1. Introduction
The proliferation of web applications, driven by their platform and hardware independence, ubiquity of use, interfaces, data transfer protocols, and programmable capabilities, has defined the development of the IT sector—the creation of digital platforms. Using a platform allows the collection and sharing of information between a huge number of users, combining results into big data. Information technologies, which are used in the development of digital platforms, are commonly called technology stacks. An important feature of IT solutions integrated into the stack is their replaceability, meaning one of the technologies can be replaced with an alternative, either newly created or a new version of the existing one. There are many techniques for individual software design phases [
1,
2] for specific technologies and software systems such as digital platforms.
The system performance depends on the efficiency of each of the components of the technology stack [
3] and on the effectiveness of their interaction [
4]. At the same time, there can be more than one ready-made technology solution for one task, both commercial and free of charge. In practice, the choice is based on load tests or expert assessments. The approaches summarize the experience of using specific components or the technology stack, but are not based on formal assessments and cannot be used to compare efficiency. Formal methods are focused on solving identification and optimization tasks that are of greater dimensionality. The proposed methods do not consider the specifics of the operation of the digital platform and its infrastructure.
The quality of the technology selection can only be judged after the entire stack of technologies has been formed, a digital platform has been developed, and characteristics are calculated. In practice, there are situations where large digital systems stop working when they start at high load. For example, the logging framework accessed the database where the main data was stored, which resulted in a significant increase in the latency of access to the data. It is typical that when the system is commissioned, it turns out that some of its write/reading functions are slower than expected, the method of storing data was incorrectly selected, and so on. In high load systems with integrated modules used, it is difficult or impossible to assess theoretically their effectiveness. In these conditions, a model and an approach are proposed, which consist of identifying a subset of technologies of the required technology stack and choosing based on an assessment of quality characteristics in conditions that simulate a real environment, e.g., parameters of network loading, parameters of virtual machines, data transfer rate, and so on.
The paper also proposes use of fuzzy logic. For example, when choosing technological solutions based on minimizing the consumption of a resource, the key indicator is not the specific number of bytes or microseconds spent on the execution of an algorithm that changes slightly from experiment to experiment, but a qualitative estimate of whether resource consumption is “high”, “medium”, or “low” in accordance with the developer’s goals and perceptions. The introduction of such quality categories makes it possible to significantly simplify the evaluation of the technological solution, breaking all the many available technological solutions into a small number of classes relative to the consumption of the resource, corresponding to the quality categories.
The article consists of six sections.
Section 2 provides an overview of related works,
Section 3 proposes a basic model,
Section 4 describes the virtual environment used for experimental research, and
Section 5 describes the example of decision-making for specific experimental studies.
Section 6 provides key results and conclusions.
2. Related Works
The basics of evaluating information technology solutions are considered within the algorithmic efficiency theory. However, in the development of digital platforms, each solution can include a large number of algorithms. Evaluating the effectiveness of each individual algorithm will require laborious research. In addition, the solutions under consideration may contain closed source code.
There are many approaches to the task of selecting effective software components [
5,
6,
7], methods for solving the problem of optimization, and formal models for the decision-making support [
8,
9]. However, the tasks under consideration are of great dimensionality and the existing solutions do not take into account the specifics of the operation of the digital platform and its infrastructure. Various methods of Database Management System (DBMS) benchmarking are well known for SQL, NoSQL, and hybrid solutions, but these methods do not address the DBMS in the context of the technology stack.
Development practices (load testing, benchmarking, expert review etc.) generalize experience in specific solutions or technology stacks and are actively applied in digital platform development practices. A significant drawback of these practices is the lack of consideration of the specifics of the operation of the digital platform and its infrastructure.
The need for experimental evaluation of the technology solutions before integration into the digital platform can be due to various reasons. For example, the software developer may need to test the hypothesis about the pros or cons of the solution under consideration [
10]. The need for cross-platform functioning [
11] also can be the reason for experimental evaluation to ensure the resulting digital platform components can run in various environments (browsers, mobile devices, operating systems etc.).
Distributed software development teams have a practice of using virtual development environments [
12]. This technology uses virtualization and virtual machine configuration management [
13] to apply the right settings and install the required components. It automates the process of synchronizing, setting up, and starting the developer’s work environment. Configuration management systems facilitate simultaneous distributed work on multiple components of the software being developed [
14] and automate the process of installing and customizing all the necessary components of the development environment [
15]. Upgrading and modifying the virtual environment also becomes simplified [
16] because configuration files can be easily distributed among developers.
To test the compatibility of technology solutions, services are used to bootstrap a virtual machine with the chosen operating system, software, and browser of a given version. Microsoft has a number of virtual machines for Internet Explorer and Edge browsers that do not require the purchase of a Windows license. However, since there are many other browsers, there are tools with a large set of options. For example, BrowserStack provides the ability to run virtual machines with a predetermined configuration on a remote server. It also provides means to run automated test scenarios, such as regression testing, during development.
A well-established approach to experimental software evaluation is software testing [
17]. In papers [
18,
19], a number of approaches to testing are considered, which differ in their types: functional, non-functional, compatibility, reliability, recoverability, performance, maintainability, security, and others. As noted in [
20], there are noticeable differences in views on the problems of software testing in industry and in science. At the stage of software maintenance, automation tools are actively used [
21,
22]. Testing the software is commonly included into the overall sequence of operations required to verify that the software meets the requirements. In addition, experiments are being carried out to assess the quality of the system [
23,
24] for the end users.
3. Technology Stack Selection Model
The concept and corresponding model for choosing a technology stack have been developed and can be described as follows. It is necessary to construct a
p-dimensional vector of the technology stack to build the digital platform:
where ξ
i—information technology solution for the technology stack (communication protocols, type of DBMS, frameworks used, Operating system (OS) version, etc.);
—the set of possible alternatives for each information technology solution type. Let each set with specific selected technology options denote
.
For the given operating conditions (that is, when the digital platform is used after its complete implementation, during the workload on software and hardware of a computing system), each set of the technology stack can be associated with a vector of efficiency characteristics, such as memory consumption, processing time of a given number of records, processing queue size, failure frequency, maximum number of users, average CPU load, client data transfer time, etc.:
The stack
will be effective if
Here, Ω is the configuration and operating conditions of the digital platform after its implementation; max—operation of comparison of vectors characterizing qualities. In this paper, the operation max is proposed to be implemented using fuzzy logic.
In this case, the choice is a problem with computational complexity determined by a complete enumeration of all elements of the sets
in
p places of the technology stack, i.e., it is necessary to enumerate all the options.
where
is cardinality of
.
The complexity of the problem lies in the necessity of complete enumeration of possible solutions, and in the fact that efficiency can be determined only by forming the entire technology stack and assessing its performance after implementation. It is proposed to solve the problem of evaluating the effectiveness by its approximation on the basis of experimental virtual environments simulating the given operating conditions, decomposing the general problem in accordance with the stages of the life cycle of the development of digital platforms. To achieve this goal, the concept of a configuration is introduced at t stages of the life cycle for a given configuration and operating conditions Ω: At each stage , each information technology solution of the technology stack is selected so that the values of the efficiency characteristics are greater or equal in a given set of alternatives.
In addition, technologies depend on the selection of previous information technology solutions included into the technology stack. For example, the programming languages chosen at the first stage limit the sets of libraries, the choice of the type of data storage limits the choice of DBMS, and the choice of the OS also introduces restrictions.
Let an operation of compatibility of solutions be introduced such that
In other words, compatible solutions are those that do not give zero efficiency values; that is, they are able to function when used together.
At each
m-th stage of the life cycle, the problem of choosing an information technology solution for the formation of a technology stack is solved, i.e., a subset of the required
is formed. The procedure for choosing an information technology solution is as follows. For each valid and compatible set
For the efficiency vector given at the
m-th stage out of
characteristics
When choosing solutions with the introduced operation of compatibility of information technology solutions, the number of options for enumeration is reduced, so the complexity estimate will be
where
is the set cardinality
;
is the coefficient characterizing the decrease in cardinality
down to
, considering solution compatibility.
The original problem of evaluating a technology stack is divided into stages. Thus, the technology stack is evaluated at each stage instead of a single evaluation after the digital platform is launched. If the completely assembled digital platform does not meet the requirements (in terms of speed, resources used, the ability to provide desired Quality-of-service (QoS) to users, etc.), it will be necessary to identify which of the technology solutions used affect efficiency (which is a very time-consuming task), and it will be necessary to reimplement or to replace these technology solutions. When using the proposed approach, assessments of the effectiveness of various alternative options are obtained at the stage of selecting technological solutions. These assessments make it possible to select effective and appropriate technological solutions before the time the platform is put into operation.
Thus, the approach allows the reduction of the number of options required to be evaluated for forming a technology stack and makes it possible to evaluate information technology solutions at the stages of the digital platforms’ development life cycle. The introduced decomposition of the selection problem allows us to reduce the dimension of the original problem and reduce the number of options under consideration, the effectiveness of which can only be assessed by conducting experiments including each of the information technology solutions into the digital platform.
The approach has limitations that must be considered when using it. The initial selection of the information technology solutions is carried out with the involvement of expert assessments, and therefore the list of options may not be complete. If initial expert assessments have led to an ineffective set of solutions, then the choice of subsequent solutions for implementation in the technology stack will be limited by the need to ensure compatibility with existing ineffective solutions. Thus, a systematic error in expert assessments can hypothetically lead to a decrease in the efficiency of the digital platform.
4. Experimental Virtual Environment
When setting up an experiment, it is important to minimize the influence of the observer on the object. To isolate the evaluated information technology solution from the influence of the observer, it is necessary to form an independent infrastructure [
25]. It can be prepared both in hardware, using physical computing devices (computers, servers, routers, etc.), and software, using virtual machines. The second option should be considered preferable, since the implementation of the infrastructure using software means more rational use of resources and portability. In addition, the use of virtual machines provides infrastructure reusability.
It should be noted that infrastructure provisioned with virtual machines has several disadvantages—it requires a large amount of disk space, it is difficult to monitor the current state of virtual machines, and the changes you make need to be documented separately.
To mitigate the shortcomings, one can use the “infrastructure as code” approach. The approach is implemented using systems such as:
Systems for creating and configuring a virtual development environment (for example, the Vagrant system);
Systems for automating the deployment and management of applications in environments with containerization support (for example, Docker);
Configuration management systems (for example, Ansible, Puppet).
Studies show that containerization systems are less suitable for setting up computational experiments. They provide less isolation of computational resources, which can affect results.
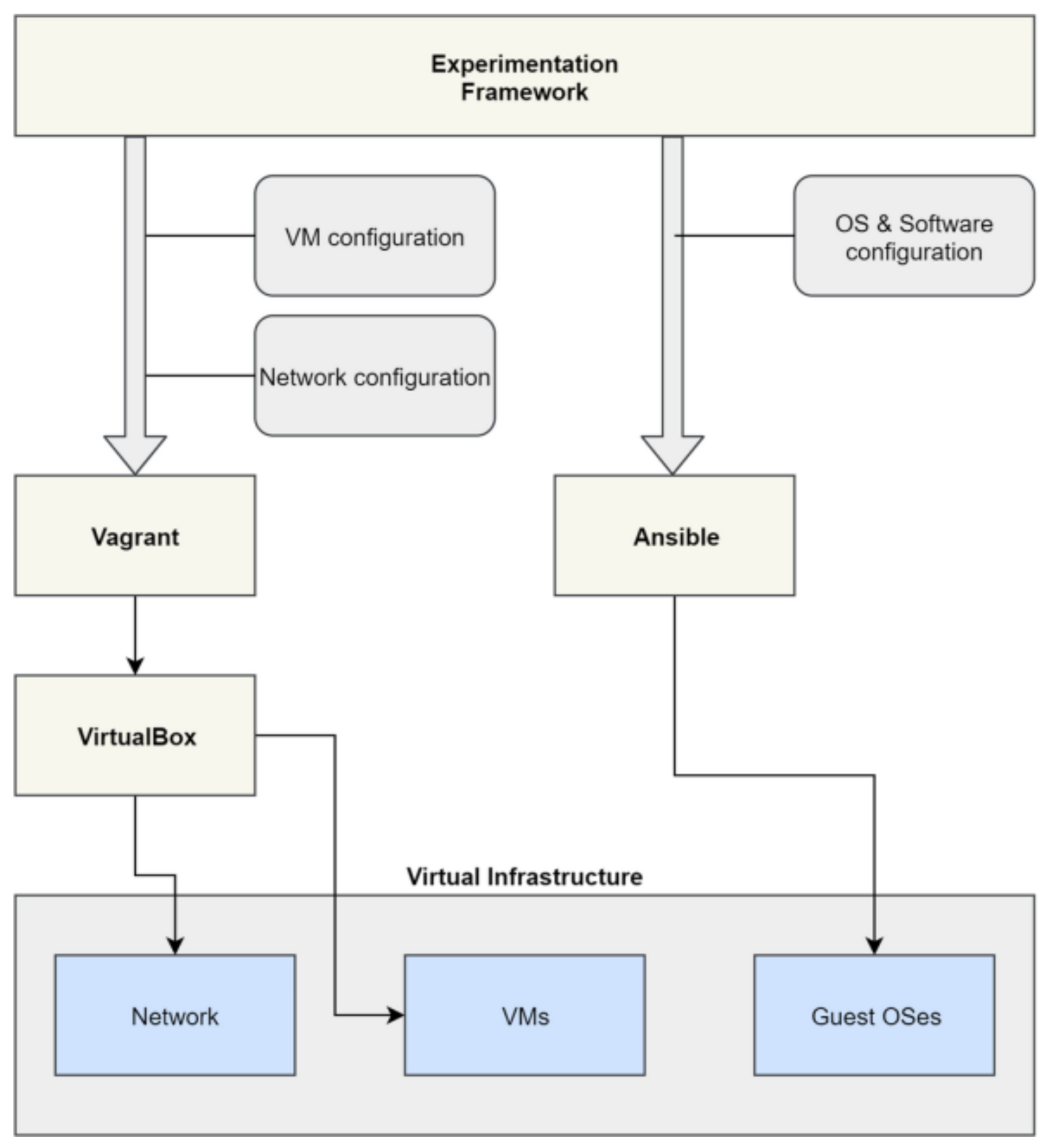
To obtain experimental evaluations of the integration of information technology solutions into digital platforms, a virtual simulation bench has been developed, as shown in
Figure 1.
Figure 1 contains a general scheme of the experimental bench. Configuration files in YAML and Ruby languages are used as initial data. Based on the configuration files, virtual machines are launched with the specified parameters and network connection settings. Then the reference image of the operating system is loaded and launched. After launch, the necessary software is installed on the guest operating systems using the configuration management system (Ansible). The detailed description of the experiment, the source code of the virtual environment, the settings of the swarm intelligence algorithm, and other parameters are presented in the paper [
25].
The proposed approach based on a virtual environment allows the obtaining of reliable estimates of the effectiveness of information technology solutions. If the requirements and operating conditions are changed (for example, the computing infrastructure is changed, servers were replaced, the amount of data received, and the number of users were changed), then the reliability of the estimates could be arguable. In this case, the estimates of the effectiveness of information technology solutions need to be recalculated. However, the methodology makes it possible to recalculate the value of the estimates using the experimental virtual environment, even if the requirements and operating conditions are subject to change.
Incorrect decomposition of the technology stack into subsets also can significantly affect the reliability of the estimates obtained. That is, the technology stack can be decomposed so that interrelated and interacting information technology solutions are selected at different stages, while the experimental evaluation of the effectiveness of these solutions occurs independently of each other, which excludes the possibility of testing and evaluating their mutual influence. In this case, the reliability of efficiency estimates can be lower than expected; however, this limitation is general for all decomposition problems. Decomposition of a single problem into many elementary problems increases the speed and reduces computational costs of solving them, but it excludes the possibility of assessing their mutual influence. Therefore, the depth of decomposition of the problem into subsets is determined by the researcher depending on the available time and computational resources for solving problems of assessing the effectiveness of information technology solutions.
5. Examples
Let there be given
functional requirements
for the digital platform, as well as
different configurations
of the infrastructure, reflecting the set of conditions for the functioning of the platform. The platform developer defines
solutions of the technology stack to choose from. Each of the
solutions implement at least one of the functional requirements
. The subsets of alternative information technology solutions from
capable of implementing the functional requirement
can be denoted as
The subsets of information technology solutions, where for each functional requirement
there is at least one component from
, are defined as technology stacks
.
is the set of all possible stacks. To assess the quality of integration of information technology solutions,
quality indicators
:
are introduced [
26]. These quality indicators belong to
space. Thus,
where
is a vector consisting of the values of the experimentally calculated quality indicators for the infrastructure configuration
and the evaluated stack
.
The following methodology for the integral quality assessment of the technology stack is proposed:
Mathematical formalization of the problem of choosing the appropriate technology stack in accordance with the above definitions.
Formation of fuzzy inference rules based on the goals and priorities of the digital platform developer.
Study of the fuzzy inference system for the completeness of coverage of the range of input values by the rules, the absence of redundant rules, and the elimination of the ambiguous choice situation by setting the weights of the rules.
The choice of the method of normalizing the values of quality indicators for transmission to the input of the fuzzy inference system.
Organization of experiments in a virtual simulation environment to obtain normalized quality values for transferring to the input of the fuzzy inference system and obtaining an integral quality indicator of the evaluated stack for infrastructure configuration .
To organize a directed search of the
technology stack for configuration
, it is proposed to use the swarm intelligence algorithm [
27].
Let us consider the application of the methodology on the example of choosing Node.js modules for developing a digital platform DigitalPsyTools [
28], designed to provide information support for population and longitudinal psychological research in Russia.
The following functional requirements are imposed on the modules used for data transmission and processing in the digital platform:
—sequentially check all elements of the array for compliance with the condition and return an array consisting of elements for which the check gave the value “True” (given alternatives: Lodash, Underscore);
—apply the specified function to all elements of the array, returning a new array consisting of the transformed elements (given alternatives: Lodash, Underscore, native JavaScript);
—return the first element of the array (given alternatives: Lodash, Underscore);
—build full path to file or directory based on specified array of path elements (given alternatives: native path module);
—find and replace a substring in the given string (given alternatives: native JavaScript);
—zip the transferred file array and return the generated Zip archive (given alternatives: Adm-zip, jszip, zipit);
—calculate the MD5 hash sum for the specified dataset (given alternatives: Hasha, md5, Ts-md5);
—read data from file (given alternatives: Fs-extra, native fs module);
—read the contents of a directory by returning an array of filenames and subdirectories inside the directory (given alternatives: Fs-extra);
—recursively read the contents of a directory and return an array of filenames and subdirectories inside the directory (given alternatives: Recursive-readdir).
Thus,
The quality of functioning is evaluated using quality indicators: —physical time spent on the experiment, ns; —microprocessor time spent on executing user code during the experiment, μs; —increase in the size of memory pages allocated to the experiment process (including heap, code segment, and stack), bytes. During the experiment, the quality indicators were normalized relative to their maximum values in the experiment, taking values on the interval [0; 1].
The use of these quality indicators is explained by the need to choose a technology stack for which resource consumption in terms of increasing the size of memory pages, processor, and physical time of program execution are minimal, which will ensure the best user experience on various desktop and mobile devices.
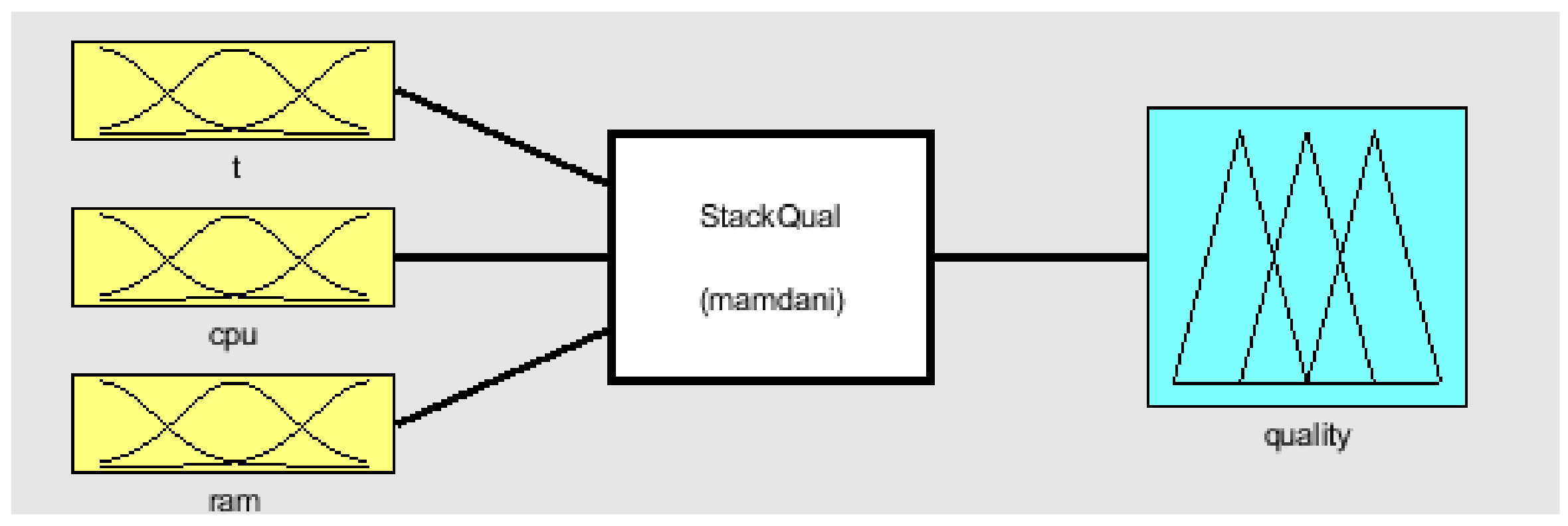
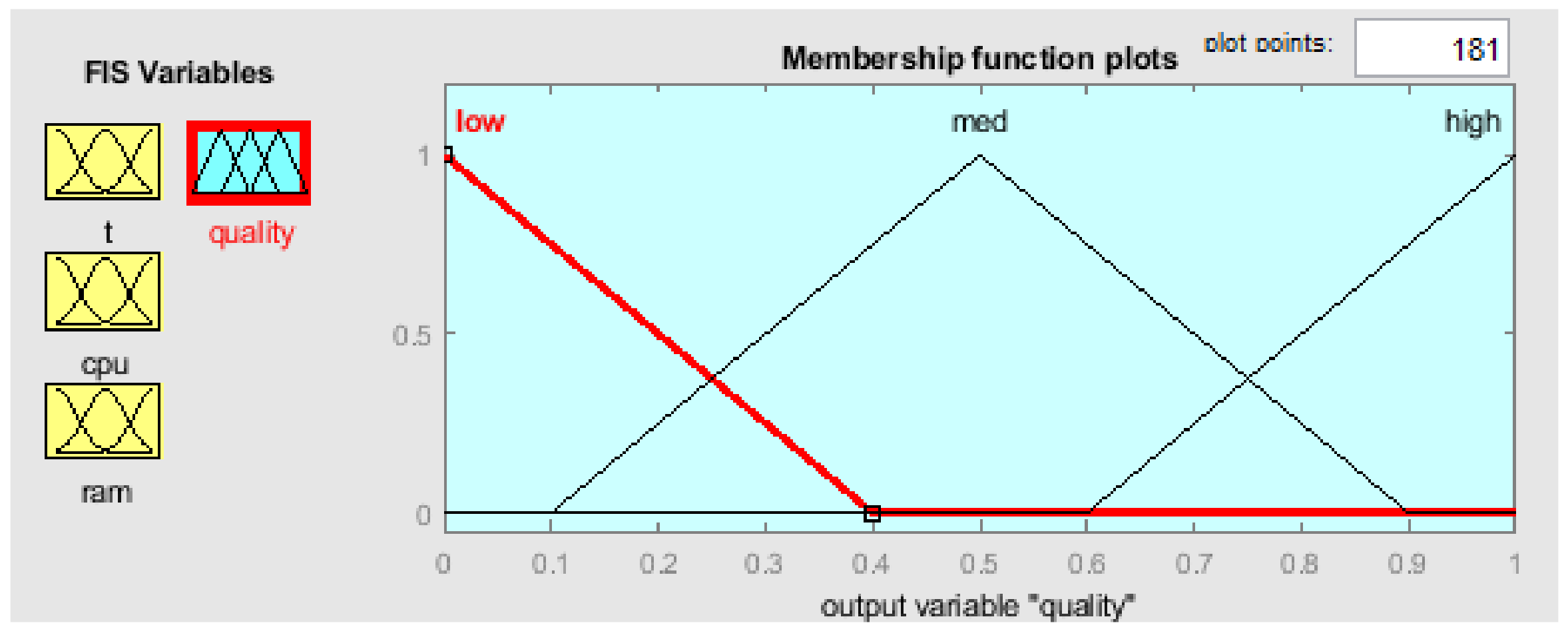
The Fuzzy Logic Toolbox for MATLAB engineering software package is used for fuzzy inference. It allows us to make the process of creating and configuring fuzzy inference systems interactive. The developer visually configures the number of fuzzy sets, the type of the membership function, the method of fuzzification of the initial quantitative data for the transition to a qualitative representation, and the defuzzification method to obtain a quantitative value at the output of the system. In the given example, the following standard fuzzy inference parameters are set: and method: min; or method: max; implication: min; aggregation: max; defuzzification: centroid.
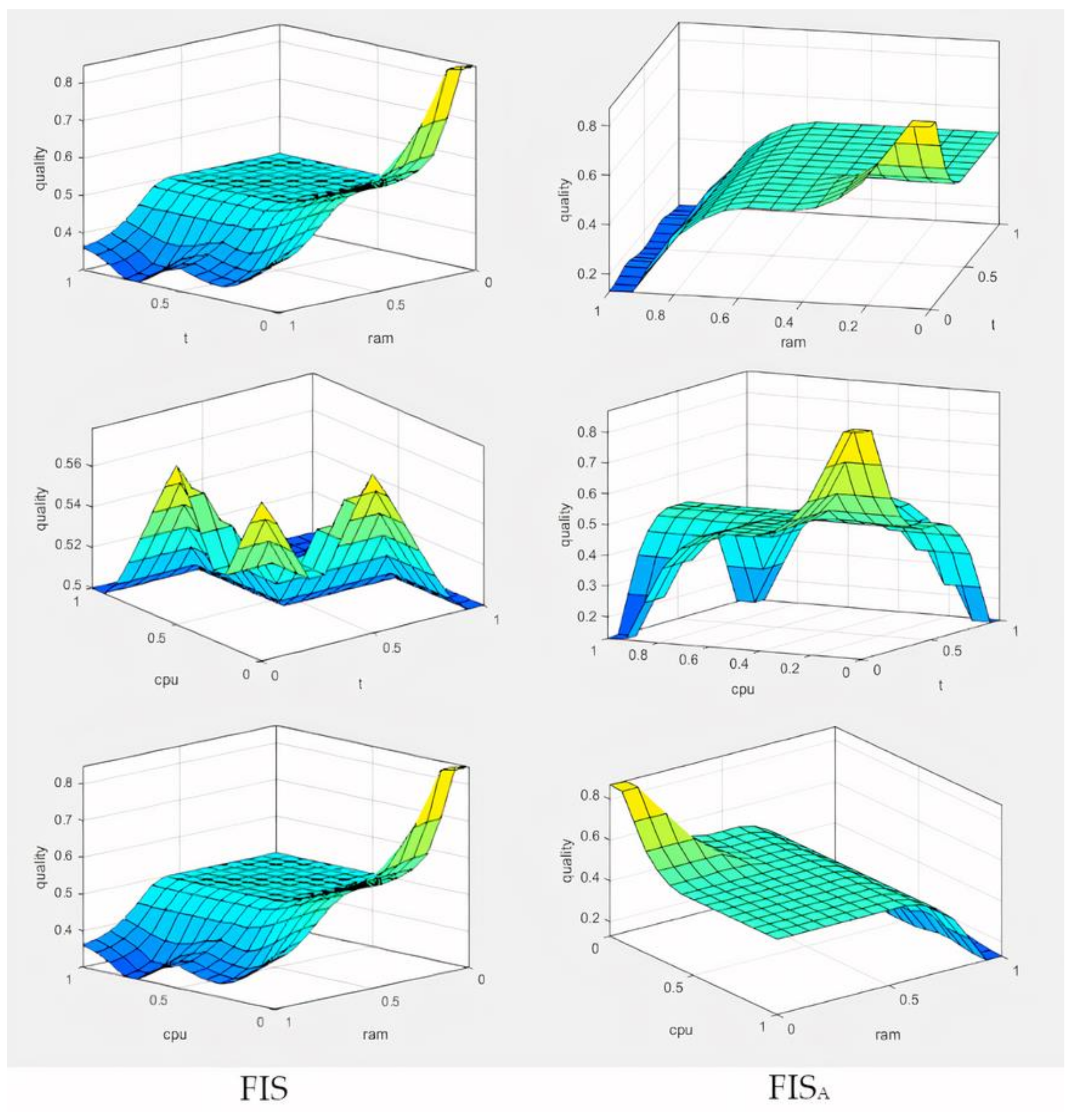
Two different fuzzy inference systems of the Mamdani type were developed to obtain integral quality indicators of the evaluated technology stack
. Both systems are described in
Appendix A.
The first fuzzy inference system led to the following technology stack for the implementation of functional requirements:
is implemented by the “Underscore” component;
and are implemented by the JavaScript language tools;
—by the “Lodash” component;
—by the “Path” component;
—by the “Adm-zip” component;
—by the “Hasha” component;
—by the “Fs” component;
—by the “Fs-extra” component;
—by the “Recursive-readdir” component.
The integral quality indicator value for the technology stack is 0.8123.
The second fuzzy inference system led to the following technology stack for the implementation of functional requirements of the given digital platform:
is implemented by the “Underscore” component;
and are implemented by the JavaScript language tools;
—by the “Lodash” component;
—by the “Path” component;
—by the “Adm-zip” component;
—by the “Ts-md5” component;
—by the “Fs-extra” component;
—by the “Fs-extra” component;
—by the “Recursive-readdir” component.
The integral quality indicator value for the technology stack is 0.8647.
6. Conclusions
A methodology for the selection of information technology solutions for a technology stack of digital platforms based on fuzzy logic has been developed. The methodology was tested on the choice of a technology stack for the component of data processing and transmission in the digital platform of population psychological research. The obtained results were confirmed experimentally, as the implementation of the selected technologies provided the required level of quality and efficiency in the collection and transmission of data in population studies. In this paper, studies of two alternative methods of fuzzy inference are carried out, demonstrating the use of fuzzy logic for the developed methodology.
The contribution of the paper to the developer community lays in demonstration of the importance of conducting experimental research and obtaining numerical estimates of technology solution efficiency during the process of digital platform development. It is shown that the software system will satisfy the specified requirements if the choice of the technology stack is reasonable. The limitation of the approach is the need to allocate additional computing resources and specialists for experimental research and analysis of the results obtained. However, these costs are justified for digital platforms that process big data or work with a large number of users, since the methodology helps to avoid many of the errors that are commonly detected at the launch stage.
The proposed methodology can be applied in various models of the digital platforms’ life cycle. Since correct experiments are time consuming, it is quite possible that the approach is difficult to apply in agile development methodologies with short sprints. The methodology is suited better to the incremental and agile methodologies with a longer sprint or iteration duration as it gives the advantage during the search of the effective information technology solutions based on the previously selected technology stack.
The proposed methodology can be used when choosing technological solutions for the technology stack of modern digital platforms and similar software systems with integrated architecture.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



