
Proposal of the Dichotomous STATIS DUAL Method: Software and Application for the Analysis of Dichotomous Data, Applied to the Test of Learning Styles in University Students

 , and
, and
Abstract
:1. Introduction
2. Background
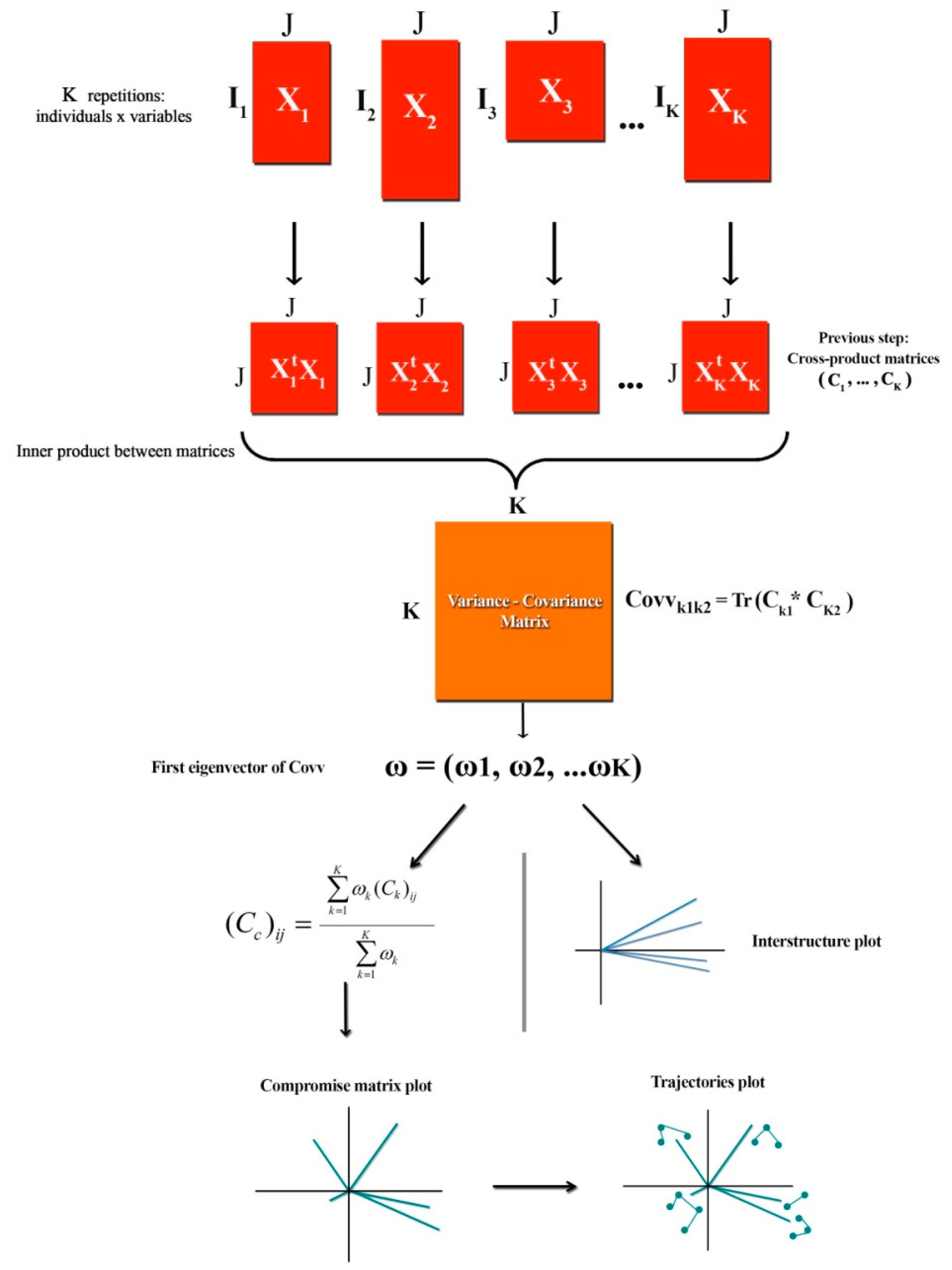
2.1. STATIS Methods
2.2. Dichotomous STATIS DUAL
2.2.1. Statistical Analysis
2.2.2. Mathematical Algorithm
3. Results
3.1. Material and Methods
3.2. Interface of the Software
3.3. Commands for the Software
3.4. Results. Example of an Empirical Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- L’Hermier des Plantes, H. Structuration Des Tableaux à Trois Indices de La Statistique. Ph.D. Thesis, Université de Montpellier II, Montpellier, France, 1976. [Google Scholar]
- Jaffrenou, P.-A. Sur l’analyse Des Familles Finies de Variables Vectorielles: Bases Algébriques et Application à La Description Statistique. Ph.D. Thesis, l’Université de Sainte-Etiene, Saint-Étienne, France, 1978. [Google Scholar]
- Thioulouse, J. Simultaneous Analysis of a Sequence of Paired Ecological Tables: A Comparison of Several Methods. Ann. Appl. Stat. 2011, 5, 2300–2325. [Google Scholar] [CrossRef] [Green Version]
- Vivien, M.; Sabatier, R. A Generalization of STATIS-ACT Strategy: DO-ACT for Two Multiblocks Tables. Comput. Stat. Data Anal. 2004, 46, 155–171. [Google Scholar] [CrossRef]
- Sauzay, L.; Hanafi, M.; Qannari, E.M.; Schlich, P. Analyse de K+ 1 Tableauxa l’aide de La Méthode STATIS: Application En Évaluation Sensorielle, 9ieme Journées Européennes Agro-Industrie et Méthodes Statistiques; Société Française de Statistique (SFdS): Montpellier, France, 2006. [Google Scholar]
- Abdi, H.; Valentin, D.; Chollet, S.; Chrea, C. Analyzing Assessors and Products in Sorting Tasks: DISTATIS, Theory and Applications. Food Qual. Prefer. 2007, 18, 627–640. [Google Scholar] [CrossRef]
- Vallejo-Arboleda, A.; Vicente-Villardón, J.L.; Galindo-Villardón, M.P. Canonical STATIS: Biplot Analysis of Multi-Table Group Structured Data Based on STATIS-ACT Methodology. Comput. Stat. Data Anal. 2007, 51, 4193–4205. [Google Scholar] [CrossRef]
- Sabatier, R.; Vivien, M. A New Linear Method for Analyzing Four-Way Multiblock Tables: STATIS-4. J. Chemom. 2008, 22, 399–407. [Google Scholar] [CrossRef]
- Marcondes Filho, D.; Fogliatto, F.S.; Oliveira, L.P.L.D. Gráficos de controle multivariados para monitoramento de processos não lineares em bateladas. Production 2011, 21, 132–148. [Google Scholar] [CrossRef] [Green Version]
- Thioulouse, J.; Simier, M.; Chessel, D. Simultaneous Analysis of a Sequence of Paired Ecological Tables. Ecology 2004, 85, 272–283. [Google Scholar] [CrossRef]
- Bénasséni, J.; Bennani Dosse, M. Analyzing Multiset Data by the Power STATIS-ACT Method. Adv. Data Anal. Classif. 2012, 6, 49–65. [Google Scholar] [CrossRef]
- Sabatier, R.; Vivien, M.; Reynès, C. Une nouvelle proposition, l’Analyse Discriminante Multitableaux: STATIS-LDA. J. Société Fr. Stat. 2013, 154, 31–43. [Google Scholar]
- Corrales, D.; Rodríguez, O. Interstatis: The Statis Method for Interval Valued Data. Rev. Matemática Teoría Apl. 2014, 21, 73–83. [Google Scholar] [CrossRef] [Green Version]
- Kriegsman, M.A. Discriminant Distatis: A Multi-Way Discriminant Analysis for Distance Matrices, Illustrations with the Sorting Task. Ph.D. Thesis, University of Texas, Dallas, TX, USA, 2018. [Google Scholar]
- Llobell, F.; Cariou, V.; Vigneau, E.; Labenne, A.; Qannari, E.M. A New Approach for the Analysis of Data and the Clustering of Subjects in a CATA Experiment. Food Qual. Prefer. 2019, 72, 31–39. [Google Scholar] [CrossRef]
- Mérigot, B.; Gaertner, J.-C.; Brind’amour, A.; Carbonara, P.; Esteban, A.; Garcia-Ruiz, C.; Gristina, M.; Imzilen, T.; Jadaud, A.; Joksimovic, A.; et al. Stability of the Relationships among Demersal Fish Assemblages and Environmental-Trawling Drivers at Large Spatio-Temporal Scales in the Northern Mediterranean Sea. Sci. Mar. 2019, 83 (Suppl. S1), 153–163. [Google Scholar] [CrossRef] [Green Version]
- Llobell, F.; Cariou, V.; Vigneau, E.; Labenne, A.; Qannari, E.M. Analysis and Clustering of Multiblock Datasets by Means of the STATIS and CLUSTATIS Methods. Application to Sensometrics. Food Qual. Prefer. 2020, 79, 103520. [Google Scholar] [CrossRef]
- Lavit, C. Analyse Conjointe de Tableaux Quantitatifs; Masson: Paris, France, 1988. [Google Scholar]
- Robert, P.; Escoufier, Y. A Unifying Tool for Linear Multivariate Statistical Methods: The RV-Coefficient. J. R. Stat. Soc. Ser. C Appl. Stat. 1976, 25, 257–265. [Google Scholar] [CrossRef]
- Ochiai, A. Zoogeographic studies on the soleoid fishes found in Japan and its neighbouring regions. Bull. Jpn. Soc. Sci. Fish. 1957, 22, 526–530. [Google Scholar] [CrossRef] [Green Version]
- Alonso, C.; Gallego, D.; Honey, Y. Cuestionario Honey-Alonso de Estilos de Aprendizaje. Procedimientos de Diagnósticos y Mejora; Ediciones Mensajero: Bilbao, Spain, 1994. [Google Scholar]
- RStudio Team. RStudio: Integrated Development for R. RStudio. PBC: Boston, MA, USA, 2020. Available online: http://www.rstudio.com/ (accessed on 3 May 2021).
- Flores, N.D.T. Análisis Multivariante de la Sostenibilidad a través del Global Reporting Initiative (GRI), Utilizando como Caso de Estudio: Brasil. In Proceedings of the Congreso Internacional De Investigación E Innovación 2016, Guanajuato, Mexico, 21–22 April 2016; p. 6. [Google Scholar]
- Cañizares, J.F.R.; Abarca, E.F.G.; Naranjo, D.N.C.; Vicente-Villardón, J.L.; Demey, J. Caracterización de germoplasma de maíz local a través de marcadores SSR asistido por biplot logístico externo (BLE). In Proceedings of the XXVI Simposio Internacional de Estadística 2016, Sincelejo, Colombia, 8–12 August 2016; p. 4. [Google Scholar]
- Rodríguez, H.d.J.D.; Limón, J.A.G.; Pisfil, M.L.; Torres, D.V.; Exume, J.C.D. Estilos de aprendizaje: Un estudio diagnóstico en el centro universitario de ciencias económico-administrativas de la U de G*. Rev. Educ. Super. 2015, 44, 121–140. [Google Scholar] [CrossRef] [Green Version]
- Viloria, A.; Petro Gonzalez, I.R.; Pineda Lezama, O.B. Learning Style Preferences of College Students Using Big Data. Procedia Comput. Sci. 2019, 160, 461–466. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
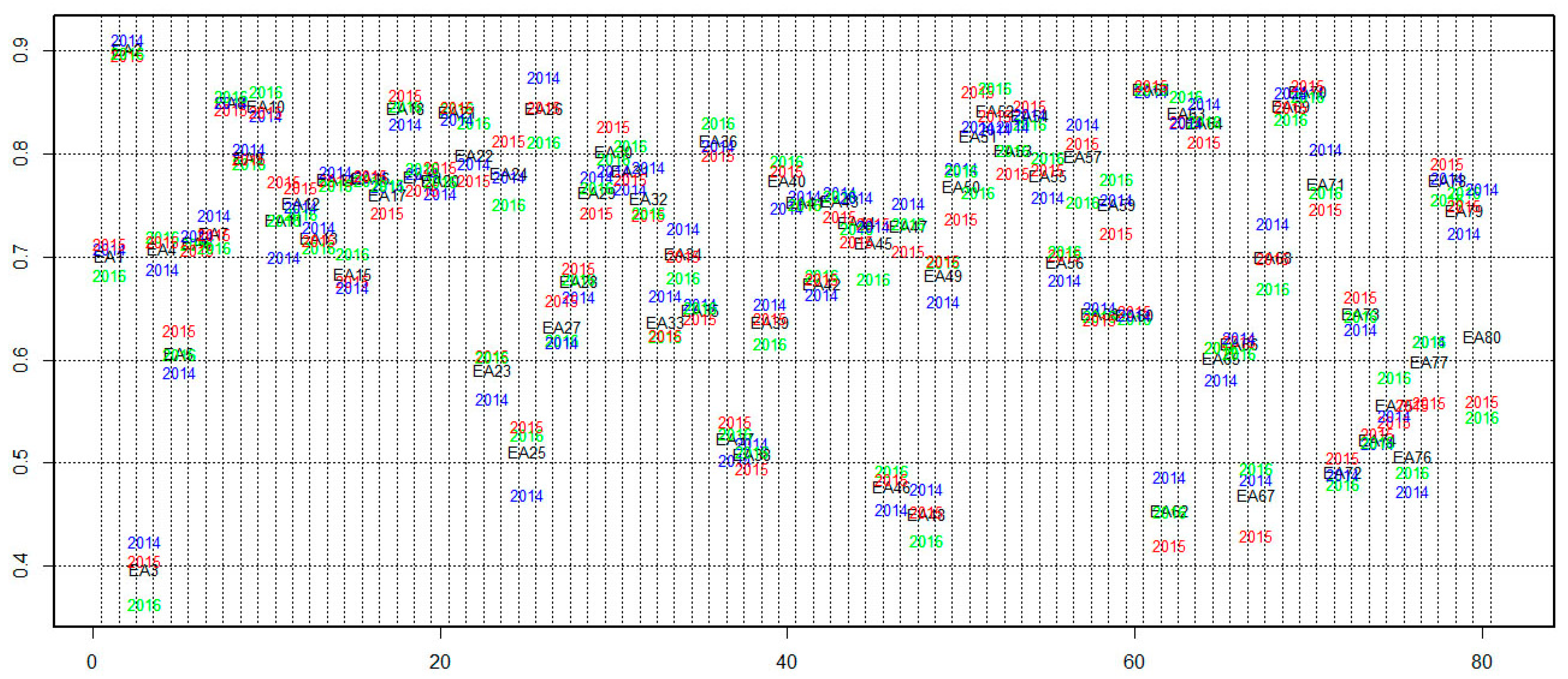
| Group | Interval of Ratios | Items Belonging to the Group | Learning Styles | |||
|---|---|---|---|---|---|---|
| Activist | Reflector | Theorist | Pragmatist | |||
| 1 | <0.5 | EA3 | 1 | 0 | 0 | 0 |
| 2 | (0.5, 0.6) | EA25, EA37, EA38, EA48, EA62, EA67, EA72, EA74, EA75, A76, EA77 | 6 | 0 | 1 | 4 |
| 3 | (0.6, 0.7) | EA5, EA6, EA7, EA13, EA23, EA27, EA28, EA33, EA35, EA39, EA42, EA46, EA47, EA49, EA56, EA58, EA60, EA65, EA68, EA73, EA80 | 6 | 6 | 7 | 4 |
| 4 | (0.7, 0.8) | EA1, EA4, EA8, EA10, EA11, EA12, EA14, EA15, EA16, EA17, EA18, EA19, EA20, EA21, EA22, EA24, EA26, EA29, EA30, EA31, EA32, EA34, EA36, EA40, EA41, EA43, EA44, EA50, EA51, EA52, EA53, EA54, EA55, EA57, EA59, EA63, EA64, EA69, EA70, EA71, EA78, EA79 | 6 | 14 | 11 | 12 |
| 5 | >0.8 | EA2, EA61 | 1 | 0 | 1 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ballesteros-Espinoza, V.I.; Rodríguez-Rosa, M.; Sánchez-García, A.B.; Vicente-Galindo, P. Proposal of the Dichotomous STATIS DUAL Method: Software and Application for the Analysis of Dichotomous Data, Applied to the Test of Learning Styles in University Students. Mathematics 2021, 9, 2797. https://doi.org/10.3390/math9212797
Ballesteros-Espinoza VI, Rodríguez-Rosa M, Sánchez-García AB, Vicente-Galindo P. Proposal of the Dichotomous STATIS DUAL Method: Software and Application for the Analysis of Dichotomous Data, Applied to the Test of Learning Styles in University Students. Mathematics. 2021; 9(21):2797. https://doi.org/10.3390/math9212797
Chicago/Turabian StyleBallesteros-Espinoza, Victoria I., Miguel Rodríguez-Rosa, Ana B. Sánchez-García, and Purificación Vicente-Galindo. 2021. "Proposal of the Dichotomous STATIS DUAL Method: Software and Application for the Analysis of Dichotomous Data, Applied to the Test of Learning Styles in University Students" Mathematics 9, no. 21: 2797. https://doi.org/10.3390/math9212797