0.2379 | 0.3154 | 0.0265 |
| 7000 | 0.5403 | 0.2241 | 0.3168 | 0.0214 | 0.5541 | 0.1383 | 0.2214 | 0.0108 | 0.4694 | 0.2401 | 0.3174 | 0.0256 |
| Batch Size | TextCNN+CBS | TextRNN+CBS | TextRCNN+CBS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 0.8121 | 0.6251 | 0.7064 | 0.5789 | 0.8072 | 0.4487 | 0.5766 | 0.4619 | 0.8246 | 0.6004 | 0.6949 | 0.5669 |
| 1000 | 0.8403 | 0.6693 | 0.7449 | 0.5802 | 0.7919 | 0.3605 | 0.4954 | 0.3300 | 0.8546 | 0.6167 | 0.7161 | 0.5563 |
| 2000 | 0.8507 | 0.5813 | 0.6907 | 0.4234 | 0.7226 | 0.2042 | 0.3184 | 0.0551 | 0.8304 | 0.5230 | 0.6418 | 0.4738 |
| 5000 | 0.8432 | 0.4940 | 0.6230 | 0.2898 | 0.6983 | 0.1510 | 0.2483 | 0.0198 | 0.8350 | 0.4142 | 0.5530 | 0.3602 |
| 7000 | 0.8005 | 0.3468 | 0.4839 | 0.0882 | 0.6638 | 0.1063 | 0.1832 | 0.0062 | 0.7800 | 0.3240 | 0.4580 | 0.1571 |
| Batch Size | TextCNN+ReLS | TextRNN+ReLS | TextRCNN+ReLS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 0.4987 | 0.3412 | 0.4052 | 0.0977 | 0.4391 | 0.3107 | 0.3639 | 0.0816 | 0.4611 | 0.3471 | 0.3961 | 0.1030 |
| 1000 | 0.5091 | 0.3320 | 0.4019 | 0.0973 | 0.4171 | 0.3016 | 0.3501 | 0.0781 | 0.5065 | 0.3401 | 0.4069 | 0.0981 |
| 2000 | 0.5574 | 0.3474 | 0.4280 | 0.1010 | 0.4757 | 0.3052 | 0.3719 | 0.0817 | 0.5318 | 0.3624 | 0.4310 | 0.1067 |
| 5000 | 0.6290 | 0.3241 | 0.4277 | 0.0829 | 0.4882 | 0.3052 | 0.3756 | 0.0854 | 0.5638 | 0.3529 | 0.4341 | 0.1046 |
| 7000 | 0.6190 | 0.3310 | 0.4313 | 0.0824 | 0.5157 | 0.2890 | 0.3704 | 0.0813 | 0.5408 | 0.3567 | 0.4299 | 0.1068 |
| Batch Size | TextCNN+CBS (On Training Data) | TextRNN+CBS (On Training Data) | TextRCNN+CBS (On Training Data) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 500 | 0.7934 | 0.5898 | 0.6766 | 0.8312 | 0.7886 | 0.4219 | 0.5496 | 0.6854 | 0.8039 | 0.5650 | 0.6636 | 0.8132 |
| 1000 | 0.8198 | 0.6353 | 0.7157 | 0.8179 | 0.7755 | 0.3395 | 0.4721 | 0.4451 | 0.8339 | 0.5805 | 0.6842 | 0.7935 |
| 2000 | 0.8290 | 0.5472 | 0.6592 | 0.5278 | 0.7195 | 0.1919 | 0.3029 | 0.0612 | 0.8076 | 0.4939 | 0.6130 | 0.6502 |
| 5000 | 0.8225 | 0.4658 | 0.5947 | 0.3245 | 0.6984 | 0.1400 | 0.2332 | 0.0208 | 0.8158 | 0.3892 | 0.5263 | 0.4777 |
| 7000 | 0.7839 | 0.3269 | 0.4614 | 0.0902 | 0.6672 | 0.0979 | 0.1707 | 0.0066 | 0.7908 | 0.2624 | 0.3938 | 0.1954 |
| Method | |||
|---|---|---|---|
| KLD | 0.124 | 0.103 | 0.090 |
| JSD | 33.3 × 10−3 | 12.8 × 10−3 | 8.97 × 10−3 |
| Model | Curriculum | ||||
|---|---|---|---|---|---|
| TextCNN | 0.5456 | 0.2311 | 0.3246 | 0.0222 | |
| + | 0.7556 | 0.3224 | 0.4407 | 0.1584 | |
| ++ | 0.8403 | 0.6693 | 0.7449 | 0.5802 | |
| TexRNN | 0.5084 | 0.1814 | 0.2674 | 0.0192 | |
| + | 0.7963 | 0.3832 | 0.5174 | 0.2536 | |
| ++ | 0.7919 | 0.3605 | 0.4954 | 0.3300 | |
| TextRCNN | 0.5021 | 0.2265 | 0.3121 | 0.0264 | |
| + | 0.7378 | 0.2590 | 0.3766 | 0.1399 | |
| ++ | 0.8546 | 0.6167 | 0.7161 | 0.5563 |
| Model | Precision | Recall |
|---|---|---|
| TextCNN | 0.0188 | 0.0498 |
| TextRNN | 0.0169 | 0.0442 |
| TextRCNN | 0.0103 | 0.0269 |
| TextCNN+CBS | 0.2599 | 0.6369 |
| TextRNN+CBS | 0.2593 | 0.6617 |
| TextRCNN+CBS | 0.1943 | 0.4778 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Han, X.; Hao, X.; Zhu, T.; Shu, H. A Curriculum Batching Strategy for Automatic ICD Coding with Deep Multi-Label Classification Models. Healthcare 2022, 10, 2397. https://doi.org/10.3390/healthcare10122397
Wang Y, Han X, Hao X, Zhu T, Shu H. A Curriculum Batching Strategy for Automatic ICD Coding with Deep Multi-Label Classification Models. Healthcare. 2022; 10(12):2397. https://doi.org/10.3390/healthcare10122397
Chicago/Turabian StyleWang, Yaqiang, Xu Han, Xuechao Hao, Tao Zhu, and Hongping Shu. 2022. "A Curriculum Batching Strategy for Automatic ICD Coding with Deep Multi-Label Classification Models" Healthcare 10, no. 12: 2397. https://doi.org/10.3390/healthcare10122397