
Demand Forecasting of Spare Parts Using Artificial Intelligence: A Case Study of K-X Tanks


Abstract
:1. Introduction
- To investigate various spare part demand forecasting models associated with classification methods, more specifically time series analysis, data mining, and deep learning, based on stacking and pairing spare parts and demand datasets.
- To identify the model with the highest forecasting accuracy based on statistical analyses.
- To highlight future research directions to ensure better management and spare part demand forecasting in the defense and logistics sectors.
2. Literature Review
2.1. Time Series
2.2. Machine Learning
2.3. Stacked Generalization
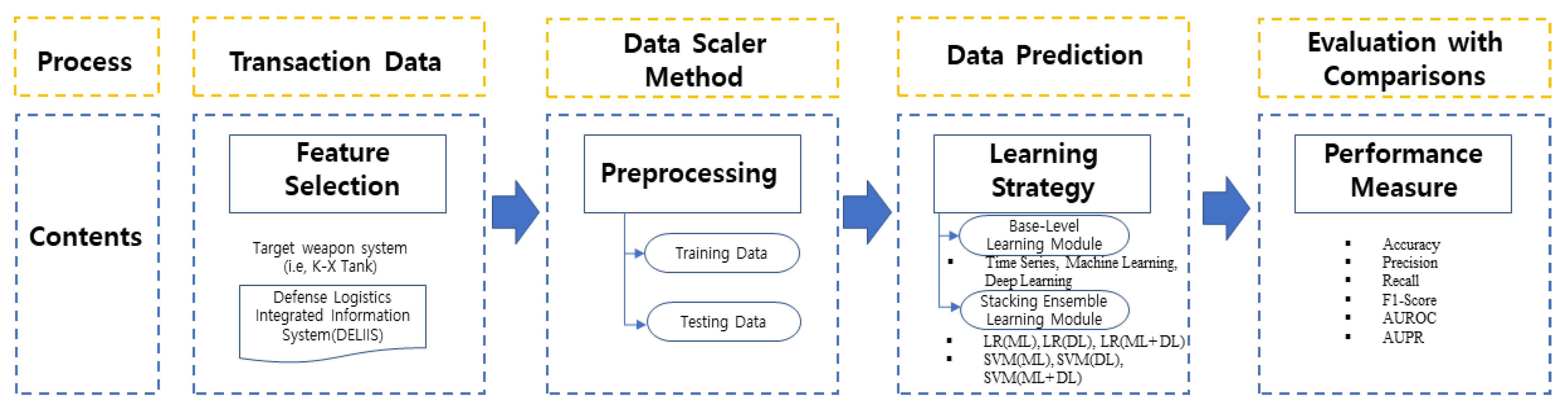
3. Problem Description and Methodology
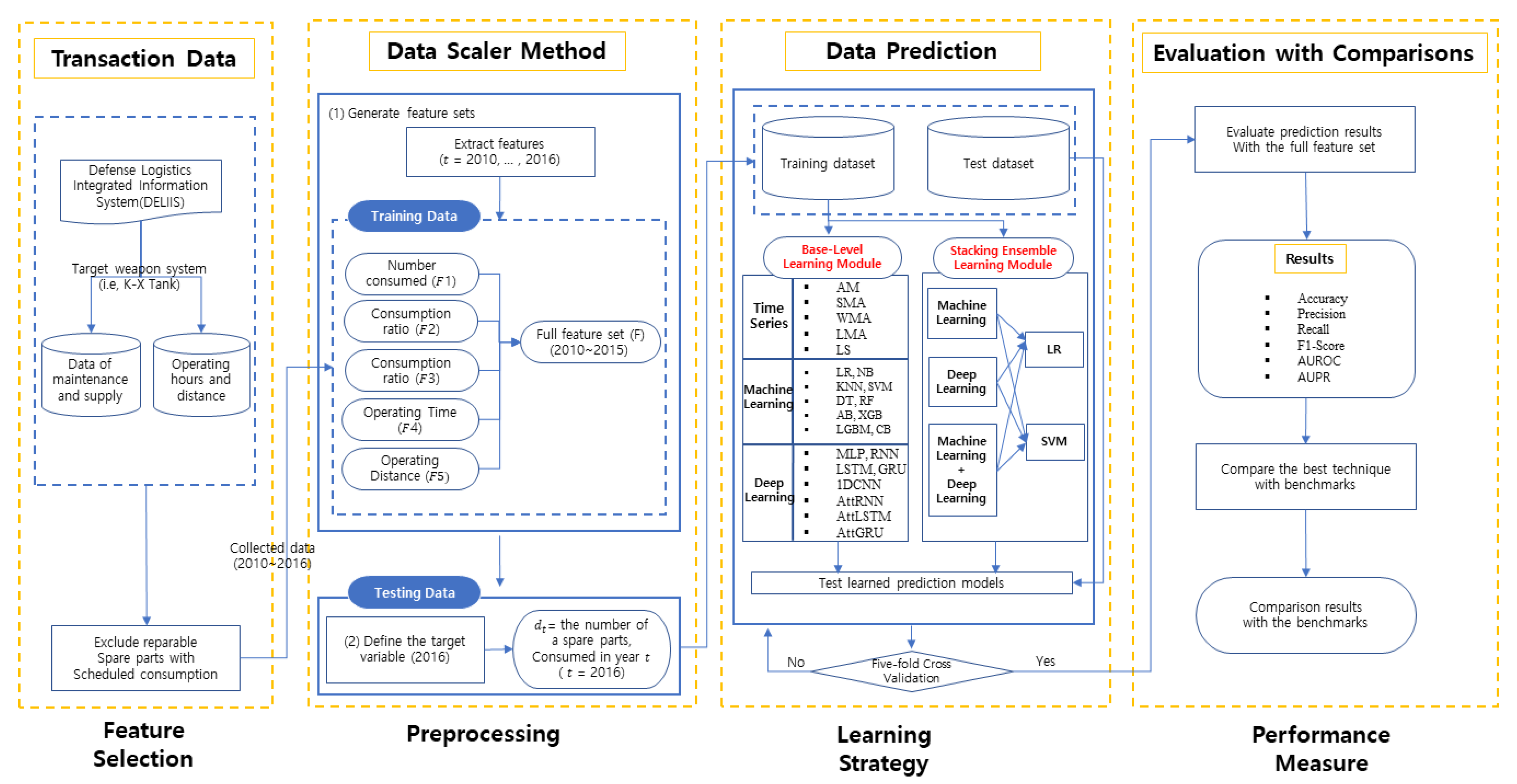
3.1. Data Collection
3.2. Proposed Stacking Ensemble Learning System
4. Experimental Study
4.1. Experimental Design
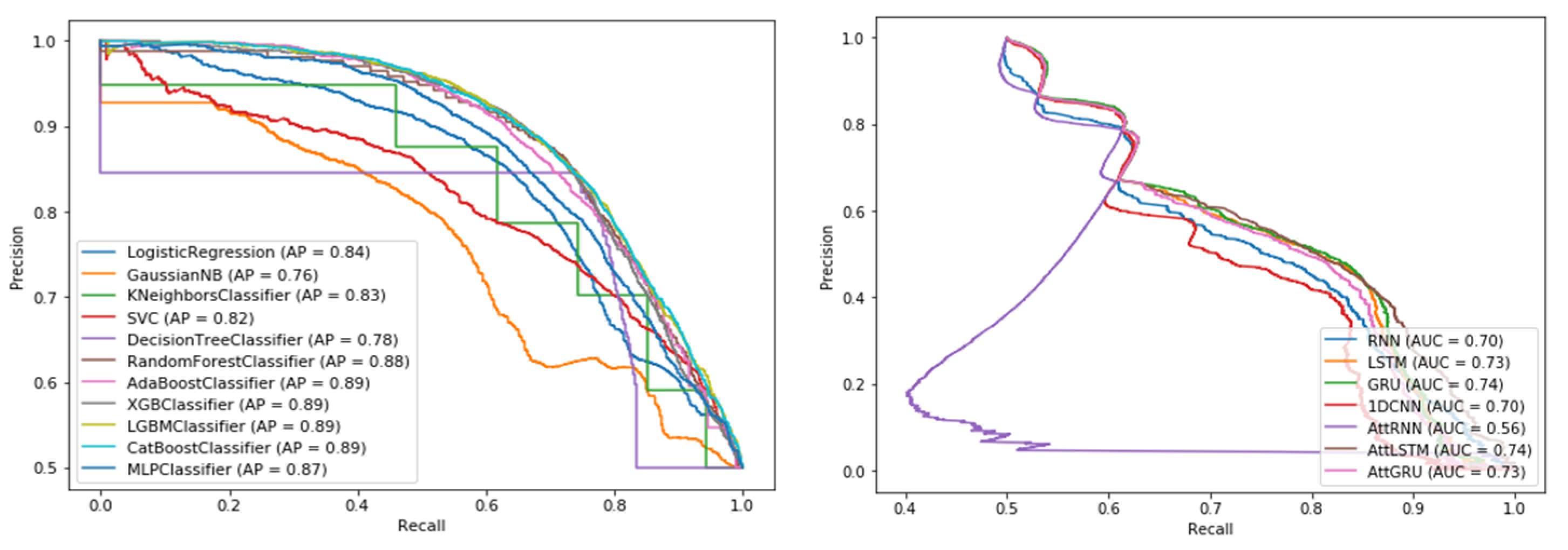
4.2. Classification Results of the Base Model
4.3. Classification Results Obtained Using the Stacking Ensemble Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AM | arithmetic mean |
| SMA | simple moving average |
| WMA | weighted moving average |
| LMA | linear moving average |
| LS | least squares |
| LR | logistic regression |
| NB | naive Bayes |
| KNN | k-nearest neighbor |
| SVM | support vector machine |
| DT | decision tree |
| RF | random forest |
| AB | AdaBoost |
| XGB | XGBoost |
| LGBM | LightGBM |
| CB | CatBoost |
| MLP | multi-layer perceptron |
| RNN | recurrent neural network |
| LSTM | long short-term memory |
| GRU | gated recurrent unit |
| 1DCNN | 1D convolutional neural networks |
| AttRNN | attention recurrent neural network |
| AttLSTM | attention long short-term memory |
| AttGRU | attention gated recurrent unit |
| AUROC | area under the receiver operating characteristic curve |
| AUPR | area under the precision–recall curve |
| ET | execution time |
References
- Adams, J.L.; Abell, J.B.; Isaacson, K.E. Modeling and Forecasting the Demand for Aircraft Recoverable Spare Parts; No. RAND/R-4211-AF/OSD; Rand Corp.: Santa Monica, CA, USA, 1993. [Google Scholar]
- Fisher, M.; Hammond, J.; Obermeyer, W.; Raman, A. Configuring a supply chain to reduce the cost of demand uncertainty. Prod. Oper. Manag. 1997, 6, 211–225. [Google Scholar] [CrossRef]
- Kim, J. Text mining-based approach for forecasting spare parts demand of K-X tanks. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, 16–19 December 2018; pp. 1652–1656. [Google Scholar]
- Bousdekis, A.; Apostolou, D.; Mentzas, G. Predictive maintenance in the 4th industrial revolution: Benefits, business opportunities, and managerial implications. IEEE Eng. Manag. Rev. 2019, 48, 57–62. [Google Scholar] [CrossRef]
- Regatteri, A.; Gamberi, M.; Gamberini, R.; Manzini, R. Managing lumpy demand for aircraft spare parts. J. Air Transp. Manag. 2005, 11, 426–431. [Google Scholar] [CrossRef]
- Kim, J.; Lee, H.; Choi, S. Machine learning based approach for demand forecasting anti-aircraft missiles. In Proceedings of the 2018 5th IEEE International Conference on Industrial Engineering and Applications (ICIEA), Singapore, 26–28 April 2018; pp. 367–372. [Google Scholar]
- Sánchez, A.; Sunmola, F. Factors influencing effectiveness of lean maintenance repair and overhaul in aviation. In Proceedings of the International Symposium on Industrial Engineering and Operations Management, Rabat, Morocco, 11–13 April 2017; pp. 855–863. [Google Scholar]
- Brown, B.B. Characteristics of Demand for Aircraft Spare Parts; Rand Corporation: Santa Monica, CA, USA, 1956. [Google Scholar]
- Ulrich, M.; Jahnke, H.; Langrock, R.; Pesch, R.; Senge, R. Classification-based model selection in retail demand forecasting. Int. J. Forecast. 2022, 38, 209–223. [Google Scholar] [CrossRef]
- Chatfield, C. Time-Series Forecasting; Chapman and Hall/CRC: London, UK, 2000. [Google Scholar]
- Rahamneh, A. Using single and double exponential smoothing for estimating the number of injuries and fatalities resulted from traffic accidents in Jordan (1981–2016). Middle-East J. Sci. Res. 2017, 25, 1544–1552. [Google Scholar]
- Hand, D.J. Principles of data mining. Drug Saf. 2007, 30, 621–622. [Google Scholar] [CrossRef] [PubMed]
- Kass, G.V. An exploratory technique for investigating large quantities of categorical data. Appl. Stat. 1980, 29, 119–127. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2014, 61, 85–117. [Google Scholar]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef] [Green Version]
- Kumpati, S.N.; Kannan, P. Identification and control of dynamical systems using neural networks. IEEE Trans. Neural Netw. 1990, 1, 4–27. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. Interspeech 2010, 2, 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar]
- Li, X.; Xu, Y.; Zhang, X.; Shi, W.; Yue, Y.; Li, Q. Improving short-term bike sharing demand forecast through an irregular convolutional neural network. Transp. Res. Part C Emerg. Technol. 2023, 147, 103984. [Google Scholar] [CrossRef]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I.H. Issues in stacked generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Wang, P.; Gao, Z.; Wang, R.; Khalighi, K. Ensemble of machine learning algorithms using the stacked generalization approach to estimate the warfarin dose. PLoS ONE 2018, 13, e0205872. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable (Number of the Unit) | Meaning | Type of Variable |
|---|---|---|
| Number consumed (6) | Sum of spare parts consumed per item by year | Independent Variable (2010–2015) |
| Number procured (6) | Sum of spare parts procured per item by year | |
| Consumption ratio (6) | Consumption ratio of spare parts consumed per item by year (Consumption ratio = number consumed/number procured) | |
| Equipment operation time (6) | Operating time of equipment by year | |
| Equipment operation distance (6) | Equipment operating distance by year | |
| Number consumed (1) | Demand forecasting of spare parts consumed per item in 2016 (Binary; 0, 1) | Dependent Variable (2016) |
| Model | Method | Accuracy | Precision | Recall | F1-Score | AUROC | AUPR | ET (Sec) |
|---|---|---|---|---|---|---|---|---|
| AM | Time series | 0.692 | 0.776 | 0.692 | 0.706 | 0.690 | 0.620 | 0.002 |
| SMA | 0.725 | 0.771 | 0.725 | 0.731 | 0.720 | 0.650 | 0.001 | |
| WMA | 0.548 | 0.914 | 0.548 | 0.649 | 0.550 | 0.520 | 0.001 | |
| LMA | 0.575 | 0.790 | 0.575 | 0.626 | 0.610 | 0.560 | 0.002 | |
| LS | 0.540 | 0.860 | 0.540 | 0.627 | 0.540 | 0.520 | 0.003 | |
| LR | Machine learning | 0.743 | 0.886 | 0.556 | 0.684 | 0.820 | 0.840 | 0.884 |
| NB | 0.593 | 0.914 | 0.206 | 0.336 | 0.740 | 0.760 | 0.908 | |
| KNN | 0.771 | 0.786 | 0.744 | 0.765 | 0.840 | 0.830 | 1.100 | |
| SVM | 0.716 | 0.811 | 0.564 | 0.665 | 0.810 | 0.820 | 2.490 | |
| DT | 0.801 | 0.838 | 0.747 | 0.79 | 0.790 | 0.780 | 2.521 | |
| RF | 0.800 | 0.834 | 0.75 | 0.79 | 0.860 | 0.880 | 2.908 | |
| AB | 0.791 | 0.839 | 0.721 | 0.775 | 0.860 | 0.890 | 3.139 | |
| XGB | 0.801 | 0.857 | 0.722 | 0.784 | 0.860 | 0.890 | 4.344 | |
| LGBM | 0.802 | 0.858 | 0.723 | 0.785 | 0.870 | 0.890 | 4.600 | |
| CB | 0.801 | 0.853 | 0.727 | 0.785 | 0.870 | 0.890 | 9.811 | |
| MLP | Deep learning | 0.775 | 0.829 | 0.692 | 0.754 | 0.840 | 0.870 | 12.407 |
| RNN | 0.646 | 0.614 | 0.787 | 0.69 | 0.700 | 0.700 | 7.902 | |
| LSTM | 0.646 | 0.614 | 0.787 | 0.69 | 0.730 | 0.730 | 8.928 | |
| GRU | 0.646 | 0.614 | 0.787 | 0.69 | 0.740 | 0.740 | 7.916 | |
| 1DCNN | 0.621 | 0.609 | 0.673 | 0.64 | 0.700 | 0.700 | 5.261 | |
| AttRNN | 0.616 | 0.607 | 0.662 | 0.633 | 0.560 | 0.560 | 2.026 | |
| AttLSTM | 0.646 | 0.614 | 0.787 | 0.69 | 0.740 | 0.740 | 4.576 | |
| AttGRU | 0.646 | 0.614 | 0.787 | 0.69 | 0.730 | 0.730 | 4.295 |
| Model | Accuracy | Precision | Recall | F1-Score | AUROC | AUPR | ET (Sec) |
|---|---|---|---|---|---|---|---|
| LR (ML) | 0.805 | 0.850 | 0.742 | 0.792 | 0.880 | 0.900 | 0.022 |
| LR (DL) | 0.647 | 0.614 | 0.789 | 0.691 | 0.750 | 0.730 | 1.060 |
| LR (ML + DL) | 0.805 | 0.849 | 0.742 | 0.792 | 0.880 | 0.900 | 1.109 |
| SVM (ML) | 0.804 | 0.868 | 0.716 | 0.785 | 0.840 | 0.830 | 0.690 |
| SVM (DL) | 0.647 | 0.615 | 0.790 | 0.691 | 0.750 | 0.760 | 3.161 |
| SVM (ML + DL) | 0.804 | 0.872 | 0.713 | 0.784 | 0.840 | 0.830 | 1.622 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-D.; Kim, T.-H.; Han, S.W. Demand Forecasting of Spare Parts Using Artificial Intelligence: A Case Study of K-X Tanks. Mathematics 2023, 11, 501. https://doi.org/10.3390/math11030501
Kim J-D, Kim T-H, Han SW. Demand Forecasting of Spare Parts Using Artificial Intelligence: A Case Study of K-X Tanks. Mathematics. 2023; 11(3):501. https://doi.org/10.3390/math11030501
Chicago/Turabian StyleKim, Jae-Dong, Tae-Hyeong Kim, and Sung Won Han. 2023. "Demand Forecasting of Spare Parts Using Artificial Intelligence: A Case Study of K-X Tanks" Mathematics 11, no. 3: 501. https://doi.org/10.3390/math11030501