
Application of Machine Learning Model for the Prediction of Settling Velocity of Fine Sediments


Abstract
:1. Introduction
1.1. Background and Problem Statement
1.2. Machine Learning Model
1.3. Research Objective
2. Methodology
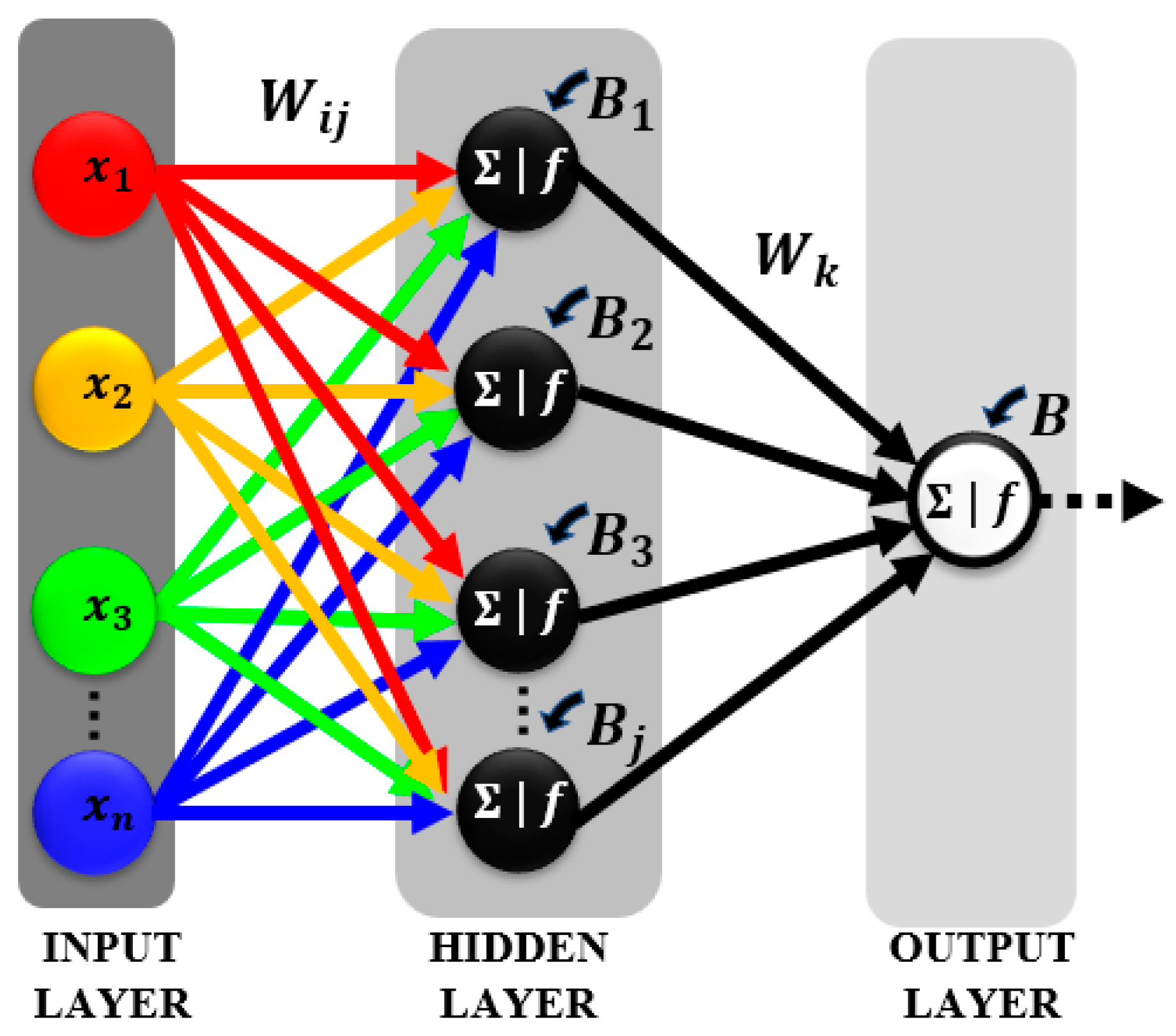
2.1. Radial Basis Function Neural Network (RBFNN)
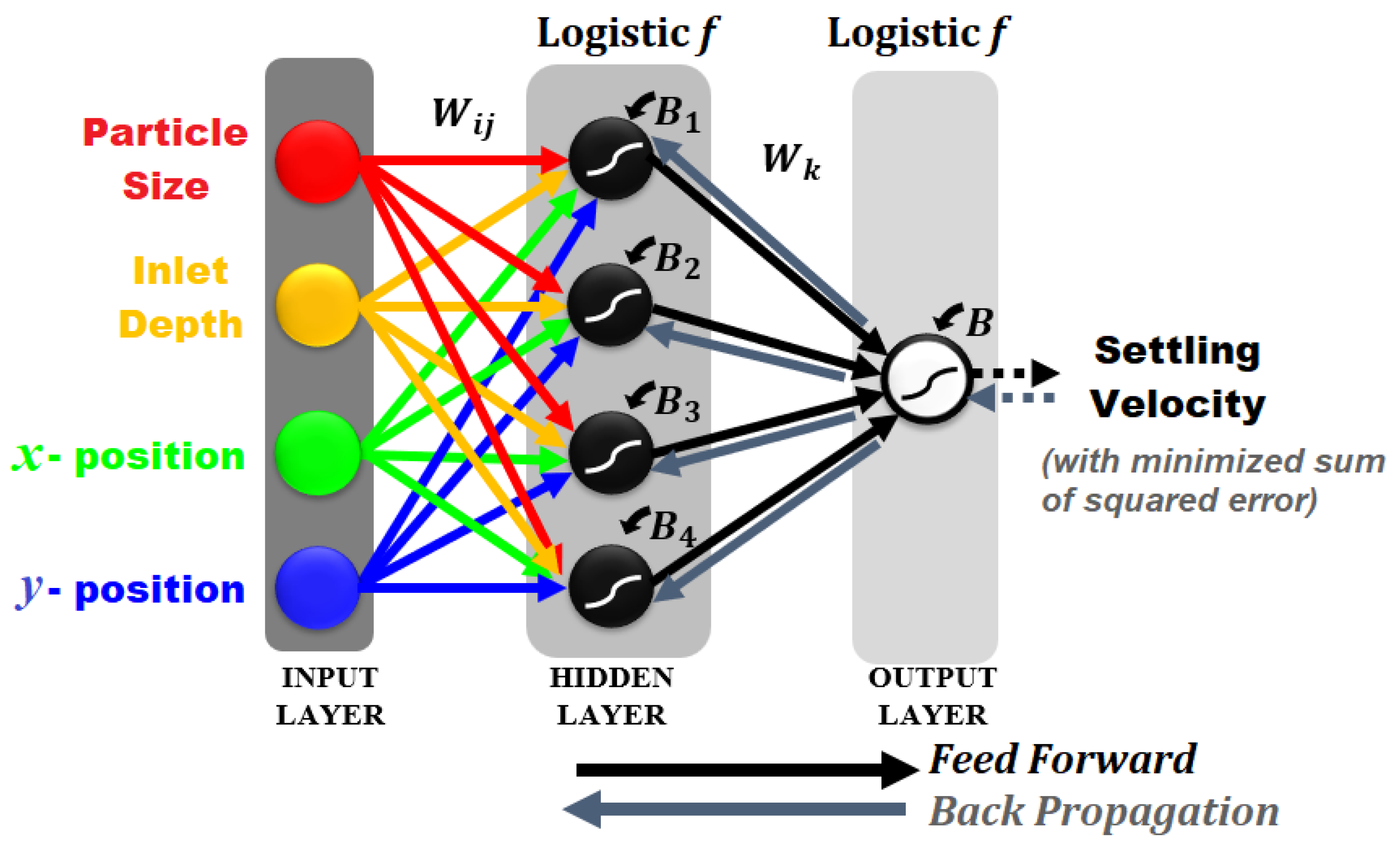
2.2. Back Propagation Neural Network (BPNN)
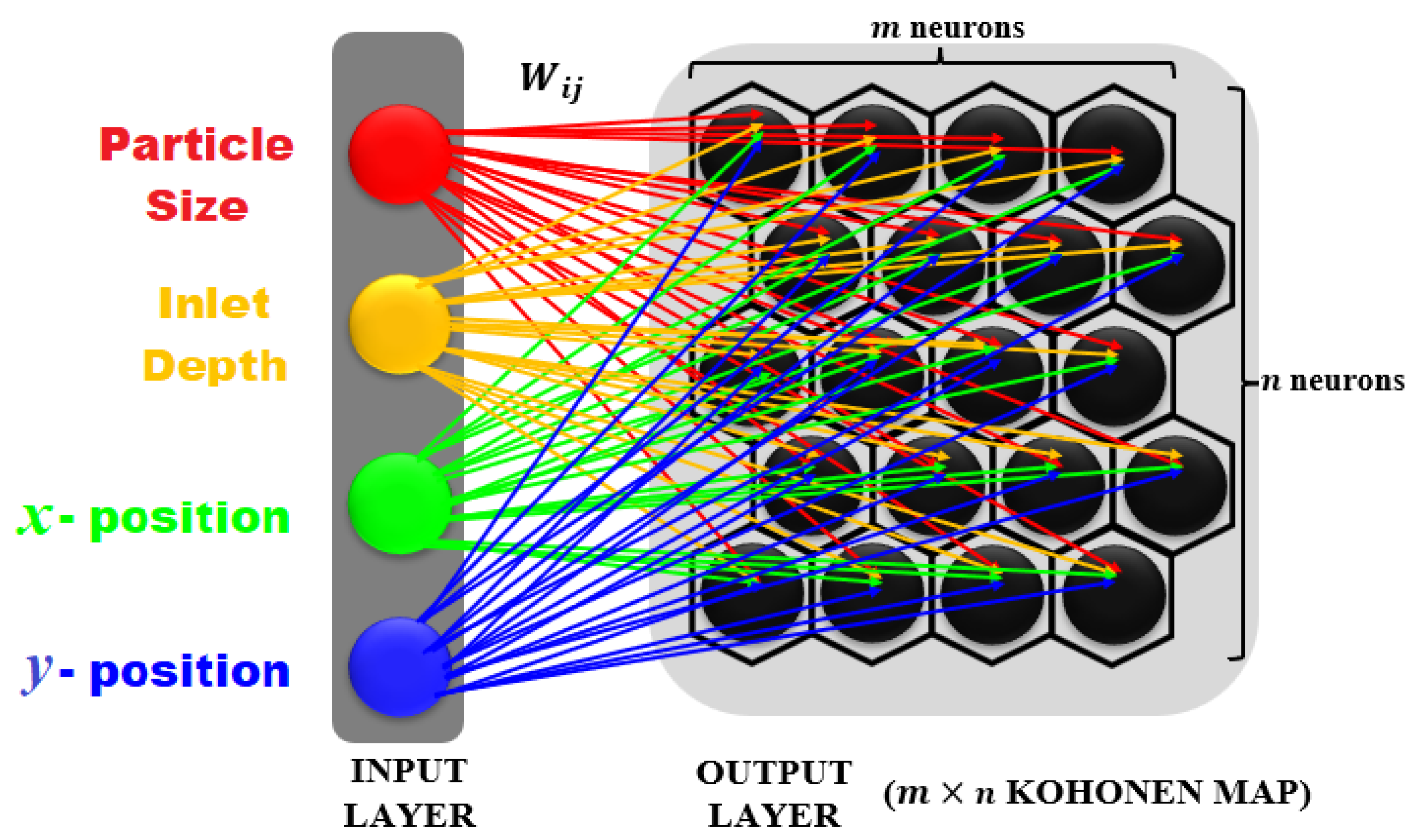
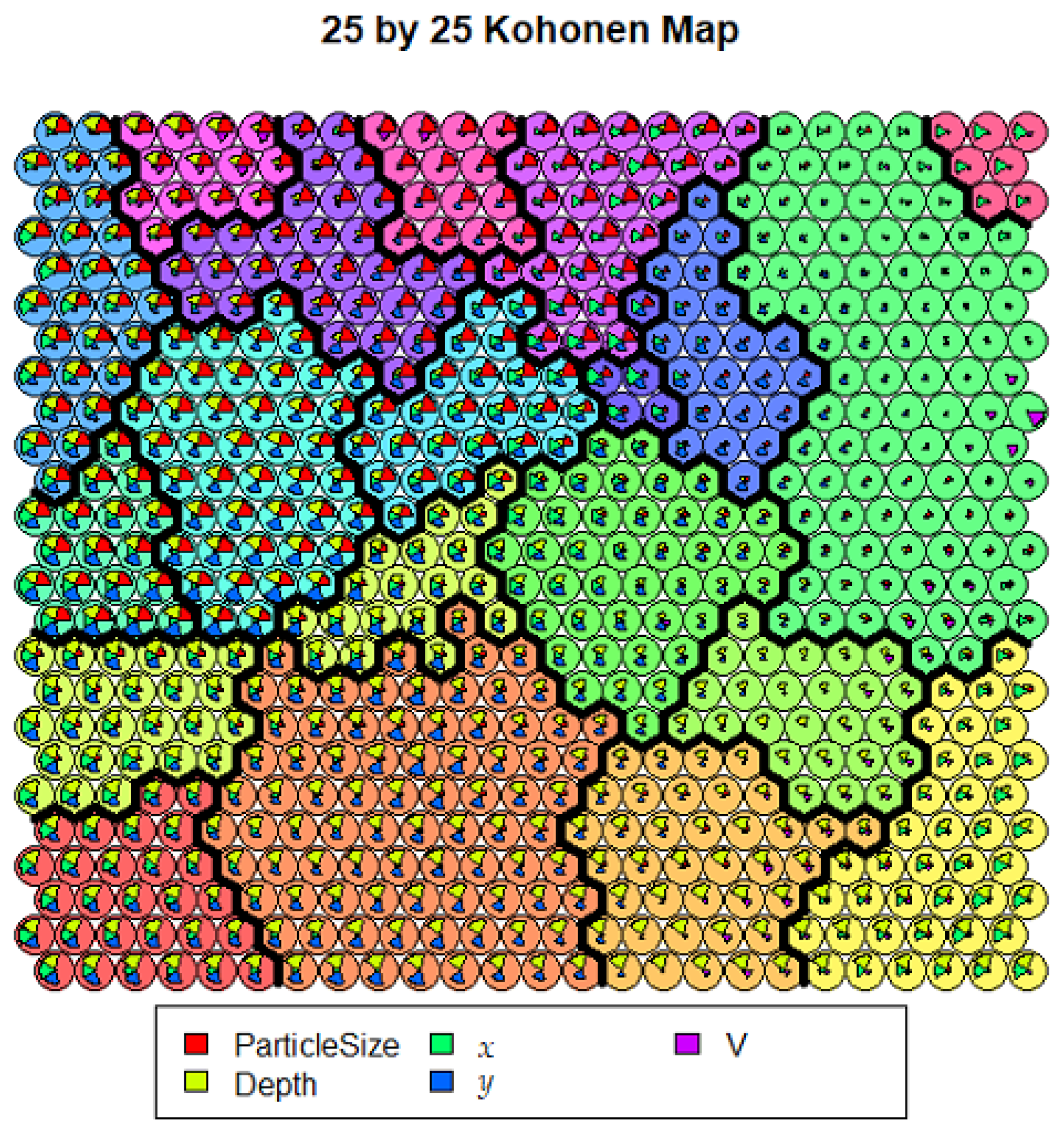
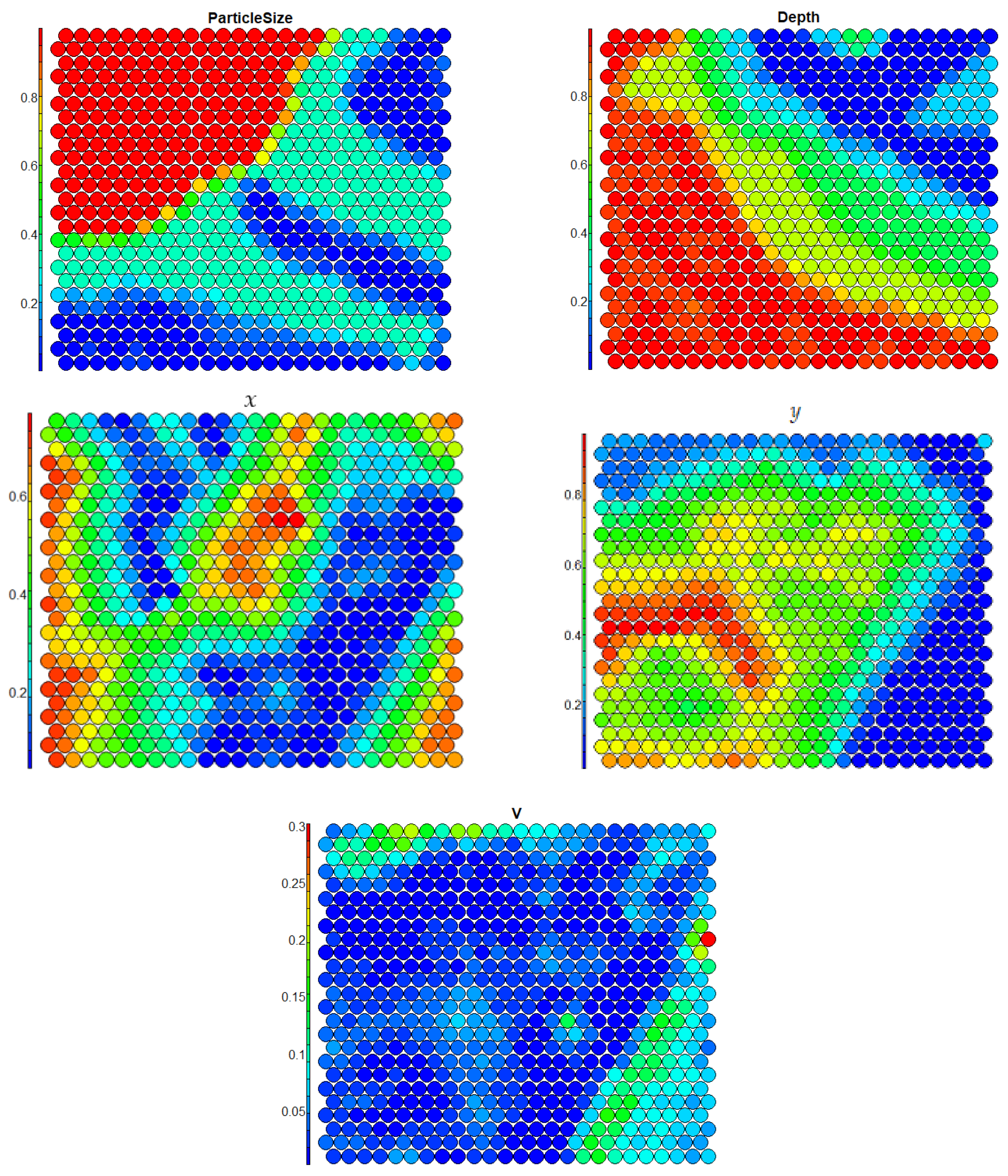
2.3. Self-Organizing Feature Map (SOFM)
2.4. Performance Measures
- (i)
- Root mean square error (RMSE):
- (ii)
- Nash–Sutcliffe efficiency (NSE):
- (iii)
- Mean absolute error (MAE):
- (iv)
- Mean value accounted for (MVAF):
- (v)
- Total variance explained (TVE):
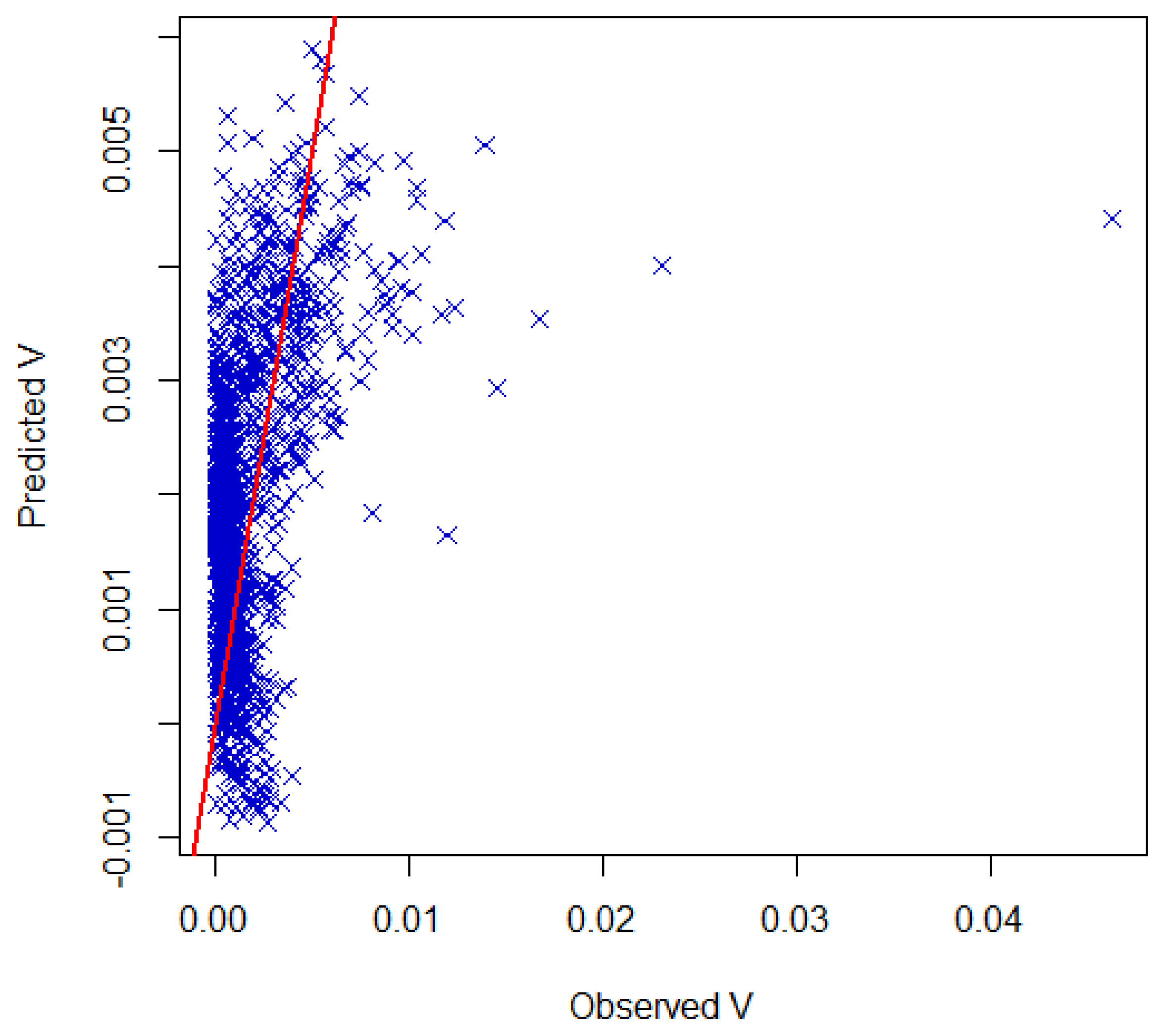
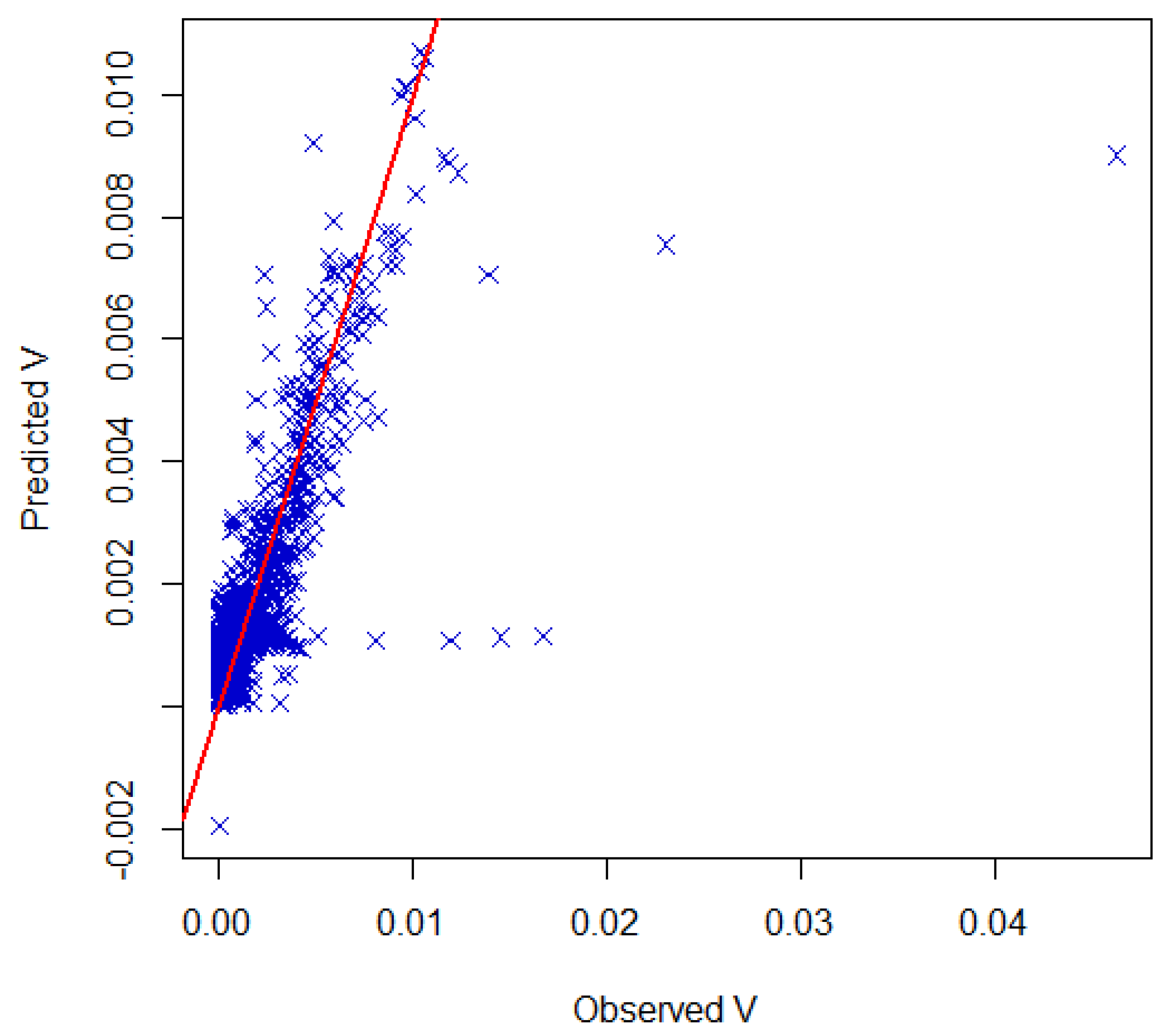
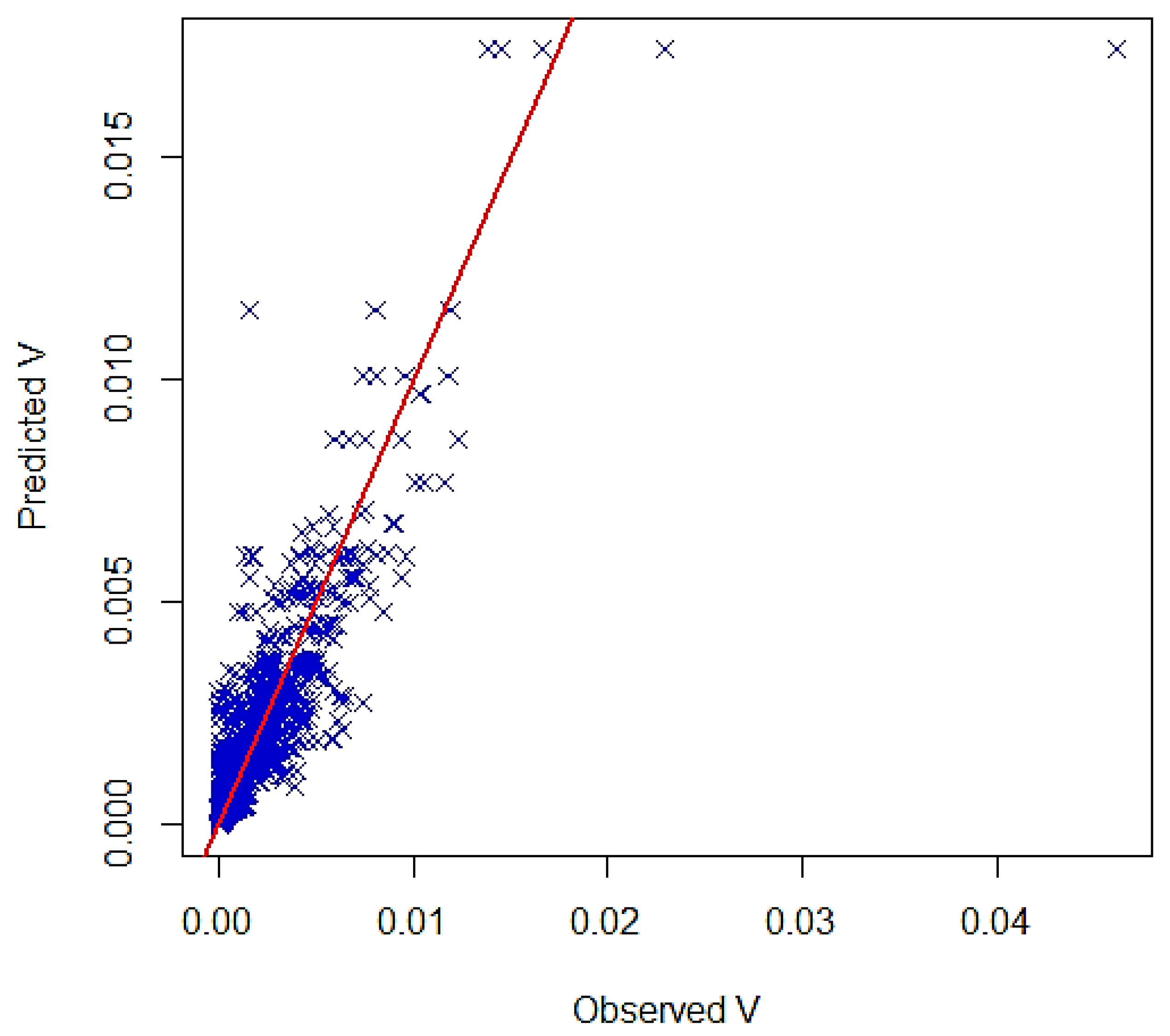
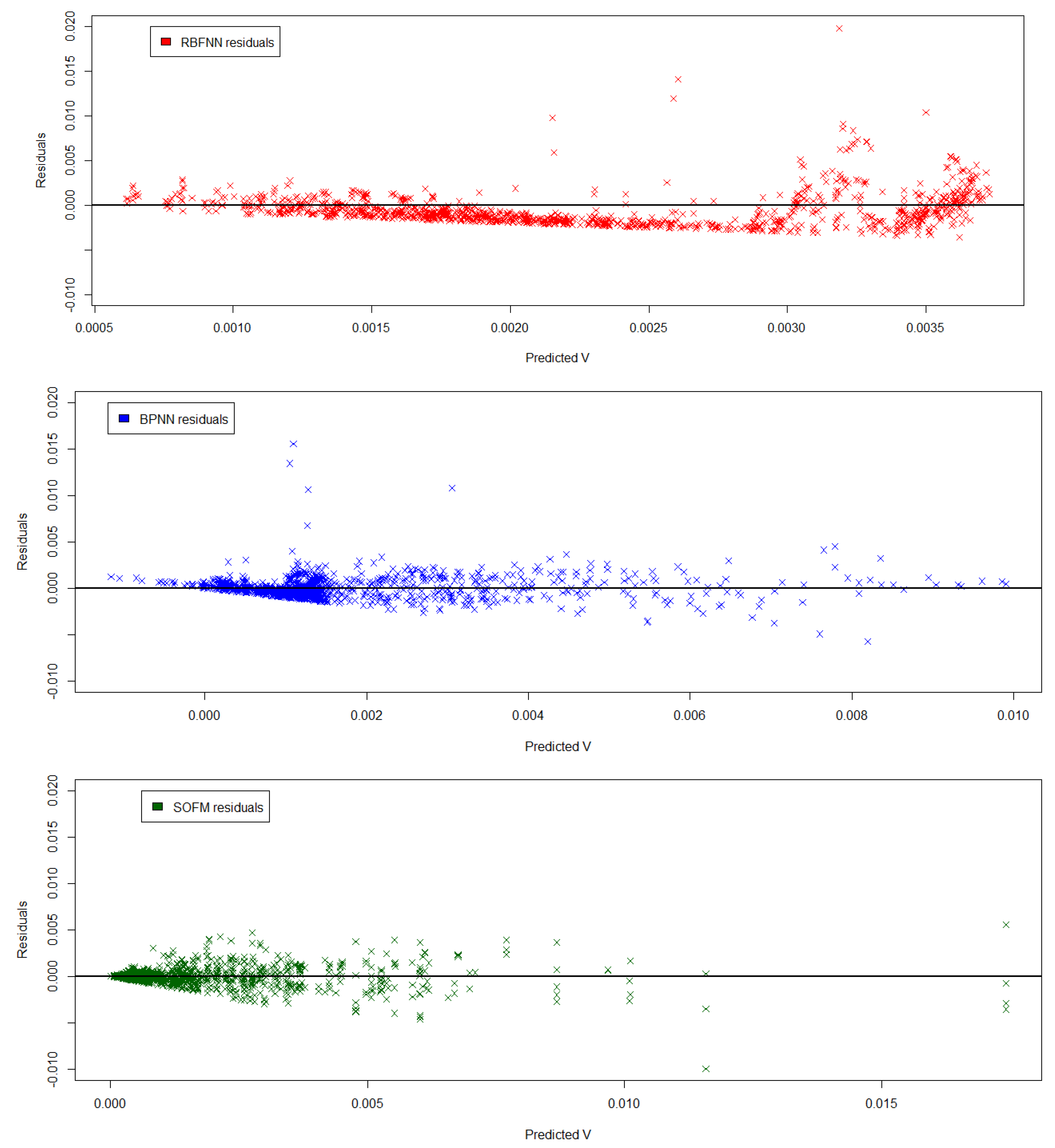
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ling, L.; Yusop, Z.; Ling, J.L. Statistical and Type II Error Assessment of a Runoff Predictive Model in Peninsula Malaysia. Mathematics 2021, 9, 812. [Google Scholar] [CrossRef]
- Gupta, S.; Larson, W. Estimating Soil Water Retention Characteristics from Particle Size Distribution, Organic Matter Percent, and Bulk Density. Water Resour. Res. 1979, 15, 1633–1635. [Google Scholar] [CrossRef]
- Sargaonkar, A.; Deshpande, V. Development of an Overall Index of Pollution for Surface Water Based on a General Classification Scheme in Indian Context. Environ. Monit. Assess. 2003, 89, 43–67. [Google Scholar] [CrossRef]
- Farias, C.A.S.; Santos, C.A.G. Self-organizing Maps for Hydro-sedimentological Modeling. In Proceedings of the X Encontro Nacional de Engenharia de Sedimentos, Foz do Iguacu, Brazil, 4–6 December 2012. [Google Scholar]
- Wahab, N.A.; Kamarudin, M.K.A.; Toriman, M.E.; Juahir, H.; Saad, M.H.M.; Ata, F.M.; Ghazali, A.; Hassan, A.R.; Abdullah, H.; Maulud, K.N.; et al. Sedimentation and Water Quality Deterioration Problems at Terengganu River Basin, Terengganu, Malaysia. Desalin. Water Treat. 2019, 149, 228–241. [Google Scholar] [CrossRef] [Green Version]
- Mietta, F.; Chassagne, C.; Winterwerp, J.C. Shear-induced Flocculation of a Suspension of Kaolinite as a function of pH and Salt Concentration. Colloid Interface Sci. 2009, 336, 134–141. [Google Scholar] [CrossRef]
- Stone, M.; Krishnappan, B. Floc Morphology and Size Distributions of Cohesive Sediment in Steady-state Flow. Water Resour. Res. 2003, 37, 2739–2747. [Google Scholar] [CrossRef]
- Mitchell, P.J.; Spence, M.A.; Aldrige, J.; Kotilainen, A.T.; Diesing, M.A. Sedimentation Rates in the Baltic Sea: A Machine Learning Approach. Cont. Shelf Res. 2021, 214, 104325. [Google Scholar] [CrossRef]
- Maggi, F. The Settling Velocity of Mineral, Biomineral, and Biological Particles and Aggregates in Water. Geophys. Res. Oceans 2013, 118, 2118–2132. [Google Scholar] [CrossRef]
- Van Leussen, W. Fine Sediment Transport Under Tidal Action. Geo-Mar. Lett. 1991, 11, 119–126. [Google Scholar] [CrossRef]
- Xu, F.; Wang, D.P.; Riemer, N. Modeling Flocculation Processes of Fine-grained Particles Using a Size-resolved Method: Comparison with Published Laboratory Experiments. Cont. Shelf Res. 2008, 28, 2668–2677. [Google Scholar] [CrossRef]
- Wang, J.; Edwards, P.J.; Wood, F. Turbidity and Suspended-Sediment Changes from Stream-Crossing Construction on a Forest Haul Road in West Virginia, USA. Int. J. For. Eng. 2013, 23, 76–90. [Google Scholar] [CrossRef] [Green Version]
- Astray, G.; Soto, B.; Barreiro, E.; Galvez, J.F.; Mejuto, J.C. Machine Learning applied to the Oxygen-18 Isotopic Composition, Salinity, and Temperature/ Potential Temperature in the Mediterranean Sea. Mathematics 2021, 9, 2523. [Google Scholar] [CrossRef]
- Makarynskyy, O.; Makarynska, D.; Rayson, M.; Langtry, S. Combining Deterministic Modelling with Artificial Neural Networks for Suspended Sediment Estimates. Appl. Soft Comput. 2015, 35, 247–256. [Google Scholar] [CrossRef]
- Hameed, M.; Sharqi, S.S.; Afan, H.A.; Yaseen, Z.M.; Hussain, A.; El-Shafie, A. Application of Artificial Intelligence (AI) Techniques in Water Quality Index Prediction: A Case Study in Tropical Region, Malaysia. Neural Comput. Appl. 2017, 28, 893–905. [Google Scholar] [CrossRef]
- Ouillon, S. Why and How Do We Study Sediment Transport? Focus on Coastal Zones and Ongoing Methods. Water 2018, 10, 390. [Google Scholar] [CrossRef]
- Vercryusse, K.; Grabowski, R.C.; Rickson, R.J. Suspended Sediment Transport Dynamics in Rivers: Multi-scale Drivers of Temporal Variation. Earth Sci. Rev. 2017, 166, 38–52. [Google Scholar] [CrossRef] [Green Version]
- Kashani, M.M.; Lai, S.H.; Ibrahim, S.; Meriam, N.; Sulaiman, N. A Study on Hydrodynamic Behavior of Fine Sediment in Retention Structure Using Particle Image Velocimetry. Water Environ. Res. 2016, 88, 2309–2320. [Google Scholar]
- Barati, R.; Salehi Neyshabouri, S.A.A.; Ahmadi, G. Sphere Drag Revisited Using Shuffled Complex Evolution Algorithm. In Proceedings of the International Conference on Fluvial Hydraulics (River Flow 2014), Lausanne, Switzerland, 3–5 September 2014. [Google Scholar]
- Barati, R.; Salehi Neyshabouri, S.A.A.; Ahmadi, G. Issues in Eulerian-Lagrangian Modelling of Sediment Transport Under Saltation Regime. Int. J. Sed. Res. 2018, 33, 441–461. [Google Scholar] [CrossRef]
- Barati, R.; Salehi Neyshabouri, S.A.A.; Ahmadi, G. Development of Empirical Models with High Accuracy for Estimation of Drag Coeeficient of Flow Around a Smooth Sphere: An Evolutionary Approach. Powder Technol. 2014, 257, 11–19. [Google Scholar] [CrossRef]
- Cao, Z.; Wofram, P.J.; Rowland, J.; Zhang, Y.; Pasqualini, D. Estimating Sediment Settling Velocity from a Theoretically Guided Data-Driven Approach. Hydraul. Eng. 2020, 146, 1–12. [Google Scholar] [CrossRef]
- Rushd, S.; Parvez, M.T.; Al-Faiad, M.A.; Islam, M.M. Towards Optimal Machine Learning Model for Terminal Settling Velocity. Powder Technol. 2021, 387, 95–107. [Google Scholar] [CrossRef]
- AlDahoul, N.; Essam, Y.; Kumar, P.; Ahmed, A.M.; Sherif, M.; Sefelnasr, A.; Elshafie, A. Suspended Sediment Load Prediction Using Long Short-Term Memory Neural Network. Sci. Rep. 2021, 11, 7826. [Google Scholar] [CrossRef] [PubMed]
- Zahraee, S.; Assadi, M.K.; Saidur, R. Application of Artificial Intelligence Methods for Hybrid Energy System Optimization. Renew. Sustain. Energy Rev. 2016, 66, 617–630. [Google Scholar] [CrossRef]
- Dirican, C. The Impacts of Robotics, Artificial Intelligence on Business and Economics. Procedia-Soc. Behav. Sci. 2015, 195, 564–573. [Google Scholar] [CrossRef] [Green Version]
- Briceno, J.; Cruz-Ramirez, M.; Prieto, M.; Navasa, M.; Urniba, J.O. Use of Artificial Intelligence as an Innovative Donor-recipient Matching Model for Liver Transplantation: Results from a Multicenter Spanish Study. J. Hepatol. 2014, 61, 1020–1028. [Google Scholar] [CrossRef]
- Khalil, B.M.; Awadallah, A.G.; Karaman, H.; El-Sayed, A. Application of Artificial Neural Networks for the Prediction of Water Quality Variables in the Nile Delta. Water Resour. Prot. 2012, 4, 388–394. [Google Scholar] [CrossRef] [Green Version]
- Nasr, M.S.; Moustafa, M.A.; Seif, H.A.; Kobrosy, G.E. Application of Artificial Neural Network (ANN) for the Prediction of EL-AGAMY Wastewater Treatment Plant Performance-EGYPT. Alex. Eng. 2012, 51, 37–43. [Google Scholar] [CrossRef] [Green Version]
- Burgan, H.I.; Aksoy, H. Annual Flow Duration Curve Model for Ungauged Basins. Hydrol. Res. 2018, 49, 1684–1695. [Google Scholar] [CrossRef]
- Portal-Porras, K.; Fernandez-Gamiz, U.; Ugarte-Anero, A.; Zulueta, E.; Zulueta, A. Alternative Artificial Neural Network Structures for Turbulent Flow Velocity Field Prediction. Mathematics 2021, 9, 1939. [Google Scholar] [CrossRef]
- Alhumade, H.; Rezk, H.; Al-Zaharani, A.A.; Zaman, S.F.; Askalany, A. Artificial Intelligence Based Modelling of Adsorption Water Desalination System. Mathematics 2021, 9, 1674. [Google Scholar] [CrossRef]
- Pektas, A.O.; Dogan, E. Prediction of Bed Load via Suspended Sediment Load Using Soft Computing Methods. Geofizika 2015, 32, 27–46. [Google Scholar] [CrossRef]
- Deng, B.; Chin, R.J.; Tang, Y.; Jiang, C.; Lai, S.H. New Approach to Predict the Motion Characteristics of Single Bubbles in Still Water. Appl. Sci. 2019, 9, 3981. [Google Scholar] [CrossRef] [Green Version]
- Chin, R.J.; Lai, S.H.; Ibrahim, S.; Wan Jaafar, W.Z.; Elshafie, A. New Approach to Mimic Rheological Actual Shear Rate Under Wall Slips Condition. Eng. Comp. 2019, 35, 1409–1418. [Google Scholar] [CrossRef]
- Chin, R.J.; Lai, S.H.; Ibrahim, S.; Wan Jaafar, W.Z.; Elshafie, A. Rheological Wall Slip Velocity Prediction Model Based on Artificial Neural Network. Exp. Theor. Artif. Intell. 2019, 31, 659–676. [Google Scholar] [CrossRef]
- Obradovic, D.; Deco, G. An Information-Theoretic Approach to Neural Computing. Perspective in Neural Computing, 1st ed.; Springer: Berlin/Heidelberg, Germany, 1996; pp. 65–107. [Google Scholar]
- Afan, H.A.; El-shafie, A.; Yaseen, Z.M.; Allawi, M.F. Input Attributes Optimization Using the Feasibility of Genetic Nature Inspired Algorithm: Application of River Flow Forecasting. Nature 2020, 10, 4684. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial Neural Networks in Hydrology. I: Preliminary Concepts. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial Neural Networks in Hydrology. II: Hydrologic Applications. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- Prasad, A.K. Particle Image Velocimetry: Simulation of Tropical Cyclones Photoperiodic Response in Subarctic Ants. Curr. Sci. 2000, 79, 51–60. [Google Scholar]
- Akter, T.; Desai, S. Developing a Predictive Model for Nanoimprint Lithography Using Artificial Neural Networks. Mater. Des. 2018, 160, 836–848. [Google Scholar] [CrossRef]
- Ye, K.; Zhang, Y.; Yang, L.; Zhao, Y.; Li, N.; Xie, Z. Modeling Connective Heat Transfer of Supercritical Carbon Dioxide Using an Artificial Neural Network. Appl. Therm. Eng. 2019, 150, 686–695. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, H.; Yang, B.; Fu, S.; Yu, J.; Wang, Z. Prediction of Phosphate Concentration Grade Based on Artificial Neural Network Modeling. Results Phys. 2018, 11, 625–628. [Google Scholar] [CrossRef]
- Aksu, G.; Guzeller, C.O.; Eser, T. The Effect of Normalization Method Used in Different Sample Sizes on the Success of Artificial Neural Network Model. Int. J. Assess. Tools Educ. 2019, 6, 170–192. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Wang, S.; Lai, K.K. An Integrated Data Preparation Scheme for Neural Network Data Analysis. IEEE Trans. Knowl. Data Eng. 2006, 18, 217–230. [Google Scholar]
- Tayfur, G. Soft Computing in Water Resources Engineering: Artificial Neural Networks, Fuzzy Logic and Genetic Algorithms, 1st ed.; WIT Press: Southampton, UK, 2012; pp. 25–43. [Google Scholar]
- Allawi, M.F.; Othman, F.B.; Afan, H.A.; Ahmed, A.N.; Hossain, M.S.; Chow, M.F.; El-Shafie, A. Reservoir Evaporation Prediction Modeling Based on Artificial Intelligence Methods. Water 2019, 11, 1226. [Google Scholar] [CrossRef] [Green Version]
- Maier, H.R.; Dandy, G.C. Neural Networks for the Prediction of Water Resources Variables: A Review of Modelling Issues and Applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Kelley, H.J. Gradient Theory of Optimal Flight Paths. Am. Rocket Soc. 1960, 30, 947–964. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 318–362. [Google Scholar]
- Rushd, S.; Hafsa, N.; Al-Faiad, M.; Arifuzzaman, M. Modelling the Settling Velocity of a Sphere in Newtonian and non-Newtonian Fluids with Machine-Learning Algorithms. Symmetry 2021, 13, 71. [Google Scholar] [CrossRef]
- Kohonen, T. Analysis of a Simple Self-Organizing Process. Biol. Cybern. 1982, 44, 135–140. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organized Formation of Topologically Correct Feature Maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Han, D.M.; Song, X.F.; Currell, M.J.; Cao, G.L. A Survey of Groundwater Levels and Hydrogeochemistry in Irrigated Fields in the Karamay Agriculture Development Area, Northwest China: Implications for Soil and Groundwater Salinity Resulting from Surface Water Transfer for Irrigation. Hydrology 2011, 405, 217–234. [Google Scholar] [CrossRef]
- Nakagawa, K.; Amano, H.; Kawamura, A.; Berndtsson, R. Classification of Groundwater Chemistry in Shimabara, Using Self-Organizing Maps. Hydrol. Res. 2017, 48, 840–850. [Google Scholar] [CrossRef] [Green Version]
- Iwashita, F.; Friedel, M.J.; Ferreira, J.F. A Self-Organizing Map Approach to Characterize Hydrogeology of the Fractured Serra-Geral Transboundary Aquifer. Hydrol. Res. 2017, 49, 794–814. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Architecture * | RMSE | NSE | MAE | MVAF (%) | TVE (%) |
|---|---|---|---|---|---|
| 4-10-1 | 0.002739 | 0.1409 | 0.001616 | 195.21 | 20.37 |
| 4-11-1 | 0.002666 | 0.1469 | 0.001493 | 187.87 | 20.27 |
| 4-12-1 | 0.002798 | 0.1333 | 0.024785 | 200.47 | 19.94 |
| 4-13-1 | 0.002681 | 0.1442 | 0.001898 | 189.09 | 20.05 |
| 4-14-1 | 0.002800 | 0.1261 | 0.001477 | 199.34 | 18.73 |
| 4-15-1 | 0.002717 | 0.1400 | 0.001527 | 192.50 | 19.89 |
| 4-16-1 | 0.002667 | 0.1478 | 0.001409 | 188.18 | 20.43 |
| 4-17-1 | 0.002495 | 0.0966 | 0.001504 | 153.50 | 11.02 |
| 4-18-1 | 0.002711 | 0.1435 | 0.002134 | 192.51 | 20.38 |
| 4-19-1 | 0.002760 | 0.1370 | 0.001420 | 196.88 | 20.03 |
| 4-20-1 | 0.002502 | 0.1196 | 0.001483 | 160.03 | 14.08 |
| Network Architecture * | RMSE | NSE | MAE | MVAF (%) | TVE (%) |
|---|---|---|---|---|---|
| 4-1-1 | 0.001893 | 0.4069 | 0.000851 | 97.51 | 40.70 |
| 4-2-1 | 0.001860 | 0.4275 | 0.000813 | 97.02 | 42.76 |
| 4-3-1 | 0.001856 | 0.4230 | 0.000792 | 96.89 | 43.02 |
| 4-4-1 | 0.001798 | 0.4652 | 0.000759 | 97.24 | 46.54 |
| 4-5-1 | 0.001780 | 0.4755 | 0.000745 | 97.63 | 47.57 |
| 4-6-1 | 0.001767 | 0.4834 | 0.000703 | 97.28 | 48.36 |
| 4-7-1 | 0.001582 | 0.5858 | 0.000683 | 97.09 | 58.61 |
| 4-8-1 | 0.001704 | 0.5216 | 0.000722 | 97.28 | 51.98 |
| 4-9-1 | 0.001641 | 0.5542 | 0.000682 | 97.30 | 55.44 |
| Network Architecture * | RMSE | NSE | MAE | MVAF (%) | TVE (%) |
|---|---|---|---|---|---|
| 21 × 21 | 0.001611 | 0.5706 | 0.000731 | 98.85 | 57.06 |
| 22 × 23 | 0.001523 | 0.6160 | 0.000696 | 96.66 | 61.64 |
| 23 × 23 | 0.001519 | 0.6178 | 0.000702 | 99.83 | 61.78 |
| 23 × 24 | 0.001350 | 0.6984 | 0.000646 | 97.42 | 69.86 |
| 24 × 24 | 0.001437 | 0.6581 | 0.000656 | 98.11 | 65.82 |
| 25 × 24 | 0.001430 | 0.6640 | 0.000655 | 99.59 | 66.15 |
| 25 × 25 | 0.001307 | 0.7170 | 0.000647 | 101.25 | 71.71 |
| 26 × 27 | 0.001378 | 0.6859 | 0.000642 | 96.67 | 68.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loh, W.S.; Chin, R.J.; Ling, L.; Lai, S.H.; Soo, E.Z.X. Application of Machine Learning Model for the Prediction of Settling Velocity of Fine Sediments. Mathematics 2021, 9, 3141. https://doi.org/10.3390/math9233141
Loh WS, Chin RJ, Ling L, Lai SH, Soo EZX. Application of Machine Learning Model for the Prediction of Settling Velocity of Fine Sediments. Mathematics. 2021; 9(23):3141. https://doi.org/10.3390/math9233141
Chicago/Turabian StyleLoh, Wing Son, Ren Jie Chin, Lloyd Ling, Sai Hin Lai, and Eugene Zhen Xiang Soo. 2021. "Application of Machine Learning Model for the Prediction of Settling Velocity of Fine Sediments" Mathematics 9, no. 23: 3141. https://doi.org/10.3390/math9233141