In this section, we will present the results of the performance of the generic model of heteroassociative max memories. Firstly, we will define the experimental setup that was employed, and then we will present the comparisons between the generic model of heteroassociative max memories and the model of heteroassociative min memories.
3.4. Generic Model of Max Heteroassociative Memory
In
Section 3.1, we described the experimental setup used to evaluate the performance of the generic maximum heteroassociative memory model, which was repeated 1000 times for each fundamental set. We utilized the fundamental sets described in
Section 3.2. We generated acquisition noise for binary images and geometric acquisition noise for gray-scale images, as detailed in
Section 3.3.1 and
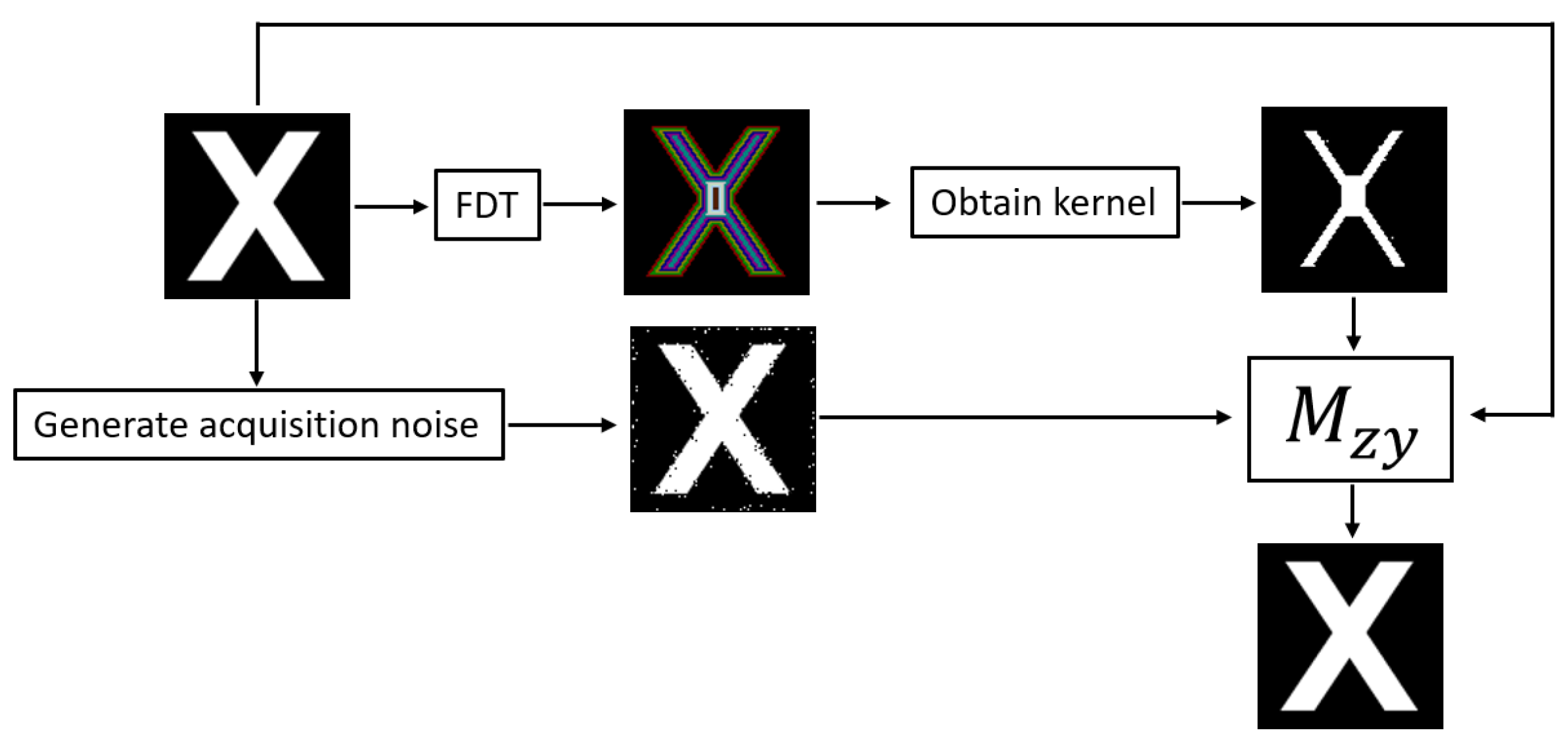
Section 3.3.2, respectively. To illustrate the process followed for binary patterns and gray-scale patterns in evaluating the performance of the generic maximum heteroassociative memory model, we have included
Figure 23 and
Figure 24.
According to the noise distribution proposed in [
38], the percentages of noise distribution mapped to distances for binary images are specified in
Table 1.
The
Table 2 defines the percentages of noise distribution mapped to distances for binary images, where the total mixed noise up to distance
is
. To create the kernel, a set of mapped pixels needs to be preserved at any distance
d from the original pattern, where noise is less likely to alter them. Based on Theorem 3, it is possible to define the probability of the generic model of maximum heteroassociative memory completely recalling the patterns. The success probability is presented in
Table 2.
The performance of the generic maximum heteroassociative memory model for fundamental set 1 is presented in
Table 3. The recall percentage for a distance of 1 is above
, which is very good for two reasons. Firstly, the expected probability of success for this distance is at least
, which is met. Secondly, the original kernel model has
recoveries with altered kernels with mixed noise. The expected probability of success can be defined by eliminating distance 1 and conserving distances 2 onward for kernel construction, which is
.
Table 3 shows that the generic max heteroassociative memory model meets the expected probability for distances 2, 3, and 4. From distance 5 onward, the pattern is recovered completely at
. These results are in compliance with Theorem 3.
Table 3 also shows the percentages of complete recovery using the heteroassociative memory min, which meets the expected probability of success but has a lower recovery than the generic max heteroassociative memory model. This is because noise is presented where there is information, the more information there is, the more noise is presented. The kernel for the heteroassociative memory min works with the pattern complement, and because of the characteristics of the fundamental patterns used in this article, there is more information and therefore more noise, causing the heteroassociative memory to fail more times than the generic max heteroassociative memory model.
Table 4 demonstrates the performance of the generic heteroassociative memory max and confirms the results in
Table 3 that meet the definition of Theorem 3, indicating the robustness of the generic model max to mixed noise. Although pattern H had the lowest performance in retrieval, it still satisfied Theorem 3. The minimum heteroassociative memories also performed well. These tables demonstrate that because the noise is concentrated at the edges, FDT enables the mapping of noise to the affected distances, making it easy to eliminate those distances affected by the noise. This approach facilitates the creation of kernels without noise, which would benefit the models of associative memories.
Table 5 is particularly interesting as it demonstrates the performance of max heteroassociative memories using binary images of faces. The recall percentages exceed what is expected according to Theorem 3. This type of image is particularly relevant for this type of memory as it tests its performance not with artificial patterns but with real patterns. As expected, min heteroassociative memories perform worse than generic heteroassociative memories max, as the creation of their kernel contains more information and therefore more noise.
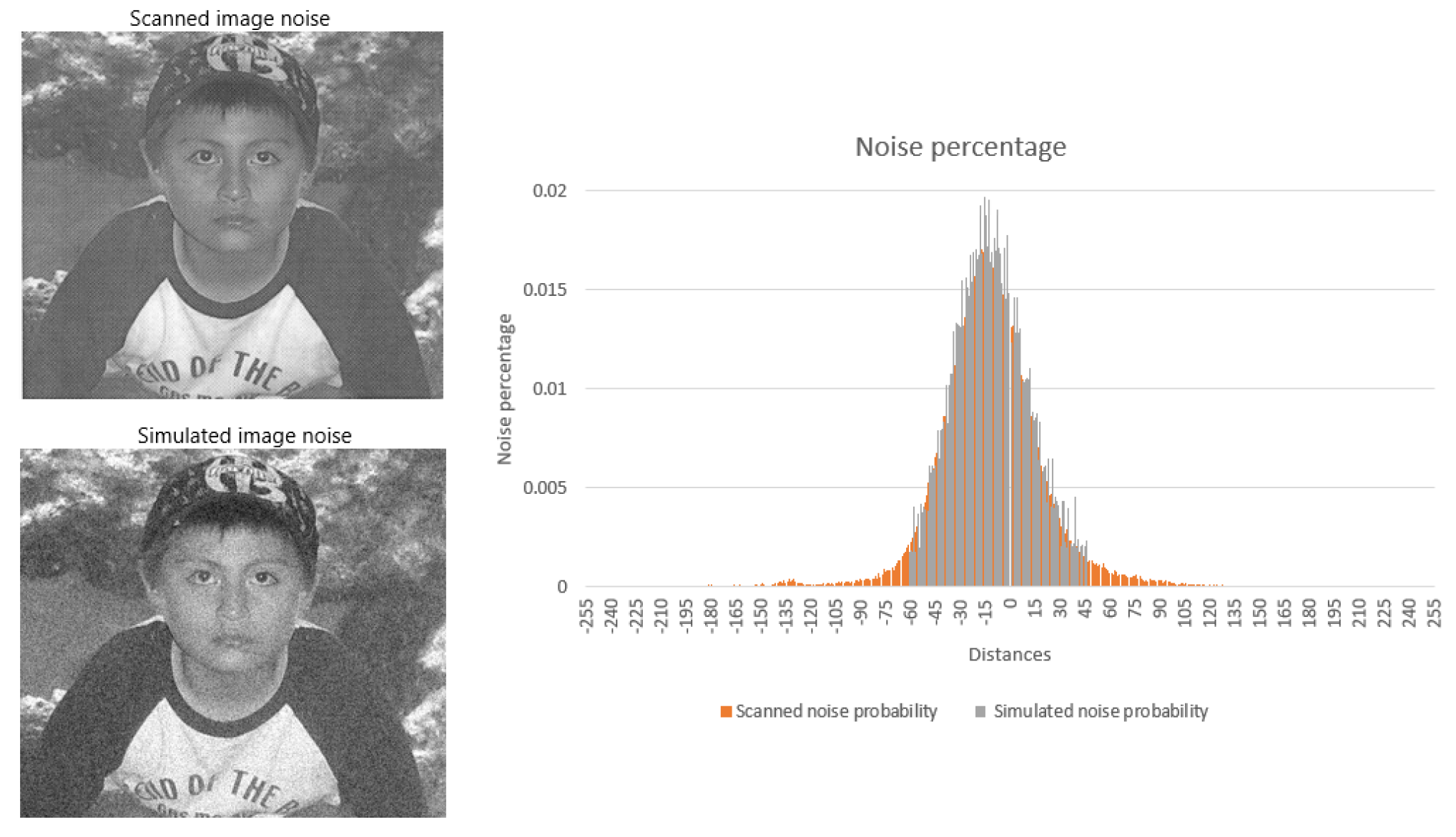
The probability distribution of mixed noise affecting distances in gray-scale images, as reported in ref. [
38], ranges from distance
to distance 187, with their respective probabilities. This noise is concentrated at these distances, accounting for
of the noise. Negative distances indicate additive noise, while positive distances indicate subtractive noise. To calculate the probability of complete recovery in the generic heteroassociative memory max, Theorem 3 must be applied.
Table 6 displays the success rates for distances ranging from 10 to 100.
Table 7 demonstrates the performance of the generic max heteroassociative memory with fundamental set 4. Both memories exceed the expected probability of success in complete pattern recovery, as shown in
Table 6. Furthermore, it is evident that the recall rate is
from distance 35, indicating that both memories are robust to mixed noise. Overall, the proposed model meets expectations for all five fundamental sets.
Table 8 presents the performance of the max heteroassociative memory with the fundamental set 5. Despite the low performance observed for distances below 30, which did not meet the expected percentage shown in
Table 6, the model is still valid. From a distance of 30 onward, it exceeds the expected success rate, demonstrating its robustness to mixed noise. The poor performance for distance 10 can be attributed to the
probability of failure, but it does not invalidate the model. Although the minimum heteroassociative memory also performed well, it had lower performance than the generic max heteroassociative memory. As previously mentioned, the kernel created for the heteroassociative memory min uses the complement of the pattern, which leads to more information acquisition and subsequently more noise. This type of noise causes the associative memories in minmax algebra to fail.
The preceding results demonstrate a comparison between robust heteroassociative memory models, min and max, against mixed noise. It is evident that the generic max heteroassociative model outperforms the min heteroassociative model. The comparison was made using morphological associative memories, which offered the advantage of using both binary and grayscale images. The results indicate that the generic max heteroassociative memory model is not only faster, but it also builds the kernel with less information, resulting in a lower probability of noise interference and, therefore, a better performance than that of the robust heteroassociative model min against acquisition noise.
Having demonstrated that the generic model of max heteroassociative memory robust to acquisition noise outperforms the heteroassociative memory min model, we proceeded to apply the generic model of maximum heteroassociative memory to the maximum memory
and to the max memory proposed by Gamino and Díaz-de-Leon (G-DL) [
6]. We only did it for the binary case, as these memories are designed specifically for this purpose. The results of our experiment are presented in
Table 9.
Table 9 indicates that the three memory models have very similar performance, which is not surprising given that they employ a generic model of maximum heteroassociative memory robust to acquisition noise and share the same fundamental set. The difference lies in the fact that Algorithm 1 generates acquisition noise randomly, resulting in distinct noise patterns for each iteration. Had the same noise patterns been applied to the generic model of maximum heteroassociative memory robust to acquisition noise across all three memory models, the results would likely have been virtually identical.
This demonstrates that the proposed model works effectively for any type of memory based on the minmax algebra, regardless of the type of operators utilized. Furthermore, the results indicate that the proposed model is superior to kernel generation models for existing minmax memories in the state of the art. Additionally, the method used to obtain the kernel aligns with the requirements of the original kernel model proposed by morphological memories. These findings suggest that, irrespective of the associative memory model employed, if the behavior of noise is known and can be mapped using a distance transform, it is feasible to create noise-free kernels. Furthermore, even when kernels are affected by noise, the proposed model offers a high probability of complete recall.
The patterns used in the fundamental set 4 are synthetic, but those in the fundamental set 5 are not. They are actual faces, which enhances the reliability of the generic heteroassociative memory max. The results demonstrate that the design of the max generic heteroassociative memory successfully meets its definitions, as its performance surpasses the expected percentages of success in pattern recovery. However, when the recalled patterns are not successful, they exhibit mixed noise, as demonstrated in Corollary 6.
Figure 25 illustrates the appearance of poorly recovered patterns, confirming Corollary 6. Notably, the poorly recovered patterns retain many of the original pattern’s characteristics.

 and
and 





 will be true if and only if
will be true if and only if





















{kind=link}
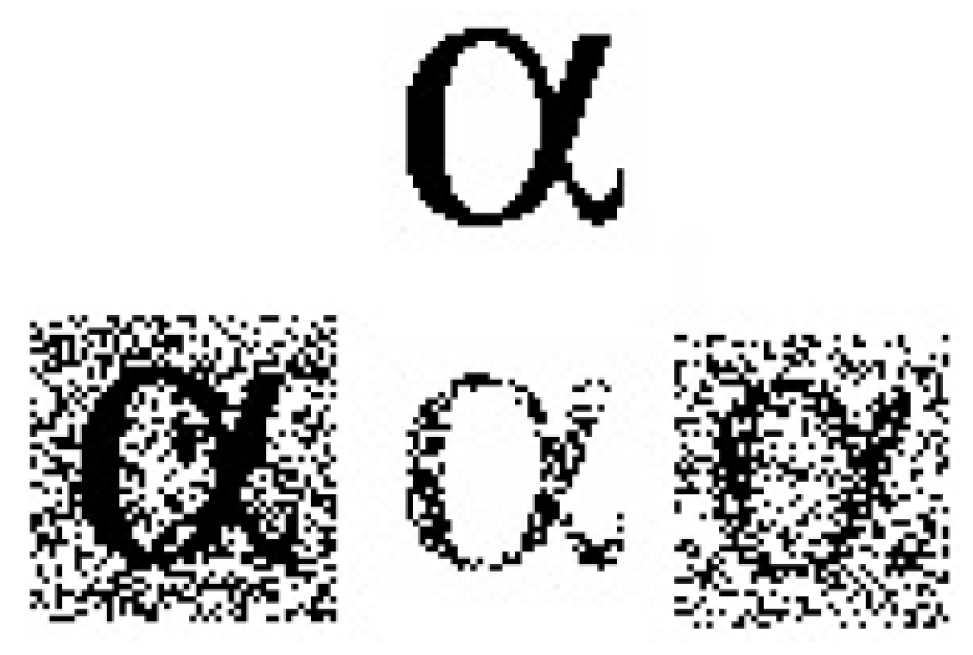{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
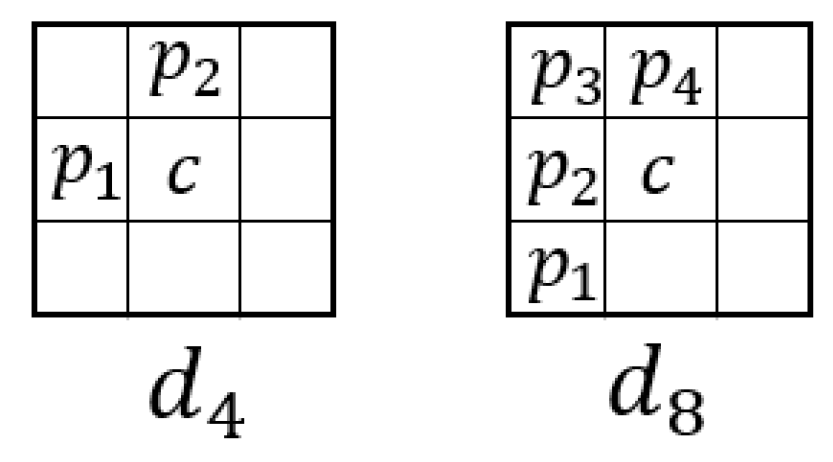{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}