
A Multimodal Auxiliary Classification System for Osteosarcoma Histopathological Images Based on Deep Active Learning


Abstract
:1. Introduction
- (1)
- The system construction lacks enough labeled data, and the initial training set is insufficient [15]. Insufficient labeled data will greatly limit the performance of intelligent diagnostic systems based on supervised learning.
- (2)
- Lots of unlabeled pathology images. The data volume of histopathological images in hospital databases is very large. However, labeled data are scarce.
- (3)
- The cost of labeling samples is high. Due to the complexity of histopathological sections of bone and flesh, non-professionals cannot distinguish them. Only relying on professional pathologists to mark samples is costly and difficult.
- (1)
- This paper builds an osteosarcoma classification system based on active learning and histopathology images. The system utilizes the fitting ability of deep neural networks to achieve image classification. It not only improves the efficiency of pathologists but also contributes to the objective accuracy of diagnosis.
- (2)
- We combine generative adversarial networks (GAN) and active learning to obtain more high-value samples; GAN constructs high-quality pseudo-samples, and active learning obtains more unlabeled images with the “richest” information. This approach maximizes the performance of the model with a small number of labeled images. It effectively reduces the cost of labeling images, which is valuable in areas where there are not enough pathologists.
- (3)
- A new strategy that integrates the query sample class diversity and uncertainty is proposed. It effectively reduces the problems of sampling bias that often result from uncertainty-based sampling alone and the increased tagging costs that can result from considering diversity alone. This approach effectively improves the ability of the model to select samples.
- (4)
- Experimental results with osteosarcoma pathology images show that our system can achieve good classification performance with only a small number of labeled images. The results processed by the system can be used as an objective reference for clinical diagnosis and improve the detection accuracy of physicians.
2. Related Works
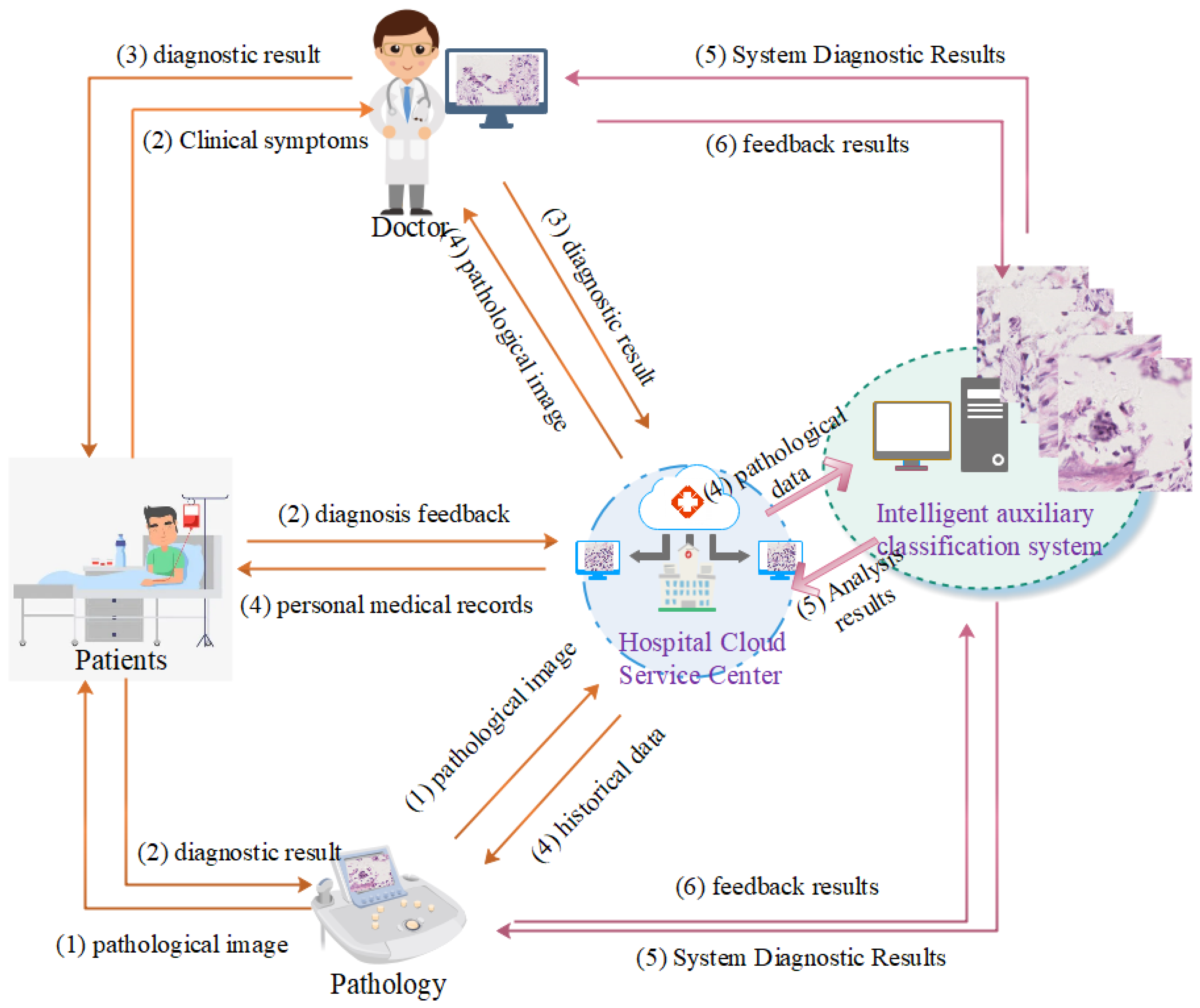
3. System Design
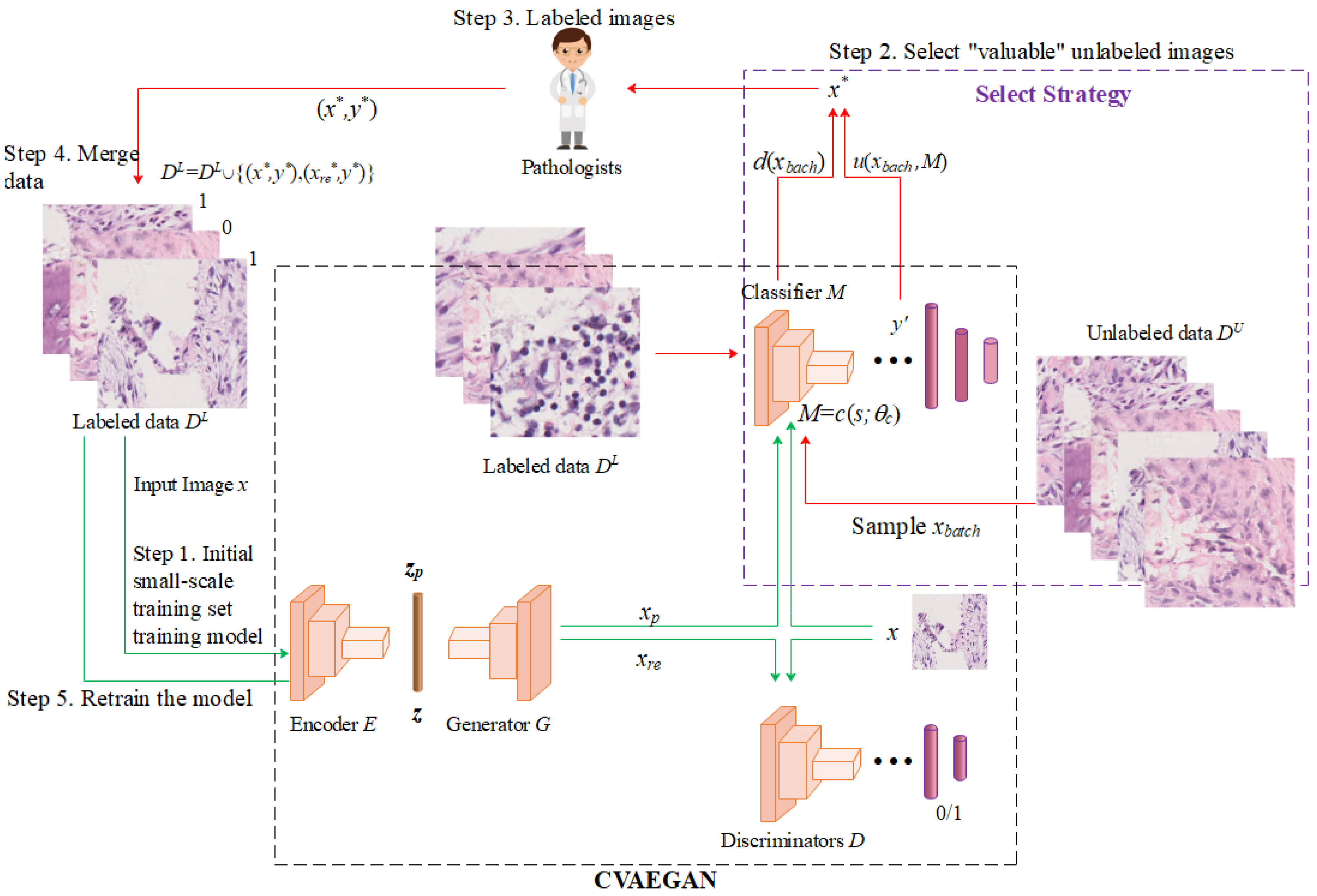
3.1. Models Design
- (1)
- Step 1: an initial small-scale labeled training set is used to train the neural network model, including encoder , generator , discriminator , and classifier .
- (2)
- Step 2: the most informative sample is selected from the large number of unlabeled samples.
- (3)
- Step 3: Pathology expert labeled data. After the pathology sample is labeled by the expert, it is put into the training set along with the reconstructed sample ( in Figure 2) for the next iteration of training.
- (4)
- Step 4 and Step 5: the selected sample data are merged into the original labeled dataset to retrain the classifier.
3.2. Selection Strategy
3.2.1. Uncertainty
3.2.2. Diversity
| Algorithm 1. Procedure of the proposed framework. | |
| Require: labeled dataset , unlabeled dataset | |
| Ensure: classifier | |
| 1: | Construct and initialize class classifier , encoder , generator , real/fake classifier |
| 2: | Train , , , with |
| 3: | while not satisfy condition do |
| 4: | randomly sample from |
| 5: | calculate according to (13) |
| 6: | select sample with the highest score |
| 7: | |
| 8: | for in do |
| 9: | query the label of from Oracle and get |
| 10: | |
| 11: | |
| 12: | |
| 13: | end for |
| 14: | retrain with by (2)–(8) |
| 15: | return |
4. Experiments and Results
4.1. Datasets and Configuration
- (1)
- Random selection (Random): the core idea of this strategy is that in each iteration, we randomly select samples to label.
- (2)
- BALD uncertainty-based strategy (denoted as BALD): in each iteration, we use BALD uncertainty to select samples for labeling.
- (3)
- (4)
- Strategy based on GAN reconstruction and BALD uncertainty (denoted as GAN + BALD): simultaneously train GAN and classifier, use BALD to select samples, and then augment the training set with reconstructed and selected images.
- (5)
- Strategy (our) based on the method proposed in this study: train the GAN and the classifier simultaneously, select samples using Equation (13), and then augment the training set with the reconstructed and selected images.
- (6)
- AIFT: It is a model that integrates active learning and transfer learning together. It is achieved by integrating active learning into fine-tuned CNNs in a continuous manner [64].
- (7)
- O-MedAL: It is a strategy that uses new labeled samples and a subset of previously labeled samples to increment the model and improve the MedAL model by introducing online learning methods [65].
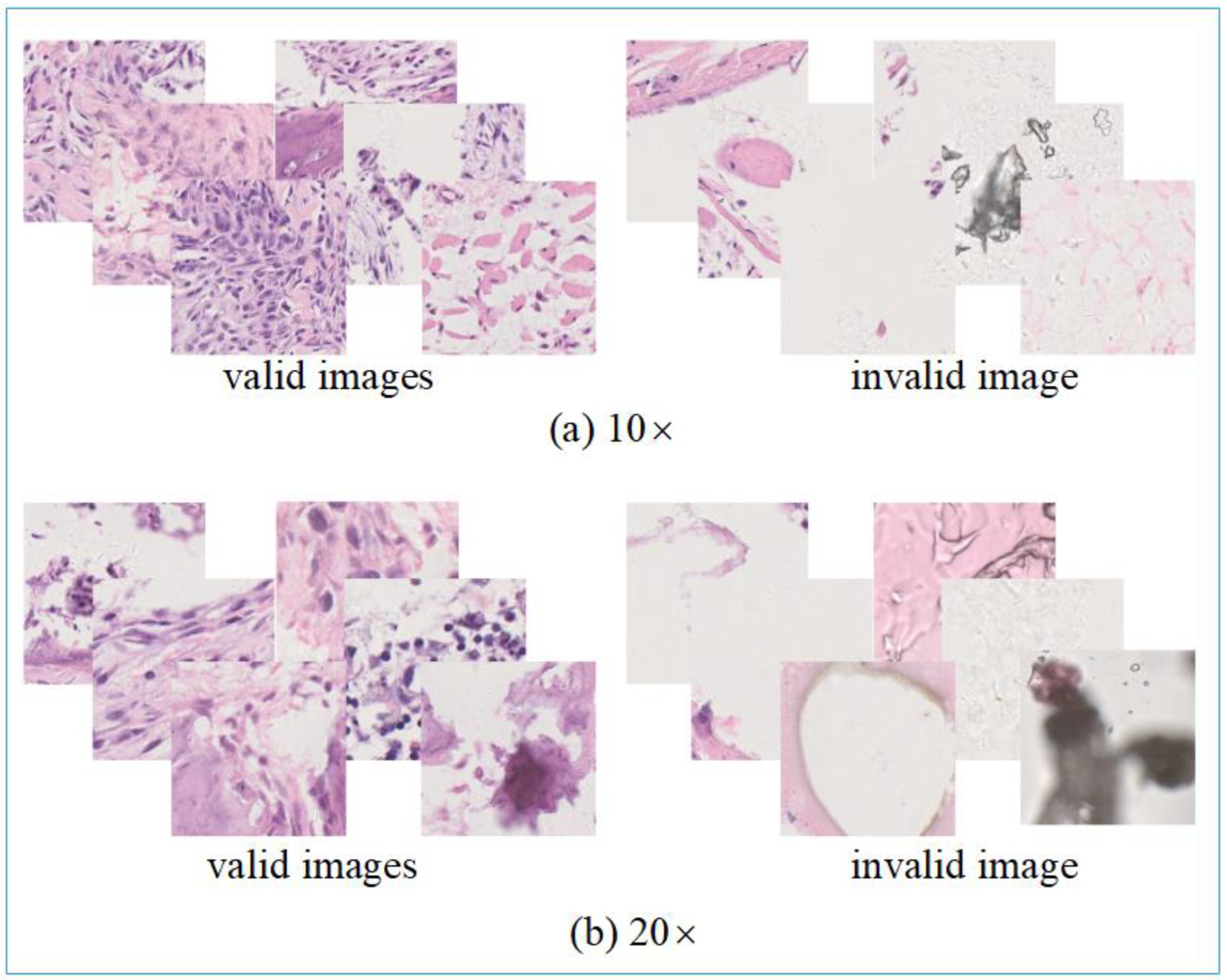
4.2. Data Processing
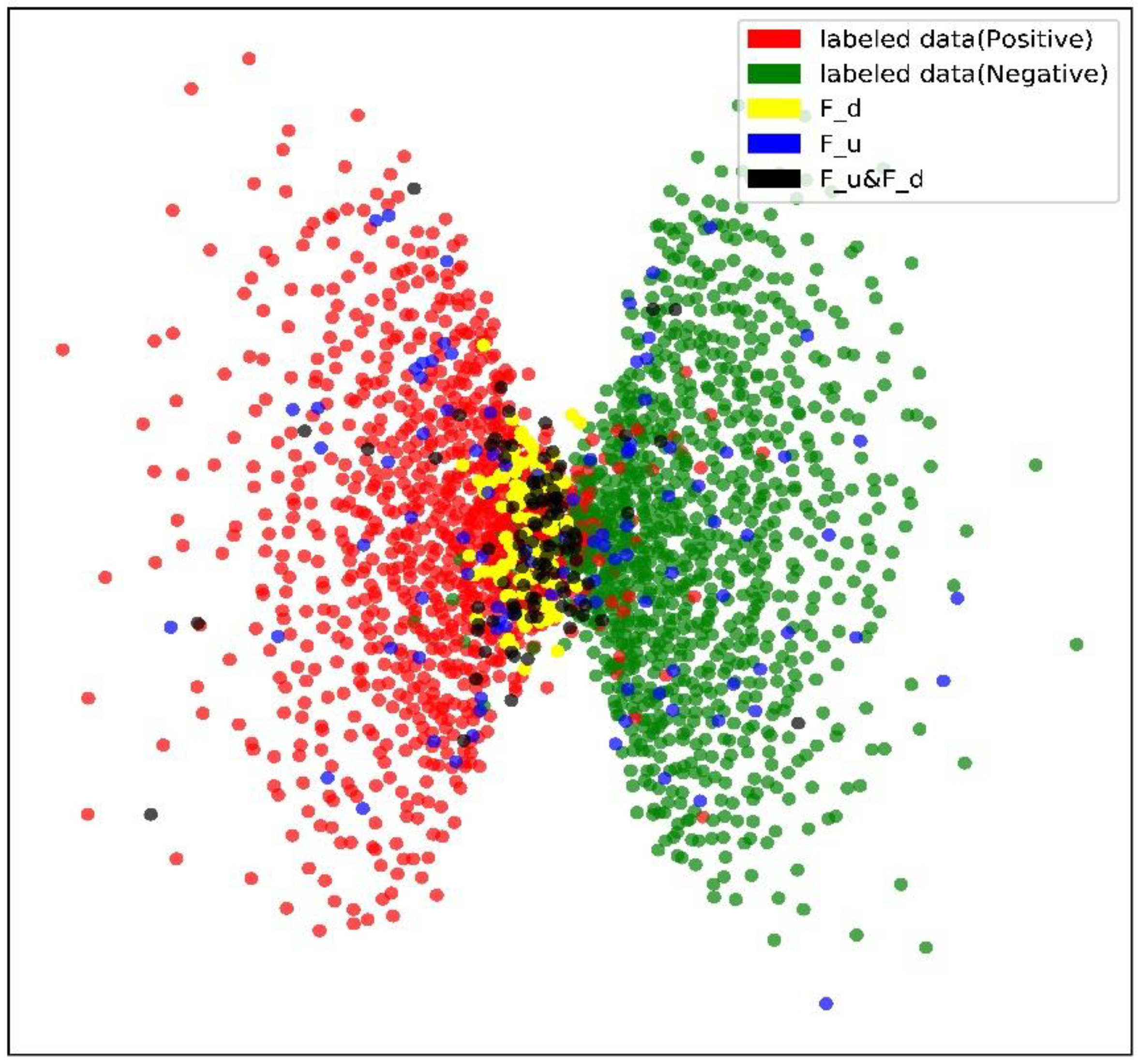
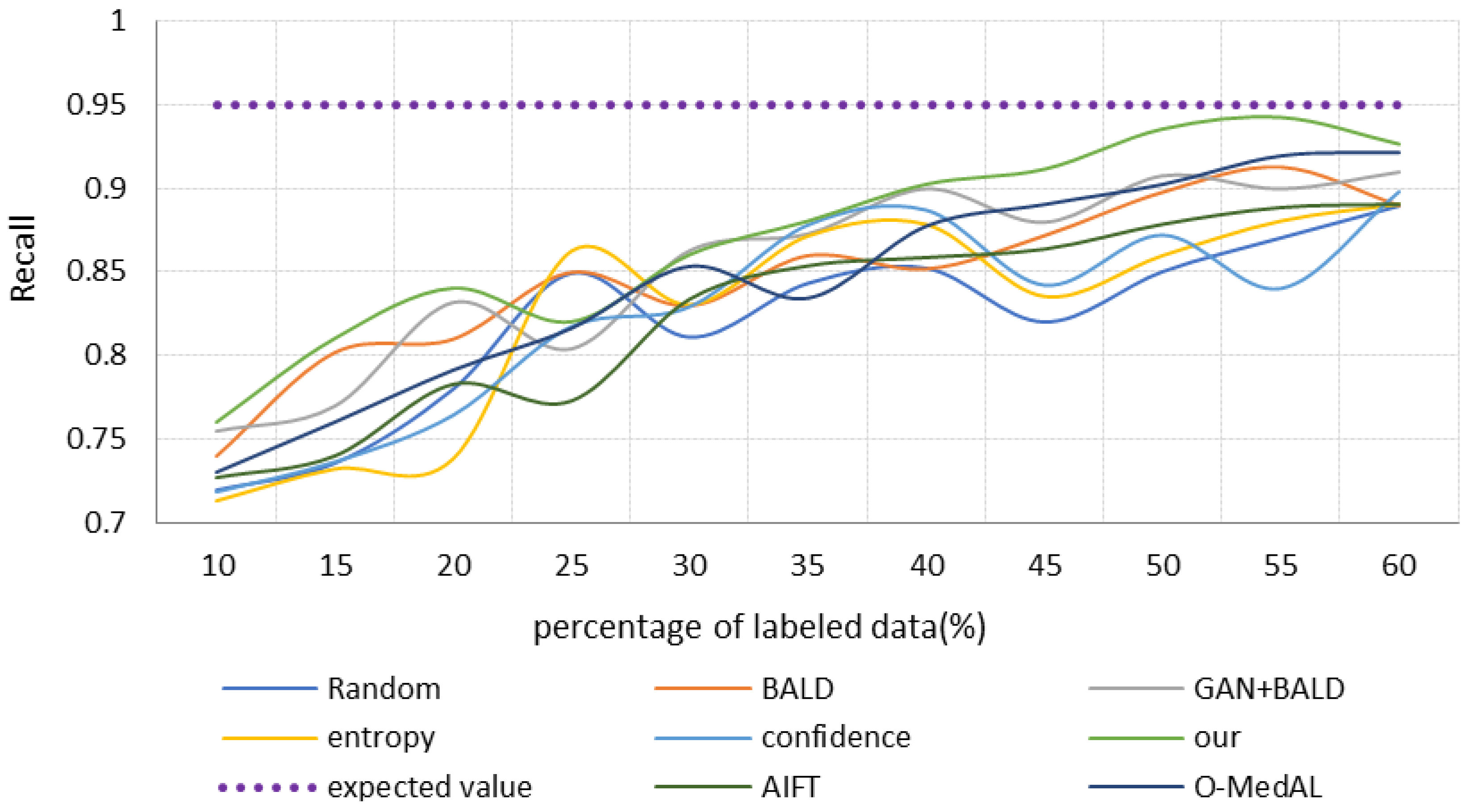
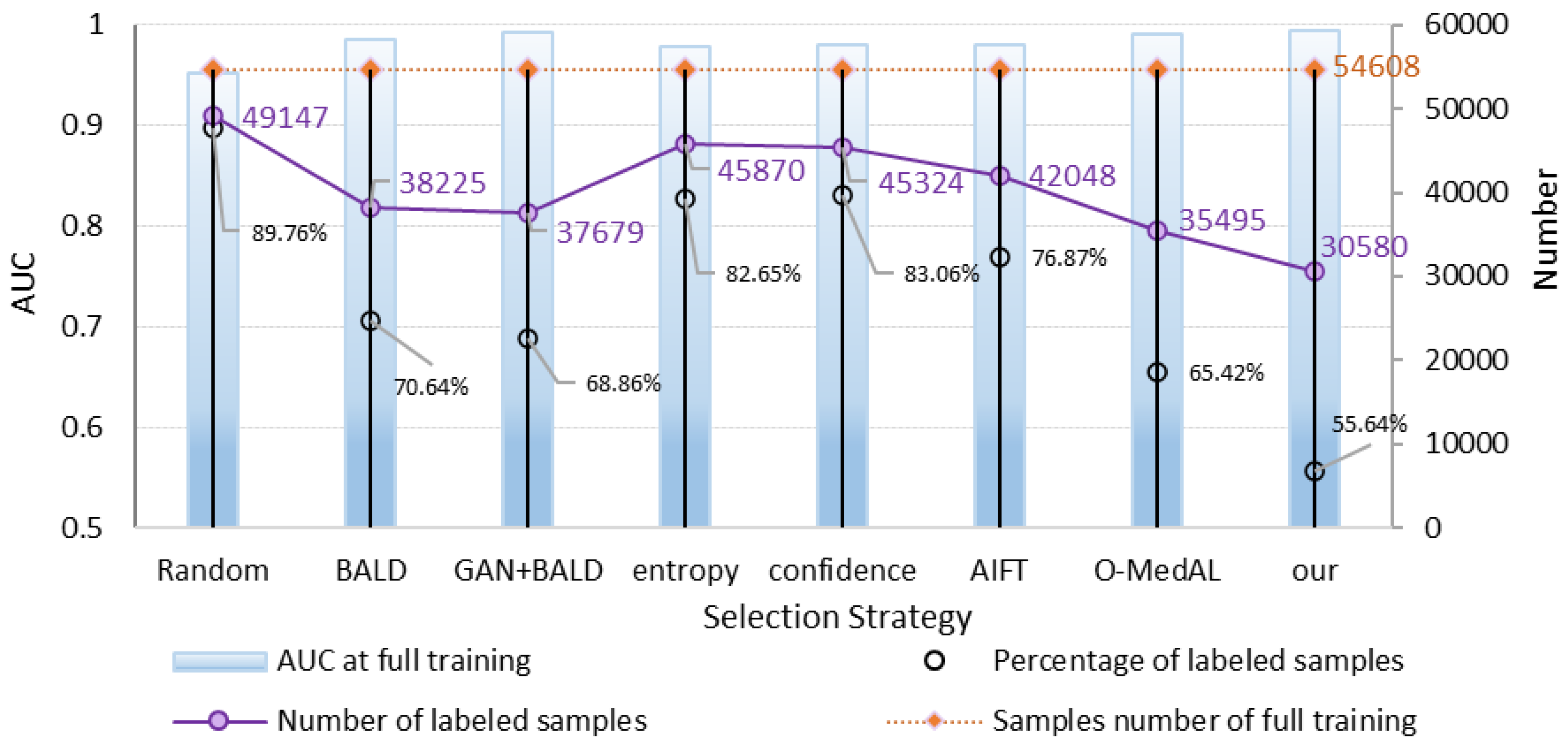
4.3. Results
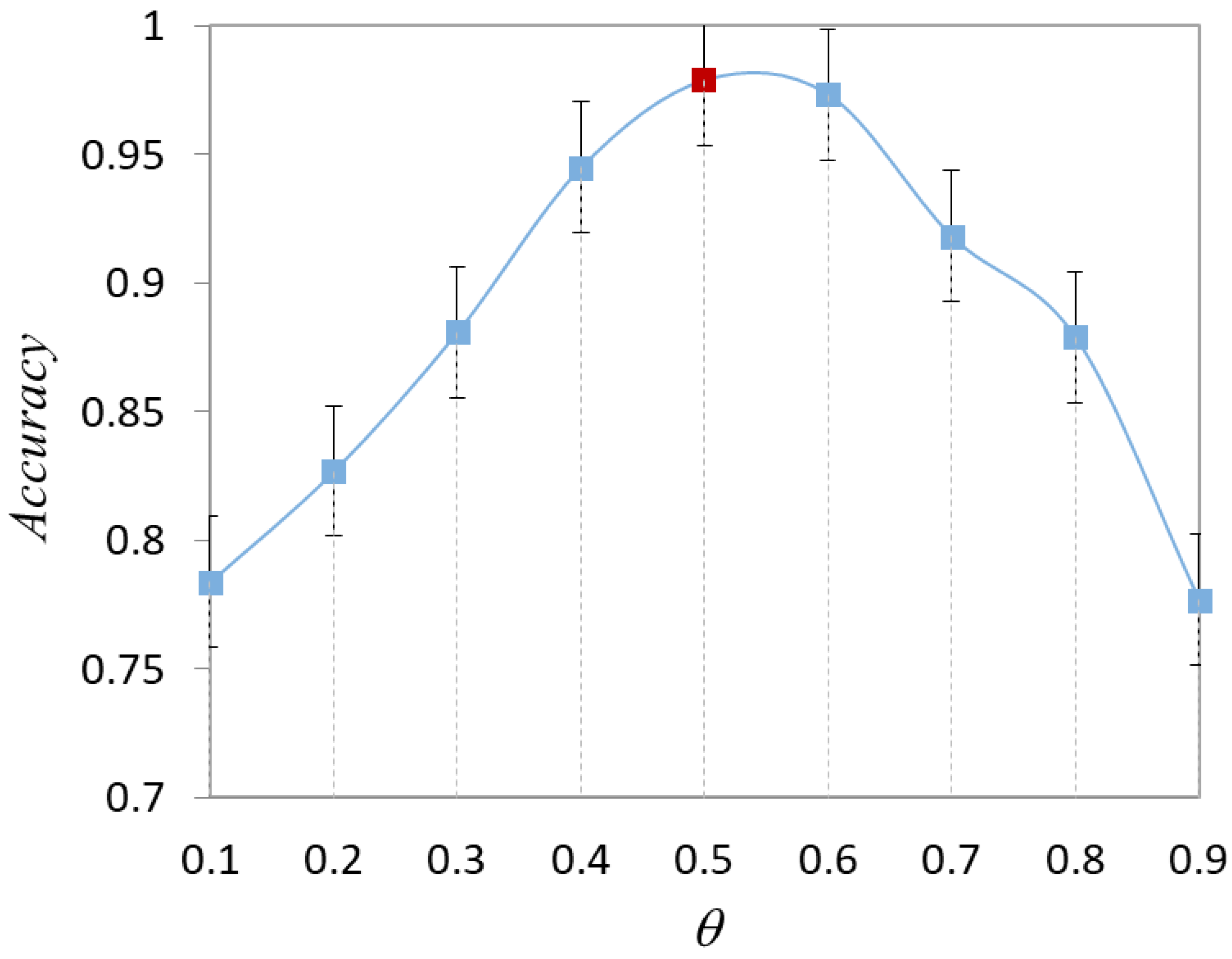
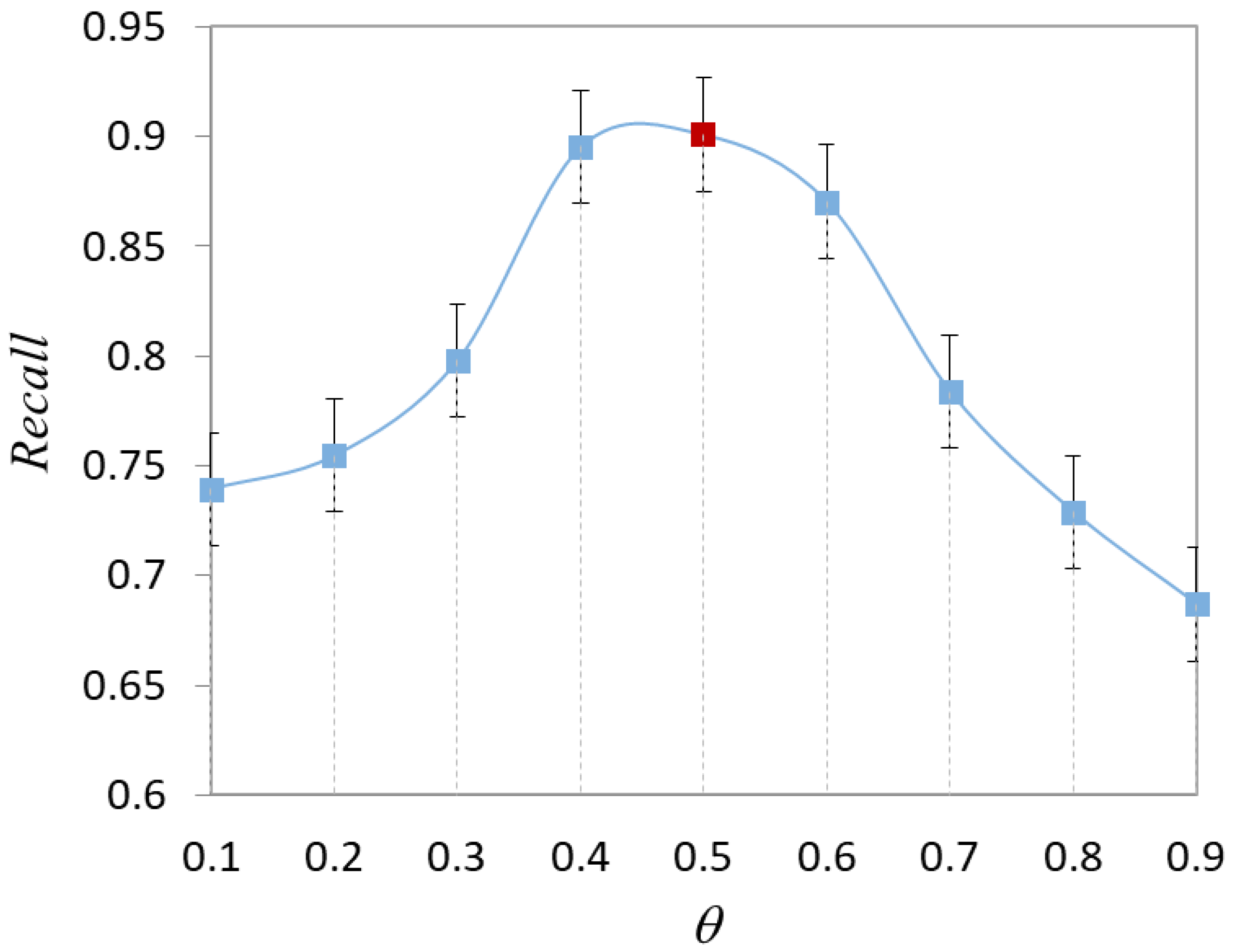
- (1)
- Validation of hyperparameters
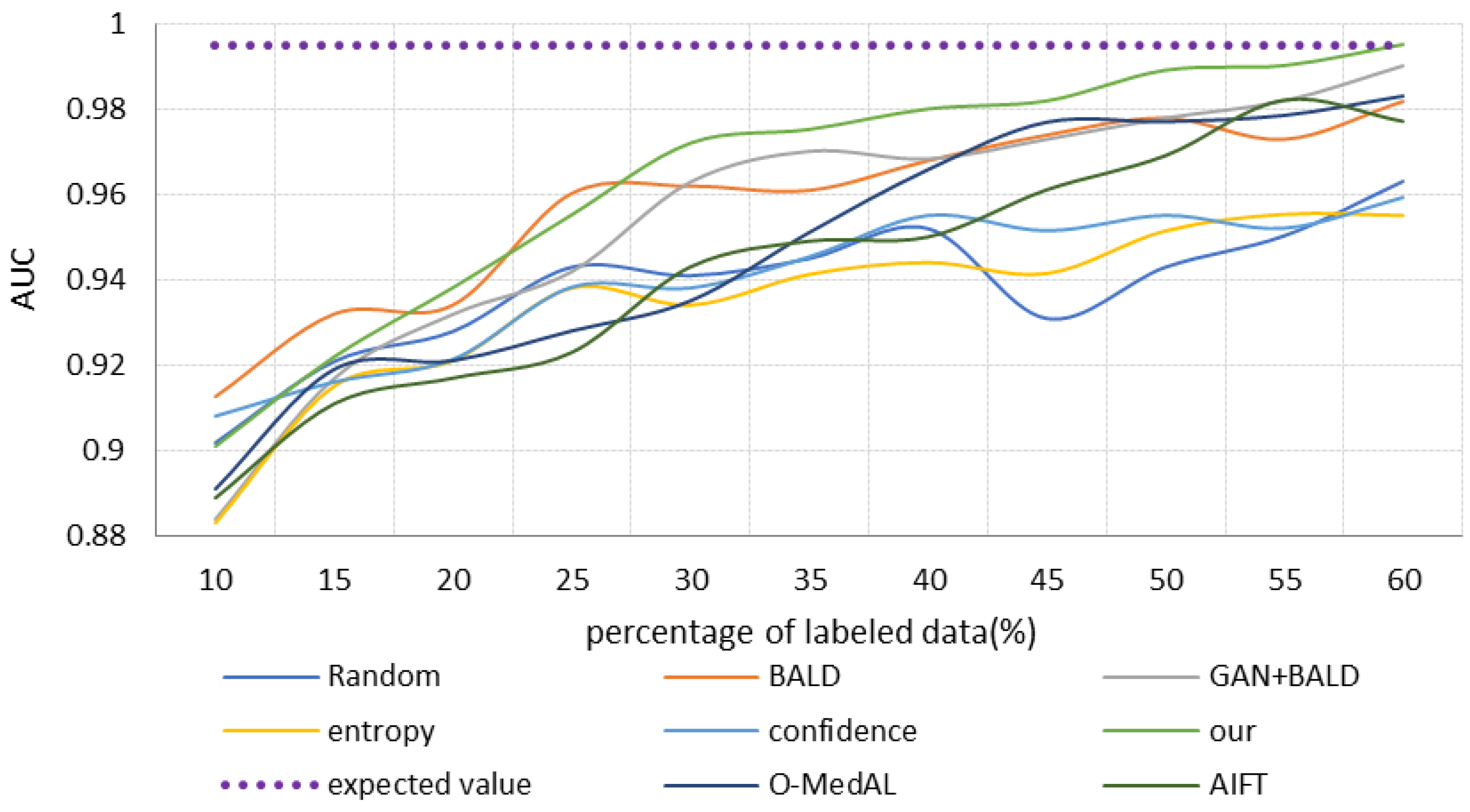
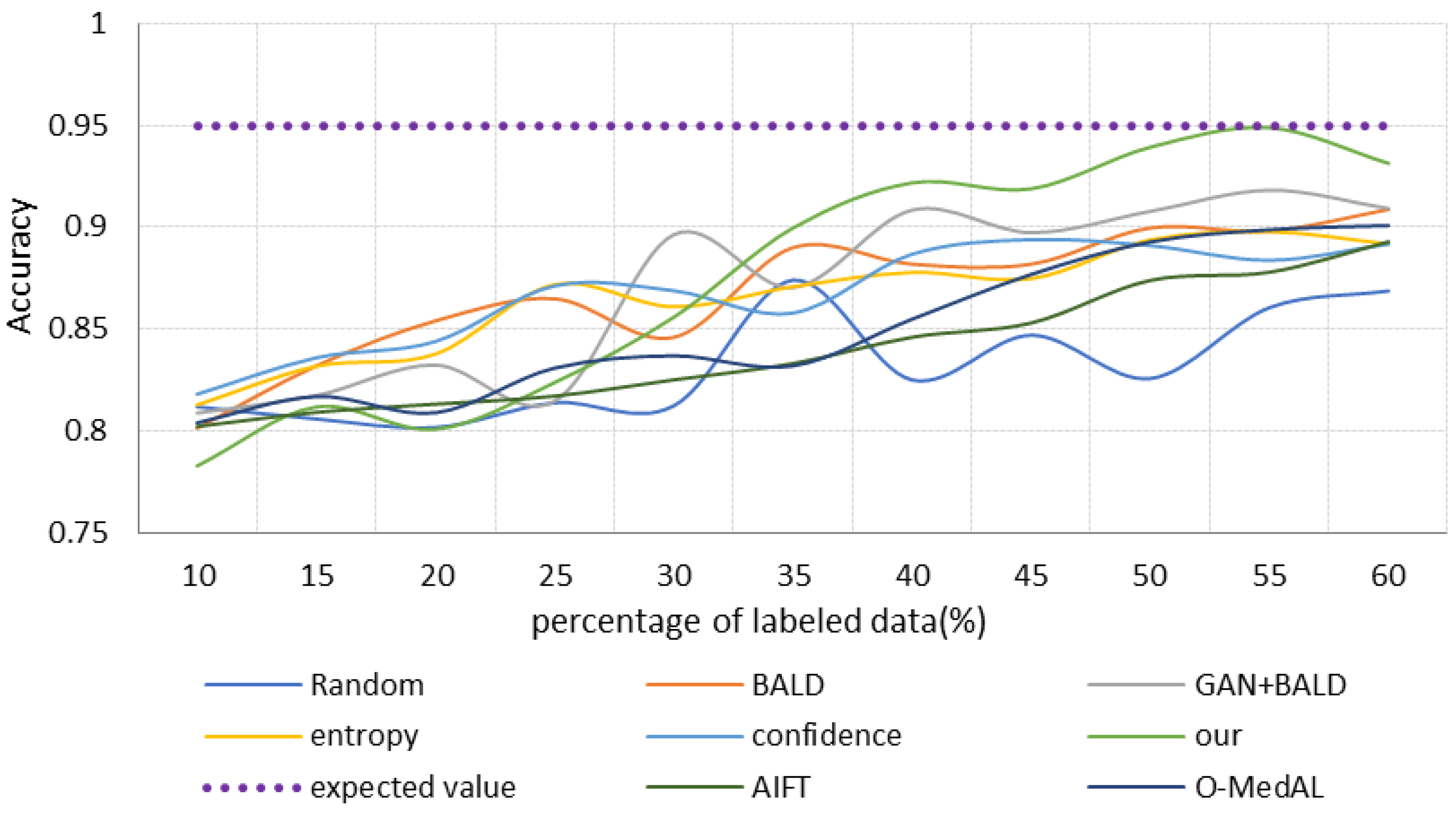
- (2)
- Analysis of the final results of model classification
- (3)
- Results of comparing different scaled datasets
- (4)
- Analysis of the results of physician verification
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, J.; Guo, Y.; Dai, Z. A medical assistant segmentation method for MRI images of osteosarcoma based on DecoupleSegNet. Int. J. Intell. Syst. 2022, 37, 8436–8461. [Google Scholar] [CrossRef]
- Eaton, B.R.; Schwarz, R.; Vatner, R.; Yeh, B.; Claude, L.; Indelicato, D.J.; Laack, N. Osteosarcoma. Pediatr. Blood Cancer 2021, 68 (Suppl. S2), e28352. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Gou, F.; Wu, J. An Attention-Preserving Network-Based Method for Assisted Segmentation of Osteosarcoma MRI Images. Mathematics 2022, 10, 1665. [Google Scholar] [CrossRef]
- Zhou, L.; Tan, Y. A Residual Fusion Network for Osteosarcoma MRI Image Segmentation in Developing Countries. Comput. Intell. Neurosci. 2022, 2022, 7285600. [Google Scholar] [CrossRef]
- Rathore, R.; van Tine, B.A. Pathogenesis and Current Treatment of Osteosarcoma: Perspectives for Future Therapies. J. Clin. Med. 2021, 10, 1182. [Google Scholar] [CrossRef]
- Wang, L.; Yu, L.; Zhu, J.; Tang, H. Auxiliary Segmentation Method of Osteosarcoma in MRI Images Based on Denoising and Local Enhancement. Healthcare 2022, 10, 1468. [Google Scholar] [CrossRef]
- Fei, F.; Harada, S.; Wei, S.; Siegal, G.P. Chapter 40—Molecular pathology of osteosarcoma. In Bone Sarcomas and Bone Metastases—From Bench to Bedside, 3rd ed.; Heymann, D., Ed.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 579–590. [Google Scholar]
- Chang, L.; Moustafa, N.; Bashir, A.K.; Yu, K. AI-Driven Synthetic Biology for Non-Small Cell Lung Cancer Drug Effectiveness-Cost Analysis in Intelligent Assisted Medical Systems. IEEE J. Biomed. Health Inform. 2022, 26, 5055–5066. [Google Scholar] [CrossRef]
- Roessner, A.; Lohmann, C.; Jechorek, D. Translational cell biology of highly malignant osteosarcoma. Pathol. Int. 2021, 71, 291–303. [Google Scholar] [CrossRef]
- Yu, G.; Chen, Z.; Tan, Y. Medical decision support system for cancer treatment in precision medicine in developing countries. Expert Syst. Appl. 2021, 186, 115725. [Google Scholar] [CrossRef]
- Wu, J.; Gou, F.; Tian, X. Disease Control and Prevention in Rare Plants Based on the Dominant Population Selection Method in Opportunistic Social Networks. Comput. Intell. Neurosci. 2022, 2022, 1489988. [Google Scholar] [CrossRef]
- Yang, W.; Luo, J.; Wu, J. Application of Information Transmission Control Strategy Based on Incremental Community Division in IoT Platform. IEEE Sens. J. 2021, 21, 21968–21978. [Google Scholar] [CrossRef]
- Xiao, P.; Huang, H.; Zhou, Z.; Dai, Z. An artificial intelligence multiprocessing scheme for the diagnosis of osteosarcoma MRI images. IEEE J. Biomed. Health Inform. 2022, 26, 4656–4667. [Google Scholar] [CrossRef]
- Roh, Y.; Heo, G.; Whang, S.E. A Survey on Data Collection for Machine Learning: A Big Data—AI Integration Perspective. IEEE Trans. Knowl. Data Eng. 2021, 33, 1328–1347. [Google Scholar] [CrossRef] [Green Version]
- Zhan, X.; Long, H.; Duan, X.; Kong, G. A Convolutional Neural Network-Based Intelligent Medical System with Sensors for Assistive Diagnosis and Decision-Making in Non-Small Cell Lung Cancer. Sensors 2021, 21, 7996. [Google Scholar] [CrossRef]
- Cho, J.W.; Kim, D.-J.; Jung, Y.; Kweon, I.S. MCDAL: Maximum Classifier Discrepancy for Active Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Lv, B.; Liu, F.; Gou, F.; Wu, J. Multi-Scale Tumor Localization Based on Priori Guidance-Based Segmentation Method for Osteosarcoma MRI Images. Mathematics 2022, 10, 2099. [Google Scholar] [CrossRef]
- Li, G.J.; Porter, M.A. A Bounded-Confidence Model of Opinion Dynamics with Heterogeneous Node-Activity Levels. arXiv 2022, arXiv:10.31235/osf.io/r6asm. Available online: https://osf.io/preprints/socarxiv/r6asm (accessed on 23 September 2022).
- Xiong, W.; Zhou, X. A Reputation Value-Based Task-Sharing Strategy in Opportunistic Complex Social Networks. Complexity 2021, 2021, 8554351. [Google Scholar] [CrossRef]
- Wu, J.; Yang, S.; Gou, F.; Zhou, Z.; Xie, P.; Xu, N.; Dai, Z. Intelligent Segmentation Medical Assistance System for MRI Images of Osteosarcoma in Developing Countries. Comput. Math. Methods Med. 2022, 2022, 7703583. [Google Scholar] [CrossRef]
- He, T.; Jin, X.; Ding, G.; Yi, L.; Yan, C. Towards Better Uncertainty Sampling: Active Learning with Multiple Views for Deep Convolutional Neural Network. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1360–1365. [Google Scholar]
- Nanda, S.K.; Ghai, D.; Ingole, P.; Pande, S. Soft Computing Techniques-based Digital Video Forensics for Fraud Medical Anomaly Detection. Comput. Assist. Methods Eng. Sci. 2022. [Google Scholar]
- Dharmale, S.G.; Gomase, S.A.; Pande, S. Comparative Analysis on Machine Learning Methodologies for the Effective Usage of Medical WSNs. In Proceedings of Data Analytics and Management, Proceedings of the International Conference on Data Analytics and Management, Polkowise, Poland, 26 June 2021; Springer: Singapore, 2022; pp. 441–457. [Google Scholar]
- Yadav, N.; Alfayeed, S.M.; Khamparia, A.; Pandey, B.; Thanh, D.N.; Pande, S. HSV model-based segmentation driven facial acne detection using deep learning. Expert Syst. 2022, 39, e12760. [Google Scholar] [CrossRef]
- Zhou, Z.; Tan, Y. A cascaded multi-stage framework for automatic detection and segmentation of pulmonary nodules in developing countries. IEEE J. Biomed. Health Inform. 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.-J.; Bento, J. Generative adversarial active learning. arXiv 2017, arXiv:1702.07956. Available online: https://arxiv.org/abs/1702.07956 (accessed on 24 August 2022).
- Tran, T.; Do, T.-T.; Reid, I.; Carneiro, G. Bayesian generative active deep learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6295–6304. [Google Scholar]
- Xue, Y.; Ye, J.; Zhou, Q.; Long, R.; Antani, S.; Xue, Z.; Cornwell, C.; Zaino, R.; Cheng, K.; Huang, X. Selective synthetic augmentation with HistoGAN for improved histopathology image classification. Med. Image Anal. 2021, 67, 101816. [Google Scholar] [CrossRef] [PubMed]
- George, K.; Faziludeen, S.; Sankaran, P.; Paul, J.K. Deep learned nucleus features for breast cancer histopathological image analysis based on belief theoretical classifier fusion. In TENCON 2019-2019 IEEE Region 10 Conference (TENCON), Proceedings of the IEEE Region 10 International Conference TENCON, Kochi, India, 17–20 October 2019; IEEE: New York, NY, USA, 2019; pp. 344–349. [Google Scholar]
- Gupta, V.; Bhavsar, A. Partially-Independent Framework for Breast Cancer Histopathological Image Classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1123–1130. [Google Scholar] [CrossRef]
- Wang, P.; Li, P.; Li, Y.; Wang, J.; Xu, J. Histopathological image classification based on cross-domain deep transferred feature fusion. Biomed. Signal Process. Control 2021, 68, 102705. [Google Scholar] [CrossRef]
- Nave, O. Adding features from the mathematical model of breast cancer to predict the tumour size. Int. J. Comput. Math. Comput. Syst. Theory 2020, 5, 159–174. [Google Scholar] [CrossRef]
- Sekhar, A.; Biswas, S.; Hazra, R.; Sunaniya, A.K.; Mukherjee, A.; Yang, L. Brain Tumor Classification Using Fine-Tuned GoogLeNet Features and Machine Learning Algorithms: IoMT Enabled CAD System. IEEE J. Biomed. Health Inform. 2022, 26, 983–991. [Google Scholar] [CrossRef]
- Wu, W.; Gao, L.; Duan, H.; Huang, G.; Ye, X.; Nie, S. Segmentation of pulmonary nodules in CT images based on 3D-UNET combined with three-dimensional conditional random field optimization. Medical Physics 2020, 47, 4054–4063. [Google Scholar] [CrossRef]
- Gur, S.; Wolf, L.; Golgher, L.; Blinder, P. Unsupervised microvascular image segmentation using an active contours mimicking neural network. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Korea, 27 October–2 November 2019; pp. 10722–10731. [Google Scholar]
- Ragland, B.D.; Bell, W.C.; Lopez, R.R.; Siegal, G.P. Cytogenetics and Molecular Biology of Osteosarcoma. Lab. Investig. 2002, 82, 365–373. [Google Scholar] [CrossRef] [Green Version]
- Mishra, R.; Daescu, O.; Leavey, P.; Rakheja, D.; Sengupta, A. Convolutional Neural Network for Histopathological Analysis of Osteosarcoma. J. Comput. Biol. 2017, 25, 313–325. [Google Scholar] [CrossRef]
- Anisuzzaman, D.M.; Barzekar, H.; Tong, L.; Luo, J.; Yu, Z. A deep learning study on osteosarcoma detection from histological images. Biomed. Signal Process. Control 2021, 69, 102931. [Google Scholar] [CrossRef]
- Shen, Y.; Dai, Z. Osteosarcoma MRI Image-Assisted Segmentation System Base on Guided Aggregated Bilateral Network. Mathematics 2022, 10, 1090. [Google Scholar] [CrossRef]
- Fu, Y.; Xue, P.; Ji, H.; Cui, W.; Dong, E. Deep Model with Siamese Network for Viability and Necrosis Tumor Assessment in Osteosarcoma. Med. Phys. 2019, 47, 4895–4905. [Google Scholar] [CrossRef] [PubMed]
- Barzekar, H.; Yu, Z. C-Net: A Reliable Convolutional Neural Network for Biomedical Image Classification. Expert Syst. Appl. 2020, 187, 116003. [Google Scholar] [CrossRef]
- D’Acunto, M.; Martinelli, M.; Moroni, D. From human mesenchymal stromal cells to osteosarcoma cells classification by deep learning. J. Intell. Fuzzy Syst. 2019, 37, 7199–7206. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Gou, F.; Tan, Y. A Staging Auxiliary Diagnosis Model for Nonsmall Cell Lung Cancer Based on the Intelligent Medical System. Comput. Math. Methods Med. 2021, 2021, 6654946. [Google Scholar] [CrossRef]
- Ouyang, T.; Yang, S.; Dai, Z. Rethinking U-Net from an Attention Perspective with Transformers for Osteosarcoma MRI Image Segmentation. Comput. Intell. Neurosci. 2022, 2022, 7973404. [Google Scholar] [CrossRef]
- Tian, X.; Yan, L.; Jiang, L.; Xiang, G.; Li, G.; Zhu, L.; Wu, J. Comparative transcriptome analysis of leaf, stem, and root tissues of Semiliquidambar cathayensis reveals candidate genes involved in terpenoid biosynthesis. Mol. Biol. Rep. 2022, 49, 5585–5593. [Google Scholar] [CrossRef]
- Cui, R.; Chen, Z.; Tan, Y.; Yu, G. A Multiprocessing Scheme for PET Image Pre-Screening, Noise Reduction, Segmentation and Lesion Partitioning. IEEE J. Biomed. Health Inform. 2021, 25, 1699–1711. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Triad link prediction method based on the evolutionary analysis with IoT in opportunistic social networks. Comput. Commun. 2022, 181, 143–155. [Google Scholar] [CrossRef]
- Wu, J.; Yu, L.; Gou, F. Data transmission scheme based on node model training and time division multiple access with IoT in opportunistic social networks. Peer-to-Peer Netw. Appl. 2022. [Google Scholar] [CrossRef]
- Long, H.; He, K. Effective Data Optimization and Evaluation Based on Social Communication with AI-Assisted in Opportunistic Social Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 4879557. [Google Scholar] [CrossRef]
- Qin, Y.; Li, X.; Yu, K. A management method of chronic diseases in the elderly based on IoT security environment. Comput. Electr. Eng. 2022, 102, 108188. [Google Scholar] [CrossRef]
- Ling, Z.; Yang, S.; Gou, F.; Dai, Z.; Wu, J. Intelligent Assistant Diagnosis System of Osteosarcoma MRI Image Based on Transformer and Convolution in Developing Countries. IEEE J. Biomed. Health Inform. 2022. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Gou, G.; Wu, J. Modified Data Delivery Strategy Based on Stochastic Block Model and Community Detection in Opportunistic Social Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 5067849. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Data Transmission Strategy Based on Node Motion Prediction IoT System in Opportunistic Social Networks. Wirel. Pers. Commun. 2022, 126, 1751–1768. [Google Scholar] [CrossRef]
- Wu, J.; Xia, J.; Gou, F. Information transmission mode and IoT community reconstruction based on user influence in opportunistic social networks. Peer-to-Peer Netw. Appl. 2022, 15, 1398–1416. [Google Scholar] [CrossRef]
- Deng, Y.; Gou, F.; Wu, J. Hybrid data transmission scheme based on source node centrality and community reconstruction in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 3460–3472. [Google Scholar] [CrossRef]
- Jiao, Y.; Qi, H. Capsule network assisted electrocardiogram classification model for smart healthcare. Biocybern. Biomed. Eng. 2022, 42, 543–555. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Zhou, Z.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J. Fine-Tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4761–4772. [Google Scholar]
- Shen, Y.; Gou, F.; Wu, J. Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks. Mathematics 2022, 10, 1669. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Message Transmission Strategy Based on Recurrent Neural Network and Attention Mechanism in Iot System. J. Circuits Syst. Comput. 2022, 31, 2250126. [Google Scholar] [CrossRef]
- Tian, X.; Wu, J. Optimal matching method based on rare plants in opportunistic social networks. J. Comput. Sci. 2022, 64, 101875. [Google Scholar] [CrossRef]
- Wu, J.; Liu, Z.; Gou, F.; Zhu, J.; Tang, H.; Zhou, X.; Xiong, W. BA-GCA Net: Boundary-Aware Grid Contextual Attention Net in Osteosarcoma MRI Image Segmentation. Comput. Intell. Neurosci. 2022, 2022, 3881833. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Wang, Y.; Belkacem, A.N.; Zhang, Q.; Xie, C.; Cao, Y.; Cheng, H.; Chen, S. Integrating Optimized Multiscale Entropy Model with Machine Learning for the Localization of Epileptogenic Hemisphere in Temporal Lobe Epilepsy Using Resting-State fMRI. J. Healthc. Eng. 2021, 2021, 1834123. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Shin, J.Y.; Gurudu, S.R.; Gotway, M.B.; Liang, J. Active, continual fine tuning of convolutional neural networks for reducing annotation efforts. Med. Image Anal. 2021, 71, 101997. [Google Scholar] [CrossRef] [PubMed]
- Smailagic, A.; Costa, P.; Gaudio, A.; Khandelwal, K.; Mirshekari, M.; Fagert, J.; Walawalkar, D.; Xu, S.; Galdran, A.; Zhang, P.; et al. O-MedAL: Online active deep learning for medical image analysis. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1353. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| The true sample | |
| Labeled data | |
| Unlabeled data | |
| Reconstructed samples | |
| Pseudo-samples | |
| Kullback–Leibler divergence operator | |
| The loss of discriminator D | |
| The loss of classifier | |
| The difference between distribution and posterior probability distribution of z | |
| The loss of generator | |
| The uncertainty of model to sample | |
| Shannon entropy | |
| The number of dropout iterations | |
| The probability that the sample is the class in the round of prediction | |
| The diversity score of the sample | |
| The distance from sample to category | |
| Trade-off factors for diversity and uncertainty |
| Selection Strategy | AUC | Accuracy | Recall |
|---|---|---|---|
| Random | 0.9546 | 0.9830 | 0.7729 |
| BALD | 0.9856 | 0.9829 | 0.7922 |
| GAN + BALD | 0.9931 | 0.9849 | 0.8743 |
| Entropy | 0.9786 | 0.9789 | 0.8598 |
| Confidence | 0.9804 | 0.9804 | 0.8526 |
| AIFT | 0.9807 | 0.9832 | 0.8712 |
| O-MedAL | 0.9918 | 0.9854 | 0.8894 |
| Our | 0.9950 | 0.9890 | 0.9080 |
| Percentage of Labeled Samples | True | Positive | Negative | |
|---|---|---|---|---|
| Predicted | ||||
| 10% | Positive | 21 | 24 | |
| Negative | 30 | 25 | ||
| 50% | Positive | 41 | 15 | |
| Negative | 11 | 33 | ||
| 100% | Positive | 46 | 5 | |
| Negative | 6 | 43 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gou, F.; Liu, J.; Zhu, J.; Wu, J. A Multimodal Auxiliary Classification System for Osteosarcoma Histopathological Images Based on Deep Active Learning. Healthcare 2022, 10, 2189. https://doi.org/10.3390/healthcare10112189
Gou F, Liu J, Zhu J, Wu J. A Multimodal Auxiliary Classification System for Osteosarcoma Histopathological Images Based on Deep Active Learning. Healthcare. 2022; 10(11):2189. https://doi.org/10.3390/healthcare10112189
Chicago/Turabian StyleGou, Fangfang, Jun Liu, Jun Zhu, and Jia Wu. 2022. "A Multimodal Auxiliary Classification System for Osteosarcoma Histopathological Images Based on Deep Active Learning" Healthcare 10, no. 11: 2189. https://doi.org/10.3390/healthcare10112189