In order to consider the proposed modification from different points, in the following subsections, several aspects were considered, including the effects of SR-based adaptation on the performance of different existing algorithms when success history-based adaptation is replaced; the influence of the available computational resource and mutation strategies; comparison with the best methods on two sets of benchmark functions. Also, a visualization of the parameter adaptation process was considered for a better understanding of the effects on the differential evolution algorithm.
4.2.1. Modification of Existing Algorithms
As was mentioned above, the success rate-based adaptation for F replaced the success history adaptation in four tested algorithms. As for the crossover rate adaptation, it was unchanged. In the case of the L-SHADE-RSP algorithm, which uses a specific mutation strategy with F and , when using the success rate, was set equal to F, and specific rules based on the current resource from jSO algorithm were removed. The parameters for all the algorithms were set according to those used in corresponding papers.
The majority of modern DE algorithms rely on the success history adaptation method introduced in SHADE, so the purpose of the study was to compare the adaptation methods, and not specific algorithms. For this purpose, in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10, we modified L-SHADE-RSP, NL-SHADE-RSP, NL-SHADE-LBC, L-NTADE, jSO, LSHADE-SPACMA, APGSK-IMODE, MLS-LSHADE and MadDE with success rate-based adaptation and compared the results.
Table 1 and
Table 2 present the comparison of the original L-SHADE-RSP with the modified L-SHADE-RSP (SR) with different
c values. Each cell in the tables contains the number of wins/ties/losses and the total standard score in brackets. Larger standard score means that the modified algorithm is better.
As can be seen from
Table 1 and
Table 2, the
c parameter significantly influences performance, and if for CEC 2017
, i.e.,
, is a bad choice; for CEC 2022 it is a reasonable setting for
. The setting which leads to good performance is
for CEC 2017. In this case, for
,
and
, there are more improvements than losses, but for
the success history adaptation works better. In the case of the CEC 2022 benchmark, the best choice is
.
In
Table 3 and
Table 4, the comparison of the basic NL-SHADE-RSP and the modified NL-SHADE-RSP (SR) is presented.
Table 3.
NL-SHADE-RSP (SR) vs. NL-SHADE-RSP, CEC 2017.
Table 3.
NL-SHADE-RSP (SR) vs. NL-SHADE-RSP, CEC 2017.
| c | | | | |
|---|
| 1 | 0/13/17 (−77.34) | 1/6/23 (−134.10) | 1/9/20 (−128.17) | 6/6/18 (−91.88) |
| 2 | 0/25/5 (−18.32) | 7/21/2 (17.65) | 14/13/3 (45.81) | 20/6/4 (89.04) |
| 3 | 2/27/1 (8.46) | 14/14/2 (64.24) | 15/13/2 (100.78) | 22/7/1 (134.60) |
| 4 | 7/22/1 (28.38) | 15/14/1 (81.37) | 17/11/2 (111.83) | 22/6/2 (141.35) |
| 5 | 8/21/1 (33.83) | 16/13/1 (73.35) | 18/10/2 (111.43) | 21/7/2 (139.24) |
| 6 | 6/24/0 (29.73) | 13/14/3 (66.20) | 17/11/2 (111.59) | 22/5/3 (135.73) |
Table 4.
NL-SHADE-RSP (SR) vs. NL-SHADE-RSP, CEC 2022.
Table 4.
NL-SHADE-RSP (SR) vs. NL-SHADE-RSP, CEC 2022.
| c | | |
|---|
| 1 | 4/4/4 (2.46) | 0/6/6 (−39.78) |
| 2 | 5/6/1 (14.26) | 1/8/3 (−8.21) |
| 3 | 6/2/4 (14.37) | 5/4/3 (5.05) |
| 4 | 6/2/4 (8.26) | 5/3/4 (4.18) |
| 5 | 5/3/4 (9.20) | 5/3/4 (6.02) |
| 6 | 6/2/4 (11.19) | 5/4/3 (8.10) |
The situation with NL-SHADE-RSP is quite different as this method was not tuned for CEC 2017 or CEC 2022. Nevertheless, small values of the c parameter lead to poor performance on both benchmarks, and increasing c up to 3 or 4 produces much better results. After , performance gains become smaller.
Table 5 and
Table 6 show the results of NL-SHADE-LBC and its modified version.
Table 5.
NL-SHADE-LBC (SR) vs. NL-SHADE-LBC, CEC 2017.
Table 5.
NL-SHADE-LBC (SR) vs. NL-SHADE-LBC, CEC 2017.
| c | | | | |
|---|
| 1 | 0/17/13 (−63.46) | 2/8/20 (−138.49) | 5/8/17 (−103.11) | 7/4/19 (−108.71) |
| 2 | 2/24/4 (−13.13) | 7/13/10 (−15.57) | 18/3/9 (62.92) | 16/8/6 (63.66) |
| 3 | 4/24/2 (21.91) | 14/12/4 (73.17) | 23/6/1 (161.08) | 23/5/2 (161.72) |
| 4 | 8/21/1 (40.55) | 16/13/1 (97.39) | 25/4/1 (185.04) | 25/5/0 (190.54) |
| 5 | 10/20/0 (53.79) | 16/13/1 (106.44) | 25/5/0 (186.03) | 27/3/0 (199.10) |
| 6 | 10/20/0 (56.07) | 17/12/1 (106.95) | 25/4/1 (176.66) | 26/4/0 (193.90) |
Table 6.
NL-SHADE-LBC (SR) vs. NL-SHADE-LBC, CEC 2022.
Table 6.
NL-SHADE-LBC (SR) vs. NL-SHADE-LBC, CEC 2022.
| c | | |
|---|
| 1 | 6/3/3 (26.91) | 3/3/6 (−19.44) |
| 2 | 2/3/7 (−23.34) | 1/4/7 (−37.09) |
| 3 | 3/2/7 (−25.30) | 2/5/5 (−20.46) |
| 4 | 2/3/7 (−26.51) | 3/4/5 (−17.18) |
| 5 | 2/3/7 (−28.37) | 3/4/5 (−20.26) |
| 6 | 2/3/7 (−28.53) | 3/4/5 (−18.72) |
As can be seen from
Table 5 and
Table 6, the situation with NL-SHADE-LBC is quite different. As this method was specifically developed for the CEC 2022 benchmark, its parameter adaptation was not tuned for the CEC 2017 benchmark, and applying success rate-based adaptation significantly improves results, with up to 27 improvements out of 30 functions in
. However, for CEC 2022, the success rate adaptation was not able to deliver better performance, but still
or higher is a reasonable choice for both benchmarks. The reason why SR-based adaptation worked worse with NL-SHADE-LBC is that the parameter adaptation of this algorithm was specifically tuned for the CEC 2022 benchmark.
Table 7 and
Table 8 contain the results of the L-NTADE algorithm and its modification.
Table 7.
L-NTADE (SR) vs. L-NTADE, CEC 2017.
Table 7.
L-NTADE (SR) vs. L-NTADE, CEC 2017.
| c | | | | |
|---|
| 1 | 2/10/18 (−105.68) | 0/8/22 (−192.68) | 0/4/26 (−218.98) | 1/2/27 (−219.12) |
| 2 | 6/15/9 (−11.94) | 3/14/13 (−65.01) | 4/8/18 (−108.84) | 5/3/22 (−124.60) |
| 3 | 9/15/6 (22.08) | 12/15/3 (43.24) | 8/17/5 (19.67) | 8/9/13 (−6.39) |
| 4 | 11/14/5 (37.30) | 14/15/1 (75.39) | 15/11/4 (69.26) | 15/11/4 (70.63) |
| 5 | 10/16/4 (44.53) | 14/15/1 (73.95) | 17/10/3 (67.77) | 15/11/4 (65.51) |
| 6 | 11/17/2 (36.40) | 9/19/2 (48.88) | 13/11/6 (25.88) | 11/12/7 (24.52) |
Table 8.
L-NTADE (SR) vs. L-NTADE, CEC 2022.
Table 8.
L-NTADE (SR) vs. L-NTADE, CEC 2022.
| c | | |
|---|
| 1 | 5/3/4 (11.08) | 3/2/7 (−22.99) |
| 2 | 6/4/2 (25.53) | 3/3/6 (−6.99) |
| 3 | 6/4/2 (25.45) | 3/5/4 (1.07) |
| 4 | 5/5/2 (26.17) | 2/6/4 (−1.82) |
| 5 | 3/8/1 (13.29) | 2/6/4 (−10.64) |
| 6 | 2/6/4 (−10.49) | 2/7/3 (−12.62) |
Although L-NTADE has two populations and has a different algorithmic scheme, applying success rate-based adaptation improved the results in both benchmarks. As before, small c values are inefficient. However, setting for CEC 2017 or probably even larger values offers significant performance benefits.
In order to test the applicability of the proposed approach to other algorithms, several of them for which the source codes were available were modified and the modifications were compared to the original results. For the CEC 2017 benchmark, in the jSO (derived from L-SHADE) [
25], the mutation step, which uses two factors,
F and
, was modified to have only a single one, and the control rules for
F were deactivated. For LSHADE-SPACMA [
35], the scaling factor sampling in the DE part was replaced by Equation (19). The comparison is shown in
Table 9.
Table 9.
Comparison of other modified approach vs. original versions, CEC 2017.
Table 9.
Comparison of other modified approach vs. original versions, CEC 2017.
| Algorithm | | | | |
|---|
| jSO (SR, ) vs. | 1/21/8 | 8/16/6 | 6/14/10 | 11/9/10 |
| jSO [25] | (−37.08) | (21.04) | (−25.27) | (−2.29) |
| LSHADE-SPACMA (SR, ) vs. | 3/22/5 | 1/24/5 | 0/22/8 | 0/23/7 |
| LSHADE-SPACMA [35] | (−22.61) | (−41.67) | (−64.32) | (−42.11) |
As can be seen from
Table 9, the modification of jSO with
may be beneficial in some cases, for example, in the 30D scenario, but in 10D the number of losses was much larger than the number of wins. As for LSHADE-SPACMA, using success rate-based adaptation leads to decreased performance. The main reason why SR-based adaptation failed to improve the performance in these cases could be that both jSO and LSHADE-SPACMA were specifically tuned for the CEC 2017 benchmark, and the SR-based adaptation is a more general approach, which was not tuned for these particular algorithms.
In
Table 10, the same modification was applied to APGSK-IMODE (only in IMODE part) [
36], MLS-LSHADE [
37] and MadDE [
38]. Due to a simpler benchmark in terms of computation time, the experiments were performed with different
c values.
Table 10.
Comparison of other modified approaches vs. original versions, CEC 2022.
Table 10.
Comparison of other modified approaches vs. original versions, CEC 2022.
| Algorithm | | |
|---|
| APGSK-IMODE (SR, ) vs. | 4/5/3 | 1/5/6 |
| APGSK-IMODE [36] | (3.66) | (−24.33) |
| APGSK-IMODE (SR, ) vs. | 4/4/4 | 1/8/3 |
| APGSK-IMODE [36] | (12.88) | (−14.19) |
| APGSK-IMODE (SR, ) vs. | 3/4/5 | 1/8/3 |
| APGSK-IMODE [36] | (−8.81) | (−12.24) |
| APGSK-IMODE (SR, ) vs. | 3/4/5 | 1/8/3 |
| APGSK-IMODE [36] | (−8.81) | (−12.24) |
| MLS-LSHADE (SR, ) vs. | 4/3/5 | 0/4/8 |
| MLS-LSHADE [37] | (−2.05) | (−49.53) |
| MLS-LSHADE (SR, ) vs. | 2/3/7 | 0/6/6 |
| MLS-LSHADE [37] | (−29.50) | (−41.34) |
| MLS-LSHADE (SR, ) vs. | 3/1/8 | 0/5/7 |
| MLS-LSHADE [37] | (−32.78) | (−41.91) |
| MLS-LSHADE (SR, ) vs. | 1/3/8 | 0/5/7 |
| MLS-LSHADE [37] | (−37.41) | (−40.96) |
| MadDE (SR, ) vs. | 5/4/3 | 2/6/4 |
| MadDE [38] | (12.46) | (−9.56) |
| MadDE (SR, ) vs. | 4/5/3 | 3/8/1 |
| MadDE [38] | (14.78) | (13.48) |
| MadDE (SR, ) vs. | 4/5/3 | 3/8/1 |
| MadDE [38] | (13.10) | (15.39) |
| MadDE (SR, ) vs. | 3/6/3 | 3/6/3 |
| MadDE [38] | (4.88) | (0.68) |
The effect of success rate-based scaling factor adaptation is different for different algorithms. For example, the performance of APGSK-IMODE was improved only in the 10D case, with and , but for MLS-LSHADE the effect was mainly negative. As for the MadDE algorithm, it was mostly improved by the modification, especially for and .
4.2.4. Success Rate-Based Adaptation with Different Mutation Strategies
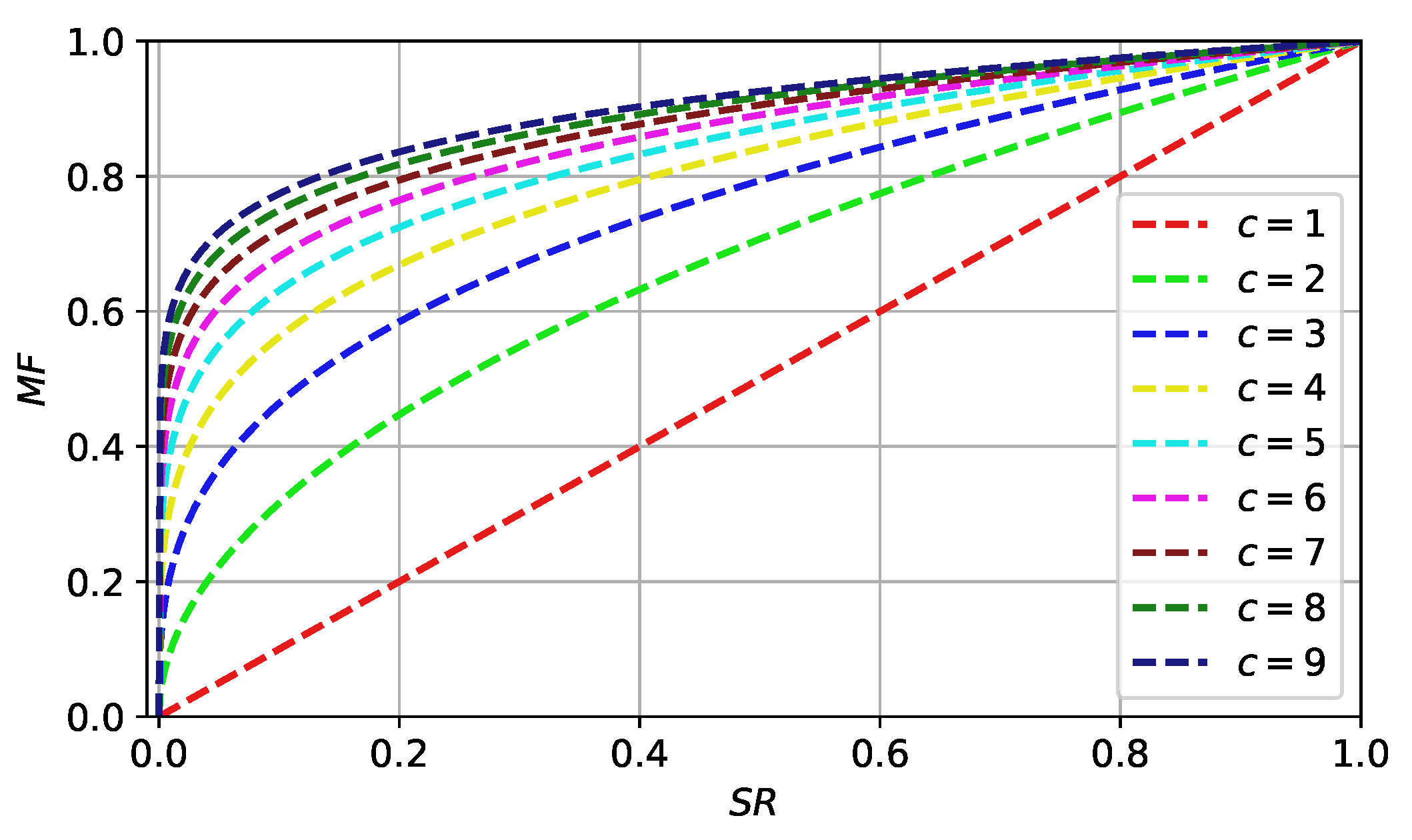
One of the possible explanations of the high performance of success rate-based adaptation for
F could be that it works in combination with the current-to-pbest strategy. If the success rate is low, smaller
F values force more exploration, while
F closer to 1 leads to a move towards one of the
best solutions. To test this effect of success rate-based adaptation, a set of experiments was performed on the standard L-SHADE algorithm with different mutation strategies, such as rand/1, rand/2, current-to-best/1, current-to-rand/1, best/1 and best/2. The
c parameter was also altered from 1 to 6, and the original L-SHADE was tested. Next, the Friedman ranking procedure was applied to compare the performance of SHA with SR. The ranks were assigned for each mutation strategy (column) independently. The experiments were repeated for both CEC 2017 and CEC 2022 benchmarks. The parameters of L-SHADE were the following:
,
,
, initial
,
, archive was not used.
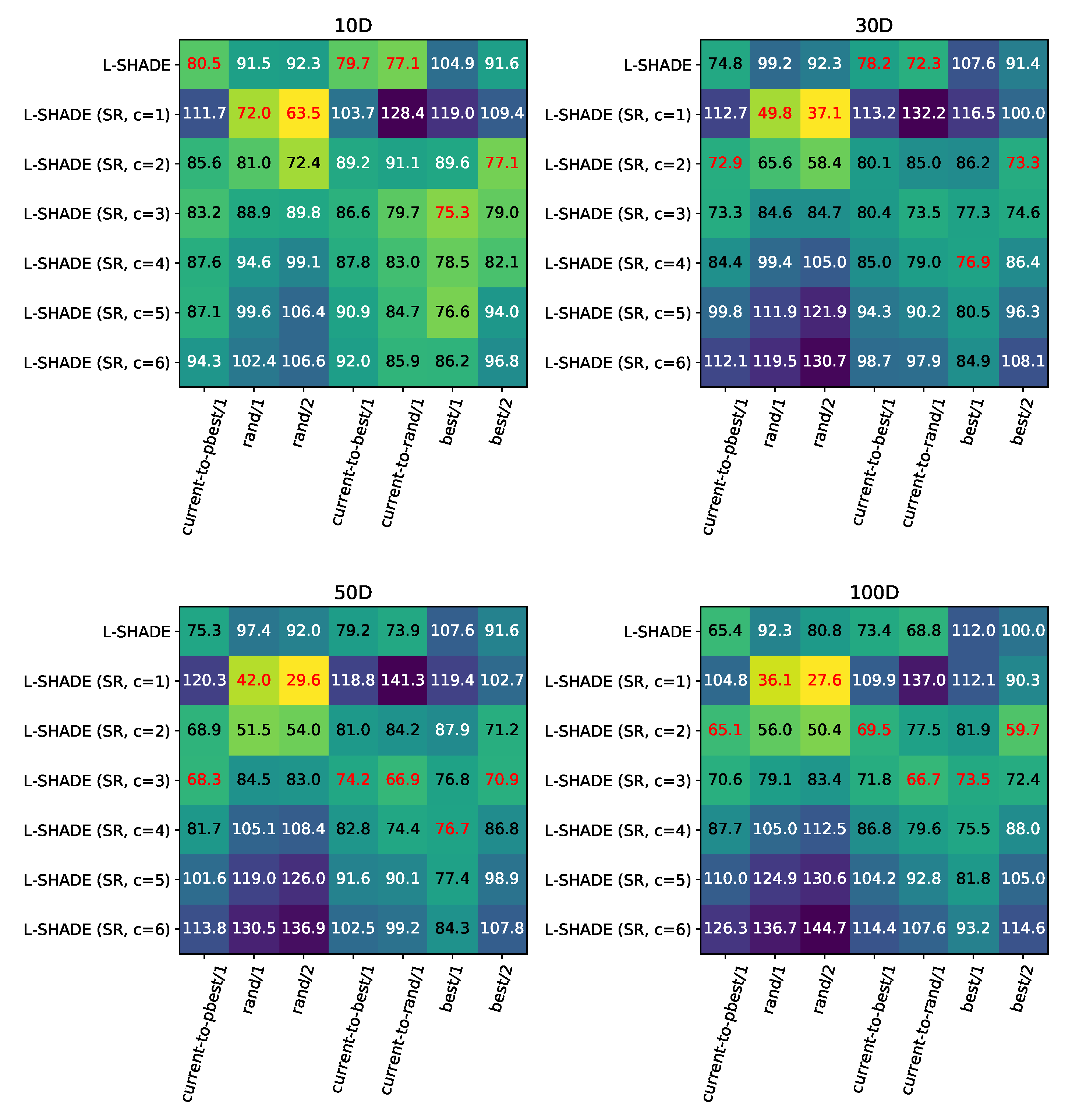
Figure 6 and
Figure 7 contain the heatmaps of the comparison.
The heatmaps for the CEC 2017 benchmark show that in low-dimensional cases like 10D and 30D, the SHA may perform better than SR, but only for current-to-pbest/1, current-to-best/1 and current-to-rand/1. As for the other strategies, rand/1 and rand/2 performed much better with the modified approach, and so did best/1 and best/2, although the difference here was smaller. In high-dimensional cases, SR is always performing better, especially when the rand/2 strategy is used. Different strategies prefer different c values; for example, rand/1 and rand/2 only use , i.e., linear dependence. In fact, this means that the success rate is used directly. Other strategies, such as best/1 and best/2, prefer , or , but this value is always smaller for best/2 compared to best/1. The same is true when comparing rand/1 and rand/2: the effect of smaller c values is larger in the case of rand/2. The current-to-best and current-to-rand strategies are similar to current-to-pbest ones, and the best settings for them are close. The comparison on CEC 2022 demonstrates the same trends, but in general smaller c values are preferred for all strategies except current-to-rand ones. Also, on this benchmark, the SHA is never the best choice.
To compare different strategies with current-to-pbest, the best performing ones from every dimension and every benchmark were chosen and compared to current-to-pbest with SR. The standard SHA was not considered here. The Mann–Whitney statistical tests for both benchmarks are shown in
Table 11 and
Table 12.
In the case of the CEC 2017 benchmark in
Table 11, the current-to-pbest strategy dominates other strategies in terms of performance in all cases. However, the closest competitor is the current-to-best which performed similar in the 50D case, which might indicate a non-optimal choice of the
parameter for current-to-best. As for the results on CEC 2022, the current-to-pbest outperformed most of the strategies but the current-to-best had several wins in both the 10D and 30D cases. Also, the rand/1 strategy has shown some competitive performance in 20D, as well as best/2 in 10D. Considering the improvements that success rate-based adaptation was able to deliver for these strategies compared to success history adaptation (
Figure 6 and
Figure 7), one may conclude that SR can be efficiently applied to other strategies, and even make them competitive.
4.2.5. Comparison with Alternative Approaches
Table 13,
Table 14 and
Table 15 contain the comparison of the L-NTADE (SR) algorithm with
to other modern DE algorithms on the CEC 2017 benchmark, and
Table 16,
Table 17 and
Table 18 on the CEC 2022 benchmark.
Table 13 shows the results of Mann–Whitney statistical tests,
Table 14 contains the Friedman ranking results, the ranking that is used in a Friedman statistical test to compare several sets of measurements; smaller total ranks are better.
Table 15 shows the recently proposed U-scores [
39].
Table 16,
Table 17 and
Table 18 contain the same results for CEC 2022. The U-scores represent a trial-based dominance method for comparing several optimization methods using Mann–Whitney U tests. For CEC 2017, the convergence speed is not taken into consideration, while for CEC 2022 the number of function evaluations to reach the desired accuracy is considered.
As can be seen from
Table 13, the L-NTADE algorithm with success rate-based adaptation is able to outperform most of the alternative algorithms in both benchmarks. EBOwithCMAR performed better in the 10D case, and LSHADE-SPACMA showed comparable in the 100D case.
Table 14 supports these results, ranking L-NTADE with
the best algorithm overall, and even the standard L-NTADE is very competitive. In
Table 15, the comparison yields similar results, and L-NTADE with
ranks first, followed by LSHADE-SPACMA and L-NTADE.
Table 15.
L-NTADE (SR) vs. alternative approaches, U-scores. Larger ranks are better [
39], CEC 2017.
Table 15.
L-NTADE (SR) vs. alternative approaches, U-scores. Larger ranks are better [
39], CEC 2017.
| Algorithm | | | - |
|---|
| LSHADE-SPACMA [35] | 263,193 | 293,839.5 | - |
| jSO [25] | 272,469 | 282,122.5 | - |
| EBOwithCMAR [40] | 322,146.5 | 303,458.5 | - |
| L-SHADE-RSP [9] | 276,570.5 | 296,012 | - |
| NL-SHADE-RSP [10] | 244,170 | 112,109 | - |
| NL-SHADE-LBC [11] | 276,146 | 161,327 | - |
| L-NTADE [12] | 248,186 | 336,712.5 | - |
| L-NTADE (SR, ) | 281,959 | 399,259 | - |
| Algorithm | | | Total |
| LSHADE-SPACMA [35] | 364,005.5 | 404,653 | 1,325,691 |
| jSO [25] | 281,506 | 262,631 | 1,098,728.5 |
| EBOwithCMAR [40] | 298,859 | 282,227 | 1,206,691 |
| L-SHADE-RSP [9] | 305,628.5 | 305,817 | 1,184,028 |
| NL-SHADE-RSP [10] | 34,664.5 | 34,687 | 425,630.5 |
| NL-SHADE-LBC [11] | 121,800.5 | 124,111 | 683,384.5 |
| L-NTADE [12] | 362,005 | 359,221 | 1,306,124.5 |
| L-NTADE (SR, ) | 416,371 | 411,493 | 1,509,082 |
Table 16.
L-NTADE (SR) vs. alternative approaches, CEC 2022.
Table 16.
L-NTADE (SR) vs. alternative approaches, CEC 2022.
| Algorithm | | |
|---|
| L-NTADE (SR, ) vs. | 8/2/2 | 10/0/2 |
| APGSK-IMODE [36] | (36.86) | (52.60) |
| L-NTADE (SR, ) vs. | 4/2/6 | 4/1/7 |
| MLS-LSHADE [37] | (−9.67) | (−19.78) |
| L-NTADE (SR, ) vs. | 8/2/2 | 8/2/2 |
| MadDE [38] | (39.05) | (43.60) |
| L-NTADE (SR, ) vs. | 2/6/4 | 5/3/4 |
| EA4eigN100 [41] | (−15.49) | (5.51) |
| L-NTADE (SR, ) vs. | 3/4/5 | 6/2/4 |
| NL-SHADE-RSP-MID [42] | (−5.98) | (17.59) |
| L-NTADE (SR, ) vs. | 5/3/4 | 4/6/2 |
| L-SHADE-RSP [9] | (14.23) | (12.24) |
| L-NTADE (SR, ) vs. | 6/3/3 | 7/4/1 |
| NL-SHADE-RSP [10] | (24.51) | (34.78) |
| L-NTADE (SR, ) vs. | 2/3/7 | 4/4/4 |
| NL-SHADE-LBC [11] | (−30.20) | (−3.75) |
| L-NTADE (SR, ) vs. | 5/5/2 | 2/6/4 |
| L-NTADE [12] | (26.17) | (−1.82) |
The comparison on the CEC 2022 benchmark in
Table 16 shows that L-NTADE with
is outperformed by NL-SHADE-LBC and EA4eigN100 in the 10D case, but in 20D the difference between them decreases. However, the MLS-LSHADE is able to deliver better performance in the 20D case. The Friedman ranking in
Table 17 sets EA4eigN100 in first place, followed by NL-SHADE-LBC, and MLS-LSHADE and L-NTADE with
. However, when using U-scores in
Table 18, L-NTADE with
takes second place after NL-SHADE-LBC, and MLS-LSHADE has an almost identical total rank. We note that L-NTADE used the same parameter settings in both benchmarks, and still was able to show highly competitive results in both of them.
Table 17.
L-NTADE (SR) vs. alternative approaches, Friedman ranking. Smaller ranks are better, CEC 2022.
Table 17.
L-NTADE (SR) vs. alternative approaches, Friedman ranking. Smaller ranks are better, CEC 2022.
| Algorithm | | | Total |
|---|
| APGSK-IMODE [36] | 81.57 | 87.92 | 169.48 |
| MLS-LSHADE [37] | 64.05 | 50.13 | 114.18 |
| MadDE [38] | 87.15 | 87.02 | 174.17 |
| EA4eigN100 [41] | 39.17 | 53.02 | 92.18 |
| NL-SHADE-RSP-MID [42] | 58.92 | 71.25 | 130.17 |
| L-SHADE-RSP [9] | 66.65 | 59.07 | 125.72 |
| NL-SHADE-RSP [10] | 88.23 | 83.58 | 171.82 |
| NL-SHADE-LBC [11] | 49.77 | 56.73 | 106.50 |
| L-NTADE [12] | 64.58 | 55.92 | 120.50 |
| L-NTADE (SR, ) | 59.92 | 55.37 | 115.28 |
Table 18.
L-NTADE (SR) vs. alternative approaches, U-scores. Larger ranks are better [
39], CEC 2022.
Table 18.
L-NTADE (SR) vs. alternative approaches, U-scores. Larger ranks are better [
39], CEC 2022.
| Algorithm | | | Total |
|---|
| APGSK-IMODE [36] | 38,228 | 28,381.5 | 66,609.5 |
| MLS-LSHADE [37] | 52,255 | 62,548.5 | 114,803.5 |
| MadDE [38] | 35,727 | 30,402.5 | 66,129.5 |
| EA4eigN100 [41] | 50358 | 60,202 | 110,560 |
| NL-SHADE-RSP-MID [42] | 56,740.5 | 44,291.5 | 101,032 |
| L-SHADE-RSP [9] | 44,754.5 | 54,543.5 | 99,298 |
| NL-SHADE-RSP [10] | 35,363.5 | 32,772.5 | 68,136 |
| NL-SHADE-LBC [11] | 64,330 | 56,998.5 | 121,328.5 |
| L-NTADE [12] | 51,346 | 57,894 | 109,240 |
| L-NTADE (SR, ) | 56,897.5 | 57,965.5 | 114,863 |
In order to compare the computational complexity of the proposed approach, the experiment on the CEC 2022 benchmark was performed according to the rules of the CEC 2022 competition rules [
14]. The T0, T1 and T2 values are the estimations of time required for the processor to perform mathematical evaluations, target function evaluation time and the algorithm runtime, respectively.
Table 19 compares L-NTADE with the SHA and the SR adaptation methods.
As can be seen from
Table 19, applying SR reduces the amount of time, as the calculation of the weighted Lehmer mean for
F in success history-based adaptation requires significant computational effort.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







