

Reversible Data Hiding for Color Images Using Channel Reference Mapping and Adaptive Pixel Prediction

Abstract
:1. Introduction
- Most methods are extensions of single-channel RDH approaches and need to adequately consider the correlations among color image channels, resulting in limited improvements in embedding capacity.
- Many approaches rely solely on techniques such as prediction error and PVO for data embedding, failing to leverage the untapped potential of other data hiding spaces within color images, such as color space transformation and color quantization.
- The majority of methods employ fixed pixel prediction strategies and parameter settings without dynamic adjustments based on specific image pixel conditions, leading to an imbalance between embedding capacity and pixel distortion.
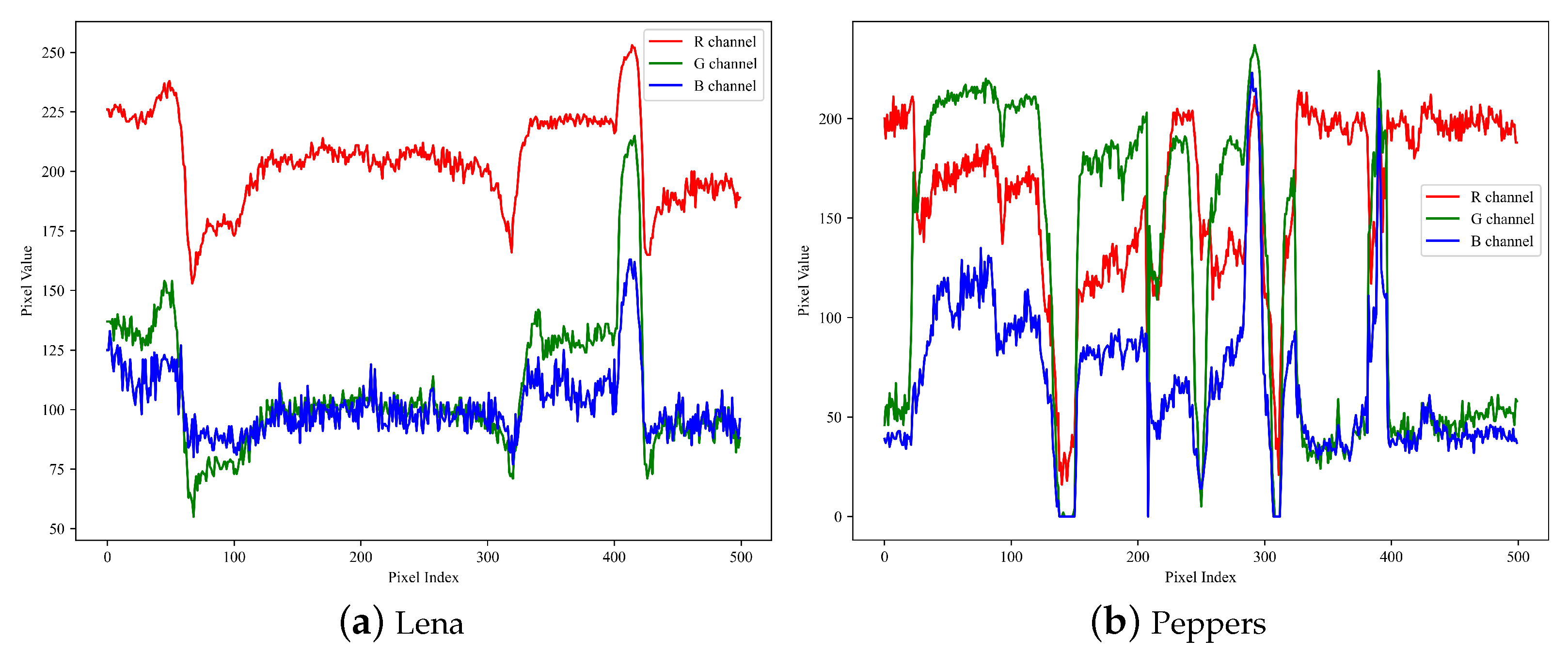
- A novel channel reference mapping (CRM) method is proposed, leveraging trends and correlations among the pixels in the three channels to establish inter-channel reference relationships. These reference relationships are incorporated into pixel-wise local complexity computation and pixel value prediction, thus effectively exploiting the inherent inter-channel connections and reducing pixel distortion during data embedding.
- An adaptive local complexity computation algorithm is proposed. Based on the CRM mode, the current channel’s pixel-wise local complexity computation context is adaptively selected according to the values of reference channel pixels. Adaptive context selection leads to a more accurate assessment of local complexity.
- An adaptive pixel prediction strategy is proposed. By considering each pixel’s neighborhood features and channel characteristics, appropriate predictors and prediction contexts are chosen, thereby enhancing the accuracy of pixel prediction while mitigating image distortion.
2. Related Work
2.1. Local Complexity Calculation Method [21]
2.2. Pixel Prediction Method [19]
3. Proposed Method
3.1. An Overview of the CRM-Based RDH Framework
3.2. Channel Reference Mapping Establishment
| Algorithm 1 CRM establishment algorithm |
| Input: : the pixel values of the RGB channels; , , , , , : six channel reference mapping modes; Output: : the established CRM mode;
|
3.3. Adaptive Local Complexity Calculation
3.4. Adaptive Pixel Prediction
3.5. Data Embedding and Data Extraction
3.6. Implementation of the Proposed CRM-Based Method
4. Experimental Results and Analysis
4.1. Color Image Datasets
4.2. Performance Comparison on Classic Color Images
4.3. Performance Comparison on Kodak Images
4.4. Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, J.C.; Chang, C.C.; Lin, Y.; Chang, C.C.; Horng, J.H. A Matrix Coding-Oriented Reversible Data Hiding Scheme Using Dual Digital Images. Mathematics 2023, 12, 86. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, K. Reversible Data Hiding in Encrypted Images Based on Two-Round Image Interpolation. Mathematics 2023, 12, 32. [Google Scholar] [CrossRef]
- Huang, H.; Cai, Z. Duple Color Image Encryption System Based on 3-D Nonequilateral Arnold Transform for IIoT. IEEE Trans. Ind. Informat. 2023, 19, 8285–8294. [Google Scholar] [CrossRef]
- Xu, X.; Gu, J.; Yan, H.; Liu, W.; Qi, L.; Zhou, X. Reputation-Aware Supplier Assessment for Blockchain-Enabled Supply Chain in Industry 4.0. IEEE Trans. Ind. Informat. 2023, 19, 5485–5494. [Google Scholar] [CrossRef]
- Yuan, X.; Cai, Z. ICHV: A New Compression Approach for Industrial Images. IEEE Trans. Ind. Informat. 2022, 18, 4427–4435. [Google Scholar] [CrossRef]
- Turner, C.J.; Oyekan, J.; Stergioulas, L.; Griffin, D. Utilizing Industry 4.0 on the Construction Site: Challenges and Opportunities. IEEE Trans. Ind. Informat. 2021, 17, 746–756. [Google Scholar] [CrossRef]
- Rathee, G.; Garg, S.; Kaddoum, G.; Choi, B.J.; Hassan, M.M.; AlQahtani, S.A. TrustSys: Trusted Decision Making Scheme for Collaborative Artificial Intelligence of Things. IEEE Trans. Ind. Informat. 2023, 19, 1059–1068. [Google Scholar] [CrossRef]
- Wang, Z.; He, D.; Hou, Y. Data-Driven Adaptive Quality Control Under Uncertain Conditions for a Cyber-Pharmaceutical-Development System. IEEE Trans. Ind. Informat. 2021, 17, 3165–3175. [Google Scholar] [CrossRef]
- Tang, P.; Peng, K.; Chen, Z.; Dong, J. A Novel Distributed CVRAE-Based Spatio-Temporal Process Monitoring Method With Its Application. IEEE Trans. Ind. Informat. 2023, 19, 10987–10997. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Xiao, M.; Zhao, Y.; Cho, H. High-Quality Reversible Data Hiding Based on Multi-Embedding for Binary Images. Mathematics 2023, 11, 4111. [Google Scholar] [CrossRef]
- Ren, F.; Wu, Z.; Xue, Y.; Hao, Y. Reversible Data Hiding in Encrypted Image Based on Bit-Plane Redundancy of Prediction Error. Mathematics 2023, 11, 2537. [Google Scholar] [CrossRef]
- Huang, C.T.; Weng, C.Y.; Shongwe, N.S. Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images. Mathematics 2023, 11, 1764. [Google Scholar] [CrossRef]
- Kong, X.; Cai, Z. An Information Security Method Based on Optimized High-Fidelity Reversible Data Hiding. IEEE Trans. Ind. Informat. 2022, 18, 8529–8539. [Google Scholar] [CrossRef]
- Celik, M.; Sharma, G.; Tekalp, A.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef] [PubMed]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar] [CrossRef]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef]
- Li, X.; Yang, B.; Zeng, T. Efficient Reversible Watermarking Based on Adaptive Prediction-Error Expansion and Pixel Selection. IEEE Trans. Image Process. 2011, 20, 3524–3533. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.J.; Chung, K.L.; Liao, H.Y.M. Efficient reversible data hiding for color filter array images. Inf. Sci. 2012, 190, 208–226. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Yang, B. Reversible data hiding scheme for color image based on prediction-error expansion and cross-channel correlation. Signal Process. 2013, 93, 2748–2758. [Google Scholar] [CrossRef]
- Yao, H.; Qin, C.; Tang, Z.; Tian, Y. Guided filtering based color image reversible data hiding. J. Vis. Commun. Image Represent. 2017, 43, 152–163. [Google Scholar] [CrossRef]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R. Efficient color image reversible data hiding based on channel-dependent payload partition and adaptive embedding. Signal Process. 2015, 108, 642–657. [Google Scholar] [CrossRef]
- Hou, D.; Zhang, W.; Chen, K.; Lin, S.J.; Yu, N. Reversible Data Hiding in Color Image With Grayscale Invariance. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 363–374. [Google Scholar] [CrossRef]
- Chang, Q.; Li, X.; Zhao, Y. Reversible Data Hiding for Color Images Based on Adaptive Three-Dimensional Histogram Modification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5725–5735. [Google Scholar] [CrossRef]
- Kong, Y.; Ke, Y.; Zhang, M.; Su, T.; Ge, Y.; Yang, S. Reversible Data Hiding Based on Multichannel Difference Value Ordering for Color Images. Secur. Commun. Netw. 2022, 2022, 3864480. [Google Scholar] [CrossRef]
- Mao, N.; He, H.; Chen, F.; Zhu, K. Reversible data hiding of color image based on channel unity embedding. Appl. Intell. 2023, 53, 21347–21361. [Google Scholar] [CrossRef]
- Bhatnagar, P.; Tomar, P.; Naagar, R.; Kumar, R. Reversible Data Hiding scheme for color images based on skewed histograms and cross-channel correlation. In Proceedings of the 2023 International Conference in Advances in Power, Signal, and Information Technology (APSIT), Bhubaneswar, India, 9–11 June 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, N.; Jung, K.H. Color image steganography scheme using gray invariant in AMBTC compression domain. Multidimens. Syst. Signal Process. 2020, 31, 1145–1162. [Google Scholar] [CrossRef]
- Kumar, R.; Sharma, D.; Dua, A.; Jung, K.H. A review of different prediction methods for reversible data hiding. J. Inf. Secur. Appl. 2023, 78, 103572. [Google Scholar] [CrossRef]
- Qu, X.; Kim, H.J. Pixel-based pixel value ordering predictor for high-fidelity reversible data hiding. Signal Process. 2015, 111, 249–260. [Google Scholar] [CrossRef]
- Yang, Y.; Zou, T.; Huang, G.; Zhang, W. A High Visual Quality Color Image Reversible Data Hiding Scheme Based on B-R-G Embedding Principle and CIEDE2000 Assessment Metric. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1860–1874. [Google Scholar] [CrossRef]
- Mao, N.; He, H.; Chen, F.; Qu, L.; Amirpour, H.; Timmerer, C. Reversible data hiding for color images based on pixel value order of overall process channel. Signal Process. 2023, 205, 108865. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | CDPP | GF-CI | GI-CI | BRG-EP | ATDHM | OPC-PVO | Proposed |
|---|---|---|---|---|---|---|---|
| Lena | 60.58 | 62.15 | 48.85 | 51.08 | 61.58 | 62.33 | 62.62 |
| Airplane | 64.72 | 65.36 | 55.58 | 60.49 | 65.48 | 64.71 | 65.74 |
| Lake | 60.34 | 62.68 | 50.58 | 57.29 | 62.72 | 62.76 | 62.92 |
| Peppers | 57.10 | 58.23 | 46.12 | 50.54 | 57.79 | 62.50 | 59.91 |
| Splash | 62.28 | 62.15 | 54.96 | 58.93 | 63.21 | 64.36 | 63.50 |
| House | 66.01 | 65.96 | 58.46 | 64.10 | 66.72 | 64.05 | 66.97 |
| Average | 61.84 | 62.76 | 52.43 | 57.07 | 62.92 | 63.45 | 63.61 |
| Image | CDPP | GF-CI | GI-CI | BRG-EP | ATDHM | OPC-PVO | Proposed |
|---|---|---|---|---|---|---|---|
| Lena | 57.85 | 59.24 | 46.14 | 48.23 | 58.96 | 59.18 | 59.31 |
| Airplane | 61.87 | 62.35 | 53.05 | 57.18 | 62.54 | 62.34 | 62.58 |
| Lake | 56.46 | 58.65 | 46.47 | 52.34 | 58.03 | 58.72 | 58.89 |
| Peppers | 54.64 | 55.66 | 43.45 | 47.68 | 55.44 | 58.27 | 56.87 |
| Splash | 60.15 | 60.52 | 52.14 | 55.89 | 60.18 | 61.82 | 61.16 |
| House | 63.29 | 63.24 | 54.28 | 60.03 | 64.09 | 61.75 | 64.35 |
| Average | 59.04 | 59.94 | 49.26 | 53.56 | 59.87 | 60.35 | 60.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, D.; Cai, Z. Reversible Data Hiding for Color Images Using Channel Reference Mapping and Adaptive Pixel Prediction. Mathematics 2024, 12, 517. https://doi.org/10.3390/math12040517
He D, Cai Z. Reversible Data Hiding for Color Images Using Channel Reference Mapping and Adaptive Pixel Prediction. Mathematics. 2024; 12(4):517. https://doi.org/10.3390/math12040517
Chicago/Turabian StyleHe, Dan, and Zhanchuan Cai. 2024. "Reversible Data Hiding for Color Images Using Channel Reference Mapping and Adaptive Pixel Prediction" Mathematics 12, no. 4: 517. https://doi.org/10.3390/math12040517