
Bayesian Analysis of Population Health Data



Abstract
:1. Introduction
2. Statistical Models
2.1. Logistic Regression
2.2. Accelerated Failure Time Survival Models
2.3. Bayesian Inference and the Integrated Nested Laplace Approximation
3. Analysis of Ischemic Stroke and Risk Factors in Poland
Bayesian Logistic and Survival Modeling
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AFT | Accelerated failure time |
| ATC | Anatomical therapeutic chemical |
| DIC | Deviance information criterion |
| ICAR | Intrinsic conditional auto-regressive |
| INLA | Integrated nested Laplace approximation |
| GMRF | Gaussian Markov random field |
| MCMC | Markov chain Monte Carlo |
| PID | Powiat index of deprivation |
| WAIC | Watanabe-Akaike information criterion |
References
- World Health Organization. The Top 10 Causes of Death. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 31 January 2021).
- Luengo-Fernandez, R.; Violato, M.; Candio, P.; Leal, J. Economic burden of stroke across Europe: A population-based cost analysis. Eur. Stroke J. 2020, 5, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Feigin, V.; Norrving, B.; George, M.; Foltz, J.; Roth, G.; Mensah, G. Prevention of stroke: A strategic global imperative. Nat. Rev. Neurol. 2016, 12, 501–512. [Google Scholar] [CrossRef] [PubMed]
- Mohan, K.; Wolfe, C.; Rudd, A.; Heuschmann, P.; Kolominsky-Rabas, P.; Grieve, A. Risk and cumulative risk of stroke recurrence: A systematic review and meta-analysis. Stroke 2011, 42, 1489–1494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Udary móZgu—Rosnący Problem w Starzejącym Się społEczeństwie; Technical Report; Instytut Ochrony Zdrowia w Polsce: Warszawa, Poland, 2016.
- An Anonymised Sample of Polish National Health Fund (NFZ) Data on the Occurrence of Ischemic Stroke. Available online: https://dane.gov.pl/pl/dataset/1711 (accessed on 31 January 2021).
- Bivand, R.S.; Gómez-Rubio, V. Spatial survival modelling of business re-opening after Katrina: Survival modelling compared to spatial probit modelling of re-opening within 3, 6 or 12 months. Stat. Model. 2021, 21, 137–160. [Google Scholar] [CrossRef]
- Ibrahim, J.G.; Chen, M.H.; Sinha, D. Bayesian Survival Analysis; Springer: New York, NY, USA, 2001. [Google Scholar]
- Leroux, B.; Lei, X.; Breslow, N. Estimation of Disease Rates in Small Areas: A New Mixed Model for Spatial Dependence. In Statistical Models in Epidemiology, the Environment and Clinical Trials; Halloran, M., Berry, D., Eds.; Springer: New York, NY, USA, 1999; pp. 135–178. [Google Scholar]
- Banerjee, S.; Wall, M.M.; Carlin, B.P. Frailty modeling for spatially correlated survival data, with application to infant mortality in Minnesota. Biostatistics 2003, 4, 123–142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aswi, A.; Cramb, S.; Duncan, E.; Hu, W.; White, G.; Mengersen, K. Bayesian Spatial Survival Models for Hospitalisation of Dengue: A Case Study of Wahidin Hospital in Makassar, Indonesia. Int. J. Environ. Res. Public Health 2020, 17, 878. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brooks, S.; Gelman, A.; Jones, G.L.; Meng, X.L. Handbook of Markov Chain Monte Carlo; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B 2009, 71, 319–392. [Google Scholar] [CrossRef]
- Christensen, R.; Johnson, W.; Branscum, A.; Hanson, T. Bayesian Ideas and Data Analysis: An Introduction for Scientists and Statisticians; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Paciorek, C.J. Computational techniques for spatial logistic regression with large data sets. Computational Statistics & Data Analysis 2007, 51, 3631–3653. [Google Scholar] [CrossRef] [Green Version]
- Besag, J. Spatial Interaction and the Statistical Analysis of Lattice Systems. J. R. Stat. Soc. Ser. B Methodol. 1974, 36, 192–236. [Google Scholar] [CrossRef]
- Banerjee, S.; Carlin, B.P.; Gelfand, A.E. Hierarchical Modeling and Analysis for Spatial Data, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; Wiley: New York, NY, USA, 1980. [Google Scholar]
- Cox, D.; Oakes, D. Analysis of Survival Data; Chapman & Hall: New York, NY, USA, 1984. [Google Scholar]
- Bardenet, R.; Doucet, A.; Holmes, C. On Markov chain Monte Carlo methods for tall data. J. Mach. Learn. Res. 2017, 18, 1–43. [Google Scholar]
- Rue, H.; Held, L. Gaussian Markov Random Fields: Theory and Applications; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Gómez-Rubio, V. Bayesian Inference with INLA; CRC Press/Taylor and Francis: Boca Raton, FL, USA, 2000. [Google Scholar]
- Martins, T.G.; Simpson, D.; Lindgren, F.; Rue, H. Bayesian computing with INLA: New features. Comput. Stat. Data Anal. 2013, 67, 68–83. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; der Linde, A.V. Bayesian Measures of Model Complexity and Fit (with discussion). J. R. Stat. Soc. Ser. B 2002, 64, 583–616. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, S. A widely applicable Bayesian information criterion. J. Mach. Learn. Res. 2013, 14, 867–897. [Google Scholar]
- The Burden of Stroke in Europe Report. Technical report, Stroke Alliance for Europe (SAFE). 2017. Available online: https://www.safestroke.eu/burden-of-stroke/ (accessed on 31 January 2021).
- King, G.; Zeng, L. Logistic Regression in Rare Events Data. Political Anal. 2001, 9, 137–163. [Google Scholar] [CrossRef] [Green Version]
- Journal of Laws of the Republic of Poland [Dz.U.] of 2002, No. 93, Item 821. Available online: https://dziennikustaw.gov.pl/DU/rok/2002/wydanie/93/pozycja/821 (accessed on 31 January 2021).
- Journal of Laws of the Republic of Poland [Dz.U.] of 2012, Item 853. Available online: https://dziennikustaw.gov.pl/DU/2012/853 (accessed on 31 January 2021).
- Boehme, A.K.; Esenwa, C.; Elkind, M.S.V. Stroke Risk Factors, Genetics, and Prevention. Circ. Res. 2017, 120, 472–495. [Google Scholar] [CrossRef] [PubMed]
- Guidelines for ATC Classification and DDD Assignment, 2021; WHO Collaborating Centre for Drug Statistics Methodology: Oslo, Norway, 2020.
- Addo, J.; Ayerbe, L.; Mohan, K.; Crichton, S.; Sheldenkar, A.; Chen, R.; Wolfe, C.; McKevitt, C. Socioeconomic status and stroke: An updated review. Stroke 2012, 43, 1186–1191. [Google Scholar] [CrossRef] [PubMed]
- Smętkowski, M.; Gorzelak, G.; Płoszaj, A.; Rok, J. Poviats Threatened by Deprivation: State, Trends and Prospects; Technical Report; EUROREG Reports and Analyses No. 7/2015; Centre for European Regional and Local Studies EUROREG: Warsaw, Poland, 2015. [Google Scholar] [CrossRef]
- Wang, X.; Ryan, Y.Y.; Faraway, J.J. Bayesian Regression Modeling with INLA; Chapman and Hall: Boca Raton, FL, USA, 2018. [Google Scholar]
- Simpson, D.P.; Rue, H.; Riebler, A.; Martins, T.G.; Sørbye, S.H. Penalising model component complexity: A principled, practical approach to constructing priors. Stat. Sci. 2017, 32, 1–28. [Google Scholar] [CrossRef]
- Van Niekerk, J.; Bakka, H.; Rue, H. A Principled Distance-Based Prior for the Shape of the Weibull Model. arXiv 2020, arXiv:2002.06519. [Google Scholar]
- The Future of the Public’s Health in the 21st Century; Understanding Population Health and Its Determinants; National Academies Press (US): Washington, DC, USA, 2002; Chapter 2.
- Bates, D.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big data in health care: Using analytics to identify and manage high-risk and high-cost patients. Health Aff. Proj. Hope 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed] [Green Version]




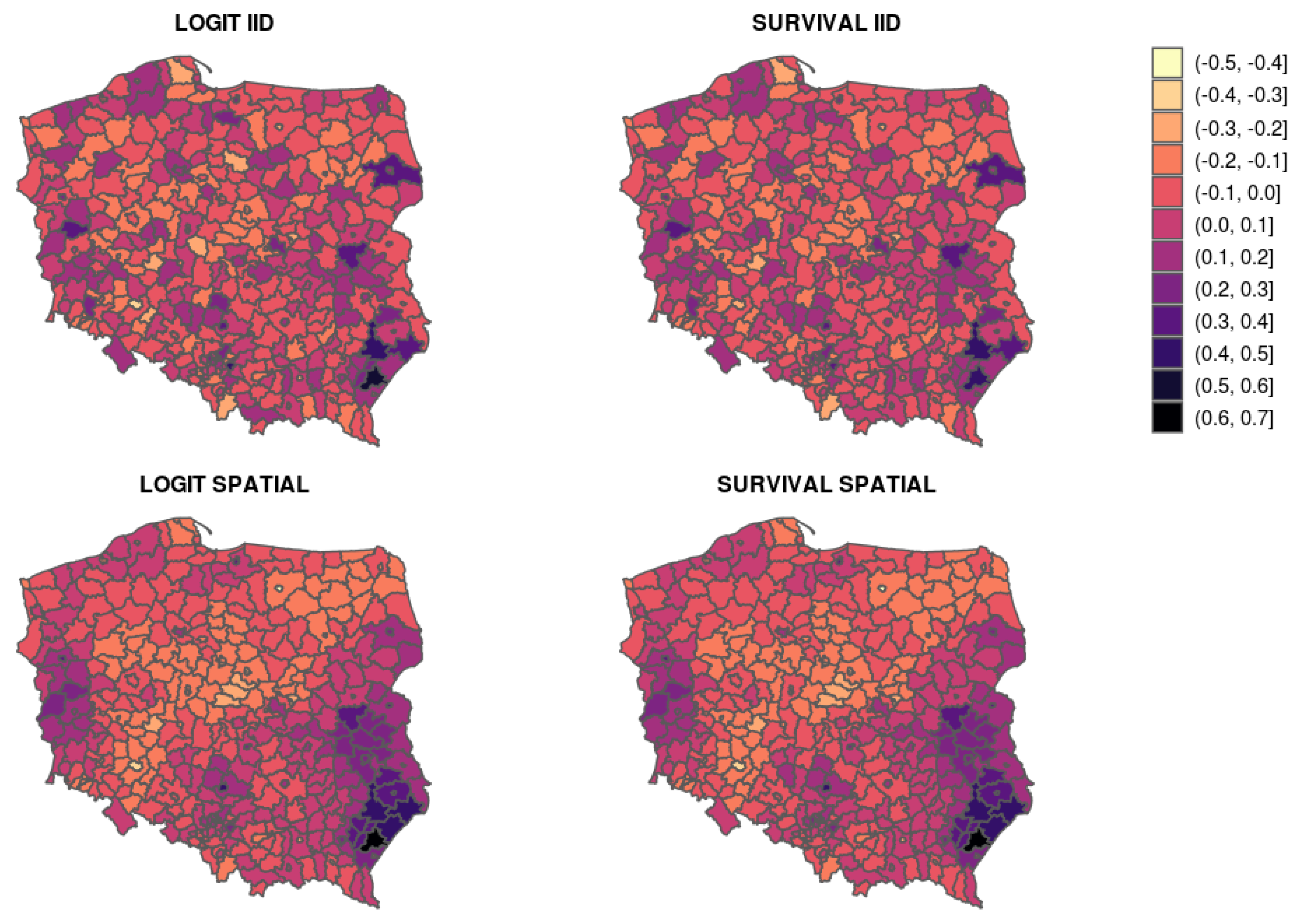{kind=link}
{kind=link}
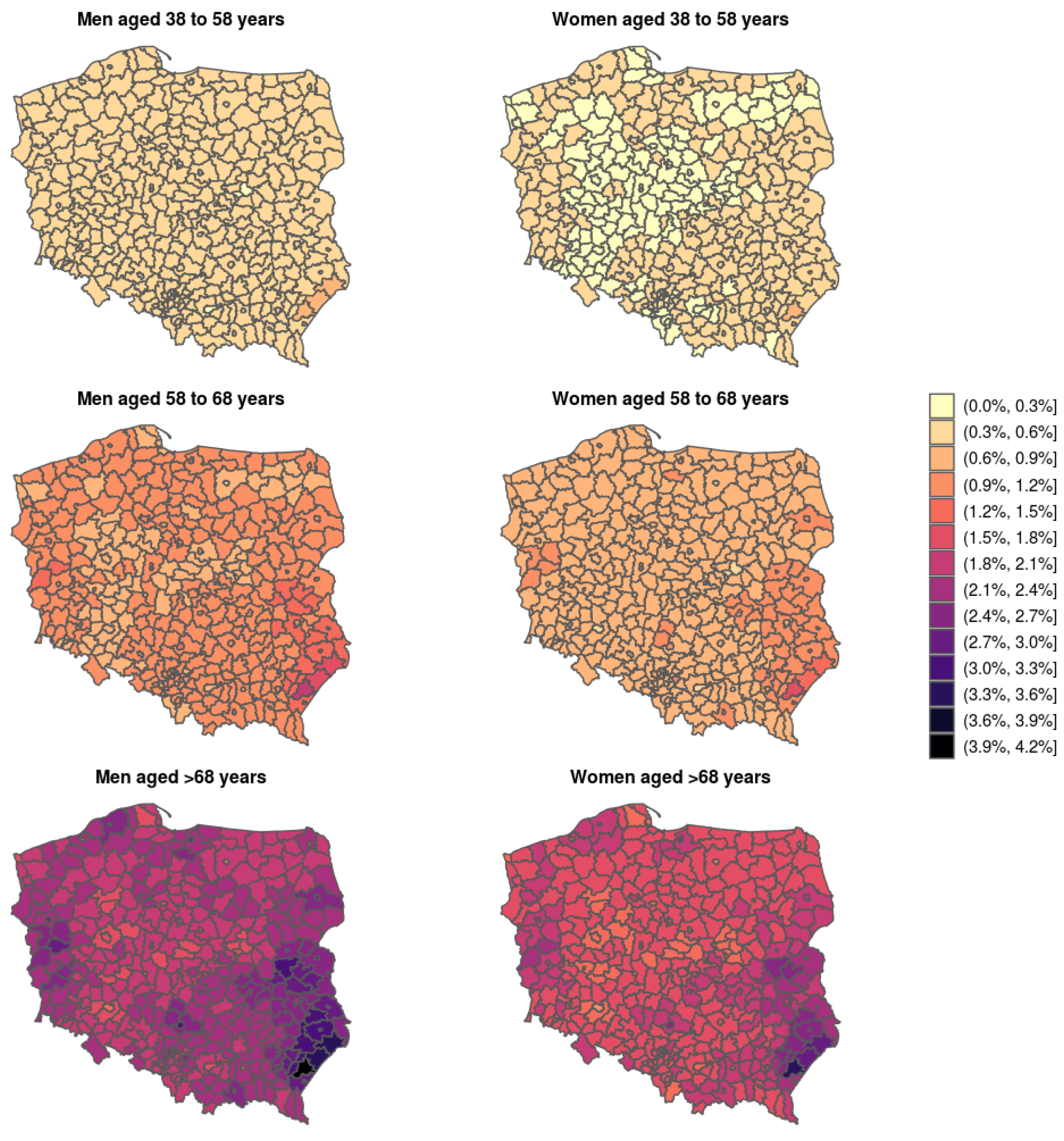{kind=link}
| Age Group | Stroke | Gender | County Type | ATC C | ATC A10 | ATC B01 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No | Yes | Men | Women | Land | City | No | Yes | No | Yes | No | Yes | |
| Age1 (38–58] | 46.76 | 0.13 | 22.07 | 24.81 | 31.67 | 15.22 | 31.94 | 14.95 | 44.53 | 2.36 | 43.89 | 3.00 |
| Age2 (58–68] | 26.69 | 0.22 | 12.11 | 14.81 | 17.21 | 9.71 | 8.72 | 18.20 | 22.39 | 4.52 | 23.75 | 3.16 |
| Age3 (68–108] | 25.68 | 0.51 | 9.62 | 16.58 | 16.31 | 9.89 | 3.74 | 22.45 | 19.66 | 6.54 | 20.82 | 5.37 |
| TOTAL | 99.13 | 0.86 | 43.80 | 56.20 | 65.19 | 34.82 | 44.40 | 55.6 | 86.58 | 13.42 | 88.46 | 11.53 |
| Covariable | Logit | Survival | Logit IID | Survival IID | Logit Spatial | Survival Spatial | |
|---|---|---|---|---|---|---|---|
| Intercept | mean CI | −5.901 (−6.013, −5.791) | −5.902 (−6.014, −5.793) | −5.925 (−6.042, −5.811) | −5.925 (−6.041, −5.811) | −5.912 (−6.061, −5.764) | −5.914 (−6.072, −5.757) |
| Woman | mean CI | −0.217 (−0.291, −0.142) | −0.214 (−0.288, −0.14) | −0.217 (−0.291, −0.142) | −0.214 (−0.288, −0.14) | −0.216 (−0.291, −0.142) | −0.214 (−0.288, −0.14) |
| Group Age2 (58−68] | mean CI | 0.935 (0.812, 1.058) | 0.933 (0.81, 1.056) | 0.933 (0.81, 1.057) | 0.931 (0.809, 1.055) | 0.933 (0.81, 1.057) | 0.932 (0.809, 1.055) |
| Group Age3 (68−108] | mean CI | 1.729 (1.613, 1.847) | 1.722 (1.606, 1.84) | 1.729 (1.612, 1.847) | 1.722 (1.605, 1.839) | 1.728 (1.611, 1.846) | 1.72 (1.604, 1.838) |
| City county | mean CI | 0.122 (−0.015, 0.258) | 0.121 (−0.015, 0.256) | 0.07 (−0.104, 0.242) | 0.07 (−0.1, 0.24) | 0.007 (−0.17, 0.184) | 0.007 (−0.173, 0.183) |
| T.A10 | mean CI | 0.238 (0.149, 0.326) | 0.235 (0.147, 0.322) | 0.238 (0.149, 0.326) | 0.235 (0.147, 0.322) | 0.239 (0.15, 0.327) | 0.236 (0.148, 0.324) |
| T.B01 | mean CI | 0.235 (0.141, 0.328) | 0.234 (0.14, 0.326) | 0.236 (0.141, 0.329) | 0.234 (0.14, 0.326) | 0.236 (0.141, 0.329) | 0.234 (0.14, 0.326) |
| T.C | mean CI | 0.324 (0.224, 0.425) | 0.322 (0.222, 0.423) | 0.325 (0.224, 0.426) | 0.323 (0.223, 0.424) | 0.324 (0.224, 0.425) | 0.322 (0.222, 0.423) |
| Deprivation index | mean CI | 0.179 (0.092, 0.265) | 0.178 (0.091, 0.263) | 0.128 (0.012, 0.243) | 0.129 (0.015, 0.242) | 0.096 (−0.022, 0.214) | 0.095 (−0.025, 0.213) |
| Precision | mean CI | 16.833 (11.063, 22.566) | 18.562 (13.66, 25.462) | 11.306 (8.472, 15.486) | 9.365 (4.78, 14.554) | ||
| Shape parameter | mean CI | 1.114 (1.075, 1.155) | 1.112 (1.08, 1.149) | 1.112 (1.079, 1.147) | |||
| Parameter | mean CI | 0.866 (0.746, 0.925) | 0.889 (0.747, 0.978) | ||||
| DIC | mean CI | 31,296.11 | 31,263.72 | 31,258.58 | 31,225.10 | 31,231.96 | 31,200.00 |
| WAIC | mean CI | 31,296.14 | 31,263.49 | 31,256.18 | 31,222.83 | 31,230.30 | 31,198.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Młynarczyk, D.; Armero, C.; Gómez-Rubio, V.; Puig, P. Bayesian Analysis of Population Health Data. Mathematics 2021, 9, 577. https://doi.org/10.3390/math9050577
Młynarczyk D, Armero C, Gómez-Rubio V, Puig P. Bayesian Analysis of Population Health Data. Mathematics. 2021; 9(5):577. https://doi.org/10.3390/math9050577
Chicago/Turabian StyleMłynarczyk, Dorota, Carmen Armero, Virgilio Gómez-Rubio, and Pedro Puig. 2021. "Bayesian Analysis of Population Health Data" Mathematics 9, no. 5: 577. https://doi.org/10.3390/math9050577