
A Graph Pointer Network-Based Multi-Objective Deep Reinforcement Learning Algorithm for Solving the Traveling Salesman Problem


Abstract
:1. Introduction
- A novel algorithm called MODGRL is introduced, which integrates a graph neural network with DRL-MOA to learn the graphical structures of TSPs. It outperforms the same selected algorithms from [7] in terms of hypervolume indicator.
- MODGRL and other algorithms’ performance are assessed by hypervolume, spread and CPF indicators, to demonstrate the importance of suitable and sufficient quality indicator selection.
- Additional experiments with 8000 iterations are performed, to demonstrate potential pitfalls that may be overlooked by many researchers.
- The same additional experiments also demonstrate the importance of using a stopping criterion that can be applied to algorithms in different categories (e.g., maximum time budget) [14].
2. Related Work
3. Multi-Objective Deep Graph Pointer Based Reinforcement Learning
3.1. Traveling Salesman Problems
3.2. Training and Validation datasets
3.3. Hyperparameters
3.4. Model
- The decomposition strategy,
- Self-critic reinforcement learning agent,
- Graph pointer network for approximations.
3.5. The Decomposition Strategy
3.6. Self-Critic Reinforcement Learning Agent
3.6.1. Actor
3.6.2. Critic
| Listing 1. The MODGRL Algorithm. |
for w1,w2 in W: |
for i in range(0,e): |
for b in T: |
t1,R1,prob = Actor() |
t2, R2 = Critic() |
loss = R1 - R2 |
loss.backwards() |
save_model() |
3.7. Graph Pointer Network for Approximations
4. Experiments and Results
4.1. Parameter Settings
4.2. Training and Testing Datasets
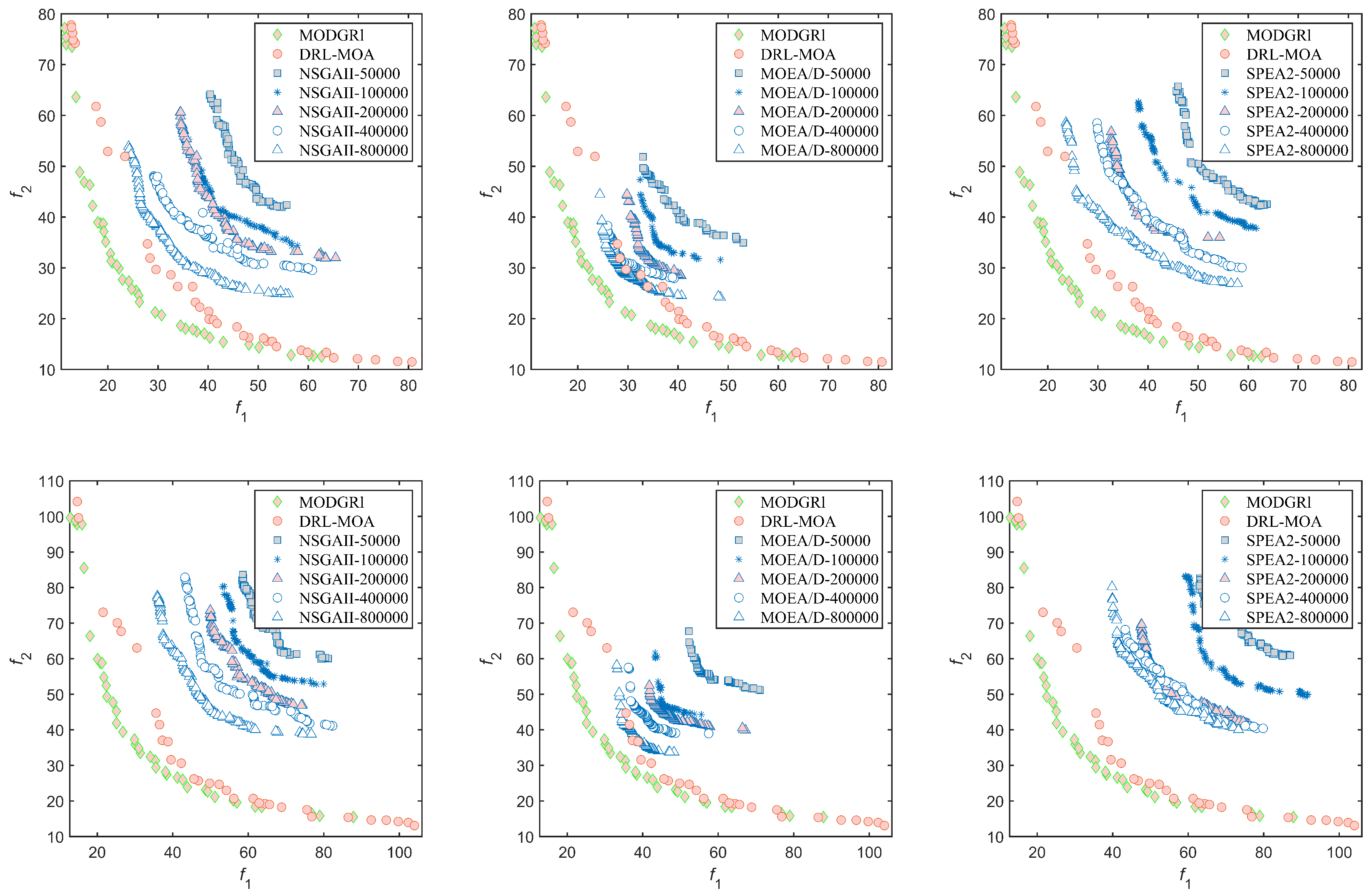
4.3. Experimental Results
5. Discussions
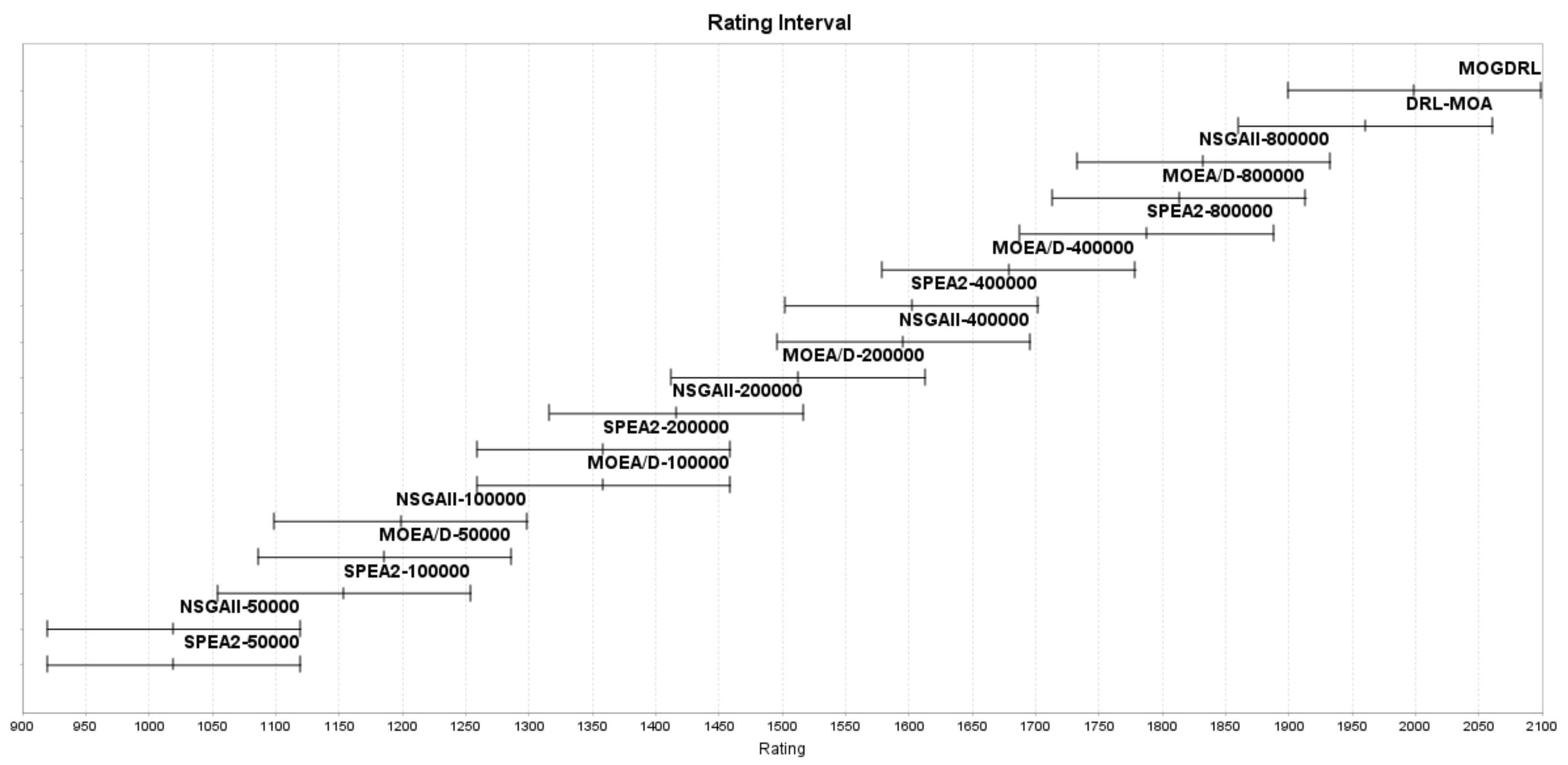
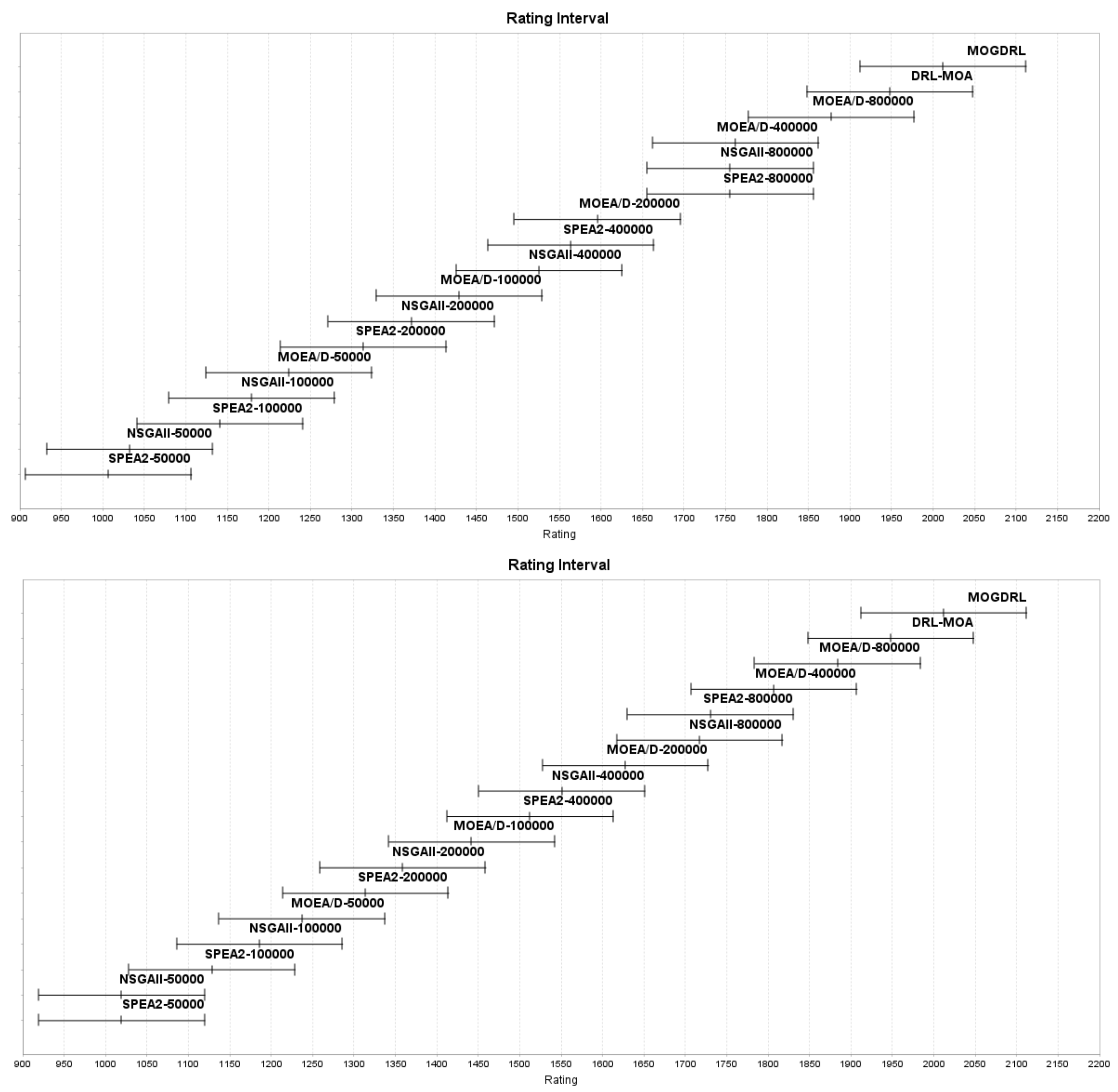
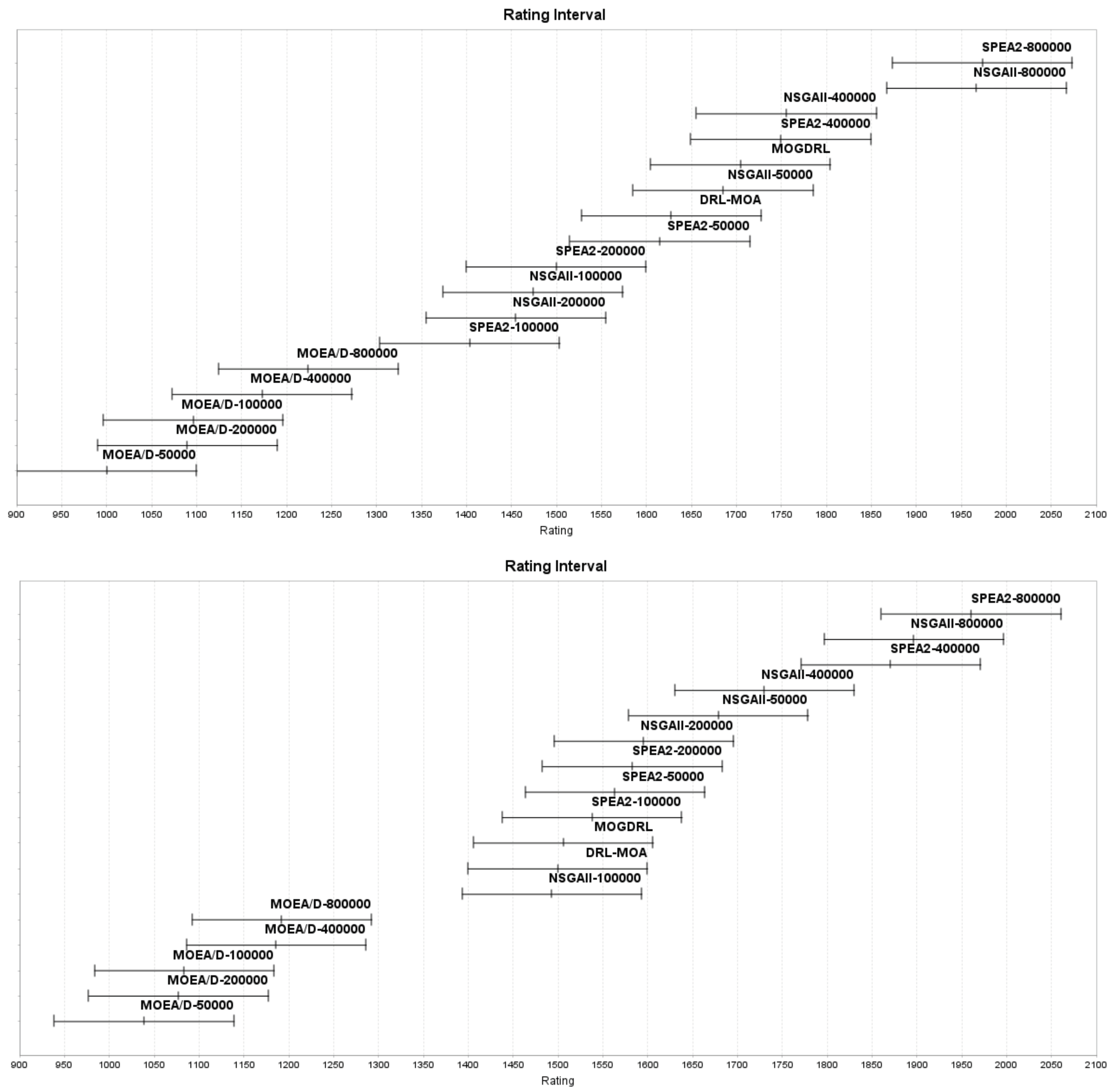
- Quality indicators: Although MODGRL stands out in terms of the hypervolume indicator for all the datasets, its CPF performance was only average between all the 17 competitors. Many researchers have discussed the applicability and advantages of different quality indicators for multi-objective optimization problems (e.g., [49]). As multi-objective deep reinforcement learning is emerging, utilizing suitable and multiple quality indicators is a must, so that the algorithms’ performances in different perspectives can be examined more thoroughly.
- Fair comparisons: Comparing experiments under the exact same settings is a precondition for all scientific disciplines. Otherwise, the findings may be incorrect and/or misleading, and the derived conclusions may be questionable. TSPs are a popular combinatorial problem that can be solved by algorithms in different categories. In this paper and [7], two kinds of algorithms (i.e., evolutionary algorithms and deep reinforcement learning algorithms) are compared with each other. First, the performance of both kinds of algorithms may be affected greatly by their parameter or hyperparameter settings. The best settings for each algorithm may be investigated first by following [35]. However, the stopping criteria of the two kinds are not comparable. For example, the maximum number of fitness evaluations (maxFEs), maximum number of iterations (maxIter), and max time budget are seen commonly as fixed stopping criteria to terminate evolutionary algorithms. Other criteria, on the other hand, terminate algorithms when the results do not improve any further during the evolutionary process. deep learning algorithms, conversely, use epoch as a fixed stopping criterion. Similarly, some researchers stop deep learning algorithms when loss begins to increase or accuracy begins to decrease. However, the criteria for evolutionary algorithms and those for deep learning algorithms are not always comparable (e.g., maxFEs vs. epoch, or fitness no longer improve vs. accuracy decreases). As observed in Appendices Appendix A.2 and Appendix A.3 in Appendix A, NSGA-II and SPEA2 with 8000 iterations outperformed all the other algorithms in terms of spread and CPF. If there were no such experiments with extra iterations presented, readers would have concluded that MODGRL (or DRL-MOA in some experiments) was the best in terms of all the three quality indicators. With such, max time budget (i.e., maximum CPU time) might be the most objective stopping criteron for comparing algorithms of the same, or even different, categories.
- Performance on Large Scale TSP: MODGRL was trained on a multi-objective TSP with only 40 cities. As is evident from the results obtained from the experiments, it was able to perform well on problems with 100, 150 and 200 cities. Based on this performance, it can be predicted that the MODGRL algorithm can scale very well to even large scale problems with more than 200 cities. Hence, we conducted a number of experiments on 500, 750, and 1000 cities. The experimental results show that MODGRL remained competitive for large scale multi-objective TSPs. Due to the space constraint, the experimental results are not included. Readers may contact the authors for more details.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Performance based on the Hypervolume Indicator

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | 100 Cities | 150 Cities | 200 Cities |
|---|---|---|---|
| NSGAII-50000 | 7180.84 ± 155.03 | 15,199.3 ± 79.02 | 25,753.2 ± 530.55 |
| NSGAII-100000 | 7723.16 ± 158.98 | 16,318.5 ± 280.08 | 27,784.8 ± 517.64 |
| NSGAII-200000 | 8165.2 ± 156.01 | 17,218.6 ± 294.58 | 29,841.6 ± 438.71 |
| NSGAII-400000 | 8547.12 ± 148.20 | 18,292.5 ± 217.11 | 31,471.7 ± 389.45 |
| MOEAD-50000 | 7731.55 ± 99.34 | 16,544.1 ± 292.57 | 28,560.6 ± 392.84 |
| MOEAD-100000 | 8055.78 ± 122.92 | 17,591.8 ± 254.73 | 30,523.3 ± 287.90 |
| MOEAD-200000 | 8382.7 ± 117.92 | 18,454.8 ± 232.21 | 32,019.1 ± 362.77 |
| MOEAD-400000 | 8681.01 ± 53.34 | 19,179.9 ± 145.75 | 33,599.7 ± 226.31 |
| SPEA2-50000 | 7164.03 ± 131.36 | 15,034.5 ± 325.94 | 25,611.6 ± 685.15 |
| SPEA2-100000 | 7600.62 ± 114.64 | 16,085.3 ± 217.06 | 27,178.7 ± 332.80 |
| SPEA2-200000 | 8072.38 ± 155.11 | 17,053.4 ± 149.45 | 29,320.9 ± 659.21 |
| SPEA2-400000 | 8556.86 ± 130.54 | 18,305.1 ± 276.31 | 31,133.4 ± 516.30 |
| DRL-MOA | 9730.87 ± 64.08 | 22,409.4 ± 63.55 | 40,396.2 ± 197.36 |
| MODGRL | 9847.84 ± 70.98 | 22,720.5 ± 80.86 | 41,010.4 ± 105.59 |
| NSGAII-800000 | 8903.32 ± 96.95 | 19,194.4 ± 270.47 | 32,876.2 ± 514.30 |
| MOEAD-800000 | 8886.74 ± 96.58 | 19,837.3 ± 193.08 | 34,927.2 ± 353.19 |
| SPEA2-800000 | 8853.22 ± 139.65 | 19,259.1 ± 322.75 | 32,857.9 ± 514.39 |


Appendix A.2. Performance Based on the Spread Indicator
| Algorithm | 100 Cities | 150 Cities | 200 Cities |
|---|---|---|---|
| NSGAII-50000 | 0.981 ± 0.007 | 0.979 ± 0.006 | 0.984 ± 0.005 |
| NSGAII-100000 | 0.989 ± 0.008 | 0.983 ± 0.004 | 0.982 0.007 |
| NSGAII-200000 | 0.984 ± 0.014 | 0.980 ± 0.008 | 0.978 ± 0.010 |
| NSGAII-400000 | 0.954 ± 0.026 | 0.961 ± 0.017 | 0.963 ± 0.019 |
| MOEAD-50000 | 1.017 ± 0.008 | 1.012 ± 0.004 | 1.008 ± 0.004 |
| MOEAD-100000 | 1.019 ± 0.010 | 1.012 ± 0.003 | 1.011 ± 0.004 |
| MOEAD-200000 | 1.014 ± 0.005 | 1.011 ± 0.003 | 1.009 ± 0.004 |
| MOEAD-400000 | 1.007 ± 0.008 | 1.015 ± 0.012 | 1.008 ± 0.005 |
| SPEA2-50000 | 0.979 ± 0.011 | 0.977 ± 0.008 | 0.980 ± 0.008 |
| SPEA2-100000 | 0.989 ± 0.006 | 0.985 ± 0.006 | 0.976 ± 0.005 |
| SPEA2-200000 | 0.985 ± 0.013 | 0.972 ± 0.014 | 0.974 ± 0.008 |
| SPEA2-400000 | 0.959 ± 0.018 | 0.959 ± 0.019 | 0.952 ± 0.016 |
| DRL-MOA | 0.937 ± 0.018 | 0.943 ± 0.015 | 0.937 ± 0.020 |
| MODGRL | 0.934 ± 0.013 | 0.943 ± 0.017 | 0.942 ± 0.017 |
| NSGAII-800000 | 0.930 ± 0.011 | 0.932 ± 0.006 | 0.942 ± 0.011 |
| MOEAD-800000 | 0.998 ± 0.011 | 1.005 ± 0.008 | 1.009 ± 0.007 |
| SPEA2-800000 | 0.926 ± 0.017 | 0.925 ± 0.009 | 0.938 ± 0.013 |

Appendix A.3. Performance Based on the CPF Indicator
| Algorithm | 100 Cities | 150 Cities | 200 Cities |
|---|---|---|---|
| NSGAII-50000 | 0.488 ± 0.026 | 0.520 ± 0.028 | 0.522 ± 0.070 |
| NSGAII-100000 | 0.442 ± 0.038 | 0.473 ± 0.047 | 0.480 ± 0.041 |
| NSGAII-200000 | 0.426 ± 0.062 | 0.464 ± 0.049 | 0.499 ± 0.031 |
| NSGAII-400000 | 0.559 ± 0.101 | 0.565 ± 0.079 | 0.549 ± 0.085 |
| MOEAD-50000 | 0.130 ± 0.027 | 0.115 ± 0.032 | 0.137 ± 0.049 |
| MOEAD-100000 | 0.181 ± 0.042 | 0.178 ± 0.026 | 0.166 ± 0.048 |
| MOEAD-200000 | 0.241 ± 0.054 | 0.178 ± 0.066 | 0.157 ± 0.056 |
| MOEAD-400000 | 0.351 ± 0.043 | 0.250 ± 0.053 | 0.255 ± 0.063 |
| SPEA2-50000 | 0.496 ± 0.039 | 0.513 ± 0.053 | 0.511 ± 0.050 |
| SPEA2-100000 | 0.430 ± 0.053 | 0.450 ± 0.041 | 0.482 ± 0.049 |
| SPEA2-200000 | 0.442 ± 0.053 | 0.486 ± 0.058 | 0.509 ± 0.044 |
| SPEA2-400000 | 0.532 ± 0.066 | 0.561 ± 0.083 | 0.620 ± 0.085 |
| DRL-MOA | 0.541 ± 0.057 | 0.506 ± 0.048 | 0.482 ± 0.046 |
| MODGRL | 0.553 ± 0.026 | 0.533 ± 0.039 | 0.489 ± 0.035 |
| NSGAII-800000 | 0.637 ± 0.039 | 0.666 ± 0.034 | 0.635 ± 0.054 |
| MOEAD-800000 | 0.408 ± 0.055 | 0.328 ± 0.056 | 0.296 ± 0.082 |
| SPEA2-800000 | 0.656 ± 0.055 | 0.678 ± 0.048 | 0.659 ± 0.063 |

References
- El Naqa, I.; Murphy, M.J. What Is Machine Learning? In Machine Learning in Radiation Oncology: Theory and Applications; El Naqa, I., Li, R., Murphy, M.J., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 3–11. [Google Scholar]
- Coello Coello, C.A. An Introduction to Evolutionary Algorithms and Their Applications. In Proceedings of the International Symposium and School on Advancex Distributed Systems, Guadalajara, Mexico, 14–18 January 2005; Ramos, F.F., Larios Rosillo, V., Unger, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 425–442. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Minsky, M.L. Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain-Model Problem. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1954. [Google Scholar]
- Levin, E.; Pieraccini, R.; Eckert, W. Using Markov decision process for learning dialogue strategies. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 12–15 May 1998; Volume 1, pp. 201–204. [Google Scholar]
- Miki, S.; Yamamoto, D.; Ebara, H. Applying Deep Learning and Reinforcement Learning to Traveling Salesman Problem. In Proceedings of the 2018 International Conference on Computing, Electronics Communications Engineering, Southend, UK, 16–17 August 2018; pp. 65–70. [Google Scholar]
- Li, K.; Zhang, T.; Wang, R. Deep Reinforcement Learning for Multiobjective Optimization. IEEE Trans. Cybern. 2020, 51, 3103–3114. [Google Scholar] [CrossRef] [Green Version]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Vamplew, P.; Nahavandi, S.; Dazeley, R.; Lim, C.P. A multi-objective deep reinforcement learning framework. Eng. Appl. Artif. Intell. 2020, 96, 103915. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Ma, Q.; Ge, S.; He, D.; Thaker, D.; Drori, I. Combinatorial Optimization by Graph Pointer Networks and Hierarchical Reinforcement Learning. arXiv 2019, arXiv:1911.04936. [Google Scholar]
- Ravber, M.; Mernik, M.; Črepinšek, M. The impact of quality indicators on the rating of multi-objective evolutionary algorithms. Appl. Soft Comput. 2017, 55, 265–275. [Google Scholar] [CrossRef]
- Ravber, M.; Mernik, M.; Črepinšek, M. Ranking multi-objective evolutionary algorithms using a chess rating system with quality indicator ensemble. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia-San Sebastian, Spain, 5–8 June 2017; pp. 1503–1510. [Google Scholar]
- Ravber, M.; Liu, S.H.; Mernik, M.; Črepinšek, M. Maximum number of generations as a stopping criterion considered harmful. Appl. Soft Comput. 2022, 128, 109478. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Santosa, B. Tutorial on Ant Colony Optimization. Institut Teknologi Sepuluh Nopember, ITS. Surabaya. 2012. Available online: https://bsantosa.files.wordpress.com/2015/03/aco-tutorial-english2.pdf (accessed on 22 November 2022).
- Shamsaldin, A.S.; Rashid, T.A.; Al-Rashid Agha, R.A.; Al-Salihi, N.K.; Mohammadi, M. Donkey and smuggler optimization algorithm: A collaborative working approach to path finding. J. Comput. Des. Eng. 2019, 6, 562–583. [Google Scholar] [CrossRef]
- Lust, T.; Teghem, J. The Multiobjective Traveling Salesman Problem: A Survey and a New Approach. In Advances in Multi-Objective Nature Inspired Computing; Coello Coello, C.A., Dhaenens, C., Jourdan, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 119–141. [Google Scholar]
- Cheikhrouhou, O.; Khoufi, I. A Comprehensive Survey on the Multiple Traveling Salesman Problem: Applications, Approaches and Taxonomy. Comput. Sci. Rev. 2021, 40, 100369. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015. [Google Scholar] [CrossRef]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A Reinforcement Learning approach to the traveling salesman problem. In Machine Learning Proceedings 1995; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 252–260. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Grondman, I.; Busoniu, L.; Lopes, G.A.D.; Babuska, R. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients. IEEE Trans. Syst. Man, Cybern. Part C (Appl. Rev.) 2012, 42, 1291–1307. [Google Scholar] [CrossRef] [Green Version]
- Bi, Y.; Meixner, C.C.; Bunyakitanon, M.; Vasilakos, X.; Nejabati, R.; Simeonidou, D. Multi-Objective Deep Reinforcement Learning Assisted Service Function Chains Placement. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4134–4150. [Google Scholar] [CrossRef]
- Keat, E.Y.; Sharef, N.M.; Yaakob, R.; Kasmiran, K.A.; Marlisah, E.; Mustapha, N.; Zolkepli, M. Multiobjective Deep Reinforcement Learning for Recommendation Systems. IEEE Access 2022, 10, 65011–65027. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Zhang, Z.; Zhou, Y. MODRL/D-EL: Multiobjective Deep Reinforcement Learning with Evolutionary Learning for Multiobjective Optimization. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, H.; Wang, J.; Zhang, Z. MODRL/D-AM: Multiobjective Deep Reinforcement Learning Algorithm Using Decomposition and Attention Model for Multiobjective Optimization. arXiv 2020. [Google Scholar] [CrossRef]
- Wang, H.; Wang, R.; Xu, H.; Kun, Z.; Yi, C.; Niyato, D. Multi-objective Mobile Charging Scheduling on the Internet of Electric Vehicles: A DRL Approach. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Rio de Janeiro, Brazil, 4–8 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, C.; Wang, Q.; Gong, W.; Yan, X. Multi-objective deep reinforcement learning for emergency scheduling in a water distribution network. Memetic Comput. 2022, 14, 211–223. [Google Scholar] [CrossRef]
- Hajiakhondi-Meybodi, Z.; Mohammadi, A.; Abouei, J. Deep Reinforcement Learning for Trustworthy and Time-Varying Connection Scheduling in a Coupled UAV-Based Femtocaching Architecture. IEEE Access 2021, 9, 32263–32281. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, Y.; Weng, P.; Han, S. Generalization in Deep RL for TSP Problems via Equivariance and Local Search. arXiv 2022, arXiv:2110.03595. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Replication and Comparison of Computational Experiments in Applied Evolutionary Computing: Common Pitfalls and Guidelines to Avoid Them. Appl. Soft Comput. 2014, 19, 161–170. [Google Scholar] [CrossRef]
- Ma, M.; Li, H. A hybrid genetic algorithm for solving bi-objective traveling salesman problems. J. Phys. Conf. Ser. 2017, 887, 012065. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Deep Reinforcement Learning. arXiv 2018, arXiv:1810.06339. [Google Scholar]
- Hameed, I. Multi-objective Solution of Traveling Salesman Problem with Time. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications 2020, Jaipur, India, 13–15 February 2020; pp. 121–132. [Google Scholar] [CrossRef]
- Reinelt, G. TSPLIB—A Traveling Salesman Problem Library. ORSA J. Comput. 1991, 3, 376–384. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Črepinšek, M. A Chess Rating System for Evolutionary Algorithms: A New Method for the Comparison and Ranking of Evolutionary Algorithms. Inf. Sci. 2014, 277, 656–679. [Google Scholar] [CrossRef]
- Veček, N.; Črepinšek, M.; Mernik, M. On the influence of the number of algorithms, problems, and independent runs in the comparison of evolutionary algorithms. Appl. Soft Comput. 2017, 54, 23–45. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Pernet, C. Null hypothesis significance testing: A short tutorial. F1000Research 2017, 4, 621. [Google Scholar] [CrossRef] [Green Version]
- While, L.; Hingston, P.; Barone, L.; Huband, S. A Faster Algorithm for Calculating Hypervolume. IEEE Trans. Evol. Comput. 2006, 10, 29–38. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wu, L.; Yuan, X. Multi-objective Self-Adaptive Differential Evolution with Elitist Archive and Crowding Entropy-based Diversity Measure. Soft Comput. 2010, 14, 193. [Google Scholar] [CrossRef]
- Tian, Y.; Cheng, R.; Zhang, X.; Jin, Y. PlatEMO: A MATLAB Platform for Evolutionary Multi-Objective Optimization [Educational Forum]. IEEE Comput. Intell. Mag. 2017, 12, 73–87. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Cheng, R.; Zhang, X.; Li, M.; Jin, Y. Diversity Assessment of Multi-Objective Evolutionary Algorithms: Performance Metric and Benchmark Problems [Research Frontier]. IEEE Comput. Intell. Mag. 2019, 14, 61–74. [Google Scholar] [CrossRef]
- Zhou, A.; Jin, Y.; Zhang, Q.; Sendhoff, B.; Tsang, E. Combining Model-based and Genetics-based Offspring Generation for Multi-objective Optimization Using a Convergence Criterion. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 892–899. [Google Scholar]
- Audet, C.; Bigeon, J.; Cartier, D.; Digabel, S.L.; Salomon, L. Performance Indicators in Multiobjective Optimization. Eur. J. Oper. Res. 2021, 292, 397–422. [Google Scholar] [CrossRef]
- Sršen, S.; Mernik, M. A JSSP solution for production planning optimization combining industrial engineering and evolutionary algorithms. Comput. Sci. Inf. Syst. 2021, 18, 349–378. [Google Scholar] [CrossRef]





| Component | Functionality | Network Type | Input | Output |
|---|---|---|---|---|
| Embedder 1 | Embed all the coordinates values of all the cities in the entire problem. | Linear Layer | Vector containing all city coordinates . | Vector of size . |
| Embedder 2 | Embed the coordinate values of the current city. | Linear Layer | Vector containing current city coordinates . | Vector of size . |
| Encoder 1 | Use the output from Embedder 1 and aggregate the neighboring values to capture the entire graph. | Graph Encoder | Output from Embedder 1. | Encoded representation of the cities of size x |
| Encoder 2 | Use the output from Embedder 1 to capture information related to the sequence of visited cities. | LSTM | Output from Embedder 2, Previous cell gate value, Previous output gate value. | Output gate value, cell gate value. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perera, J.; Liu, S.-H.; Mernik, M.; Črepinšek, M.; Ravber, M. A Graph Pointer Network-Based Multi-Objective Deep Reinforcement Learning Algorithm for Solving the Traveling Salesman Problem. Mathematics 2023, 11, 437. https://doi.org/10.3390/math11020437
Perera J, Liu S-H, Mernik M, Črepinšek M, Ravber M. A Graph Pointer Network-Based Multi-Objective Deep Reinforcement Learning Algorithm for Solving the Traveling Salesman Problem. Mathematics. 2023; 11(2):437. https://doi.org/10.3390/math11020437
Chicago/Turabian StylePerera, Jeewaka, Shih-Hsi Liu, Marjan Mernik, Matej Črepinšek, and Miha Ravber. 2023. "A Graph Pointer Network-Based Multi-Objective Deep Reinforcement Learning Algorithm for Solving the Traveling Salesman Problem" Mathematics 11, no. 2: 437. https://doi.org/10.3390/math11020437