
Estimating the Quadratic Form xTA−mx for Symmetric Matrices: Further Progress and Numerical Computations


Abstract
:1. Introduction
- Statistics: The inverse of the covariance matrix, which is referred to as a precision matrix, usually appears in statistics. The covariance matrix reveals marginal correlations between the variables, whereas the precision matrix represents the conditional correlations between two data variables of the other variables [2]. The diagonal of the inverse of covariance matrices provides information about the quality of data in uncertainty quantification [3].
- Network analysis: The determination of the importance of the nodes of a graph is a major issue in network analysis. Information for these details can be extracted by the evaluation of the diagonal elements of the matrix , where A is the adjacency matrix of the network, , and is the spectral radius of A. This matrix is referred to as a resolvent matrix, see, for example, [4] and the references therein.
- Numerical analysis: Quadratic forms arise naturally in the context of the computation of the regularization parameter in Tikhonov regularization for solving ill-posed problems. In this case, the matrix has the form , . In the literature, many methods have been proposed for the selection of the regularization parameter , such as the discrepancy principle, cross-validation, generalized cross-validation (GCV), L-curve, and so forth; see, for an example, [5] (Chapter 15) and references therein. These methods involve quadratic forms of type , with .
- Finding an such that
- Assessing the absolute error of the above estimate, i.e., determining a bound for the quantity
2. Bounds on the Error
- UB1.
- UB2.
- UB3.
- UB4.
- UB5.
- For estimates satisfying , we have also the family of error boundswherecan be chosen as any integer such that.
- UB1.
- UB2.
- UB3.
- UB4.
- UB5.
3. Estimate of by the Projection Method
- Observe that upper bounds UB1 and UB4 from Proposition 1 are minimal for . In this case, we have ; thus, b has the smallest possible norm. Therefore, from the point of view of minimizing the upper bound on the error (more precisely, minimizing upper bounds UB1 and UB4), a convenient choice is .
- However, if the goal is fast estimation, we can take for even m and for odd m, as these two choices provide and , respectively, which are both easy to evaluate.
4. Estimate of Using the Minimization Method
5. The Heuristic Approach
6. A Comparison with Other Methods
6.1. The Extrapolation Method
- For , .
- For , .
- For , .
6.2. Gaussian Techniques
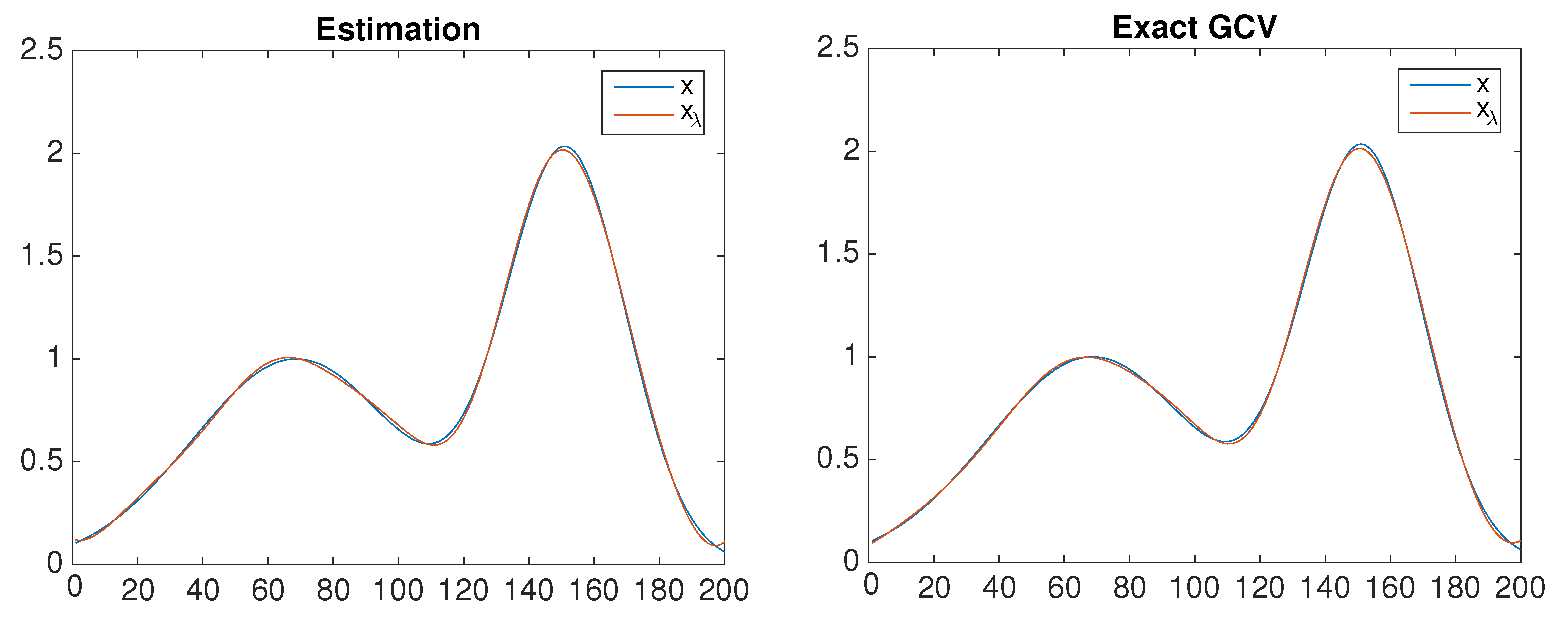
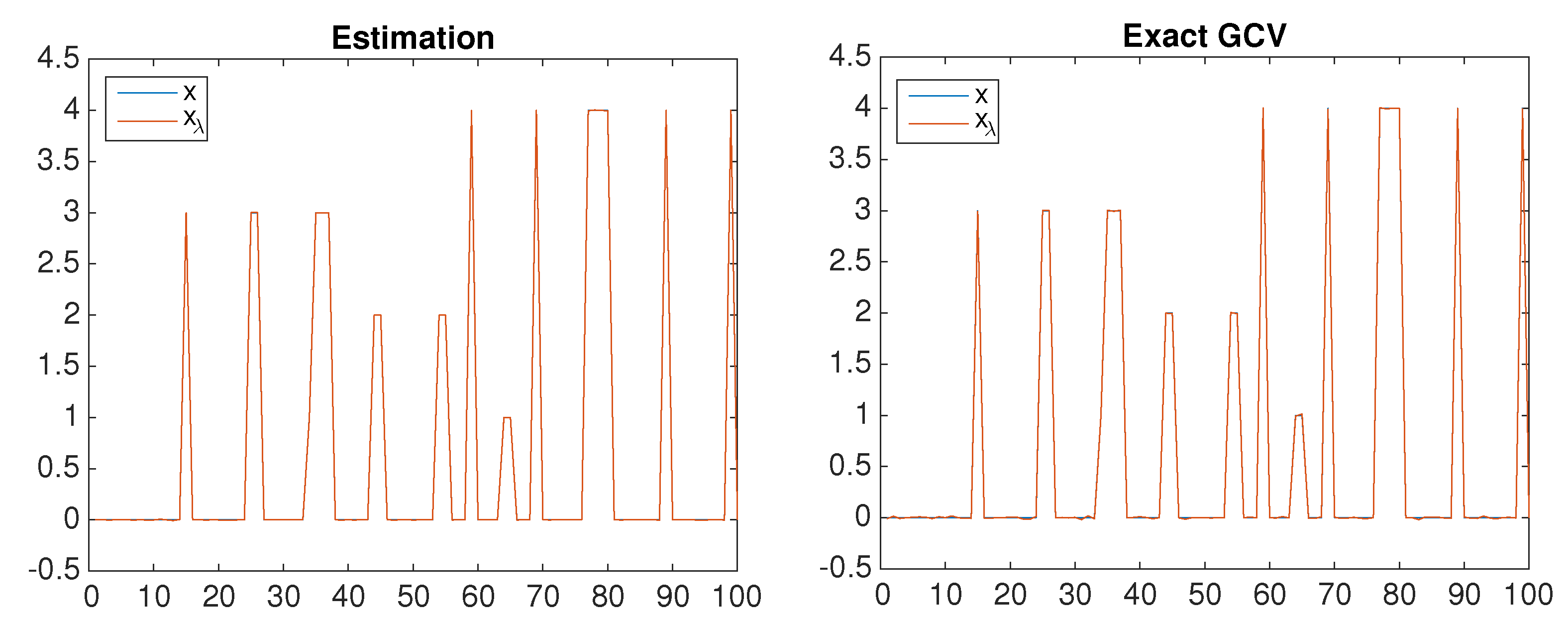
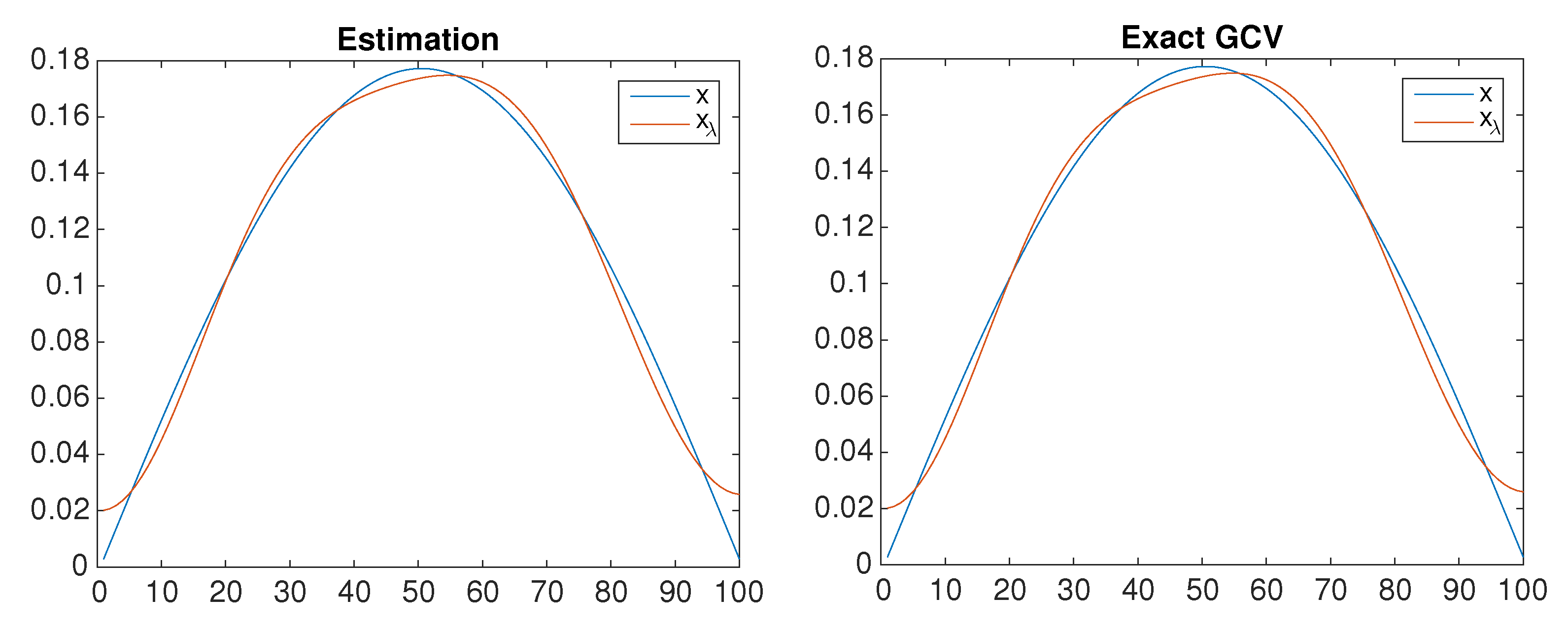
7. Application in Estimating
8. Numerical Examples
9. Conclusions
- The projection method improves the results of the extrapolation procedure by providing bounds on the absolute error.
- Although the estimates based on the Gauss quadrature are accurate, they require more time and more mvps than the proposed approaches as the number of the Lanczos iterations increases. The methods shown in the present paper are thus convenient especially in situations when a fast estimation of moderate accuracy is sought.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Fika, P.; Mitrouli, M.; Turek, O. On the estimation of xTA−1x for symmetric matrices. 2020; submitted. [Google Scholar]
- Fan, J.; Liao, Y.; Liu, H. An overview on the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Tang, J.; Saad, Y. A probing method for computing the diagonal of a matrix inverse. Numer. Linear Algebra Appl. 2012, 19, 485–501. [Google Scholar] [CrossRef] [Green Version]
- Benzi, M.; Klymko, C. Total Communicability as a centrality measure. J. Complex Netw. 2013, 1, 124–149. [Google Scholar] [CrossRef]
- Golub, G.H.; Meurant, G. Matrices, Moments and Quadrature with Applications; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Bai, Z.; Fahey, M.; Golub, G. Some large-scale matrix computation problems. J. Comput. Appl. Math. 1996, 74, 71–89. [Google Scholar] [CrossRef] [Green Version]
- Fika, P.; Mitrouli, M.; Roupa, P. Estimates for the bilinear form xTA−1y with applications to linear algebra problems. Electron. Trans. Numer. Anal. 2014, 43, 70–89. [Google Scholar]
- Fika, P.; Mitrouli, M. Estimation of the bilinear form y*f(A)x for Hermitian matrices. Linear Algebra Appl. 2016, 502, 140–158. [Google Scholar] [CrossRef]
- Bekas, C.; Curioni, A.; Fedulova, I. Low-cost data uncertainty quantification. Concurr. Comput. Pract. Exp. 2012, 24, 908–920. [Google Scholar] [CrossRef]
- Taylor, A.; Higham, D.J. CONTEST: Toolbox Files and Documentation. Available online: http://www.mathstat.strath.ac.uk/research/groups/numerical_analysis/contest/toolbox (accessed on 15 April 2021).
- Reichel, L.; Rodriguez, G.; Seatzu, S. Error estimates for large-scale ill-posed problems. Numer. Algorithms 2009, 51, 341–361. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P.C. Regularization Tools Version 4.0 for MATLAB 7.3. Numer. Algorithms 2007, 46, 189–194. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Estimated | Upper Bounds on | |||||
|---|---|---|---|---|---|---|
| Value | UB1 | UB2 | UB3 | UB4 | UB5 | |
| 0.0103 | 0.0541 | 0.1909 | 0.0690 | 0.1080 | 0.0540 | |
| 0.0103 | 0.0540 | 0.1926 | 0.0692 | 0.1079 | 0.0540 | |
| 0.0106 | 0.0731 | 0.1029 | 0.0499 | 0.1460 | 0.0538 | |
| 0.0105 | 0.0701 | 0.1032 | 0.0497 | 0.1401 | 0.0538 | |
| 0.0103 | 0.0541 | 0.1872 | 0.0684 | 0.1082 | 0.0540 | |
| 0.0103 | 0.0543 | 0.1828 | 0.0677 | 0.1084 | 0.0540 | |
| 1.0176 | 0.8636 | 1.0268 | 0.9910 | 1.1990 | 1.2335 |
| 296.6203 | 296.5306 | 299.8469 | 297.7640 | 296.7100 | 296.7562 |
| n | Estimate | MRE | Time |
|---|---|---|---|
| 1000 | 1.2688 × | 5.3683 × | |
| 4.3539 × | 5.4723 × | ||
| 2.9994 × | 2.3557 × | ||
| 3.0020 × | 2.1121 × | ||
| 3.5996 × | 6.5678 × | ||
| 3.8761 × | 5.9529 × | ||
| 1.2687 × | 1.7068 | ||
| 3000 | 4.2294 × | 2.2339 × | |
| 1.4516 × | 2.2521 × | ||
| 1.0508 × | 1.2698 | ||
| 1.0528 × | 1.0726 | ||
| 1.2004 × | 2.5384 × | ||
| 1.6973 × | 5.1289 × | ||
| 4.2294 × | 1.1647 × | ||
| 5000 | 2.5377 × | 1.4881 × | |
| 8.7099 × | 1.4502 × | ||
| 6.6113 × | 1.2790 × | ||
| 6.6256 × | 8.3479 | ||
| 7.2027 × | 1.7101 × | ||
| 1.1532 × | 6.4850 | ||
| 2.5377 × | 2.0130 × |
| Network | ||||||
|---|---|---|---|---|---|---|
| pref | 8.770 × | 1.646 × | 3.008 × | 1.240 × | 9.218 × | 6.500 × |
| [2.723 × ] | [3.447 × ] | [5.091] | [4.105] | [3.747 × ] | [9.471 × ] | |
| lock and key | 3.590 × | 6.700 × | 1.540 × | 4.313 × | 3.620 × | 3.170 × |
| [3.927 × ] | [4.429 × ] | [6.754] | [4.884] | [4.946 × ] | [8.387 × ] | |
| renga | 7.173 × | 1.014 × | 2.875 × | 5.516 × | 4.110 × | 2.936 × |
| [4.153 × ] | [4.724 × ] | [4.597] | [4.059] | [5.103 × ] | [6.477 × ] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitrouli, M.; Polychronou, A.; Roupa, P.; Turek, O. Estimating the Quadratic Form xTA−mx for Symmetric Matrices: Further Progress and Numerical Computations. Mathematics 2021, 9, 1432. https://doi.org/10.3390/math9121432
Mitrouli M, Polychronou A, Roupa P, Turek O. Estimating the Quadratic Form xTA−mx for Symmetric Matrices: Further Progress and Numerical Computations. Mathematics. 2021; 9(12):1432. https://doi.org/10.3390/math9121432
Chicago/Turabian StyleMitrouli, Marilena, Athanasios Polychronou, Paraskevi Roupa, and Ondřej Turek. 2021. "Estimating the Quadratic Form xTA−mx for Symmetric Matrices: Further Progress and Numerical Computations" Mathematics 9, no. 12: 1432. https://doi.org/10.3390/math9121432