1. Introduction
Complex network models can be used to study a large number of systems in both natural and social relations, e.g., gene networks, social networks and knowledge networks. These types of networks often have the properties of structural complexity, connection diversity, meta-complication, etc. which make them difficult to process and study [
1]. However, with the development of computer technology and the improvement of computing power, researchers can process large-scale network data more effectively, which boosts different kinds of research topics based on complex networks. Among all those topics, link prediction is one of the most concerned and important which aims to use known network information (links and node features) to infer the missing connection between a pair of nodes that should have existed or predict the possible future interaction between two nodes. This technique is widely used in areas such as recommender systems, community discovery, and bioinformatics [
2].
In the field of link prediction, there are three types of methods commonly applied by researchers. The first type is of methods based on node similarity metrics such as CN (Common Neighborhood), AA (Adamic-Adar) [
3] and CCLP [
4]. Local similarity measures usually depend on the nature of the common neighbor nodes and it is easy to calculate, while the global similarity indexes focus more on the global structure of the network, but suffer from the high computational complexity because they usually involve the calculation of multiple nodes and links. In addition, methods based on network embedding are also well studied and used. M Zhang and Y Chen proposed a graph neural network (GNN) based link prediction architecture in literature [
5] and H Wang used multiple deep autoencoders to map each node to a low-dimensional feature space [
6]. The last type of methods is based on random walks, represented by restart random walk (RWR) and extended restart random walk (ROWER) [
7]. This type of methods designs different random walk algorithms to calculate the stable probability of a node transferring to another and uses the probability as a measure to infer the possibility of connecting edges.
In this paper, we propose a new similarity index specifically designed for bipartite networks inspired by the concept
motifs, which is very instructive in the exploration of graph structure.
Motifs was first proposed by Milo et al. in literature [
8], defined as statistically significant patterns of interconnections or subgraphs recurring in certain network.
Different from the usual usage of motifs, in our research, we consider the 4-motifs structure instead of the common 3-motifs one to build our similarity index and combine it with the well-known existing index used in collaborative filtering. We use our mixed index to measure the connection probability between unconnected nodes and test its predictive effect in six real-world bipartite networks. The significance and contributions of our research are summarized as follows:
We propose a new motif-based similarity index that tries to capture more structural information from bipartite networks, which may be neglected by simply examining edges or nodes. This construction is very enlightening and can be extended by considering different motifs.
We combine our index with a traditional widely-applied similarity measure and use the mixed index to predict links.
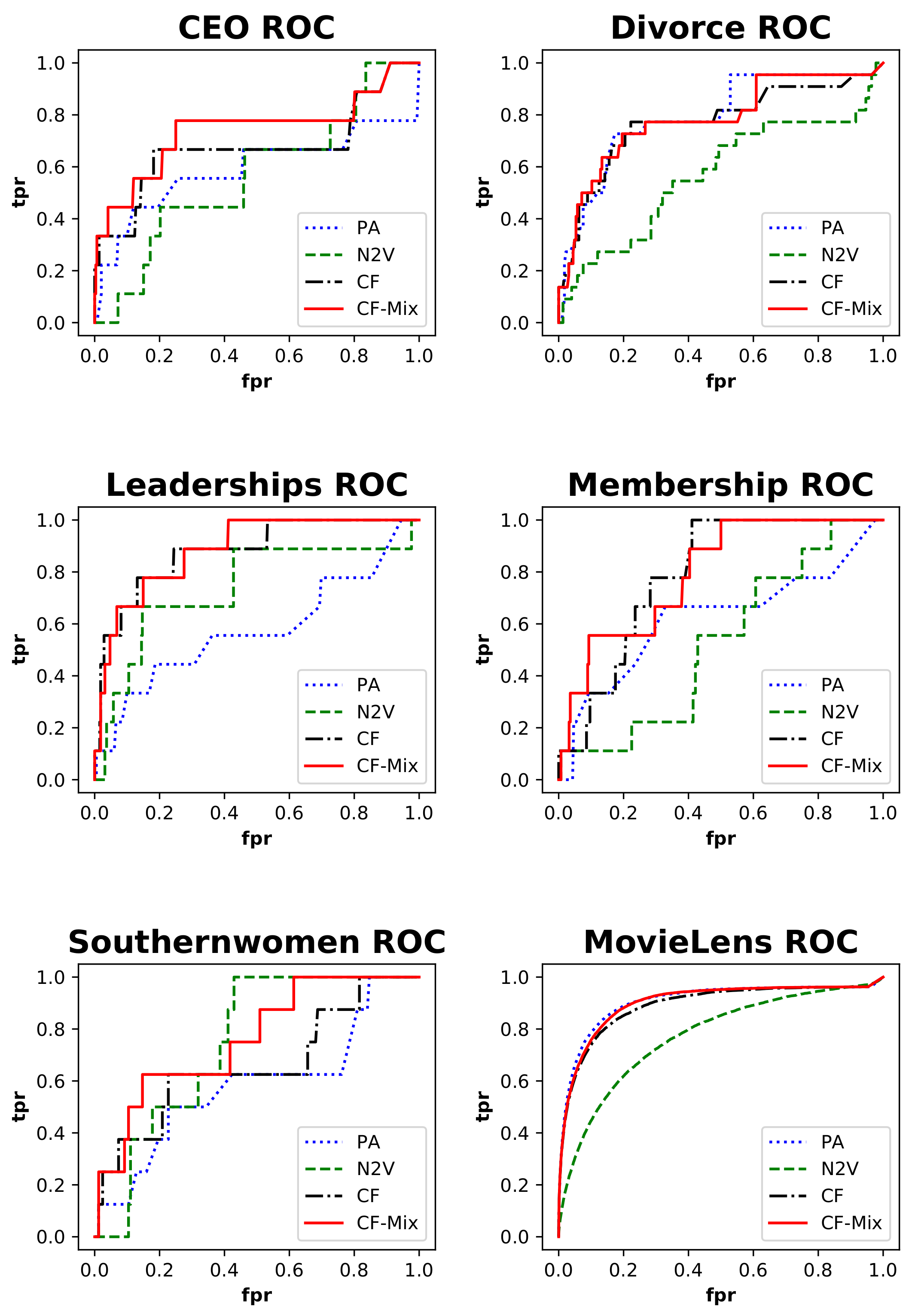
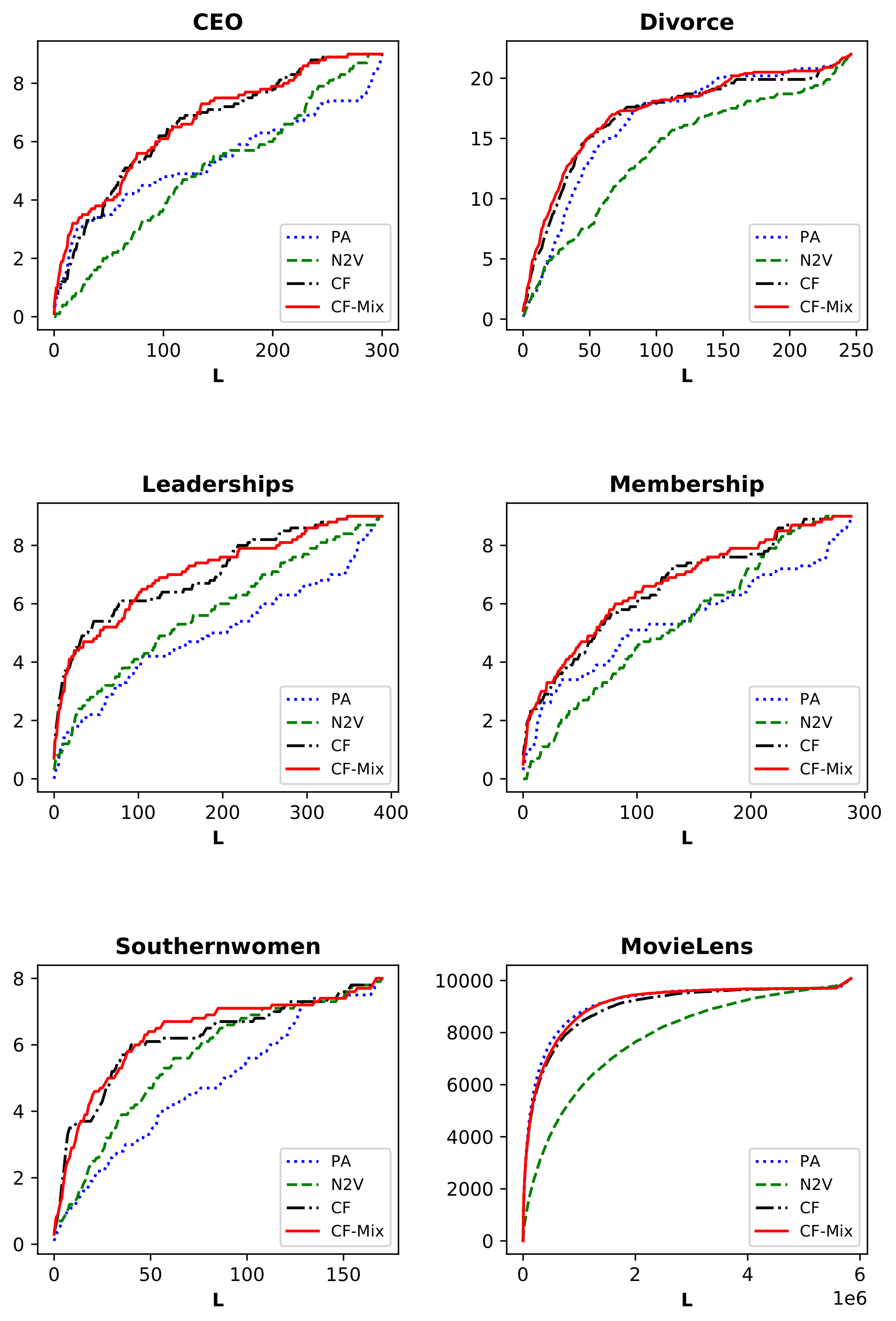
We experiment with our mixed index on six public benchmark datasets and acquire better prediction accuracy and generalization ability in most cases.
The rest of the paper proceeds as follows.
Section 2 summarizes the related work on link prediction in bipartite graph and recommendation algorithms.
Section 3 introduces our proposed similarity measure, its definition and properties.
Section 4 describes the experiments and analyzes the performance of our index. Finally, we conclude the paper with future work in
Section 5.
3. Methods
The similarity measurements for bipartite-graph recommender systems are classified as item-based similarity and user-based similarity, both of which focus on the common neighbors of targeted nodes. For example, the similarity between two items
can be defined as the number of users that once had these two items. Also, normalization is always introduced to make the similarity more reasonable, such as the cosine-similarity-based Salton Index (SA) [
23],
And in the frame of item-based CF index, the interest of user
u on item
j can be defined as
where
is the similarity between items
and the summation is always performed on items with the top
k similarities.
The similarity of the CF index is always related to the common neighbor information of targeted items
, which neglects the structural information in their local environment. To reflect more local structures, a motif-based similarity will be introduced to reveal the local connection density,
where
is the set of four cycles involving items
and
is the set of four chains involving
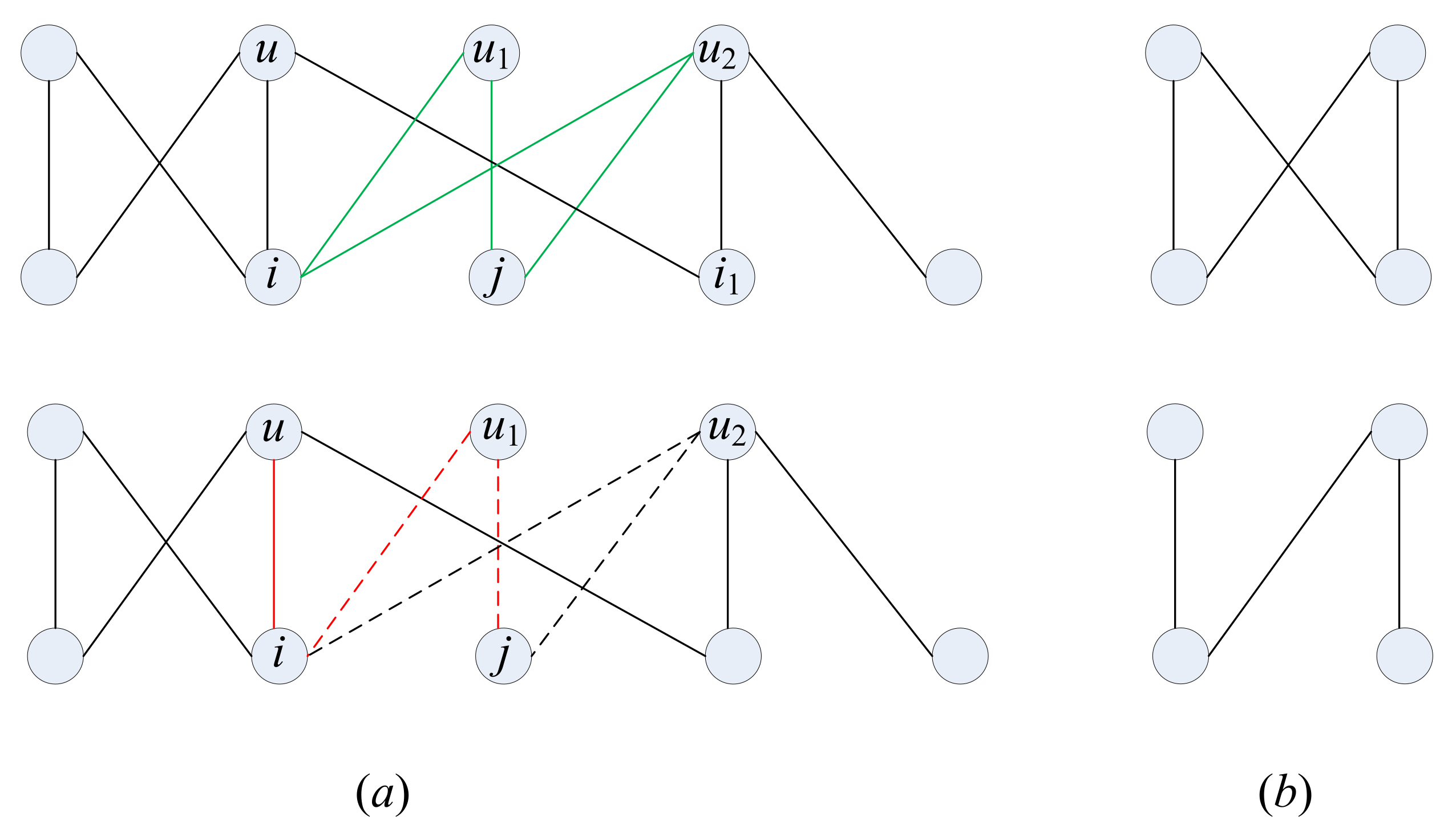
. A schematic view of the difference between
and
is shown in
Figure 1a. Similar to the CF index, the potential of connection between user
u and item
j can be defined as
In the viewpoint of the study of motifs and the example in
Figure 1, traditional similarity indexes mostly consider the common neighbors, which are indeed three motifs. However, our proposed motif-based similarity considers the four motif such as four chains or four cycles, which can be treated as a high-order evaluation on the local structures. Combining the effect of CF index and the
index, a mixed strategy for the potential evaluation between user
u and item
j can be given as
where the first term in the summation can be viewed as a three order structure (3-motif) statistics, the second term is a four order structure (four motif) statistics and
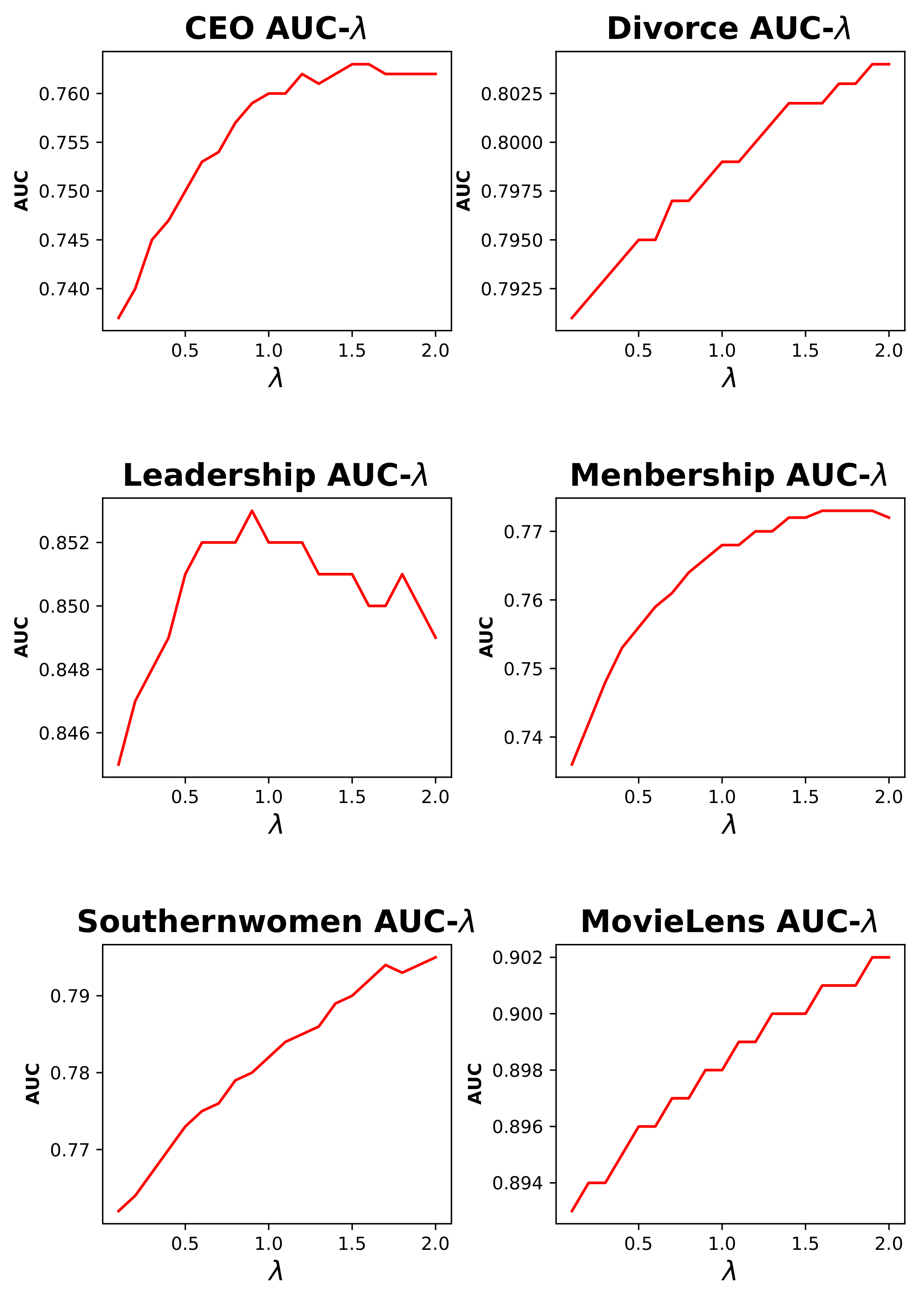
is an adjustable weight measuring the contribution of four motifs in the definition. There is no definite standard for the choice of weight
. As we will see in the experiments section, the best value of
is different in different networks. With regard to application, we strongly recommend that users test different values of
and select the best one.
The definition of the CF-Mix index combines two kinds of local structures and can reflect more local structural information. Also, inspired by the Taylor formula expansion, higher order characteristics can describe more details of the potential correlations among objects. As four cycles of targeted items in the CF-Mix index only emerge in the common neighbors, the counting of four cycles only exploit special structures with thier common neighborhood of , which brings no more time consumption. For the 4 chains with item j as an end, it is induced by nodes and one of their common neighbors with some neighbors of node i. So the counting of such four chains only consider the wedges’ (induced by and one of their common neighbors) number multiplied by degree of i, which does not increase the computational complexity. Thus, the CF-Mix index has no more time consumption than the CF but it contains more information.
For items , counting the number of covers that of because belongs to . Therefore, to find all the members of , the main effort is to enumerate all the neighbors of item i and j and check whether i connects j’s neighbor or j connects i’s neighbor. The number of such operation will not exceed and its computational cost will not be greater than , in which N is the number of users. Also, to find all the members of , we need to find all the common neighbors of i and j, so the computational cost will not be greater than either. Therefore, the computational cost of calculating between user u and item j will be at the level of , in which M is the number of items. In addition, detecting four motifs structures has the same computational cost as three motifs structures, and this can be generalized to more complicated motifs structures on bipartite graphs.
5. Conclusions and Discussions
The link prediction problem on bipartite graphs is a widely researched topic in graph learning, and most of the recommendation rules focus on the local structures or user/item based similarity. In this paper, a motif-based similarity for items is proposed based on some typical four motif structures, which sufficiently uses the relations of the targeted user and item, and a CF-Mix index based on the classical CF index, but considering both three motifs and four motifs is provided for potential edge prediction. Experiments on some real-world datasets show the efficiency of our proposed method, and the contribution of four motifs on different networks is also discussed by optimizing the mixed parameter .
As a generalization, other higher order structures such as five motifs or six motifs can also be used to optimize the definition of the CF-Mix index, but corresponding higher computational complexity will arise, which will create a large obstacle for large-scale networks. Higher order motifs may lead to a sharp increasing of the motif number, and the effective way to detect key motifs in local structures (e.g., random walk) will be an interesting direction for link prediction investigation, which will be studied in our future work.Also, the similarity measurement and link prediction problem based on graph structure can provide an alternative research tool for synchronization and control of complex networks, especially those with a bipartite structure. The similarity measurement proposed in this paper, which is based on high-order topology of bipartite graphs, can be applied to the collaborative control and synchronization optimization of complex networks by effectively combining neural network methods [
31,
32]. This is also an important and meaningful research direction.
In terms of application, our proposed method also has huge potential. Up to now, link prediction methods have been successfully applied to many fields. For instance, Kagan et al. utilized link prediction algorithms to detect fake profiles in social networks [
33]. Meanwhile, Berlusconi et al. [
34] and Calderoni et al. [
35] applied this technique to criminology studies, which is a very practical and meaningful scenario. On the other hand, Barbieri et al. presented a link prediction-based method to make user recommendations on Twitter and Flickr [
36], while Pham et al. carried out link prediction experiments in the biomedical domain to exploit potential protein interaction [
37]. In view of the great success of our proposed method on test datasets, we have begun to consider how to apply it in practice, which is also an open topic for researchers to study.







{kind=link}
{kind=link}
{kind=link}
{kind=link}