1. Introduction
One of the first issues in data mining and pattern recognition is an economy representation of implicitly specified massive data arrays with the subsequent extraction of specific features and classification [
1,
2,
3]. Every element of the data set can be associated with a vector of which the components are the numerical values of certain properties of the phenomenon of interest under one or another operating condition. As a rule, a complete description of the data is not available due to high dimensions and cardinality, and the very absence of an explicit “generating” mechanism. Instead, a representative enough sample from the data set may be considered, leading to a point representation of the respective continuum domain, and the desired characteristics can then be measured just at these sample points.
There exist many ways to organize such samples. The most obvious one is to arrange a deterministic rectangular grid over the respective many-dimensional domain. However, this approach suffers several drawbacks. First, for high dimensions, the density of the grid needed for a reasonable representation of the set is very large; second, it can be efficiently implemented only for box-shaped sets; finally, sets that differ from rectangles may be embedded into larger boxes, however, the so-called rejection rate (the amount of “idle” grid points lying outside the domain of interest) may grow very quickly with the growth of dimension. A more efficient technique relates to the generation of quasi-random points in the feasible domain; they are also referred to as
sequences introduced in [
4]; however, this mechanism heavily exploits the box shape of the set. For the discussion of these questions, see [
5] and the references therein.
Since recently, a purely randomized approach to the solution of various problems in the above-mentioned fields became very popular [
6]. The overall idea is to embed a deterministic formulation of the problem into a stochastic setup and to obtain an approximate solution, which is “close” to that of the original problem with certain probability. Often, such a reformulation considerably diminishes computational efforts; moreover, the associated probabilities can be efficiently estimated. This is particularly important for many-dimensional problems involving massive data arrays and containing various uncertainties and inaccuracies.
As compared to deterministic techniques, straightforward random sampling can be applied to a much wider class of sets; still, its application is limited to “regular” sets in a sense, for example, such as those bounded in some vector or matrix norm [
6]. However, it often happens that the only information about the set is available in the form of the so-called
boundary oracle, which is formulated as follows. Given a point inside the set and an arbitrary line through it, the oracle returns the intersection points of this line and the boundary of the set. The term “boundary oracle” introduced presumably in [
7] originates in the optimization theory, where various assumptions on the available information about the function under minimization and the constraint set lead to estimates of complexity of the corresponding optimization methods [
8,
9]. For instance, search methods assume just the knowledge of the function value at any point; in first-order methods, the derivative is also available, i.e., we possess the
gradient oracle; in second-order methods, on top of that we also have a
Hessian oracle. The same goes for the constraint set, for which various assumptions (such as membership oracle, separation oracle) are adopted [
9].
One of the efficient sampling procedures that are based on the availability of boundary oracles is the Hit-and-Run (HR) algorithm, which was proposed in [
10] with the primary goal to facilitate numerical calculation of multi-dimensional integrals over convex domains. It became popular after the publication of [
11], and later, various modifications and ramifications of this algorithm were proposed; for example, see [
12,
13]. In particular, a promising Markov chain sampler, the
billiard walk exploits “reflections” of a moving particle from the boundary of a convex set. It was deeply analyzed in [
14] and showed itself rather efficient; however, it requires not only the availability of a boundary oracle but also the information about the curvature of the boundary, and is more time-consuming in implementation.
The basic HR procedure is very simple in implementation and requires little information about the problem. It was proved to have a polynomial
mixing time; i.e., the number of iterations required to “approximately” reach the desired theoretical distribution grows polynomially in the dimension [
12]. In applications, it possesses quite fast practical convergence for so-called isotropic sets. It also can be generalized to deal with non-convex sets and to produce limiting distributions that differ from the uniform one. At the same time, the algorithm is not free of drawbacks. First, the proved theoretical convergence is very slow. Also, the method tends to get stuck at the corners of “thin” non-isotropic sets; on the other hand, there exist modifications of the HR algorithm, which are capable of escaping the corners [
15].
Overall, the Hit-and-Run is widely considered to be one of the preferred practical and theoretical tools for uniform sampling inside large-dimensional convex bodies; for example, see [
14,
16,
17]. Moreover, in [
17], a comparison tool was proposed to quantify the performance of several commonly used Markov chain sampling techniques, and it turned out that the basic HR procedure outperforms other approaches and is less intensive computationally.
Those interested in the history of the HR algorithm are referred to [
10,
11,
12]; later developments can be found in [
18] and also in [
19,
20], where a promising modification using barrier functions was proposed; of the most recent papers we mention [
17,
21,
22].
The HR algorithm has found applications in random sampling inside various sets (non-convex and not connected as well), approximate computation of the volume of convex sets [
23] and, most efficiently, in the probabilistic approach to numerical optimization. For the latter, see, for example, [
24,
25], where the authors proposed new versions of the cutting plane scheme for use in efficient methods of optimization. Namely, the HR points were generated with the aim of approximating the center of gravity of the support set of the optimized function. Other applications include random walks in graph spaces [
26], machine learning [
16,
27], etc. In particular, for a specific determinantal point process problem, a version of the HR sampler based on the zonotopic structure of the problem was proposed in [
16]. This approach, though being faster than the conventional HR, requires solving additional linear programs and is not easy to implement.
However, in spite of a wide range of applications of the Hit-and-Run sampler, to the best of our knowledge, almost no research was devoted to its use in control. Perhaps the only paper in this direction is [
28], where this method was applied to the design of stabilizing controllers in the simplest form.
In this paper we do not deal with applications of the HR to specific control problems; this is the subject for future research. Nor do we analyze the convergence and optimization of the performance of the HR algorithm. Instead, we limit ourselves to the considerations related to its BO component, and propose several numerical schemes for the implementation of this component.
In principle, instead of having a BO, the availability of a weaker membership oracle might be assumed, and a straightforward line search can then be used. However, this search has to be performed many times, so that it is important to provide a “closed-form” solution to this operation in order to improve the performance of the algorithm. By closed-form solution we also mean various numerical procedures such as finding the roots of a polynomial or the eigenvalues of a matrix, solving semidefinite programs (SDPs) of moderate size and the like. These operations are indeed very fast and numerically efficient in the standard Matlab implementation.
In this paper, we propose efficient computations of several BOs for various vector and matrix sets defined by linear matrix inequalities (LMIs).
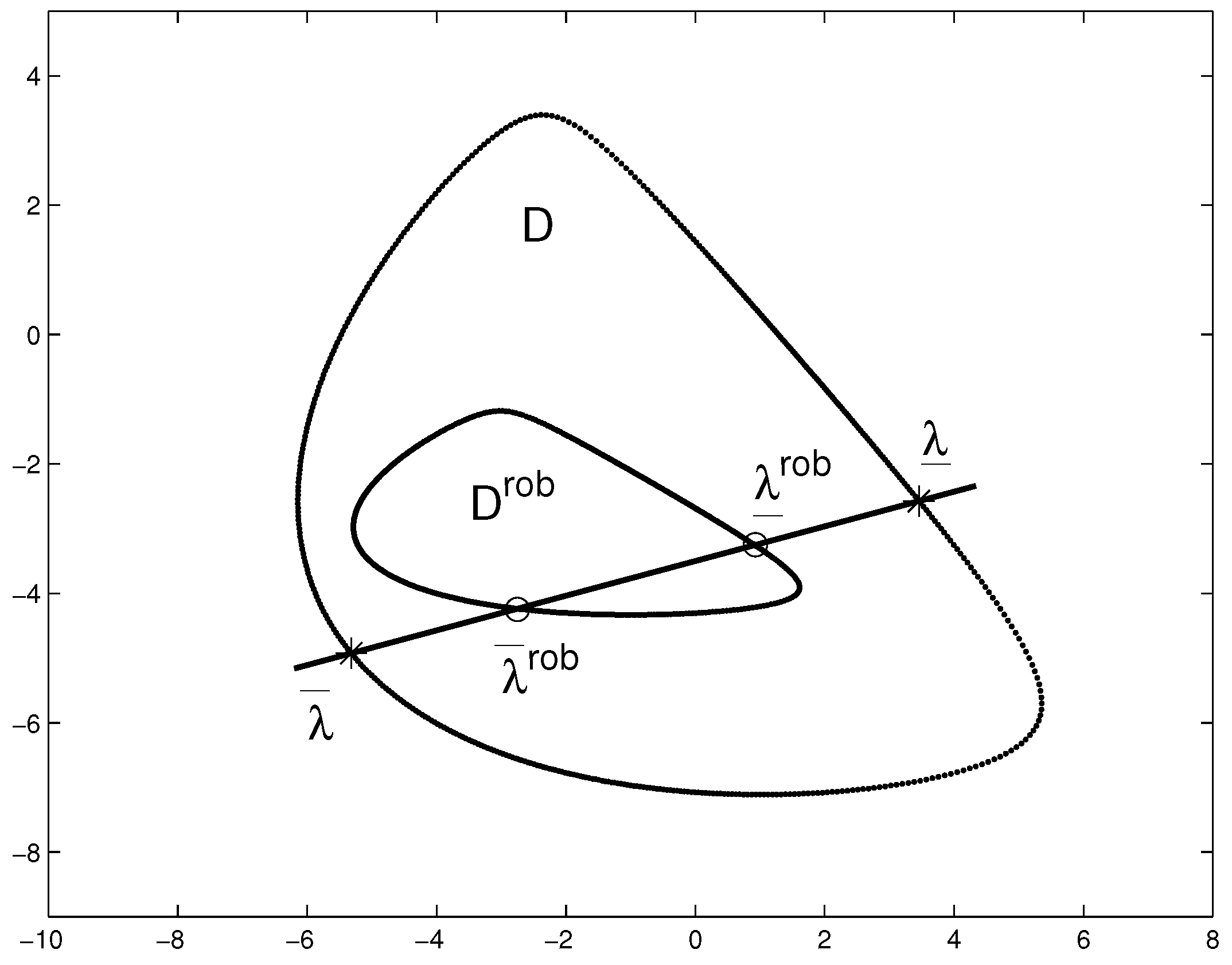
The sets that we analyze in the paper appear in control problems in a natural way, and we consider sets specified by LMIs in the canonical form, the classical matrix Lyapunov inequality, and algebraic matrix Riccati inequalities. We also pay attention to various robust versions of these inequalities, where the matrix coefficients contain additive uncertainty.
We focus on the sets defined by LMIs because of the generality and flexibility of this technique and it is wide spread in systems theory; see the classical book [
29] and the recent survey paper [
30]. Overall, LMI-sets describe a wast variety of convex sets. Notably, because of convexity, only two intersection points are to be found.
One of the few works in this research direction is the conference paper [
31], where first attempts were made to the implementation of such boundary oracles. Since then, possible applications of the HR algorithm became broader, and some of them motivated us to get back to this subject and consider it in a different context. For instance, one of the novel applications of this technique might be processing huge data arrays obtained from ultrasound computed tomography in medical diagnostics; for example, such as in [
32]. This may lead to fast image reconstruction algorithms and improve the quality of the image.
In the current paper several major changes are performed as compared to [
31]. The introduction section is completely re-written to better substantiate the importance of the research; for the same purpose, the order of the exposition and the overall wording is changed, the bibliography list is considerably extended to account for the new available developments, some proofs are added and some of them are corrected and made more transparent, several mathematical inaccuracies in the exposition are also corrected, many new notations are introduced to facilitate the understanding of the material, and typos are removed.
The notation used in the paper is very standard. Namely, and denote the space of real column vectors of length n and real matrices; is the transposition sign; ⊕ and ⊗ stand for the Kronecker sum and Kronecker product of two matrices; the signs denote the negative (positive) definiteness (semidefiniteness) of a matrix; is the Euclidean vector norm or the spectral or the Frobenius matrix norm (this will be clear from the context); is the matrix square root of the positive-definite matrix W.
We use the following acronyms:
BO—Boundary Oracle;
HR—Hit-and-Run;
LMI—Linear Matrix inequality;
LQR—Linear Quadratic Regulation;
SDP—SemiDefinite Programming.
2. Background and an Illustration
2.1. The Hit-and-Run Procedure
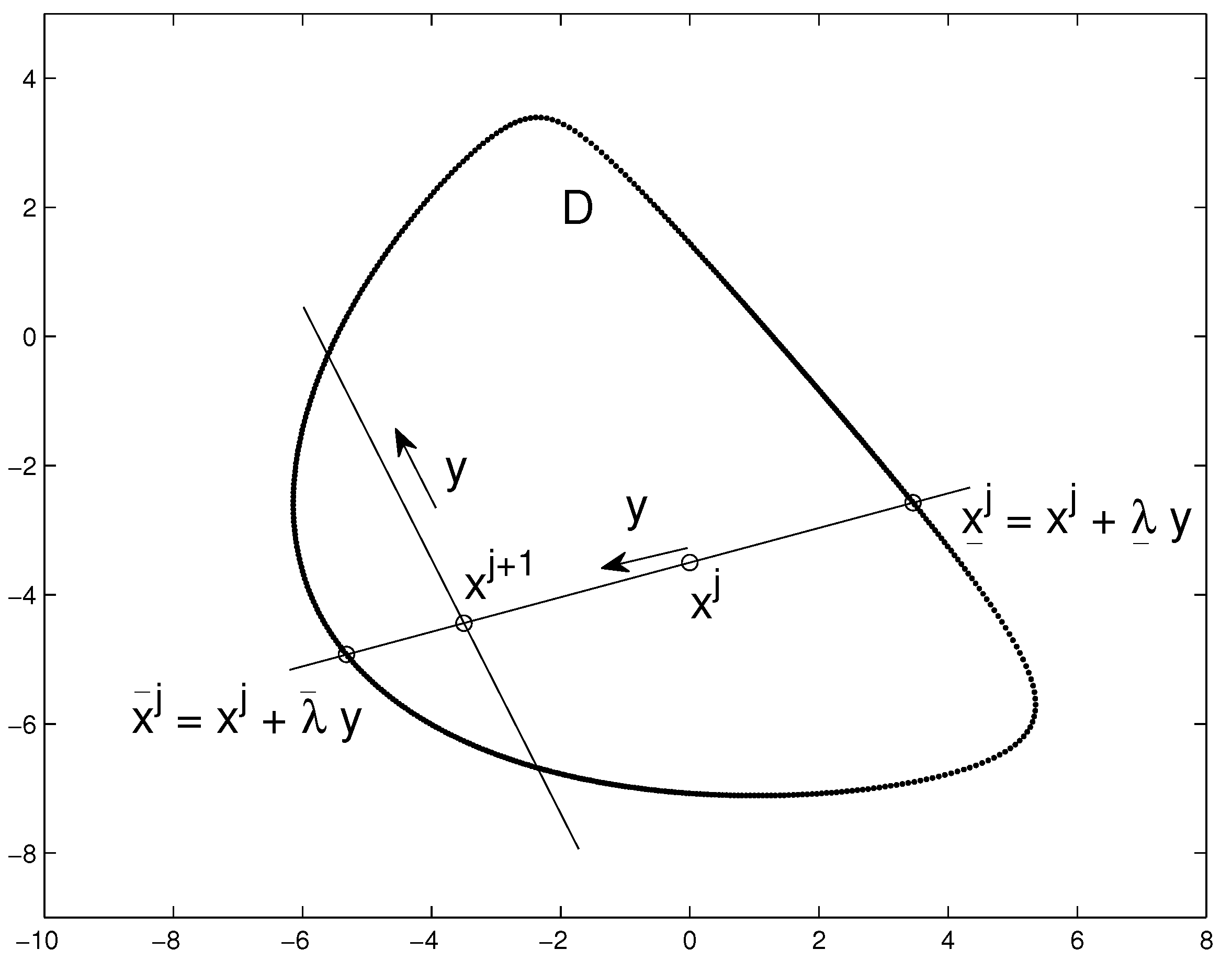
We briefly formulate the main components of the HR procedure as applied to convex sets and uniform distributions.
Denote by
an initial point in the interior of a closed convex bounded domain
, and let
denote the point generated at the
jth step of the procedure. The next point is generated as follows. First, a random unit-length vector
is generated uniformly on the sphere in
and the line
through this point in the direction
y is considered. Denote by
and
the points of intersection of this line and the boundary of
; they are assumed to be obtained with the use of BO. Then the next point
is generated uniformly randomly on the segment
, a new random direction is generated, etc. The scheme of the HR algorithm is presented in
Figure 1 for
.
In the HR-related literature it is shown that, under mild conditions on the set and the choice of initial , the resulting sequence of random points tend to the uniform distribution over as the number of points grow.
It is interesting to note that the HR method and particularly, its BO component can be used not only for generating points
inside sets, but also for approximate point description of the
boundary of implicitly specified sets. This description is obtained at no extra cost by simply memorizing the “side-product” endpoints
and
. We note that there exist specialized methods that generate points exactly on the boundary of the sets of interest [
33].
2.2. Illustration: Static Output Feedback Stabilization
Let us consider a linear time invariant system in the state-space description
Here the system matrices , , are fixed and known. Assume that there exists a static output control that makes the closed-loop matrix Hurwitz stable, and let the set of all such stabilizing gain matrices K be bounded. A typical control problem is to optimize certain “engineering” performance indices over the set of these matrix gains, such as overshoot, oscillation, damping time.
First, it is well known that the very existence of a stabilizing output feedback is hard to establish [
34], not talking about optimizing such a control. Second, the engineering performance indices mentioned above are not easy to formalize and optimize even in a much simpler situation where
state feedback is considered.
As an alternative to the existing techniques we can instead arrange random sampling over the domain
, compute the value of the performance index for each sample, and pick the best one. This approach to optimal controller design suggests the availability of a representative enough sample set in
, and it can be obtained by using the HR-algorithm. In its simplest form this approach was considered in [
35,
36], where only low-order controllers were considered and the domain
was two-dimensional. No random sampling was used, but the authors suggested to pick a point in
with a mouse on the computer screen and compute the respective performance index. Such a “manual” semi-heuristic approach, being very simple, often leads to controllers that outperform those obtained by the methods available in the literature.
To arrange the HR algorithm in the general many-dimensional setting, assume that we possess a feasible , denote by a matrix direction, take instead of K, and consider the -dependent matrix , where . Then the goal of the BO is to find the minimum and maximum values of that guarantee the stability of over the whole segment .
To further simplify notation, denote
and
; then we have
, where
is stable. Hence, the boundary oracle reduces to finding the so-called unidirectional stability segment of maximum length [
37].
For the clarity of the overall exposition, we present the corresponding result.
Lemma 1 ([
37])
. Let , and let be Hurwitz stable. The minimal and the maximal values of the parameter that guarantee the stability of are defined bywhere are real eigenvalues of the matrix , and denotes the Kronecker sum. We recall that the Kronecker sum of the two square matrices A and B is defined as , where are identity matrices of appropriate dimensions and ⊗ stands for the Kronecker product of matrices.
Back to our problem, we see that the matrix segment obtained with the use of the lemma above belongs to the set of output stabilizing gain matrices. Therefore, the next matrix (i.e., the next HR point) is then generated randomly on this segment.
Unfortunately, in Lemma 1 one has to compute eigenvalues of matrices, which makes computations slow for high dimensions. For instance, already for , the computations would take about a second on a standard laptop, which is considered rather slow, keeping in mind multiple executions of this procedure as required in the HR-algorithm. On the other hand, (i) typically, problems arising in control are of lower dimensions, and (ii) the availability of boundary oracle can be relaxed to the assumption of having a membership oracle, so that a boundary oracle can always be constructed by means of a linear search. However, for a wide range of problems, a boundary oracle can be easily formulated in closed form, and below we present particular boundary oracles for matrix sets specified by linear matrix inequalities.
6. Implementation Issues
We briefly discuss some technical implementation issues and report on the processor time required for the computation of the boundary oracles proposed above.
First, to generate a vector uniformly distributed on the surface of the unit ball in
, we use the
Matlab routine
randn to obtain a random vector
y with the standard Gaussian distribution and then normalize it to obtain
, which is distributed uniformly on the unit sphere. As far as the generation of
matrix directions
Y in
Section 4 and
Section 5 is considered, we generate them randomly uniformly on the surface of the unit ball in the Frobenius norm (i.e., on the surface of the ball in
) with the subsequent symmetrization.
The main tool for computing the Lyapunov and Riccati BOs, Lemma 2 requires finding generalized eigenvalues of a pair of matrices, and it can be efficiently applied to matrices of rather high dimensions.
The robust boundary oracles in
Section 4.2 and
Section 5.2 require solving semidefinite programs in two scalar variables with LMI constraints having dimension
(Theorem 1) or
(Theorem 2). To solve these problems, we used the
Matlab-compatible software
cvx [
42].
The following illustrative experiment was performed. We generated randomly
samples of the data required in Lemma 2 and Theorems 1 and 2. For each of these samples, we measured the execution time for the four boundary oracles proposed in the paper, and averaged over
N samples. The results obtained on a standard laptop are presented in
Table 1.
From the first two rows of the table we see that nonrobust oracles are indeed very fast, since they exploit just the eigenvalue computation, and this operation is “perfectly” implemented in various available toolboxes. Instead, robust boundary oracles are based on solving a specific optimization problem, which is more time-consuming. The last row of the table clearly shows that up to , the robust Riccati oracle is fast enough, whereas for the required execution time is approximately one and a half second, which may be considered slow. Note however, that in the latter case, the matrices in the LMI constraints are of quite large size .
In the experiment, we considered “full” matrices and used the standard freeware
cvx for solving semidefinite programs. To speed up the computations in higher dimensions, one may exploit a sparse structure of the system matrices, which is typically the case for control problems, or try to use alternative optimization methods and software. On the other hand, practical control problems have lower dimensions, usually not exceeding
; see [
43], a popular collection of control-related test problems. In other words, in practice, all the proposed BOs seem to be fast enough to be used in sampling the respective sets.
Another observation is that the execution time grows nonlinearly with increase of problem dimension n. This is because the coefficient matrices in the respective LMIs contain elements and because of a specific representation of the LMI constraints in the internal language of cvx solvers. It is also seen that, for a given n, the execution time of the robust Riccati oracle is not exactly the same as that of the robust Lyapunov oracle for the doubled dimension (recall the relative sizes of the respective LMI constraints). This is because the structure of these constraints in the robust Riccati oracle is slightly more complicated.







{kind=link}
{kind=link}
{kind=link}