Efficient Space–Time Reduced Order Model for Linear Dynamical Systems in Python Using Less than 120 Lines of Code


Abstract
:1. Introduction
- We derive the block structures of least-squares Petrov–Galerkin (LSPG) space–time ROM operators for linear dynamical systems for the first time and compare them with the Galerkin space–time ROM operators.
- We present an error analysis for LSPG space–time ROMs for the first time and demonstrate the growth rate of the stability constant with the actual space–time operators used in our numerical results.
- We compare the performance between space–time Galerkin and space–time LSPG reduced order models on several linear dynamical systems.
- For each numerical problem, we cover the entire space–time ROM process in less than 120 lines of Python code, which includes sweeping a wide parameter space and generating data from the full order model, constructing the space–time ROM, and generating the ROM prediction in the online phase.
2. Linear Dynamical Systems
3. Space–Time Reduced Order Models
3.1. Linear Subspace Solution Representation
3.2. Galerkin Projection
3.3. Least-Squares Petrov–Galerkin (LSPG) Projection
3.4. Comparison of Galerkin and LSPG Projections
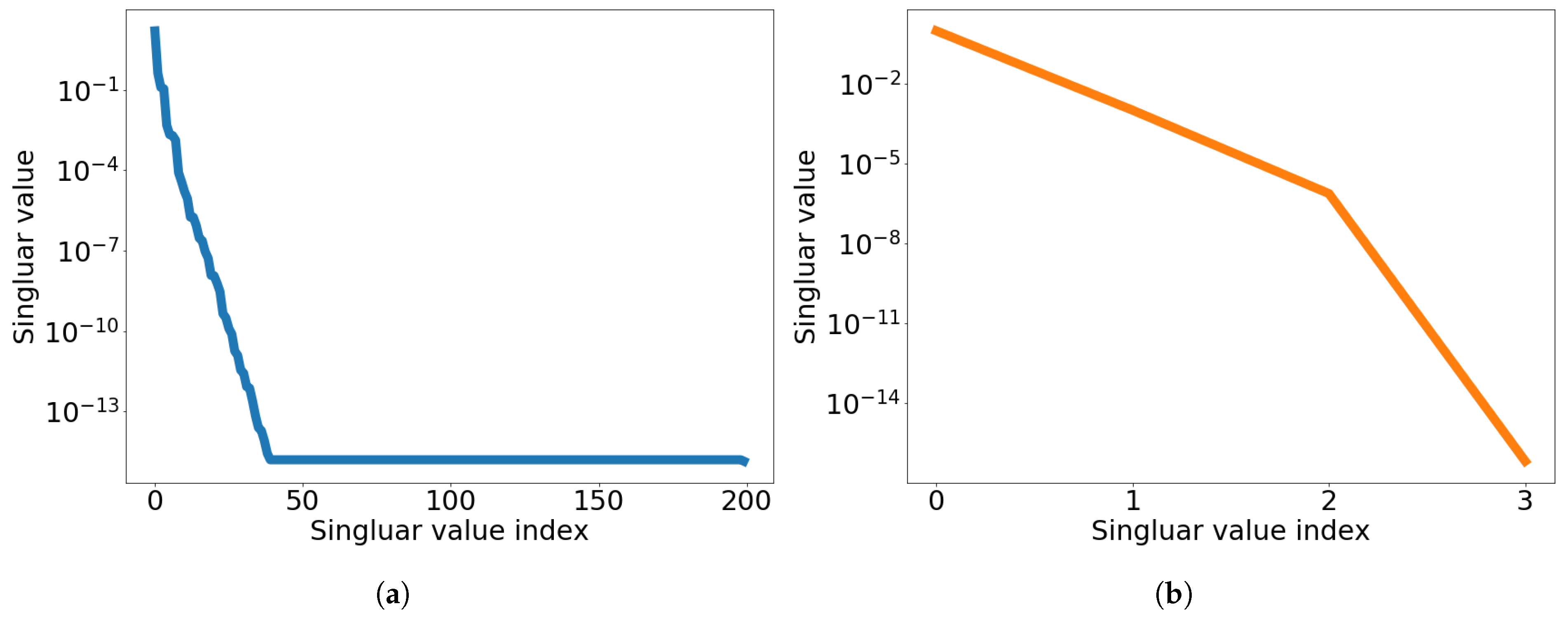
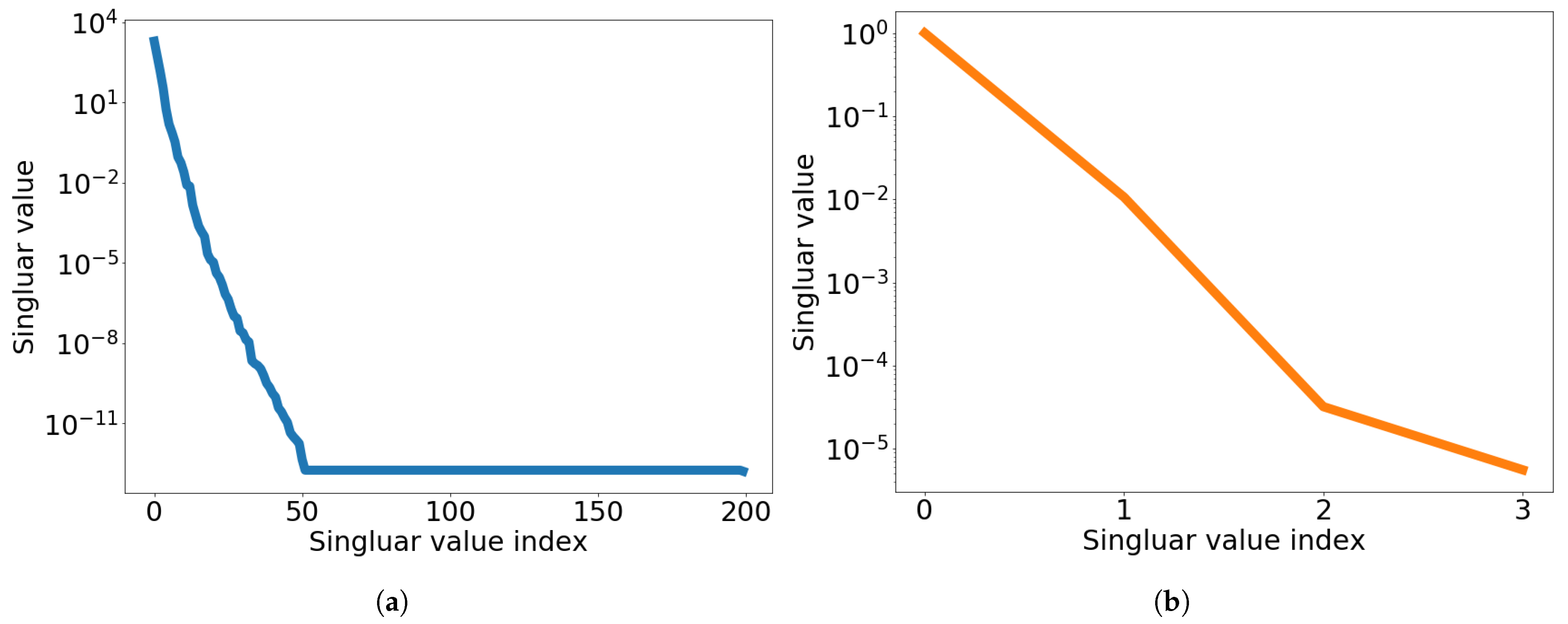
4. Space-Time Basis Generation
5. Space-Time Reduced Order Models in Block Structure
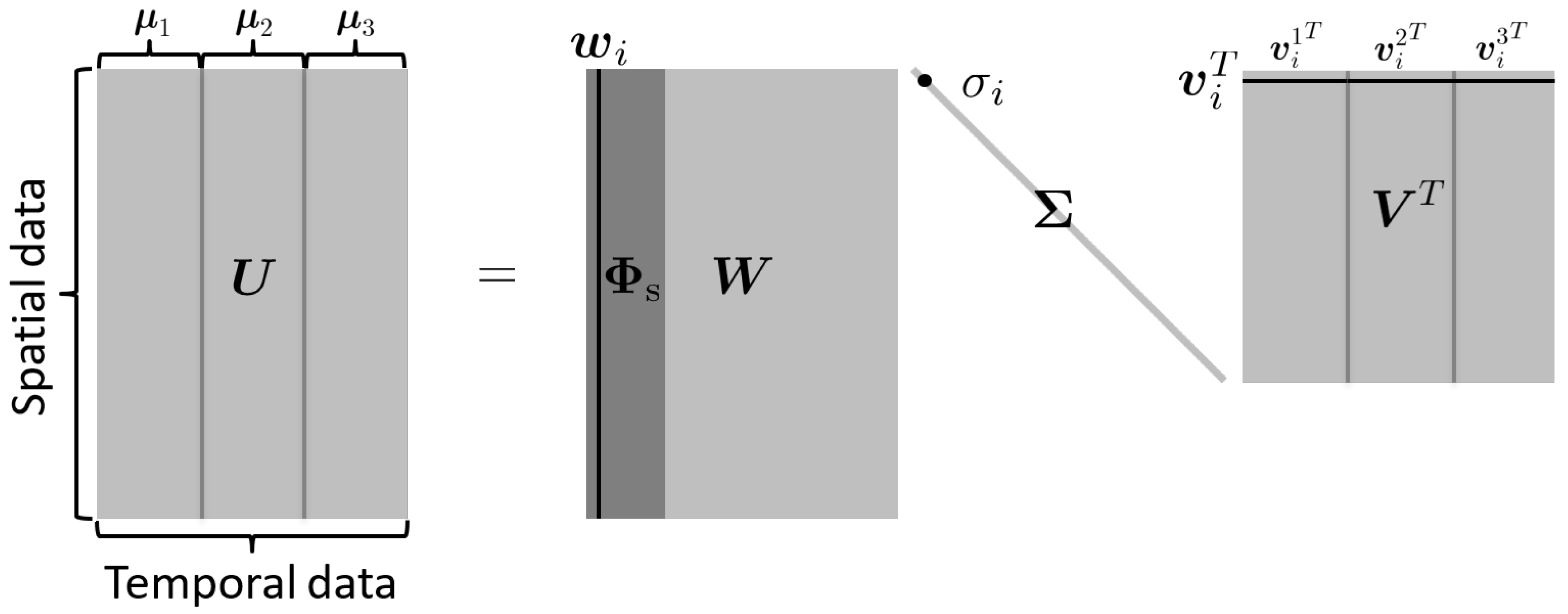
5.1. Block Structures of Space–Time Basis
5.2. Block Structures of Galerkin Projection
5.3. Block Structures of LSPG Projection
5.4. Comparison of Galerkin and LSPG Block Structures
5.5. Computational Complexity of Forming Space–Time ROM Operators
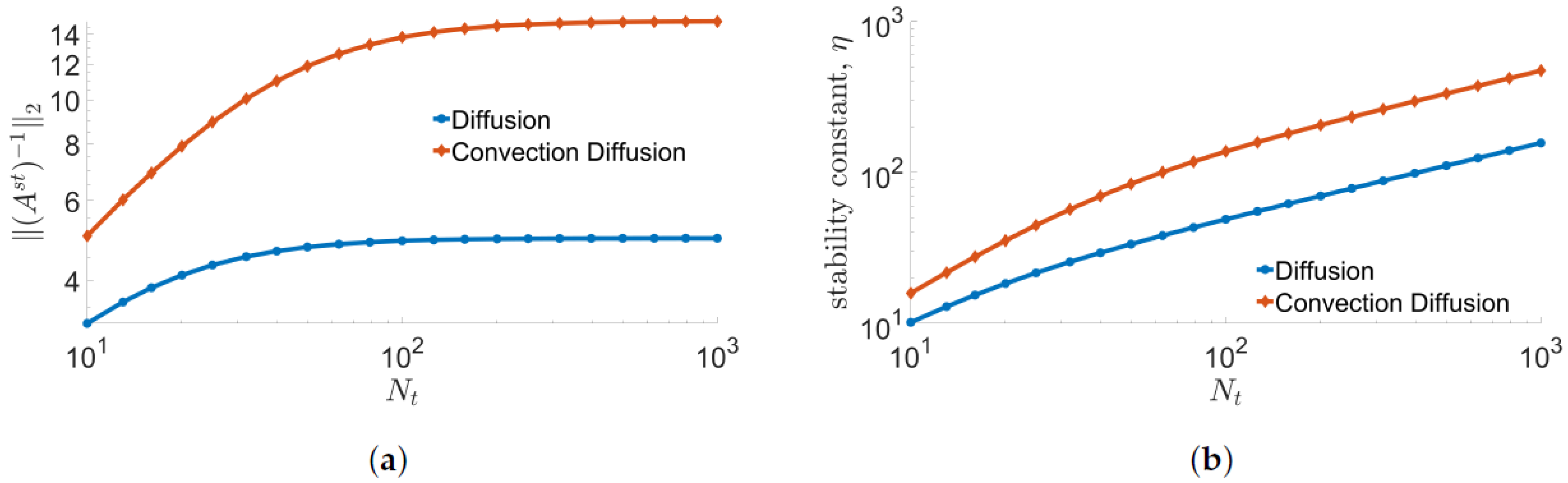
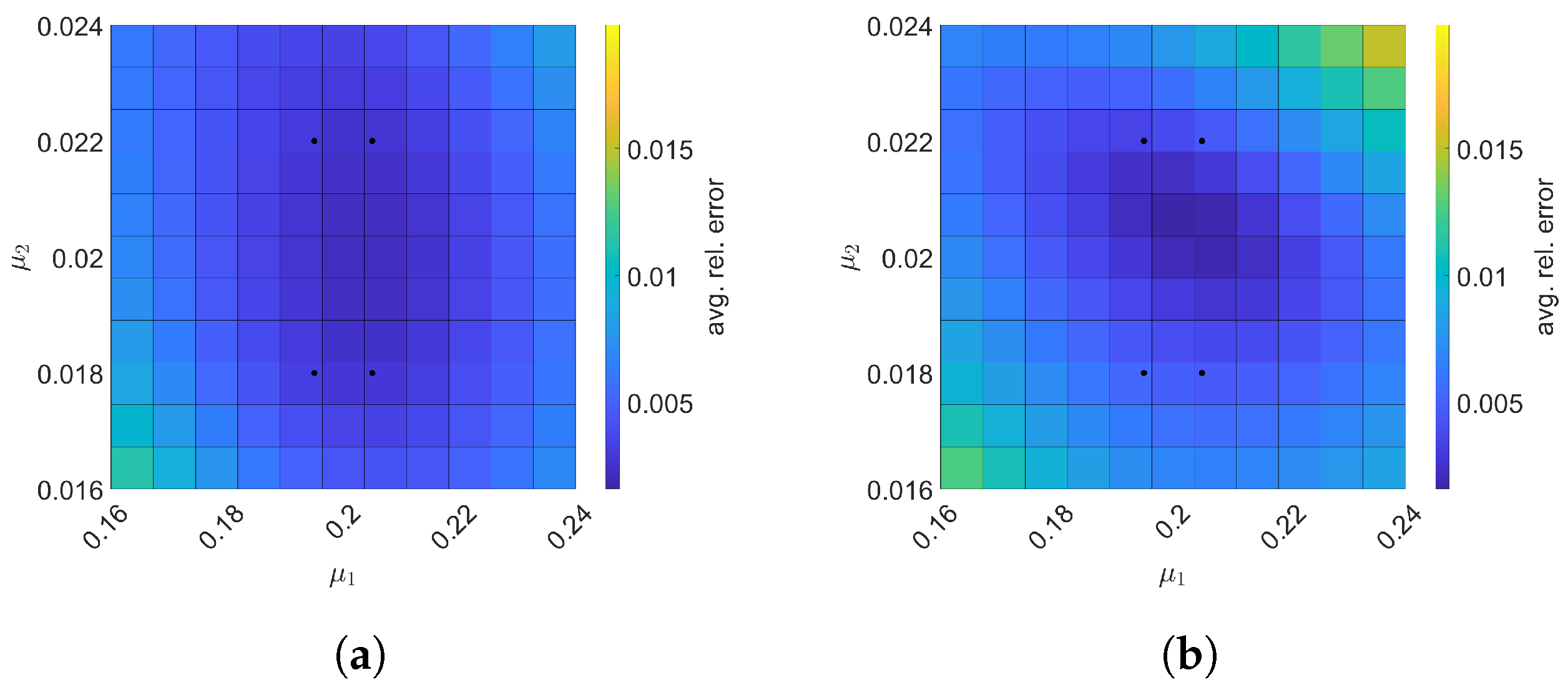
6. Error Analysis
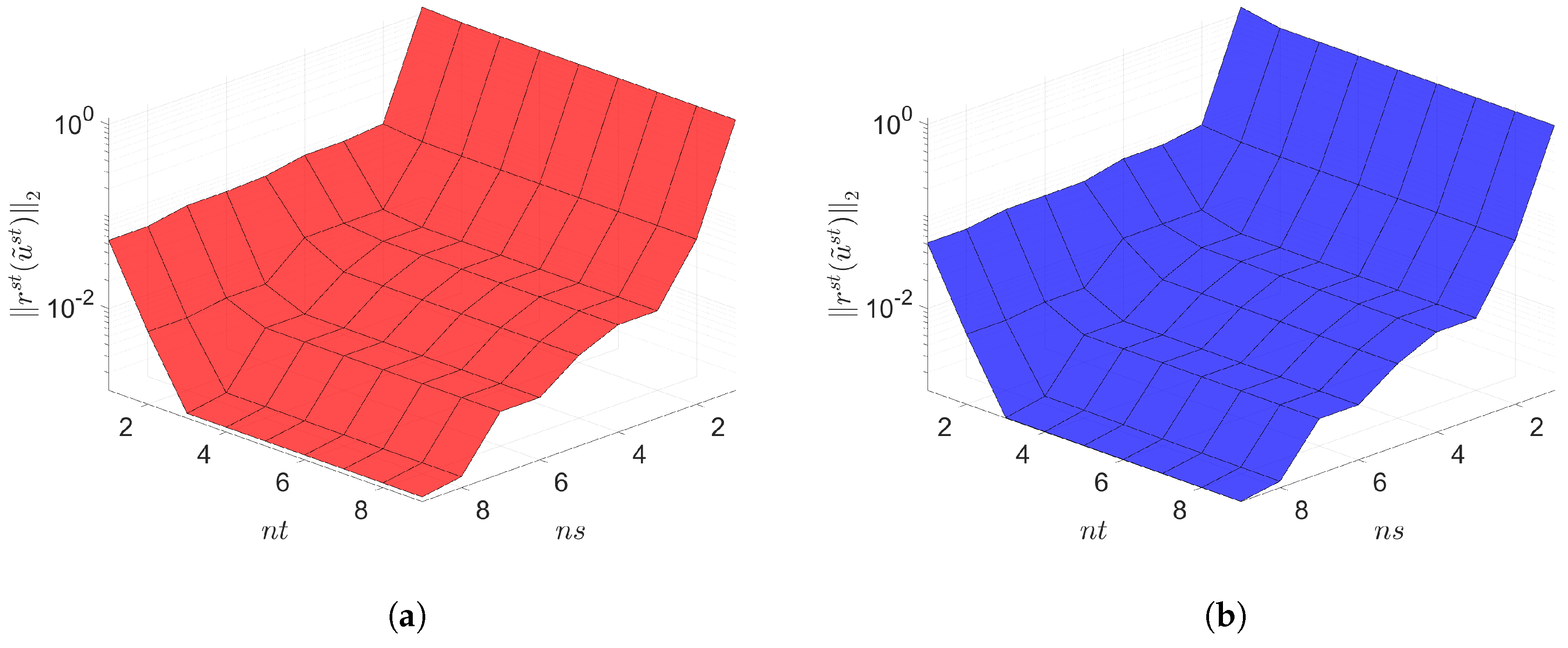
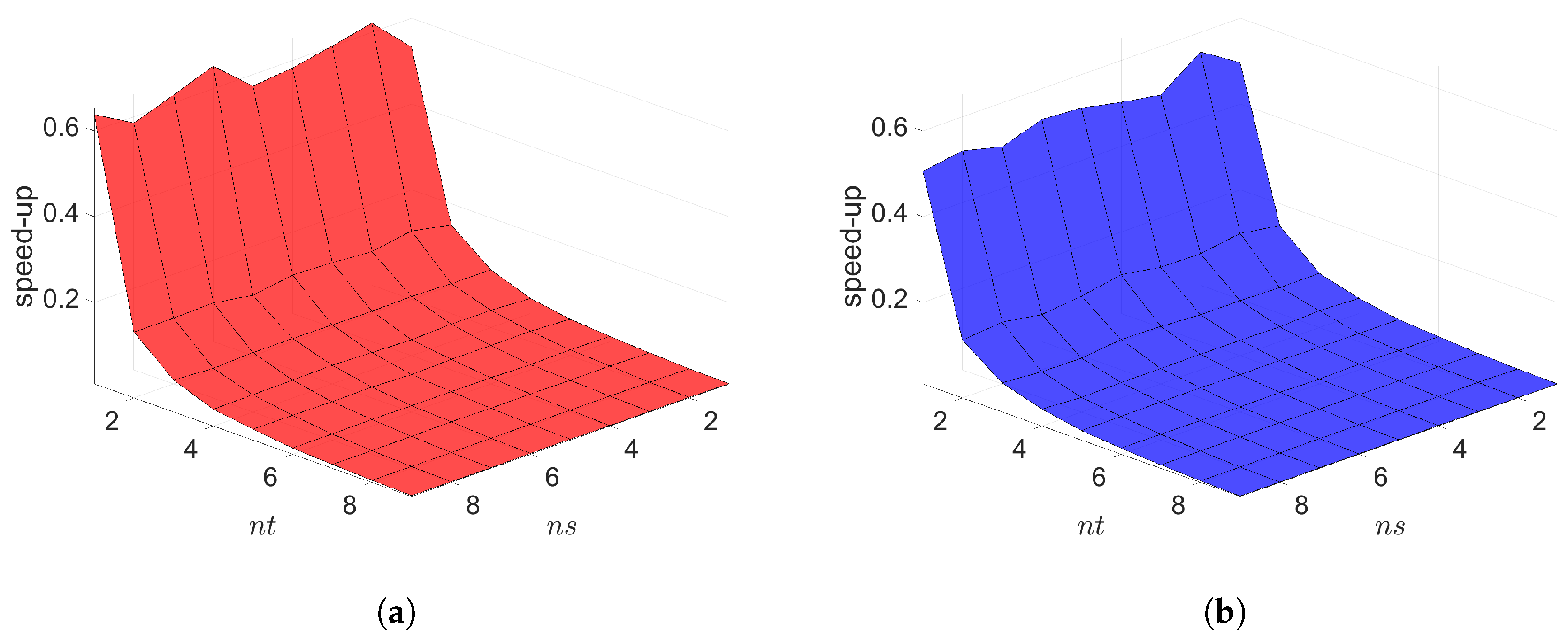
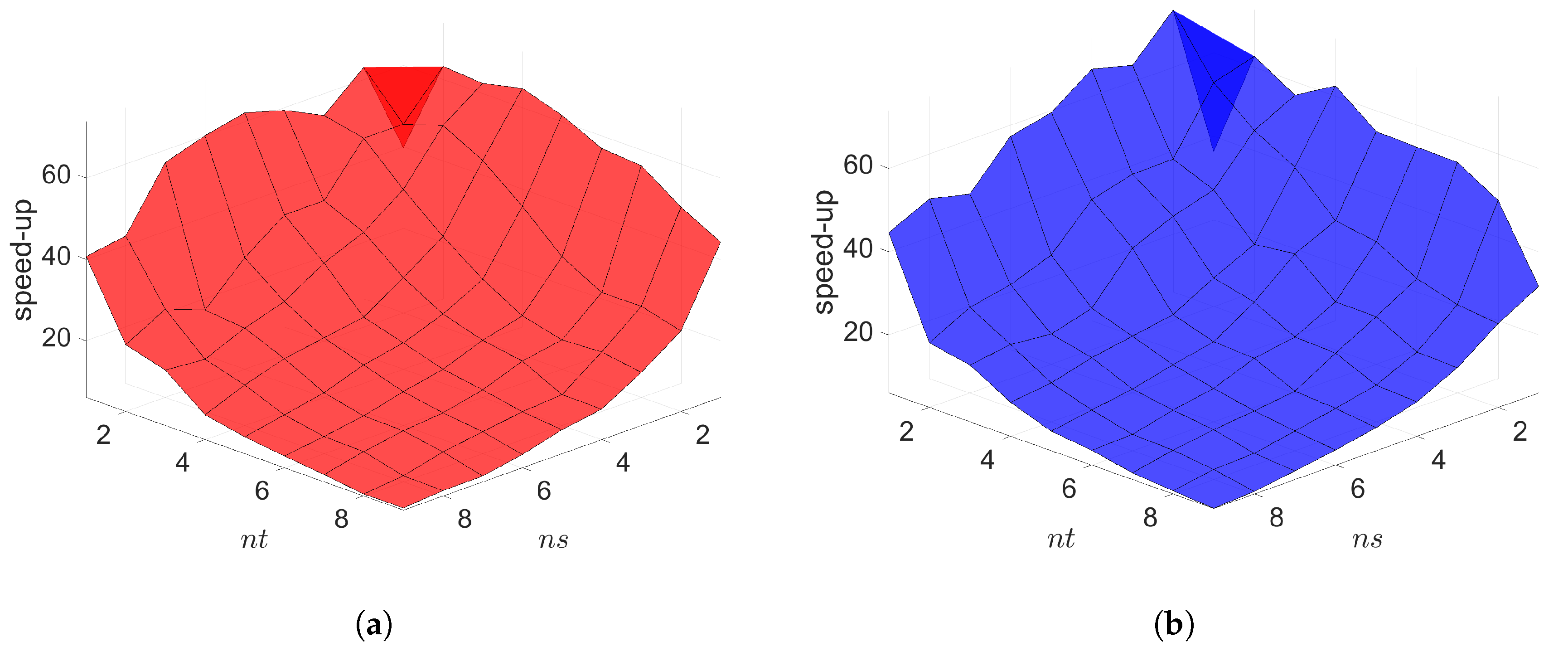
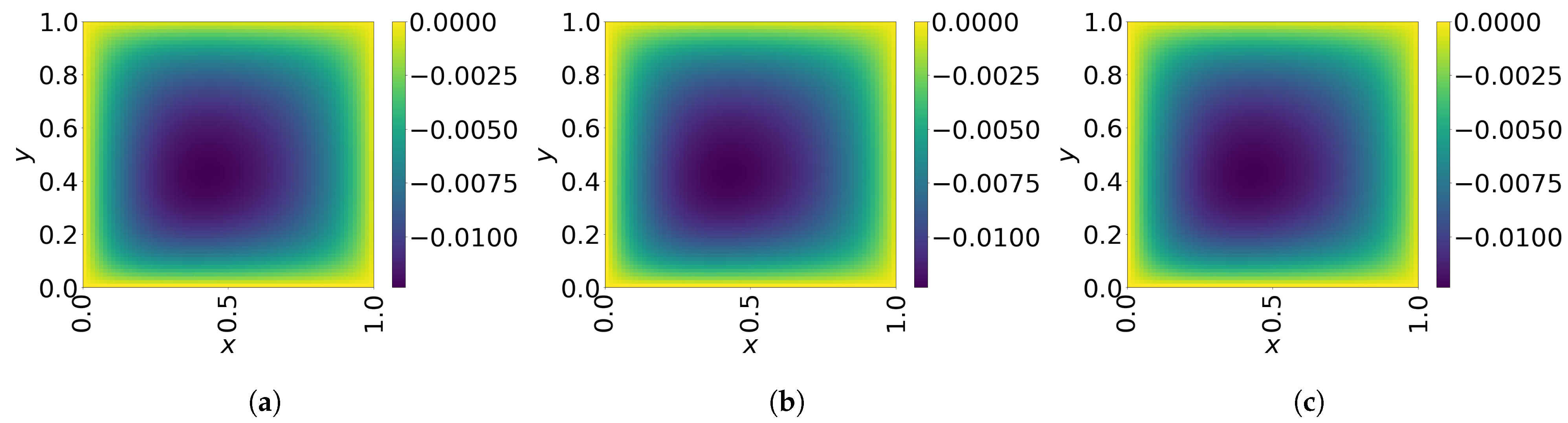
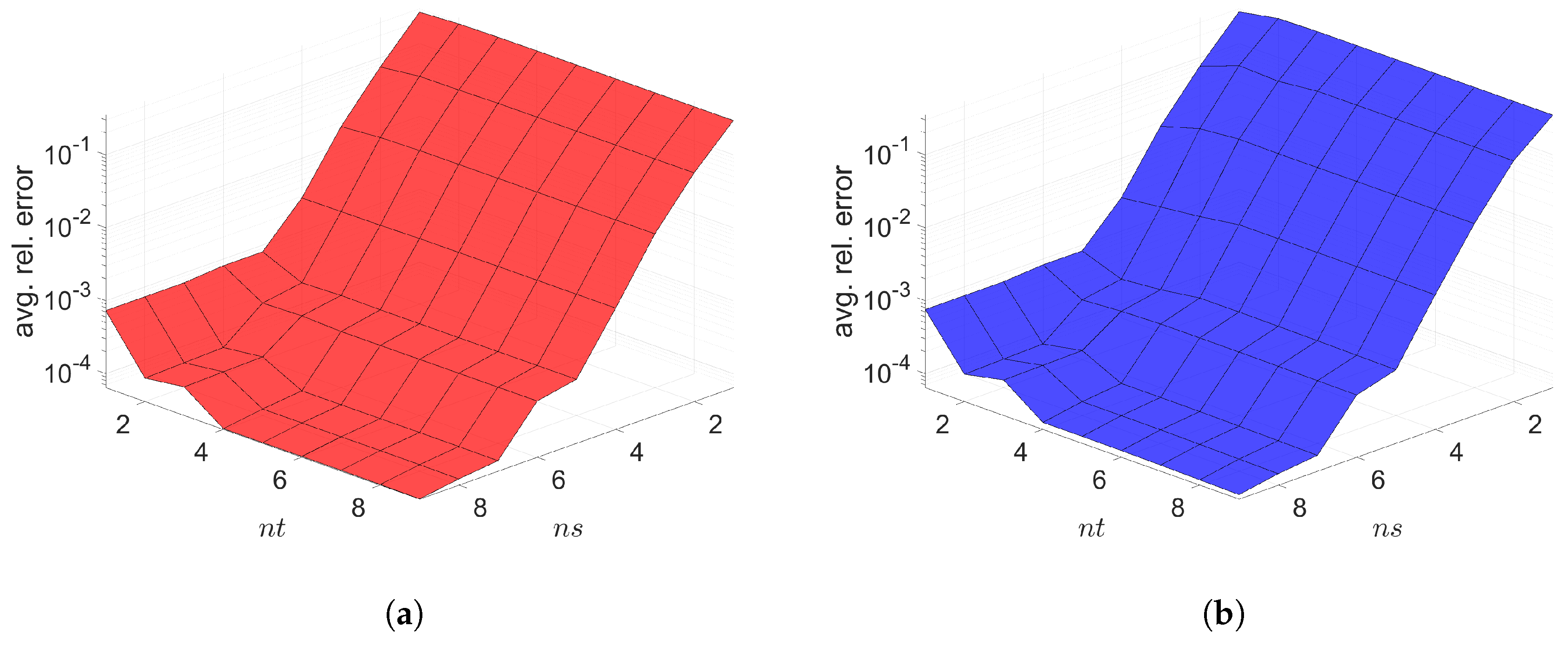
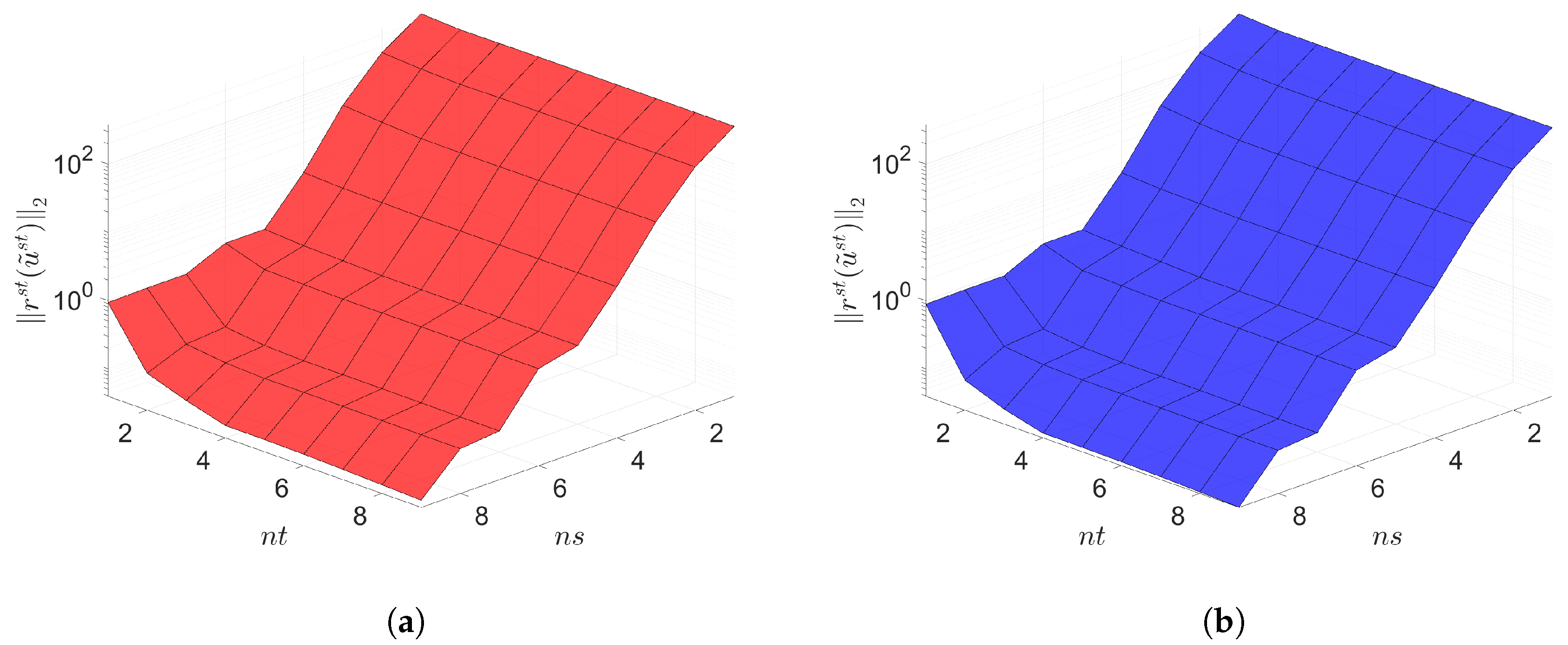
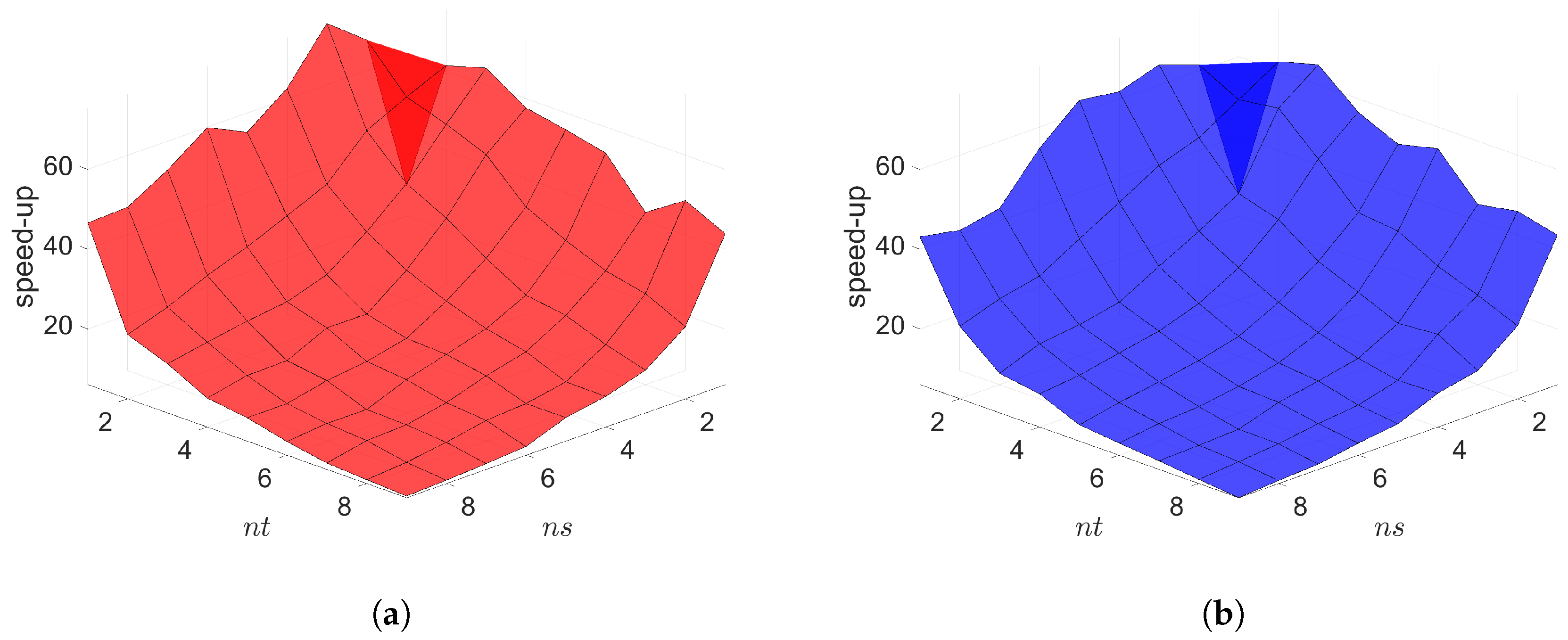
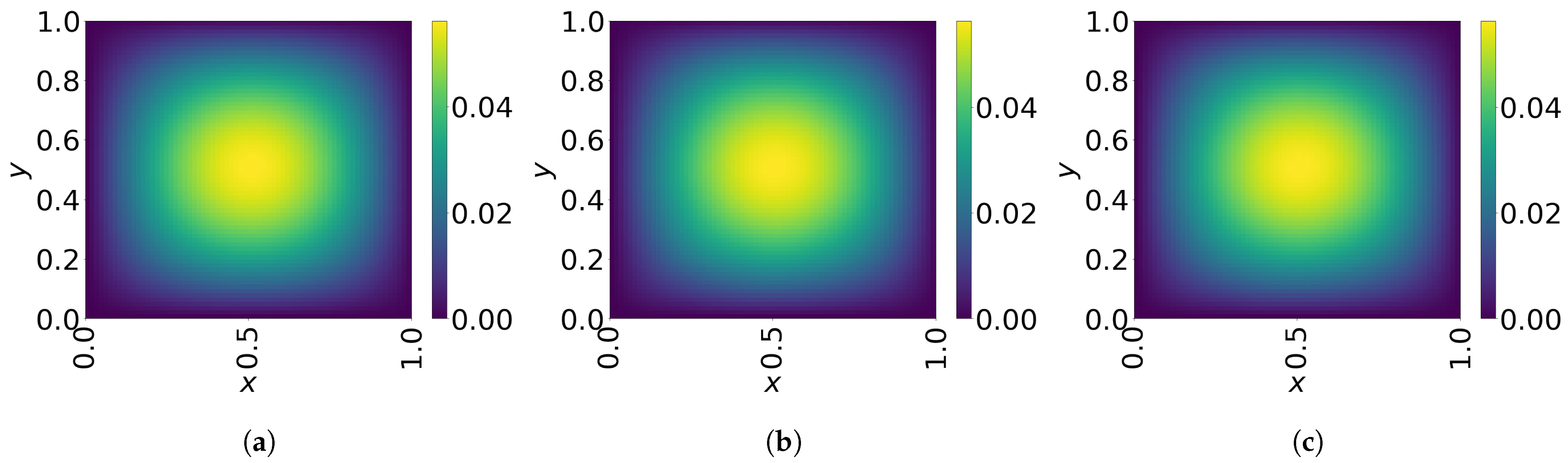
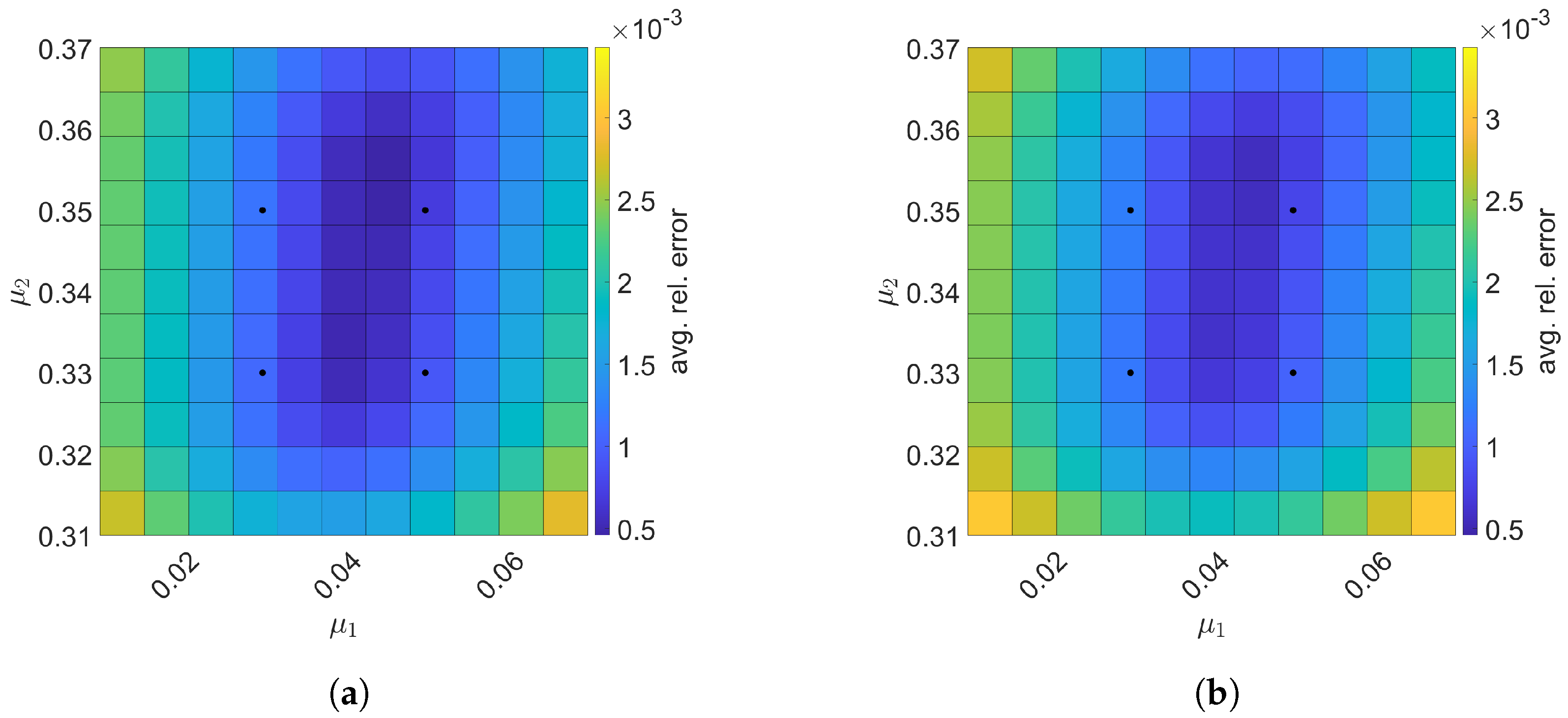
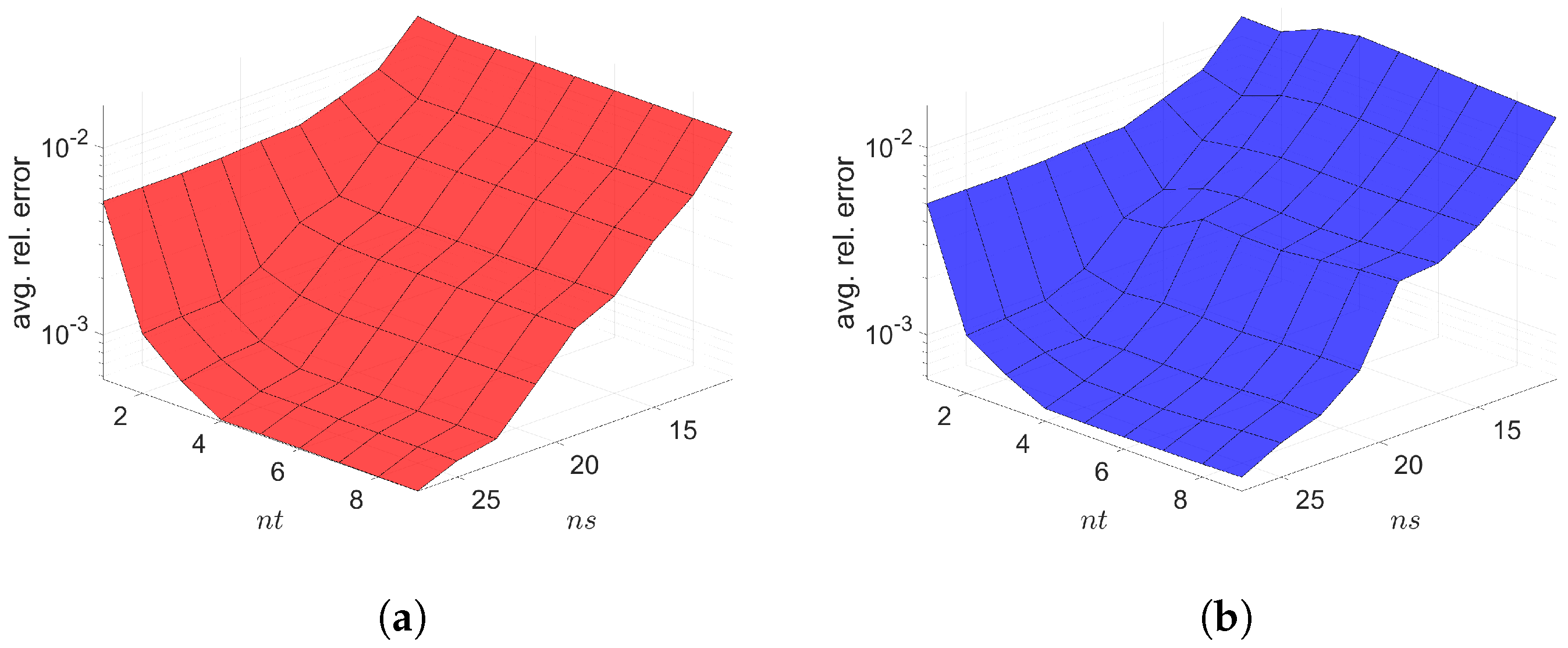
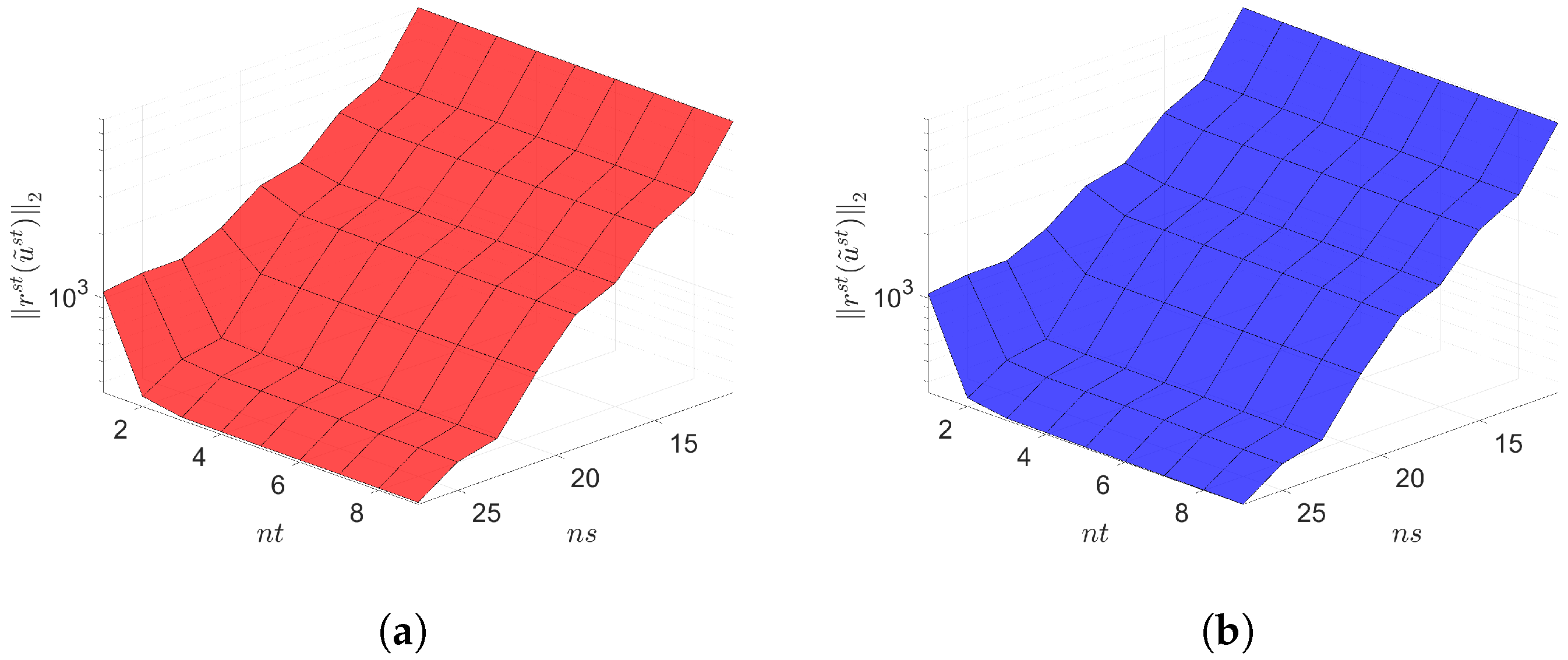
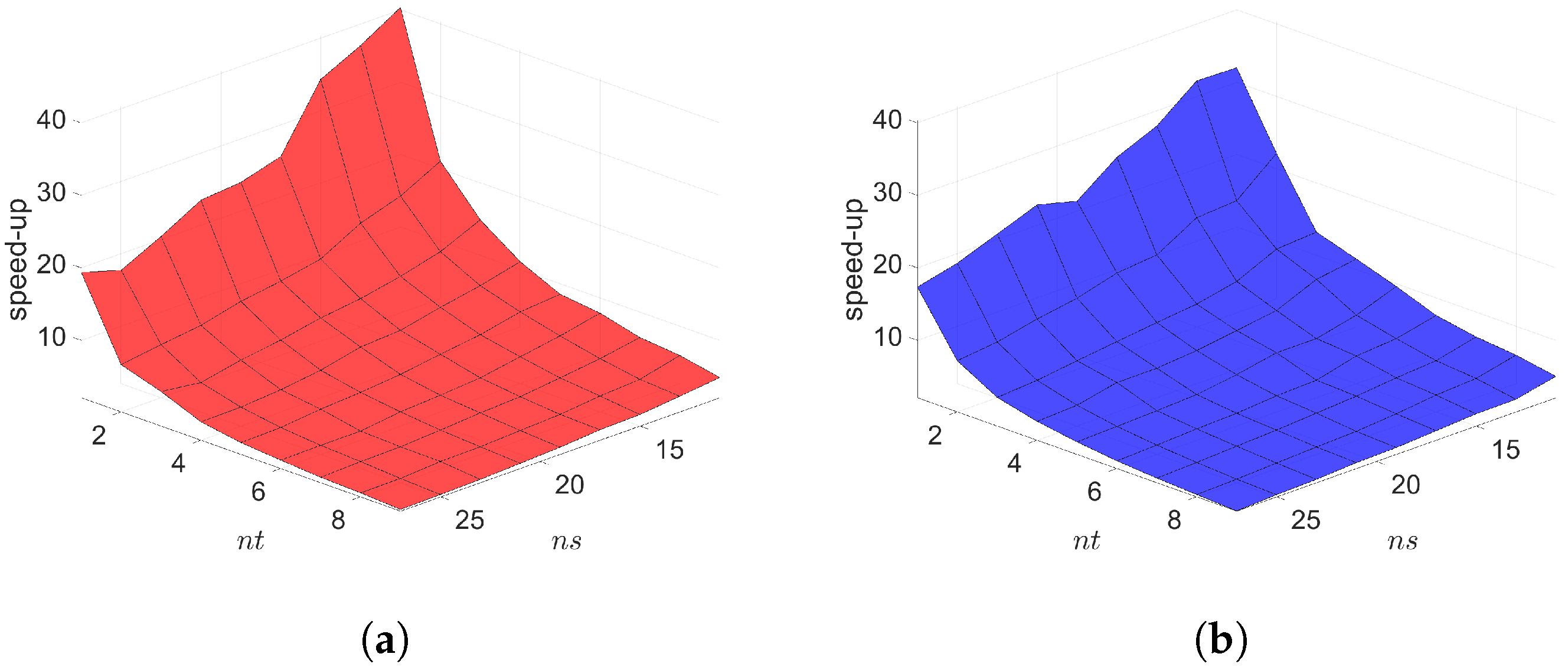
7. Numerical Results
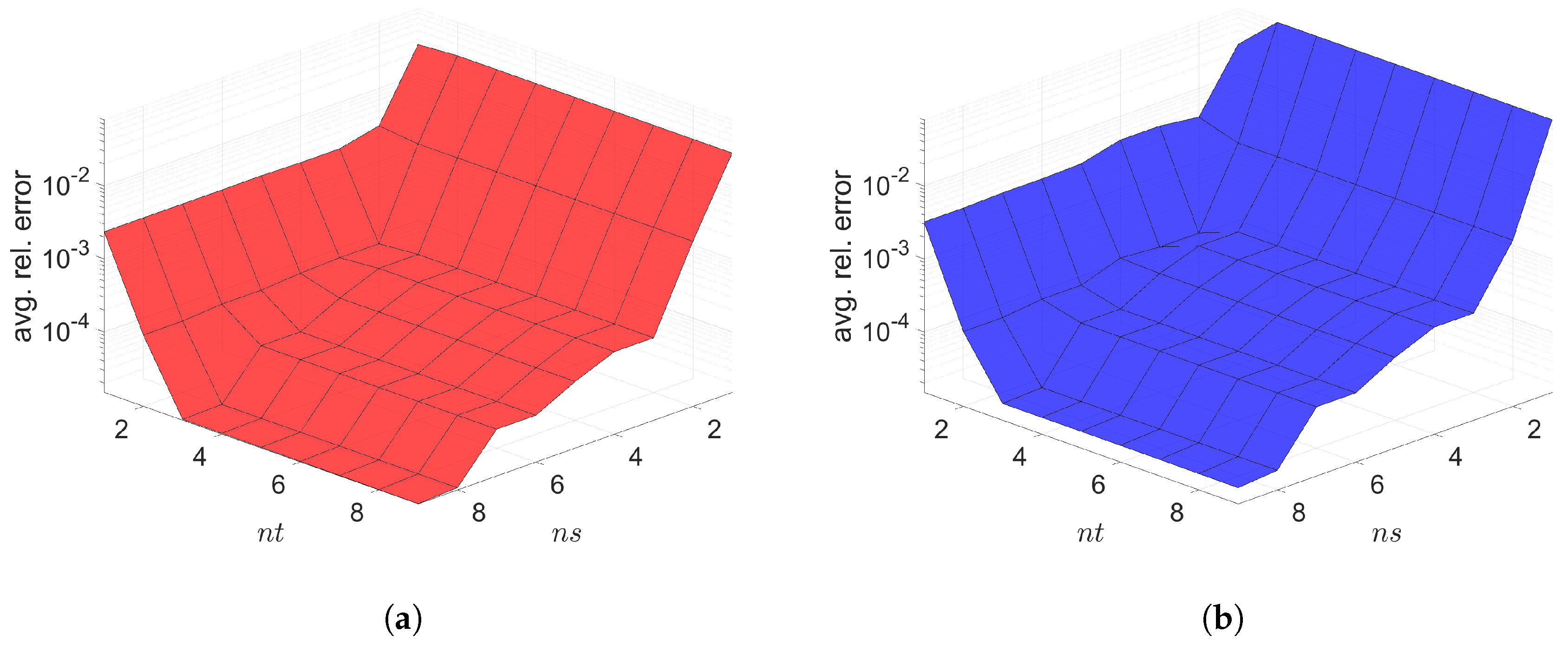
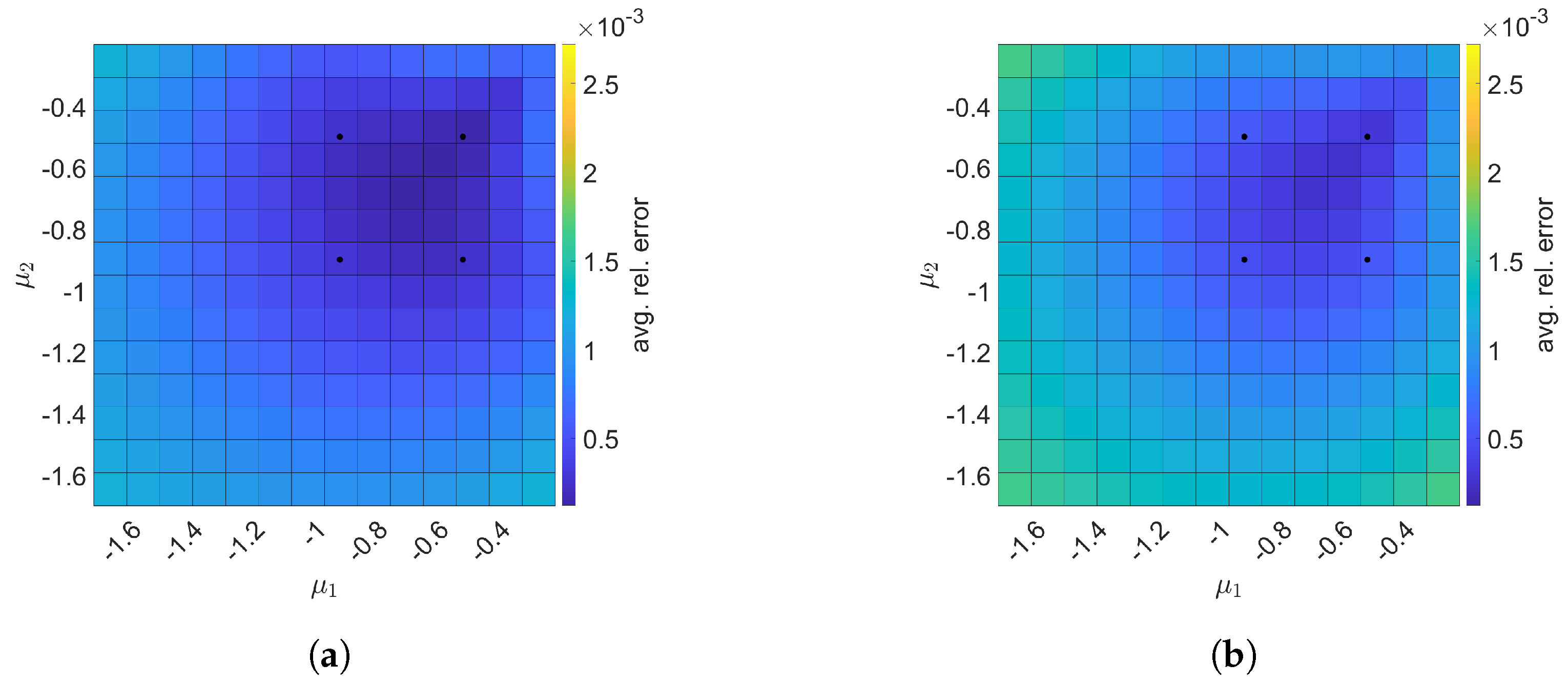
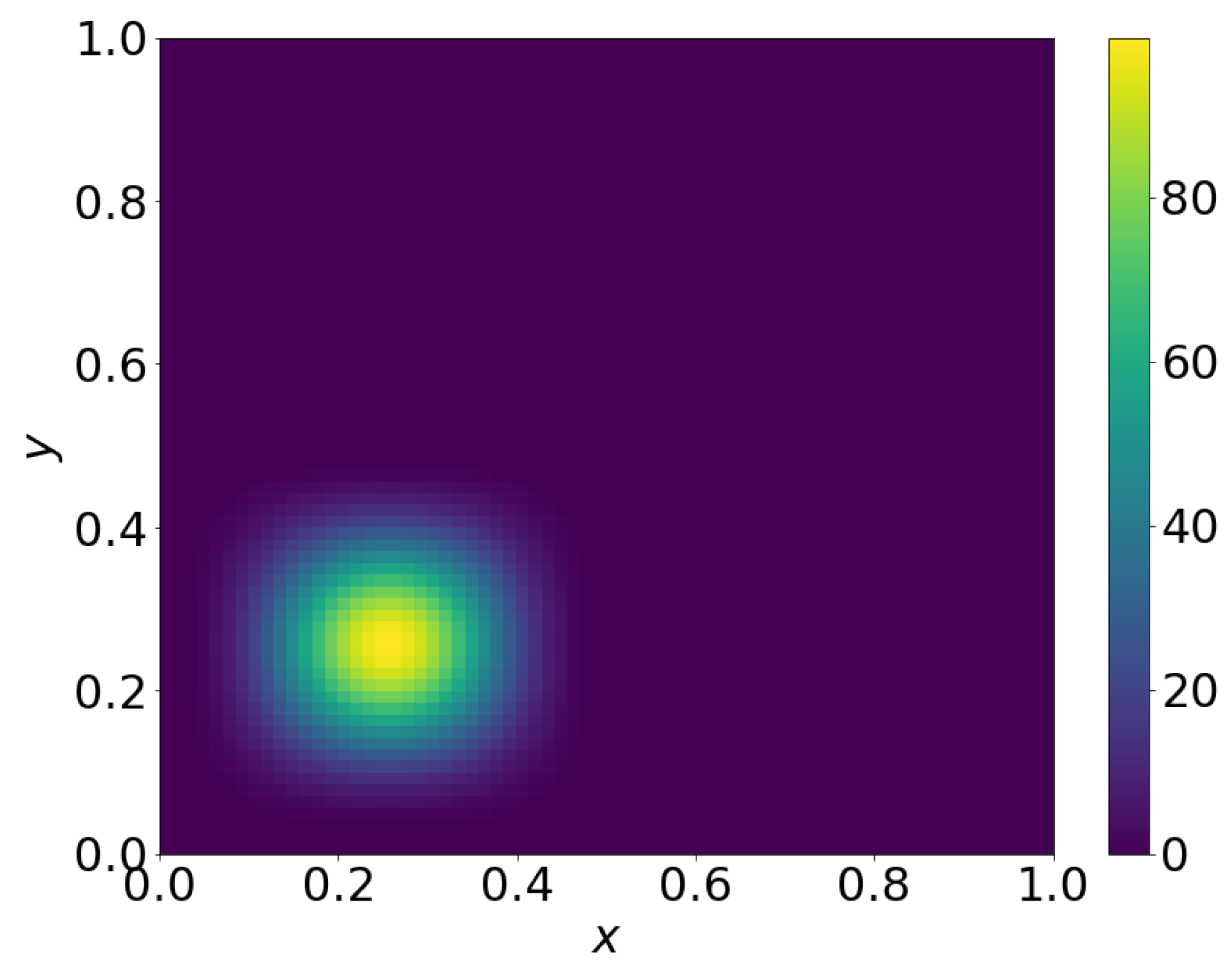
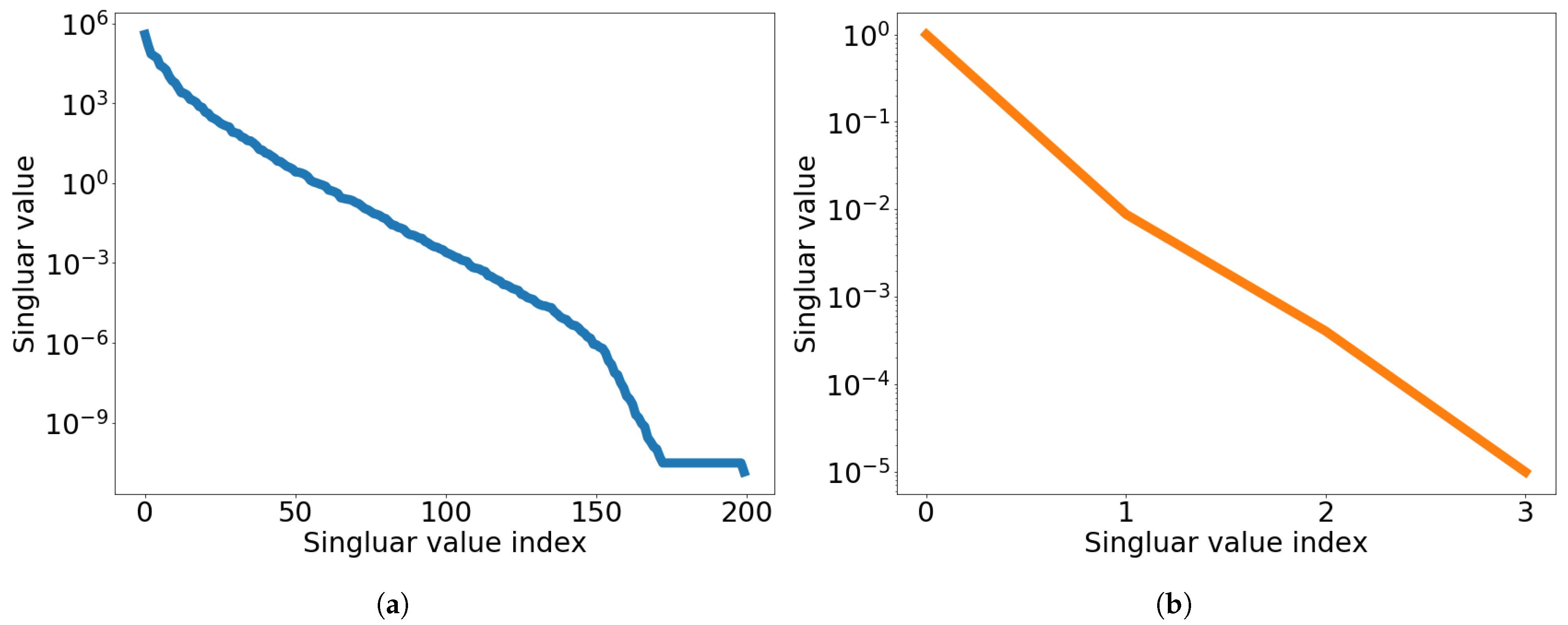
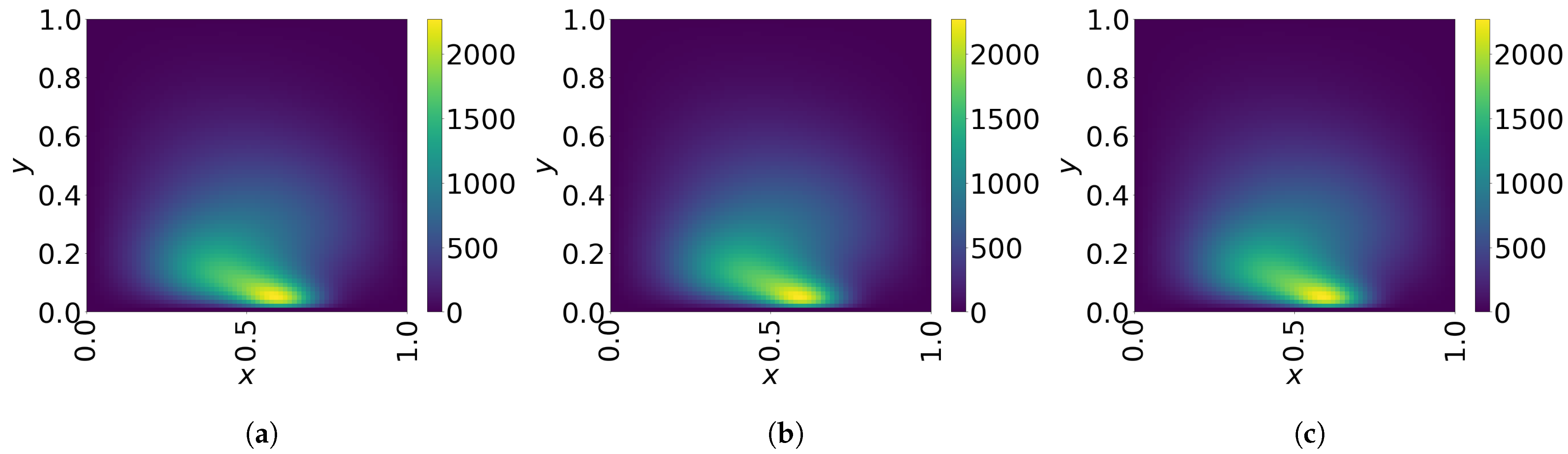
7.1. 2D Linear Diffusion Equation
7.2. 2D Linear Convection Diffusion Equation
7.2.1. Without Source Term
7.2.2. With Source Term
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Python Codes in Less than 120 Lines of Code for All Numerical Models Described in Section 7
- 1.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term (111 lines)
- 2.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term (117 lines)
- 3.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation (119 lines)
- 4.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation (119 lines)
- 5.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term (114 lines)
- 6.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term (119 lines)
Appendix A.1. Galerkin Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term


Appendix A.2. LSPG Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term



Appendix A.3. Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation


Appendix A.4. LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation



Appendix A.5. Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term


Appendix A.6. LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term



References
- Mullis, C.; Roberts, R. Synthesis of minimum roundoff noise fixed point digital filters. IEEE Trans. Circuits Syst. 1976, 23, 551–562. [Google Scholar] [CrossRef]
- Moore, B. Principal component analysis in linear systems: Controllability, observability, and model reduction. IEEE Trans. Autom. Control 1981, 26, 17–32. [Google Scholar] [CrossRef]
- Willcox, K.; Peraire, J. Balanced model reduction via the proper orthogonal decomposition. AIAA J. 2002, 40, 2323–2330. [Google Scholar] [CrossRef]
- Willcox, K.; Megretski, A. Fourier series for accurate, stable, reduced-order models in large-scale linear applications. SIAM J. Sci. Comput. 2005, 26, 944–962. [Google Scholar] [CrossRef] [Green Version]
- Heinkenschloss, M.; Sorensen, D.C.; Sun, K. Balanced truncation model reduction for a class of descriptor systems with application to the Oseen equations. SIAM J. Sci. Comput. 2008, 30, 1038–1063. [Google Scholar] [CrossRef] [Green Version]
- Sandberg, H.; Rantzer, A. Balanced truncation of linear time-varying systems. IEEE Trans. Autom. Control 2004, 49, 217–229. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, C.; Vulcanov, V.M.; Schütte, C. Balanced truncation of linear second-order systems: A Hamiltonian approach. Multiscale Model. Simul. 2010, 8, 1348–1367. [Google Scholar] [CrossRef] [Green Version]
- Petreczky, M.; Wisniewski, R.; Leth, J. Balanced truncation for linear switched systems. Nonlinear Anal. Hybrid Syst. 2013, 10, 4–20. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Rowley, C.W.; Tadmor, G. Snapshot-based balanced truncation for linear time-periodic systems. IEEE Trans. Autom. Control 2010, 55, 469–473. [Google Scholar]
- Bai, Z. Krylov subspace techniques for reduced-order modeling of large-scale dynamical systems. Appl. Numer. Math. 2002, 43, 9–44. [Google Scholar] [CrossRef] [Green Version]
- Gugercin, S.; Antoulas, A.C.; Beattie, C. H_2 model reduction for large-scale linear dynamical systems. SIAM J. Matrix Anal. Appl. 2008, 30, 609–638. [Google Scholar] [CrossRef]
- Astolfi, A. Model reduction by moment matching for linear and nonlinear systems. IEEE Trans. Autom. Control 2010, 55, 2321–2336. [Google Scholar] [CrossRef]
- Chiprout, E.; Nakhla, M. Generalized moment-matching methods for transient analysis of interconnect networks. In Proceedings of the 29th ACM/IEEE Design Automation Conference, Anaheim, CA, USA, 8–12 June 1992; pp. 201–206. [Google Scholar]
- Pratesi, M.; Santucci, F.; Graziosi, F. Generalized moment matching for the linear combination of lognormal RVs: application to outage analysis in wireless systems. IEEE Trans. Wirel. Commun. 2006, 5, 1122–1132. [Google Scholar] [CrossRef]
- Ammar, A.; Mokdad, B.; Chinesta, F.; Keunings, R. A new family of solvers for some classes of multidimensional partial differential equations encountered in kinetic theory modeling of complex fluids. J. Non-Newton. Fluid Mech. 2006, 139, 153–176. [Google Scholar] [CrossRef] [Green Version]
- Ammar, A.; Mokdad, B.; Chinesta, F.; Keunings, R. A new family of solvers for some classes of multidimensional partial differential equations encountered in kinetic theory modelling of complex fluids: Part II: Transient simulation using space-time separated representations. J. Non-Newton. Fluid Mech. 2007, 144, 98–121. [Google Scholar] [CrossRef] [Green Version]
- Chinesta, F.; Ammar, A.; Cueto, E. Proper generalized decomposition of multiscale models. Int. J. Numer. Methods Eng. 2010, 83, 1114–1132. [Google Scholar] [CrossRef]
- Pruliere, E.; Chinesta, F.; Ammar, A. On the deterministic solution of multidimensional parametric models using the proper generalized decomposition. Math. Comput. Simul. 2010, 81, 791–810. [Google Scholar] [CrossRef] [Green Version]
- Chinesta, F.; Ammar, A.; Leygue, A.; Keunings, R. An overview of the proper generalized decomposition with applications in computational rheology. J. Non-Newton. Fluid Mech. 2011, 166, 578–592. [Google Scholar] [CrossRef] [Green Version]
- Giner, E.; Bognet, B.; Ródenas, J.J.; Leygue, A.; Fuenmayor, F.J.; Chinesta, F. The proper generalized decomposition (PGD) as a numerical procedure to solve 3D cracked plates in linear elastic fracture mechanics. Int. J. Solids Struct. 2013, 50, 1710–1720. [Google Scholar] [CrossRef]
- Barbarulo, A.; Ladevèze, P.; Riou, H.; Kovalevsky, L. Proper generalized decomposition applied to linear acoustic: A new tool for broad band calculation. J. Sound Vib. 2014, 333, 2422–2431. [Google Scholar] [CrossRef] [Green Version]
- Amsallem, D.; Farhat, C. Stabilization of projection-based reduced-order models. Int. J. Numer. Methods Eng. 2012, 91, 358–377. [Google Scholar] [CrossRef]
- Amsallem, D.; Farhat, C. Interpolation method for adapting reduced-order models and application to aeroelasticity. AIAA J. 2008, 46, 1803–1813. [Google Scholar] [CrossRef] [Green Version]
- Thomas, J.P.; Dowell, E.H.; Hall, K.C. Three-dimensional transonic aeroelasticity using proper orthogonal decomposition-based reduced-order models. J. Aircr. 2003, 40, 544–551. [Google Scholar] [CrossRef]
- Hall, K.C.; Thomas, J.P.; Dowell, E.H. Proper orthogonal decomposition technique for transonic unsteady aerodynamic flows. AIAA J. 2000, 38, 1853–1862. [Google Scholar] [CrossRef]
- Simoncini, V. A new iterative method for solving large-scale Lyapunov matrix equations. SIAM J. Sci. Comput. 2007, 29, 1268–1288. [Google Scholar] [CrossRef] [Green Version]
- Benner, P.; Li, J.R.; Penzl, T. Numerical solution of large-scale Lyapunov equations, Riccati equations, and linear-quadratic optimal control problems. Numer. Linear Algebra Appl. 2008, 15, 755–777. [Google Scholar] [CrossRef]
- Rowley, C.W. Model reduction for fluids, using balanced proper orthogonal decomposition. Int. J. Bifurc. Chaos 2005, 15, 997–1013. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Ahuja, S.; Rowley, C.W. Reduced-order models for control of fluids using the eigensystem realization algorithm. Theor. Comput. Fluid Dyn. 2011, 25, 233–247. [Google Scholar] [CrossRef] [Green Version]
- Lall, S.; Marsden, J.E.; Glavaški, S. A subspace approach to balanced truncation for model reduction of nonlinear control systems. Int. J. Robust Nonlinear Control. IFAC-Affil. J. 2002, 12, 519–535. [Google Scholar] [CrossRef] [Green Version]
- Gosea, I.V.; Gugercin, S.; Beattie, C. Data-driven balancing of linear dynamical systems. arXiv 2021, arXiv:2104.01006. [Google Scholar]
- Chinesta, F.; Ladeveze, P.; Cueto, E. A short review on model order reduction based on proper generalized decomposition. Arch. Comput. Methods Eng. 2011, 18, 395. [Google Scholar] [CrossRef] [Green Version]
- Mayo, A.; Antoulas, A. A framework for the solution of the generalized realization problem. Linear Algebra Its Appl. 2007, 425, 634–662. [Google Scholar] [CrossRef] [Green Version]
- Scarciotti, G.; Astolfi, A. Data-driven model reduction by moment matching for linear and nonlinear systems. Automatica 2017, 79, 340–351. [Google Scholar] [CrossRef]
- Schmid, P.J. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 2010, 656, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.K.; Tu, J.H.; Rowley, C.W. Variants of dynamic mode decomposition: Boundary condition, Koopman, and Fourier analyses. J. Nonlinear Sci. 2012, 22, 887–915. [Google Scholar] [CrossRef]
- Williams, M.O.; Kevrekidis, I.G.; Rowley, C.W. A data—Driven approximation of the koopman operator: Extending dynamic mode decomposition. J. Nonlinear Sci. 2015, 25, 1307–1346. [Google Scholar] [CrossRef] [Green Version]
- Takeishi, N.; Kawahara, Y.; Yairi, T. Learning Koopman invariant subspaces for dynamic mode decomposition. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1130–1140. [Google Scholar]
- Askham, T.; Kutz, J.N. Variable projection methods for an optimized dynamic mode decomposition. SIAM J. Appl. Dyn. Syst. 2018, 17, 380–416. [Google Scholar] [CrossRef] [Green Version]
- Schmid, P.J.; Li, L.; Juniper, M.P.; Pust, O. Applications of the dynamic mode decomposition. Theor. Comput. Fluid Dyn. 2011, 25, 249–259. [Google Scholar] [CrossRef]
- Kutz, J.N.; Fu, X.; Brunton, S.L. Multiresolution dynamic mode decomposition. SIAM J. Appl. Dyn. Syst. 2016, 15, 713–735. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Dietrich, F.; Bollt, E.M.; Kevrekidis, I.G. Extended dynamic mode decomposition with dictionary learning: A data-driven adaptive spectral decomposition of the Koopman operator. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 103111. [Google Scholar] [CrossRef]
- Proctor, J.L.; Brunton, S.L.; Kutz, J.N. Dynamic mode decomposition with control. SIAM J. Appl. Dyn. Syst. 2016, 15, 142–161. [Google Scholar] [CrossRef] [Green Version]
- Tu, J.H.; Rowley, C.W.; Luchtenburg, D.M.; Brunton, S.L.; Kutz, J.N. On dynamic mode decomposition: Theory and applications. arXiv 2013, arXiv:1312.0041. [Google Scholar]
- Kutz, J.N.; Brunton, S.L.; Brunton, B.W.; Proctor, J.L. Dynamic Mode Decomposition: Data-Driven Modeling of Complex Systems; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Choi, Y.; Coombs, D.; Anderson, R. SNS: A solution-based nonlinear subspace method for time-dependent model order reduction. SIAM J. Sci. Comput. 2020, 42, A1116–A1146. [Google Scholar] [CrossRef] [Green Version]
- Hoang, C.; Choi, Y.; Carlberg, K. Domain-decomposition least-squares Petrov-Galerkin (DD-LSPG) nonlinear model reduction. arXiv 2020, arXiv:2007.11835. [Google Scholar]
- Carlberg, K.; Choi, Y.; Sargsyan, S. Conservative model reduction for finite-volume models. J. Comput. Phys. 2018, 371, 280–314. [Google Scholar] [CrossRef] [Green Version]
- Berkooz, G.; Holmes, P.; Lumley, J.L. The proper orthogonal decomposition in the analysis of turbulent flows. Annu. Rev. Fluid Mech. 1993, 25, 539–575. [Google Scholar] [CrossRef]
- Gubisch, M.; Volkwein, S. Proper orthogonal decomposition for linear-quadratic optimal control. Model Reduct. Approx. Theory Algorithms 2017, 5, 66. [Google Scholar]
- Kunisch, K.; Volkwein, S. Galerkin proper orthogonal decomposition methods for parabolic problems. Numer. Math. 2001, 90, 117–148. [Google Scholar] [CrossRef]
- Hinze, M.; Volkwein, S. Error estimates for abstract linear—Quadratic optimal control problems using proper orthogonal decomposition. Comput. Optim. Appl. 2008, 39, 319–345. [Google Scholar] [CrossRef]
- Kerschen, G.; Golinval, J.C.; Vakakis, A.F.; Bergman, L.A. The method of proper orthogonal decomposition for dynamical characterization and order reduction of mechanical systems: An overview. Nonlinear Dyn. 2005, 41, 147–169. [Google Scholar] [CrossRef]
- Bamer, F.; Bucher, C. Application of the proper orthogonal decomposition for linear and nonlinear structures under transient excitations. Acta Mech. 2012, 223, 2549–2563. [Google Scholar] [CrossRef]
- Atwell, J.A.; King, B.B. Proper orthogonal decomposition for reduced basis feedback controllers for parabolic equations. Math. Comput. Model. 2001, 33, 1–19. [Google Scholar] [CrossRef]
- Rathinam, M.; Petzold, L.R. A new look at proper orthogonal decomposition. SIAM J. Numer. Anal. 2003, 41, 1893–1925. [Google Scholar] [CrossRef]
- Kahlbacher, M.; Volkwein, S. Galerkin proper orthogonal decomposition methods for parameter dependent elliptic systems. Discuss. Math. Differ. Inclusions Control Optim. 2007, 27, 95–117. [Google Scholar] [CrossRef] [Green Version]
- Bonnet, J.P.; Cole, D.R.; Delville, J.; Glauser, M.N.; Ukeiley, L.S. Stochastic estimation and proper orthogonal decomposition: Complementary techniques for identifying structure. Exp. Fluids 1994, 17, 307–314. [Google Scholar] [CrossRef]
- Placzek, A.; Tran, D.M.; Ohayon, R. Hybrid proper orthogonal decomposition formulation for linear structural dynamics. J. Sound Vib. 2008, 318, 943–964. [Google Scholar] [CrossRef] [Green Version]
- LeGresley, P.; Alonso, J. Airfoil design optimization using reduced order models based on proper orthogonal decomposition. In Proceedings of the Fluids 2000 Conference and Exhibit, Denver, CO, USA, 19–22 June 2000; p. 2545. [Google Scholar]
- Efe, M.O.; Ozbay, H. Proper orthogonal decomposition for reduced order modeling: 2D heat flow. In Proceedings of the 2003 IEEE Conference on Control Applications, (CCA 2003), Istanbul, Turkey, 25–25 June 2003; Volume 2, pp. 1273–1277. [Google Scholar]
- Urban, K.; Patera, A. An improved error bound for reduced basis approximation of linear parabolic problems. Math. Comput. 2014, 83, 1599–1615. [Google Scholar] [CrossRef] [Green Version]
- Yano, M.; Patera, A.T.; Urban, K. A space-time hp-interpolation-based certified reduced basis method for Burgers’ equation. Math. Model. Methods Appl. Sci. 2014, 24, 1903–1935. [Google Scholar] [CrossRef]
- Yano, M. A space-time Petrov–Galerkin certified reduced basis method: Application to the Boussinesq equations. SIAM J. Sci. Comput. 2014, 36, A232–A266. [Google Scholar] [CrossRef]
- Baumann, M.; Benner, P.; Heiland, J. Space-time Galerkin POD with application in optimal control of semilinear partial differential equations. SIAM J. Sci. Comput. 2018, 40, A1611–A1641. [Google Scholar] [CrossRef] [Green Version]
- Towne, A.; Schmidt, O.T.; Colonius, T. Spectral proper orthogonal decomposition and its relationship to dynamic mode decomposition and resolvent analysis. J. Fluid Mech. 2018, 847, 821–867. [Google Scholar] [CrossRef] [Green Version]
- Towne, A. Space-time Galerkin projection via spectral proper orthogonal decomposition and resolvent modes. In Proceedings of the AIAA Scitech 2021 Forum, San Diego, CA, USA, 3–7 January 2021; p. 1676. [Google Scholar]
- Towne, A.; Lozano-Durán, A.; Yang, X. Resolvent-based estimation of space–time flow statistics. J. Fluid Mech. 2020, 883. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Carlberg, K. Space–Time Least-Squares Petrov–Galerkin Projection for Nonlinear Model Reduction. SIAM J. Sci. Comput. 2019, 41, A26–A58. [Google Scholar] [CrossRef]
- Parish, E.J.; Carlberg, K.T. Windowed least-squares model reduction for dynamical systems. J. Comput. Phys. 2021, 426, 109939. [Google Scholar] [CrossRef]
- Shimizu, Y.S.; Parish, E.J. Windowed space-time least-squares Petrov-Galerkin method for nonlinear model order reduction. arXiv 2020, arXiv:2012.06073. [Google Scholar]
- Choi, Y.; Brown, P.; Arrighi, W.; Anderson, R.; Huynh, K. Space–time reduced order model for large-scale linear dynamical systems with application to Boltzmann transport problems. J. Comput. Phys. 2020, 424, 109845. [Google Scholar] [CrossRef]
- Barone, M.F.; Kalashnikova, I.; Segalman, D.J.; Thornquist, H.K. Stable Galerkin reduced order models for linearized compressible flow. J. Comput. Phys. 2009, 228, 1932–1946. [Google Scholar] [CrossRef]
- Rezaian, E.; Wei, M. A hybrid stabilization approach for reduced-order models of compressible flows with shock-vortex interaction. Int. J. Numer. Methods Eng. 2020, 121, 1629–1646. [Google Scholar] [CrossRef]
- Carlberg, K.; Bou-Mosleh, C.; Farhat, C. Efficient nonlinear model reduction via a least-squares Petrov–Galerkin projection and compressive tensor approximations. Int. J. Numer. Methods Eng. 2011, 86, 155–181. [Google Scholar] [CrossRef]
- Huang, C.; Wentland, C.R.; Duraisamy, K.; Merkle, C. Model reduction for multi-scale transport problems using structure-preserving least-squares projections with variable transformation. arXiv 2020, arXiv:2011.02072. [Google Scholar]
- Yoon, G.H. Structural topology optimization for frequency response problem using model reduction schemes. Comput. Methods Appl. Mech. Eng. 2010, 199, 1744–1763. [Google Scholar] [CrossRef]
- Amir, O.; Stolpe, M.; Sigmund, O. Efficient use of iterative solvers in nested topology optimization. Struct. Multidiscip. Optim. 2010, 42, 55–72. [Google Scholar] [CrossRef]
- Amsallem, D.; Zahr, M.; Choi, Y.; Farhat, C. Design optimization using hyper-reduced-order modelsvd. Struct. Multidiscip. Optim. 2015, 51, 919–940. [Google Scholar] [CrossRef]
- Gogu, C. Improving the efficiency of large scale topology optimization through on-the-fly reduced order model construction. Int. J. Numer. Methods Eng. 2015, 101, 281–304. [Google Scholar] [CrossRef]
- Choi, Y.; Boncoraglio, G.; Anderson, S.; Amsallem, D.; Farhat, C. Gradient-based constrained optimization using a database of linear reduced-order models. J. Comput. Phys. 2020, 423, 109787. [Google Scholar] [CrossRef]
- Choi, Y.; Oxberry, G.; White, D.; Kirchdoerfer, T. Accelerating design optimization using reduced order models. arXiv 2019, arXiv:1909.11320. [Google Scholar]
- White, D.A.; Choi, Y.; Kudo, J. A dual mesh method with adaptivity for stress-constrained topology optimization. Struct. Multidiscip. Optim. 2020, 61, 749–762. [Google Scholar] [CrossRef]
- Najm, H.N. Uncertainty quantification and polynomial chaos techniques in computational fluid dynamics. Annu. Rev. Fluid Mech. 2009, 41, 35–52. [Google Scholar] [CrossRef]
- Walters, R.W.; Huyse, L. Uncertainty Analysis for Fluid Mechanics with Applications; Technical Report; National Aeronautics and Space Administration Hampton va Langley Research Center: Hampton, VA, USA, 2002. [Google Scholar]
- Zang, T.A. Needs and Opportunities for Uncertainty-Based Multidisciplinary Design Methods for Aerospace Vehicles; National Aeronautics and Space Administration, Langley Research Center: Hampton, VA, USA, 2002. [Google Scholar]
- Petersson, N.A.; Garcia, F.M.; Copeland, A.E.; Rydin, Y.L.; DuBois, J.L. Discrete Adjoints for Accurate Numerical Optimization with Application to Quantum Control. arXiv 2020, arXiv:2001.01013. [Google Scholar]
- Choi, Y.; Farhat, C.; Murray, W.; Saunders, M. A practical factorization of a Schur complement for PDE-constrained distributed optimal control. J. Sci. Comput. 2015, 65, 576–597. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y. Simultaneous Analysis and Design in PDE-Constrained Optimization. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2012. [Google Scholar]
- Sirovich, L. Turbulence and the dynamics of coherent structures. I. Coherent structures. Q. Appl. Math. 1987, 45, 561–571. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Carlberg, K.T. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 2020, 404, 108973. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Choi, Y.; Widemann, D.; Zohdi, T. A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder. arXiv 2020, arXiv:2009.11990. [Google Scholar]
- Kim, Y.; Choi, Y.; Widemann, D.; Zohdi, T. Efficient nonlinear manifold reduced order model. arXiv 2020, arXiv:2011.07727. [Google Scholar]
- McBane, S.; Choi, Y. Component-wise reduced order model lattice-type structure design. Comput. Methods Appl. Mech. Eng. 2021, 381, 113813. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Galerkin | LSPG |
|---|---|
| Galerkin | LSPG |
|---|---|
| Galerkin | LSPG | |
|---|---|---|
| Not using block structures | ||
| Using block structures |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Wang, K.; Choi, Y. Efficient Space–Time Reduced Order Model for Linear Dynamical Systems in Python Using Less than 120 Lines of Code. Mathematics 2021, 9, 1690. https://doi.org/10.3390/math9141690
Kim Y, Wang K, Choi Y. Efficient Space–Time Reduced Order Model for Linear Dynamical Systems in Python Using Less than 120 Lines of Code. Mathematics. 2021; 9(14):1690. https://doi.org/10.3390/math9141690
Chicago/Turabian StyleKim, Youngkyu, Karen Wang, and Youngsoo Choi. 2021. "Efficient Space–Time Reduced Order Model for Linear Dynamical Systems in Python Using Less than 120 Lines of Code" Mathematics 9, no. 14: 1690. https://doi.org/10.3390/math9141690