
An Influence-Based Label Propagation Algorithm for Overlapping Community Detection
Abstract
:1. Introduction
2. Related Work
2.1. Disjoint Community Detection Algorithm
2.2. Overlapping Community Detection Algorithm
2.3. LPA for Overlapping Community Detection
- 1
- Label initialization; given a network with nodes, for any node in the network, assign a separate label to every v, with the membership of node v to label being 1;
- 2
- Update the label of node v based on the neighbors (Formula (1)). If there are multiple labels to choose from, randomly select labels from the alternative labels. The parameter is the maximum number of labels that a node can have;
- 3
- If the algorithm reaches the set maximum number of iterations, the algorithm stops; otherwise, continue to step 2;
- 4
- The community is divided based on the node label.
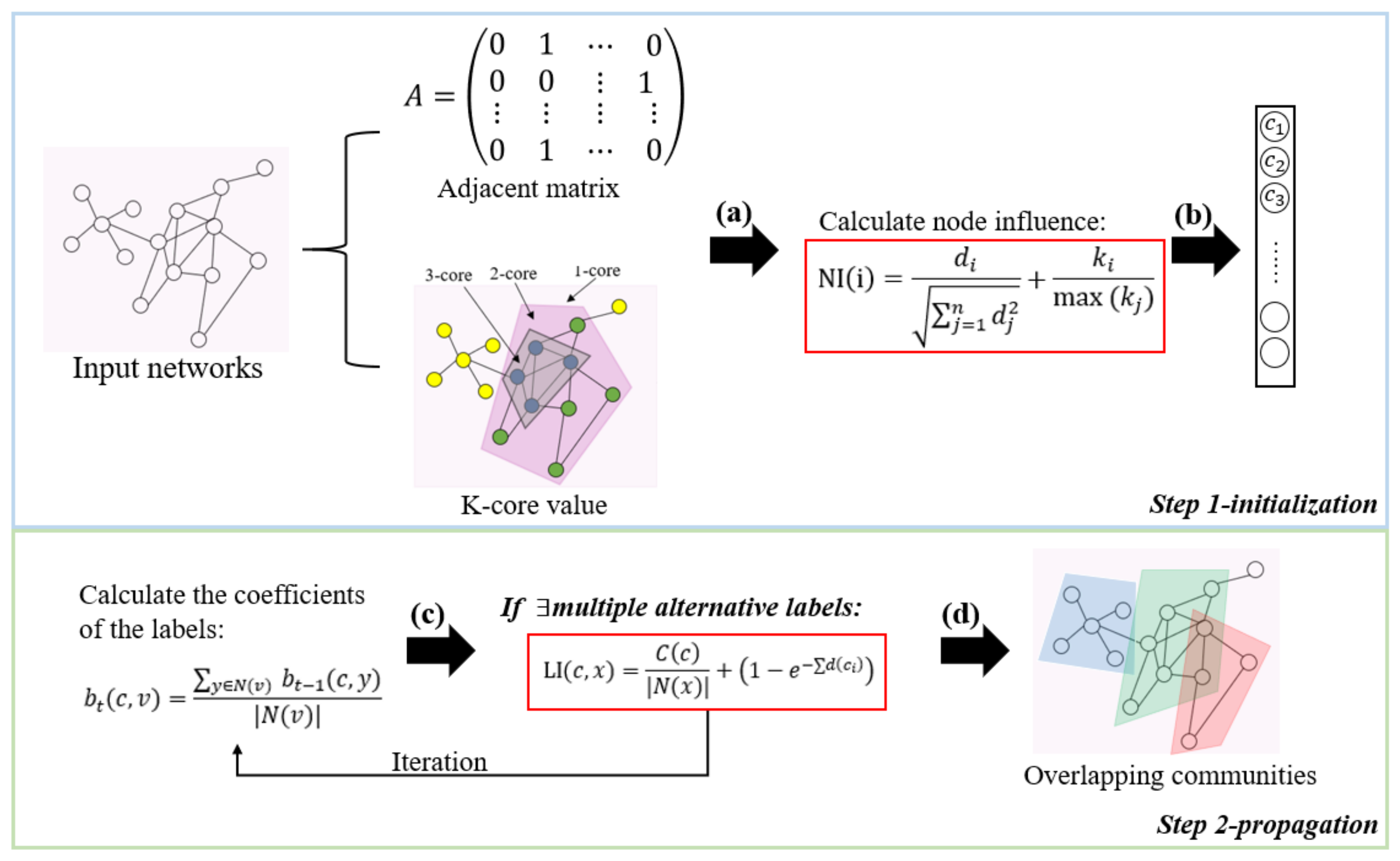
3. Influence-Based Community Overlap Propagation Algorithm
3.1. Initialization in INF-COPRA
| Algorithm 1 Initialization |
Input: network , V is the node set in the network, E is the edge set in the network Output: node influence sequence
|
3.2. Label Propagation in INF-COPRA
| Algorithm 2 Propagation |
Input: network , threshold Output: label list
|
4. Experiments
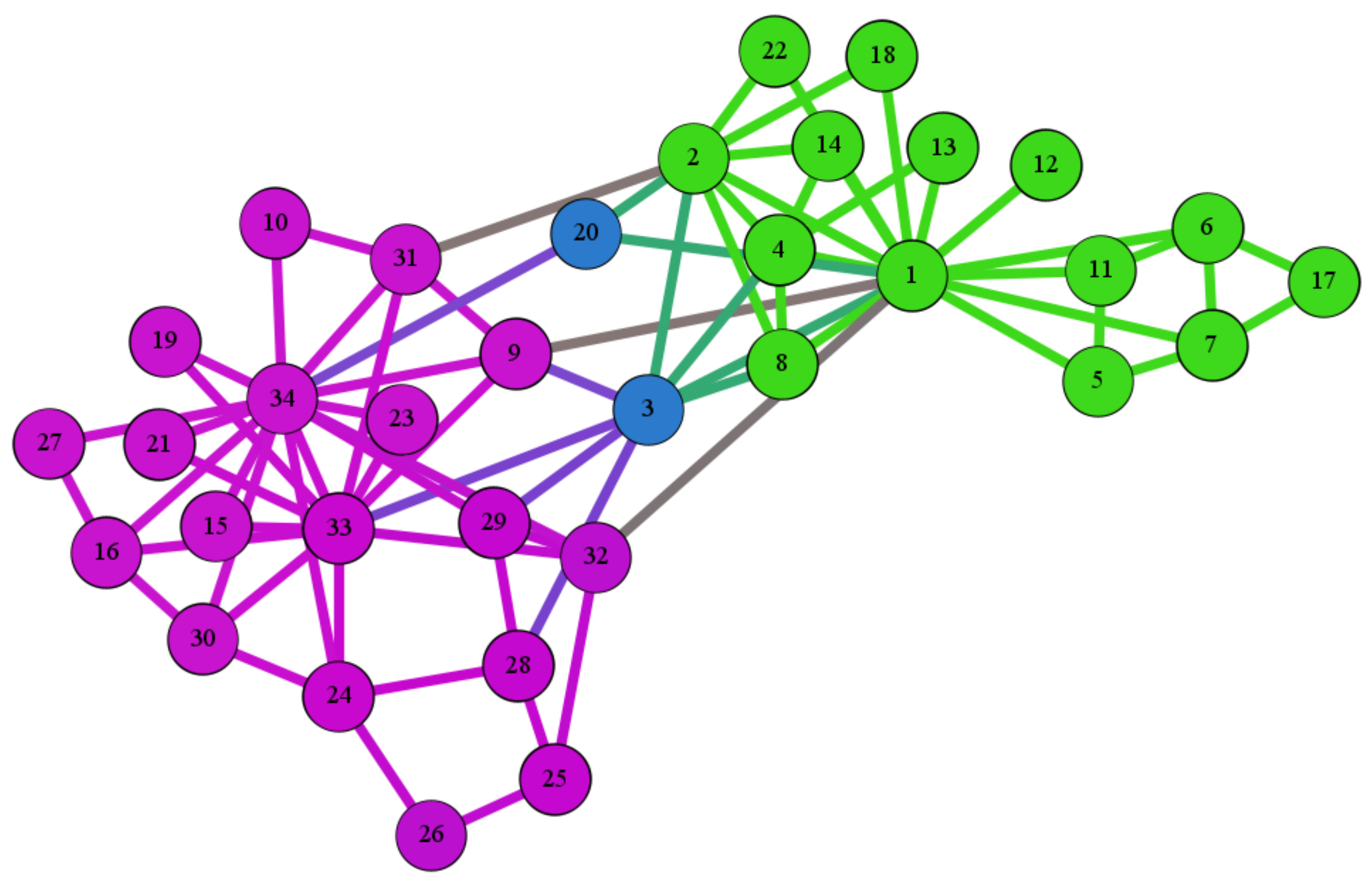
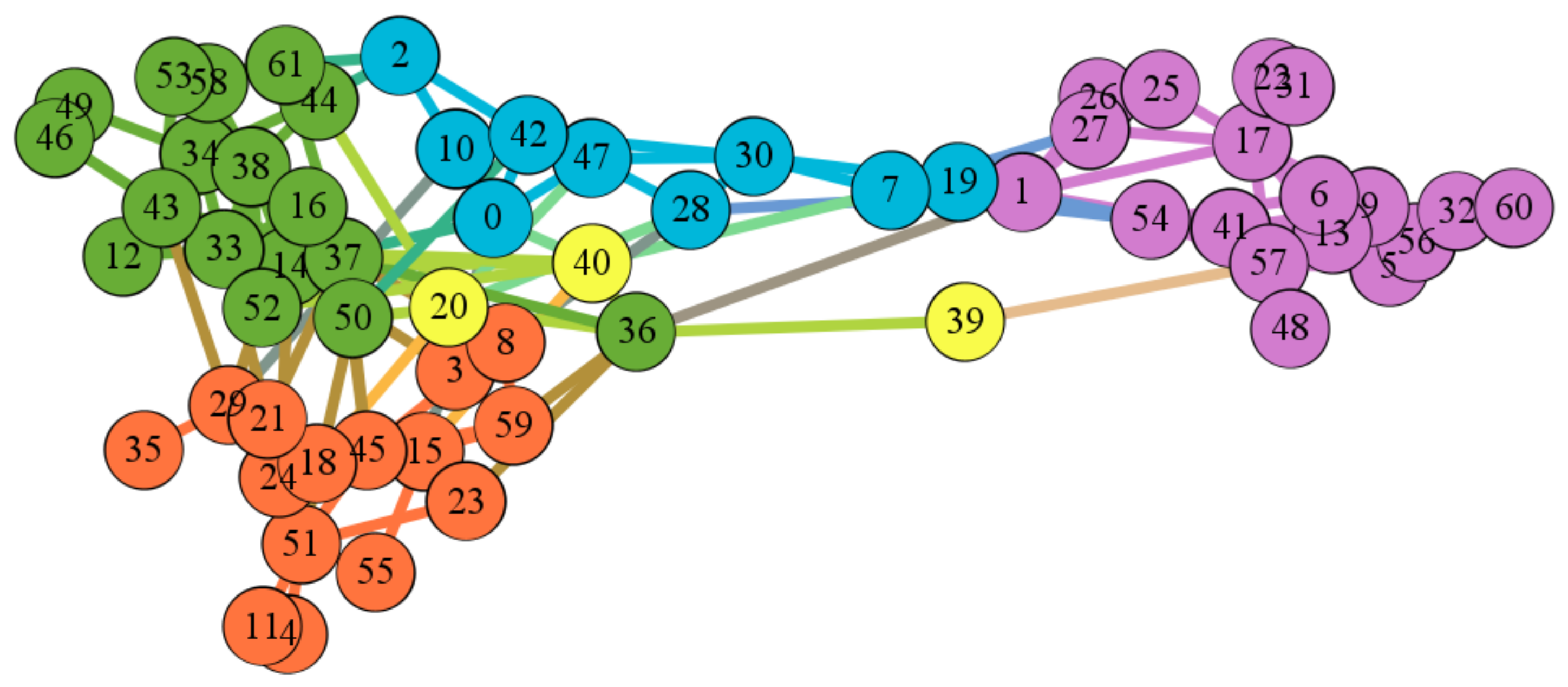
4.1. Datasets
4.2. Evaluation Metrics
5. Results and Discussion
5.1. Results on Synthetic Networks
5.2. Results on Real Networks
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, B.; Liu, D.; Liu, J. Handbook of Social Network Technologies and Applications; Springer: Boston, MA, USA, 2010; pp. 331–346. [Google Scholar]
- Fortunato, S.; Newman, M.E. 20 years of network community detection. Nat. Phys. 2022, 18, 848–850. [Google Scholar] [CrossRef]
- Chen, Y.; Chuang, C.; Chiu, Y. Community detection based on social interactions in a social network. J. Assoc. Inf. Sci. 2014, 539–550. [Google Scholar] [CrossRef]
- Cai, B.; Wang, Y.; Zeng, L. Edge classification based on Convolutional Neural Networks for community detection in complex network. Physica A 2020, 556, 124826. [Google Scholar] [CrossRef]
- Li, G.; Guo, K.; Chen, Y.Z. A dynamic community detection algorithm based on Parallel Incremental Related Vertices. In Proceedings of the IEEE International Conference on Big Data Analysis, Beijing, China, 10–12 March 2017; pp. 10–12. [Google Scholar]
- Hu, D.; Sarder, P.; Ronhovde, P. Automatic segmentation of fluorescence lifetime microscopy images of cells using multiresolution community detection—A first study. Microscopy 2013, 1, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Liu, Z.P.; Chen, L. Identification of overlapping communities in protein interaction networks using multi-scale local information expansion. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 6–8. [Google Scholar]
- Tian, B.; Li, W. Community Detection Method Based on Mixed-norm Sparse Subspace Clustering. Neurocomputing 2018, 275, 2150–2161. [Google Scholar] [CrossRef]
- Newman, M. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Cai, Q.; Ma, L.; Gong, M.; Tian, D. A survey on network community detection based on evolutionary computation. Int. J. Bio-Inspir. Com. 2016, 8, 84–98. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Tikhonov, A. Community detection through likelihood optimization: In search of a sound model. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1498–1508. [Google Scholar]
- Romdhane, L.B.; Chaabani, Y.; Zardi, H. A robust ant colony optimization-based algorithm for community mining in large scale oriented social graphs. Expert. Syst. Appl. 2013, 40, 5709–5718. [Google Scholar] [CrossRef]
- Žalik, K.R.; Žalik, B. Multi-objective evolutionary algorithm using problem-specific genetic operators for community detection in networks. Neural. Comput. Appl. 2018, 30, 2907–2920. [Google Scholar] [CrossRef]
- Satuluri, V.; Parthasarathy, S. Scalable graph clustering using stochastic flows: Applications to community discovery. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data mining, Paris, France, 28 June–1 July 2009; pp. 737–746. [Google Scholar]
- Lynn, C.W.; Bassett, D.S. Quantifying the compressibility of complex networks. Proc. Natl. Acad. Sci. USA 2021, 118, 32. [Google Scholar] [CrossRef]
- Patel, N.V.; Sutaria, N. A survey on community detection in social network using genetic algorithm. Proc. SPIE Int. Soc. Opt. Eng. 2015, 3, 16–19. [Google Scholar]
- Vieira, V.D.F.; Xavier, C.R.; Evsukoff, A.G. A comparative study of overlapping community detection methods from the perspective of the structural properties. Appl. Net. Sci. 2020, 5, 1–42. [Google Scholar] [CrossRef]
- Mittal, R.; Bhatia, M.P.S. Classification and comparative evaluation of community detection algorithms. Arch. Comput. Method E 2021, 28, 1417–1428. [Google Scholar] [CrossRef]
- Gregory, S. Finding overlapping communities in networks by label propagation. NJP 2010, 12, 10. [Google Scholar] [CrossRef]
- Chen, N.; Liu, Y.; Chen, H. Detecting communities in social networks using label propagation with information entropy. Physica A 2017, 471, 788–798. [Google Scholar] [CrossRef]
- Jia, H.C.; Ratnavelu, K. Detecting Community Structure by Using a Constrained Label Propagation Algorithm. PLoS ONE 2016, 11, e0155320. [Google Scholar]
- Xing, Y.; Meng, F.; Zhou, Y.; Zhu, M.; Shi, M.; Sun, G. A Node Influence Based Label Propagation Algorithm for Community Detection in Networks. Sci. World J. 2014, 2014, 627581. [Google Scholar] [CrossRef]
- Xie, J.; Szymanski, B.K. LabelRank: A Stabilized Label Propagation Algorithm for Community Detection in Networks. In Proceedings of the 2013 IEEE 2nd Network Science Workshop (NSW), New York, NY, USA, 29 April–1 May 2013; pp. 138–143. [Google Scholar]
- Girvan, M.; Newman, M.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 12, 99. [Google Scholar] [CrossRef]
- Kernighan, B.W.; Lin, S. An efficient heuristic procedure for partitioning graphs. Bell Labs Tech. J. 2014, 2, 291–307. [Google Scholar] [CrossRef]
- Kigerl, A. Behind the Scenes of the Underworld: Hierarchical Clustering of Two Leaked Carding Forum Databases. Soc. Sci. Comput. Rev. 2022, 3, 618–640. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 6, 69. [Google Scholar] [CrossRef] [PubMed]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10, P10008. [Google Scholar] [CrossRef]
- Xie, J.; Kelley, S.; Szymanski, B.K. Overlapping Community Detection in Networks: The State of the Art and Comparative Study. ACM Comput. Surv. 2013, 4, 1–35. [Google Scholar] [CrossRef]
- Guimera, R.; Danon, L.; Diaz-Guilera, A.; Giralt, F.; Arenas, A. The real communication network behind the formal chart: Community structure in organizations. J. Econ. Behav. Organ. 2006, 61, 653–667. [Google Scholar] [CrossRef]
- Palla, G.; Deranyi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef]
- Zhang, H.; Qiu, B.; Giles, C.L.; Foley, H.C.; Yen, J. An LDA-based community structure discovery approach for large-scale social networks. In Proceedings of the 2007 IEEE Intelligence and Security Informatics, New Brunswick, NJ, USA, 23–24 May 2007; pp. 200–207. [Google Scholar]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Baumes, J.; Goldberg, M.K.; Krishnamoorthy, M.S.; Magdon-Ismail, M.; Preston, N. Finding communities by clustering a graph into overlapping subgraphs. IADIS AC 2005, 5, 97–104. [Google Scholar]
- Bandyopadhyay, S.; Chowdhary, G.; Sengupta, D. FOCS: Fast Overlapped Community Search. IEEE Trans. Knowl. Data Eng. 2015, 27, 2974–2985. [Google Scholar] [CrossRef]
- Nepusz, T.; Yu, H.; Paccanaro, A. Detecting overlapping protein complexes in protein-protein interaction networks. Nat. Methods 2012, 9, 471–472. [Google Scholar] [CrossRef]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near Linear Time Algorithm to Detect Community Structures in Large-Scale Networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef]
- Xie, J.; Szymanski, B.K. Community Detection Using A Neighborhood Strength Driven Label Propagation Algorithm. In Proceedings of the 2011 IEEE Network Science Workshop, Washington, DC, USA, 22–24 June 2011; pp. 188–195. [Google Scholar]
- Huang, L.; Wang, G.; Wang, Y. LPANNI: Overlapping community detection using label propagation in large-scale complex networks. IEEE Trans. Knowl. Data Eng. 2019, 31, 1736–1749. [Google Scholar]
- Fortunato, S.; Darko, H. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Centola, D. The Spread of Behavior in an Online Social Network Experiment. Science 2010, 329, 1194–1197. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1976, 33, 452–473. [Google Scholar] [CrossRef]
- Alamsyah, A.; Rahardjo, B. Community Detection Methods in Social Network Analysis. J. Comput. Theor. Nanosci. 2014, 20, 250–253. [Google Scholar] [CrossRef]
- Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data/ (accessed on 1 June 2014).
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 9, P09008. [Google Scholar] [CrossRef]
- Shen, H.; Cheng, X.; Cai, K.; Hu, M.B. Detect overlapping and hierarchical community structure in networks. Physica A 2009, 388, 1706–1712. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Kertész, J. Detecting the overlapping and hierarchical community structure in complex networks. New J. Phys. 2009, 11, 033015. [Google Scholar] [CrossRef]
- Ye, F.; Chen, C.; Zheng, Z. Deep autoencoder like nonnegative matrix factorization for community detection. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1393–1402. [Google Scholar]
- Ye, T.; Yang, S.; Zhang, X. An evolutionary multiobjective optimization based fuzzy method for overlapping community detection. IEEE Trans. Fuzzy Syst. 2019, 28, 2841–2855. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node | Edge | |
|---|---|---|
| karate | 34 | 78 |
| dolphins | 62 | 159 |
| football | 115 | 613 |
| 4039 | 88,234 | |
| 36,692 | 183,831 |
| Network | N | ||
|---|---|---|---|
| LFR- | 1000–8000 | 0.1 | - |
| 0.2 | - | ||
| 0.3 | - | ||
| 0.4 | - | ||
| 0.5 | - | ||
| 0.6 | - | ||
| LFR- | 1000–8000 | - | 0.1 |
| - | 0.2 | ||
| - | 0.4 | ||
| - | 0.6 | ||
| - | 0.8 |
| N | INF-COPRA | COPRA | CPM | SLPA | LFM | DANMF | EMOFM-SC | |
|---|---|---|---|---|---|---|---|---|
| 1000 | 0.1 | 0.97 | 0.9 | 0.224 | 0.68 | 0.8 | 0.94 | 0.963 |
| 0.2 | 0.92 | 0.74 | 0.15 | 0.59 | 0.62 | 0.81 | 0.835 | |
| 0.3 | 0.73 | 0.58 | 0.071 | 0.49 | 0.47 | 0.78 | 0.802 | |
| 0.4 | 0.45 | 0.13 | 0.043 | 0.32 | 0.24 | 0.55 | 0.611 | |
| 0.5 | 0.29 | 0.05 | 0.026 | 0.07 | 0.25 | 0.5 | 0.478 | |
| 0.6 | 0.2 | 0.006 | 0.0009 | 0.02 | 0.19 | 0.34 | 0.38 | |
| 2000 | 0.1 | 0.98 | 0.9 | 0.23 | 0.6 | 0.917 | 0.95 | 0.947 |
| 0.2 | 0.97 | 0.76 | 0.17 | 0.59 | 0.803 | 0.84 | 0.909 | |
| 0.3 | 0.83 | 0.6 | 0.08 | 0.54 | 0.526 | 0.78 | 0.853 | |
| 0.4 | 0.55 | 0.06 | 0.05 | 0.32 | 0.291 | 0.48 | 0.732 | |
| 0.5 | 0.29 | 0.01 | 0.02 | 0.07 | 0.25 | 0.44 | 0.205 | |
| 0.6 | 0.2 | 0.009 | 0.007 | 0.02 | 0.177 | 0.36 | 0.082 | |
| 5000 | 0.1 | 0.98 | 0.6 | 0.3 | 0.88 | 0.78 | 0.9 | 0.927 |
| 0.2 | 0.95 | 0.5 | 0.28 | 0.79 | 0.7 | 0.88 | 0.884 | |
| 0.3 | 0.9 | 0.24 | 0.27 | 0.68 | 0.61 | 0.86 | 0.851 | |
| 0.4 | 0.64 | 0.009 | 0.07 | 0.22 | 0.4 | 0.58 | 0.673 | |
| 0.5 | 0.28 | 0.007 | 0.05 | 0.07 | 0.23 | 0.34 | 0.258 | |
| 0.6 | 0.08 | 0.006 | 0.015 | 0.002 | 0.14 | 0.2 | 0.104 | |
| 8000 | 0.1 | 0.96 | 0.74 | 0.67 | 0.7 | 0.81 | 0.9 | 0.916 |
| 0.2 | 0.94 | 0.68 | 0.59 | 0.6 | 0.75 | 0.87 | 0.805 | |
| 0.3 | 0.8 | 0.47 | 0.42 | 0.48 | 0.54 | 0.52 | 0.649 | |
| 0.4 | 0.6 | 0.29 | 0.27 | 0.3 | 0.36 | 0.27 | 0.531 | |
| 0.5 | 0.32 | 0.04 | 0.02 | 0.1 | 0.18 | 0.005 | 0.152 | |
| 0.6 | 0.2 | 0.006 | 0.0009 | 0.02 | 0.09 | 0.0004 | 0.093 |
| N | INF-COPRA | COPRA | CPM | SLPA | LFM | DANMF | EMOFM-SC | |
|---|---|---|---|---|---|---|---|---|
| 1000 | 0.1 | 0.95 | 0.85 | 0.48 | 0.88 | 0.78 | 0.89 | 0.923 |
| 0.2 | 0.91 | 0.74 | 0.38 | 0.79 | 0.7 | 0.82 | 0.905 | |
| 0.4 | 0.63 | 0.2 | 0.16 | 0.38 | 0.42 | 0.65 | 0.647 | |
| 0.6 | 0.35 | 0.009 | 0.07 | 0.02 | 0.16 | 0.39 | 0.478 | |
| 0.8 | 0.2 | 0.002 | 0.05 | 0.007 | 0.07 | 0.26 | 0.091 | |
| 2000 | 0.1 | 0.98 | 0.6 | 0.32 | 0.77 | 0.77 | 0.89 | 0.875 |
| 0.2 | 0.96 | 0.56 | 0.3 | 0.79 | 0.68 | 0.88 | 0.893 | |
| 0.4 | 0.69 | 0.1 | 0.12 | 0.38 | 0.46 | 0.65 | 0.649 | |
| 0.6 | 0.33 | 0.004 | 0.06 | 0.02 | 0.25 | 0.37 | 0.531 | |
| 0.8 | 0.09 | 0.002 | 0.03 | 0.007 | 0.15 | 0.2 | 0.192 | |
| 5000 | 0.1 | 0.95 | 0.73 | 0.65 | 0.71 | 0.82 | 0.89 | 0.798 |
| 0.2 | 0.91 | 0.67 | 0.59 | 0.7 | 0.74 | 0.86 | 0.634 | |
| 0.4 | 0.8 | 0.47 | 0.42 | 0.28 | 0.55 | 0.51 | 0.571 | |
| 0.6 | 0.6 | 0.29 | 0.27 | 0.02 | 0.37 | 0.28 | 0.208 | |
| 0.8 | 0.32 | 0.03 | 0.017 | 0.007 | 0.2 | 0.005 | 0.081 | |
| 8000 | 0.1 | 0.95 | 0.755 | 0.265 | 0.71 | 0.482 | 0.489 | 0.693 |
| 0.2 | 0.928 | 0.738 | 0.159 | 0.6 | 0.374 | 0.486 | 0.592 | |
| 0.4 | 0.809 | 0.492 | 0.106 | 0.28 | 0.192 | 0.32 | 0.502 | |
| 0.6 | 0.563 | 0.011 | 0.065 | 0.1 | 0.162 | 0.28 | 0.291 | |
| 0.8 | 0.32 | 0.008 | - | 0.01 | - | - | - |
| INF-COPRA | COPRA | CPM | SLPA | LFM | DANMF | EMOFM-SC | |
|---|---|---|---|---|---|---|---|
| karate | 0.413 | 0.387 | 0.116 | 0.214 | 0.328 | 0.39 | 0.257 |
| dolphins | 0.392 | 0.379 | 0.287 | 0.381 | 0.341 | 0.375 | 0.272 |
| football | 0.591 | 0.359 | 0.331 | 0.353 | 0.513 | 0.603 | 0.301 |
| 0.558 | 0.456 | 0.263 | 0.505 | 0.386 | 0.386 | 0.409 | |
| 0.392 | 0.224 | 0.013 | 0.317 | 0.348 | 0.35 | 0.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Ran, Y.; Xing, J.; Tao, L. An Influence-Based Label Propagation Algorithm for Overlapping Community Detection. Mathematics 2023, 11, 2133. https://doi.org/10.3390/math11092133
Xu H, Ran Y, Xing J, Tao L. An Influence-Based Label Propagation Algorithm for Overlapping Community Detection. Mathematics. 2023; 11(9):2133. https://doi.org/10.3390/math11092133
Chicago/Turabian StyleXu, Hao, Yuan Ran, Junqian Xing, and Li Tao. 2023. "An Influence-Based Label Propagation Algorithm for Overlapping Community Detection" Mathematics 11, no. 9: 2133. https://doi.org/10.3390/math11092133