
An Application of p-Fibonacci Error-Correcting Codes to Cryptography

Abstract
:1. Introduction
2. Related Works
Our Contribution
3. Preliminaries
3.1. p-Fibonacci Error Correcting Codes
- The n-th power of is given by:where is the Fibonacci p-number.
- ,
- ,
- , and .
- 1.
- ,
- 2.
- ,
- 3.
- .
- ,
- ,
- .
- 1.
- Given such that and , it is possible to find and such that .
- 2.
- Given , there exist and such that .
- It is sufficient to take as the identity matrix and or and as the identity matrix.
- It is sufficient to take and .
3.2. Zero-Knowledge Identification Protocols
4. Veron Identification Protocol in the Fibonacci Setting
4.1. Description of the Protocol
Commitment Compression
4.2. Zero-Knowledge Properties
4.2.1. Completeness
4.2.2. Soundness
- such that and ;
- such that , , , and ;
- such that and .
- From preimages: ,
- From preimages: ,
- From preimages: , and .
- if or 1:
- −
- pick randomly the values
![Mathematics 09 00789 i001]() ,
, ![Mathematics 09 00789 i001]() such that , F
such that , F ![Mathematics 09 00789 i001]() ,such that .
,such that . - −
- Compute .
- −
- If , reveal .If , reveal .
Verification follows. - if or 2:
- −
- pick randomly the values
![Mathematics 09 00789 i001]()
![Mathematics 09 00789 i001]() ,
, ![Mathematics 09 00789 i001]() .
. - −
- Compute .
- −
- If , reveal .If , reveal .
Verification follows. - if or 2:
- −
- pick randomly the values
![Mathematics 09 00789 i001]()
![Mathematics 09 00789 i001]() such that ,
such that ,![Mathematics 09 00789 i001]() , such that
, such that - −
- Compute .
- −
- If , reveal .If , reveal .
Verification follows.

4.2.3. Zero-Knowledge
- chooses randomly
![Mathematics 09 00789 i001]()
![Mathematics 09 00789 i001]() such that , and
such that , and ![Mathematics 09 00789 i001]() such that .also chooses corresponding to the challenge it is trying to guess.
such that .also chooses corresponding to the challenge it is trying to guess.- If , sends such that:.
- If , sends such that:.
- If , sends such that:.
- chooses .
- If , sends .If , sends .If , sends .
- If , the execution provides a valid transcript ( verifies correctly), and saves the execution. Otherwise, restarts the execution.
- : the simulated transcript contains , while the real one ;
- : the simulated transcript contains , while the real one ;
- : the simulated transcript contains , while the real one .
5. Comparisons
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Toy Example
- If , then the prover sends:The verifier returns TRUE, that is identification success, if:The response step costs 48 bits, because it is given by plus a matrix in .
- If , then the prover sends:Then, the verifier returns TRUE if:The response step cost is 288 bits, since is given by the three matrices in .
- If , then the prover sends:The verifier returns TRUE if:The response step cost 48 bits as in the case of .
References
- Stern, J. A new identification scheme based on syndrome decoding. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 22–26 August 1993; pp. 13–21. [Google Scholar]
- Véron, P. Improved identification schemes based on error-correcting codes. Appl. Algebra Eng. Commun. Comput. 1997, 8, 57–69. [Google Scholar] [CrossRef] [Green Version]
- Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schwabe, P.; Seiler, G.; Stehle, D.; Bai, S. CRYSTALS-Dilithium: Algorithm Specifications and Supporting Documentation; 2020. Available online: https://pq-crystals.org/ (accessed on 5 April 2021).
- Bindel, N.; Akleylek, S.; Alkim, E.; Barreto, P.S.; Buchmann, J.; Eaton, E.; Gutoski, G.; Kramer, J.; Longa, P.; Polat, H.; et al. Submission to NIST’s Post-Quantum Project: Lattice-Based Digital Signature Scheme qTESLA; 2019. Available online: https://qtesla.org/ (accessed on 5 April 2021).
- Chen, M.S.; Hülsing, A.; Rijneveld, J.; Samardjiska, S.; Schwabe, P. MQDSS Specifications; Version 2.0; 2019. Available online: http://mqdss.org/ (accessed on 5 April 2021).
- Chase, M.; Derler, D.; Goldfeder, S.; Orlandi, C.; Ramacher, S.; Rechberger, C.; Slamanig, D.; Katz, J.; Wang, X.; Kolesnikov, V.; et al. The Picnic Signature Algorithm Specification; Version 3.0; 2020. Available online: https://microsoft.github.io/Picnic/ (accessed on 5 April 2021).
- NIST. Round 1 Submissions. 2018. Available online: https://csrc.nist.gov/Projects/Post-Quantum-Cryptography/Round-1-Submissions (accessed on 5 April 2021).
- Boorghany, A.; Jalili, R. Implementation and Comparison of Lattice-based Identification Protocols on Smart Cards and Microcontrollers. IACR Cryptol. ePrint Arch. 2014, 2014, 78. [Google Scholar]
- Bellini, E.; Caullery, F.; Hasikos, A.; Manzano, M.; Mateu, V. You Shall Not Pass!(Once Again) An IoT Application of Post-quantum Stateful Signature Schemes. In Proceedings of the 5th ACM on ASIA Public-Key Cryptography Workshop, Incheon, Korea, 4 June 2018; pp. 19–24. [Google Scholar]
- Cayrel, P.L.; Véron, P.; Alaoui, S.M.E.Y. A zero-knowledge identification scheme based on the q-ary syndrome decoding problem. In Proceedings of the International Workshop on Selected Areas in Cryptography, Waterloo, ON, Canada, 12–13 August 2010; pp. 171–186. [Google Scholar]
- Dagdelen, Ö.; Galindo, D.; Véron, P.; Alaoui, S.M.E.Y.; Cayrel, P.L. Extended security arguments for signature schemes. Des. Codes Cryptogr. 2016, 78, 441–461. [Google Scholar] [CrossRef]
- Gaborit, P.; Schrek, J.; Zémor, G. Full cryptanalysis of the chen identification protocol. In Proceedings of the International Workshop on Post-Quantum Cryptography, Taipei, Taiwan, 29 November–2 December 2011; pp. 35–50. [Google Scholar]
- Aguilar, C.; Gaborit, P.; Schrek, J. A new zero-knowledge code based identification scheme with reduced communication. In Proceedings of the Information Theory Workshop (ITW), Paraty, Brazil, 16–20 October 2011; pp. 648–652. [Google Scholar]
- Bellini, E.; Caullery, F.; Hasikos, A.; Manzano, M.; Mateu, V. Code-Based Signature Schemes from Identification Protocols in the Rank Metric. In Proceedings of the International Conference on Cryptology and Network Security, Naples, Italy, 30 September–3 October 2018; pp. 277–298. [Google Scholar]
- Bellini, E.; Caullery, F.; Gaborit, P.; Manzano, M.; Mateu, V. Improved Veron Identification and Signature Schemes in the rank metric. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1872–1876. [Google Scholar]
- Bellini, E.; Gaborit, P.; Hasikos, A.; Mateu, V. Enhancing Code Based Zero-Knowledge Proofs Using Rank Metric. In Proceedings of the International Conference on Cryptology and Network Security, Vienna, Austria, 14–16 December 2020; pp. 570–592. [Google Scholar]
- Stakhov, A.P. Fibonacci matrices, a generalization of the Cassini formula, and a new coding theory. Chaos Solitons Fractals 2006, 30, 56–66. [Google Scholar] [CrossRef]
- Basu, M.; Prasad, B. The generalized relations among the code elements for Fibonacci coding theory. Chaos Solitons Fractals 2009, 41, 2517–2525. [Google Scholar] [CrossRef]
- Esmaili, M.; Esmaeili, M. A Fibonacci–polynomial based coding method with error detection and correction. Comput. Math. Appl. 2010, 60, 2738–2752. [Google Scholar] [CrossRef] [Green Version]
- Esmaili, M.; Moosavi, M.; Gulliver, T.A. A new class of Fibonacci sequence based error-correcting codes. Cryptogr. Commun. 2017, 9, 379–396. [Google Scholar] [CrossRef]
- Bellini, E.; Marcolla, C.; Murru, N. On the decoding of 1-Fibonacci error-correcting codes. Discret. Math. Algorithms Appl. 2020. [Google Scholar] [CrossRef]
- Pless, V.S.; Huffman, W.; Brualdi, R.A. Handbook of Coding Theory; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Berlekamp, E.; McEliece, R.; Van Tilborg, H. On the inherent intractability of certain coding problems (Corresp.). IEEE Trans. Inf. Theory 1978, 24, 384–386. [Google Scholar] [CrossRef]
- Aguilar, C.; Blazy, O.; Deneuville, J.C.; Gaborit, P.; Zémor, G. Efficient Encryption from Random Quasi-Cyclic Codes. arXiv 2016, arXiv:1612.05572. [Google Scholar]
- Katz, J.; Menezes, A.J.; Van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- May, A.; Ozerov, I. On computing nearest neighbors with applications to decoding of binary linear codes. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 26–30 April 2015; pp. 203–228. [Google Scholar]
- Aragon, N.; Gaborit, P.; Hauteville, A.; Tillich, J.P. A new algorithm for solving the rank syndrome decoding problem. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2421–2425. [Google Scholar]
- Chabaud, F.; Stern, J. The cryptographic security of the syndrome decoding problem for rank distance codes. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Seoul, Korea, 23–24 November 1996; pp. 368–381. [Google Scholar]
- Ourivski, A.V.; Johansson, T. New technique for decoding codes in the rank metric and its cryptography applications. Probl. Inf. Transm. 2002, 38, 237–246. [Google Scholar] [CrossRef]
- Gaborit, P.; Ruatta, O.; Schrek, J. On the complexity of the rank syndrome decoding problem. IEEE Trans. Inf. Theory 2016, 62, 1006–1019. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
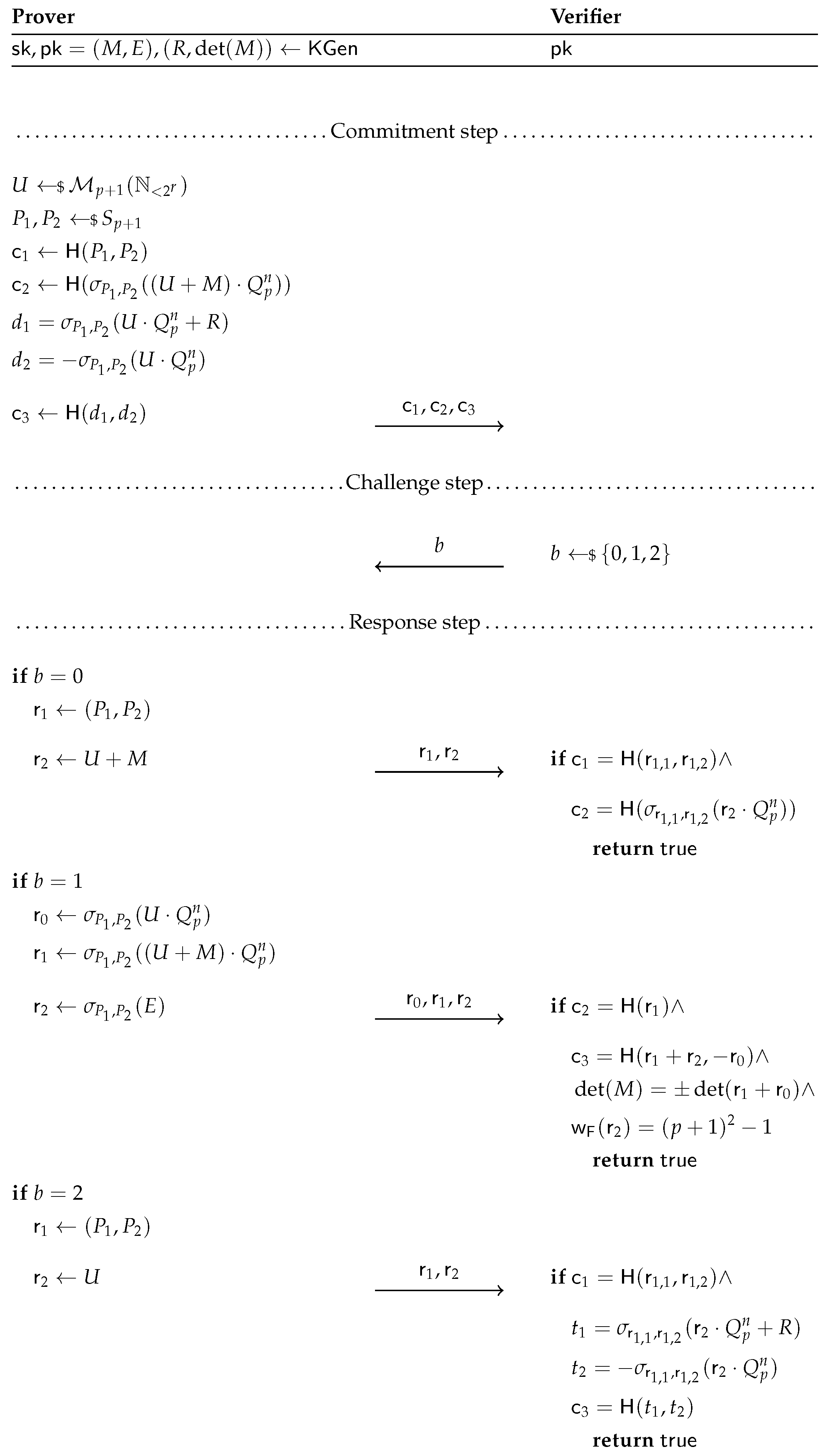{kind=link}
| Hamming | Rank | ||||
|---|---|---|---|---|---|
| Code | Fibonacci | GL [2] | DC [13] | GL [14] | DC [15] |
| Best known attack A | [19], | [26] | [27] | ||
| Code parameters | |||||
| Public param.size | |||||
| n | n | ||||
| Rsp.step cost | |||||
| Response step cost | |||||
| Concrete parameters for | |||||
| 130 | 128 | 128 | 124 | 124 | |
| Code parameters | ( 2, 20, 22) | ( 2, 1320, 660, 140) | ( 2, 1320, 140) | ( 2, 31, 26, 13, 8) | ( 2, 31, 26, 8) |
| Public param. size | 10 | 435,601 | 1321 | 5242 | 809 |
| 5292 | 1980 | 1980 | 1209 | 1209 | |
| 4410 | 1320 | 1320 | 806 | 806 | |
| Rsp. step cost | 1066 | 14,343 | 14,343 | 2040 | 2040 |
| Rsp. step cost . | 13,230 | 2640 | 2640 | 1612 | 1612 |
| Concrete parameters for | |||||
| 96 | 96 | 96 | 95 | 95 | |
| Code parameters | ( 2, 16, 18) | ( 2, 990, 495, 110) | ( 2, 990, 110) | ( 2, 29, 22, 11, 7) | ( 2, 29, 22, 7) |
| Public param. size | 10 | 245,026 | 991 | 3511 | 640 |
| 3468 | 1485 | 1485 | 957 | 957 | |
| 2890 | 990 | 990 | 638 | 638 | |
| Rsp. step cost | 717 | 10,346 | 10,346 | 1644 | 1644 |
| Rsp. step cost . | 8670 | 1980 | 1980 | 1276 | 1276 |
| Concrete parameters for | |||||
| 80 | 80 | 80 | 78 | 78 | |
| Code parameters | ( 2, 14, 16) | ( 2, 826, 413, 90) | ( 2, 826, 90) | ( 2, 23, 22, 11, 6) | ( 2, 23, 22, 6) |
| Public param. size | 9 | 170,570 | 827 | 2785 | 508 |
| 2475 | 1239 | 1239 | 759 | 759 | |
| 2025 | 826 | 826 | 506 | 506 | |
| Rsp. step cost | 567 | 8416 | 8416 | 1266 | 1266 |
| Rsp. step cost . | 6075 | 1652 | 1652 | 1012 | 1012 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellini, E.; Marcolla, C.; Murru, N. An Application of p-Fibonacci Error-Correcting Codes to Cryptography. Mathematics 2021, 9, 789. https://doi.org/10.3390/math9070789
Bellini E, Marcolla C, Murru N. An Application of p-Fibonacci Error-Correcting Codes to Cryptography. Mathematics. 2021; 9(7):789. https://doi.org/10.3390/math9070789
Chicago/Turabian StyleBellini, Emanuele, Chiara Marcolla, and Nadir Murru. 2021. "An Application of p-Fibonacci Error-Correcting Codes to Cryptography" Mathematics 9, no. 7: 789. https://doi.org/10.3390/math9070789