
A Cross-Level Requirement Trace Link Update Model Based on Bidirectional Encoder Representations from Transformers

Abstract
:1. Introduction
- A pre-trained model-based approach DRAFT is proposed for updating cross-level requirement trace links. Compared with existing studies, we extended the features into two dimensions. In terms of feature types, process features are added in addition to text features. In terms of requirement types, instead of directly analyzing the candidate requirement pairs (i.e., direct features), the requirements related to candidate requirements (i.e., extended features) are also analyzed.
- An experimental evaluation is performed for eight open-source projects in various domains and scales. The results revealed that the performance of DRAFT is considerably better than that of the baseline methods such as VSM, relevance feedback, and TraceBERT. DRAFT achieved average F1 and F2 scores of 69.3% and 76.9%, which are up to 16.5% and 22.3% higher than those of the baselines, respectively.
- The datasets and DRAFT-related code are made available online (https://gitee.com/ttstr/DRAFT, accessed on 25 January 2023).
2. Research Background and Problem Definition
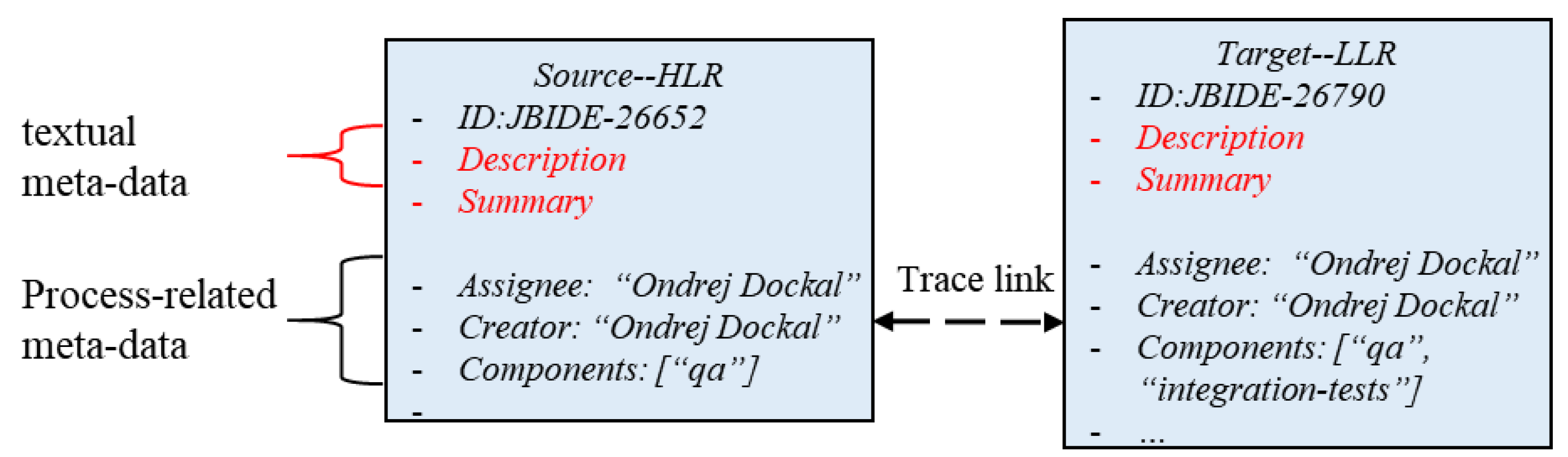
2.1. Research Background: Cross-Level Requirements Traceability
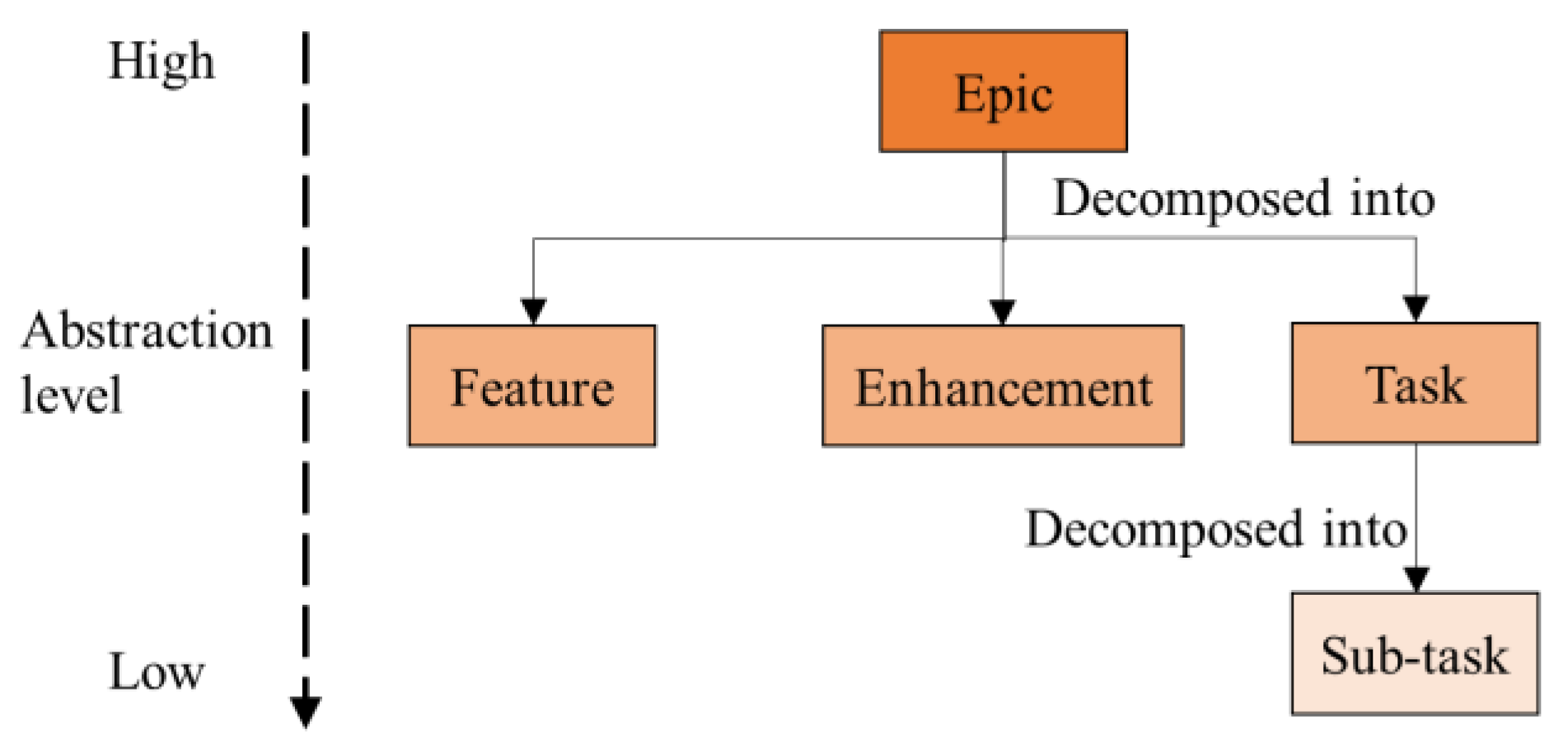
2.2. Problem Definition: Update of Requirement Trace Links
3. Related Work
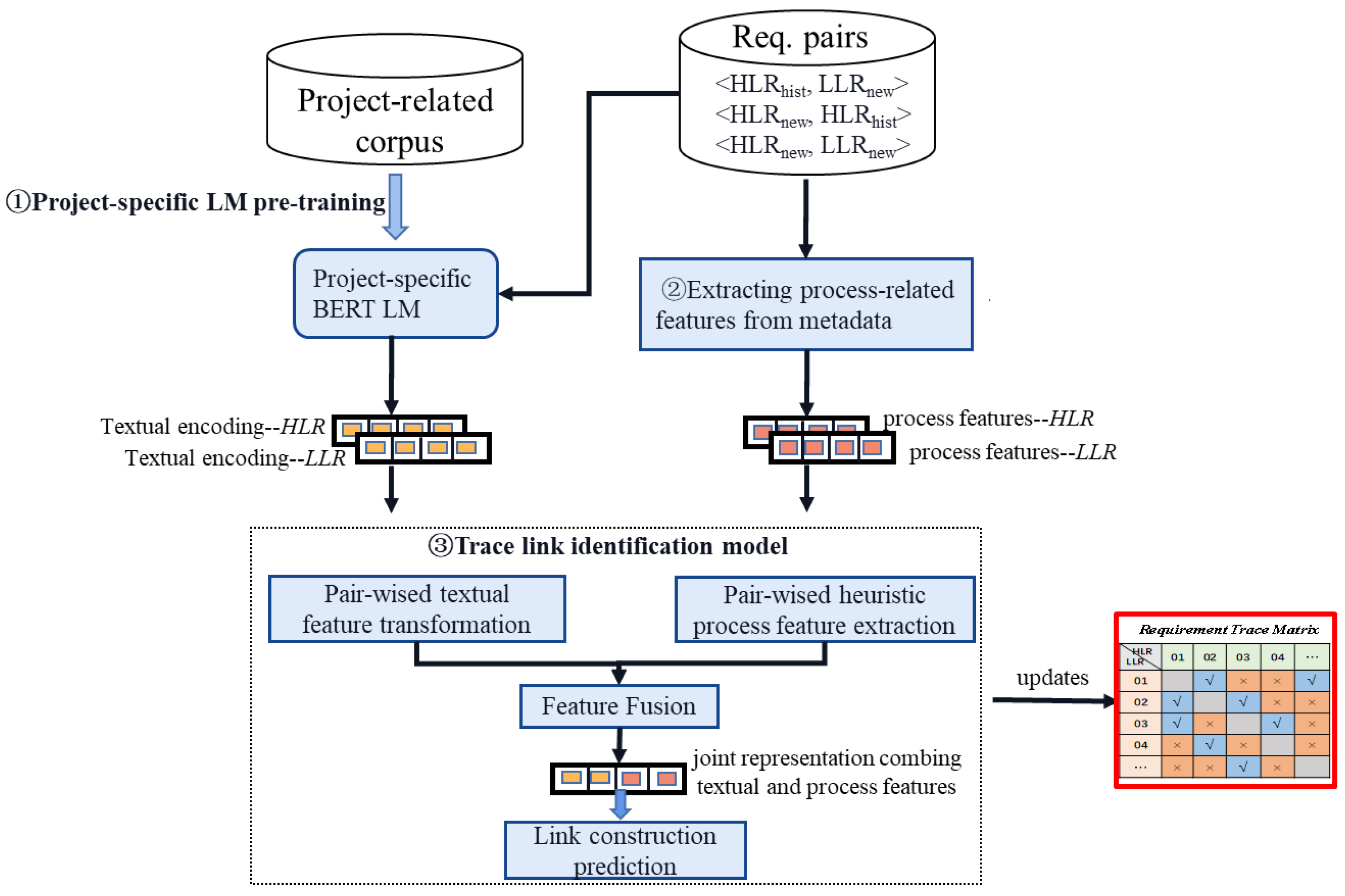
4. DRAFT Framework
5. Project-Specific Pre-Training
6. Heuristic Feature Extraction Based on Metadata
6.1. Heuristic Features Related to Components and Labels
6.2. Heuristic Features of Stakeholder Information
6.3. Extended Features Based on Historical Trace Links
6.4. Textual Feature
7. Trace Link Identification Model Fusing Heterogeneous Features
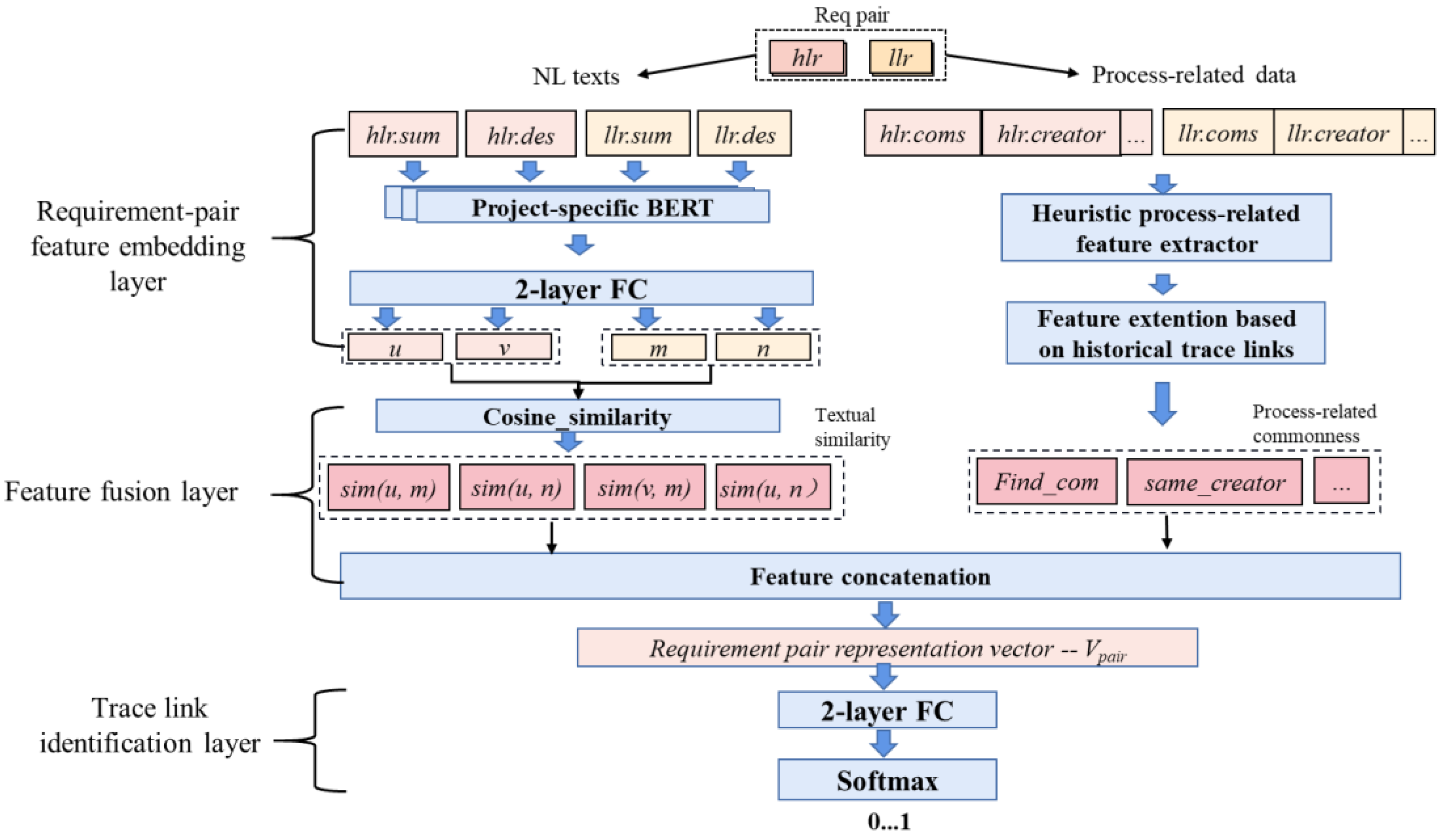
7.1. Model Structure
- Requirement-pair feature embedding layer. This layer embeds text features and process features for the input cross-level requirement pair <hlr, llr> using the feature extraction method described in Section 6.
- 2.
- Heterogeneous feature fusion layer. The feature fusion layer is used to fuse text features and heuristic features with various dimensions to comprehensively analyze the commonality of a pair of requirements in terms of text semantics and process data. After the processing at the feature embedding layer, the 200-dimensional text embedding representation vector is obtained in the natural language description, whereas heuristic features are one-dimensional.
- 3.
- Trace link identification layer. This layer includes two fully connected layers and one Softmax output layer. As presented in Equation (10), the feature of the requirement pair in the previous step is used as the input, and the trace link identification result Cpair of this pair of cross-level requirements is output. Here, Cpair is one-dimensional, and takes the value of 0 (no trace link) or 1 (with a trace link), and W is a 1 × 10-dimensional trainable parameter.
7.2. Loss Function
8. Experimental Evaluation
8.1. Objectives of Experimental Evaluation
8.2. Data Acquisition
8.3. Implementation and Results of Experimental Evaluation
8.3.1. Baseline Methods and Evaluation Indicators
8.3.2. Evaluation Results and Analysis
RQ1: Performances of DRAFT (the Proposed Method) and Baseline Methods in Trace Link Identification
RQ2: Ablation Experiment
- Role of Second-Phase Pre-Training in DRAFT
- 2.
- Metadata-Based Heuristic Features in DRAFT
9. Discussion
9.1. Validity Threats
9.2. Limitations
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gorschek, T.; Wohlin, C. Requirements Abstraction Model. Requir. Eng. 2006, 11, 79–101. [Google Scholar] [CrossRef]
- Dong, L.; Liu, K.; Zhao, P.; Dai, J. A Quantitative Analysis Method of Itemized Requirement Traceability for Aircraft Development. In Complex Systems Design & Management; Krob, D., Li, L., Yao, J., Zhang, H., Zhang, X., Eds.; Springer: Cham, Switzerland, 2021; pp. 89–101. [Google Scholar] [CrossRef]
- Special Committee 205 of Radio Technical Commission for Aeronautics. DO-178C, Software Considerations in Airborne Systems and Equipment Certification; RTCA: Washington, DC, USA, 2011; pp. 32–42. [Google Scholar]
- IEEE Recommended Practice for Software Requirements Specifications. In IEEE Std 830-1998; IEEE-SA Standards Board: New York, NY, USA, 2002.
- McClure, J. CMMI for Development v 1.3 by Mary Beth Chrissis, Mike Konrad and Sandy Shrum. ACM SIGSOFT Softw. Eng. Notes 2011, 36, 34–35. [Google Scholar] [CrossRef]
- Samuel, B.M.; Bala, H.; Daniel, S.L.; Ramesh, V. Deconstructing the Nature of Collaboration in Organizations Open Source Software Development: The Impact of Developer and Task Characteristics. IEEE Trans. Softw. Eng. 2022, 48, 3969–3987. [Google Scholar] [CrossRef]
- Rempel, P.; Mäder, P. Preventing Defects: The Impact of Requirements Traceability Completeness on Software Quality. IEEE Trans. Softw. Eng. 2017, 43, 777–797. [Google Scholar] [CrossRef]
- Arnold, S.; Ricossa, S. Requirements engineering at CISCO. In Proceedings of the Workshop on Requirements Engineering, International Symposium on Software Reliability Engineering, San Jose, CA, USA, 1–4 November 2010. [Google Scholar]
- Rahimi, M.; Cleland-Huang, J. Evolving Software Trace Links between Requirements and Source Code. In Proceedings of the 10th International Workshop on Software and Systems Traceability, SST@ICSE 2019, Montreal, QC, Canada, 27 May 2019; Steghöfer, J.-P., Niu, N., Eds.; IEEE/ACM: New York, NY, USA, 2019; p. 12. [Google Scholar] [CrossRef]
- Cleland-Huang, J.; Gotel, O.; Hayes, J.H.; Mäder, P.; Zisman, A. Software Traceability: Trends and Future Directions. In Proceedings of the Future of Software Engineering, FOSE 2014, Hyderabad, India, 31 May–7 June 2014; Herbsleb, J.D., Dwyer, M.B., Eds.; ACM: Rochester, NY, USA, 2014; pp. 55–69. [Google Scholar] [CrossRef] [Green Version]
- Maro, S.; Anjorin, A.; Wohlrab, R.; Steghöfer, J.-P. Traceability Maintenance: Factors and Guidelines. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, ASE 2016, Singapore, 3–7 September 2016; Lo, D., Apel, S., Khurshid, S., Eds.; ACM: Rochester, NY, USA, 2016; pp. 414–425. [Google Scholar] [CrossRef]
- Mäder, P.; Gotel, O. Towards Automated Traceability Maintenance. J. Syst. Softw. 2012, 85, 2205–2227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hübner, P.; Paech, B. Interaction-Based Creation and Maintenance of Continuously Usable Trace Links between Requirements and Source Code. Empir. Softw. Eng. 2020, 25, 4350–4377. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.-S. A Vector Space Model for Automatic Indexing. Commun. ACM. 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Lucia, A.D.; Oliveto, R.; Tortora, G. Assessing IR-Based Traceability Recovery Tools through Controlled Experiments. Empir. Softw. Eng. 2009, 14, 57–92. [Google Scholar] [CrossRef]
- Capobianco, G.; Lucia, A.D.; Oliveto, R.; Panichella, A.; Panichella, S. Improving IR-Based Traceability Recovery via Noun-Based Indexing of Software Artifacts. J. Softw. Evol. Process. 2013, 25, 743–762. [Google Scholar] [CrossRef]
- Hayes, J.H.; Dekhtyar, A.; Sundaram, S.K. Advancing Candidate Link Generation for Requirements Tracing: The Study of Methods. IEEE Trans. Softw. Eng. 2006, 32, 4–19. [Google Scholar] [CrossRef] [Green Version]
- Rocchio, J.J. Relevance Feedback Information Retrieval. In The Smart Retrieval System—Experiments in Automatic Document Processing; Prentice Hall: Hoboken, NJ, USA, 1971. [Google Scholar]
- Hayes, J.H.; Dekhtyar, A.; Osborne, J. Improving Requirements Tracing via Information Retrieval. In Proceedings of the IEEE International Conference on Requirements Engineering, Monterey Bay, CA, USA, 12 September 2003. [Google Scholar]
- Li, Z.; Chen, M.; Huang, L.; Ng, V. Recovering Traceability Links in Requirements Documents. In Proceedings of the Conference on Computational Natural Language Learning, Beijing, China, 30–31 July 2015. [Google Scholar]
- Cleland-Huang, J.; Czauderna, A.; Gibiec, M.; Emenecker, J. A Machine Learning Approach for Tracing Regulatory Codes to Product Specific Requirements. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering, ICSE 2010, Cape Town, South Africa, 1–8 May 2010; Volume 1. [Google Scholar]
- Gervasi, V.; Zowghi, D. Supporting Traceability through Affinity Mining. In Proceedings of the Requirements Engineering Conference, Karlskrona, Sweden, 25–29 August 2014. [Google Scholar]
- Rath, M.; Rendall, J.; Guo, J.L.C.; Cleland-Huang, J.; Mäder, P. Traceability in the Wild: Automatically Augmenting Incomplete Trace Links. In Proceedings of the 40th International Conference on Software Engineering, ICSE 2018, Gothenburg, Sweden, 27 May–3 June 2018; Chaudron, M., Crnkovic, I., Chechik, M., Harman, M., Eds.; ACM: Rochester, NY, USA, 2018; pp. 834–845. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Poudel, A.; Yu, W.; Zeng, Q.; Jiang, M.; Cleland-Huang, J. Enhancing Automated Software Traceability by Transfer Learning from Open-World Data. arXiv 2022. [Google Scholar] [CrossRef]
- Guo, J.; Cheng, J.; Cleland-Huang, J. Semantically Enhanced Software Traceability Using Deep Learning Techniques. In Proceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, 20–28 May 2017; Uchitel, S., Orso, A., Robillard, M.P., Eds.; IEEE/ACM: New York, NY, USA, 2017; pp. 3–14. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Liu, Y.; Zeng, Q.; Jiang, M.; Cleland-Huang, J. Traceability Transformed: Generating More Accurate Links with Pre-Trained BERT Models. In Proceedings of the 43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22–30 May 2021; IEEE: New York, NY, USA, 2021; pp. 324–335. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Rochester, NY, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Bhowmik, T.; Do, A.Q. Refinement and Resolution of Just-in-Time Requirements in Open Source Software and a Closer Look into Non-Functional Requirements. J. Ind. Inf. Integr. 2019, 14, 24–33. [Google Scholar] [CrossRef]
- Gupta, A.; Wang, W.; Niu, N.; Savolainen, J. Answering the Requirements Traceability Questions. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, ICSE 2018, Gothenburg, Sweden, 27 May–3 June 2018; Chaudron, M., Crnkovic, I., Chechik, M., Harman, M., Eds.; ACM: Rochester, NY, USA, 2018; pp. 444–445. [Google Scholar] [CrossRef]
- Haering, M.; Stanik, C.; Maalej, W. Automatically Matching Bug Reports with Related App Reviews. In Proceedings of the 43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22–30 May 2021; IEEE: New York, NY, USA, 2021; pp. 970–981. [Google Scholar] [CrossRef]
- Zhou, Y.; Tong, Y.; Gu, R.; Gall, H.C. Combining Text Mining and Data Mining for Bug Report Classification. J. Softw. Evol. Process 2016, 28, 150–176. [Google Scholar] [CrossRef]
- Hall, M.A.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Guo, J.; Gibiec, M.; Cleland-Huang, J. Tackling the Term-Mismatch Problem in Automated Trace Retrieval. Empir. Softw. Eng. 2017, 22, 1103–1142. [Google Scholar] [CrossRef]
- Guo, J.; Monaikul, N.; Plepel, C.; Cleland-Huang, J. Towards an Intelligent Domain-Specific Traceability Solution. In Proceedings of the ACM/IEEE International Conference on Automated Software Engineering, ASE’14, Vasteras, Sweden, 15–19 September 2014; Crnkovic, I., Chechik, M., Grünbacher, P., Eds.; ACM: Rochester, NY, USA, 2014; pp. 755–766. [Google Scholar] [CrossRef]
- D’Ambros, M.; Lanza, M.; Robbes, R. Evaluating Defect Prediction Approaches: A Benchmark and an Extensive Comparison. Empir. Softw. Eng. 2012, 17, 531–577. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Ma, Y.; Cukic, B.; Singh, H. Robust Prediction of Fault-Proneness by Random Forests. In Proceedings of the 15th International Symposium on Software Reliability Engineering (ISSRE 2004), Saint-Malo, Bretagne, France, 2–5 November 2004; IEEE Computer Society: New York, NY, USA, 2004; pp. 417–428. [Google Scholar] [CrossRef]
- Jahan, M.S.; Khan, H.U.; Akbar, S.; Farooq, M.U.; Gul, S.; Amjad, A. Bidirectional Language Modeling: A Systematic Literature Review. Sci. Program 2021, 2021, 6641832. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U., von Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Springer: Cham, Switzerland, 2017; pp. 5998–6008. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Araci, D. FinBERT: Financial Sentiment Analysis with Pre-Trained Language Models. arXiv 2019. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; Cohn, T., He, Y., Liu, Y., Eds.; Findings of ACL. Association for Computational Linguistics: Rochester, NY, USA, 2020; Volume EMNLP, pp. 1536–1547. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, H.; Liu, W.; Weng, Z.; Kuang, H. Semi-Supervised Pre-Processing for Learning-Based Traceability Framework on Real-World Software Projects. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, 14–18 November 2022; Roychoudhury, A., Cadar, C., Kim, M., Eds.; ACM: Rochester, NY, USA, 2022; pp. 570–582. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Rochester, NY, USA, 2019; pp. 3980–3990. [Google Scholar] [CrossRef] [Green Version]
- Zogaan, W.; Sharma, P.; Mirakhorli, M.; Arnaoudova, V. Datasets from Fifteen Years of Automated Requirements Traceability Research: Current State, Characteristics, and Quality. In Proceedings of the 25th IEEE International Requirements Engineering Conference, RE 2017, Lisbon, Portugal, 4–8 September 2017; Moreira, A., Araújo, J., Hayes, J., Paech, B., Eds.; IEEE Computer Society: New York, NY, USA, 2017; pp. 110–121. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Feature Type | Feature Name | Applicable Requirement Pair | Explanation |
|---|---|---|---|---|
| Ft.1 | Process feature | same_coms | * (a), * (b), and * (c) | The normalized representation of the number of components shared by a pair of cross-level requirements. (See Section 6.1) |
| Ft.2 | find_coms | The maximal degree that the component labels of one requirement can be covered by the summary and description of the other one. (See Section 6.1) | ||
| Ft.3 | same_labels | The normalized representation of the number of labels shared by a pair of cross-level requirements. (See Section 6.2) | ||
| Ft.4 | same_creator | Whether the two requirements have the same creator, i.e., if hlr.creator = llr.creator. (See Section 6.2) | ||
| Ft.5 | same_assignee | Whether the two requirements are assigned by the same assignee, i.e., if hlr.assignee = llr.assignee. (See Section 6.2) | ||
| Ft.6 | same_stk | Whether the creator of one requirement is equal to the assignee of the other one, i.e., if hlr.creator = llr.assignee or hlr.assignee = llr.creator. (See Section 6.2) | ||
| Ft.7–10 | extended_features | (a) and (b) | Extracting Ft. 1, Ft.2, Ft.4, Ft.5 between *llrhist.tracedReq and hlrnew (in scenario a), or between *hlrhist.tracedReq and llrnew (in scenario (b)). (See Section 6.3) | |
| Ft.11 | Text feature | text_feature | (a), (b), and (c) | Text embedding of hlr.description, hlr.summary, llr.description and llr.summary. (See Section 6.4) |
| Project | Affiliated Foundation | Number of Requirements | Number of Cross-Level Trace Links | Project Duration (till 10 March 2022) | Related Domain |
|---|---|---|---|---|---|
| BEAM | Apache | 1837 | 1637 | Over 6 years | Data stream processing |
| CB | 1985 | 1814 | Over 10 years | Mobile software development | |
| FH | Redhat | 1498 | 1906 | Over 7 years | Enterprise mobile application platform |
| JBIDE | 4464 | 4208 | Over 18 years | Development tool integration | |
| AAH | 482 | 620 | Over 3 years | Application configuration and deployment platform | |
| KEYCLOAK | 2978 | 3788 | Over 9 years | Authentication and rights management | |
| KOGITO | 2244 | 2998 | Over 5 years | Service process modeling | |
| PROJQUAY | 483 | 647 | Over 4 years | Openshift container platform |
| Project | Pre-trained Corpus Size (MB) | Training Set Size | Test Set Size | Tracetrain/Tracetest | Splitting Version V | ||
|---|---|---|---|---|---|---|---|
| Trace Space | Trace Links | Trace Space | Trace Links | ||||
| AAH | 0.56 | 18,303 | 492 | 5060 | 128 | 3.8: 1 | “4.4.0” |
| PROJQUAY | 1.0 | 18,842 | 487 | 6832 | 160 | 3.0:1 | “quay-v3.5.5” |
| FH | 1.2 | 145,338 | 1285 | 205,038 | 621 | 2.1: 1 | “ios-swift-6.0.0” |
| CB | 3.45 | 270,184 | 1350 | 200,796 | 464 | 2.9:1 | “3.5.0” |
| KOGITO | 3.34 | 280,191 | 2329 | 149,946 | 669 | 3.5:1 | “1.7.0.Final” |
| BEAM | 14.5 | 333,796 | 1264 | 16,063 | 373 | 3.4:1 | “2.29.0” |
| KEYCLOAK | 7.07 | 810,648 | 2943 | 601,183 | 845 | 3.5:1 | “11.0.0” |
| JBIDE | 15.9 | 1,588,846 | 3448 | 853,117 | 850 | 4.0:1 | “4.5.0.Final” |
| Project/Method | DRAFT | VSM | LSI | RF-Keydim | T-BERT | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | F1 | F2 | |
| AAH | 0.536 | 0.621 | 0.309 | 0.322 | 0.232 | 0.289 | 0.356 | 0.369 | 0.212 | 0.173 |
| PROJQUAY | 0.767 | 0.829 | 0.349 | 0.323 | 0.203 | 0.198 | 0.454 | 0.413 | 0.335 | 0.419 |
| FH | 0.797 | 0.872 | 0.363 | 0.329 | 0.236 | 0.249 | 0.59 | 0.615 | 0.322 | 0.286 |
| CB | 0.611 | 0.660 | 0.486 | 0.545 | 0.505 | 0.460 | 0.589 | 0.574 | 0.503 | 0.460 |
| KOGITO | 0.544 | 0.647 | 0.413 | 0.407 | 0.334 | 0.312 | 0.557 | 0.542 | 0.383 | 0.336 |
| BEAM | 0.739 | 0.796 | 0.540 | 0.513 | 0.423 | 0.411 | 0.67 | 0.704 | 0.471 | 0.556 |
| KEYCLOAK | 0.805 | 0.859 | 0.466 | 0.456 | 0.398 | 0.417 | 0.566 | 0.553 | 0.435 | 0.457 |
| JBIDE | 0.748 | 0.868 | 0.497 | 0.653 | 0.464 | 0.620 | 0.438 | 0.596 | 0.737 | 0.763 |
| AVERAGE | 0.693 | 0.769 | 0.428 | 0.444 | 0.349 | 0.37 | 0.528 | 0.546 | 0.425 | 0.431 |
| Methods for Comparison | VSM | LSI | RF-Keydim | T-BERT | |
|---|---|---|---|---|---|
| Metrics | |||||
| F1 | p < 0.01 | p < 0.01 | p < 0.05 | p < 0.01 | |
| F2 | p < 0.01 | p < 0.01 | p < 0.01 | p < 0.01 | |
| Project | BERT | F1 Improvement (Gain) | F2 Improvement (Gain) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Original | Project-Specific Second-Phase Pre-Training | |||||||||
| P * | R * | F1 | F2 | P | R | F1 | F2 | |||
| AAH | 0.408 | 0.695 | 0.514 | 0.609 | 0.436 | 0.695 | 0.536 | 0.621 | 0.02 (4%) | 0.01 (2%) |
| PROJQUAY | 0.826 | 0.744 | 0.783 | 0.759 | 0.685 | 0.875 | 0.767 | 0.829 | −0.02 (−3%) | 0.07 (9%) |
| FH | 0.598 | 0.703 | 0.646 | 0.679 | 0.543 | 0.698 | 0.611 | 0.660 | −0.03 (−5%) | −0.02 (−3%) |
| CB | 0.778 | 0.747 | 0.762 | 0.753 | 0.696 | 0.931 | 0.797 | 0.872 | 0.04 (5%) | 0.12 (16%) |
| KOGITO | 0.427 | 0.745 | 0.543 | 0.648 | 0.430 | 0.740 | 0.544 | 0.648 | 0.00 (0%) | 0.00 |
| BEAM | 0.400 | 0.802 | 0.578 | 0.668 | 0.660 | 0.839 | 0.739 | 0.796 | 0.16 (28%) | 0.13 (19%) |
| KEYCLOAK | 0.742 | 0.803 | 0.771 | 0.790 | 0.729 | 0.899 | 0.805 | 0.859 | 0.03 (4%) | 0.07 (9%) |
| JBIDE | 0.550 | 0.971 | 0.702 | 0.842 | 0.608 | 0.972 | 0.748 | 0.868 | 0.05 (7%) | 0.03 (4%) |
| AVERAGE | 0.591 | 0.776 | 0.662 | 0.719 | 0.598 | 0.831 | 0.693 | 0.769 | 0.03 (5%) | 0.05 (7%) |
| Project | Whether to Use Heuristic Features | F1 Improvement (Gain) | F2 Improvement (Gain) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| No | Yes | |||||||||
| P * | R * | F1 | F2 | P | R | F1 | F2 | |||
| AAH | 0.268 | 0.375 | 0.313 | 0.347 | 0.436 | 0.695 | 0.536 | 0.621 | 0.22 (70%) | 0.27 (78%) |
| PROJQUAY | 0.344 | 0.331 | 0.338 | 0.334 | 0.685 | 0.875 | 0.767 | 0.829 | 0.44 (130%) | 0.50 (150%) |
| FH | 0.339 | 0.403 | 0.368 | 0.388 | 0.696 | 0.931 | 0.797 | 0.872 | 0.43 (117%) | 0.48 (124%) |
| CB | 0.48 | 0.416 | 0.446 | 0.427 | 0.543 | 0.698 | 0.611 | 0.660 | 0.21 (47%) | 0.23 (54%) |
| KOGITO | 0.404 | 0.424 | 0.414 | 0.420 | 0.43 | 0.74 | 0.544 | 0.647 | 0.13 (31%) | 0.23 (55%) |
| BEAM | 0.402 | 0.374 | 0.387 | 0.379 | 0.66 | 0.839 | 0.739 | 0.796 | 0.35 (90%) | 0.42 (111%) |
| KEYCLOAK | 0.45 | 0.433 | 0.441 | 0.436 | 0.729 | 0.899 | 0.805 | 0.859 | 0.36 (82%) | 0.42 (96%) |
| JBIDE | 0.572 | 0.912 | 0.703 | 0.815 | 0.608 | 0.972 | 0.748 | 0.868 | 0.05 (7%) | 0.05 (6%) |
| AVERAGE | 0.407 | 0.459 | 0.426 | 0.443 | 0.598 | 0.831 | 0.693 | 0.769 | 0.274 (72%) | 0.325 (84%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, J.; Zhang, L.; Lian, X. A Cross-Level Requirement Trace Link Update Model Based on Bidirectional Encoder Representations from Transformers. Mathematics 2023, 11, 623. https://doi.org/10.3390/math11030623
Tian J, Zhang L, Lian X. A Cross-Level Requirement Trace Link Update Model Based on Bidirectional Encoder Representations from Transformers. Mathematics. 2023; 11(3):623. https://doi.org/10.3390/math11030623
Chicago/Turabian StyleTian, Jiahao, Li Zhang, and Xiaoli Lian. 2023. "A Cross-Level Requirement Trace Link Update Model Based on Bidirectional Encoder Representations from Transformers" Mathematics 11, no. 3: 623. https://doi.org/10.3390/math11030623