1. Introduction
Machine learning is now widely used in computer science research and practical industrial applications, generating huge social impact and economic benefits. In particular, convolutional neural networks have great potential in the field of image processing, such as face recognition [
1,
2,
3] and speech recognition [
4]. Due to their wide applicability, service providers are starting to rent neural networks as a commodity for their services. In this scenario, the model is pre-trained by the service provider and the client simply uploads their own private data to obtain the desired output.
With the advent of the digital age, massive data infrastructures are being built and sensitive data is being generated. The end-to-end communication between the client and the service provider can create security vulnerabilities, allowing the leakage of the private data owned by the client as well as model parameters trained by the service provider at great human and material cost [
5]. Therefore, there is a need to protect the privacy of parties during the inference process, and neural networks that supports secure computation become a hot topic of current research.
Secure multi-party computation (SMC) offers a promising solution for privacy-preserving neural network, which originates from the Millionaire’s Problem proposed by Yao in 1982 [
6]. In the SMC framework, collaborating parties do not reveal their private data to each other. Depending on the number of members involved in the protocol, current research is divided into (1) two-party secure computation (2PC) [
7,
8,
9,
10]; (2) three-party secure computation (3PC) [
11,
12,
13,
14,
15]; and (3) four-party secure computation (4PC) [
16,
17].
SecureML [
18] is based on a two-server model and relies on techniques such as oblivious transfer [
19] and garbled circuits to support secure computation of shared decimal numbers, implementing protocols for various machine learning algorithms such as linear regression, logistic regression and neural networks. A hybrid protocol framework is proposed in [
20] that effectively combines arithmetic sharing, boolean sharing and Yao’s garbled circuits to provide a solution for 2PC problem, which is known as ABY. Chandran et al. [
21] build a compiler based on ABY to convert easy-to-write and high-level programs into efficient 2PC protocols using boolean or arithmetic circuits for better performance. Agrawal et al. [
22] combine boolean sharing and arithmetic sharing to propose a ternary matrix-vector multiplication protocol with correlated oblivious transfer, and design a new fixed-point optimisation algorithm through a floating-point adaptive gradient optimisation procedure to improve prediction efficiency.
Homomorphic encryption is also an effective mean of protecting privacy, which is often used in 2PC. The first to use homomorphic encryption for secure inference is the CryptoNet [
23] framework, where the user encrypts his private data and uploads it to the cloud server, which performs the corresponding computation directly on the ciphertext and returns the resulting ciphertext. The data exists in ciphertext form, which protects the user’s privacy. However, in this framework, the non-linear layer needs to be calculated by approximation, e.g., the activation function is replaced by a square function, and therefore the accuracy of the model may be reduced due to the difference between the approximation function and the original function. Researches [
24,
25,
26,
27,
28] based on this are very computationally expensive and have high latency due to the limitations of homomorphic encryption itself, so further improvements are still needed, e.g., in combination with secret sharing or garbled circuits. Gazelle [
29] combines garbled circuits with homomorphic encryption to achieve homomorphic linear algebraic kernel which maps neural network layers to optimized homomorphic matrix multiplication and convolution computation, improving the inference time of neural networks. Delphi [
30] builds on Gazelle and proposes a new planner that automatically generates neural network architecture configurations to navigate the trade-off between performance and accuracy to further improve performance.
Araki et al. [
31] propose a 3PC framework for boolean circuits with honest majorities, which is secure in the presence of semi-honest adversaries. Furukawa et al. [
32] build on this by constructing beaver multiplication triples [
33] to verify the correctness of the computation, making the protocol secure in the presence of malicious adversaries at most one party. Mohassel et al. propose a three-server model, namely the ABY3 [
34], which generalises and optimises the conversion between arithmetic sharing, binary sharing and Yao’s garbled circuits on the basis of ABY, and propose new techniques for fixed-point multiplication with shared decimal values. Chameleon [
35] is a hybrid protocol framework that utilises additive secret sharing, garbled circuits and the Goldreich-Micali-Wigderson (GMW) protocol [
36] to improve performance, and introduces a semi-honest third party to design a more efficient oblivious transfer protocol for arithmetic triples. SecureNN [
37] studies the computation of forward prediction and backpropagation training for deep learning models in a three-party computation environment, using only arithmetic addition and secret sharing, eliminating expensive cryptographic operations and guaranteeing semi-honest security. Malicious security is also presented in that paper, but the computation of its protocol is not accurate in this security setting. Falcon [
38] proposes an end-to-end 3PC protocol for neural networks training and inference based on the ideas of SecureNN and ABY3, improving performance and ensuring semi-honest as well as malicious security, which is the main reference of this paper.
Trident [
39] is a privacy-preserving machine learning framework that implements a four-server model. The fourth party in the protocol is inactive in the online phase except for input sharing and output reconstruction. Flash [
40] guarantees output delivery security (all parties get the output regardless of the behaviour of the adversary), and optimises the dot product protocol to make its computation independent of vector size as well as truncation and highest significant bit extraction algorithms. QuantizedNN [
41] proposes an efficient privacy-preserving machine learning framework using the quantization scheme of Jacob et al. [
42], and provides protocols under the semi-honest or malicious security setting.
In the above studies, the 2PC [
18,
20,
21,
22] requires both parties involved in the protocol to be semi-honest. The 4PC [
39,
40,
41] is not of practical importance due to the limitation of the number of computing servers. Instead, the 3PC [
32,
34,
37,
38] is considered to be one of the most promising framework available due to its security and efficiency. The main techniques include secret sharing, garbled circuits [
43], homomorphic encryption, GMW protocol, etc. Each technique has its advantages and disadvantages, for example, homomorphic encryption has the highest computational complexity, while secret sharing requires the least bandwidth compared to garbled circuits or GMW protocol. Therefore, we mainly use secret sharing to build a 3PC framework for privacy-preserving neural network prediction. Our contributions are shown below.
A neural network prediction model for three-party secure computation is constructed. Experiments are conducted on pre-trained different model architectures with the MNIST dataset, achieving an accuracy of 96.64%, 97.04%, 98.70% and 96.50%, respectively, with errors of no more than 1% from the results predicted directly on the plaintext.
We define two security models. In the semi-honest environment, collaborators behave honestly, performing calculations according to the protocol and ensuring that they do not learn the shares held by the remaining parties. In the malicious environment, the protocol is terminated if malicious activity is detected, ensuring correct computation. Depending on the application scenario and performance requirements, the choice between the two security environments can be made.
New sub-protocol algorithms for neural networks are designed using secret sharing, and they can be combined to construct secure prediction modelwith different combinations, it was possible to construct secure prediction model, improving the time required for prediction and the cost of communication compared to previous work.
The rest of the paper is structured as follows:
Section 2 focuses on the relevant theoretical knowledge;
Section 3 introduces the prediction framework and the sub-protocol algorithms for the neural network;
Section 4 presents the experimental results; and
Section 5 provides the conclusion.
3. Framework and Protocols
In this section, we describe the prediction model for 3PC, the basic operations and some sub-protocols for the fully connected, convolutional, activation and pooling layers over replicated secret sharing.
3.1. Overview of the Framework
In this paper, we focus on the prediction phase of neural networks, where users query inference results by leasing pre-trained models. Our proposed 3PC prediction model consists of three roles, as shown in
Figure 1. One is the data owner
, which applies its own private data to the leased model; the second is the service provider
, which provides pre-trained network models for users to perform query services; and the last is the helper service
, which performs auxiliary computations.
First, shares private data and shares model parameters in the form of 2-out-of-3 replicated secret sharing, where and are both 2-out-of-3 replicated secret sharing of 0. Afterwards, the three parties jointly use their shared data for inference. The result is also in sharing form. Finally, the communicates with the and reconstructs to obtain the final inference result. In this way, the user’s input data, the specific parameters of the model, and the final inference output are all in secret sharing form, and no information about the original data can be leaked by any of the parties’ shares, thus allowing for complete privacy.
In most of the current studies [
31,
34,
38], outsourced cloud computers are used to perform SMC. Therefore, the computation volume of each computer as well as its security assumptions are the same, while in proposed model,
, as the service renter, is semi-honest and does not modify the data in order to get the final expected value. Therefore, the proposed model has the following two definitions of security, based on the security assumptions of the party
and
.
Definition 1. The model is defined as a semi-honest security model if both and are semi-honest.
Definition 2. The model is defined as a malicious security model if or is malicious.
In the semi-honest security model, the parties will obey the protocol but will attempt to learn the shares owned by the remaining parties from the results of the intermediate calculations received. In a malicious security model, the malicious party may corrupt the correctness of the protocol by tampering with the intermediate data so that the model does not achieve the desired result. Therefore, we need a method of validation to ensure that the protocol can proceed correctly.
3.2. Basic Operation
Linear calculations. Assuming that a, b, c are common constant and , are secret sharing, then the sharing of the linear calculation can be expressed as , , . The addition between secret sharing can be added directly corresponding to shares, whereas constant addition only requires adding the constant to a certain share. Constant multiplication requires that each share be multiplied by the constant. These three operations only need to be calculated locally without interaction, so does not require a security algorithm.
Multiplication. Let and , then a total of two steps are required to obtain the secret sharing of . First, party computes locally, which gets the 3-out-of-3 secret sharing of z, i.e., , , , which is defined as . Afterwards, the party sends share to party , which gets the 2-out-of-3 replicated secret sharing of z, i.e., , where a 3-out-of-3 secret sharing of 0 is added for blinding to ensure the security of the data.
In the malicious security model, the information sent by
and
could be changed, so validation means need to be added to ensure the correctness of the data, as shown in Algorithm 1. An additional uniformly distributed tuple
is needed, which
.
| Algorithm 1 Multiplication protocol |
-
Input: shares of and held by , , and . -
Output: shares of held by , , and . -
Common Randomness: 3-out-of-3 secret sharing of 0, 2-out-of-3 replicated secret sharing of 0, and uniformly distributed tuple , where . - 1:
for , computes locally . - 2:
for , computes , , , and . These calculations can be performed locally. - 3:
for , sends to in the malicious security model, while only needs to send to in the semi-honest security model. - 4:
computes . Output ⊥ if , otherwise, continue the protocol. - 5:
computes locally . - 6:
transmits to . - 7:
return.
|
Theorem 1. The protocol described in Algorithm 1 allows for correct and secure operation of the multiplication functionality.
Proof of Theorem 1. In step 1 and 2, there are
,
,
,
,
,
, then
So in step 4,
, which means the messages sent by
and
are correct, without being tempered, and can continue to be calculated. Otherwise, terminal the protocol. Thus, in step 5,
can correctly calculate
and send the share to get
after adding the random number. The introduction of common randomness during the transmission ensures the security of the data in Algorithm 1. □
Reconstruction. In the semi-honest security model, denoted by for 2-out-of-3 replicated secret sharing of 0, sends to , then the party has shares , , and , which can be recovered by computing to recover the global value x, which only need 1 round communication and 1 message. In the malicious security model, because and may tamper with the data, in order to ensure the correctness of the final result, it is necessary for and to transmit both to . judges the received messages, and if the two messages are equal, it means that the correct value is transmitted in this round of communication without tampering, and the subsequent calculation can be continued. Otherwise, it is immediately terminated.
3.3. Fully Connected Layer
The computation of the fully connected layer is a matrix multiplication such that the input
and the weight
, then the output
. Since the addition calculation can be performed directly locally, the main focus is on the multiplication between the shares and the matrix multiplication based on it. We use a fixed-point algorithm (as shown in Section 5.1 of [
34]), so the matrix multiplication result needs to be truncated in the protocol
, which is shown in Algorithm 2, to ensure that the accuracy of the input and output remains consistent.
The two secret sharing of input are , and the sharing of output is . The protocol needs to generate a pair of shared random numbers , where (Each element of the matrix is divided by , d indicates the precision bit of the input). First, the parties compute locally , where . After that, transmits the blinded with to , and transmits the blinded with to , ensuring the privacy of the shared values in transmission. receives the messages from and and performs an addition operation for reconstruction, as shown in Line 5, to obtain the blinded , so that the parameter of the party cannot be calculated by . Because multiplication leads to a larger precision of the result, the truncation algorithm is needed to reduce the precision. In order to get the output sharing, needs to blind Z and send it to , then the final 2-out-of-3 replicated secret sharing is obtained.
In the malicious security model, similarly, an additional uniformly distributed tuple
is needed, which
, to ensure the correctness of the data.
| Algorithm 2 Matrix Multiplication protocol |
-
Input: shares of and held by , , and . -
Output: shares of held by , , and . -
Common Randomness:truncation pair of shared random number , where , and uniformly distributed tuple , where . - 1:
for , computes locally , . - 2:
for , computes , , , and . These calculations can be performed locally. - 3:
for , transmits to in the malicious security model, while only needs to send to in the semi-honest security model. - 4:
computes . Output ⊥ if , otherwise, continue the protocol. - 5:
computes and truncates . - 6:
transmits to . - 7:
return.
|
Theorem 2. The protocol described in Algorithm 2 allows for correct and secure operation of the matrix multiplication functionality.
Proof of Theorem 2. The proof of the theorem proceeds similarly to Theorem 1. □
3.4. Convolutional Layer
The convolution computation can be viewed as the merging of multiple matrix multiplications, so the convolution can be expanded into a matrix of larger dimensionality. Suppose the convolution calculation between an input image of
and a kernel of size
(with the step of 1) can be converted into a matrix multiplication between
and
, which as follows.
Then we can call the protocol directly to calculate it.
3.5. Wrap Function
The definition of the
functions
,
and
is given below, which can compute the carry efficiently when the shared values are summed as integers.
Next, we describe the relationship between the most significant bit of a and function on the secret sharing . Note that and is a share within modulo L, and we can see the most significant bit , where c is the carry of the previous index. The key insight here is that ignoring the most significant bit of , the carry c of the previous index is obtained by performing the function on with modulo . Furthermore, this operation is equivalent to performing function on with modulo L. That is, .
The
function can be computed directly locally and therefore does not require a security algorithm. In addition, the
function allows us to write the following exact integer equation: if
, then
. Where the former is a congruence relation and the latter is an integer relation which is exactly equal. Finally, Algorithm 3 gives the
protocol on the 2-out-of-3 replicated secret sharing of
a. It is necessary to blind the transmitted data in the communication to ensure data security, so two 2-out-of-3 replicated secret sharing of 0, denoted by
and
, are introduced.
| Algorithm 3 Wrap protocol |
-
Input: shares of held by , , and . -
Output: shares of a bit held by , , and , where . -
Common Randomness: (random shares of 0), where , and (a bit random shares of 0). - 1:
for , computes locally and . - 2:
In the semi-honest security setting, sends to . While in the malicious security setting, sends to and sends to . - 3:
In the malicious security setting, first needs to judge whether the hash value of from is equal to from . Output ⊥ if it is not equal, otherwise, continue the protocol. - 4:
computes and sends to . - 5:
return.
|
Theorem 3. The protocol described in Algorithm 3 allows for correct and secure operation of the functionality.
Proof of Theorem 3. The following equations exist in Algorithm 3:
where
,
and
represent the exact
function, Equations (4), (5) and (7) follow the definition of the exact
function, while Equation (
6) follows the definition of the
function. because
and
, so
. From the Eqs.4-7 we can get
Equation (
8) modulo 2 is operated to get
, which is used to calculate the
in Algorithm 3. Similarly, in the malicious security model, the verification method in step 3 ensures that the data is correct, so the protocol
is correct. In addition, the introduction of random numbers ensures the security of Algorithm 3. □
3.6. ReLU Activation Layer
In the decimal real number field, the activation function is defined as if , otherwise, . Under the C++ data type representation on the ring , indicates a negative number whose most significant bit , and indicates a positive number whose most significant bit . Therefore, when using fixed-point encoding, the definition of can be converted as follows: if , , otherwise, , i.e., .
When the secret shared values of
x are known, the most significant bit
is given as follows.
The secret sharing of
is obtained by first calling the
protocol to calculate the sharing of the carry bits, and then locally dissociating directly with the most significant bit of the shares of x, as shown in Line 2 of Algorithm 4. If the secret sharing of
x and
are held in different number fields, i.e.,
and
, then calling the multiplication protocol on two sharing can obtain
, which is not the expected value. So we cannot call the multiplication protocol directly, but need to convert the secret sharing of
in
to the secret sharing of
in
and then call the protocol
to get the 2-out-of-3 replicated secret sharing of
.
| Algorithm 4 ReLU protocol |
-
Input: shares of held by , , and . -
Output: shares of held by , , and , where . -
Common Randomness:random numbers and . - 1:
Run to get where . - 2:
for , computes locally to obtain . - 3:
Run to get c where and broadcasts c to and . - 4:
If , set , otherwise, . - 5:
Run over and to get . - 6:
return.
|
Theorem 4. The protocol described in Algorithm 4 allows for correct and secure operation of the functionality.
Proof of Theorem 4. The protocol
called in step 1 is correct and secure. Step 2 is computed locally without the security algorithm. Step 3 invokes the protocol
and then exposes
c as the blinded
, so ensuring that the true value of
is not known to the parties. Step 4 is computed locally and if
, indicating that
r is the same as
, then
, otherwise
when
r is complementary to
, then
. The protocol
called in step 5 is correct and secure. Therefore, it follows from Theorem 1.2 in [
44] that combined protocol
is also correct and secure. □
3.7. Max-Pooling Layer
In the max-pooling layer, we treat the elements in the local field as a row vector as follows:
Then the computation at this layer is to find the maximum element in each row vector. The functionality of the protocol
is simply expressed as the input of a vector in the form of secret sharing and the output of secret sharing of its maximum value. At the intermediate layer, we only need to focus on the maximum value of each vector, so it is sufficient to carry out the calculations in steps 3, 4 and 5 of Algorithm 5. Iterating through the input via a for loop, the difference between the two numbers is first calculated and the protocol
is called to determine if the difference is zero, which in turn gives the maximum value of the current traversal. In the final predictive classification, the index of the maximum value in the vector, i.e., the label, needs to be obtained. So we pre-generate a number of one-hot vectors
with
and select the output in step 6 to get the index of the maximum value of the output vector.
| Algorithm 5 Maxpool function |
-
Input: shares of in held by , , and . -
Output: shares of and held by , , and , where and with and . -
Common Randomness:No additional common randomness required. - 1:
Set and . - 2:
fordo - 3:
Set . - 4:
, . - 5:
. - 6:
. - 7:
end for - 8:
return.
|
Theorem 5. The protocol described in Algorithm 5 allows for correct and secure operation of the functionality.
Proof of Theorem 5. Algorithm 5 calls the protocol in step 4 (the computation of b is in steps 1 and 2 of Algorithm 4), and the protocol in step 6. Similarly, because sub-protocols are secure, the combined protocol is also secure. In step 6, if , , so the current and output . If , , so and the one-hot vector corresponding to is outputted. In summary, Algorithm 5 is correct and secure. □
3.8. Performance Analysis
We summarise the overhead of the protocol theoretically, with the number of rounds and the communication complexity shown in
Table 1. The protocol
requires the transmission of 1 message in the semi-honest security model and 2 messages in the malicious security model. the protocol
represents matrix multiplication of dimensions
and
and requires 2 communications in the semi-honest security model (e.g., steps 3 and 6), whereas in the malicious security model, although the same 2 communications are performed, the first communication complexity is 2×. If the number of elements transmitted is the same, the communication complexity of
under the malicious security model can be the same as that of the protocol
under the semi-honest security model. The focus of protocol
is on the combined computation of
,
and
. The protocol
only needs to compute the maximum value in the pooling layer of the neural network, i.e., only steps 3–5 in the for loop need to be performed. Let matrix dimension after local feature transformation be
, then the protocol
needs to be called
times. The full protocol
is only called when the final label classification is performed and the one-hot encoding of each label needs to be calculated.
As can be seen from
Table 1, the number of rounds under the malicious security model is essentially the same as that under the semi-honest security model, but the communication complexity is approximately
, making it a much less efficient implementation.
We compared the theoretical complexity of the Astra [
45], Blaze [
46], Falcon [
38], Flash [
40] and Trident [
39] frameworks with the proposed scheme. We compares the end-to-end overhead of the protocol
due to the different methods used in this framework to calculate the non-linear functions.
Table 2 shows the comparison of the theoretical complexity. Astra is a third-party secure computation framework with semi-honest security. Blaze builds on Astra to achieve malicious security and fairness in a 3PC honest majority corruption model and uses an adder circuit approach for non-linear function computation. The framework which is most similar to the proposed scheme is Falcon and introduces a non-zero random number
r in step 1 of the protocol
, so the PC protocol needs to be called in step 4 to compare the
x and
r, which is in
Section 3.3 of the [
38]. In contrast, we introduce a secret sharing of 0, so there is no need to call the PC protocol, resulting in a
reduction in the number of rounds and a
reduction in communication complexity for the protocol
.
4. Results
Our experiments are written in C++ program on the virtual machine Ubuntu 22.04.1 LTS amd64 and focus on evaluating the performance overhead of the proposed scheme for private prediction on multiple neural networks.
The training is first performed on plaintext data using the torch library, with the accuracy of 98.06% on Network-A, 99.00% on Network-B, 99.56% on Network-C and 99.77% on Network-D (networks are described in
Section 4.1). Afterwards, the performance of various sub-protocols under semi-honest and malicious security is benchmarked as shown in
Section 4.2.
Section 4.3 evaluates the prediction time and communication cost of the proposed scheme in this paper based on the model parameters obtained from training with the test dataset. Finally, the feasibility of this scheme is verified by comparing the accuracy under the secret sharing and plaintext in
Section 4.4.
The inputs to the neural network as well as the parameters are generally floating point numbers, so they must be encoded in fixed point form, setting their precision bit to 13. Experiments in this paper are conducted using a smaller ring , allowing the entire framework to run on smaller data types with half the communication complexity compared to the generic framework with . The Eigen library is used to speed up the matrix multiplication calculation.
4.1. Dataset and Networks
The dataset is MNIST [
47], where each image is a
pixel handwritten digital image with labels between 0 and 9, consisting of 60,000 images in the training set and 10,000 images in the test set.
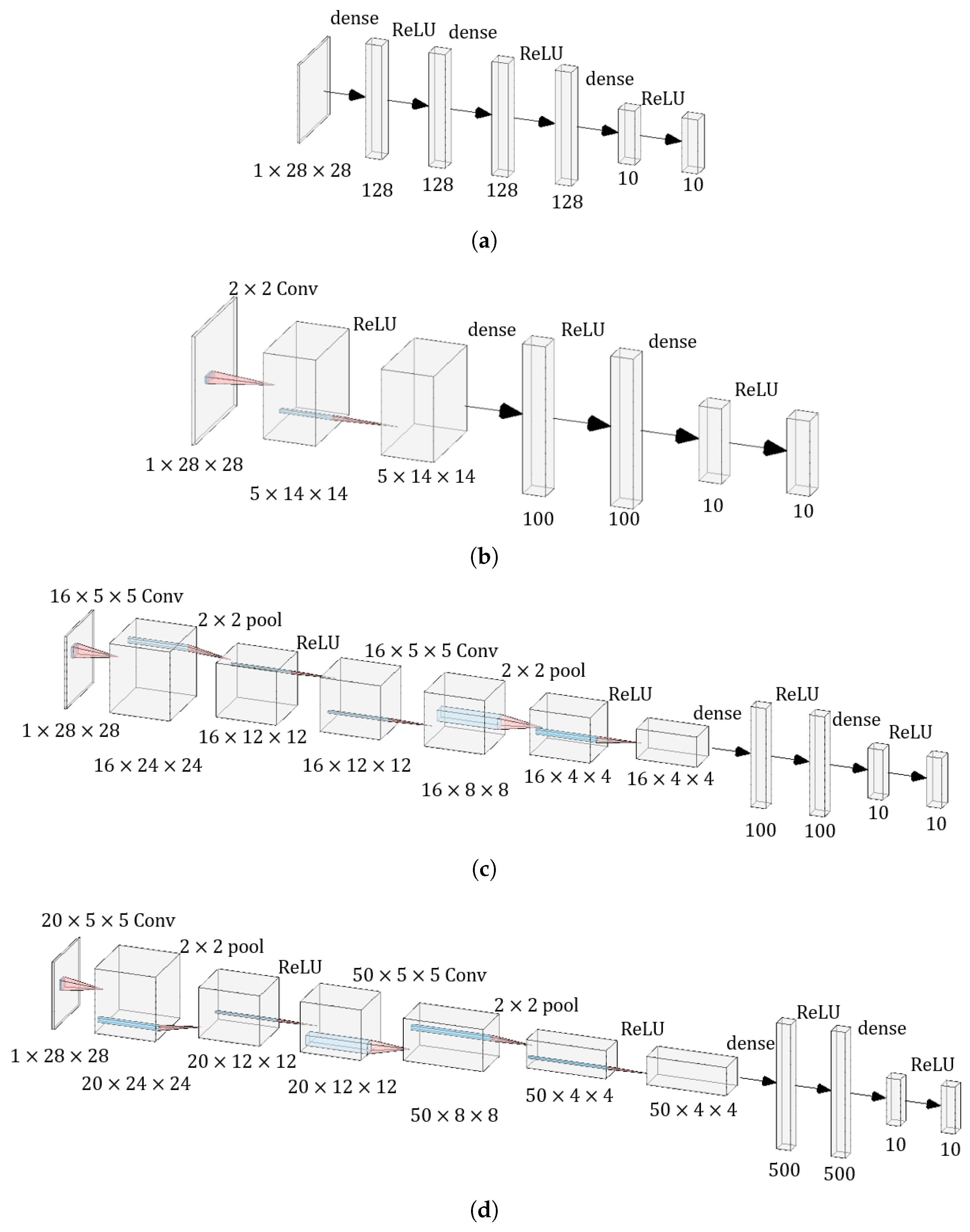
For comparisons with different neural network architectures, four standard network architectures are chosen for the experiments, which are shown in
Figure 2.
Network-A: This is a neural network evaluated in the SecureML [
18] framework. It consists of 3 fully connected layers, with an activation layer added after each layer. The number of nodes in each layer is
,
,
. This is the smallest network with 118,282 parameters.
Network-B: This is a neural network evaluated in the Chameleon [
35] framework. The network structure has 6 layers in total. The first layer is a convolutional layer with a kernel of
. The third and fifth layers are fully connected layers with nodes of
,
, respectively. The second, fourth and sixth layers are the activation layers. Its total number of parameters is about 99,135.
Network-C: This is a neural network evaluated in the MiniONN [
48] framework. The network has a total of 10 layers. The first and fourth layers are convolutional layers with kernels of
,
, respectively. The second and fifth layers are pooling layers with kernels of
. Layers 7 and 9 are fully connected layers with nodes of
, 10, respectively, and the rest of the layers are activation layers. Its total number of parameters is 33,542.
Network-D: The network was first proposed in [
47] for automatic detection of postal codes and digit recognition, which has 10 layers. The first and fourth layers are convolutional layers with kernels of
,
, respectively. the second and fifth layers both are pooling layers with kernels of
. Layers 7 and 9 are fully connected layers with nodes of
,
, respectively, and the rest of the layers are activation layers. It has a total of 431,080 parameters.
4.2. Microbenchmarks
In this section, we benchmark the computations of the fully connected, convolutional, activation and pooling layers. Three different parameter sets are used for the experiments, and the average of 100 experiments is taken as the result. A comparison of the sub-layers performance in a semi-honestly security model is shown in
Table 3. The fully connected and convolutional layers mainly invoke the protocol
which reduces the computational complexity from
to
compared to Falcon, resulting in an improvement in communication cost of about 1/4 under the same parameters. In the activation layer, compared to Falcon, there are fewer calls to the comparison protocol, resulting in performance improvement of about
–
in computation time and about
in communication cost for the same parameters. In the pooling layer, we mainly calculate the maximum value in the local field without focusing on its index, and the protocol
is based on the protocol
, so the performance is also improved compared to Falcon, with the
–
improvement in computation time and about
–
in communication cost.
In the malicious security model, the computational performance of the sub-layers is shown in
Table 4. The performance is lower than in the semi-honest security model due to the need to verify the correctness of the data in the communication in each protocol. In our scheme, the introduction of the hash function leads to a significant reduction in communication cost. Compared to Falcon, the improvement is much higher than in in the semi-honest model. For example, with the same parameter setting of the fully connected and convolutional layers, the communication cost is improved by about
with the semi-honest security setting, while it can be improved by about
–
with the malicious security setting. With the same parameter setting in the activation layer, the communication cost is increased by about
with the semi-honest security setting, while it can be increased by
with the malicious security setting. In the pooling layer with the same parameter setting, the communication cost is increased by approximately
with the semi-honest security setting, while it is increased by approximately
with the malicious security setting.
After theoretical and experimental analysis, verify that the proposed scheme has better performance in terms of computation time as well as communication complexity. Experiments under both security definitions are also compared and show that the performance of the malicious model is lower than that of the semi-honest model, but the performance improvement of the malicious model is higher than that of the semi-honest model compared to other works.
4.3. Security Prediction
Table 5 shows the number of communication bytes (KB) and the end-to-end latency (ms) for the proposed scheme to perform a single inference query with the Falcon framework. We execute the queries in different network architectures as well as in semi-honest and malicious settings. In the semi-honest setting, predicting a single sample takes about 45.71 ms with an improvement of
, and its communication cost is about 8.90 KB with an improvement of
on Network-A. On Network-B, it takes about 39.54 ms with an improvement of
, and its communication cost is about 34.65 KB with an improvement of
. On Network-C, it takes about 32.36 ms (
), and its communication cost is about 324.02 KB (
). Network-D takes about 155.28 ms (
), and its communication cost is about 476.52 KB (
). In a malicious security setting, our work is
–
faster, with a communication efficiency improvement of about
–
compared to Falcon.
These experiments show that the proposed method has lower latency and fewer communication cost in single-sample prediction. Depending on the trust assumptions, malicious model requires more communication as well as higher runtimes compared to the semi-honest model.
Figure 3 shows that the time performing batch prediction on different networks is roughly linear in the number of samples. Similarly, compared to the Falcon framework, our scheme performs better when predicting the same number of samples.
4.4. Comparison vs. Plaintext Computation
We perform experiments comparing secure prediction using secret sharing with traditional plaintext prediction using PyTorch. Results with the 64-bit floating-point data type on PyTorch (plaintext) and the 32-bit data type (secret sharing) are shown in
Table 6. The second and third columns show the accuracy with the training set and test set obtained by setting the learning rate to 0.1 and iterating 15 times using traditional prediction methods. The fourth column is the accuracy of the test set under three-party secure computation. The fifth column is the error values for prediction accuracy, with differences all less than 1% between secure computation and plaintext computation. The results show that most networks have no/low loss in accuracy when the computation is performed as a fixed-point integer with the 13-bit precision in our work, confirming the effectiveness of the proposed scheme.
5. Conclusions
This paper proposes a neural network model for privacy prediction based on a 3PChree-party secure computing framework. While traditional 3PChree-party secure computing outsources all computations to three non-colluding servers, our three-party refers to the client, the service provider and the third-party server that assists in the computation. Because of the inclusion of the client in the computation, the definition of security in the model is slightly different than before. Therefore, depending on the different trust assumptions, this paper proposes wo definitions of security to choose from, namely semi-honest and malicious security.
The introduction of the secret sharing technique ensures that the model parties do not have access to the original data of the client as well as the model parameters of the service provider, thus ensuring data security. Therefore, we give sub-protocols such as , , , , and through the secret sharing technique. Compared to existing works, our scheme offers an improvement in both prediction time and communication cost.
The times reported in our experiments are all online times, and the performance of the framework would be further improved if the multiplicative triples computation is divided into the offline phase. As the entire codebase is parallelizable, improvements may be made later by parallelization or using GPUs in future work.







{kind=link}
{kind=link}
{kind=link}