
Multi-Step Ahead Ex-Ante Forecasting of Air Pollutants Using Machine Learning




Abstract
:1. Introduction
2. Concepts of Multi-Step Ahead Strategies and Literature Review
- Recursive Strategy
- Direct Strategy
- DirRec Strategy
- MIMO Strategy
- DIRMO Strategy
3. Materials and Methods
3.1. Proposed Approach
3.1.1. Single Models
3.1.2. Averaging Models
3.1.3. Framework of the Proposed Strategy
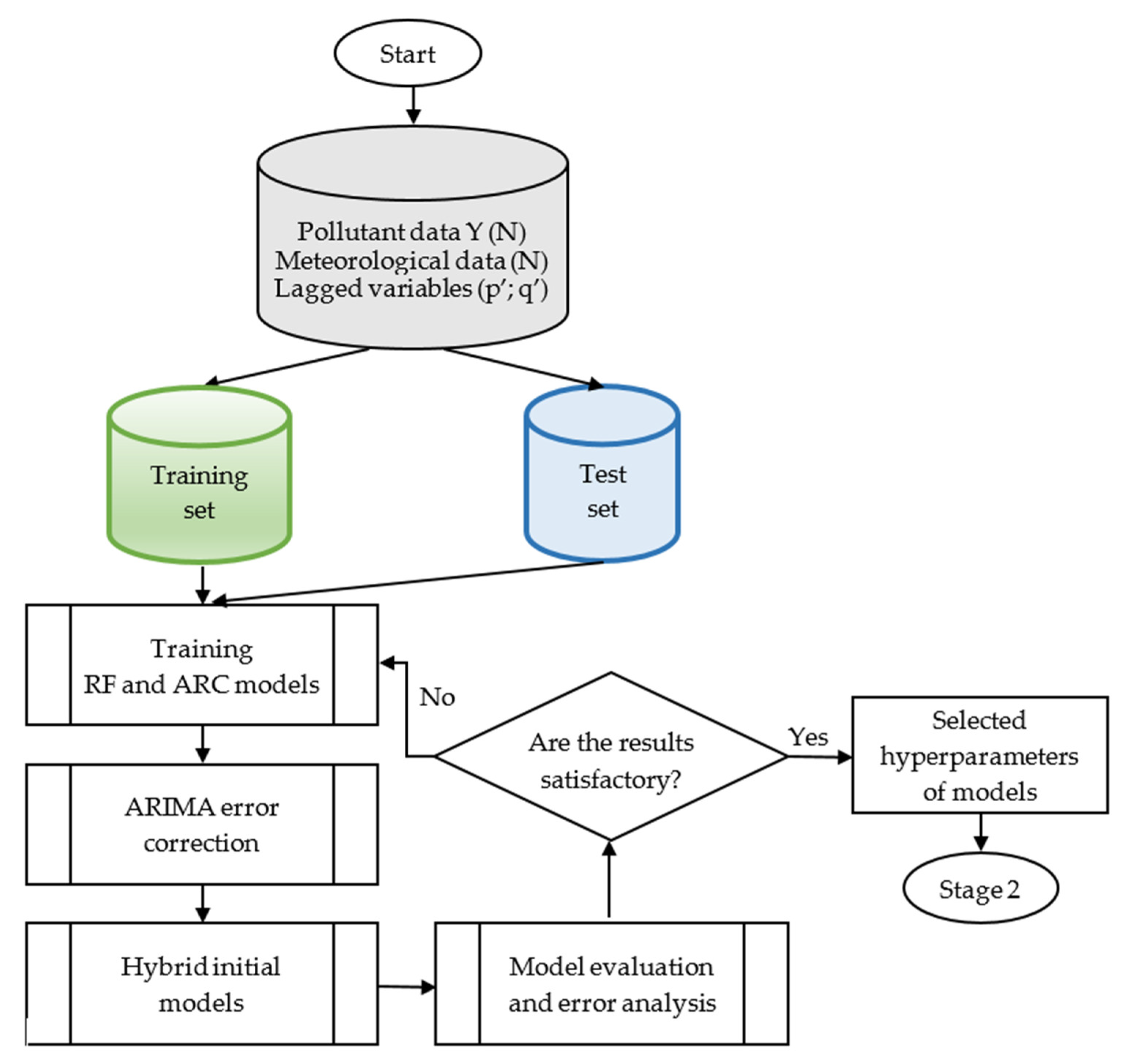
- Stage 1: Generating Initial Models
- Stage 2: Multi-Step Ahead Forecasting
- Construction of single independent models and determining their predictions;
- Calculating averaged predictions (averaging models);
- Evaluation and comparison of the results.
3.2. Model Assumptions
- using the ML regression-type method to construct forecasting models for multivariate time series dependent on predictors;
- predictor variables of qualitative and quantitative type;
- fixed forecasting horizon .
3.3. Methods
- Ensemble Model
- Random Forest
- Arcing
- Autoregressive Moving Average with Transfer Functions
- Hybrid method
3.4. Evaluation Measures
3.5. Study Area and Data
4. Results
4.1. Preliminary Statistical Processing
4.2. Construction and Evaluation of the Initial Hybrid Models
4.3. Results from Stage 2—Multi-Step Forecasting
4.3.1. Construction and Evaluation of the Single Models
4.3.2. Construction and Evaluation of the Averaging Models
4.4. Comparison of the Accuracy Measures of the Forecasts
4.4.1. Comparison among the Two ML Methods
4.4.2. Comparison among the Two Multi-Step Ahead Strategies
5. Discussion with Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization, Regional Office for Europe. 2021. Review of Evidence on Health Aspects of Air Pollution—REVIHAAP Project: Technical Report. Available online: https://www.euro.who.int/__data/assets/pdf_file/0004/193108/REVIHAAP-Final-technical-report-final-version.pdf (accessed on 9 February 2023).
- Gibson, J. Air pollution, climate change, and health. Lancet Oncol. 2015, 16, e269. [Google Scholar] [CrossRef] [PubMed]
- Manisalidis, I.; Stavropoulou, E.; Stavropoulos, A.; Bezirtzoglou, E. Environmental and health impacts of air pollution: A review. Front. Public Health 2020, 8, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajagopalan, S.; Al-Kindi, S.; Brook, R. Air pollution and cardiovascular disease: JACC state-of-the-art review. J. Am. Coll. Cardiol. 2018, 72, 2054–2070. [Google Scholar] [CrossRef] [PubMed]
- Tecer, L.; Alagha, O.; Karaca, F.; Tuncel, G.; Eldes, N. Particulate matter (PM 2.5, PM 10–2.5, and PM 10) and children’s hospital admissions for asthma and respiratory diseases: A bidirectional case-crossover study. J. Toxicol. Environ. Health A 2008, 71, 512–520. [Google Scholar] [CrossRef] [PubMed]
- Sicard, P.; Augustaitis, A.; Belyazid, S.; Calfapietra, C.; de Marco, A.; Fenn, M.; Bytnerowicz, A.; Grulke, N.; He, S.; Matyssek, R.; et al. Global topics and novel approaches in the study of air pollution, climate change and forest ecosystems. Environ. Pollut. 2016, 213, 977–987. [Google Scholar] [CrossRef] [PubMed]
- Ravindra, K.; Rattan, P.; Mor, S.; Aggarwal, A. Generalized additive models: Building evidence of air pollution, climate change and human health. Environ. Int. 2019, 132, 104987. [Google Scholar] [CrossRef]
- Brasseur, G.P.; Jacob, D.J. Modeling of Atmospheric Chemistry; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Barratt, R. Atmospheric Dispersion Modelling: An Introduction to Practical Applications; Routledge: London, UK, 2013. [Google Scholar] [CrossRef]
- Todorov, V.; Dimov, I.; Ostromsky, T.; Zlatev, Z.; Georgieva, R.; Poryazov, S. Optimized quasi-Monte Carlo methods based on Van der Corput sequence for sensitivity analysis in air pollution modelling. In Recent Advances in Computational Optimization. WCO 2020. Studies in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 986, pp. 389–405. [Google Scholar] [CrossRef]
- Ostromsky, T.; Dimov, I.; Georgieva, R.; Zlatev, Z. Air pollution modelling, sensitivity analysis and parallel implementation. Int. J. Environ. Pollut. 2011, 46, 83–96. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, Y.; Lu, J. Exploring the relationship between air pollution and meteorological conditions in China under environmental governance. Sci. Rep. 2020, 10, 14518. [Google Scholar] [CrossRef]
- Holst, J.; Mayer, H.; Holst, T. Effect of meteorological exchange conditions on PM10 concentration. Meteorol. Z. 2008, 17, 273–282. [Google Scholar] [CrossRef] [Green Version]
- Veleva, E.; Zheleva, I. Statistical modeling of particle mater air pollutants in the city of Ruse, Bulgaria. MATEC Web Conf. 2018, 145, 01010. [Google Scholar] [CrossRef] [Green Version]
- Tsvetanova, I.; Zheleva, I.; Filipova, M.; Stefanova, A. Statistical analysis of ambient air PM10 contamination during winter periods for Ruse region, Bulgaria. MATEC Web Conf. 2018, 145, 01007. [Google Scholar] [CrossRef] [Green Version]
- Veleva, E.; Georgiev, R. Seasonality of the levels of particulate matter PM10 air pollutant in the city of Ruse, Bulgaria. AIP Conf. Proc. 2020, 2302, 030006. [Google Scholar] [CrossRef]
- Tsvetanova, I.; Zheleva, I.; Filipova, M. Statistical study of the influence of the atmospheric characteristics upon the particulate matter (PM10) air pollutant in the city of Silistra, Bulgaria. AIP Conf. Proc. 2019, 2164, 120014. [Google Scholar] [CrossRef]
- Siew, L.Y.; Chin, L.Y.; Wee, P.M.J. ARIMA and integrated ARFIMA models for forecasting air pollution index in Shah Alam, Selangor. Malays. J. Analyt. Sci. 2008, 12, 257–263. [Google Scholar]
- Veleva, E.; Zheleva, I. GARCH models for particulate matter PM10 air pollutant in the city of Ruse, Bulgaria. AIP Conf. Proc. 2018, 2025, 040016. [Google Scholar] [CrossRef]
- Lasheras, F.; Nieto, P.; Gonzalo, E.; Bonavera, L.; de Cos Juez, F. Evolution and forecasting of PM10 concentration at the Port of Gijon (Spain). Sci. Rep. 2020, 10, 11716. [Google Scholar] [CrossRef]
- Feng, R.; Zheng, H.J.; Gao, H.; Zhang, A.R.; Huang, C.; Zhang, J.X.; Luo, K.; Fan, J.R. Recurrent Neural Network and random forest for analysis and accurate forecast of atmospheric pollutants: A case study in Hangzhou, China. J. Clean. Prod. 2019, 231, 1005–1015. [Google Scholar] [CrossRef]
- Yazdi, D.; Kuang, Z.; Dimakopoulou, K.; Barratt, B.; Suel, E.; Amini, H.; Lyapustin, A.; Katsouyanni, K.; Schwartz, J. Predicting fine particulate matter (PM2. 5) in the greater London area: An ensemble approach using machine learning methods. Remote Sens. 2020, 12, 914. [Google Scholar] [CrossRef] [Green Version]
- Masih, A. Application of ensemble learning techniques to model the atmospheric concentration of SO2. Glob. J. Environ. Sci. Manag. 2019, 5, 309–318. [Google Scholar] [CrossRef]
- Bougoudis, I.; Iliadis, L.; Papaleonidas, A. Fuzzy inference ANN ensembles for air pollutants modeling in a major urban area: The case of Athens. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Sofia, Bulgaria, 5–7 September 2004; Springer: Cham, Switzerland, 2014; pp. 1–14. [Google Scholar] [CrossRef]
- Zhai, B.; Chen, J. Development of a stacked ensemble model for forecasting and analyzing daily average PM2.5 concentrations in Beijing, China. Sci. Total. Environ. 2018, 635, 644–658. [Google Scholar] [CrossRef]
- Wang, P.; Liu, Y.; Qin, Z.; Zhang, G. A novel hybrid forecasting model for PM10 and SO2 daily concentrations. Sci. Total. Environ. 2015, 505, 1202–1212. [Google Scholar] [CrossRef] [PubMed]
- Dairi, A.; Harrou, F.; Khadraoui, S.; Sun, Y. Integrated multiple directed attention-based deep learning for improved air pollution forecasting. IEEE Trans. Instrum. Meas. 2021, 70, 3520815. [Google Scholar] [CrossRef]
- Sayegh, A.; Munir, S.; Habeebullah, T. Comparing the Performance of Statistical Models for Predicting PM10 Concentrations. Aerosol. Air Qual. Res. 2014, 14, 653–665. [Google Scholar] [CrossRef] [Green Version]
- Sethi, J.K.; Mittal, M. A new feature selection method based on machine learning technique for air quality dataset. J. Stat. Manag. Syst. 2019, 22, 697–705. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, H.; Duan, Z. A novel hybrid model for multi-step daily AQI forecasting driven by air pollution big data. Air. Qual. Atmos. Health 2020, 13, 197–207. [Google Scholar] [CrossRef]
- Pankratz, A. Forecasting with Dynamic Regression Models; John Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Firmino, P.R.A.; de Mattos Neto, P.S.; Ferreira, T.A. Error modeling approach to improve time series forecasters. Neurocomputing 2015, 153, 242–254. [Google Scholar] [CrossRef]
- Gocheva-Ilieva, S.; Voynikova, D.; Stoimenova, M.; Ivanov, A.; Iliev, I. Regression trees modeling of time series for air pollution analysis and forecasting. Neural Comput. Appl. 2019, 31, 9023–9039. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approaches for outdoor air quality modelling: A systematic review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef] [Green Version]
- Masih, A. Machine learning algorithms in air quality modeling. Glob. J. Environ. Sci. Manag. 2019, 5, 515–534. [Google Scholar] [CrossRef]
- Ganchev, I.; Ji, Z.; O’Droma, M. A generic multi-service cloud-based IoT operational platform-EMULSION. In Proceedings of the 2019 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Athens, Greece, 8–10 December 2019. [Google Scholar] [CrossRef]
- Cheng, H.; Tan, P.-N.; Gao, J.; Scripps, J. Multistep-ahead time series prediction. Lect. Notes Comput. Sci. 2006, 3918, 765–774. [Google Scholar] [CrossRef]
- Taieb, S.B.; Bontempi, G.; Atiya, A.F.; Sorjamaa, A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst. Appl. 2012, 39, 7067–7083. [Google Scholar] [CrossRef] [Green Version]
- Ahani, I.; Salari, M.; Shadman, A. Statistical models for multi-step-ahead forecasting of fine particulate matter in urban areas. Atmos. Pollut. Res. 2019, 10, 689–700. [Google Scholar] [CrossRef]
- Ahani, I.K.; Salari, M.; Shadman, A. An ensemble multi-step-ahead forecasting system for fine particulate matter in urban areas. J. Clean. Prod. 2020, 263, 120983. [Google Scholar] [CrossRef]
- Kang, I.-B. Multi-period forecasting using different models for different horizons: An application to U.S. economic time series data. Int. J. Forecast. 2003, 19, 387–400. [Google Scholar] [CrossRef]
- Liu, H.; Duan, Z.; Chen, C. A hybrid framework for forecasting PM2.5 concentrations using multi-step deterministic and probabilistic strategy. Air. Qual. Atmos. Health 2019, 12, 785–795. [Google Scholar] [CrossRef]
- Vassallo, D.; Krishnamurthy, R.; Sherman, T.; Fernando, H. Analysis of random forest modeling strategies for multi-step wind speed forecasting. Energies 2020, 13, 5488. [Google Scholar] [CrossRef]
- Galicia, A.; Talavera-Llames, R.; Troncoso, A.; Koprinska, I.; Martínez-Álvarez, F. Multi-step forecasting for big data time series based on ensemble learning. Knowl.-Based Syst. 2019, 163, 830–841. [Google Scholar] [CrossRef]
- Mustakim, R.; Mamat, M.; Yew, H.T. Towards on-site implementation of multi-step air pollutant index prediction in Malaysia industrial area: Comparing the NARX neural network and support vector regression. Atmosphere 2022, 13, 1787. [Google Scholar] [CrossRef]
- Air Quality Standards, European Commission. Environment. Available online: https://www.eea.europa.eu/themes/air/air-quality-concentrations/air-quality-standards (accessed on 9 February 2023).
- Ren, Y.; Zhang, L.; Suganthan, P.N. Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput. Intell. Mag. 2016, 11, 41–53. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breiman, L. Arcing classifiers. Ann. Stat. 1998, 26, 801–824. [Google Scholar]
- Khanchel, R.; Limam, M. Empirical comparison of boosting algorithms. In Classification—The Ubiquitous Challenge. Studies in Classification, Data Analysis, and Knowledge Organization; Weihs, C., Gaul, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 161–167. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comp. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Bauer, E.; Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Schmidt, A.F.; Finan, C. Linear regression and the normality assumption. J. Clinic. Epidem. 2018, 98, 146–151. [Google Scholar] [CrossRef] [Green Version]
- Bliemel, F. Theil’s forecast accuracy coefficient: A clarification. J. Mark. Res. 1973, 10, 444–446. [Google Scholar] [CrossRef]
- Willmott, C. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Armstrong, J.S. Principles of Forecasting: A Handbook for Researchers and Practitioners; Kluwer Academic: Boston, MA, USA, 2001. [Google Scholar]
- SPM—Salford Predictive Modeler. 2022. Available online: https://www.minitab.com/enus/products/spm/ (accessed on 9 February 2023).
- IBM SPSS Statistics 29. 2022. Available online: https://www.ibm.com/products/spss-statistics (accessed on 9 February 2023).
- Yordanova, L.; Kiryakova, G.; Veleva, P.; Angelova, N.; Yordanova, A. Criteria for selection of statistical data processing software. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1031, 012067. [Google Scholar] [CrossRef]
- RIOSV Pernik: Monthly Monitoring of Atmospheric Air: Monthly Report on the Quality of Atmospheric air of Pernik according to Data from Automatic Measuring Station “Pernik-Center”. Available online: http://pk.riosv-pernik.com/index.php?option=com_content&view=category&id=29:monitoring&Itemid=28&layout=default (accessed on 9 February 2023). (In Bulgarian).
- Pernik Historical Weather. Available online: https://www.worldweatheronline.com/pernik-weather-history/pernik/bg.aspx (accessed on 9 February 2023).
- Yadav, S.; Shukla, S. Analysis of k-fold cross-validation over hold-out validation on colossal datasets for quality classification. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; pp. 78–83. [Google Scholar] [CrossRef]
- Ljung, G.; Box, G. On a measure of lack of fit in time series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Fischer, B.; Planas, C. Large scale fitting of regression models with ARIMA errors. J. Off. Stat. 2000, 16, 173–184. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| s, Model (s) | (s = 1) | (s = 2) | (s = 3) | (s = 4) | (s = 5) | (s = 6) | (s = 7) | (s = 8) | (s = 9) | (s = 10) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| t | ||||||||||||
| t + 1 | ||||||||||||
| t + 2 | ||||||||||||
| t + 3 | ||||||||||||
| t + 4 | ||||||||||||
| t + 5 | ||||||||||||
| t + 6 | ||||||||||||
| t + 7 | ||||||||||||
| t + 8 | ||||||||||||
| t + 9 | ||||||||||||
| t + 10 | ||||||||||||
| … | … | … | … | … | … | |||||||
| Variable | PM10 (μg/m3) | SO2 (μg/m3) | NO2 (μg/m3) | MaxT (°C) | MinT (°C) | Speed (m/s) | Humidity (%) | Pressure (mbar) | Cloud (%) | Precipi (mm) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Statistics | |||||||||||
| Valid | 1411 | 1431 | 1434 | 1481 | 1481 | 1481 | 1481 | 1481 | 1481 | 1481 | |
| Missing | 70 | 50 | 47 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Mean | 36.49 | 27.06 | 41.58 | 17.77 | 10.04 | 2.0004 | 0.694 | 1017.67 | 0.3197 | 1.759 | |
| Median | 27.00 | 17.00 | 35.00 | 19.00 | 10.00 | 1.9400 | 0.700 | 1017.00 | 0.2500 | 0.000 | |
| Std. Deviation | 30.309 | 45.114 | 28.920 | 10.527 | 10.243 | 0.8576 | 0.142 | 7.068 | 0.2629 | 4.0538 | |
| Variance | 918.626 | 2035.244 | 836.351 | 110.815 | 104.914 | 0.736 | 0.020 | 49.957 | 0.069 | 16.433 | |
| Skewness | 2.623 | 10.198 | 1.543 | −0.151 | −0.186 | 1.382 | −0.088 | 0.248 | 0.707 | 4.284 | |
| Kurtosis | 8.384 | 158.460 | 4.456 | −0.925 | −0.666 | 4.127 | −0.747 | 0.463 | −0.536 | 26.605 | |
| Minimum | 2 | 1 | 0 | −13 | −27 | 0.28 | 0.31 | 990 | 0.00 | 0.0 | |
| Maximum | 219 | 916 | 262 | 38 | 30 | 7.50 | 0.98 | 1039 | 1.00 | 44.0 | |
| Day | Direction$ | Direction$_f | Day | Direction$ | Direction$_f |
|---|---|---|---|---|---|
| 1 | ESE | ESE | 6 | SW | SE |
| 2 | SE | SSE | 7 | S | SE |
| 3 | WSW | NNE | 8 | S | SSW |
| 4 | NE | NNE | 9 | ESE | W |
| 5 | NNW | N | 10 | SSW | S |
| Statistic | Pollutant Variables | Initial Hybrid Models | |||||||
|---|---|---|---|---|---|---|---|---|---|
| YPM10 | YSO2 | YNO2 | hTRF_P | hTAR_P | hTRF_S | hTAR_S | hTRF_N | hTAR_N | |
| Mean | 36.1249 | 25.4146 | 41.3707 | 36.046 | 36.306 | 25.377 | 25.730 | 41.283 | 42.244 |
| Median | 27.00 | 17.00 | 35.00 | 28.540 | 28.056 | 17.859 | 17.422 | 37.640 | 37.615 |
| Std. Dev. | 29.562 | 29.064 | 27.973 | 25.996 | 27.792 | 25.190 | 27.295 | 23.217 | 24.390 |
| Variance | 873.913 | 844.717 | 782.463 | 675.8 | 772.38 | 634.548 | 745.001 | 539.031 | 594.885 |
| Skewness | 2.551 | 2.932 | 1.281 | 2.412 | 2.632 | 2.355 | 2.892 | 1.058 | 1.241 |
| Kurtosis | 7.694 | 11.985 | 2.183 | 6.806 | 8.178 | 6.905 | 11.324 | 1.562 | 2.141 |
| Minimum | 2 | 1 | 0 | 6.311 | 8.295 | 0.379 | 0.457 | 0 | 0 |
| Maximum | 190 | 215 | 160 | 176.071 | 185.111 | 171.522 | 202.785 | 142.038 | 149.649 |
| Statistic | Initial Hybrid Models | |||||
|---|---|---|---|---|---|---|
| hTRF_P | hTAR_P | hTRF_S | hTAR_S | hTRF_N | hTAR_N | |
| Variable | YPM10 | YPM10 | YSO2 | YSO2 | YNO2 | YNO2 |
| ARIMA/TF | (2,0,14) | (1,0,3) | (1,0,5) | (0,0,11) | (1,0,21) | (2,0,21) |
| Ljung-Box Sig. | 0.231 | 0.454 | 0.905 | 0.304 | 0.360 | 0.154 |
| RMSE | 8.3182 | 6.0339 | 8.9356 | 7.2069 | 10.0499 | 8.9468 |
| NMSE | 0.0792 | 0.0417 | 0.0946 | 0.0615 | 0.1292 | 0.1024 |
| FB | −0.0006 | −0.005 | 0.001 | −0.0123 | 0.0013 | −0.0209 |
| Uii | 0.0046 | 0.0034 | 0.006 | 0.0049 | 0.0052 | 0.0047 |
| IA | 0.99998 | 0.99999 | 0.99998 | 0.99999 | 0.99997 | 0.99998 |
| R2 | 0.932 | 0.960 | 0.932 | 0.966 | 0.884 | 0.905 |
| Statistic | RF_P, AR_P | RF_S, AR_S | RF_N, AR_N | aRF_P, aAR_P | aRF_S, aAR_S | aRF_N, aAR_N |
|---|---|---|---|---|---|---|
| RMSE | 0.897 | 0.676 | 0.676 | 0.912 | 0.676 | 0.603 |
| NMSE | 0.838 | 0.382 | 0.397 | 0.926 | 0.368 | 0.412 |
| FB | 0.853 | 0.941 | 0.824 | 1.000 | 0.926 | 0.926 |
| Uii | 0.662 | 0.029 a | 0.368 | 0.750 | 0.091 a | 0.809 |
| IA | 0.618 | 0.471 | 0.574 | 0.706 | 0.647 | 0.029 a |
| Statistic | RF_P, aRF_P | AR_P, aAR_P | RF_S, aRF_S | AR_S, aAR_S | RF_N, aRF_N | AR_N, aAR_N |
|---|---|---|---|---|---|---|
| RMSE | 0.794 | 0.691 | 0.809 | 0.809 | 0.426 | 0.647 |
| NMSE | 0.824 | 0.794 | 0.647 | 0.779 | 0.309 | 0.618 |
| FB | 0.912 | 0.794 | 0.956 | 0.912 | 0.987 | 0.794 |
| Uii | 0.603 | 0.662 | 0.706 | 0.632 | 0.750 | 0.485 |
| IA | 0.338 | 0.544 | 0.294 | 0.088 a | 0.632 | 0.324 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gocheva-Ilieva, S.; Ivanov, A.; Kulina, H.; Stoimenova-Minova, M. Multi-Step Ahead Ex-Ante Forecasting of Air Pollutants Using Machine Learning. Mathematics 2023, 11, 1566. https://doi.org/10.3390/math11071566
Gocheva-Ilieva S, Ivanov A, Kulina H, Stoimenova-Minova M. Multi-Step Ahead Ex-Ante Forecasting of Air Pollutants Using Machine Learning. Mathematics. 2023; 11(7):1566. https://doi.org/10.3390/math11071566
Chicago/Turabian StyleGocheva-Ilieva, Snezhana, Atanas Ivanov, Hristina Kulina, and Maya Stoimenova-Minova. 2023. "Multi-Step Ahead Ex-Ante Forecasting of Air Pollutants Using Machine Learning" Mathematics 11, no. 7: 1566. https://doi.org/10.3390/math11071566