
Optimal Model Averaging Estimation for the Varying-Coefficient Partially Linear Models with Missing Responses

Abstract
:1. Introduction
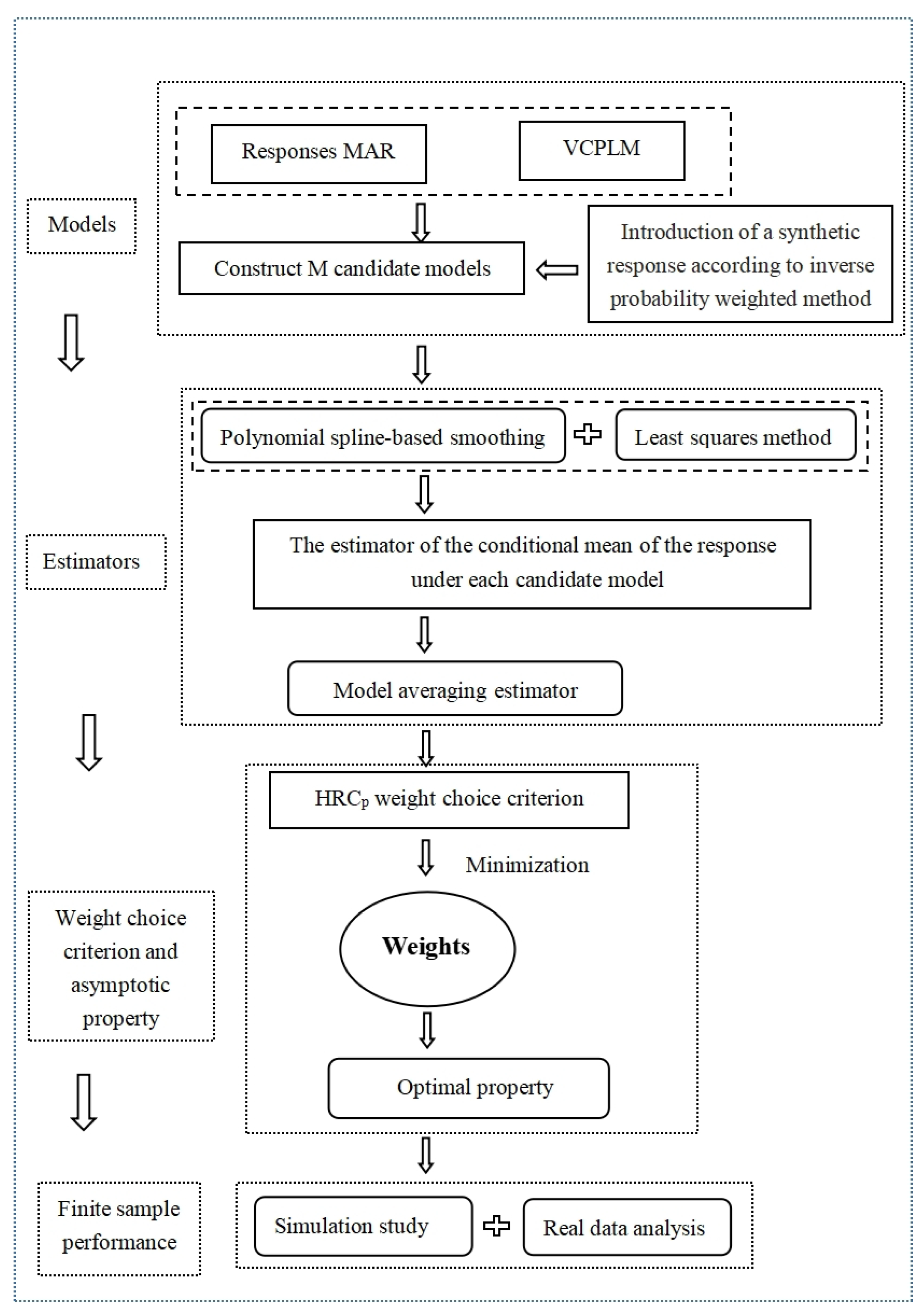
2. Model Averaging Estimation
2.1. Model and Estimators
2.2. Weight Choice Criterion and Asymptotically Optimal Property
- (Condition (C.1)) has a unique maximum at in , where is an inner point of and is compact. , and is twice continuously differentiable with respect to , where is a constant. for all ’s in a neighborhood of .
- (Condition (C.2)) for some integer and for some constant . There exists a constant , such that .
- (Condition (C.3)) , where K is given in Condition (C.2).
- (Condition (C.4)) Each coefficient function .
- (Condition (C.5)) The density function of u, say f, is bounded away from 0 and infinity on .
- (Condition (C.6)) , where denotes the ith diagonal element of .
- (Condition (C.7)) .
- (Condition (C.8)) .
3. A Simulation Study
3.1. Data Generation Process
- Case 1: ;
- Case 2: .
3.2. Estimation and Comparison
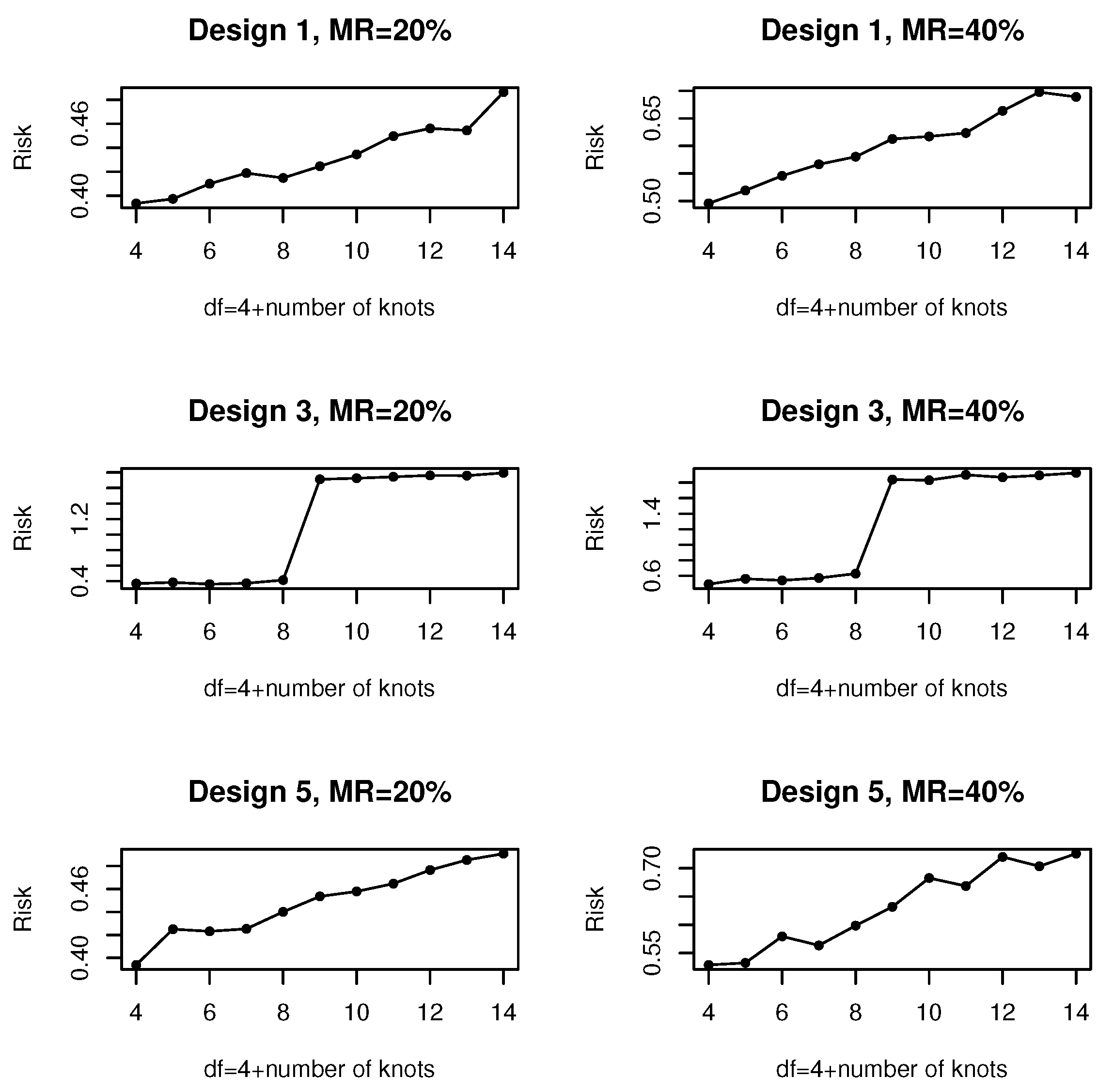
3.2.1. Selection of the Knot Number
3.2.2. Alternative Methods
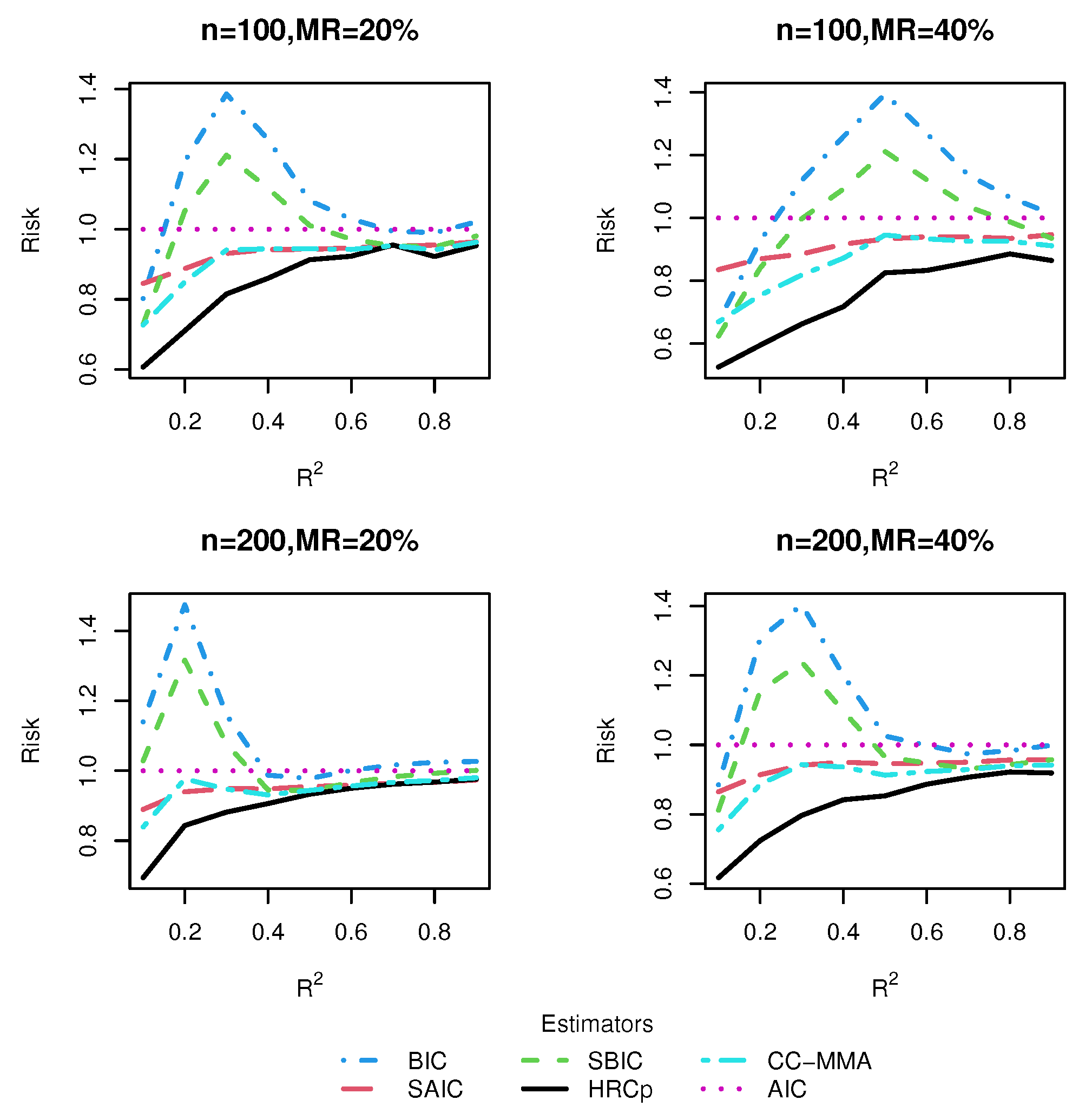
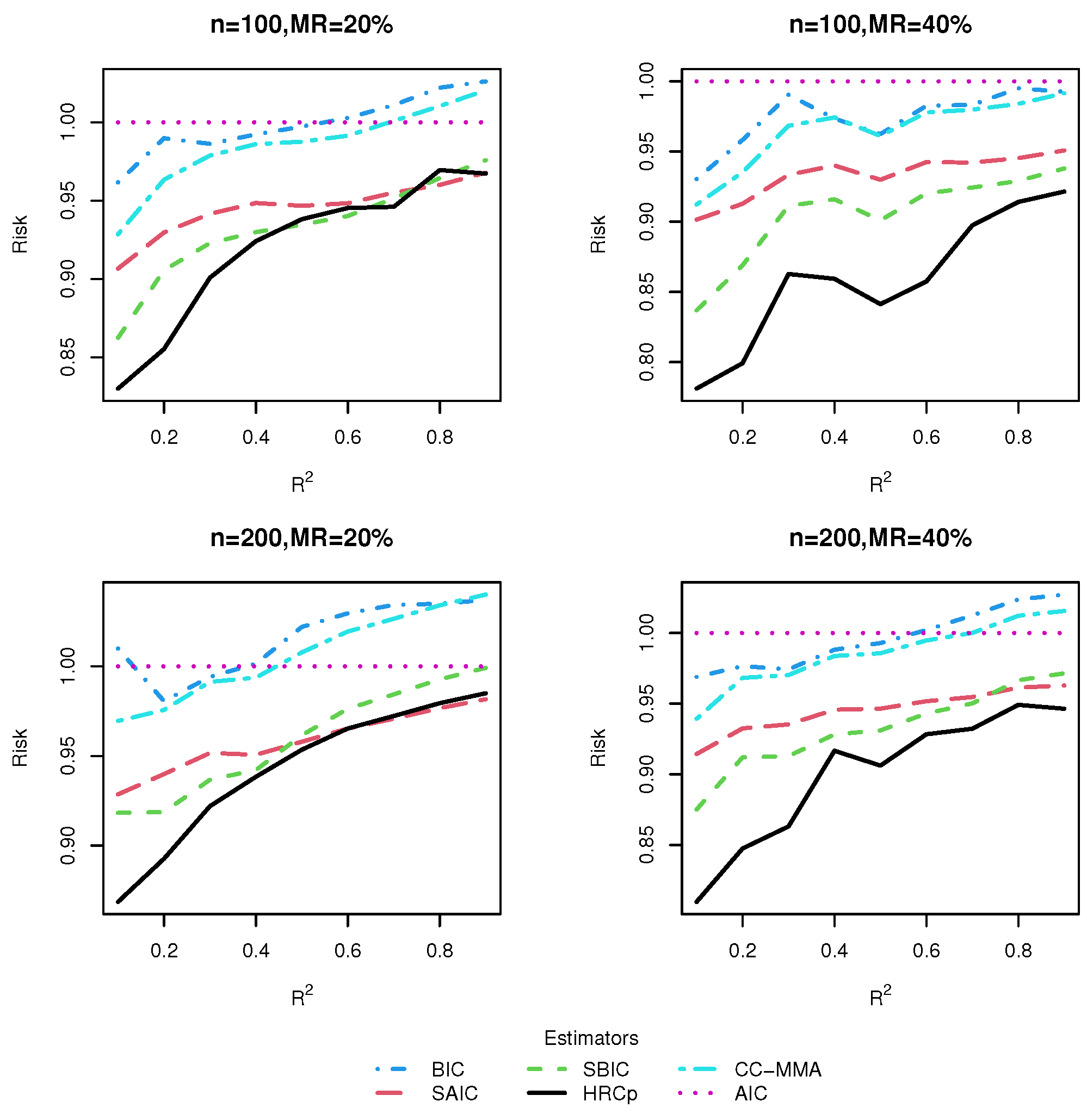
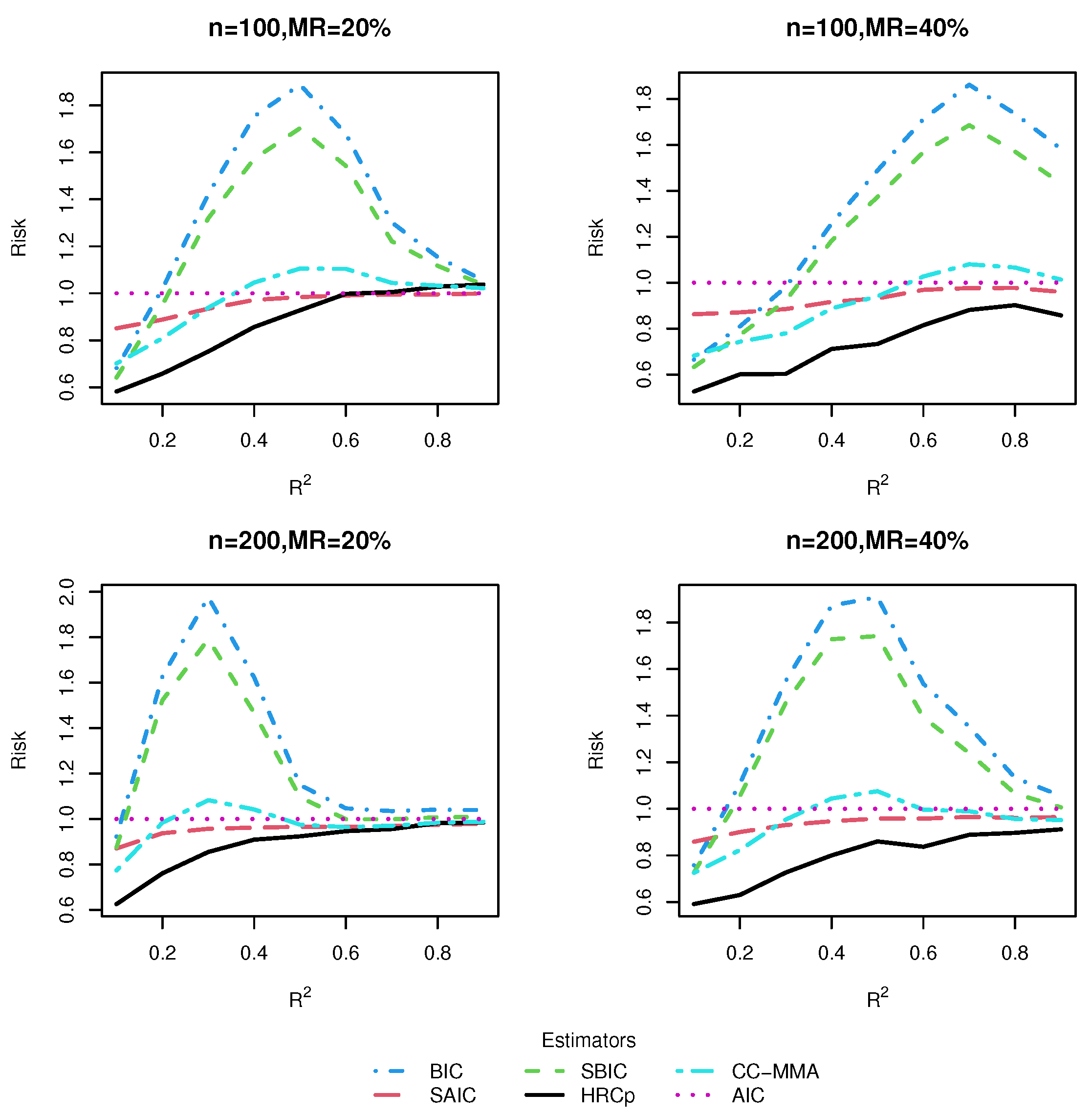
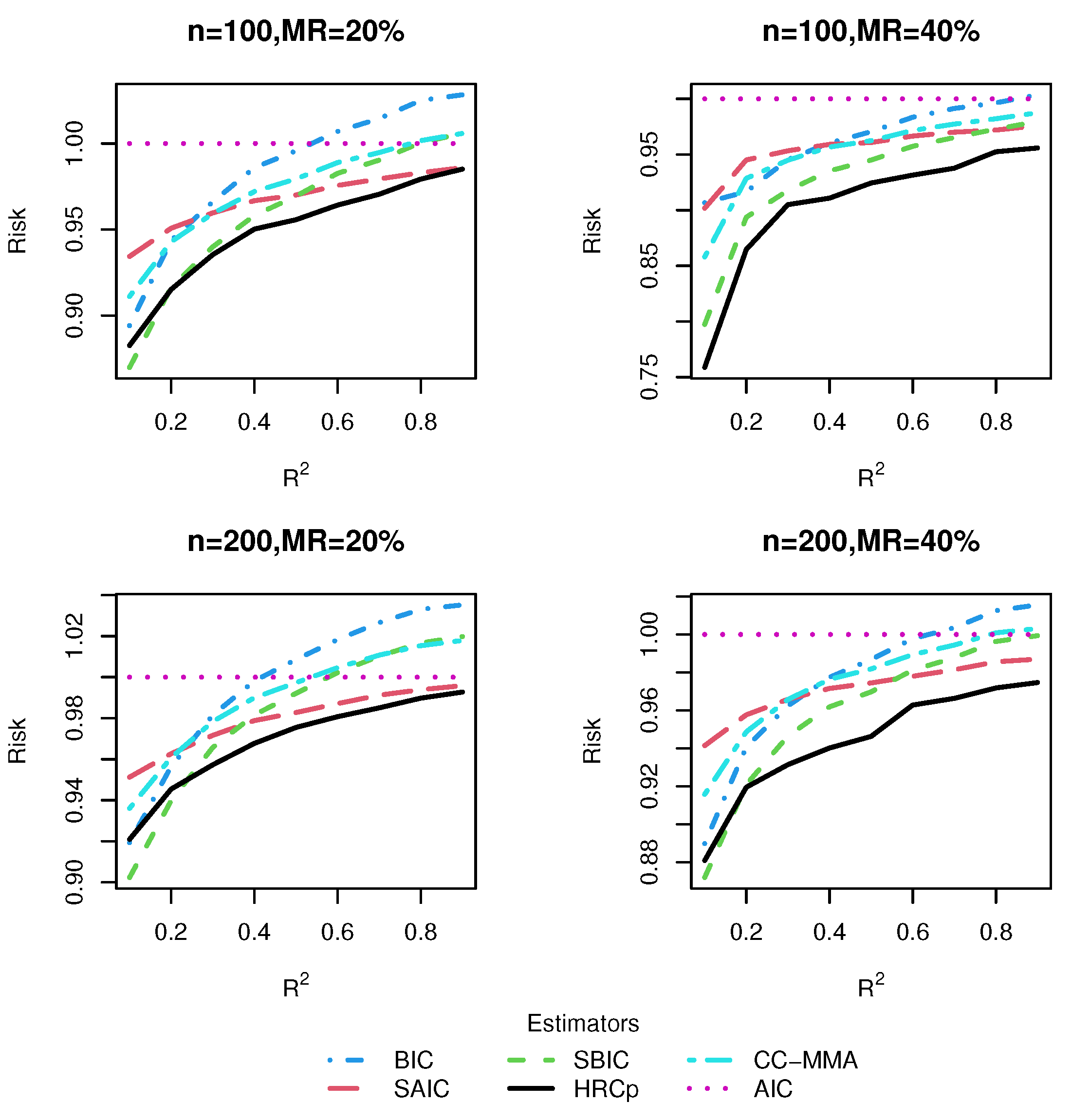
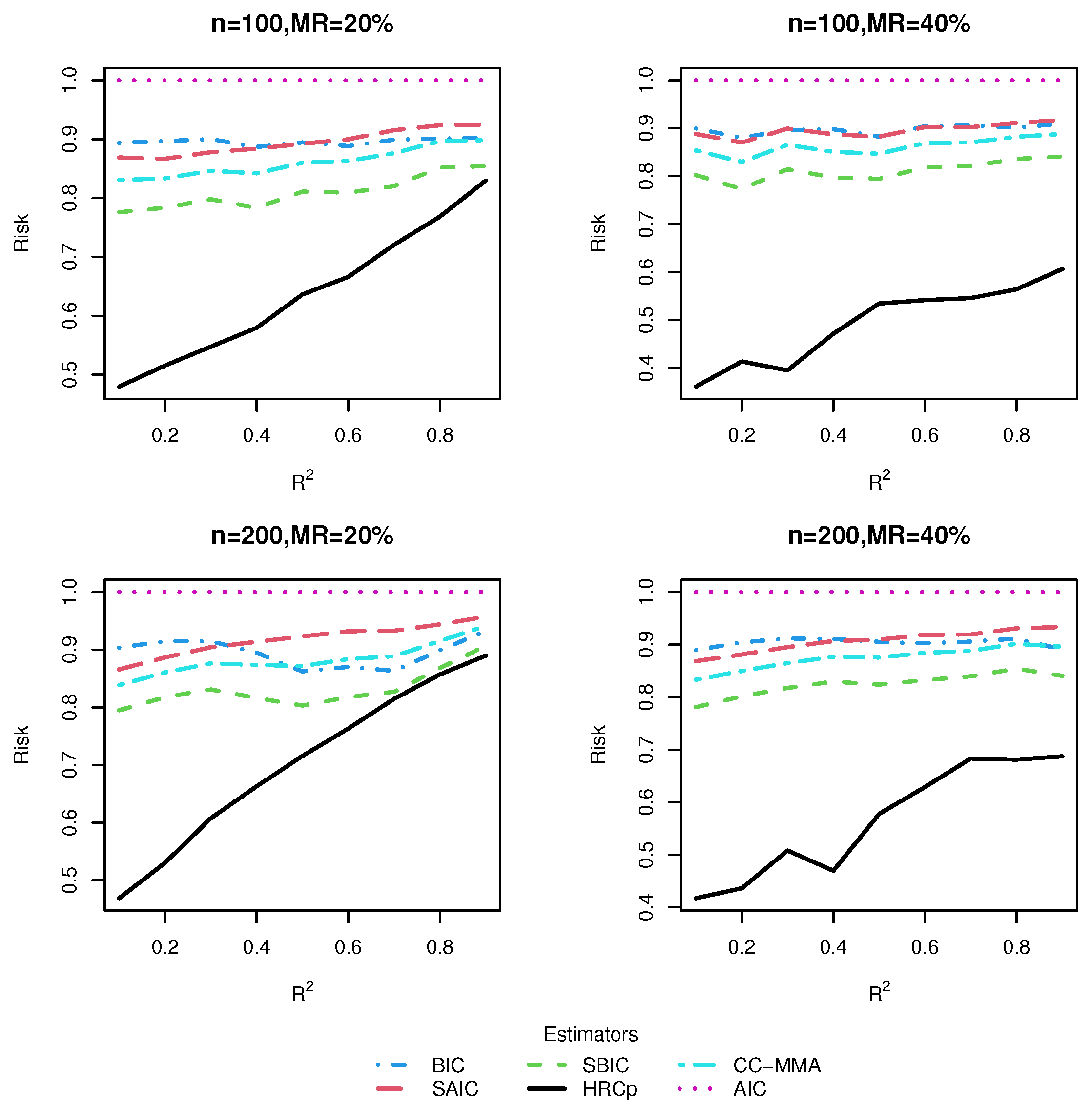
3.3. Simulation Results
3.3.1. Risk Comparison
3.3.2. Computation Time Comparison
4. Real Data Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Hansen, B.E. Least squares model averaging. Econometrica 2007, 75, 1175–1189. [Google Scholar] [CrossRef]
- Wan, A.T.K.; Zhang, X.; Zou, G. Least squares model averaging by Mallows criterion. J. Economet. 2010, 156, 277–283. [Google Scholar] [CrossRef]
- Liang, H.; Zou, G.; Wan, A.T.K.; Zhang, X. Optimal weight choice for frequentist model average estimators. J. Am. Stat. Assoc. 2011, 106, 1053–1066. [Google Scholar] [CrossRef]
- Hansen, B.E.; Racine, J.S. Jackknife model averaging. J. Economet. 2012, 167, 38–46. [Google Scholar] [CrossRef]
- Zhang, X.; Wan, A.T.K.; Zou, G. Model averaging by jackknife criterion in models with dependent data. J. Economet. 2013, 174, 82–94. [Google Scholar] [CrossRef]
- Lu, X.; Su, L. Jackknife model averaging for quantile regressions. J. Economet. 2015, 188, 40–58. [Google Scholar] [CrossRef]
- Liu, Q.; Okui, R. Heteroscedasticity-robust Cp model averaging. Economet. J. 2013, 16, 463–472. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, G.; Carroll, R.J. Model averaging based on Kullback-Leibler distance. Stat. Sinica 2015, 25, 1583–1598. [Google Scholar] [CrossRef] [PubMed]
- Zhu, R.; Zhang, X.; Wan, A.T.K.; Zou, G. Kernel averaging estimators. J. Bus. Econ. Stat. 2022, 41, 157–169. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.A. Model averaging prediction by K-fold cross-validation. J. Economet. 2022, in press. [Google Scholar]
- Zhang, X. Model averaging with covariates that are missing completely at random. Econ. Lett. 2013, 121, 360–363. [Google Scholar] [CrossRef]
- Fang, F.; Lan, W.; Tong, J.; Shao, J. Model averaging for prediction with fragmentary data. J. Bus. Econ. Stat. 2019, 37, 517–527. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Q.; Liu, W. Model averaging for linear models with responses missing at random. Ann. I. Stat. Math. 2021, 73, 535–553. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Q. Cross-validation-based model averaging in linear models with responses missing at random. Stat. Probabil. Lett. 2021, 171, 108990. [Google Scholar] [CrossRef]
- Xie, J.; Yan, X.; Tang, N. A model-averaging method for high-dimensional regression with missing responses at random. Stat. Sinica 2021, 31, 1005–1026. [Google Scholar] [CrossRef]
- Li, Q.; Huang, C.J.; Li, D.; Fu, T.T. Semiparametric smooth coefficient models. J. Bus. Econ. Stat. 2002, 20, 412–422. [Google Scholar] [CrossRef]
- Zhang, W.; Lee, S.Y.; Song, X. Local polynomial fitting in semivarying coefficient model. J. Multivariate Anal. 2002, 82, 166–188. [Google Scholar] [CrossRef]
- Ahmad, I.; Leelahanon, S.; Li, Q. Efficient estimation of a semiparametric partially linear varying coefficient model. Ann. Stat. 2005, 33, 258–283. [Google Scholar] [CrossRef]
- Fan, J.; Huang, T. Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli 2005, 11, 1031–1057. [Google Scholar] [CrossRef]
- Li, R.; Liang, H. Variable selection in semiparametric regression modeling. Ann. Stat. 2008, 36, 261–286. [Google Scholar] [CrossRef]
- Zhao, P.; Xue, L. Variable selection for semiparametric varying coefficient partially linear models. Stat. Probabil. Lett. 2009, 79, 2148–2157. [Google Scholar] [CrossRef]
- Zhao, P.; Xue, L. Variable selection for semiparametric varying coefficient partially linear errors-in-variables models. J. Multivariate Anal. 2010, 101, 1872–1883. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, R.; Liu, J.; Lv, Y. Robust and efficient variable selection for semiparametric partially linear varying coefficient model based on modal regression. Ann. I. Stat. Math. 2014, 66, 165–191. [Google Scholar] [CrossRef]
- Wang, H.; Zou, G.; Wan, A.T.K. Model averaging for varying-coefficient partially linear measurement error models. Electron. J. Stat. 2012, 6, 1017–1039. [Google Scholar] [CrossRef]
- Zeng, J.; Cheng, W.; Hu, G.; Rong, Y. Model averaging procedure for varying-coefficient partially linear models with missing responses. J. Korean Stat. Soc. 2018, 47, 379–394. [Google Scholar] [CrossRef]
- Zhu, R.; Wan, A.T.K.; Zhang, X.; Zou, G. A Mallows-type model averaging estimator for the varying-coefficient partially linear model. J. Am. Stat. Assoc. 2019, 114, 882–892. [Google Scholar] [CrossRef]
- Hjort, N.L.; Claeskens, G. Frequentist model average estimators. J. Am. Stat. Assoc. 2003, 98, 879–899. [Google Scholar] [CrossRef]
- Hu, G.; Cheng, W.; Zeng, J. Model averaging by jackknife criterion for varying-coefficient partially linear models. Commun. Stat.-Theor. M. 2020, 49, 2671–2689. [Google Scholar] [CrossRef]
- Xia, X. Model averaging prediction for nonparametric varying-coefficient models with B-spline smoothing. Stat. Pap. 2021, 62, 2885–2905. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W. Optimal model averaging estimation for partially linear models. Stat. Sinica 2019, 29, 693–718. [Google Scholar] [CrossRef]
- White, J. Maximum likelihood estimation of misspecified models. Econometrica 1982, 50, 1–25. [Google Scholar] [CrossRef]
- Liang, Z.; Chen, X.; Zhou, Y. Mallows model averaging estimation for linear regression model with right censored data. Acta Math. Appl. Sin. E. 2022, 38, 5–23. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, H. Focused information criterion and model averaging for generalized additive partial linear models. Ann. Stat. 2011, 39, 174–200. [Google Scholar] [CrossRef]
- Li, K.C. Asymptotic optimality for Cp, CL, cross-validation and generalized cross-validation: Discrete index set. Ann. Stat. 1987, 15, 958–975. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, D.; Zou, G.; Liang, H. Optimal model averaging estimation for generalized linear models and generalized linear mixed-effects models. J. Am. Stat. Assoc. 2016, 111, 1775–1790. [Google Scholar] [CrossRef]
- Ando, T.; Li, K.C. A weighted-relaxed model averaging approach for high-dimensional generalized linear models. Ann. Stat. 2017, 45, 2654–2679. [Google Scholar] [CrossRef]
- Morris, C.N.; Norton, E.C.; Zhou, X.H. Parametric duration analysis of nursing home usage. In Case Studies in Biometry; Lang, N., Ryan, L., Billard, L., Brillinger, D., Conquest, L., Greenhouse, J., Eds.; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Fan, J.; Lin, H.; Zhou, Y. Local partial-likelihood estimation for lifetime data. Ann. Stat. 2006, 34, 290–325. [Google Scholar] [CrossRef]
- Whittle, P. Bounds for the moments of linear and quadratic forms in independent variables. Theor. Probab. Appl. 1960, 5, 331–335. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design | M | Covariate Setting |
|---|---|---|
| 1 | INT() | All candidate models shared a common nonparametric structure of , and their parametric parts were a set of , with the mth candidate model including the first m covariates. In other words, all of the candidate models were nested. |
| 2 | Identical to Design 1 except that all candidate models were non-nested, and their linear parts were constructed by varying combinations of . | |
| 3 | INT() | Identical to Design 1 except that all candidate models shared a common nonparametric structure of . |
| 4 | Identical to Design 2 except that all candidate models shared a common nonparametric structure of . | |
| 5 | 50 | The covariate set included . Each candidate model included at least one covariate in the linear part and one covariate in the nonparametric part, and each covariate could not exist in both parts. |
| Method | Design 1 | Design 2 | Design 3 | Design 4 | Design 5 |
|---|---|---|---|---|---|
| AIC | 0.213 | 0.223 | 0.220 | 0.223 | 0.248 |
| BIC | 0.220 | 0.229 | 0.219 | 0.218 | 0.247 |
| SAIC | 0.222 | 0.232 | 0.224 | 0.225 | 0.254 |
| SBIC | 0.224 | 0.229 | 0.222 | 0.222 | 0.249 |
| CC-MMA | 0.239 | 0.233 | 0.232 | 0.242 | 0.261 |
| HR | 0.251 | 0.242 | 0.246 | 0.254 | 0.284 |
| Method | BIC | SAIC | SBIC | CC-MMA | HRCp | |
|---|---|---|---|---|---|---|
| 700 | mean | 0.991 | 0.984 | 0.981 | 0.989 | 0.980 |
| median | 0.997 | 0.989 | 0.988 | 0.993 | 0.985 | |
| SD | 0.624 | 0.660 | 0.573 | 0.622 | 0.619 | |
| 800 | mean | 0.993 | 0.987 | 0.985 | 0.990 | 0.982 |
| median | 0.997 | 0.990 | 0.988 | 0.994 | 0.985 | |
| SD | 0.882 | 0.909 | 0.866 | 0.881 | 0.884 | |
| 900 | mean | 0.994 | 0.988 | 0.987 | 0.991 | 0.984 |
| median | 0.995 | 0.989 | 0.988 | 0.992 | 0.986 | |
| SD | 0.827 | 0.861 | 0.792 | 0.847 | 0.836 | |
| 1000 | mean | 0.995 | 0.989 | 0.988 | 0.991 | 0.985 |
| median | 0.997 | 0.989 | 0.989 | 0.992 | 0.986 | |
| SD | 0.890 | 0.885 | 0.883 | 0.888 | 0.876 | |
| 1100 | mean | 0.995 | 0.990 | 0.990 | 0.991 | 0.986 |
| median | 0.998 | 0.993 | 0.991 | 0.992 | 0.990 | |
| SD | 0.968 | 0.968 | 0.957 | 0.966 | 0.939 |
| Method | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 700 | DM | 3.622 | 9.693 | 7.738 | 4.147 | 10.528 | 6.196 | 15.908 | 2.165 |
| p-value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.030 | |
| 800 | DM | 5.345 | 15.916 | 11.589 | 9.472 | 15.832 | 6.216 | 18.979 | 10.863 |
| p-value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 900 | DM | 3.353 | 10.127 | 8.009 | 4.725 | 11.867 | 5.502 | 14.992 | 5.128 |
| p-value | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 1000 | DM | 2.930 | 9.012 | 7.165 | 4.192 | 12.665 | 7.697 | 17.102 | 3.214 |
| p-value | 0.003 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.001 | |
| 1100 | DM | 3.550 | 12.475 | 8.565 | 7.291 | 13.101 | 5.299 | 12.739 | 4.395 |
| p-value | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| Method | |||||||||
| 700 | DM | 9.173 | 3.452 | −4.682 | 6.001 | −7.245 | 0.942 | 11.426 | |
| p-value | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.346 | 0.000 | ||
| 800 | DM | 12.102 | 3.276 | −4.274 | 8.501 | −6.835 | 1.827 | 12.183 | |
| p-value | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.068 | 0.000 | ||
| 900 | DM | 8.740 | 2.935 | −1.231 | 7.078 | −5.352 | 1.301 | 10.278 | |
| p-value | 0.000 | 0.000 | 0.218 | 0.000 | 0.000 | 0.193 | 0.000 | ||
| 1000 | DM | 10.586 | 1.404 | −2.053 | 8.353 | −2.975 | 3.537 | 9.486 | |
| p-value | 0.000 | 0.160 | 0.040 | 0.000 | 0.003 | 0.000 | 0.000 | ||
| 1100 | DM | 9.937 | 1.154 | −0.892 | 7.721 | −1.626 | 4.149 | 11.254 | |
| p-value | 0.006 | 0.249 | 0.372 | 0.000 | 0.104 | 0.000 | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, J.; Cheng, W.; Hu, G. Optimal Model Averaging Estimation for the Varying-Coefficient Partially Linear Models with Missing Responses. Mathematics 2023, 11, 1883. https://doi.org/10.3390/math11081883
Zeng J, Cheng W, Hu G. Optimal Model Averaging Estimation for the Varying-Coefficient Partially Linear Models with Missing Responses. Mathematics. 2023; 11(8):1883. https://doi.org/10.3390/math11081883
Chicago/Turabian StyleZeng, Jie, Weihu Cheng, and Guozhi Hu. 2023. "Optimal Model Averaging Estimation for the Varying-Coefficient Partially Linear Models with Missing Responses" Mathematics 11, no. 8: 1883. https://doi.org/10.3390/math11081883