
Android Malware Detection Using Machine Learning with Feature Selection Based on the Genetic Algorithm


Abstract
:1. Introduction
2. Android Malware Analysis
2.1. Structure of Android Application
- Manifest: This area contains basic information regarding the application and is located at the root of all APK files under the name AndroidManifest.xml, a binary XML file containing the declarations of important information regarding the application, such as the package name, component, application permissions, and device compatibility.
- Signatures: This is the area containing the signature of the application. The META-INF directory, where the application signature files are located, is found in this area.
- Assets: Assets are used to store static files used in an application and are implemented as an asset directory, which requires invoking the AssetManager class to access files in the area when real-operating applications are used.
- Compiled Resources: It contains pre-compiled resource information, which exists as a resources.arsc file. This file is responsible for matching the resource files and resource IDs to record them such that resources can be found, accessed, and used within an application.
- Native libraries: These make up the area for the libraries used in an application. Library files tailored to the CPU instruction set of the target device are located at the lib directory, primarily written in C/C++.
- Dalvik bytecode: This area contains JAVA’s byte code. Within the application, it is implemented in the classes.dex file, and contains source code content compiled into bytecodes that Dalvik virtual machines can compile. Each application contains one DEX file as a default, but there are applications with multiple DEX files [21].
- Resources: This is the collection of resources used in an application. The resources of the Android application are saved in the res directory.
2.2. Static and Dynamic Analysis
3. Machine Learning Techniques
3.1. Feature Selection
3.2. Genetic Algorithm
3.3. Machine Learning Algorithm
- Decision Tree: A decision tree is a machine learning technique that classifies or regresses the data by creating classification rules for the trees. A decision tree is guided by a training case in which information is represented by a tuple and the class label of the attribute values is written down. Owing to the vast space to be retrieved, a tree is typically guided by training data and empty trees and into greedy, top-down, and recursive processes. The tree is created using processes that best partition the training data as the root splitting attribute. The training data are then partitioned into disjoint subsets that satisfy the values of the splitting attribute [39]. Owing to the disadvantage of easily overfitting the trees, pruning may be applied while executing the algorithm, or some trees might be removed to form generalized results.
- Random Forest: A random forest is a classifier consisting of a collection of uncorrelated tree structure classifiers designed by L. Breiman [40]. Each tree has the characteristic of finding solutions while voting for the most generalized class for input values. A supervised learning algorithm trained using the bagging method builds multiple decision trees and merges them to obtain a more accurate and stable prediction [7].
- Decision Table: A decision table is a simple means of documenting different decisions or actions taken under different sets of conditions [41]. The decision table allows the creation of a classifier, which summarizes the dataset into a decision table that contains the same number of attributes as the original dataset [42] and applies the classification of new incoming data using the table.
- Naïve Bayes: Naïve Bayes is a classification model based on the conditional probability of a Bayes rule. The independent naïve Bayes model is based on estimating and comparing probabilities; the larger significant probability points out that the actual label is more likely to be the class label value of the larger probability [14]. As the algorithm assumes that the predictive attributes are conditionally independent given the class, and it posits that no hidden or latent attributes influence the prediction process [43], it is difficult to apply to data dependent on different classes through specific attributes.
- MLP: A multi-layer perceptron (MLP) uses omnidirectional artificial neural networks for learning [44]. The neural network structure is presented in three parts: the input layer, hidden layer, and output layer. The input layer obtains the data, the hidden layer is calculated through an activation function, and the output layer shows the results of classification/regression. Although the input/output layers of the model exist individually, the hidden layer can be stacked as multiple layers. It is also known that the deeper a model is, the more generalized it can be in comparison to a shallowly stacked model [45].
- SVM: A support vector machine (SVM), also known as a support vector network (SVN), is a learning model for binary classification that embodies the idea that input vectors map non-linearly to high-dimensional feature spaces. In this feature space, a linear decision surface is constructed to ensure the high generalization ability of the learning machine owing to the unique properties of the decision surface [46].
- Logistic Regression: Logic regression is a machine learning technique that explains how variables with two or more categories are associated with a set of continuous or categorical predictors through probability functions [47]. Unlike ordinary linear regression using straight lines for classification, logistic regression is suitable for binary classification, using a logistic function in the shape of when fitting the data.
- AdaBoost: AdaBoost is a boosting algorithm that combines multiple weak classifiers to create a robust classifier that increases the performance. Unlike previously proposed boosting algorithms, a weak classifier is characterized by errors returned by the weak classifier [48], which affects the focus of the weak classifier on the problematic examples of the training set [49], allowing it to better classify the attributes.
- K-NN: As the fundamental principle of a K-nearest neighbor (K-NN), if most of the samples around the data on a point in a particular space belong to a specific category, the data on that point can be judged to fall into that category [50]. The K-NN algorithm operates by checking the label of the appropriate numbers of samples closest to the data being classified and subsequently labeling the data as the most aggregated of the samples.
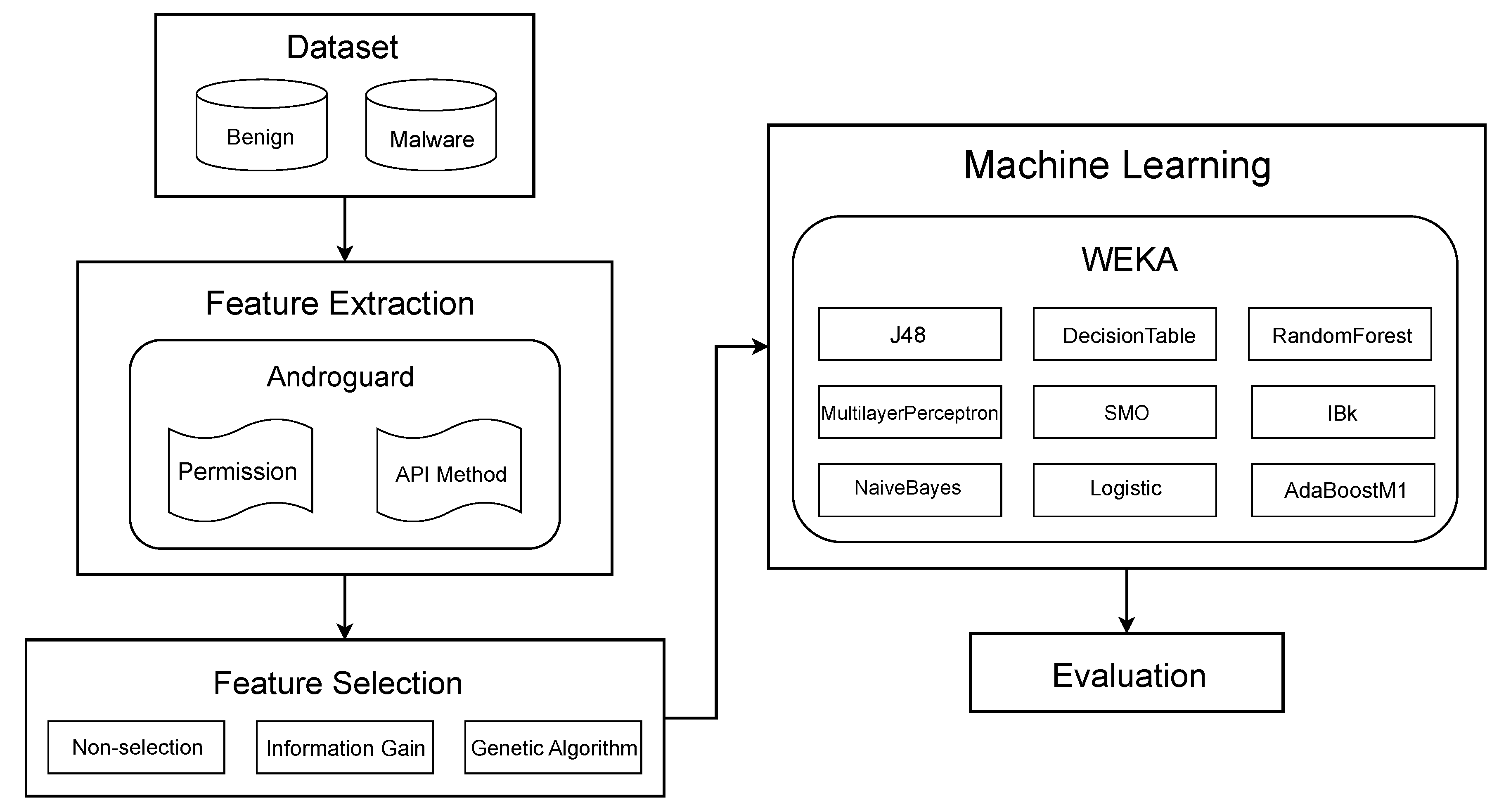
4. Experimental Methodology
4.1. Dataset Selection and Modification
4.2. Initial Feature Extraction
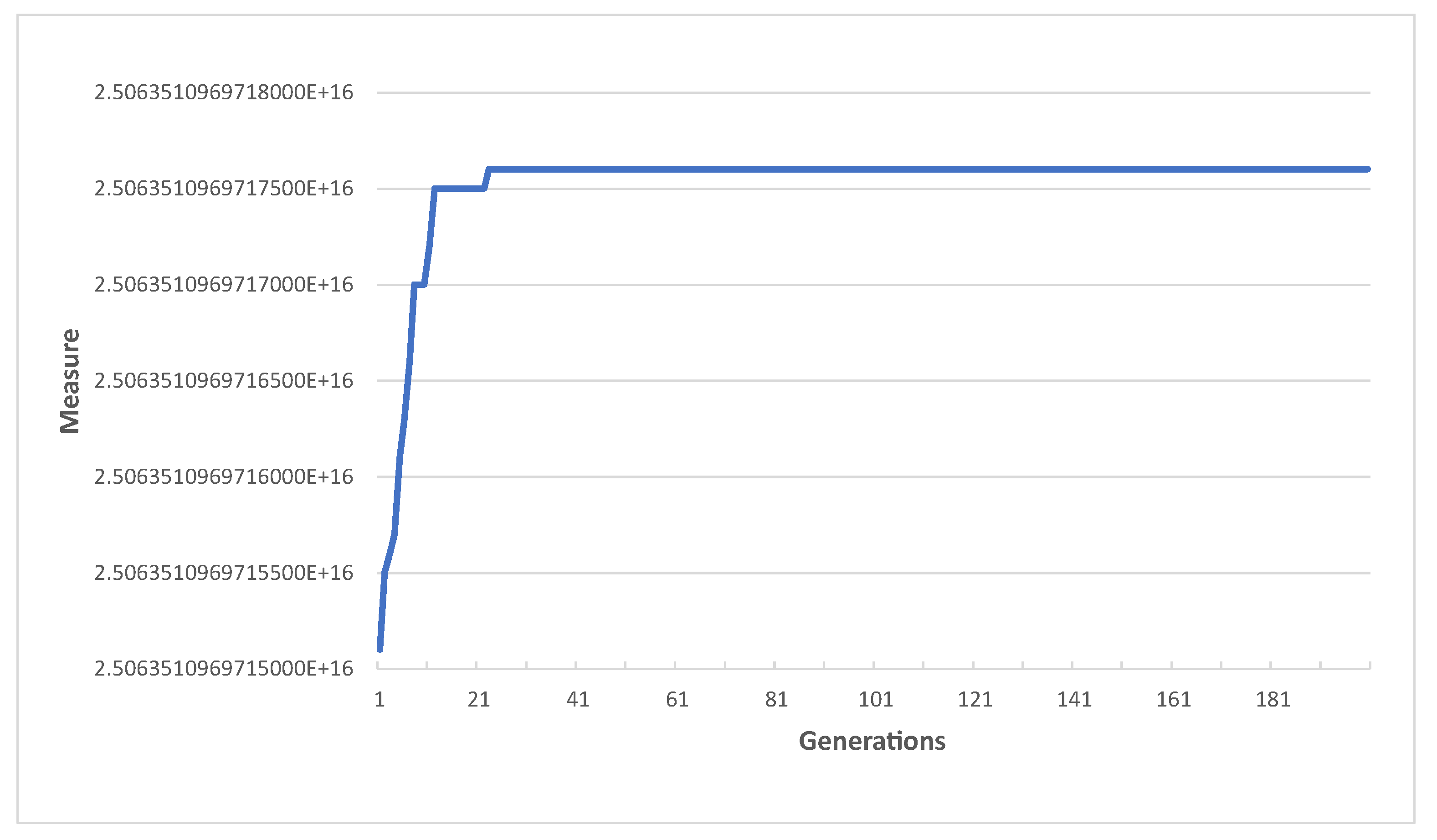
4.3. Feature Selection
| Algorithm 1: Pseudo-code of the genetic algorithm used in the experiment. |
 |
4.4. Machine Learning
4.5. Measurement Metrics
- Accuracy describes how accurate the overall prediction is.
- Precision describes how much is actual true among the predicted true.
- Recall describes how much is predicted true among the actual true.
- F1 Score reflects both precision and recall.
4.6. Statistical Analysis
5. Experimental Results
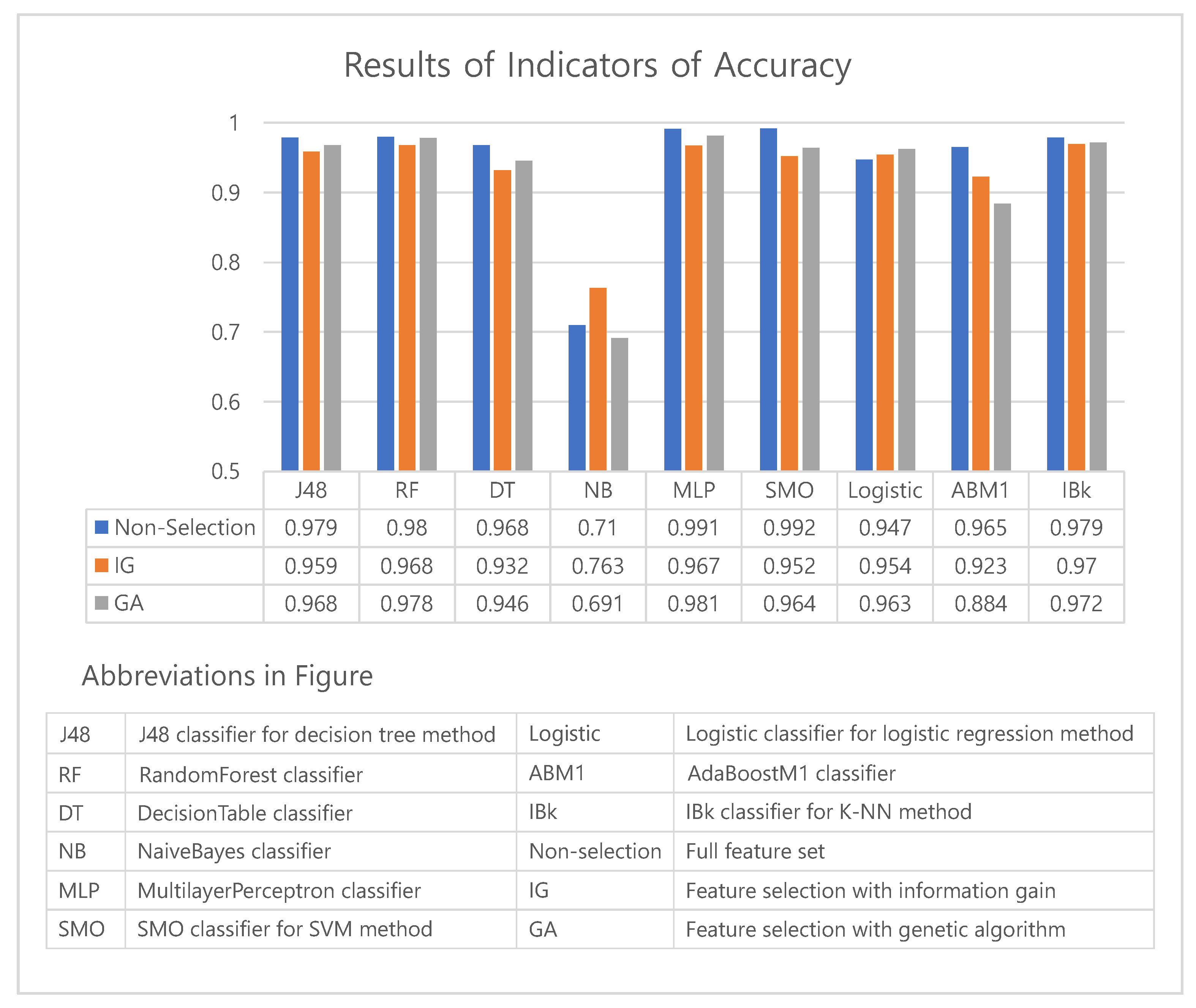
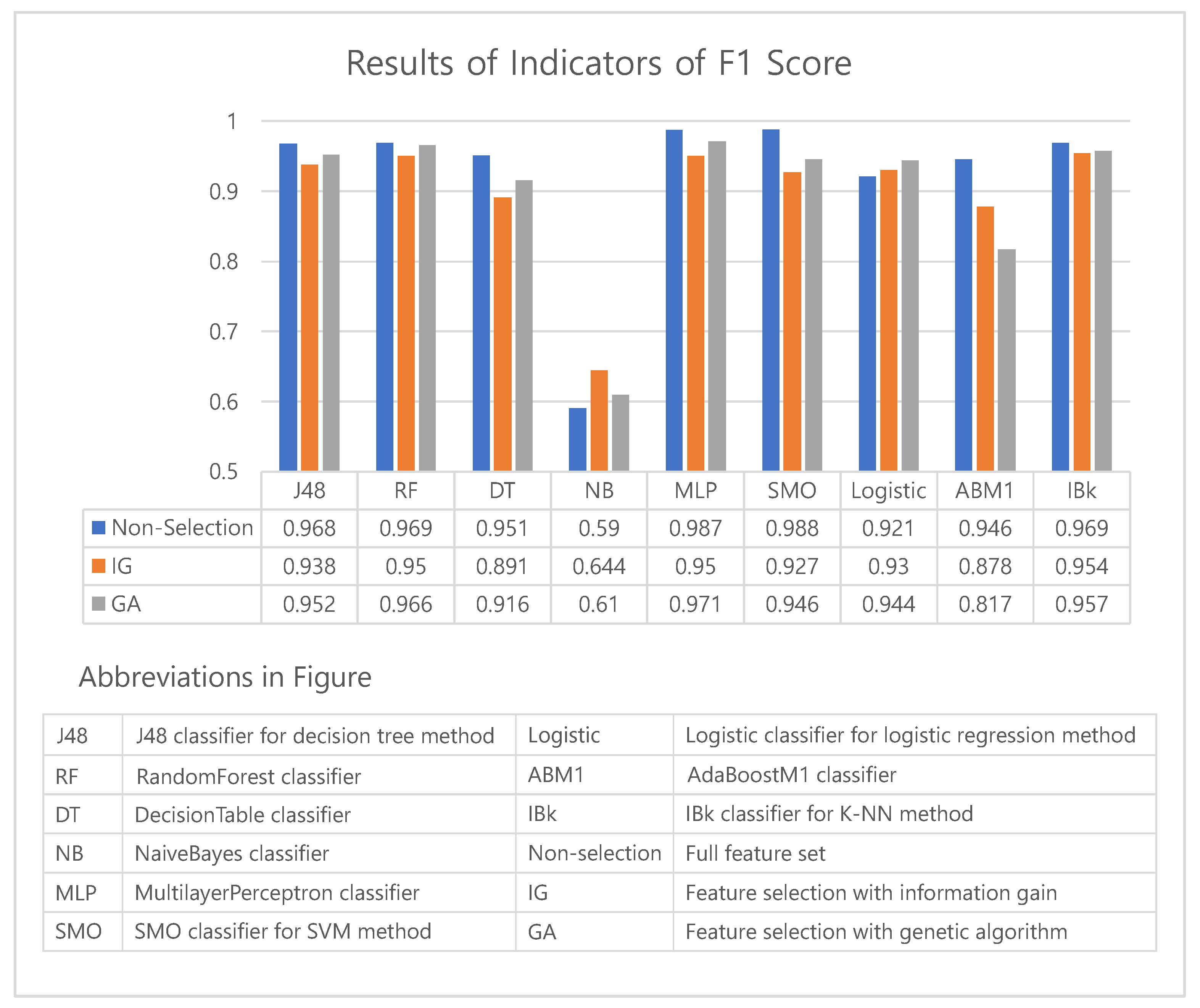
5.1. Accuracy/F1 Score Performance by Algorithm
5.2. Time Cost for Model Building
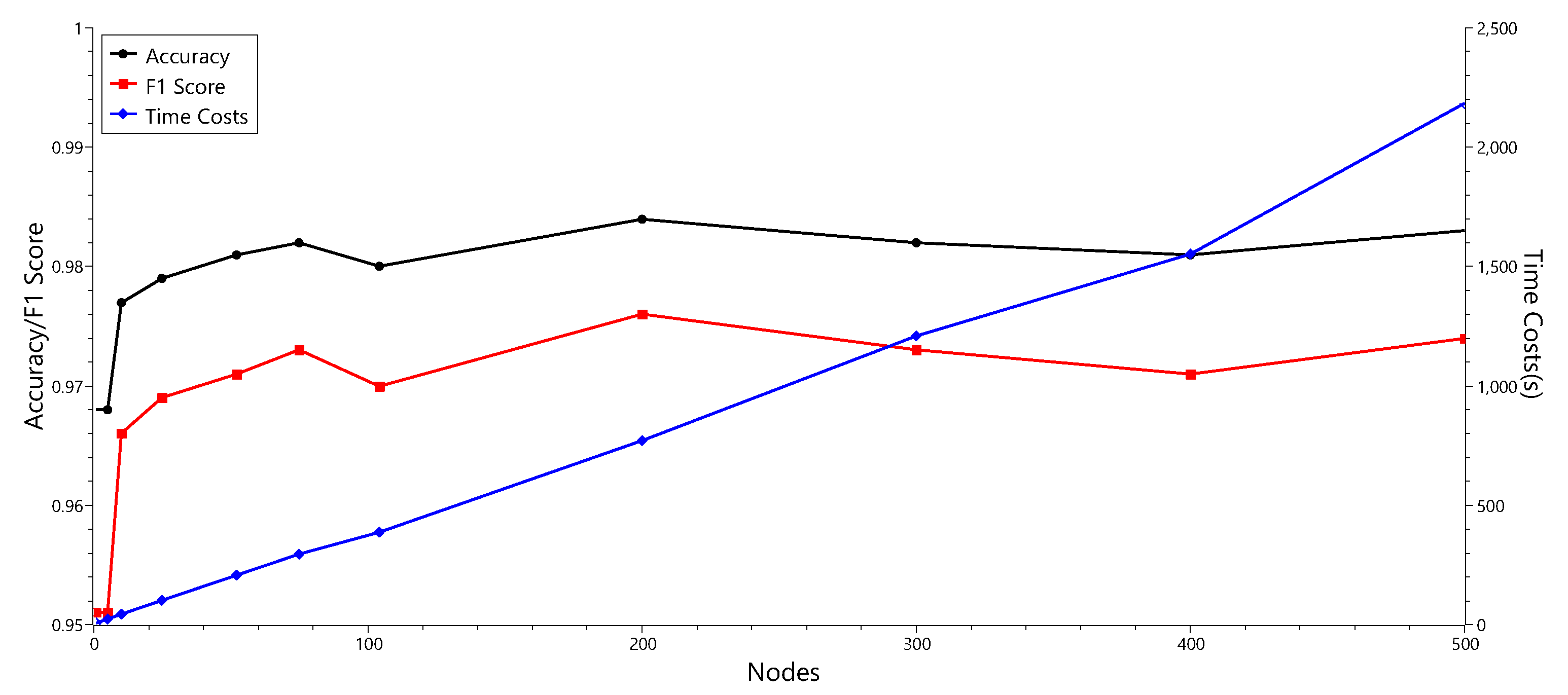
5.3. Hyperpatameter Optimization
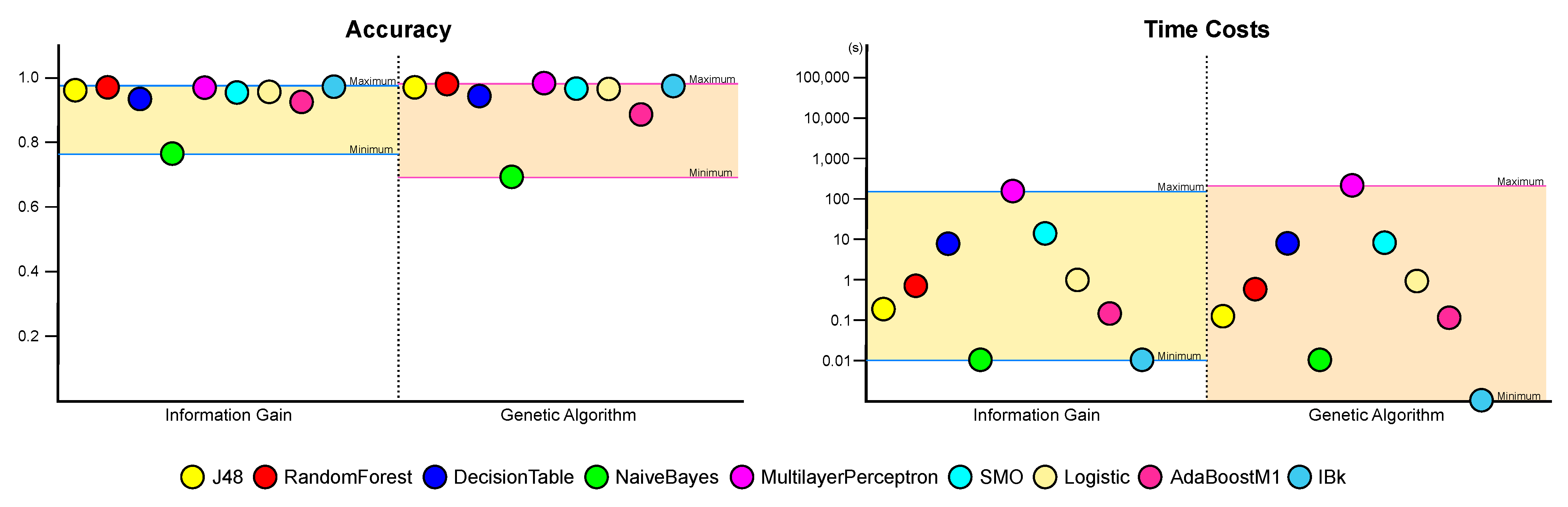
5.4. Total Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Topgül, O.; Tatlı, E. The Past and Future of Mobile Malwares. In The 7th International Conference on Information Security and Cryptology; Springer: Berlin, German, 2014; pp. 1–7. [Google Scholar]
- Chebyshev, V. Mobile Malware Evolution 2020. 1 March 2021. Available online: https://securelist.com/mobile-malware-evolution-2020/101029/ (accessed on 7 May 2021).
- StatCounter. Mobile Operating System Market Share Worldwide. May 2021. Available online: https://gs.statcounter.com/os-market-share/mobile/worldwide (accessed on 10 June 2021).
- Sawle, P.D.; Gadicha, A. Analysis of malware detection techniques in android. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 176–182. [Google Scholar]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Chi, Y. Review of android malware detection based on deep learning. IEEE Access 2020, 8, 181102–181126. [Google Scholar] [CrossRef]
- Rana, M.S.; Gudla, C.; Sung, A.H. Evaluating machine learning models for Android malware detection: A comparison study. In Proceedings of the 2018 VII International Conference on Network, Communication and Computing, Taipei City, Taiwan, 14–16 December 2018; pp. 17–21. [Google Scholar]
- Ahmadi, M.; Sotgiu, A.; Giacinto, G. Intelliav: Toward the feasibility of building intelligent anti-malware on android devices. In Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Cham, Switzerland, 2017; pp. 137–154. [Google Scholar]
- Mahindru, A.; Sangal, A. MLDroid—Framework for Android malware detection using machine learning techniques. Neural Comput. Appl. 2021, 33, 5183–5240. [Google Scholar] [CrossRef]
- Şahin, D.Ö.; Kural, O.E.; Akleylek, S.; Kılıç, E. A novel Android malware detection system: Adaption of filter-based feature selection methods. J. Ambient. Intell. Humaniz. Comput. 2021, 15, 1–15. [Google Scholar]
- Lei, S. A Feature Selection Method Based on Information Gain and Genetic Algorithm. In Proceedings of the 2012 International Conference on Computer Science and Electronics Engineering, Hangzhou, China, 23–25 March 2012; Volume 2, pp. 355–358. [Google Scholar]
- Firdaus, A.; Anuar, N.B.; Karim, A.; Ab Razak, M.F. Discovering optimal features using static analysis and a genetic search based method for Android malware detection. Front. Inf. Technol. Electron. Eng. 2018, 19, 712–736. [Google Scholar]
- Fatima, A.; Maurya, R.; Dutta, M.K.; Burget, R.; Masek, J. Android malware detection using genetic algorithm based optimized feature selection and machine learning. In Proceedings of the 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; pp. 220–223. [Google Scholar]
- Yildiz, O.; Doğru, I.A. Permission-based android malware detection system using feature selection with genetic algorithm. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 245–262. [Google Scholar] [CrossRef]
- Meimandi, A.; Seyfari, Y.; Lotfi, S. Android malware detection using feature selection with hybrid genetic algorithm and simulated annealing. In Proceedings of the 2020 IEEE 5th Conference on Technology In Electrical and Computer Engineering (ETECH 2020) Information and Communication Technology (ICT), Tehran, Iran, 22 October 2020. [Google Scholar]
- Wang, J.; Jing, Q.; Gao, J.; Qiu, X. SEdroid: A robust Android malware detector using selective ensemble learning. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Wang, L.; Gao, Y.; Gao, S.; Yong, X. A New Feature Selection Method Based on a Self-Variant Genetic Algorithm Applied to Android Malware Detection. Symmetry 2021, 13, 1290. [Google Scholar]
- Ratazzi, E.P. Understanding and improving security of the Android operating system. Ph.D. Thesis, Syracuse University, Syracuse, NY, USA, 2016. [Google Scholar]
- Aswini, A.M.; Vinod, P. Droid permission miner: Mining prominent permissions for Android malware analysis. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014; pp. 81–86. [Google Scholar]
- Yen, Y.S.; Sun, H.M. An Android mutation malware detection based on deep learning using visualization of importance from codes. Microelectron. Reliab. 2019, 93, 109–114. [Google Scholar]
- Lim, K.; Kim, N.Y.; Jeong, Y.; Cho, S.j.; Han, S.; Park, M. Protecting Android Applications with Multiple DEX Files Against Static Reverse Engineering Attacks. Intell. Autom. Soft Comput. 2019, 25, 143–154. [Google Scholar]
- Bhatt, M.S.; Patel, H.; Kariya, S. A survey permission based mobile malware detection. Int. J. Comput. Technol. Appl. 2015, 6, 852–856. [Google Scholar]
- Emanuelsson, P.; Nilsson, U. A comparative study of industrial static analysis tools. Electron. Notes Theor. Comput. Sci. 2008, 217, 5–21. [Google Scholar] [CrossRef] [Green Version]
- Amro, B. Malware Detection Techniques for Mobile Devices. Int. J. Mob. Netw. Commun. Telemat. 2017, 7, 1–10. [Google Scholar] [CrossRef]
- Ball, T. The concept of dynamic analysis. In Software Engineering—ESEC/FSE’99; Springer: Berlin/Heidelberg, Germany, 1999; pp. 216–234. [Google Scholar]
- Wong, M.Y.; Lie, D. IntelliDroid: A Targeted Input Generator for the Dynamic Analysis of Android Malware. In Proceedings of the Annual Symposium on Network and Distributed System Security (NDSS), San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Hsu, H.H.; Hsieh, C.W.; Lu, M.D. Hybrid feature selection by combining filters and wrappers. Expert Syst. Appl. 2011, 38, 8144–8150. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.J.; Moon, H.J.; Kim, D.J.; Yoon, Y. Genetic algorithm-based feature selection for depression scale prediction. In Proceedings of the ACM GECCO Conference, Prague, Czech Republic, 13–17 July 2019; pp. 65–66. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Lambora, A.; Gupta, K.; Chopra, K. Genetic algorithm-A literature review. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 380–384. [Google Scholar]
- Panchal, G.; Panchal, D. Solving NP hard problems using genetic algorithm. Transportation 2015, 106, 6-2. [Google Scholar]
- Montazeri, M.; Montazeri, M.; Naji, H.R.; Faraahi, A. A novel memetic feature selection algorithm. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 28–30 May 2013; pp. 295–300. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Su, J.; Zhang, H. A fast decision tree learning algorithm. In Proceedings of the America Association for Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 6, pp. 500–505. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Witt, G. Writing Effective Business Rules; Morgan Kaufmannr: Burlington, MA, USA, 2012. [Google Scholar]
- Kalmegh, S.R. Comparative analysis of the weka classifiers rules conjunctive rule & decision table on indian news dataset by using different test mode. Int. J. Eng. Sci. Invent. (IJESI) 2018, 7, 1–9. [Google Scholar]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers. In Proceedings of the 11th Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18 August 1995; pp. 338–345. [Google Scholar]
- Abirami, S.; Chitra, P. Energy-efficient edge based real-time healthcare support system. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2020; Volume 117, pp. 339–368. [Google Scholar]
- Montúfar, G.; Pascanu, R.; Cho, K.; Bengio, Y. On the number of linear regions of deep neural networks. In Proceedings of the NIPS’14: Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8 December 2014; Volume 27. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Fatah, K.; Mahmood, F.R. Parameter Estimation for Binary Logistic Regression Using Different Iterative Methods. J. Zankoy Sulaimani Part A 2017, 19, 175–184. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar]
- Freund, Y.; Schapire, R. A Short Introduction to Boosting. J. Jpn. Soc. Artif. Intell. 1999, 14, 771–780. [Google Scholar]
- Kuang, Q.; Zhao, L. A Practical GPU Based KNN Algorithm. In Proceedings of the Second Symposium International Computer Science and Computational Technology(ISCSCT’09), Huangshan, China, 26 December 2009. [Google Scholar]
- Androguard. Available online: https://github.com/androguard/androguard (accessed on 8 May 2021).
- Eibe, F.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Jang, J.W.; Kang, H.; Woo, J.; Mohaisen, A.; Kim, H.K. Andro-AutoPsy: Anti-malware system based on similarity matching of malware and malware creator-centric information. Digit. Investig. 2015, 14, 17–35. [Google Scholar] [CrossRef]
- Syswerda, G. Uniform Crossover in Genetic Algorithms. In Proceedings of the 3rd International Conference on Genetic Algorithms, Fairfax, VA, USA, 4 June 1989. [Google Scholar]
- Kim, T.K. T test as a parametric statistic. Korean J. Anesthesiol. 2015, 68, 540. [Google Scholar] [CrossRef] [Green Version]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Analysis Method | Static Analysis | Dynamic Analysis |
|---|---|---|
| Target of analysis | Source code and program components | Logs, traffic obtained by program execution |
| Pros |
|
|
| Cons |
|
|
| Class | Training | Test |
|---|---|---|
| Benign | 4000 | 1000 |
| Malware | 2000 | 500 |
| Actual | Positive | Negative | |
|---|---|---|---|
| Predicted | |||
| Positive | True Positive | False Positive | |
| Negative | False Negative | True Negative | |
| Algorithm | Non-Selection | Information Gain | Genetic Algorithm | |||
|---|---|---|---|---|---|---|
| Acc. | F1 Score | Acc. | F1 Score | Acc. | F1 Score | |
| J48 | 0.979 | 0.968 | 0.959 | 0.938 | 0.968 | 0.952 |
| RandomForest | 0.98 | 0.969 | 0.968 | 0.95 | 0.978 | 0.966 |
| DecisionTable | 0.968 | 0.951 | 0.932 | 0.891 | 0.946 | 0.916 |
| NaiveBayes | 0.71 | 0.59 | 0.763 | 0.644 | 0.691 | 0.61 |
| MultilayerPerceptron | 0.991 | 0.987 | 0.967 | 0.95 | 0.981 | 0.971 |
| SMO | 0.992 | 0.988 | 0.952 | 0.927 | 0.964 | 0.946 |
| Logistic | 0.947 | 0.921 | 0.954 | 0.93 | 0.963 | 0.944 |
| AdaBoostM1 | 0.965 | 0.946 | 0.923 | 0.878 | 0.884 | 0.817 |
| IBk | 0.979 | 0.969 | 0.97 | 0.954 | 0.972 | 0.957 |
| Algorithm | Time Costs (s) | ||
|---|---|---|---|
| Non-Selection | Information Gain | Genetic Algorithm | |
| J48 | 3.92 | 0.18 | 0.12 |
| RandomForest | 3.32 | 0.68 | 0.56 |
| DecisionTable | 100.85 | 7.48 | 7.63 |
| NaiveBayes | 0.05 | 0.01 | 0.01 |
| MultilayerPerceptron | 31705.55 | 150.19 | 207.93 |
| SMO | 11.18 | 13.44 | 7.93 |
| Logistic | 13.56 | 0.95 | 0.89 |
| AdaBoostM1 | 2.74 | 0.14 | 0.11 |
| IBk | 0 | 0.01 | 0 |
| # Nodes | Accuracy | F1 Score | Time Costs (s) |
|---|---|---|---|
| 1 | 0.968 | 0.951 | 6.54 |
| 5 | 0.968 | 0.951 | 24.24 |
| 10 | 0.977 | 0.966 | 43.71 |
| 25 | 0.979 | 0.969 | 101 |
| 52 | 0.981 | 0.971 | 207.93 |
| 75 | 0.982 | 0.973 | 296.95 |
| 104 | 0.98 | 0.97 | 387.1 |
| 200 | 0.984 | 0.976 | 771.83 |
| 300 | 0.982 | 0.973 | 1208.84 |
| 400 | 0.981 | 0.971 | 1553.27 |
| 500 | 0.983 | 0.974 | 2182.71 |
| Location of New Layer | # Nodes | Accuracy | F1 Score | Time Costs (s) |
|---|---|---|---|---|
| Before existing layer | 1 | 0.968 | 0.951 | 17.88 |
| 25 | 0.984 | 0.976 | 154.59 | |
| 52 | 0.982 | 0.972 | 332.12 | |
| 104 | 0.982 | 0.972 | 602.83 | |
| After existing layer | 1 | 0.982 | 0.972 | 162.01 |
| 25 | 0.981 | 0.971 | 243.97 | |
| 52 | 0.982 | 0.972 | 332.12 | |
| 104 | 0.98 | 0.97 | 530.98 |
| Reference | Dataset | Set Size | Feature | Feature Selection Method | Classifier | Accuracy | F1 Score |
|---|---|---|---|---|---|---|---|
| [7] | Drebin | 5560 | assembly, API calls | none | Random Forest | 0.9433 | 0.94 |
| [10] | VirusShare, APKPure | 6000 | permission | RFFS+ Acc2+M2 | Random Forest | undetermined | 0.952 |
| [12] | Drebin, Play store | 6105 | permission, code-based, directory path | Genetic Selection | Functional Tree (FT) | 0.95 | 0.972 |
| [13] | undetermined | 40,000 | app component, permission | Genetic Algorithm | SVM | 0.95 | 0.95 |
| [14] | AMGP, Play store | 1740 | permission | Genetic Algorithm | SVM | 0.985 | 0.981 |
| The best result in this study | Andro-AutoPsy | 7500 | permission, API method | Genetic Algorithm | MultilayerPerceptron | 0.984 | 0.976 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Jang, H.; Ha, S.; Yoon, Y. Android Malware Detection Using Machine Learning with Feature Selection Based on the Genetic Algorithm. Mathematics 2021, 9, 2813. https://doi.org/10.3390/math9212813
Lee J, Jang H, Ha S, Yoon Y. Android Malware Detection Using Machine Learning with Feature Selection Based on the Genetic Algorithm. Mathematics. 2021; 9(21):2813. https://doi.org/10.3390/math9212813
Chicago/Turabian StyleLee, Jaehyeong, Hyuk Jang, Sungmin Ha, and Yourim Yoon. 2021. "Android Malware Detection Using Machine Learning with Feature Selection Based on the Genetic Algorithm" Mathematics 9, no. 21: 2813. https://doi.org/10.3390/math9212813