1. Introduction
If we consider the partition of random type algorithms for global optimisation between those that are adaptive, that is, those that have a search distribution, at a given step, to depend on the distributions of previous steps (see [
1,
2,
3] for comprehensive approaches and, for yet another example, [
4]) and those algorithms with steps being independent distributed search variables, it seems that only with those of the second class can we expect to escape the curse of being trapped in local extrema. This curse is surely related to the well known slogan
global optimisation requires global information first proposed by Stephens and Baritompa (see [
5] and illustrated in [
6]). One obvious way to counteract the pernicious effect of adaptivity of the algorithms is to include an intermediate
pure random search (PRS) step (see [
7]) that will overcame the proclivity of the algorithm to be trapped on a possible local extremum. However, this introduction comes with a price, namely the slowing down of the rate of convergence of the adaptive algorithm. As a countermeasure, we can consider the parallelisation of the algorithm at the pure random stage. Let us briefly state our main objectives in order to give some context to the remainder of this introduction. Our first objective in this work is to study the effect of parallelisation on the rate of convergence of a parallelizable stochastic algorithm for global optimisation with no constraints in the search for the maximum of a function. Our second objective is to study a random adaptive algorithm for global optimisation of functions that may be assumed to attain its extremums at the border of the bounded set where these functions are defined. Thorough and fundamental expositions on the general subject of random algorithms requiring familiarity with probability theory, as well as some knowledge of deterministic and stochastic differential equations and Markov chains, are found in [
8,
9]. A broad introduction to stochastic algorithms for global optimisation is found in [
10]. An excellent reference treaty on stochastic methods for global optimisation is found in [
11]; the authors lay a solid ground for further studies, for instance, in detailing extreme value theory and its applications to statistical inference in some stochastic optimisation algorithms. The quest for better performing algorithms for stochastic optimisation continues to develop newer approaches aiming at more general applicability, provable convergence, and stability in regard to small changes in the parameters. An interesting example of such a work is [
12], where the objective functions are supposed to be weakly convex, having as a particular case compositions of convex losses with smooth functions seen in machine learning algorithms. Another example may be found in the recent work [
13]; the algorithm proposed is akin to the
zig-zag algorithm first introduced in [
14]—further studied in [
15] and with its convergence also studied in [
6]—and a thorough comparison of the performance of the introduced algorithm with other well known stochastic optimisation algorithms is detailed. Further results on the convergence of global stochastic optimisation algorithms using perturbed Liapunov function methods are presented in [
16]. Let us stress that the subject of
stochastic optimisation is broad, encompassing many different types of algorithms such as simulated annealing, genetic algorithms, and tabu search; a review of these different types is provided in [
17], detailing advantages and disadvantages and summarising the literature on optimal values of the inputs. There are many instances of the idea that the algorithm may, in itself, guide the search into more promising regions; for instance, in [
18], modifications of the pure random search algorithm are proposed following this idea—implemented using the regularity of the function to determine the more promising regions—and we quote,
...We think that if the objective function satisfies some conditions such as continuity, the Lipschitz condition or differentiability etc., the regions containing the minimal points are easy to be determined. If the algorithm generates many points in the regions of this kind, the probability of success will be large.Fruitful ideas to build global optimisation algorithms with stochastic differential equations were previously published in, for instance, [
19,
20,
21,
22,
23,
24,
25,
26]. For numerical methods in stochastic differential equations, a fundamental reference is [
27]. The splendid book [
19] provides a well-founded approach to the convergence of algorithms either using functional compactness arguments or weak convergence results; some of the algorithms studied are taken as perturbations of ideal deterministic algorithms by an additive noise, not necessarily Gaussian, satisfying regularity properties. The idea of defining the intensity of the additive noise, the volatility of the stochastic differential equation by an annealing rate decreasing to zero with increasing time, is proposed in [
21], and weak convergence is studied. In [
25], the convergence of the studied algorithm for global optimisation with constraints is established for general nonconvex, smooth functions; the stochastic differential equation underpinning the algorithm .has as a drift the symmetric of the gradient of the function—a well known approach for obtaining a solution to an unconstrained optimisation problem considering the ordinary differential equation—and for the volatility, the square root of a positive function denominated
annealing schedule with a parameter to be chosen according to the problem under analysis. This approach was already studied in [
20], where a detailed justification for the choice of the stochastic differential equation is given, alongside many interesting related results. In [
26], the authors use Euler discretisation of a stochastic differential equation with mean reversion, in which the volatility is suitably modified in order to reduce the Gaussian noise contribution as the number of iterations increase; the method is tested against 14 classical functions, and the results indicate that the random search guided by the trajectory of a discretised diffusion perform well. The fine study of stochastic algorithms based on stochastic differential equations can be read in [
28], where, using perturbed Liapunov function methods, stability results of the algorithms are established. Furthermore, in [
16], an algorithm of simulated annealing-type procedure is studied and the following recommendation is stated:
...whenever possible, one can and should use parallel processors....
In this work, we do not need much of a theoretical background on parallel computing, as we use a standard computation tool to take advantage of the processors being able to compute either with the specification of working independently or not. Some general references for the study of parallel algorithms are [
29,
30,
31]. Early efforts on the parallelisation of those stochastic algorithms that may be called by the
random search type can be read in [
32], where a particular structure of the algorithm is designed using several units capable of processing data independently, notwithstanding communication with the units during the computation. In [
29], a collective work, there is an excellent review of the main ideas of parallelisation techniques for global optimisation algorithms. More recently, in [
33], the authors propose a framework to estimate the parallel performance of a given algorithm by analysing the runtime behaviour of its sequential version; the goal is achieved by approximating the runtime distribution of the sequential process with statistical methods, and then the runtime behaviour of the parallel process can be predicted by a model based on order statistics. The method we develop in this work bears some resemblance with this general idea.
As we previously observed, some fundamental random search algorithms for global optimisation built using discretised stochastic differential equations have as volatilities—that is, variances—parametrised quantities derived from simulated annealing principles. Parallelisation of simulated annealing type algorithms were studied by several authors. A precursor work is [
34], where the simulated annealing algorithm is mapped onto a dynamically structured tree of processors; the algorithm presented achieves
speedups between
and
,
N being the number of processors. Another important work is a volume edited by Robert Azencott, from which [
35] is a paradigmatic chapter. In [
36], five parallel algorithms for global optimisation are studied; these algorithms are categorised by the amount of information exchanged among the different parallel runs with the
asynchronous approach, being such that no information is exchanged among parallel runs. The parallelisation we propose is asynchronous, and the parallel runs are independent. In [
37], there are three proposals of parallel algorithms for simulated annealing that fall in a similar categorisation for the the amount of information exchanged among the different parallel runs leading to independent, semi-independent, and co-operating searches. An important reference on the same vein is [
38], reporting on five conversions of simulated annealing algorithm from sequential-to-parallel forms on high-performance computers and their application to a set of standard function optimisation problems. In the algorithm proposal of [
39], a common feature of simulated annealing algorithms, that is, adaptive cooling based on variance, is abandoned; instead, the algorithm resamples the states across processors periodically, and the resampling interval is tuned according to the success rate for each specific number of processors.
We now present in greater detail the contents and main contributions of this work. The first one is to develop and study a novel formal description of parallelisation of random algorithms for global optimisation with no constraints, and the second one is to introduce and study a novel stochastic differential equation-based algorithm suited to functions attaining the extremum at some points of the border of the domain of definition, for instance, unbounded functions. On the first contribution, in Theorem 1, we detail a proof of the convergence of the
pure random search algorithm for measurable functions, using simple results of martingale theory in discrete time, with the main purpose of highlighting the perspective used in this work, to wit, a stochastic algorithm may be seen as a sequence of random variables. With this perspective, in Theorem 2, we show that two convergent pure random search algorithms associated with the same function converge to random variables with the same law. We define, in Definition 3, the rate of convergence of a random algorithm and, in Definition 4, the parallelisation of such an algorithm, following the MPI standard, which is designed for distributed memory with multiple kernels of computation. Theorem 3 is another of the main contributions of this work, since we prove an estimate showing the improvement of the rate of convergence of a parallelised algorithm measured with respect to the nonparallelised version of the algorithm. We show that the parallelisation of the pure random search algorithm behaves in conformity with the results of Theorem 3 with examples of standard test functions for global optimisation. For the second main contribution of this work, in
Section 4, we introduce a novel algorithm using stochastic differential equations based on a maximum principle, which is specially suited for unbounded functions; we consider an example that we treat both in the parallelised and nonparallelised versions of the algorithm, thus showing again the advantage of parallelising a random algorithm. The proposed algorithm is different from the algorithms proposed in the literature, in particular, in the works referred above in the paragraph on global optimisation algorithms with stochastic differential equations, and we intend to further explore the properties of this new algorithm in future work. Broadly stated, the main difference stems from the fact that the stochastic differential equation is built in order for the algorithm to be a martingale and for a maximum principle to be applied.
2. On the Parallelisation of Random Algorithms
The introduction of a pure random search step in an adaptive stochastic algorithm for global optimisation is an auxiliary device to avoid missing the global extremum. However, keeping in mind that adaptive algorithms are introduced to increase the convergence rates, the pure random search step is counterproductive, since it slows down the whole algorithm.
Thus, we propose parallelisation of the algorithm at the pure random search step level in order to improve the global rate of convergence of the algorithm. For completeness, we first describe a martingale approach to pure random search. Next, in
Section 2.2, we show that, with an appropriate definition of the rate of convergence, parallelisation of a stochastic algorithm improves the global rate of convergence.
2.1. Pure Random Search Revisited
A probabilistic description of the pure random search may be defined as follows.
Definition 1 (Pure random search for global optimisation). A pure random search algorithm for the global maximisation of a function f on a compact set K is a sequence of random variables, such that:
- (i)
The function , defined on K a compact set of , is measurable.
- (ii)
The sequence is a sequence of independent and identically distributed (IID) random variables with , that is, X is uniformly distributed in K. We recall that, with λ denoting the Lebesgue measure over we have—with the symbol ⌢ denotingwith probability law—that: - (iii)
The sequence is a sequence of random variables with values in K defined for almost all by and for :with the consequence that is a nondecreasing sequence for almost all .
Four our purposes, we recall an essential definition.
Definition 2 (The essential supremum of a function over a compact set)
. The essential supremum of the function f over K is given by: We next single out Hypothesis 1 with the purpose of focusing on the most interesting cases for our study. In Remark 1, we identify the extension of Theorem 1 to the excluded cases of this hypothesis.
Hypothesis 1. We will suppose that . This hypothesis implies that, for all , we have that f is of p-power integrable (see for instance ([40], p. 190)). We now present the convergence result for the random algorithm of pure random search for global optimisation.
Theorem 1 (On the convergence of the pure random search algorithm). Under Hypothesis 1, we have that, for the pure random search algorithm in Definition 1:
- 1.
The sequence is asubmartingalewith respect to its natural filtration , that is, with: .
- 2.
The sequence convergesalmost surelyto a random variable such that, with the essential supremum of f over K in Definition 2, that is, the random variable is astrongsolution of the global optimisation problem of f over K.
Proof. We first observe that the random variables of the sequence
are integrable. In fact as we have, by Formula (
2) and by the righthand side of Formula (
1), that:
and we may conclude by induction. Now, since the conditional expectations are well defined and the sequence
is a nondecreasing sequence for almost all
, we have that:
and so we have the first statement in Theorem 1. In order to prove that the submartingale
converges, we will take advantage of Hypothesis 1 to obtain an uniform bound on the terms in the furthest left-hand side of Formula (
5). Since we have that:
we have that, for every
, there exists
, such that
, and such that
almost everywhere on
K with respect to
. This implies the uniform bound:
As a consequence of the bound in Formula (
6), we have, by a standard result on martingale theory (see ([
41], p. 50)), that the submartingale
converges almost surely to a random variable that we denote by
. In order to prove that
is a strong solution of the maximisation problem for
f over
K—defined to be a solution such that Formula (
4) is satisfied—we consider, for an arbitrary
, the fixed set defined by:
and we proceed with the following sequence of observations. Without loss of generality, we may assume, as an Hypothesis 2, that
, since, by Hypothesis 1, if it is otherwise, we can always consider a translation of
f.
- (j)
For
we have that:
We first observe that, by the fact that
, and as a consequence of a standard
supremum argument, we have that
Now, since the sequence
is an IID sequence, by the converse of Borel–Cantelli lemma, as a consequence of Formula (
9),
, and so the announced result in Formula (
8) follows.
- (jj)
Almost surely, we will have
for some integer
, that is, more precisely,
Let us suppose the contrary, that is,
Consider, for
, the set,
which we know, by Formula (
8), to have full probability and select
according to the condition in Formula (
10). Now, by the definition of
in Formula (
11), there exists
, such that
, that is such that
. However, by the condition in Formula (
10), we have that
, and so, by the definition of the sequence
in Formula (
2), we should have that
and so
, that is,
, a statement that contradicts the condition in Formula (
10).
- (jjj)
We have the final conclusion of the second statement in the theorem, Formula (
4), that is:
Take
and
satisfying Observation
(jj), that is, a set of full probability and such that,
Now, since the sequence
is almost surely nondecreasing, for all
and the adequate
, we can write:
a condition that implies
. We have thus shown that
a condition that, by a standard argument, implies Formula (
4).
Being so, the proof of the theorem is now complete. □
Remark 1 (On the case of an infinite essential supremum)
. In order to extend Theorem 1 to the case , we may consider thata condition that, for any submartingale, is equivalent to , that is, the sequence is bounded in (see ([41], pp. 50–51)). Furthermore, by observing that, ifwe have for arbitrary that , and so we can consider, instead of , the set . We then show that with a similar proof, a condition that, in turn, implies that almost surely. We now state a remark and an important result on the laws of the solution of the global optimisation problem by means of pure random search that we will use in the sequel.
Remark 2 (On the laws of the variables of the algorithm). Consider the two sequences , and of IID random variables with , and let and be the corresponding pure random search algorithms according to Definition 1. Then, for all , we have that and have the same law. In fact, a simple proof by induction shows that, for every , the law of —and consequently, the law of —only depends on the law of .
Theorem 2 (On the unicity of the global optimisation solution of pure random search). Suppose that , the essential supremum of f over the compact K, is finite. Let and be two pure random search algorithms associated with and , two sequences of IID random variables with , as in Remark 2. Suppose that these random algorithms converge to and , respectively. Then, we have that , and so and have the same law.
Proof. We can consider the sequence defined for
by:
Now, we may observe the following. Firstly, we have that, almost surely for
,
as an immediate consequence of the definition in Formula (
12). Then, we have that, almost surely,
is a nondecreasing sequence, as it is defined as the pointwise maximum of two nondecreasing sequences. Lastly, since, for all
, we have that
and
have the same law (see Remark 2), and since, by Formula (
2), we have that:
then
is a pure random search algorithm for global optimisation of
f over
K that, by Theorem 1, converges almost surely to some random variable
. Since we have that, for almost all
, the sequences
and
are subsequences of
, we immediately have that
almost surely, as claimed. □
2.2. On the Rate of Convergence of a Parallelisation of a Random Algorithm
In this section, we use the Ky Fan distance to define the rate of convergence of a generic random algorithm, and we obtain natural bounds for the rate of convergence of a parallelisation of this random algorithm. The
pure random search developed in
Section 2.1 is a basic algorithm, to which the following results apply.
Consider a stochastic algorithm for global optimisation—for instance, on what follows, maximisation—of a measurable function
f on a regular domain
given by the sequence of random variables
. We will suppose that
converges, at least in probability, to some random variable
. We recall that
, the Ky Fan metric (see ([
42], p. 289)), is defined for two random variables
X and
Y to be:
and that this distance is the distance of the convergence in probability. Furthermore, we have that
.
We now introduce a quantitative notion for the rate of convergence of an algorithm.
Definition 3 (The rate of convergence of a random algorithm)
. Suppose that the random algorithm converges in probability to some random variable . The rate of convergence of the algorithm is given by the numerical sequence:that is, the rate of convergence of the algorithm is the rate of convergence to zero of the numerical sequence , with, by definition, . We now consider a definition of parallelisation of a random algorithm.
Definition 4 (Parallelisation of a random algorithm). Given a random algorithm for global optimisation of a measurable function f on a regular domain , converging in probability to some random variable , we say that this algorithm is parallelisable if, for every integer and for every , there exist r independent copies of the terms of the algorithm sequence and of the random variable —namely and for and every —such that the following two conditions are verified:
For all , we have that .
For all , the random variable is a solution of theweakoptimisation problem for f on D, that is, , with the essential supremum of f (see Definition 2).
Remark 3 (PRS as an example of a parallelizable algorithm)
. The pure random search of a measurable function f on a compact set K studied in Section 2.1 is parallelisable. In fact, given any two samples of , as in Remark 2 and Theorem 2, the correspondent terms of the two algorithms generated by the two samples are independent as a consequence of the fact that, as seen in Remark 2, the law of only depends on the law of the initial segment of the sample of used to define it. It thus follows firstly that the limit random variables are independent, because almost sure limits of term-by-term independent sequences are independent by an application of a standard reasoning using characteristic functions. Moreover, as by Theorem 2, both limits of the two algorithms are equal almost surely if one of these limits is a solution of the (strong) optimisation problem. We now state the result that compares the parallelisation of a random algorithm with the version of the algorithm without parallelisation. This result can be used to determine stopping criteria for parallelised random algorithms, as detailed in Remark 5.
Theorem 3 (On the rate of convergence of a parallelised random algorithm)
. Let be a parallelizable random algorithm for global optimisation of a measurable function f on a regular domain and let the limit in probability of the algorithm and solution of the global optimisation problem be the random variable. Let be an integer and let and , for , be the independent copies of the algorithm and of the solution of the optimisation problem according to Definition 4. We then have for all :and also, for all such that , Proof. For the proof, we will use Lemma 1, which is well known, but which we reproduce next for the reader’s convenience. Since we have, by definition, that:
we also have that, for every integer
,
Without loss of generality, we may assume that the sequence
is nondecreasing. Now, the algorithm being parallelisable, by Definition 4, we have the necessary conditions to apply the estimate in Formula
(a) of Lemma 1, and so we obtain
The bound in Formula (
14) now follows by taking the limit as
k goes to infinity, since
. The proof of Formula (
15) is a consequence of applying the estimate in Formula
(b) of Lemma 1 to obtain
and then by taking the limit as
k goes to infinity. □
For the reader’s convenience, we recall the following well known elementary result that was used in the proof of Theorem 3.
Lemma 1. Let be a sequence of non-negative, independent and identically distributed with a random variable Z. We then have, for all ϵ:
- (a)
- (b)
Proof. We have that
and so it follows, by the independence and the identical distributions of
, that:
The proof of the second assertion is similar by observing that
which is equivalent to the second stated formula. □
Remark 4 (On the rate of convergence of a parallelised random algorithm)
. The rate of convergence of an algorithm , as in Definition 3, is the rate of convergence to zero of the sequence , with the terms of the sequence being as in Formula (16). In this formula, the infimum is attained (see again ([42], p. 289)), and so we have that:If this random algorithm is parallelisable, as in Theorem 3, we may consider that the gain in performance with this parallelisation is observed on the behaviour ofa behaviour that can be assessed in Formula (14), that is, As a consequence, we should compare this behaviour with the behaviour of the original algorithm in Formula (17). It is clear that, when , there is, for the parallelised algorithm, a remarkable improvement in the probability of a deviation from zero of the random variable in Formula (18) that measures the gain in performance with the parallelisation. Remark 5 (On the actual implementation of a parallelisation of a random algorithm). One way for an actual implementation of a random algorithm to take advantage of the improvement in the performance gained with the parallelisation, observed in Remark 4, is the following. Let for be the current maximum at step n for each one of the parallel runs of the algorithm. Let be such that is the smallest integer, such that at least one of the current maxima changes. Let for be the changed current maxima at step . Applying the stopping criteria to will accelerate the algorithm stopping.
3. Some Parallel Computations with the Pure Random Search Algorithm
This section is devoted to present a computational study aiming at exhibiting the effects of parallel computing with the pure random search algorithm. Intuitively, asynchronous parallelisation of an algorithm with the parallel runs running independently is tantamount to performing the evaluations of the algorithm in several different machines, not necessarily simultaneously; with this perspective, it seems equivalent to perform four thousand search steps in a single machine or one thousand search steps in each one of four similar distinct machines and then collect the results. It may be observed that, in order to consider the possible performance improvements with the parallelisation of an algorithm, we have to account for the execution times. Moreover, there is evidence of an upper limit for the gain obtained by the parallelisation of an algorithm, namely Amdhal’s Law (see ([
43], p. 65)) or the latter refined Gustafson’s Law (see [
44]). In Remark 5, we suggested a procedure to take into account the execution time of the best performing copy of the parallelised algorithm in order to stop the algorithm. In the following, we will not stop the algorithm whenever there is a copy of the algorithm satisfying the stopping criteria. Instead, we will stop the parallelised algorithm only when all the copies satisfy the stopping criteria and take the result of the copy—both in the variables time of execution and value attained—having the value attained when stopped that is closest to the maximum. This approach also allows us to study the improvement in the time variable in a simple way.
From Formula (
14), in Theorem 3, we have a theoretical upper bound on a tail probability of the parallelised algorithm and the rate of convergence of the nonparallelised algorithm that depends on
r, the number of independent copies of the algorithm in the parallelisation. In the study presented in the following, we intend to illustrate a determined quantitative improvement with the parallelisation of the pure random search algorithm.
The proposed method for the study is described in the following steps.
- 1.
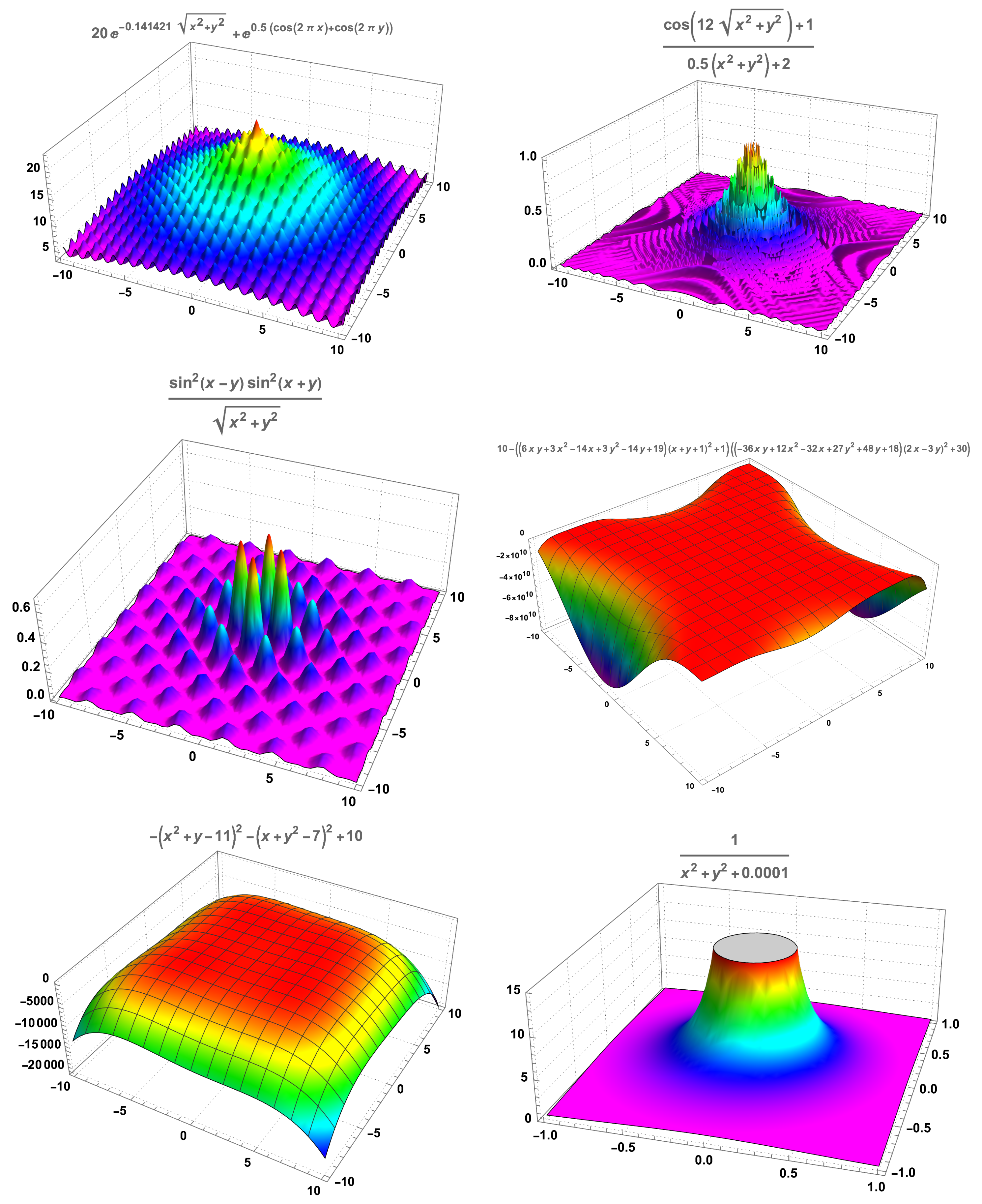
For each of the functions of two real variables studied (see
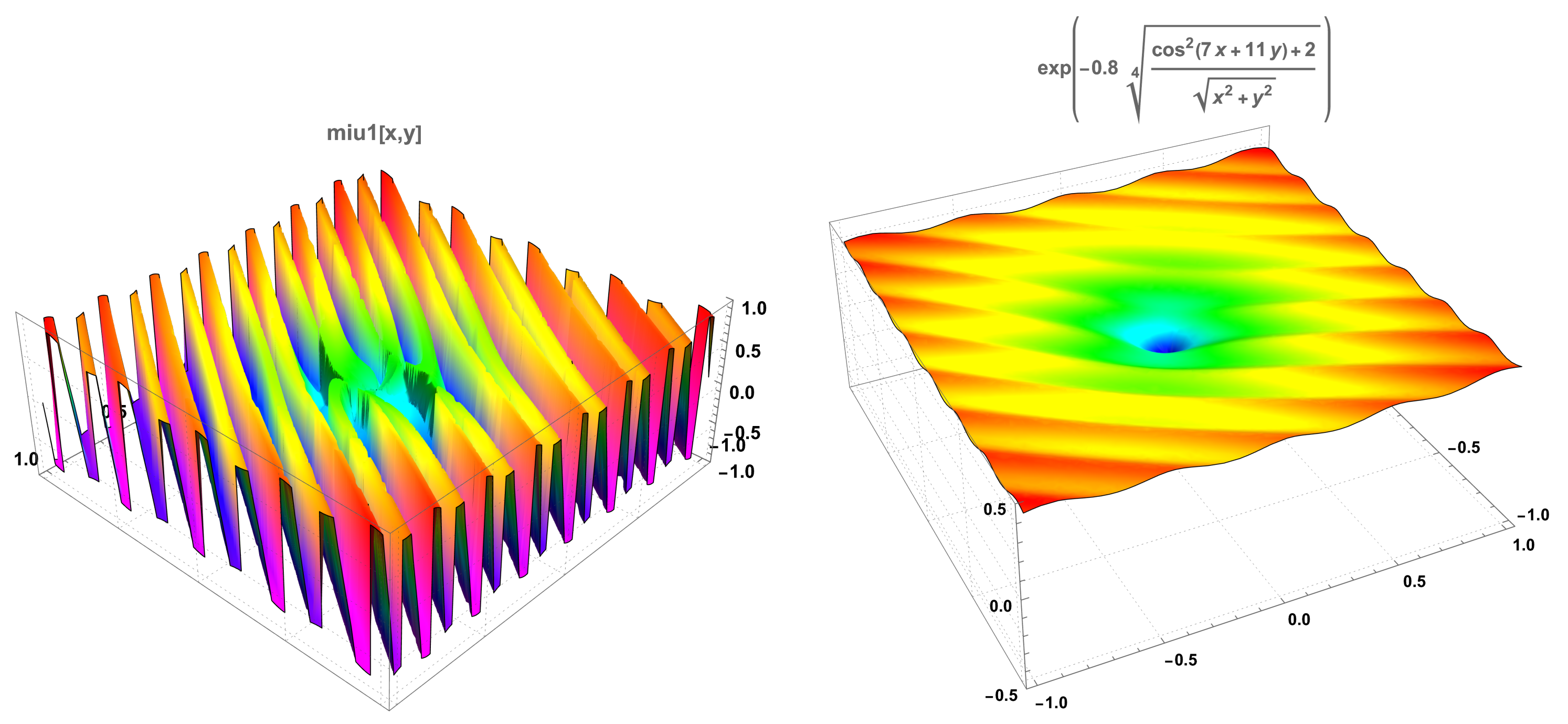
Appendix A for additional information on these functions)—Ackley’s, drop-wave, Keane’s, Goldstein-Price’s, Himmelblau’s, and a
nearly unbounded function—we determined, by Monte Carlo simulation, two lists of pairs of numbers,
UU and
VV. The list
VV has 400 pairs of numbers, the first number of the pair being the time in seconds that the nonparallelised PRS algorithm overcomes
of the known maximum of the function, at which point the simulation stopped, and the second number being the value attained at the moment the algorithm stopped. The list
UU is similar to the list
VV, but it contains the pair corresponding to the best performing kernel—among the four kernels of the machine used in the parallelised algorithm—regarding the value attained. In
Appendix B, we detail the machine characteristics as well as the main code used in the computations both of the parallelised and the simple algorithms.
- 2.
We fitted a continuous bivariate distribution to both samples
UU and
VV, truncated to exact intervals of both time, the first marginal variate, and value, the second marginal variate. Then, using the probability density functions (PDF) of the marginals, denoted
and
for the first marginal and
and
for the second marginal of each of the two samples
UU and
VV, we determined two values of reference one
the
time reference and the other
the
value reference, such that:
We observe that, in some cases, and were not unique solutions of the equations in the variable v and in the variable t; whenever this situation occurred, we chose the solutions closest to the medians of the two distributions. Furthermore, in at least one of the cases, there was no solution of the equations with the PDF, and we used a solution of a similar equation but with the cumulative distribution functions.
- 3.
With the determined values of
and
, we can immediately compute the conditional probabilities given by
for the parallelised algorithm,
V being the value variable and
T the time marginal variable, and similarly,
for the nonparallelised algorithm. By analogy with Formula (
14) in Theorem 3 and due to the choice of
and
, we would expect to have:
where
r is the number of copies in the parallelised algorithm. As a consequence, with:
we expect to have
in the examples given.
In
Table 1, we present the results of the computations just described, with
kernels, using the machine and code both presented in
Appendix B. A first observation is that the result for the nearly unbounded function is the best among all functions tested. This kind of function will be the object of the results presented in
Section 4. A second observation is that the median time values come from samples of repetitions of the algorithm both in the parallelised and nonparallelised versions; in the parallelised version, there are four times more repetitions than in the nonparallelised version, and being so, it is possible for the median times obtained with parallel algorithms to be sometimes worse than with the nonparallelised version.
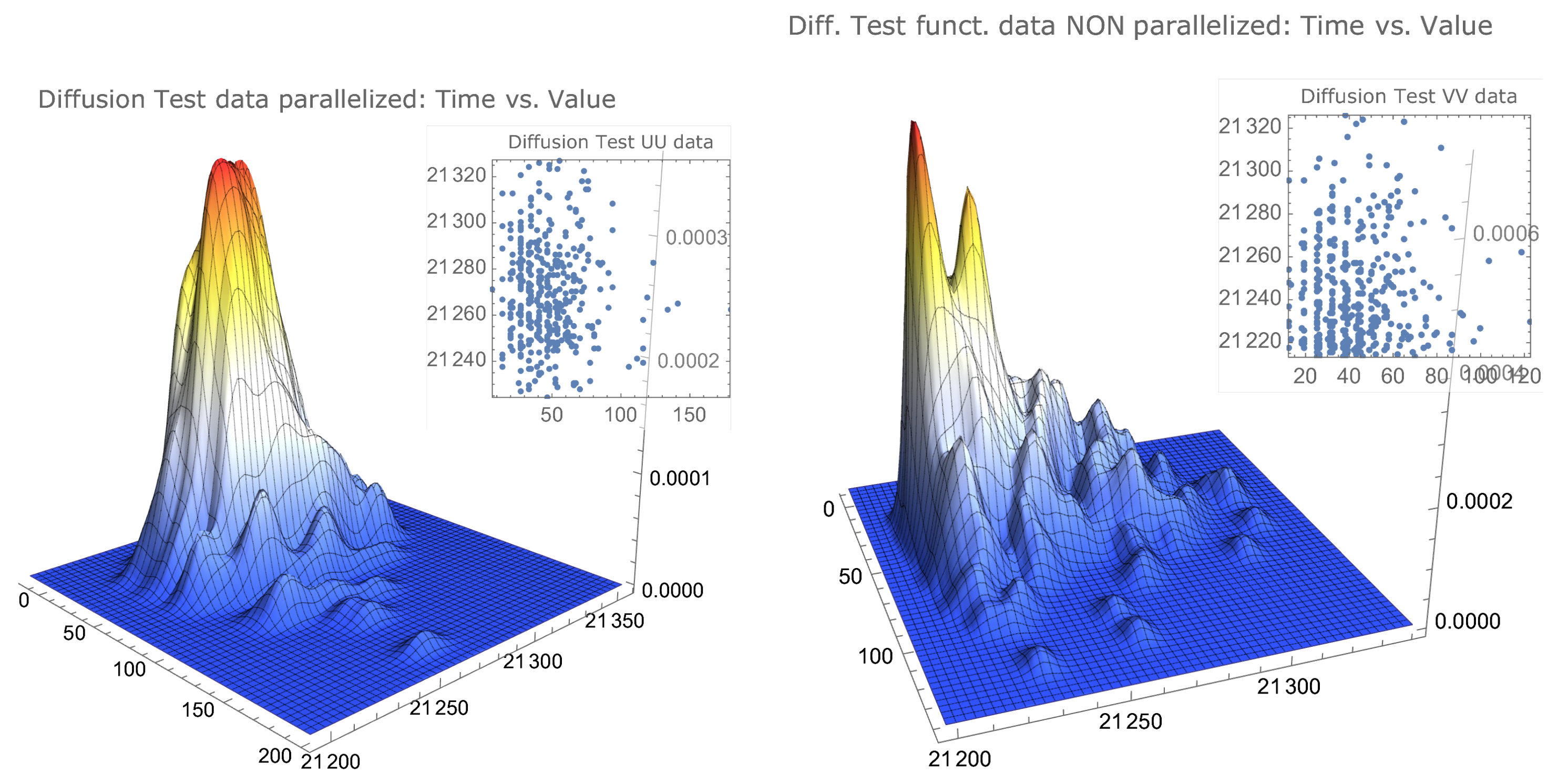
Remark 6 (Quantitative experimental validation of the advantage of a parallelisation of a pure random search)
. The results presented in Table 1 seem to substantiate the claim presented in Theorem 3, in Formula (14). In fact, it seems clear that, both for the examples of slightly modified well known test functions having several local maximums—Ackley’s, drop-wave, and Keane’s—and the functions attaining their maximums on a plateau-like surface—Goldstein–Price’s and Himmelblau’s—we obtain estimates of , given by , that can be considered acceptable, taking into account that, in the parallelised algorithm, efficiency losses occur in the distribution of tasks among kernels. Remark 7 (Simulated data representations for examples of two types of functions)
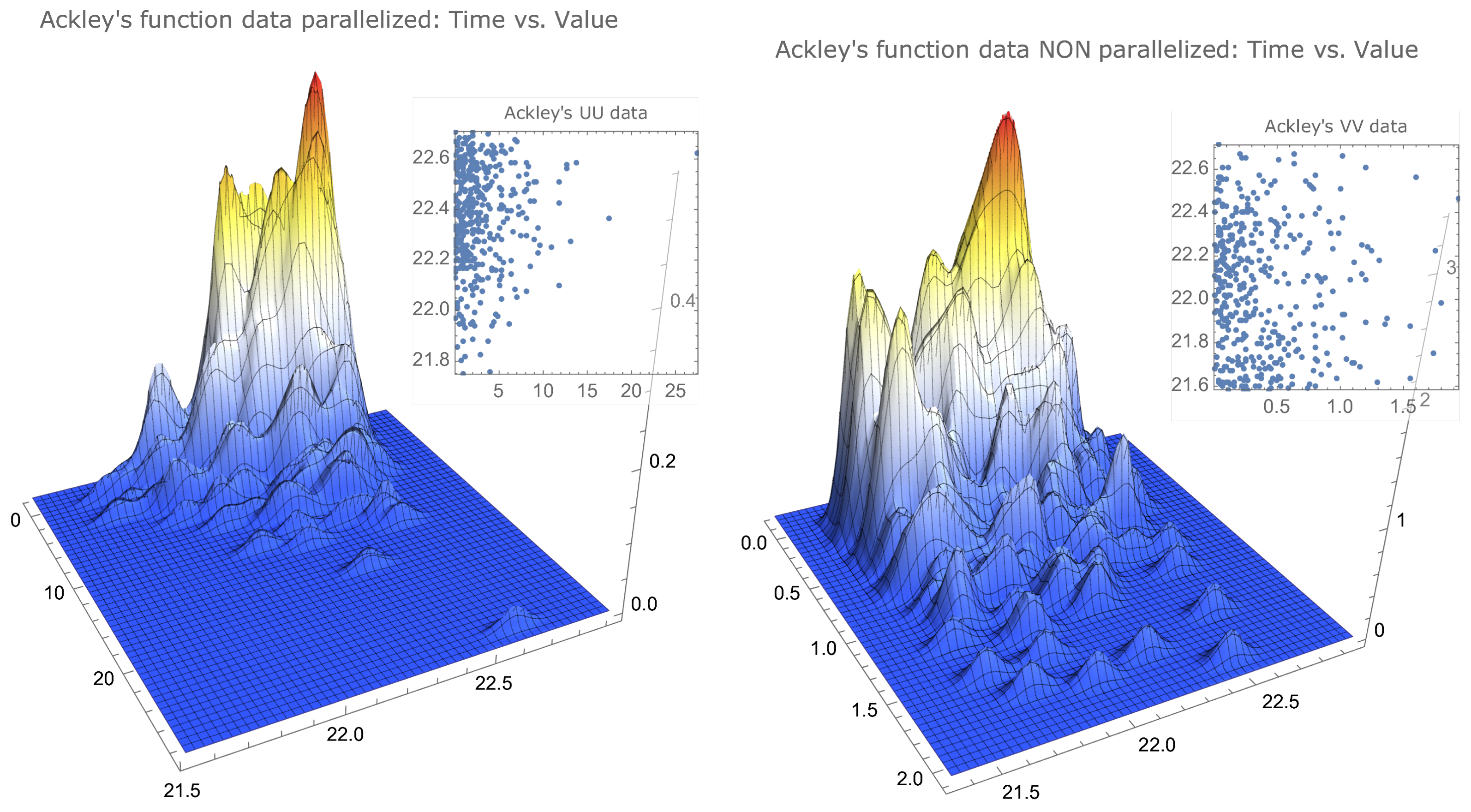
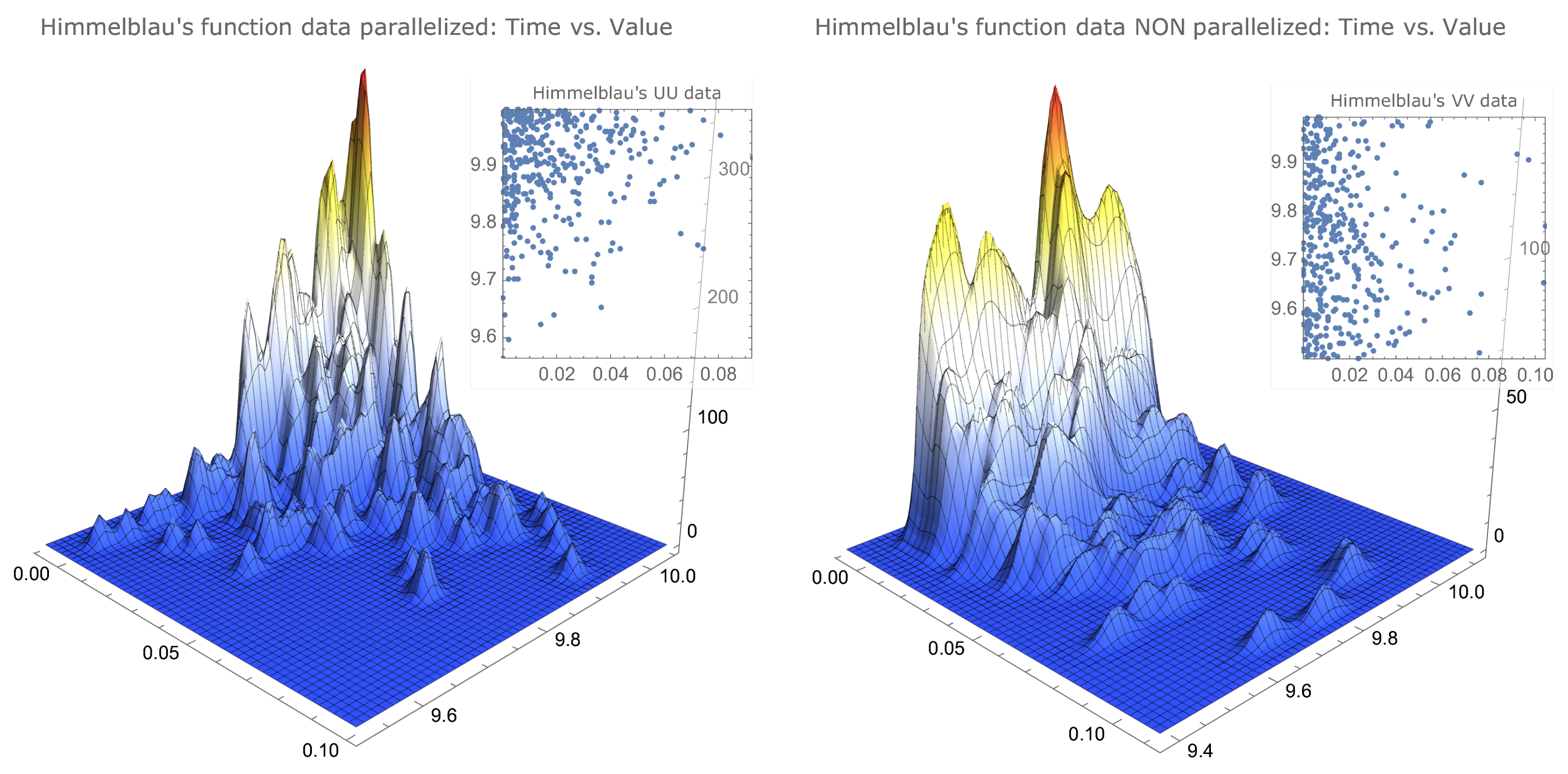
. The simulated data that allowed us to determine the values of Table 1 can be visualised to provide a better insight of their characteristics. In Figure 1 and Figure 2, we compare the same data for functions that clearly differ in the maximum localisation characteristics. As already mentioned, the drop-wave function presents several local maxima, with some of these local maxima agglomerated together with the global maximum, and the Himmelblau’s function has its maximum—with four distinct maximisers—in a surface plateau.There is a noticeable similarity between the parallelised data of both functions, as well as between the nonparallelised data of both functions.
However, there is a noticeable difference, for each function, between the parallelised data and the nonparallelised data. The parallelised data for both functions show a concentration on the upper left corner—less accentuated for Ackley’s function—that is, surrounding the best values in a way that can be described as: closest to the true maximum and smallest times—more noticeable for Himmelblau’s function—while the nonparallelised data, for both functions, appear to be uniformly distributed in the interval , also being more scattered in the time variable.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










