1. Introduction
Network slicing is a key novel technology introduced in 5G networks as a response to two challenges:
to efficiently transmit data with completely different characteristics and Quality of Service (QoS) requirements over the same physical network infrastructure, and
to provide seamless support for diverse business models and market scenarios, for example, Mobile Virtual Network Operators (MVNO), which do not possess their own network infrastructure yet seek autonomy in administration and admission control.
Network slicing permits creating a multitude of logical networks for different tenants over a common infrastructure. Current industry standards define a network slice as a logical network that provides specific network capabilities and network characteristics [
1,
2]. According to Reference [
2], the dynamic scale-in and scale-out of resources in a slice should be supported and occur with minimal impact on QoS. ITU-T Recommendations also indicate that slices should be isolated from each other, so that their interference is minimal [
3]. Moreover, depending on the slices’ requirements, different levels of isolation should be available, which may result, for instance, in the preemption of a slice’s resources by another slice with a higher isolation level [
2].
Slices can span across several network segments—user equipment (which can belong to multiple slices simultaneously), Radio Access Network (RAN), core network, and so forth—and thus constitute complete end-to-end logical networks. The resources allocated to a slice can be dedicated and/or shared in terms of processing power, storage, bandwidth, and so forth [
4]. Since network slicing implies infrastructure sharing, its efficiency is contingent upon finding an adequate policy for allocating resources among slices. In light of the requirements stated above and common industry practice, such a policy should be QoS-oriented and provide
efficient resource usage,
fair, non-discriminating resource allocation among users, and
flexible isolation of slices from one another.
The problem of resource allocation in network slicing has been addressed in many recent studies, some theoretical and of a more general nature, and some technology-specific. One category of works, namely References [
5,
6,
7], deals with the end-to-end slicing, which relates and extends the virtual network embedding problem [
5]. Generally, this approach implies representing the physical network and the virtual network formed by the slices in graph form and finding a mapping between them. Another large category of studies focuses on how to share a particular network resource or a combination of resources among a set of slices. For the most part, this category revolves around RAN and radio spectrum (channel) resources, since the latter inherently cannot be easily scaled up. However, the ways to consider and slice RAN resources vary—while many studies address the slicing of the radio resources of a single base station [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17], others consider a combination of specific RAN-related resources, namely the base station’s radio channel capacity, cache and backhaul bandwidth [
18], a cluster of several homogeneous [
19,
20,
21] or heterogeneous [
22,
23,
24] base stations, or the capacity of a Cloud-RAN (C-RAN), in which the baseband resources of several homogeneous [
25,
26] or heterogeneous [
27,
28] radio systems are centralized into a single resource pool. Besides, some studies deal with finite sets of purely abstract [
29,
30] or more specific—radio, transport and computing [
31]—network resources.
The assumptions regarding the network slices also vary. Some researchers tailor their slicing schemes for the standardized slice types defined in Reference [
1] and corresponding to the three categories of 5G services [
2]—Enhanced Mobile Broadband (eMBB), Ultra-Reliable Low-Latency Communications (URLLC) and Massive Machine-Type Communications (mMTC) also referred to as Massive Internet of Things (MIoT). RAN resource allocation among such three slices is addressed in Reference [
10,
15]. Some authors generalize the previous approach and consider a finite set of slices, assuming each slice to carry either data-rate- or delay-sensitive traffic [
11,
16,
26], which loosely corresponds to eMBB and URLLC. The trade-off between data-rate- and delay-sensitivity for each slice can be adjusted through weights in Reference [
13], while in References [
23,
24,
31] slices are characterized by delay tolerance and bit rate requested for the slice’s user at every base station. In Reference [
32], slices are assumed to carry either elastic or inelastic traffics. References [
17,
18] consider a set of slices, each providing a finite number of services with certain characteristics. Finally, many studies consider a set of slices without specifying the nature of the carried traffic [
9,
12,
14,
19,
20,
21,
22,
25,
29]; in this case, the scenario of MVNOs is sometimes exploited, although from a broader perspective than that of the one currently deployed. Yet another approach is adopted in Reference [
28], where each slice tenant is assumed to have a Service Level Agreement (SLA) with the infrastructure provider, specifying the slice’s bounds in terms of data rate. Three types of slices are thus defined—with upper and lower bounds fixed, with only a lower bound fixed, and unrestricted (best effort).
The network slicing strategies proposed in the literature are aimed at fulfilling manifold criteria, such as to maximize the overall user data rate [
15,
19,
27], to maximize data-rate- and latency-related utility functions [
13,
24], to minimize the overall resource usage while providing performance isolation of the slices [
25] or meeting data-rate- and latency-related requirements [
16,
23]. In References [
23,
24] a fixed bandwidth allocated to the slice in the core network is considered as an additional constraint. The policy proposed in Reference [
12] is aimed at satisfying, on average, the prenegotiated resource shares per tenant within an allowed deviation. Preset minimum shares per slice are also assumed in References [
8,
9,
19,
29], however in References [
8,
29] the effective slice capacities are allowed to go below the guaranteed minima, following the slice workload, while in Reference [
19] the minima serve as an optimization constraint, hence being reserved. The objective of the slicing policy proposed in Reference [
29] is to minimize the weighted sum of the relative differences between allocated and demanded resource shares. QoS provision and fairness are the focus of References [
15,
30]. The objective in Reference [
26] is to maximize the time-averaged expectation of the infrastructure provider’s utility, defined as the difference between the income (data rate and delay gain) and cost (power and spectrum resources). Some works adopt auction models, where resource allocation follows the tenants’ bids for their slices [
14] or for their slice users [
20,
21]. Some works [
16,
17] specifically consider slice isolation, which is provided by setting a fixed upper limit on the slice’s capacity. Slice isolation via guaranteed minima is proposed in References [
8,
9,
19,
29]. Finally, some authors, namely References [
15,
17,
27], take into account slice priorities.
In the literature, the majority of studies, except for the most technology-specific ones, assume each of the considered resources to be homogeneous and divisible, and propose an algorithm for determining slices’ sizes (capacities) as shares of the resources’ capacities [
9,
12,
13,
14,
15,
18,
20,
21,
29,
30]. If the services provided in the slice to end users require a certain minimum data rate, such as Guaranteed Bit Rate (GBR) services, the slicing policy may include not only resource allocation but also admission control [
17,
21,
23,
27]. Network slicing at the admission-control level is discussed in Reference [
33] along with other approaches to RAN slicing, while user blocking probabilities for such systems are estimated in References [
17,
21]. Besides, since network slices are to be created and terminated dynamically [
2], some studies [
31,
32,
34] investigate the slice admission control, that is, whether a new slice instance can/should be admitted to the network. The problem of associating users to base stations under slicing constraints is addressed in References [
23,
24]. More technology-specific works, such as References [
10,
11], represent radio resources in the form of a time-frequency grid composed of Resource Blocks (which reflects the physical layer of 4G/5G RAN) and consider not only the share of the total number of Resource Blocks allocated to a slice per time slot, but also their position on the grid, taking account of the corresponding technology-specific constraints.
Two major approaches to the resource slicing problem can be distinguished in the literature. Some authors [
12,
13,
19,
20,
21,
23,
27] propose to perform resource allocation to slices (inter-slice allocation) by means of resource allocation to individual network users with some additional slicing-specific constraints. Then, the slice capacity can be obtained by summing up the resource shares allocated to the corresponding users. Although such a strategy can yield the optimal solution, it may also be computationally inefficient and deprive slice tenants of a certain degree of autonomy and confidentiality [
15,
22]. The other approach assumes a hierarchical resource slicing (also referred to as two-level [
14] or distributed [
22]), in which inter-slice allocation is decoupled from resource scheduling to slice users (intra-slice allocation). In this case, the slice shares are determined based upon some aggregated information about slice users and/or additional criteria (e.g., the tenants’ bids [
14]), after which resources are allocated to slice users within the computed slice capacities. Furthermore, some researchers assume the two steps of the hierarchical RAN slicing to be performed on the same time scale [
8,
15,
22], usually every Transmission Time Interval, while others consider a longer slicing/decision interval [
9,
11], which may imply traffic prediction using machine learning techniques [
25,
31].
The predominant mathematical methods applied in slicing-related resource-sharing problems are those of optimization theory—the resource shares allocated to slices/slice users are often determined as the solution to a linear or non-linear optimization problem [
7,
11,
12,
13,
15,
16,
18,
19,
23,
24,
26,
27,
28,
31]. Algorithmic resource slicing policies are proposed in References [
8,
9]. Besides, numerous works opt for game theory methods [
14,
20,
21,
22]. Machine learning along with Markov decision processes are applied in References [
25,
31,
32]. Continuous-Time Markov Chain (CTMC) models for network slicing analysis are proposed in References [
17,
34]. The authors of Reference [
34] consider a one-dimensional CTMC which transitions represent slice instantiation and termination, and use it to establish a flexible auction-based slice-admission policy. A four-dimensional CTMC which transitions correspond to establishing and terminating user sessions is proposed in Reference [
17] to analyze the performance of resource allocation to two network slices each offering two GBR services with different priorities.
In this article, we propose a flexible and highly customizable resource slicing scheme that satisfies the important criteria given above—efficient resource usage, fairness and performance isolation of slices. The scheme is intended for a QoS-aware, service-oriented slicing, where each slice is homogeneous with respect to traffic characteristics and QoS requirements. We adopt a hierarchical approach to slicing and focus on the inter-slice allocation, assuming that the intra-slice allocation is performed by slice tenants at their discretion. Overall, our approach and formulation of the inter-slice allocation problem is similar to the one adopted in Reference [
15], however, we consider the performance isolation of slices, by which we understand, in particular, that traffic bursts in one slice do not affect performance and QoS in other slices, or, at least, effects thereof are minimized. A similar concept of performance isolation is adopted in References [
9,
25]. Also, similar to References [
17,
21,
23,
27], we assume user admission control as part of our slicing scheme.
The proposed slicing scheme is formulated in such a way that its efficiency and the impact of its various parameters and customizable components can be readily analyzed via session-level analytical modeling. To this end, we make use of the Markov process theory and develop a multi-class service system with state-dependent preemptive priorities, in which job service rates are found as the solution to a non-linear programming problem. Also, we use the Markovian Arrival Process (MAP, [
35,
36]) for one class of jobs to represent a slice which workload is less regular than that represented by a Poisson process. Being both analytically tractable and highly parametrizable, the MAP allows for applying the matrix-analytic methods and, on the other hand, permits to specify a wide range of arrival processes due to its many independent parameters; moreover, there exist techniques for MAP fitting from real traffic data (see e.g., Reference [
37]). Similar to Reference [
38], we apply matrix-analytic methods to obtain the stationary distribution of the CTMC representing the system and use it to find expressions for performance measures. Finally, we provide a numerical example, where the analytical model serves to compare the proposed policy with the classical resource sharing schemes—complete sharing (CS) and complete partitioning (CP, sometimes referred to as static slicing in the context of network slicing [
20]). An algorithm based upon the Gradient Projection Method [
39] is suggested for solving the arising optimization problem.
The contribution of the article is twofold. First, we propose a new resource slicing scheme, which focuses on flexible performance isolation of slices and fairness, and is customizable to reflect both QoS requirements and SLA terms. Second, the scheme is formalized to allow for session-level stochastic modeling, and in order to evaluate its performance we develop a CTMC model—a multi-class service system with state-dependent preemptive priorities, a MAP and the service rates obtained as a solution to a convex programming problem—for which the stationary state distribution is derived.
The article is structured as follows.
Section 2 introduces the basic model assumptions.
Section 3 details the proposed slicing policy and formalizes its resource allocation and preemption components. In
Section 4, we present a multi-class service system for analyzing the performance of the proposed policy for three active slices. The steady-state distribution of the system is derived and the expressions of its main performance metrics are obtained.
Section 5 offers numerical results, which give an insight into the performance of the proposed slicing policy, in particular, in comparison with CS and CP. Also, an algorithm for solving the optimization problem based upon the Gradient Projection Method is suggested.
Section 6 concludes the article.
2. Basic Assumptions
We consider the downlink transmission from a 4G/5G co-located base station (featuring both LTE and NR radio access technologies) at which radio access resource virtualization and network slicing are implemented [
40]. Note that the proposed approach is applicable to a 5G-only network as well, however, although the network architecture for 5G has not yet been standardized (in contrast to its radio interface), the likely upcoming solution is a full integration with 4G (akin to 2G/GSM or 3G/UMTS). Following Reference [
28], we suppose that the network slicing is performed at the level of virtualized resources. This approach implies the resource allocation among slices/users in terms of virtual resources, which are then translated into network (physical) resources. Generally speaking, the total amount of virtual resources available for allocation depends on the radio conditions for users at each time instant; however, for simplicity, we assume the total base station capacity available for allocation to be fixed.
Suppose that
S slices are active at the base station and denote the set of active slices by
,
. Denote by
the capacity of the base station (measured in bits per second, bps), that is, the total amount of resources available, and by
the capacity of slice
. We assume that each slice is intended for a particular type of traffic, for example, for streaming video, videoconferencing, software updates, and so forth, rather than for a mix of diverse traffic administrated by the same tenant (which may be the case namely in the MVNO scenario). Thus, we assume that each slice
is homogeneous in terms of traffic characteristics and QoS requirements and provides to its users only one service with a data rate not smaller than
(bps) and not larger than
(bps). The lower bound may reflect QoS requirements [
25,
27] and corresponds, for instance, to the data rate necessary for providing a certain maximum tolerable delay [
15], while the upper bound may be due to the characteristics of a particular service, implying that a higher data rate does not improve the associated QoS (the transmission of voice is a good example of a service with such characteristics). Note that we assume all capacity/data rate parameters to be real-valued, that is,
.
Let denote the number of users in slice . We suppose that an effective data rate , , allocated to a slice s user i is variable and depends on the slice’s capacity and the number of users currently in it, since the sum of the users’ data rates cannot exceed the capacity of the slice, that is, . Without loss of generality, we assume further that a slice’s resources are equally shared among all its users, that is, , . Note that the latter assumption serves only to determine the slices’ capacities , , by the slicing scheme detailed in the next session, however, once the capacities established, the actual allocation among users , , is not the subject of this work, and the capacity of a slice can be distributed among its users at the discretion of the slice’s tenant (e.g., in function of the radio channel conditions). Finally, we assume that a user can be active in one slice only and have no more than one active connection in it.
A slicing algorithm implemented at the base station is aimed at proving (a) efficient resource usage, (b) fair resource allocation among users, and (c) performance isolation of slices. Clearly, performance isolation cannot be guaranteed for unlimited traffic in all slices, hence, following Reference [
32], we assume that performance isolation of slice
is provided as long as the number
of users in this slice does not exceed a threshold
,
. Since
, the threshold can be set as a share
of the capacity
C, in which case
,
. Note that we allow for capacity overbooking [
31], and therefore, in the general case,
.
In order to provide flexibility and efficient resource usage, we assume that the booked capacity is not reserved or strictly guaranteed to slice s, but rather slice s has priority in its allocation. Generally speaking, if the base station is fully loaded, the slices in which the number of users is less or equal to have priority in resource allocation over slices in which the number of users is above (or the share of the base station resources occupied by the slice’s users at the minimum data rate is above ).
We suppose that the allocated user data rate is not allowed to drop below , because this results in the violation of the service’s QoS requirements. In order to satisfy the minimum data rate requirements and provide performance isolation, admission control with request prioritization is used as a part of the slicing scheme. We assume that a request arriving to a slice where the number of users is under or equal to , if free resources are not enough, will preempt users in “violator” slices—the slices in which the number of users is above the threshold. We define the proposed slicing scheme formally in the next section.
5. Numerical Results
Suppose that three slices are instantiated at a base station of capacity 40 Mbps. Each slice provides a service that implies transferring files of size 2.5 MB on average with rates no less than 2 Mbps for slice 1 and no less than 1 Mbps for slices 2 and 3. We model this scenario using the service system presented in
Section 4 with the following parameter values:
,
,
,
and
,
. Additionally, we set
for all
and specify the MAP of slice 3 by
The MAP has been chosen so that its fundamental rate equals that of the other two arrival processes, but the variance of the interarrival time is substantially higher—20.875 vs. 3.306.
To obtain the numerical results presented in this section, we used UMFPACK routines for solving the global balance equations (
26), while the optimization problem (
3)–(
5) was solved for
such that
using the Gradient Projection Method via Algorithm 3.
| Algorithm 3: Numerical solution of (3)–(5) using the Gradient Projection Method |
![Mathematics 08 01177 i003]() |
First, we set the booked capacity shares of the slices equal to each other,
,
, and vary
from 0 to 1 with step 0.025 (which yields overbooking for
). The charts in
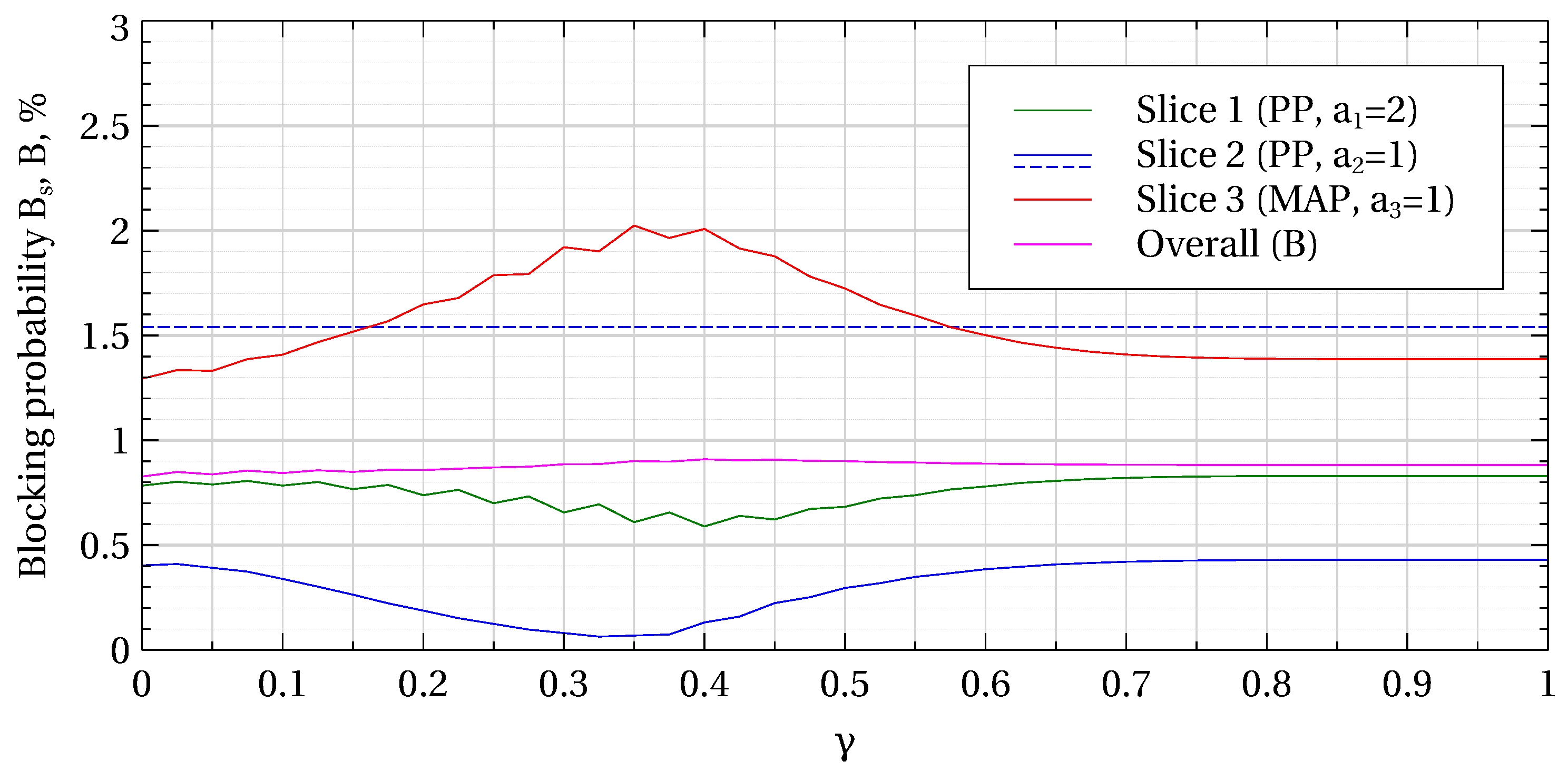
Figure 1,
Figure 2 and
Figure 3 permit to compare the proposed slicing scheme with the CS and CP policies in terms of blocking probabilities (
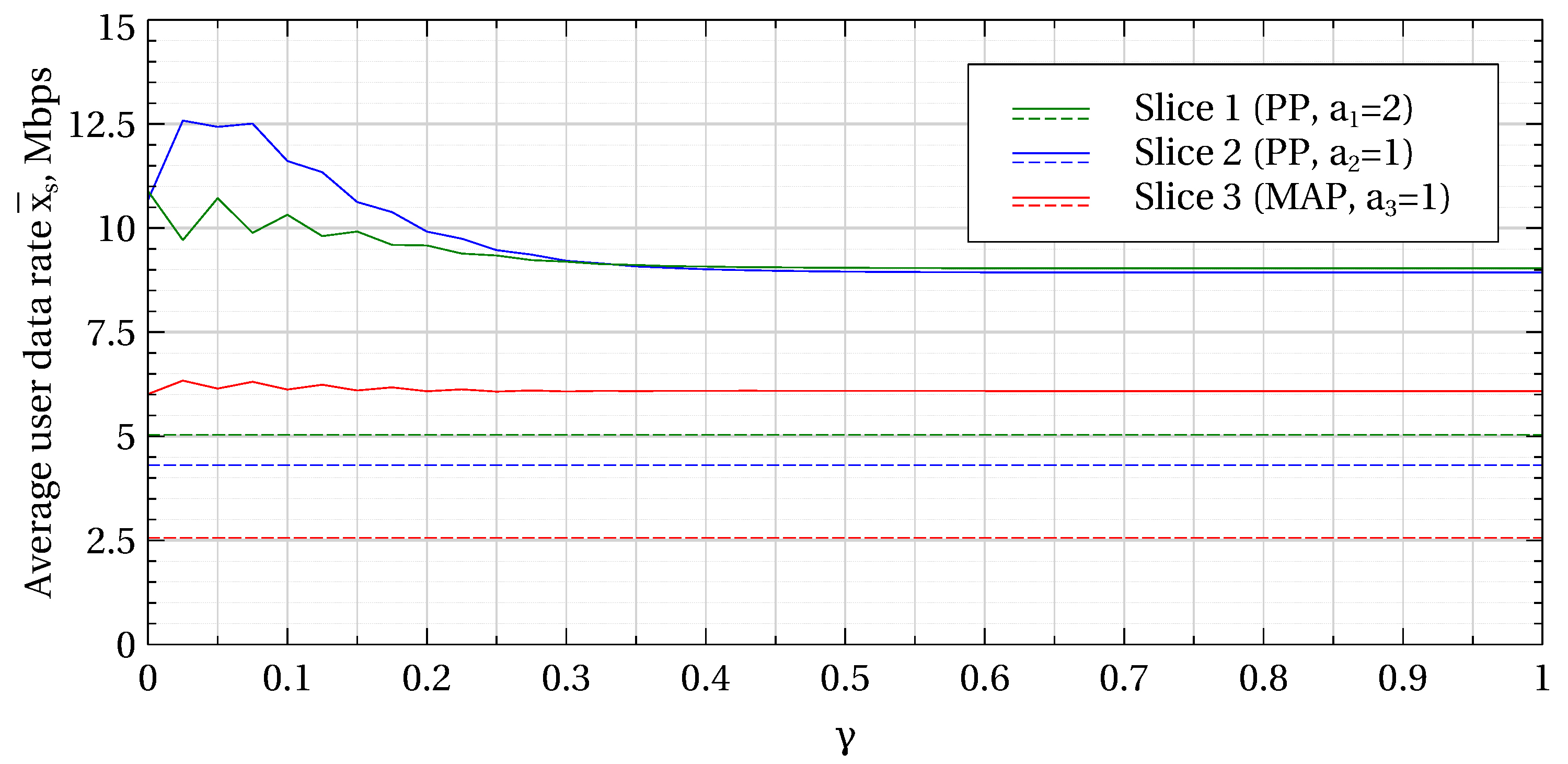
Figure 1) average user data rate (
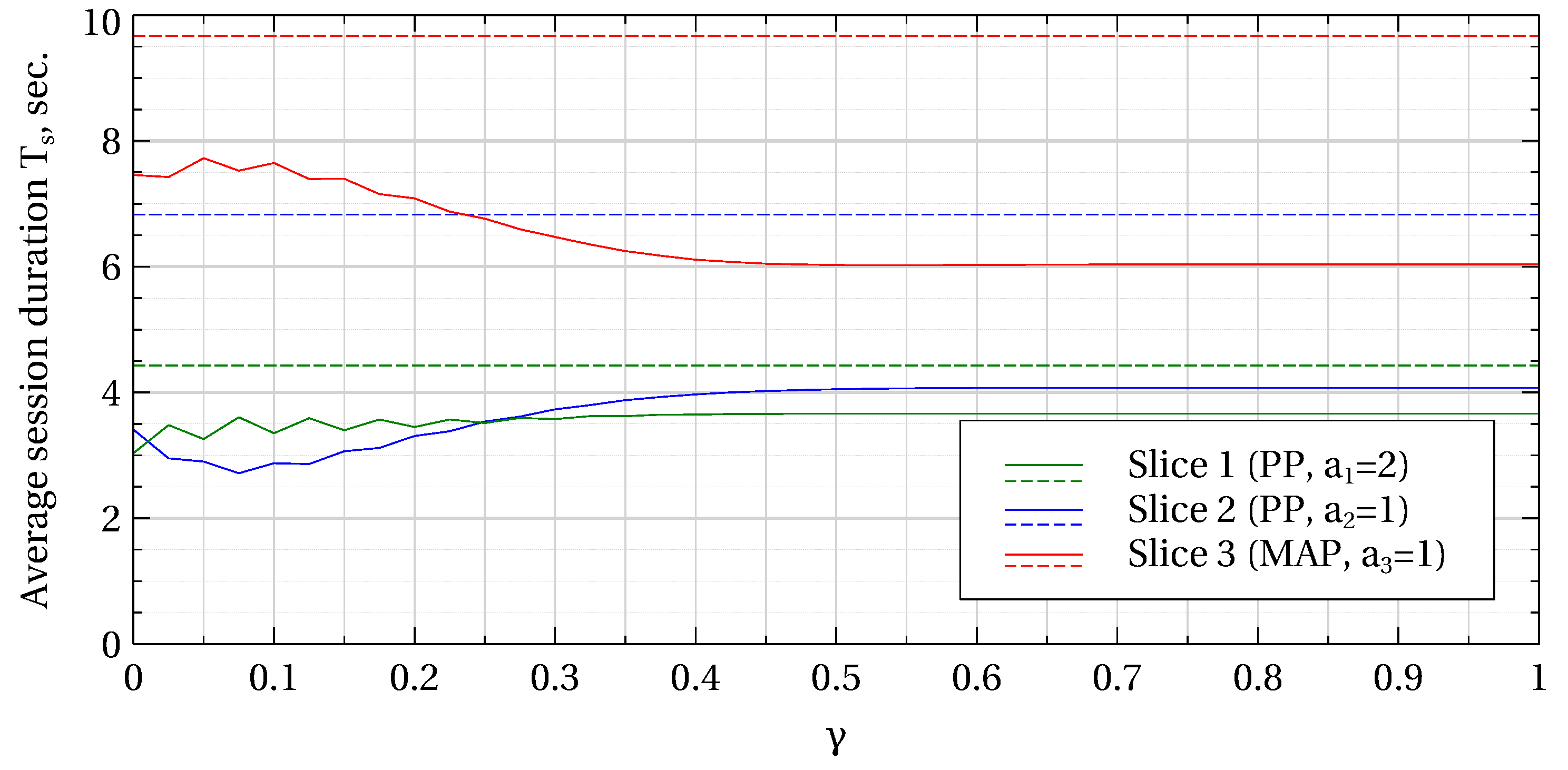
Figure 2) and average user session duration (
Figure 3). Indeed,
corresponds to CS with max–min resource allocation and first-come, first served (FCFS) discipline, since all the weights equal 1 and there are no preemptive priorities among slices. Such CS provides high resource utilization and max–min fair resource allocation to users but no slice isolation. The values of the performance measures under CS are not explicitly indicated in
Figure 1,
Figure 2 and
Figure 3; they can be found on the corresponding curves for the slicing policy for
. The respective performance measures under CP such that the capacity of each slice is fixed and equals exactly
are shown by dashed lines. These values were obtained separately for each slice via the CTMC model of
Section 4 with the rates of the arrival processes corresponding to the other two slices set to zero and the system’s capacity set to
. Note that CP provides perfect slice isolation but may result in poor utilization and fairness.
The zigzag shape of the curves is due to the fact that, as we have stated in
Section 2,
is not used in the slicing scheme directly but through parameter
via the relation
,
. As
grows from 0 to 1,
increases by 1 at
,
, while
increase by 1 at
,
. In particular, this explains that the average user data rate in slice 2 is higher than that in slice 1 for small
(see
Figure 2). Indeed, for
we have
and
, which gives advantage to slices 2 and 3 over slice 1 in resource allocation. This advantage is slightly compensated at
, since here
increases to 1, while
, but becomes important again at
since
is still 1 while
.
Overall, we can see that the proposed slicing scheme leads to a much better network performance compared to the CP policy (static slicing) not only in terms of the blocking probability (which are almost by one order of magnitude greater under CP for all slices), but also when considering average data rate (which are roughly half as large under CP) and average session duration (factors depending on the slices due to their different characteristics). A higher blocking probability in slice 1 compared to slice 2 under CP or CS is due to a higher minimum data rate in slice 1, while an even higher blocking probability in slice 3 stem from the MAP parameters. As expected, the difference in the arrival processes’ characteristics between slices 1 and 2, on the one side, and slice 3, on the other side, clearly determine the behavior of the curves, with
being an obvious turning point.
Figure 1,
Figure 2 and
Figure 3 demonstrate that the slicing policy protects slices 1 and 2 from the irregular slice 3 traffic—for smaller
through resource allocation, and for larger
also through resource preemption. Indeed, for
there is no preemption of resources, but the more users a slice has the less capacity per user it receives. Interestingly, the overall blocking probability for
is slightly lower than for
.
While
Figure 1,
Figure 2 and
Figure 3 give insight into the functioning of the proposed slicing scheme,
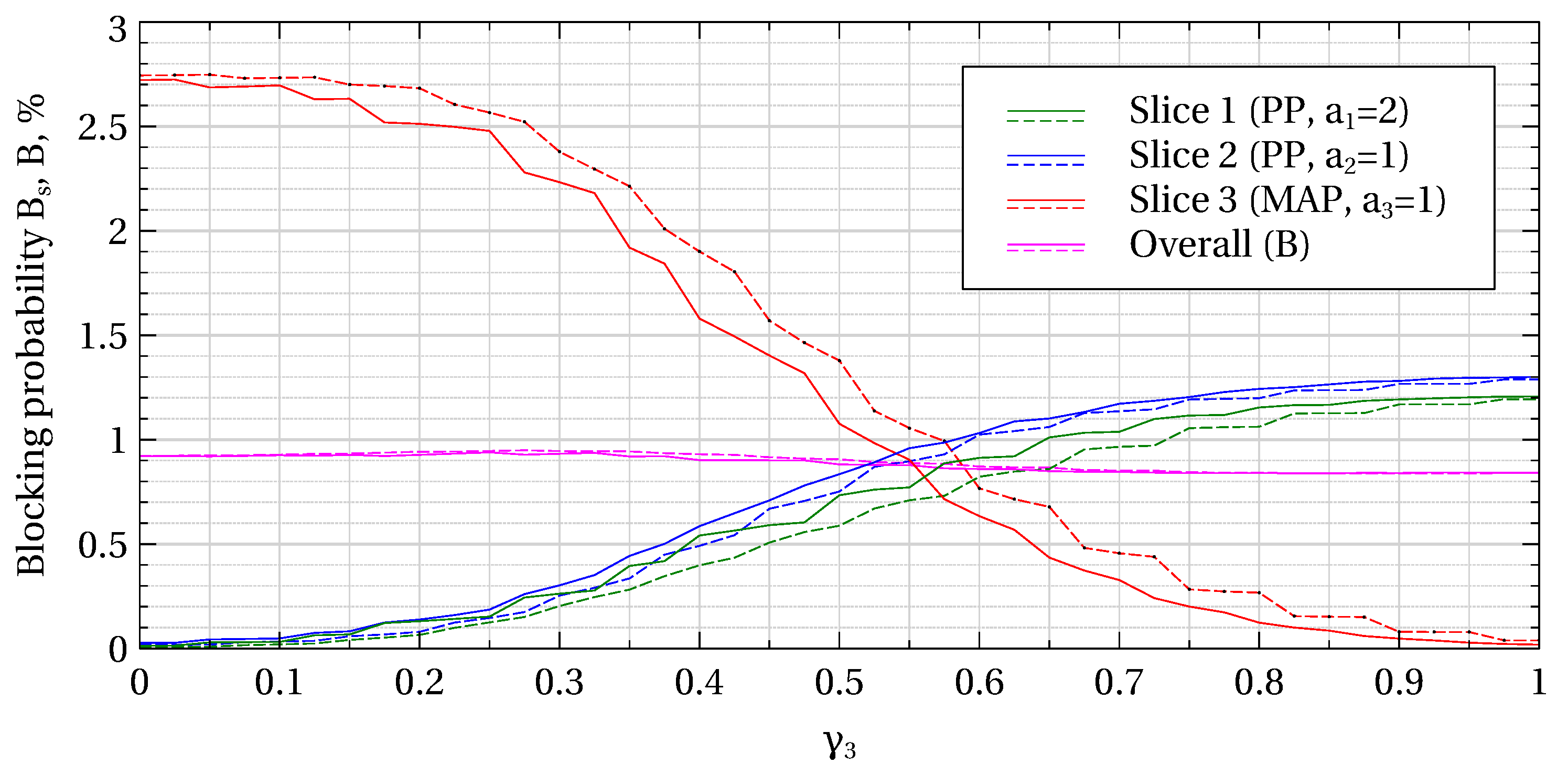
Figure 4,
Figure 5 and
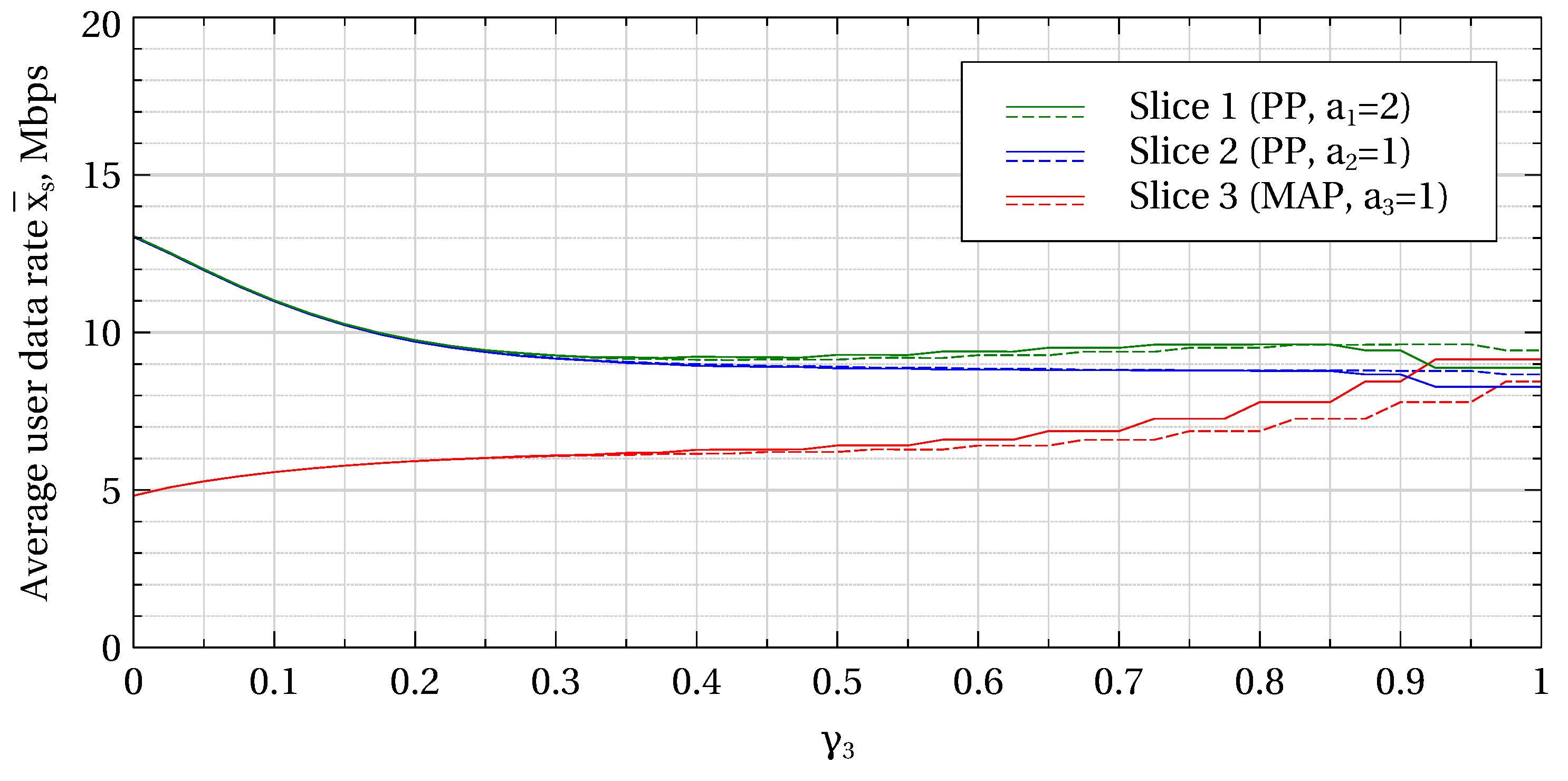
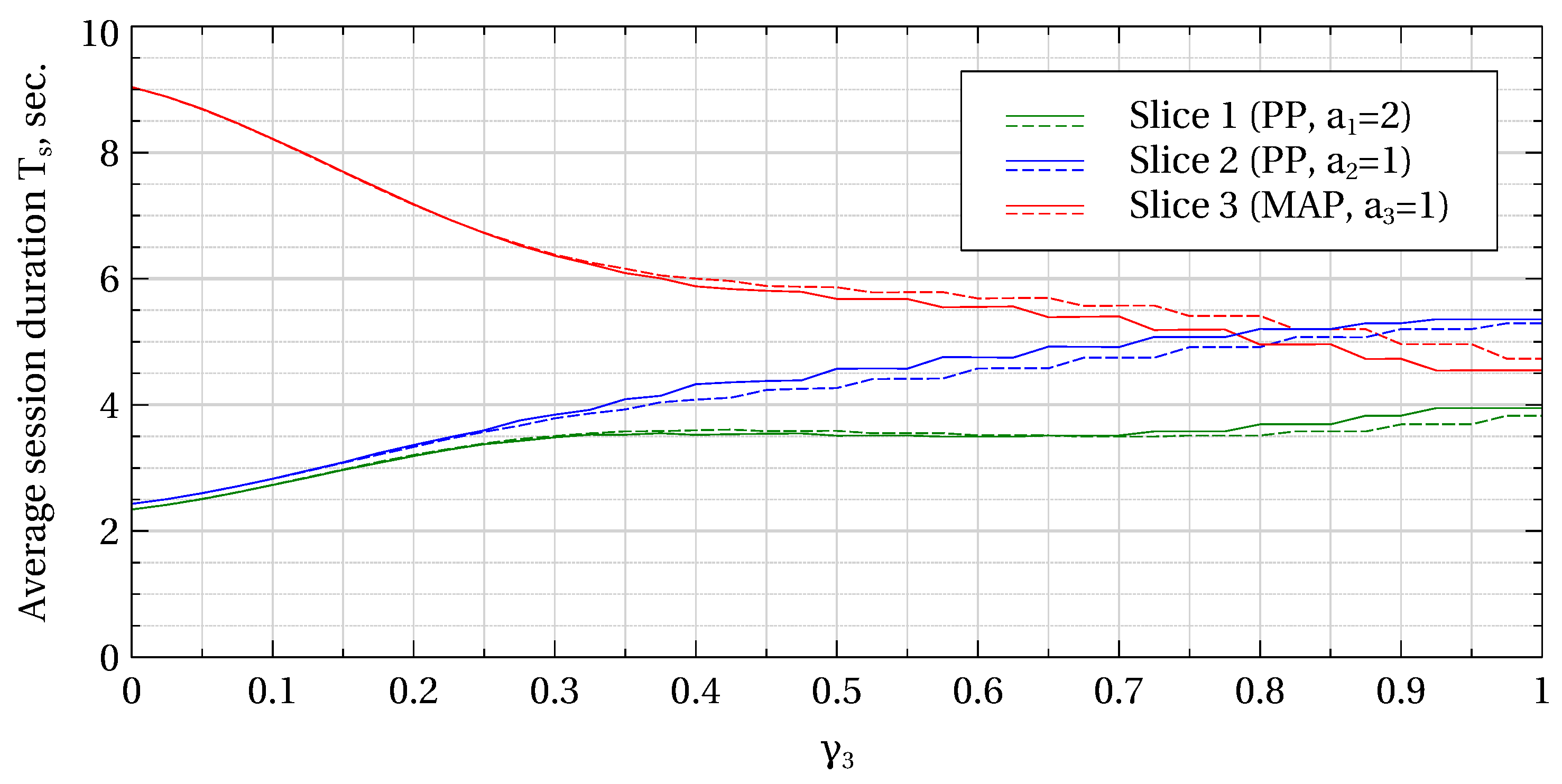
Figure 6 illustrate how the scheme can be used to accommodate slices with different traffic characteristics and balance their performance. Here, the booked capacity share of slice 3,
, is plotted along the abscissa, while the booked capacities of slices 1 and 2 are determined as
,
for fully booked capacity (solid lines) and as
,
for 10% overbooking (dashed lines).
Figure 4,
Figure 5 and
Figure 6 show, respectively, the blocking probabilities, average user data rates the average user session duration as functions of
. As one can see from
Figure 4, by varying
it is possible to protect some slices from the others to a different extent as well as to bring the blocking probability in each slice to the base-station average level. Note that the overall blocking probability is, again, slightly higher on average in the case of overbooking.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








