1. Introduction
Priority queuing systems, which are an essential part of the queuing theory, are effectively used in the analysis of real technical and social systems [
1,
2,
3,
4,
5,
6,
7]. Examples of systems with priority traffic include digital television, in which the transmission of synchronization signals has a higher priority than the transmission of video, and computer networks with Quality of Service (QoS) support, in particular—Internet of Things (IoT) systems [
1,
2,
3,
4]. Furthermore, information services with different categories of users [
5], as well as any social systems with different types of clients, such as hospitals, are other examples of the systems with priority traffic. As an example of the latter, we can cite the studies [
6,
7], which investigate the effectiveness of algorithms for allocating places in the organ transplant queue for patients depending on the severity of their disease. In addition, priority systems are used to provide users with priority login when working with various services. For example, the paper [
5] provides an analysis of the impact of priorities on the workload, transaction time, and other characteristics, investigating the performance of various databases for users with different access priorities.
It is well-known [
8] that traffic in modern computer networks is correlated, and it is essential to use Markovian arrival processes (
) [
9] to model it. A natural generalization of
for the case of heterogeneous traffic is marked Markovian arrival process (Marked
,
) [
9], which describes correlated arrivals of an arbitrary number of customers types.
Systems with
are poorly studied in the world literature compared to classical
arrival processes. The article [
10] analyzes the queue size of the priority system
. Investigation of the conditions for a stationary mode of a multi-server queueing system with an incoming
is presented in the paper [
6]. However, it lacks a description of the algorithm for calculating stationary state probabilities and other system performance characteristics. In recent works [
11,
12], the problem of finding a stationary solution for priority systems with a
for the case of one server was investigated. The paper [
11] examines the relative priority queue, and [
12] examines the absolute priority queue.
Paper [
13] considers a complex multi-server queueing system with a
, two priority classes, and no buffer. Current research is a development and generalization of this paper. The fundamental difference between this paper and [
13] is the presence of a buffer of finite capacity and an arbitrary number of customers types. On the one hand, such a generalization significantly complicates the mathematical analysis even for two customers types. However, on the other hand, it expands the area of the practical application of the model considered in the paper. The key contribution of this research is the development of a new method for studying queueing systems with an arbitrary number of customers types, based on a combination of machine learning and simulation methods. This method can be effectively used to study many problems in the theory of queues, for which finding a rigorous analytical solution and numerical results is either difficult or even impossible using traditional approaches. In particular, this method was applied to study a Fork-join type QS, and in [
14] to estimate performance characteristics of complex adaptive polling systems.
This paper presents for the first time the results of a study of a multi-server queueing system with a
, a queue with finite capacity, and an arbitrary number of customers types. The service times for customers of all types have a phase-type (
) distribution with different parameters.
Section 2 provides the formal problem statement and description of the model. For a particular case of two types of customers,
Section 3 gives an analytical solution, including a description of a multidimensional Markov chain, an algorithm for calculating stationary state probabilities, and other characteristics.
Section 4 describes a new method for studying a generalized model of a multi-server queueing system based on a combination of machine learning and simulation methods. Finally,
Section 5, using a new approach, presents the results of a numerical study of the crucial characteristics of the multi-server queueing system, including the loss probabilities of the customers and the time spent by customers of the given type in the system.
Section 6 discusses results and concludes the paper.
2. Problem Statement
Let us consider a multi-server queueing system with
N servers and a queue with capacity
R. Customers of different types arrive according to a marked Markovian arrival process directed by the underlying irreducible continuous time Markov chain
,
with state space
. Process
stays in state
during exponentialy distributed time with parameter
,
. After that the process moves to state
and either generates a customer of type
k,
with probability
, or moves without customer generation with probability
. Any possible loop transition should happen together with customer generation, i.e.,
,
, but
. Transition probabilities should meet the following requirement:
Thus, the process is defined by
, number of states in the underlying Markov chain;
K, number of customer types;
, transition rates;
, , , transition probabilities between states in the underlying Markov chain .
All the information regarding
process is conveniently stored in square matrices
,
of order
:
Elements of matrices , are transitions rates of the process , accompanied by generation of type k customers. Non-diagonal elements of matrix have a similar meaning, while diagonal elements hold the negated sum of state departure transition rates.
A natural requirement for the matrices , is that not all of them are zero. When this requirement is met, the matrix is non-degenerate and stable since its eigenvalues have a negative real part.
The matrices , can be defined by their matrix generating function Note that the value of this function at (matrix ) is the infinitesimal generator of the underlying Markov chain , . The stationary distribution of this chain, represented as a rowvector , is defined as a solution of the linear algebraic system Here and below is a column vector consisting of ones.
Arrival rate
of customers of type
k and the total cumulative arrival rate
of
process are defined as
Variance
of inter-arrival intervals of
k-type customers is calculated as
Correlation coefficient
of lengths of two adjacent inter-arrival intervals of
k-type customers is calculated by the formula
More details about a
can be found, for instance, in [
15]. Note that stationary Poisson arrival process is a special case of
with
,
,
and
.
In the general case, customers of different types differ in priorities and parameters of distribution of service time. These differences will be described in more detail below.
Let us consider that all servers are equal and operate independently. Service time of the
k-type customer has
(Phase Type) distribution with representation
. Here
is a row vector of size
, and
is a square matrix of size
. Thus, the service time is interpreted as the time during which an underlying Markov chain
,
with state space
, will reach the only absorbing state
. Transition rates of the chain
,
within the space of transient states
are defined by the sub-generator
and the transition rates to the absorbing state are defined by the vector
. Initial state of the process
,
at the time the service starts is selected according to the probability row vector
. More information regarding
PH distributions may be found, e.g., in [
16,
17].
We assume that customers of type have higher relative priority than customers of type k. It means that all customers with higher priority are placed in the queue in front of customers with lower priority. Let an incoming customer of type finds all servers busy and , customers waiting in the queue. With probability this customer will join the queue and will be put ahead of all non-priority customers of types and after all priority customers of types . With probability , the new customer decides not to join the queue and leaves the system forever. If any new customer finds the queue fully occupied, it also leaves the system forever. To simplify notation, in the case of types of customers, we will denote the probabilities of joining the queue of length i for priority customers of type as , and for non-priority customers of type as .
Our goal is to calculate the stationary distribution of the system, its performance characteristics and conduct a numerical experiment to measure performance, including the probability of customers losses and the system’s response time. We will use the analytic model, Monte Carlo method, and machine learning (ML) to calculate the system characteristics.
3. Queueing System with Two Priority Classes
3.1. Markov Chain of the System States
Let at the time t,
be the number of customers in the queue, ;
be the number of high priority (type 1) customers in the queue, ;
be the number of busy servers, ;
be the number of servers servicing high priority customers, ;
be the number of servers servicing high priority customers for which the underlying process is in state , ;
be the number of servers servicing low priority (type 2) customers for which the underlying process is in state , ;
be the state of the underlying process of , .
Operation of the system is described by a regular irreducible Markov chain
with continuous time
with the state space
The number of vectors in the state space for
is
and, for any fixed
the number of vectors is
Let us denote:
I (O) is an identity (zero) matrix of the appropriate dimension;
⊗ and ⊕ are the symbols of the Kronecker product and sum of matrices, see [
18];
;
;
;
is a block diagonal matrix in which the diagonal blocks are , , and the remaining blocks are zero;
is a square over-diagonal block matrix in which the over-diagonal blocks are
,
, and the remaining blocks are zero, i.e., this is a matrix of the form
is a square sub-diagonal block matrix in which the sub-diagonal blocks are
,
, and the remaining blocks are zero, i.e., this is a matrix of the form
;
is a servicing process for customers of type 1 (high priority customers);
is a servicing process for customers of type 2 (low priority customers).
With the last two notations, the Markov chain
can be written in a more compact form
We arrange the states of the Markov chain so that the first four components are arranged in direct lexicographic order, and the states of each of the processes and are arranged in reverse lexicographic order. Reverse lexicographic ordering is required here to describe in what follows the transition rates of the processes and using the matrices and
Let us give a brief explanation of the probabilistic values of these matrices. For this, we introduce the matrices
Then:
is a matrix of dimension , containing transition rates of the random process , leading to service end at one of the servers, servicing customers of type l. Here k is the number of available servers, n is the total number of available servers and servers servicing type l customers.
is a matrix of dimension . It contains transition rates of the process , leading to increase from n to the number of servers servicing type l customers.
is a matrix of dimension . The matrix contains transition rates, which do not lead to the change of the number n of busy servers, servicing type l customers. Here n is the number of servers servicing customers of type l, k is the total number of available servers and servers servicing customers of type l.
In the following we assume
The algorithm for calculating the matrices
and
follows from the results of V. Ramaswamy and D. Lucantoni published in [
19,
20]. This algorithm is described clearly step by step in [
21]. We give the corresponding description in
Appendix A.
Theorem 1. The infinitesimal generator of the Markov chain has the following block structure:where non-zero blocks are defined as: - 1.
is a tridiagonal block matrix, where
- (a)
is a square matrix of order - (b)
is a square matrix of order where - (c)
is a matrix of dimension - (d)
is matrix of dimension
- 2.
Block is a matrix of dimension :where square matrices of order are defined as: - 3.
Block is a matrix of dimension :where square matrices of order are defined as: - 4.
Block of order - 5.
Block is a square matrix of order : - 6.
Block is a square matrix of order :where matrix is derived from matrix by replacing the Kronecker factors with the factors - 7.
Block of dimension :where is a matrix of dimension defined as
Matrices are diagonal matrices, such that the equality holds.
Remark 1. Let us explain in more details how to calculate matrices . Let . Firstly, calculate the column vector . Then the elements of this vector, taken with a minus sign, are the diagonal elements of the matrix Similarly, to build the matrix for , we need to calculate the column vector . Then the elements of this vector, taken with a minus sign, are the diagonal elements of the matrix
3.2. Stationary Distribution
Let
be the row vector of the stationary probability distribution of the states of the Markov chain. Then, this vector is defined as the only solution of the system of linear algebraic equations
If system (
1) has large dimension. For this, we represent vector
as
, where vector
has order
, and vector
has order
.
Then the vectors , can be calculated by the algorithm, which consists of the following steps.
- 1.
Find the matrices
from the reverse recursion equation:
where
- 2.
Calculate
by the formulas
- 3.
Find the matrices
from the recurrence relations:
- 4.
Calculate the vector
as the only solution of the system of algebraic equations:
- 5.
Calculate vectors
using formulas:
Remark 2. When solving a system of linear algebraic Equations (2) and (3) it is necessary to know that system (2) has a rank equal to its dimension minus one. However, replacing one of the equations, for example, the first one, of this system by Equation (3), we get a system that has a unique solution. This modification must be done before solving the system. Remark 3. Generally speaking, in order to find the Markov chain stationary distribution, it is necessary to solve the system of linear algebraic Equations (1) or, writing by blocks, This system has rank and, for reasonably large values of and dimensions of and , the rank of this system becomes so large that it is not possible to solve the system straightforward, for example, using an inverse matrix. Therefore, it seems appropriate to use the algorithm described above, in which the maximum block size used is
However, for small values of the parameters, system (
1) or (
4) can be used to check the solution obtained using the algorithm described above. In particular, this fact can be used when debugging the algorithm.
3.3. Performance Measures
As a result of the calculation of the stationary distribution of the system, a number of important stationary performance measures can be found. Let us discuss some of them.
We implemented the algorithm for calculating the stationary distribution of the system states and performance metrics described above in Python 3 language. Numerical results are discussed in
Section 5.
4. Performance Evaluation of Priority Queueing Systems with an Arbitrary Number of Customers Types
The analytical solution is applicable only for priority systems with two types of customers. For systems in general, it is almost impossible to construct a Markov chain generator, find a stationary distribution, and calculate all the necessary performance characteristics.
Using simulation for finding characteristics for a large dataset of input parameters records can take too long (tens or hundreds of hours). Therefore, to solve the problem formulated in the article, a new method has been developed based on a combination of machine learning (ML) and simulation methods.
The essence of the method is that based on the synthetic dataset, train a machine learning model to predict the characteristics of the priority system. The training dataset is generated by repeated execution of the simulation model on different random input parameters values. To train machine learning algorithms, we generated a dataset of 200,000 records.
This section firstly describes the simulation model. Since most ML algorithms require a fixed number of input parameters, we had to restrict the input parameters space and use a functional definition of some of the model parameters. Below, we discuss this approach, outline the ML algorithms used, and describe how the synthetic input dataset for model training was generated.
4.1. Performance Estimation with Monte Carlo Method
The discrete-event simulation model [
22] allows estimation of the characteristics of the priority queueing system by simulating the events occurring in it: the arrival of new customers, service start and finish times. The time in the model changes in leaps and bounds at the start of event processing. During the execution of the model, various characteristics are calculated, e.g., queue length, customers delays, the total busy time of the servers. When the execution ends, the collected data is averaged to provide estimates of stationary values of the system characteristics.
The main limitation of this method is the need to simulate a massive number of events to obtain robust estimates. The number of events depends both on the model’s size (queue capacity, number of devices and priority classes, dimensions of underlying chains in and distributions) and on the stochastic characteristics of the random distributions. For instance, to obtain the results presented in this article, it was required to simulate an average of 5 million events for each set of input data.
The simulation model uses the same input parameters as the analytic model:
K is the number of customers types;
is a set of matrices defining the , ;
is a set of phase-type distributions of service time for customers of type k, specified with matrices and initial probability vectors , ;
R is the queue capacity;
N is the number of servers;
is an array of size , in which cell contains the probability that the customer of type k joins the queue when its length is equal to r, .
In order to validate the implementation of the Monte Carlo method, we used the results of the analytical model obtained for
. We discuss the validation results in
Section 5.
4.2. Performance Estimation with Machine Learning (ML) Methods
The estimation of the characteristics of a priority system with the Monte Carlo method is relatively slow. As noted above, the computation of a simulation model with large input datasets takes much time.
In order to speed up the estimation of the characteristics, we decided to use machine learning methods. We concentrated on estimating average response time and packet loss probability for the given customer type. In general, the model can be trained to predict any characteristic obtained using the Monte Carlo method. Let us consider in more detail the application of ML algorithms.
4.2.1. Definition of ML Input Parameters
To estimate the priority queueing system performance we need to specify the number of customers types K, matrices , , set of distributions for each customer type, number of servers N, queue capacity R and an array of customer joining probabilities , . The machine learning algorithm cannot be constructed for an arbitrary and distributions since the algorithm must have a fixed number of input parameters. At the same time, there can be an arbitrary number of customer types and, correspondingly, an arbitrary number of matrices , and vectors . Moreover, and distributions matrices may have an arbitrary order. Therefore, we applied the following restrictions and assumptions to the problem to limit the number of input parameters.
We define
with the number of types of customers
K, coefficient of variation
, skewness
, lag-1 autocorrelation
l and arrival rates
,
. For these parameters, we firstly fit stationary
distribution with matrix
with arrival rate
using the three moments matching method proposed by Johnson and Taafe [
23]. Then we use method proposed by Horvath et al. [
24] to find
from this
distribution and lag-1 autocorrelation
l. Finally, we split the matrix
of the found
into matrices
,
, proportionally to the arrival rates
.
To avoid an arbitrary number of arrival rates , we explicitly specify rates of the lowest and highest priority customers and only. To find intermediate rates, we specify an approximation function f, such that any arrival rate can be computed as . This function f along with boundary rates and are input parameters for the ML algorithm.
We define the phase-type distributed service times for customers of different types in the same way as we defined the
by specifying coefficient of variation
, skewness
and service rates
,
. To define service rates, we specify only boundary rates
and
for the highest and lowest priority customers, and the approximation function
g such that the service rate of any intermediate customer type is
. To fit
distributions from these parameters, we use the moments matching method [
23]. The main limitation here is that service time distributions of different types of customers have the same coefficient of variation and skewness and differ only in rate.
To slightly simplify the model, we assumed that the probability that the customer joins the queue when all servers are busy depends only on this customer type. Thus, the joining probability is assumed independent of the queue length. Then, we assumed that customers with the highest priority always join the queue (), while the joining probability for customers of other types depends on the type number k. This dependence is specified with a function h, such that .
Taking into account the assumptions described above, it is possible to build a machine learning algorithm for a given class of problems, the input parameters of which are:
K, number of customers types;
N, number of servers;
, coefficient of variation of the arrival ;
, skewness of the arrival ;
l, lag-1 autocorrelation of the arrival ;
, arrival rate of the highest priority customers;
, arrival rate of the lowest priority customers;
, approximation function of arrival rates, , ;
, coefficient of variation of service time distributions;
, skewness of service time distributions;
, service rate of the lowest priority customers;
, service rate of the highest priority customers;
, approximation function of service rates, , ;
R, queue capacity;
h, approximation function of customer joining probability , such that and for any .
Using these input parameters, we built ML models for the prediction of system response time and customers loss probability. In addition, we also built ML models for systems classification depending on the given threshold values of the response time and customer loss probability (e.g., the system is classified as “good” or “bad” depending on the predicted loss probability is below or above the threshold). These ML models use artificial neural networks, decision trees, and random forests.
4.2.2. Machine Learning Models
To study priority queueing system performance, we used ML methods to solve two types of problems: regression and classification.
In regression problems, we trained the models to predict the performance characteristics value, e.g., “what is the expected average system size for this input?”.
In classification problems, we used the ML models to predict whether the specific performance characteristic fits the given threshold, e.g., “will the system for this input provide priority customer loss probability less than 0.05?”.
We used four types of ML algorithms: decision trees [
25], random forests [
26], gradient boosting [
27] and artificial neural networks (ANN). All of these algorithms were applied to both regression and classification problems.
Hyperparameters for decision trees, random forests, and gradient boosting are presented in
Section 5. Let us discuss neural networks in more detail since their architecture for regression and classification problems is different.
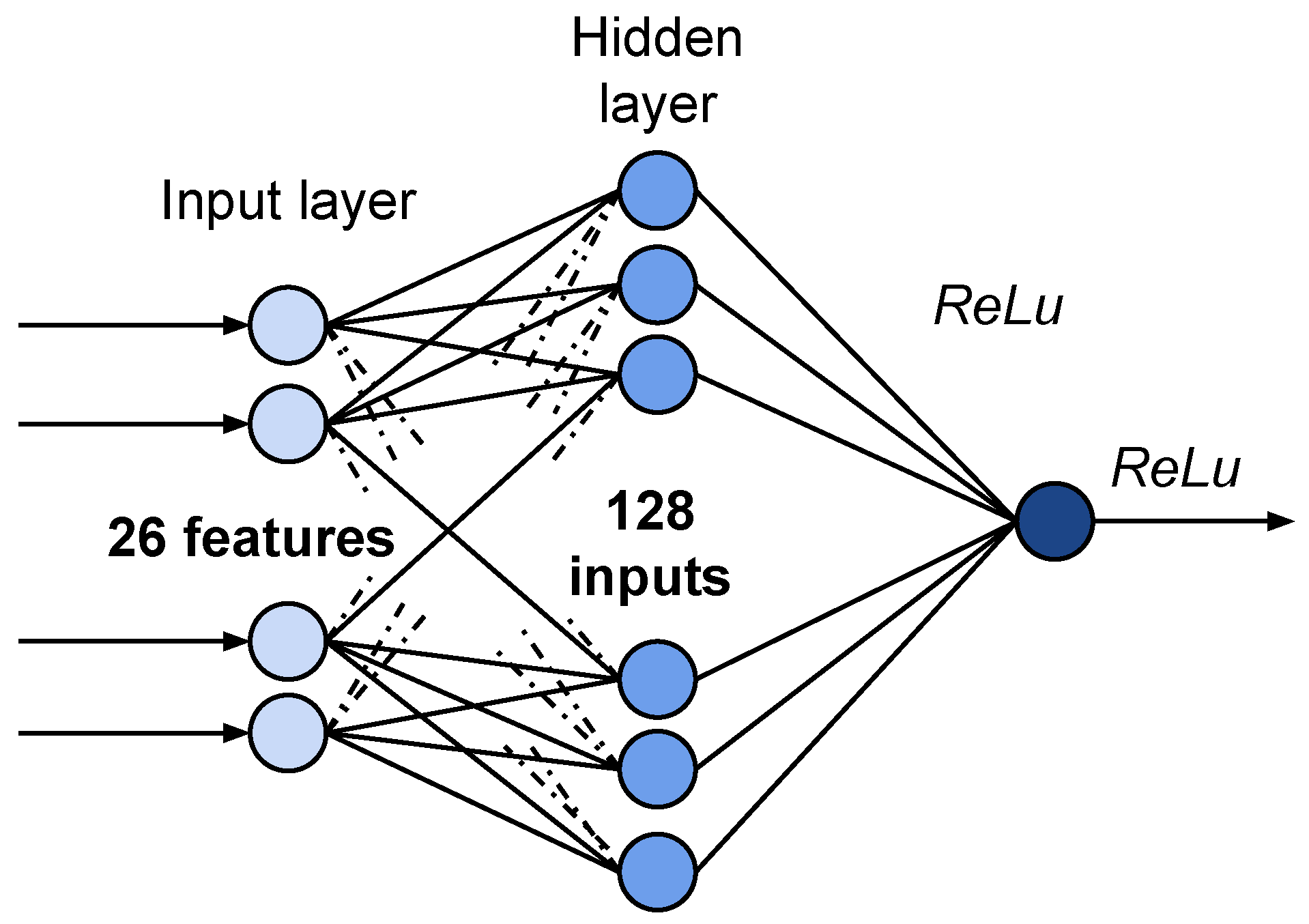
Figure 1 shows the architecture of a neural network for regression problems of predicting response time and loss probability. We used a brute force algorithm to select optimal neural network parameters by varying the number of hidden layers from one to two and the number of neurons from 64 up to 256. The network has one hidden layer with 128 perceptrons. We used Adam’s algorithm [
28] to optimize the stochastic gradient descent. Activation function on the hidden and output layers was ReLu [
29]. To train the ANN, the dataset was split into subsets (batches) of 512 copies. The number of epochs for training was equal to 1000.
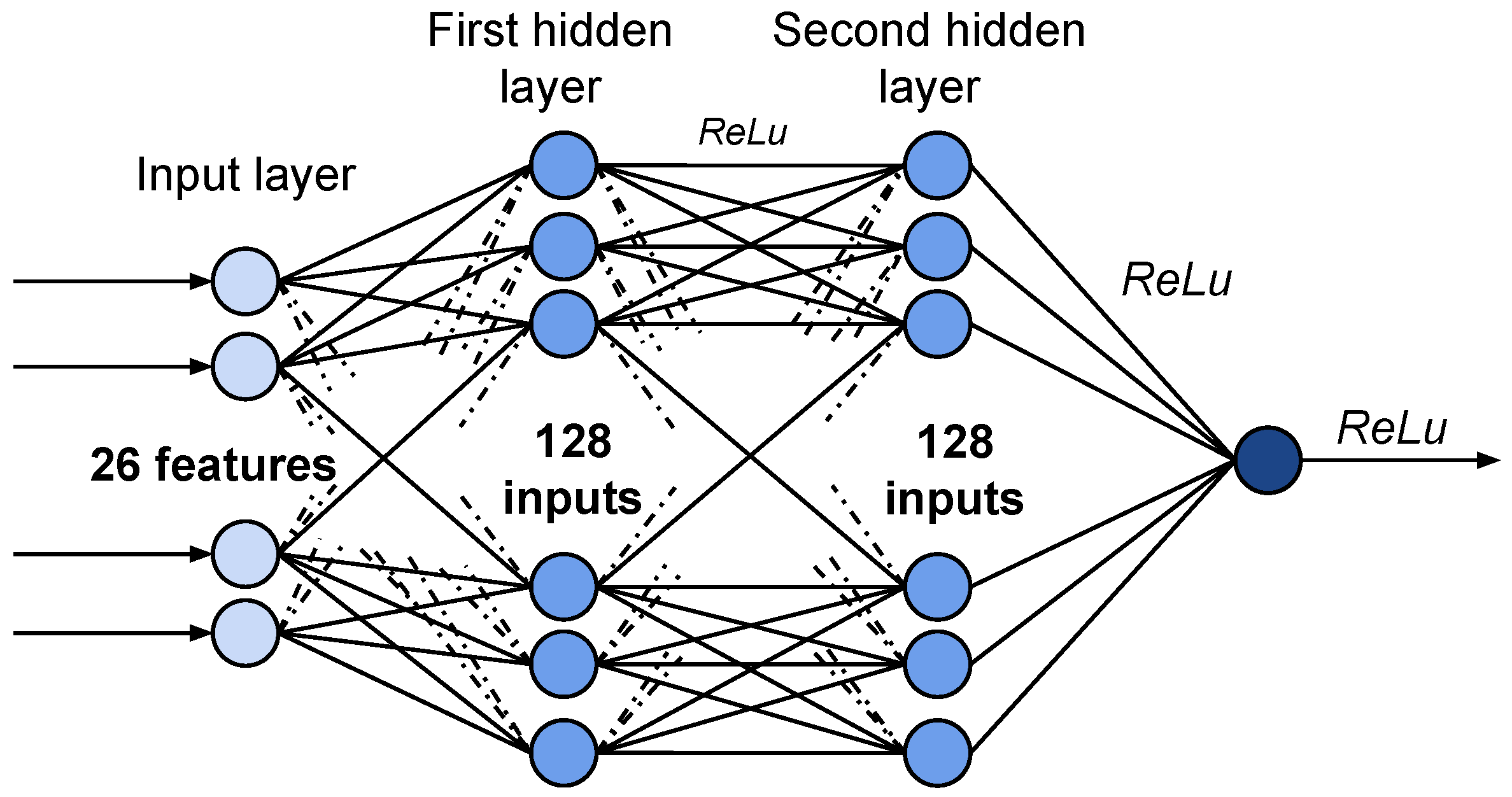
Figure 2 shows the neural network architecture for classification problems. We used brute force algorithm to select optimal neural network parameters. The network consists of an input layer with 26 inputs, two hidden layers with 128 perceptrons in each one, and an output layer. Each layer uses the ReLu activation function. As in ANN for regression problems, we used Adam’s algorithm to optimize gradient descent.
4.2.3. Generation of Synthetic Dataset for Machine Learning
The dataset is needed to train and test the ML model. We used the data obtained after repeated simulation model execution with different randomly generated input parameters to build this dataset. Let us discuss the synthetic input parameters generator in more detail.
All the numerical parameters are assumed to be uniformly distributed. For each of them we specify its minimum and maximum values.
To set the customers arrival rates , we explicitly select random arrival rates of the highest and lowest priority customers , along with the approximation function , . This approximation function is randomly selected from the predefined set of functions. The same approach is used for customers service rates and the probabilities of customers joining the queue.
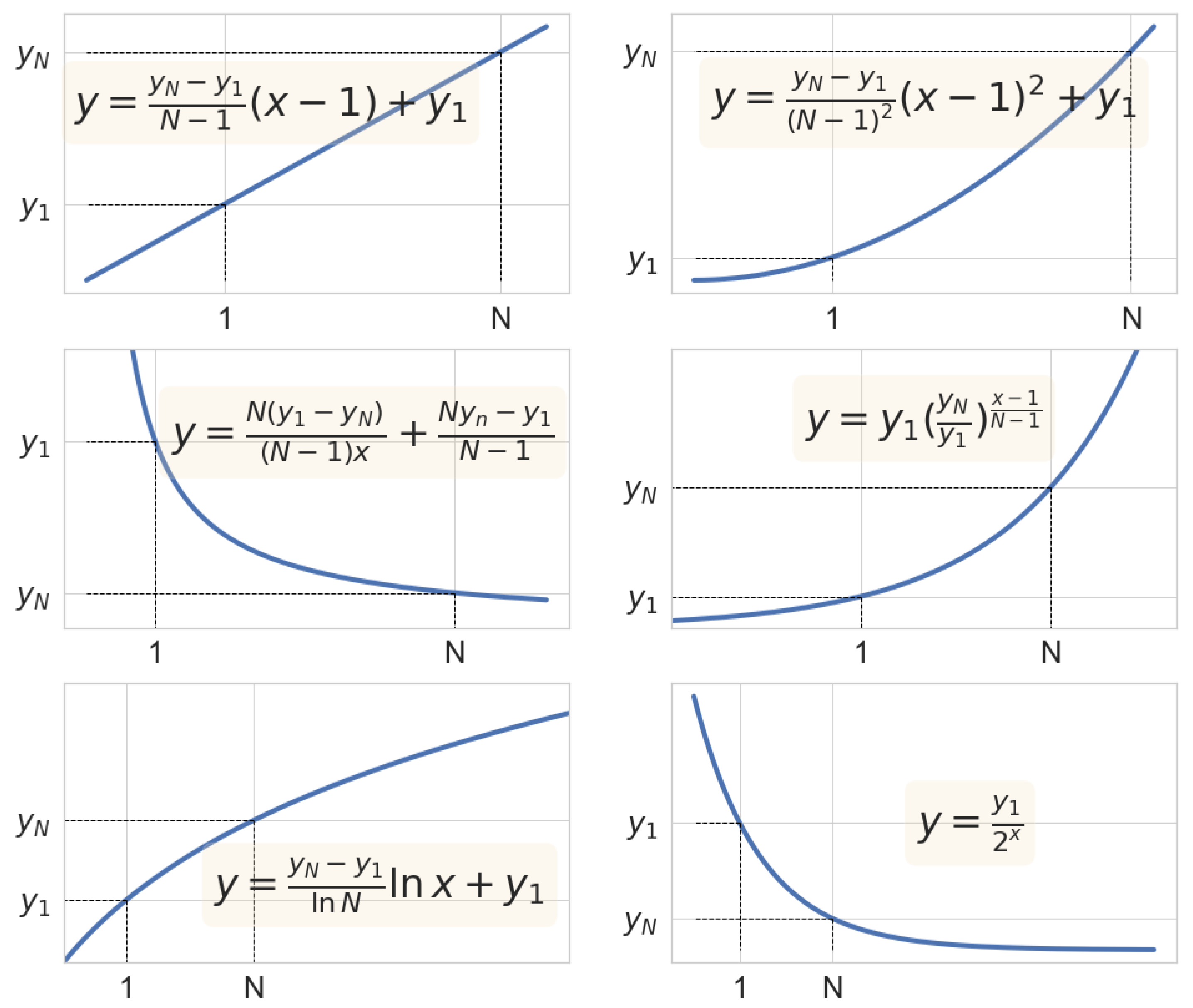
Figure 3 shows the set of approximation functions used for arrival rates
and service rates
for customers types
calculation. This set includes:
, constant values;
, linear approximation;
, parabolic approximation;
, hyperbolic approximation;
, exponential approximation;
, logarithmic approximation;
, geometric progression.
In all functions, n is an integer and takes values from . To generate the probabilities of customers joining the queue, we used four functions:
, customers always join the queue if it has space;
, linear approximation;
, hyperbolic approximation;
, geometric progression approximation.
Note that the accuracy of predictions obtained using ML methods depends on how representative is the training dataset. For example, suppose the system’s behavior on a particular set of input parameters differs significantly from everything observed in the training dataset. In that case, it will not be possible to obtain an accurate prediction at such an input. Because of this, we considered wide ranges for all input parameters, and the training sample was quite large (200,000 records). At the same time, it is crucial to avoid overfitting since the prediction accuracy also decreases.
The main limitation of our approach to describing input parameters is the use of the same coefficients of variation and skewness for service times and intervals between consumers of different types. It is easy to get around it, for example, using the same functional approach for setting the coefficients of variation and skewness that we used to set the arrival and service rates of intermediate types of customers. In this case, however, the input dimension will increase, and a larger dataset may need to be considered. In addition, more sophisticated and computationally expensive methods to fitting will be needed.
5. Numerical Results
To study the performance of the priority queueing system using the proposed methodology, we conducted a series of numerical experiments:
Firstly, we analyzed the analytic model complexity and used it to validate the simulation model based on Monte Carlo method.
Secondly, we generated a synthetic dataset for training and testing ML models.
Finally, we studied the accuracy of models predictions.
We compared customer loss probability, the average number of customers in the queue, and the average number of customers in the system during the simulation model validation. These metrics were computed for different values of queue capacity and servers number. All validations were passed, which showed that the simulation model is correct and can be safely used in the following experiments.
In the numerical experiments with ML models, we analyzed two characteristics of the priority systems: response time and loss probability of priority customers. In the scope of telecommunication networks, these characteristics are essential for verifying QoS compliance. However, our methodology allows studying any other characteristic, e.g., the average system size, number of high-priority customers, or number of busy servers. Furthermore, we investigated regression and classification problems using ML methods for both response time and loss probability.
The algorithm for computing stationary distribution of the system states that we described in
Section 3 was implemented in Python language, as well as the simulation model interface. In addition, we used the C++ language to implement the core of the simulation model to improve performance. To connect Python interfaces and C++ core, we used Cython. Also, we used Jupyter Notebook to work with the dataset.
5.1. Complexity of the Analytical Model
Before moving on, we studied the bounds of size of the input, where results can be obtained with the analytical model. Since the number of customers in the analytical model is always equal to , we varied the number of servers, the queue capacity, order of arrival , and service times.
The key metric that defines the problem complexity is the order of the infinitesimal generator since it defines a linear equation system that needs to be solved to obtain the characteristic values.
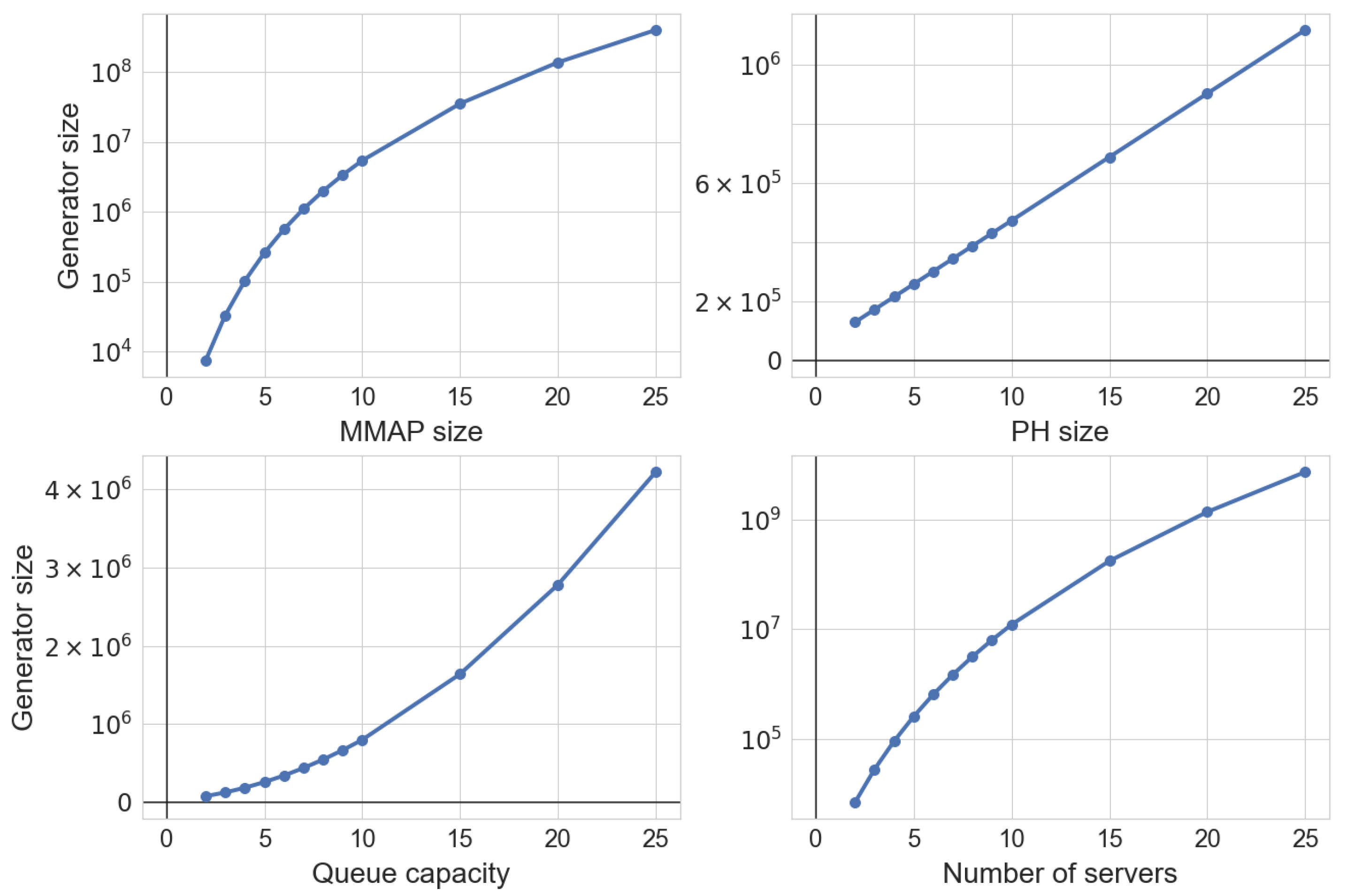
Figure 4 shows the dependency between the system generator order and the number of states in
or
, queue capacity, and the number of servers. It can be seen that the generator complexity exponentially grows along with the order of
and the number of servers. However, it linearly depends on the order of
service time distributions and almost linearly on the queue capacity.
In general, for reasonably large input values, the generator is too big to be used to compute stationary states distribution and performance characteristics. For instance,
Table 1 provides measurements of time required to build the generator matrix depending on the number of servers. The experiment was conducted on a computer with an Intel Core-i7 processor and 16 GB of RAM. Although this particular limitation can be circumvented by using a more efficient matrix representation. The problem remains since the dependence of the generator order on the number of servers is exponential.
5.2. Validation of the Simulation Model
We used the analytical model to validate the simulation model implementation on reasonably small input values, where an analytical solution could be obtained. In these validations, we varied the number of servers and queue capacity and used different
flows and
service time distributions. For example,
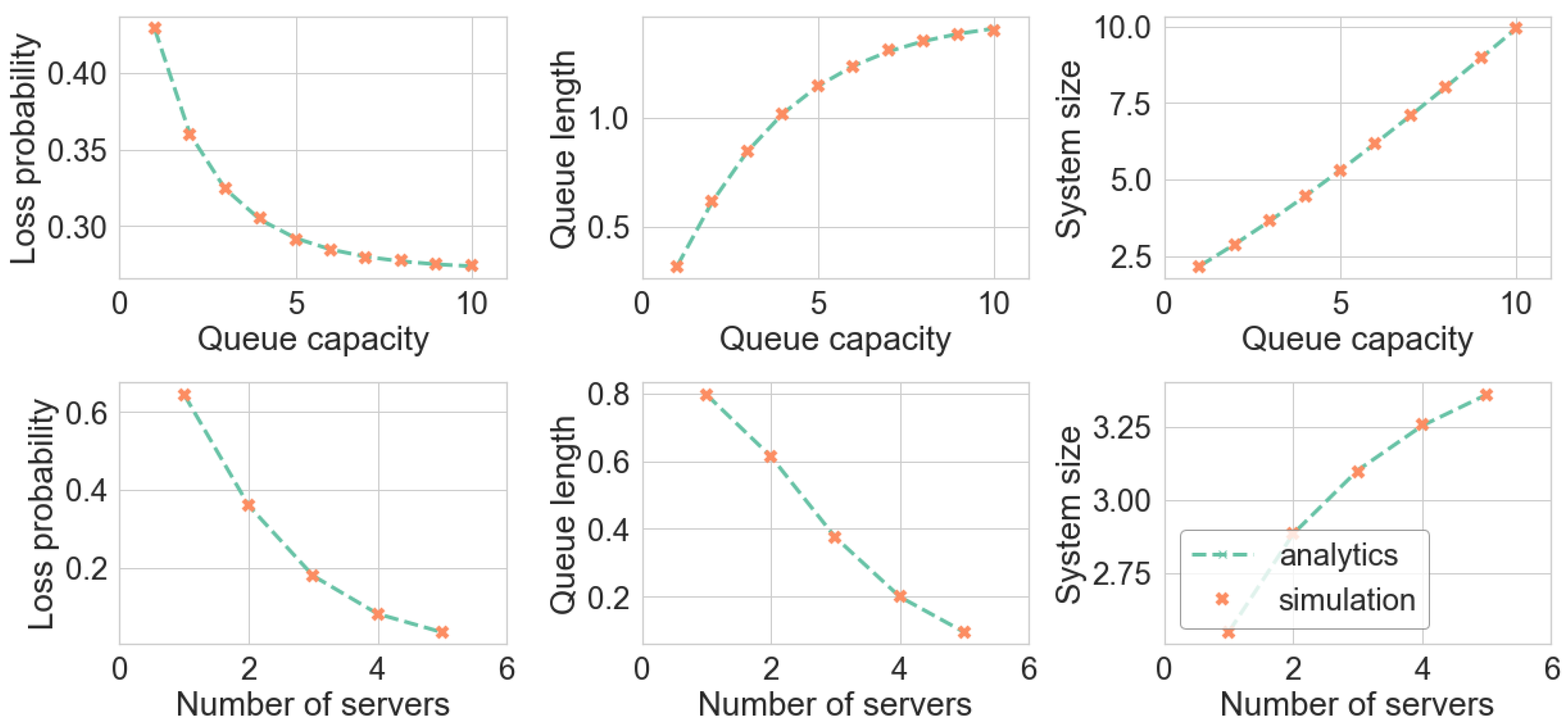
Figure 5 shows the results of comparing customer’s loss probability, queue size, and the number of customers in the system.
All validations were passed and showed that the simulation model provides numerical results with high precision. The relative error in the experiment does not exceed . However, to reach high accuracy simulation model had to process about 1,000,000 customers for each input value, which required a reasonably large amount of time.
Simulation model validation was automated using the PyTest library. Each time the simulation model code changed, unit tests were executed to compare simulation and analytical results. This approach allows being sure that any change in the code does not break the model’s correctness.
5.3. Generation of the Dataset for Machine Learning Algorithms
To train and test ML models, we generated a large dataset with 200,000 random input vectors, as was described in
Section 4. After that, the simulation model was used to get performance characteristics values for each input record in this dataset. Boundary values for all input parameters are shown in
Table 2.
Note that the skewness did not have the minimum value. Instead, it was computed for the selected CV as described in [
23].
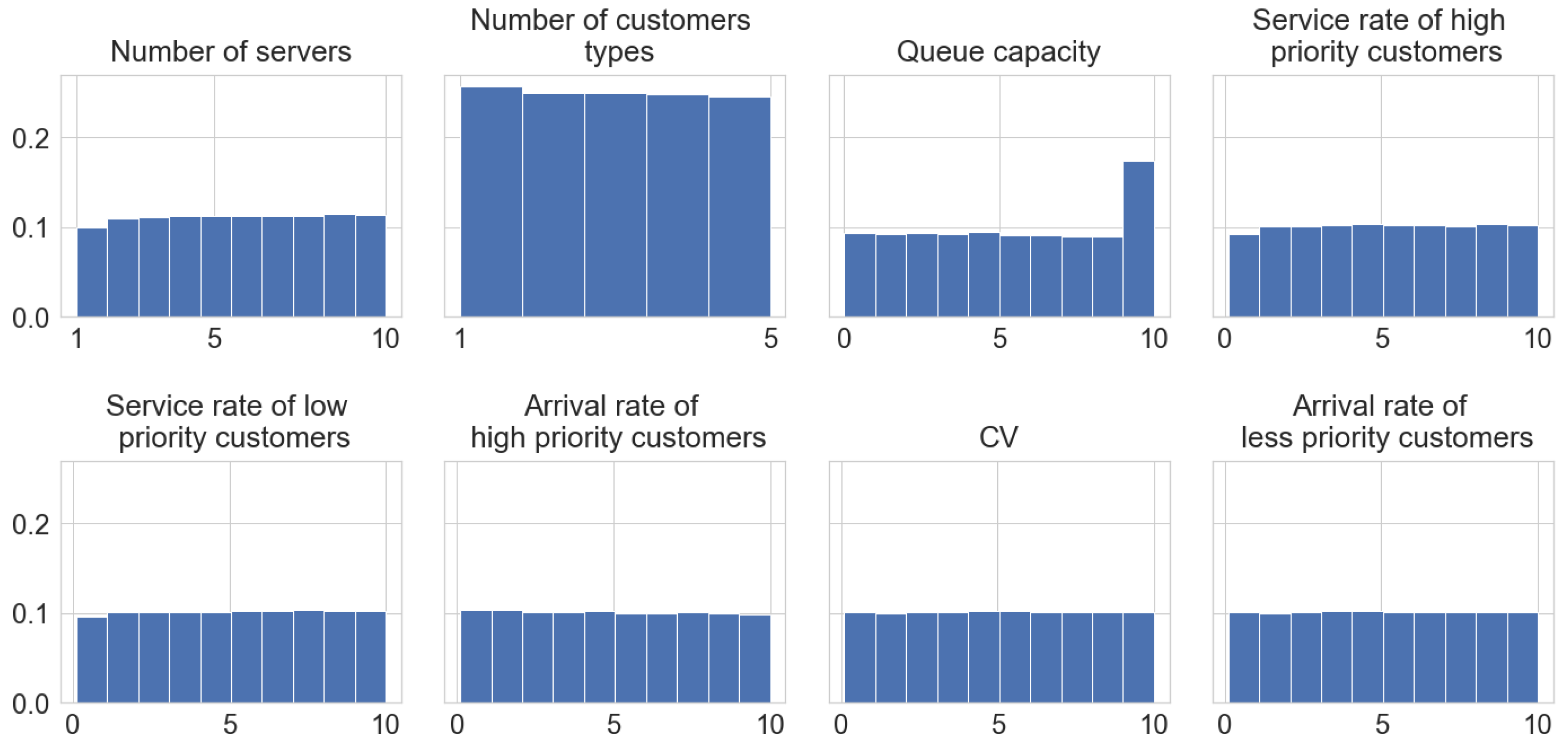
Figure 6 shows the histograms of different input parameters over the generated dataset. Most of the parameters are distributed almost uniformly; the only exception is the queue capacity. We forced the generator to include more samples with big capacity for the systems with a large number of customers types.
5.4. Prediction of System Response Time
The first performance metric we studied using machine learning methods was the system response time, i.e., the time the customer spends in the system from arrival to the end of the service. Regression models were used to predict the exact response time value. The classification models answered whether the system response time for the given input is less than a given threshold.
5.4.1. Regression Problem
We used decision trees, random forests, gradient boosting, and neural networks in the regression problem for predicting the system response time. To select the optimal hyperparameters for each algorithm, we used the grid search method. The optimal decision metric for the trees algorithms was chosen among MSE and MAE, and the max tree depth varied from 4 to 20. The number of predictors, a parameter specific for random forest and gradient boosting, was chosen from an array
with step 100. To estimate the accuracy of the algorithms, we used three metrics: the correlation coefficient, R2-coefficient, and the mean squared error.
Table 3 shows the optimal hyperparameters for tree algorithms. The optimal metric for each tree algorithm was the mean squared error. The maximum tree depth was equal to 16 for the random forest algorithm.
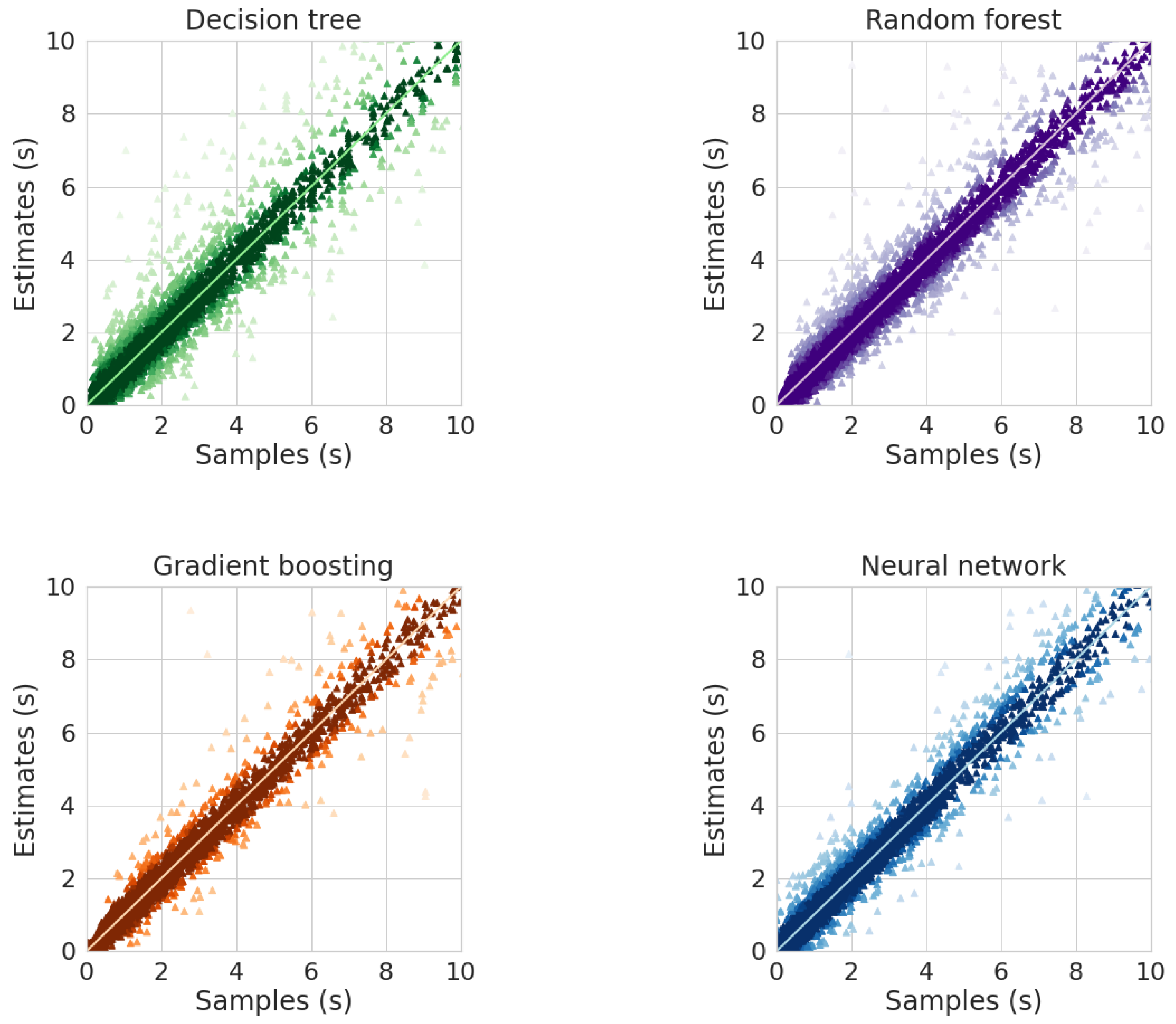
Figure 7 shows the scatter diagrams for ML algorithms. The decision tree algorithm demonstrates the largest scatter and error; in some cases, the relative error reaches
.
Table 4 shows the metric values for regression models for system response time prediciton. The random forest algorithm and gradient boosting demonstrate similar results for all metrics. The best results for all metrics were obtained with the neural networks.
We analyzed the dependency between the system response time and the number of servers, service rate of high priority customers, and queue capacity to validate the models. In each case, the system response time was computed using the simulation model and each trained ML model.
In the first experiment, the number of servers varied from 1 to 10, while other parameters were fixed:
,
,
,
(linear approximation of arrival rates),
,
,
,
,
,
,
,
,
.
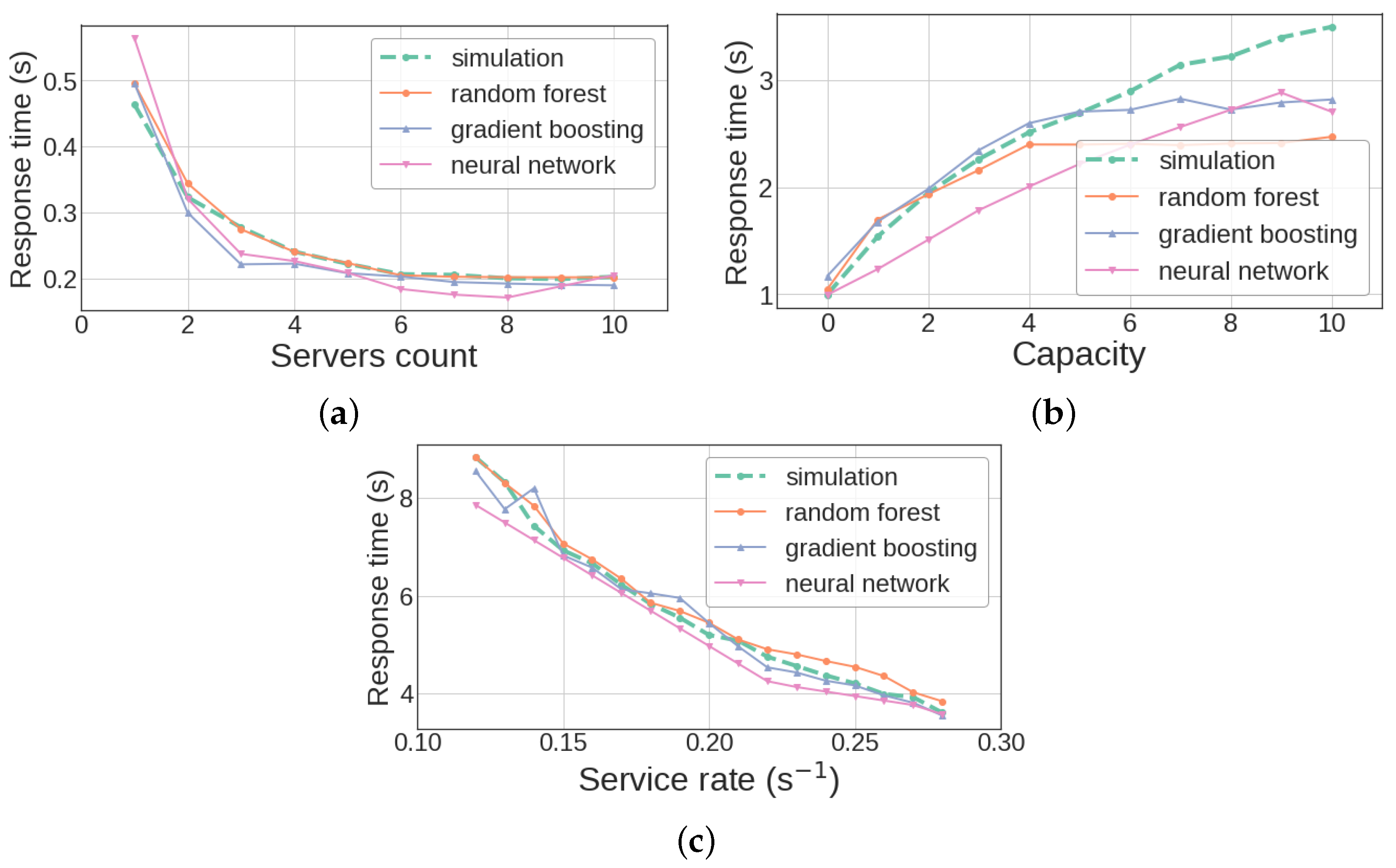
Figure 8a shows the results. In this case, the random forest algorithm demonstrates the most accurate results, while the neural network prediction is the worst. The maximum error in random forest prediction arises for the system with a single server.
In the second experiment (see
Figure 8b)) we varied the queue capacity from 0 up to 10 and set other parameters to
,
,
,
,
,
,
,
,
,
,
,
,
. In contrast to the previous experiment, the neural network gives here the highest accuracy, while the random forest has the greatest error.
In the third experiment (see
Figure 8c) the service rate of the highest priority customers was varied from
to
, while the other parameters were fixed:
,
,
,
,
,
,
,
,
,
,
,
,
. Random forest and gradient boosting has the highest accuracy, while the neural network gives the worst prediction, especially when the service rate is small.
5.4.2. Classification Problem
In many practical applications, the exact value of the system response time is not important. Instead, we may be interested in whether the response time is short enough. To answer this question, we trained several ML models to classify the priority queueing systems depending on the expected value of the response time. As a threshold, we assumed the response time equal one second, i.e., the system belongs to the first class if its response time is more than one second; otherwise, it belongs to the second class.
In addition to decision trees, random forests, gradient boosting and neural networks, we used logistic regression [
30] as this is the simplest ML method applied to classification problems.
Table 5 shows the results of the accuracy comparison.
The experiment result shows that gradient boosting and neural networks provide the most precise results. As expected, the logistic regression algorithm is less effective than any other algorithm being used [
31,
32].
5.5. Prediction of the Priority Customers Loss
The second metric we studied using ML methods was the probability of losing the customer with the highest priority. According to the assumptions in
Section 4.2.1, the highest priority customer may be lost in the only case that the queue is full. As in the response time prediction, both regression and classification problems were considered.
5.5.1. Regression Problem
To solve the regression problem for predicting the loss probability, we used only two algorithms: a gradient boosting and neural network. Early experiments showed that the decision tree and random forest give an unacceptably high error. Therefore, we trained two models and compared the results.
Gradient boosting algorithm and neural network show similar results (see
Table 6); their metrics are practically the same.
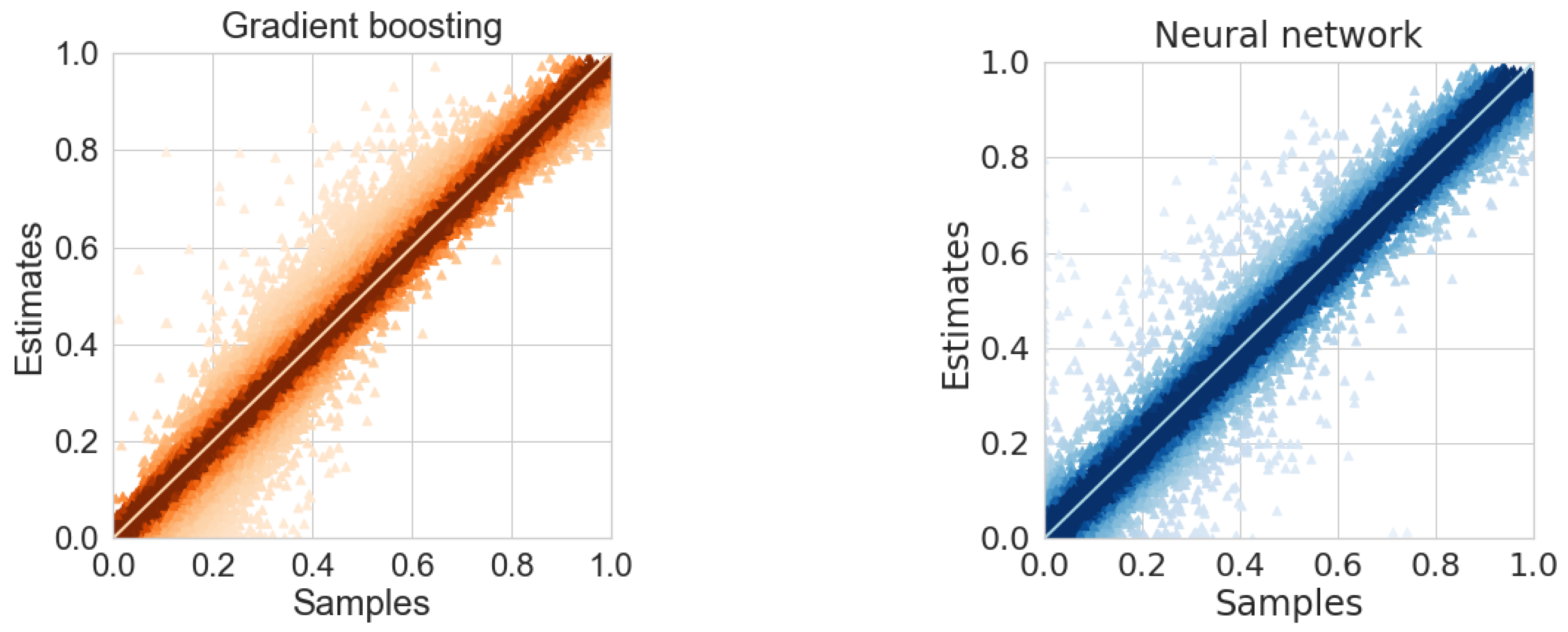
Figure 9 demonstrates that the neural network has the same absolute error for all samples. As for gradient boosting, it provides a larger absolute error when samples values (that is loss probability) are close to zero.
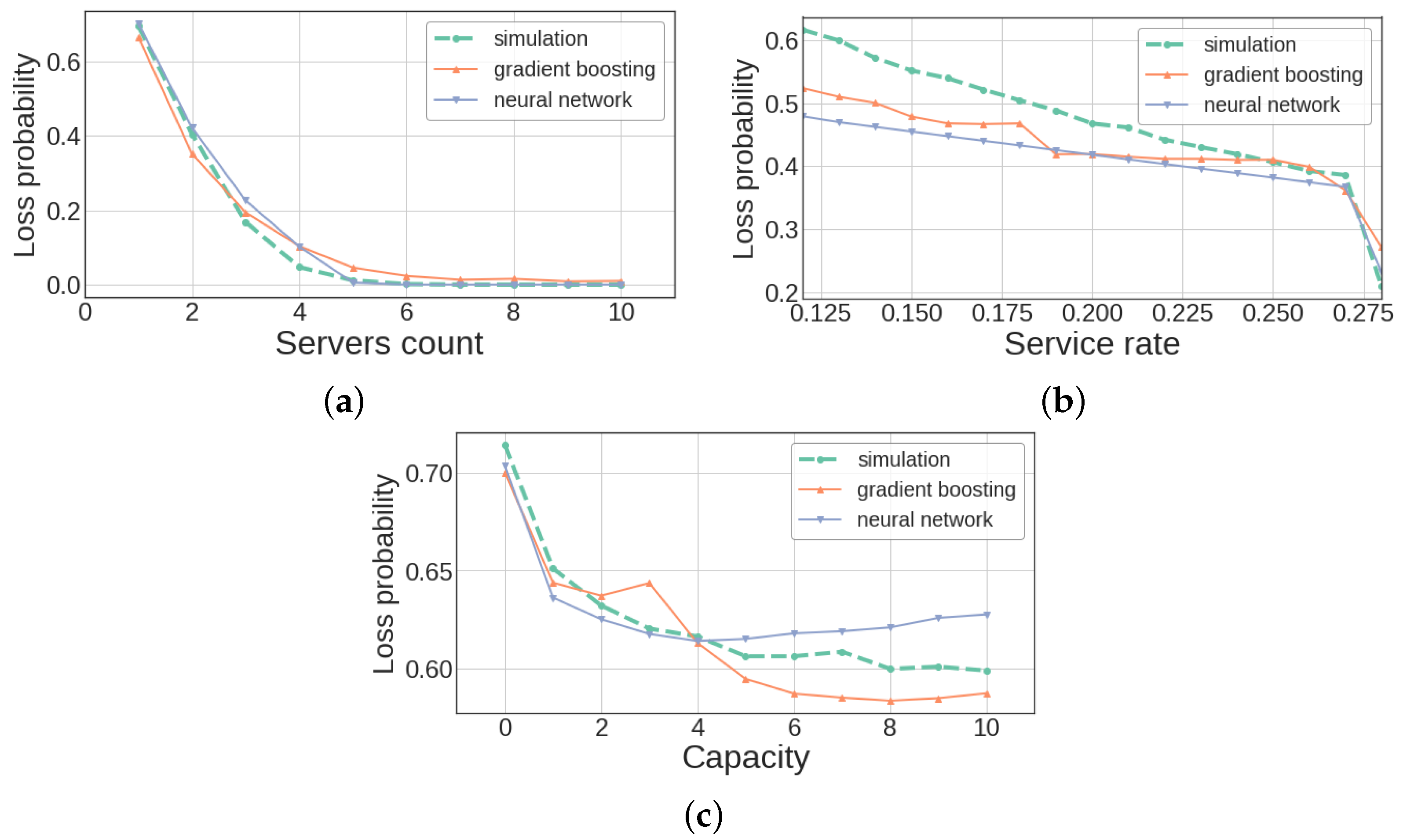
To validate ML models for loss probability prediction we used the similar validation datasets as for response time validation.
Figure 10a–c show the numerical results.
5.5.2. Classification Problem
The classification models define whether the probability of losing a priority customer is greater than
. We used logistic regression, tree algorithms, and neural network algorithms for classification problems. Results in
Table 7 shows that the neural network provides the best precision.
5.6. Analysis of Elapsed Time
To use machine learning algorithms, they need to be trained, which takes a significant amount of time. For example,
Table 8 shows the time it took to train on a dataset with 200,000 records of decision tree algorithms, random forests, gradient boosting, and artificial neural networks.
Neural network training takes about 1200 s for 1000 epochs. The batch size equals 8192, the average time for epoch is about 1 s.
Table 9 shows the typical time that is required for estimation of system response time by analytical model, Monte Carlo method, and trained ML algorithms. For
and
distributions of reasonably small size, it took about 35 s to compute response time using the analytic method. In the same case, the Monte-Carlo method is ten times more efficient than the analytics algorithm. It is worth noting that the complexity of the analytical model grows exponentially, so in general, the simulation model is the only way to estimate the performance characteristics of the systems of arbitrary size.
At the same time, the performance of ML algorithms is more than times better than the simulation model. Thus, while we needed to spend a significant amount of time generating a synthetic dataset and training machine learning algorithms, this time is fully compensated by the gain from the trained algorithms if estimates need to be obtained a very large number of distinct input vectors.
6. Conclusions
In this paper, we investigated the multi-server priority queueing system with correlated arrival flow of arbitrary number K of types of customers and finite queue. The type of the customer defines its priority, service time distribution, and the probability that the customer will join the queue when all servers are busy. Such systems are practically not studied in the literature. We presented an analytical solution for the system with two types of customers, calculated stationary distribution of the system states, and main performance measures, including average system size, the average number of priority customers, customer loss probability, and the number of busy servers.
The analytical model has a very high computational complexity, exponentially dependent on the number of servers and order of . Thus, in the numerical experiment, we could compute the model characteristics for systems with only four servers, while adding one more server led to memory overrun. Another limitation of the analytical model is that it supports only two classes of customers. To overcome these limitations, we described a new methodology for the fast estimation of system characteristics using a combination of simulation modeling (based on the Monte Carlo method) and machine learning. We conducted numerical experiments, showing that the proposed methodology allows estimating characteristics with high precision, up to 96–98%. Furthermore, estimation on the given input with a trained ML model requires several orders of magnitude less time than the barebone Monte Carlo method. As for machine learning methods, random forest and gradient boosting showed similar results in regression and classification problems for priority packets response time and loss probabilities.
The proposed methodology provides means for using the priority queueing system model in complex optimization problems, appearing in the design and implementation of modern telecommunication networks, where the traffic is essentially heterogeneous.
We plan to improve the algorithm’s performance for queueing system characteristics computation by using more advanced numerical techniques and sparse matrices. This idea is based on the observation that the generators are block matrices with lots of zeros. While this improvement can not solve the problem of exponential growth of the state space, it may help expand the area where the precise solution may be found. We also plan to explore the possibilities of using machine learning methods to solve other problems of queuing theory that cannot be solved using traditional methods. Finally, we are also working on the development of methods for applying the proposed model to estimate the characteristics of real technical telecommunication systems. The results of these researches will be presented in future papers.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}