

A Two-Machine Learning Date Flow-Shop Scheduling Problem with Heuristics and Population-Based GA to Minimize the Makespan
 , ,
, ,  and
and
Abstract
:1. Introduction
- We introduce the two-machine flow-shop scheduling problem with step-learning, where job processing times decrease if they start after their job-dependent learning dates;
- We establish that the proposed scheduling problem is NP-hard, which implies that finding an exact optimal solution is computationally challenging;
- We present an integer programming model as a method to address the scheduling problem, providing a theoretical framework for optimization.
2. Notations and Problem Definition
- {M1, M2}: represents a collection of two machine codes;
- = {J1, J2, …, Jn}: represents a collection of n labeled jobs;
- and : represent the actual processing time of job j on machine 1 and machine 2, respectively;
- and : represent the learning dates for job j on machine 1 and machine 2, respectively;
- and : represent the original processing times of job Jj on machine 1 and machine 2 in ;
- and : represent the processing time of job Jj on machine one and machine two, respectively, under the learned schedule via σ for the jobs sorted by order;
- : represent two full schedules of jobs;
- : represent two partial subsequences of jobs;
- and : represent the starting times for a job on machine 1 and machine 2 in ;
- and : represent the completion times of job i and job j on machine k in schedule , k = 1, 2;
- and : represent the completion times of job i and job j on machine k in schedule , k = 1, 2;
- [ ]: represents the position of the job in a certain schedule.
3. Exact Solution Methods
Branch-and-Bound Method
4. Heuristics and Population-Based Genetic Algorithm
- Heuristic 1 (named as J2LD-pi)
- Step 1: Input a set of ;
- Step 2: Set and , i;
- Step 3: Set , , and
- Step 4: Find and
- Step 5: If , then job is assigned to be fth position in a schedule,
- (i.e., ), f = f + 1, and delete job from . Go to Step 7;
- Step 6: If , then job is assigned to be lth position in a schedule,
- (i.e., ), l = l − 1, and delete job from ;
- Step 7: If is not empty, return to do Step 4 to Step 6; otherwise, output the final complete schedule ;
- Step 8: Refine the final complete schedule by using a pairwise interchange method.
- Heuristic 2 (named as J2U-pi)
- Step 1: Input a set of ;
- Step 2: Set and , i;
- Step 3 to Step 8 are the same as those of J2LD.
- Heuristic 3 (named as J2V-pi)
- Step 1: Input a set of ;
- Step 2: Set and , i;
- Step 3 to Step 8 are the same as those of J2LD.
- Heuristic 4 (named as J2UV-pi)
- Step 1: Input a set of ;
- Step 2: Set and , i;
- Step 3 to Step 8 are the same as those of J2LD.
Genetic Algorithm
- The details of GA:
- Step 1. Initialize parameters: Set the values of n_size (number of parents), Pm (mutation rate), and g_size (number of iterations);
- Step 2. Generate an initial population of n_size parents (schedules) and evaluate their fitness values;
- Step 3. Iterate i from 1 to g_size:
- -
- Select two parents from the population using the roulette wheel method;
- -
- Apply linear order crossover to produce a set of n_size offspring;
- -
- For each offspring, generate a random number r (0 < r < 1). If r is less than Pm, perform a displacement mutation to create a new offspring;
- -
- Keep track of the best schedule found so far;
- -
- Replace the current population of parents with their offspring;
- Step 4. End the iteration loop (g_size);
- Step 5. Output the final best schedule and its corresponding fitness value.
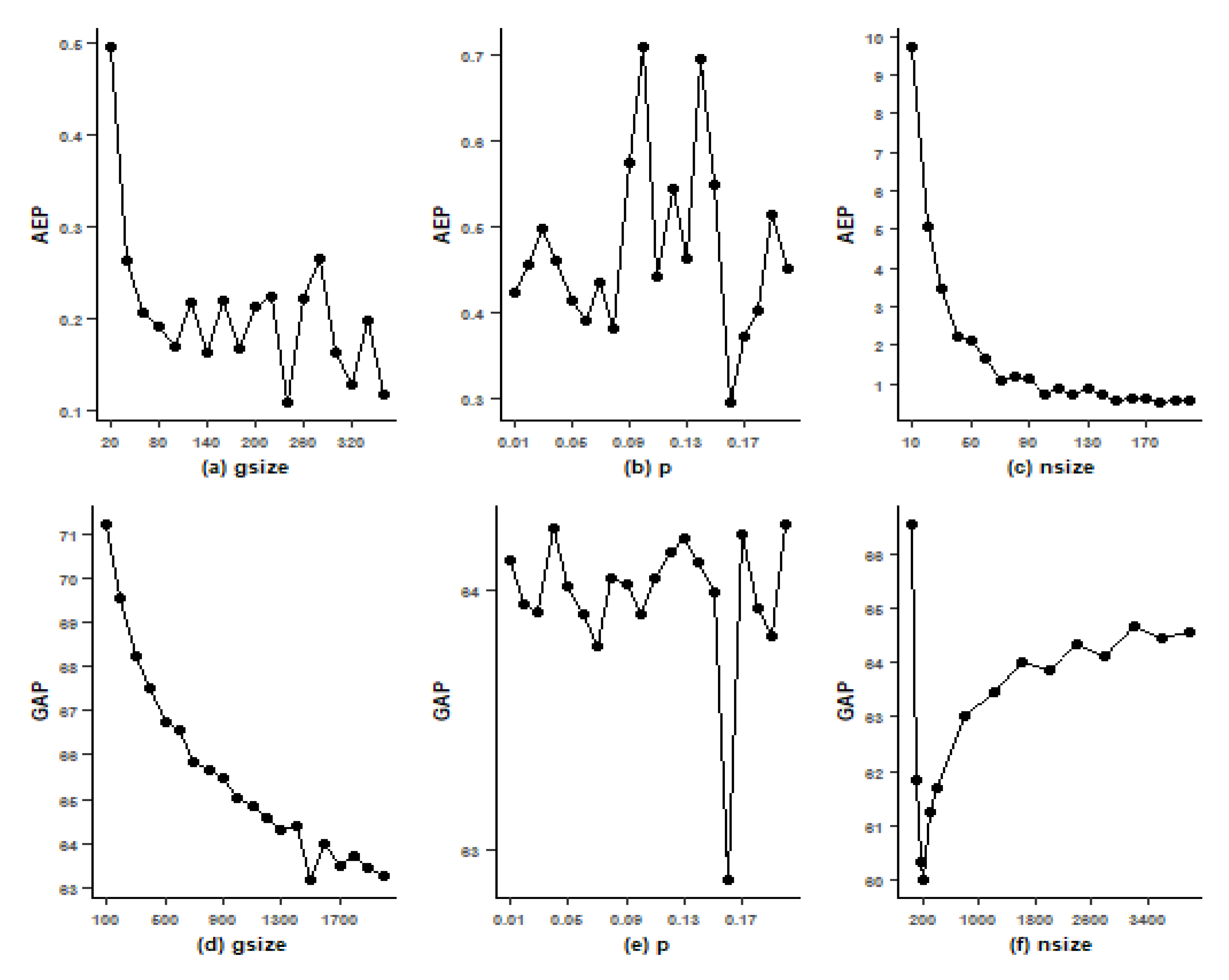
5. The Parameter Exploration for GA
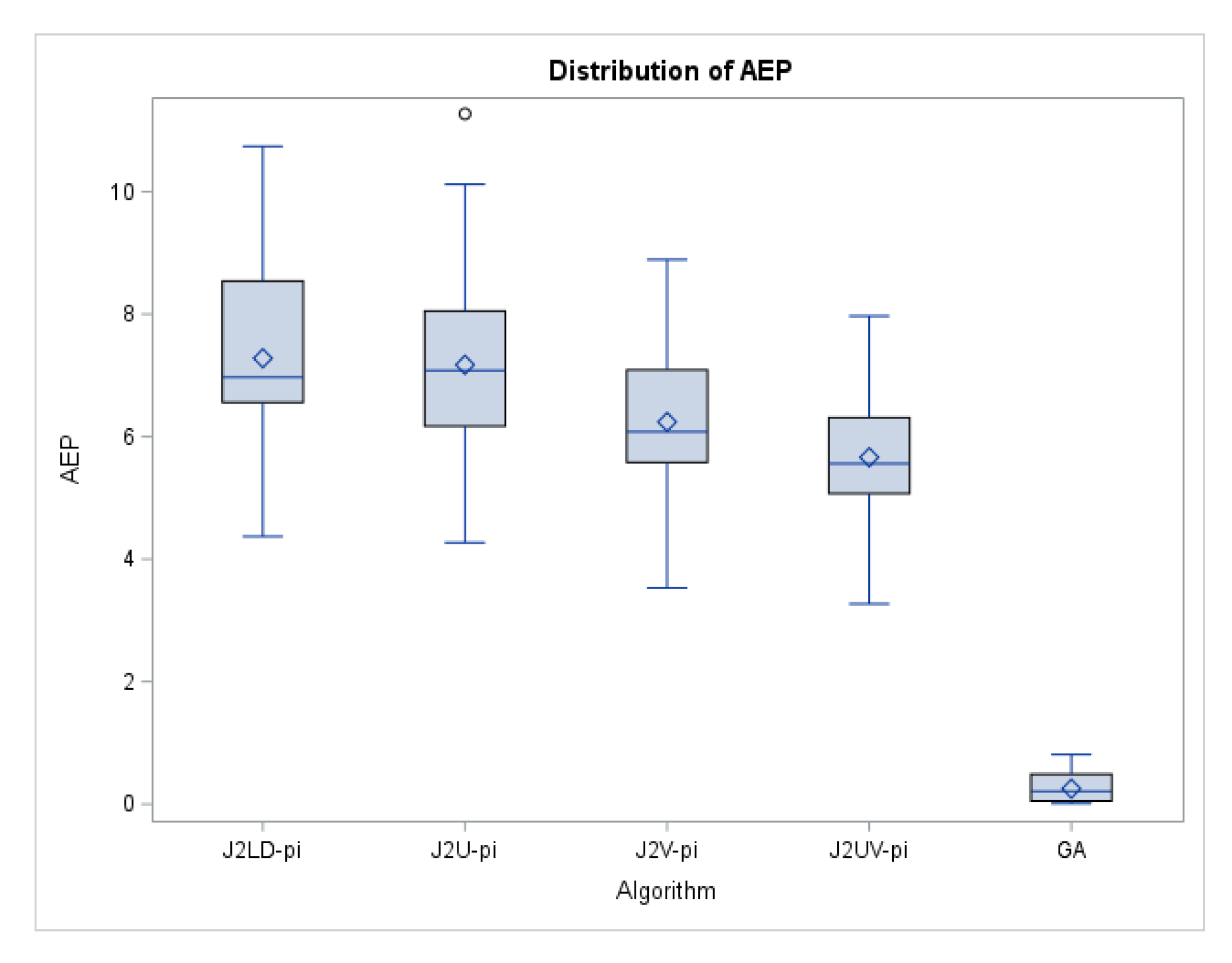
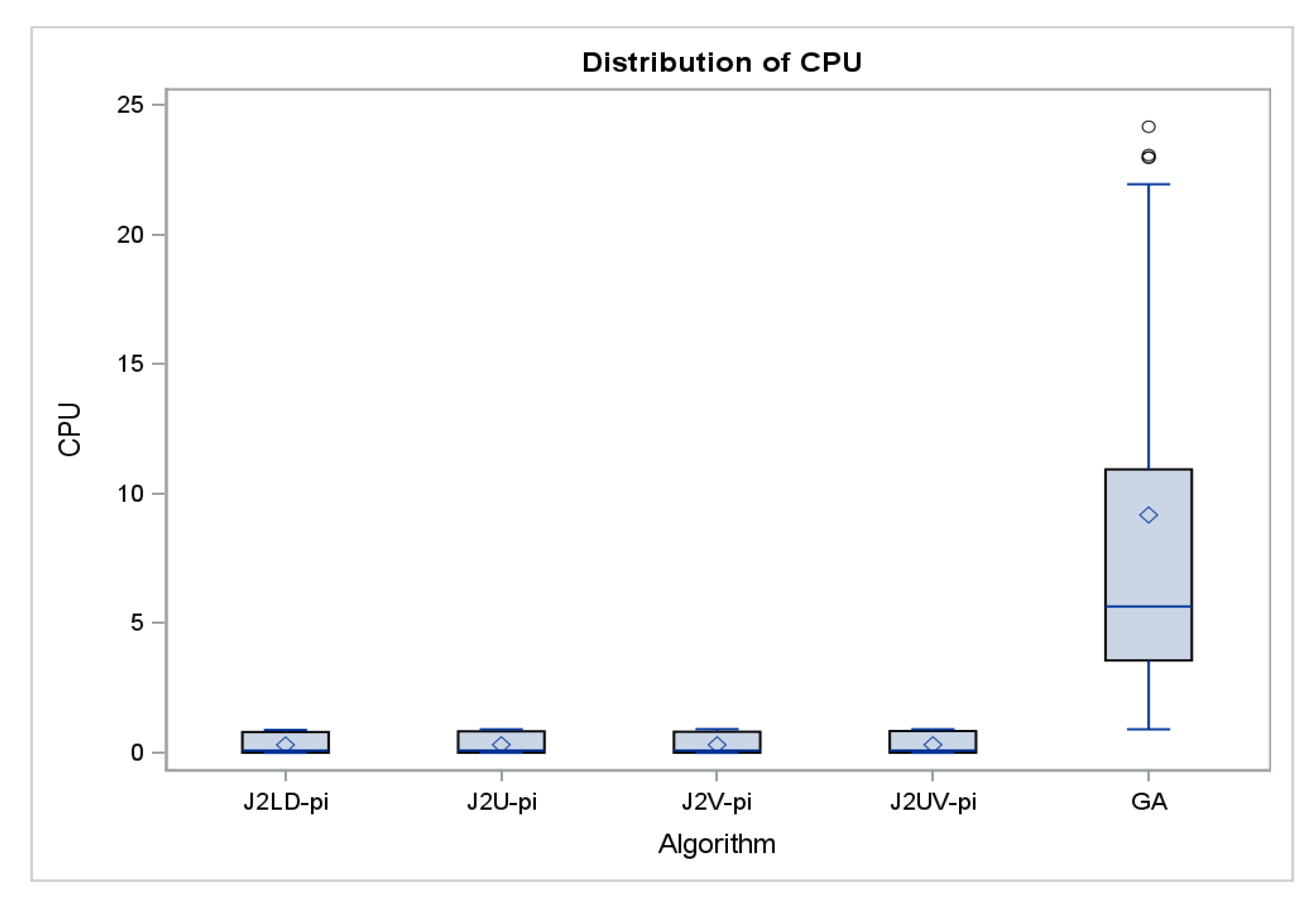
6. Simulation Results for Proposed Algorithms
7. Conclusions and Suggestions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Pinedo, M. Scheduling: Theory, Algorithms, and Systems; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Prentice Hall: Hoboken, NJ, USA, 2010. [Google Scholar]
- Biskup, D. Single-machine scheduling with learning considerations. Eur. J. Oper. Res. 1999, 115, 173–178. [Google Scholar] [CrossRef]
- Cheng TC, E.; Wang, G. Single machine scheduling with learning effect considerations. Ann. Oper. Res. 2000, 98, 273–290. [Google Scholar] [CrossRef]
- Kuo, W.H.; Yang, D.L. Minimizing the total completion time in a single- machine scheduling problem with a time- dependent learning effect. Eur. J. Oper. Res. 2006, 174, 1184–1190. [Google Scholar] [CrossRef]
- Koulamas, C.; Kyparisis, G.J. Single-machine and two-machine flowshop scheduling with general learning functions. Eur. J. Oper. Res. 2007, 178, 402–407. [Google Scholar] [CrossRef]
- Wang, J.B. Single-machine scheduling problems with the effects of learning and deterioration. Omega 2007, 35, 397–402. [Google Scholar] [CrossRef]
- Yin, Y.; Xu, D.; Sun, K.; Li, H. Some scheduling problems with general position-dependent and time-dependent learning effects. Inf. Sci. 2009, 179, 2416–2425. [Google Scholar] [CrossRef]
- Wu, C.-C.; Yin, Y.; Cheng, S.-R. Some single-machine scheduling problems with a truncation learning effect. Comput. Ind. Eng. 2011, 60, 790–795. [Google Scholar] [CrossRef]
- Wu, C.-C.; Yin, Y.; Wu, W.-H.; Cheng, S.-R. Some polynomial solvable single-machine scheduling problems with a truncation sum-of-processing-times based learning effect. Eur. J. Ind. Eng. 2012, 6, 441–453. [Google Scholar] [CrossRef]
- Wu, C.-C.; Yin, Y.; Cheng, S.-R. Single-machine and two-machine flowshop scheduling problems with truncated position-based learning functions. J. Oper. Res. Soc. 2013, 64, 147–156. [Google Scholar] [CrossRef]
- Wang, J.B.; Wang, J.-J. Single machine scheduling with sum-of-logarithm- processing-times based and position based learning effects. Optim. Lett. 2014, 8, 971–982. [Google Scholar] [CrossRef]
- Niu, Y.-P.; Wan, L.; Wang, J.-B. A Note on Scheduling Jobs with Extended Sum-of-Processing-Times-Based and Position-Based Learning Effect. Asia Pac. J. Oper. Res. 2015, 32, 1550001. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, S.C.; Yin, Y.; Wu, C.-C. Single-machine scheduling problems with a learning effect matrix. Iranian Journal of Science and Technology. Trans. A Sci. 2018, 42, 1327–1335. [Google Scholar]
- Biskup, D. A state-of-the-art review on scheduling with learning effect. Eur. J. Oper. Res. 2008, 188, 315–329. [Google Scholar] [CrossRef]
- Janiak, A.; Krysiak, T.; Trela, R. Scheduling problems with learning and ageing effects: A survey. Decis. Mak. Manuf. 2011, 5, 19–36. [Google Scholar] [CrossRef]
- Azzouz, A.; Ennigrou, M.; Ben Said, L. Scheduling problems under learning effects: Classification and cartography. Int. J. Prod. Res. 2018, 56, 1642–1661. [Google Scholar] [CrossRef]
- Wang, J.B.; Xia, Z.Q. Flow-shop scheduling with a learning effect. J. Oper. Res. Soc. 2005, 56, 1325–1330. [Google Scholar] [CrossRef]
- Xu, Z.; Sun, L.; Gong, J. Worst-case analysis for flow shop scheduling with a learning effect. Int. J. Prod. Econ. 2008, 113, 748–753. [Google Scholar] [CrossRef]
- Wu, C.C.; Wu, W.H.; Hsu, P.H.; Lai, K. A two-machine flowshop scheduling problem with a truction sunm of processing-times-based learning function. Appl. Math. Model. 2012, 36, 5001–5014. [Google Scholar] [CrossRef]
- Wang, J.B.; Wang, M.Z. Worst-Case analysis for flow shop scheduling problems with an exponential learning effect. J. Oper. Res. Soc. 2012, 63, 130–137. [Google Scholar] [CrossRef]
- Cheng, T.C.E.; Wu, C.C.; Chen, J.C.; Wu, W.H.; Cheng, S.R. Two-machine flowshop scheduling with a truncated learning function to minimize the makespan. Int. J. Prod. Econ. 2013, 141, 79–86. [Google Scholar] [CrossRef]
- Wang, X.Y.; Zhou, Z.; Zhang, X.; Ji, P.; Wang, J.B. Several flowshop scheduling problems with truncated position-based learning effect. Comput. Oper. Res. 2013, 40, 2906–2929. [Google Scholar] [CrossRef]
- Wang, J.B.; Liu, F.; Wang, J.J. Research on m-machine flow shop scheduling with truncated learning effects. Int. Trans. Oper. Res. 2019, 26, 1135–1151. [Google Scholar] [CrossRef]
- Hsu, C.-L.; Lin, W.-C.; Duan, L.; Liao, J.-R.; Wu, C.-C.; Chen, J.-H. A robust two-machine flow-shop scheduling model with scenario-dependent processing times. Discret. Dyn. Nat. Soc. 2020, 2020, 3530701. [Google Scholar] [CrossRef]
- Ho, M.H.; Hnaien, F.; Dugardin, F. Electricity cost minimisation for optimal makespan solution in flow shop scheduling under time-of-use tariffs. Int. J. Prod. Res. 2021, 59, 1041–1067. [Google Scholar] [CrossRef]
- Lo, T.C.; Lin, B.M.T. Relocation scheduling in a two-machine flow shop with resource recycling operations. Mathematics 2021, 9, 1527. [Google Scholar] [CrossRef]
- Chen, X.; Miao, Q.; Lin, B.M.T.; Sterna, M.; Blazewicz, J. Two-machine flow shop scheduling with a common due date to maximize total early work. Eur. J. Oper. Res. 2022, 300, 504–511. [Google Scholar] [CrossRef]
- Choi, B.C.; Park, M.J. Two machine fowshop scheduling with convex resource consumption functions. Optim. Lett. 2023, 17, 1241–1259. [Google Scholar] [CrossRef]
- Johnson, S.M. Optimal two- and three-stage production schedules with setup times. Nav. Res. Logist. Q. 1954, 1, 61–68. [Google Scholar] [CrossRef]
- Holland, J. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Essafi, I.; Matib, Y.; Dauzere-Peres, S. A genetic local search algorithm for minimizing total weighted tardiness in the job-shop scheduling problem. Comput. Oper. Res. 2008, 35, 2599–2616. [Google Scholar] [CrossRef]
- Nguyen, S.; Mei, Y.; Zhang, M. Genetic programming for production scheduling: A survey with a unified framework. Complex Intell. Syst. 2017, 3, 41–66. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, C.; Liu, Q.; Shen, W.; Gao, L. An improved genetic algorithm for flexible job shop scheduling problem considering reconfigurable machine tools with limited auxiliary modules. J. Manuf. Syst. 2022, 62, 650–667. [Google Scholar] [CrossRef]
- Tutumlu, B.; Saraç, T. A MIP model and a hybrid genetic algorithm for flexible job-shop scheduling problem with job-splitting. Comput. Oper. Res. 2023, 155, 10622. [Google Scholar] [CrossRef]
- Wang, Y.C.; Chen, T. Adapted techniques of explainable artificial intelligence for explaining genetic algorithms on the example of job scheduling. Expert Syst. Appl. 2023, 234 Pt A, 1213769. [Google Scholar] [CrossRef]
- Iyer, S.K.; Saxena, B.S. Improved memetic genetic algorithm for the permutation flowshop scheduling problem. Comput. Oper. Res. 2004, 31, 593–606. [Google Scholar] [CrossRef]
- Wu, C.-C.; Wu, W.-H.; Chen, J.C.; Yin, Y.; Wu, W.-H. A study of the single-machine two-agent scheduling problem with release times. Appl. Soft Comput. 2013, 13, 998–1006. [Google Scholar] [CrossRef]
- Larranaga, P.; Kuijpers, C.M.H.; Murga, R.H.; Inza, I.; Dizdarevic, S. Memetic genetic algorithms for the Travelling Salesman Problem: A Review of Representations and Operators. Artif. Intell. Rev. 1999, 13, 129–170. [Google Scholar] [CrossRef]
- Kellegoz, T.; Toklu, B.; Wilson, J. Comparing efficiencies of genetic crossover operators for one machine total weighted tardiness problem. Appl. Math. Comput. 2008, 199, 590–598. [Google Scholar] [CrossRef]
- Castelli, M.; Cattaneo, G.; Manzoni, L.; Vanneschi, L. A distance between populations for n-points crossover in memetic genetic algorithms. Swarm Evol. Comput. 2019, 44, 636–645. [Google Scholar] [CrossRef]
- Nearchou, A.C. The effect of various operators on the genetic search for large scheduling problems. Int. J. Prod. Econ. 2004, 88, 191–203. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Model | Parameters | Objective Form | Algorithm |
|---|---|---|---|---|
| Hsu et al. [28] | Two-machine flow-shop with scenario-dependent processing times | i = 1,2; , , | A branch-and-bound; a cloud theory-based simulated annealing | |
| Ho et al. [29] | Two-machine flow-shop under time-of-use tariffs | i = 1,2; , | Min or | Three heuristics based on Johnson’s rule and three heuristics based on Hadda’s algorithm |
| Lo and Lin [30] | Two-machine flow-shop with resource recycling operations | i = 1,2; , | Min or | An integer programming model; ant colony optimization |
| Chen et al. [31] | Two-machine flow-shop with a common due date | i = 1,2; , | Maximize total early work | A fully polynomial time approximation scheme |
| Choi and Park [32] | Two-machine flow-shop with convex resource | i=1,2; ; > 0, > 0. | Minimize the sum of the makespan and the total resource consumption cost | Approximation method |
| This paper | Two-machine flow-shop with learning dates | { i = 1,2; , | Min or | A branch-and-bound; heuristics; population-based GA |
| n | BB | J2LD-pi | J2U-pi | J2V-pi | J2UV-pi | GA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | max | mean | sd | mean | sd | mean | sd | mean | sd | mean | sd | |||
| 8 | 0.25 | 0.25 | 10 | 146 | 9.41 | 7.43 | 8.65 | 7.21 | 6.41 | 6.55 | 5.56 | 4.76 | 0.01 | 0.08 |
| 0.50 | 1298 | 7649 | 7.21 | 6.11 | 6.63 | 5.48 | 5.40 | 5.36 | 5.22 | 4.70 | 0.03 | 0.18 | ||
| 0.75 | 5075 | 19594 | 4.37 | 4.66 | 4.27 | 4.84 | 3.54 | 4.16 | 3.27 | 4.28 | 0.00 | 0.03 | ||
| 0.50 | 0.25 | 206 | 3171 | 6.82 | 5.33 | 7.08 | 5.86 | 6.71 | 5.72 | 5.86 | 5.02 | 0.07 | 0.37 | |
| 0.50 | 89.63 | 1025 | 7.56 | 5.30 | 7.45 | 5.02 | 5.85 | 4.40 | 5.33 | 4.06 | 0.04 | 0.19 | ||
| 0.75 | 3727 | 19,875 | 4.71 | 5.25 | 4.78 | 4.87 | 3.53 | 3.66 | 3.63 | 3.52 | 0.03 | 0.23 | ||
| 0.75 | 0.25 | 1466 | 11,481 | 5.30 | 4.76 | 5.59 | 4.82 | 4.77 | 5.1 | 4.39 | 4.85 | 0.04 | 0.30 | |
| 0.50 | 1090 | 8064 | 6.69 | 5.12 | 6.17 | 4.56 | 5.82 | 4.34 | 5.07 | 4.26 | 0.06 | 0.26 | ||
| 0.75 | 2610 | 12,331 | 4.70 | 4.51 | 4.93 | 4.24 | 4.50 | 4.04 | 4.08 | 3.97 | 0.05 | 0.28 | ||
| 10 | 0.25 | 0.25 | 48 | 3428.00 | 6.27 | 5.83 | 7.13 | 5.61 | 7.09 | 5.92 | 5.53 | 5.12 | 0.21 | 0.75 |
| 0.50 | 2499 | 41,120.00 | 9.77 | 5.84 | 10.12 | 6.37 | 6.6 | 4.44 | 5.82 | 4.55 | 0.17 | 0.41 | ||
| 0.75 | 49,700 | 424,496 | 7.93 | 5.37 | 8.54 | 5.78 | 5.65 | 4.69 | 5.38 | 4.47 | 0.13 | 0.48 | ||
| 0.50 | 0.25 | 4752 | 91,532 | 8.07 | 5.58 | 7.60 | 4.70 | 8.02 | 5.41 | 6.57 | 4.24 | 0.28 | 0.77 | |
| 0.50 | 2580 | 44,931 | 8.90 | 5.09 | 9.00 | 4.83 | 7.65 | 4.48 | 6.87 | 4.41 | 0.54 | 1.04 | ||
| 0.75 | 44,392 | 486,987 | 7.06 | 4.52 | 7.56 | 4.78 | 5.68 | 4.57 | 4.90 | 3.79 | 0.22 | 0.69 | ||
| 0.75 | 0.25 | 76,650 | 533,020 | 4.97 | 4.25 | 5.37 | 4.79 | 5.42 | 4.57 | 4.82 | 4.49 | 0.18 | 0.53 | |
| 0.50 | 38,918 | 387,621 | 6.56 | 4.75 | 5.75 | 4.62 | 5.67 | 4.40 | 5.59 | 4.41 | 0.23 | 0.64 | ||
| 0.75 | 31,791 | 176,396 | 6.81 | 4.92 | 6.18 | 4.35 | 5.58 | 3.83 | 5.56 | 4.11 | 0.23 | 0.62 | ||
| 12 | 0.25 | 0.25 | 129 | 11,366 | 6.76 | 4.89 | 6.98 | 5.07 | 7.13 | 5.50 | 6.19 | 4.99 | 0.21 | 0.55 |
| 0.50 | 170,353 | 7,713,811 | 10.74 | 5.71 | 11.27 | 5.59 | 8.31 | 5.17 | 7.43 | 5.09 | 0.52 | 0.99 | ||
| 0.75 | 5,014,307 | 77699120 | 7.87 | 5.48 | 7.45 | 4.91 | 5.96 | 4.58 | 5.89 | 3.95 | 0.19 | 0.57 | ||
| 0.50 | 0.25 | 122,303 | 1,916,426 | 8.62 | 5.06 | 8.05 | 4.73 | 8.89 | 5.10 | 7.73 | 4.39 | 0.61 | 1.15 | |
| 0.50 | 48,587 | 2,792,148 | 10.09 | 5.73 | 9.17 | 4.60 | 8.49 | 4.08 | 7.97 | 4.01 | 0.81 | 0.96 | ||
| 0.75 | 1,363,555 | 16,993,648 | 8.54 | 4.61 | 7.70 | 5.01 | 6.49 | 4.52 | 6.34 | 4.17 | 0.39 | 0.74 | ||
| 0.75 | 0.25 | 3,589,247 | 32,696,624 | 5.70 | 4.88 | 5.52 | 4.04 | 6.45 | 5.58 | 5.59 | 4.73 | 0.37 | 0.84 | |
| 0.50 | 1,590,399 | 19,702,024 | 6.88 | 4.95 | 6.90 | 5.06 | 6.08 | 4.44 | 5.26 | 4.14 | 0.53 | 0.93 | ||
| 0.75 | 1,941,574 | 43,576,680 | 6.97 | 4.21 | 6.68 | 4.74 | 6.62 | 3.50 | 6.31 | 4.44 | 0.49 | 0.99 | ||
| mean | 522494 | 7.23 | 7.13 | 6.23 | 5.63 | 0.25 | ||||||||
| n | J2LD_pi | J2U-pi | J2V-pi | J2UV-pi | GA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | sd | mean | sd | mean | sd | mean | sd | mean | sd | |||
| 100 | 0.25 | 0.25 | 5.91 | 3.18 | 5.94 | 2.71 | 6.86 | 2.64 | 6.16 | 2.5 | 0.03 | 0.21 |
| 0.5 | 13.26 | 3.44 | 11.5 | 3.67 | 10.54 | 3.34 | 8.87 | 2.76 | 0.00 | 0.00 | ||
| 0.75 | 10.96 | 4.74 | 9.82 | 4.35 | 9.24 | 4.06 | 7.56 | 3.66 | 0.00 | 0.00 | ||
| 0.50 | 0.25 | 11.04 | 3.44 | 10.1 | 2.97 | 12.72 | 3.10 | 11.72 | 3.83 | 0.00 | 0.00 | |
| 0.5 | 9.05 | 3.65 | 7.74 | 2.68 | 8.32 | 3.03 | 7.71 | 2.39 | 0.00 | 0.00 | ||
| 0.75 | 12.00 | 4.14 | 9.68 | 4.05 | 8.25 | 3.97 | 7.58 | 3.37 | 0.00 | 0.00 | ||
| 0.75 | 0.25 | 9.71 | 4.25 | 8.25 | 3.59 | 12.09 | 4.76 | 9.69 | 3.86 | 0.00 | 0.00 | |
| 0.5 | 9.76 | 4.97 | 7.31 | 3.25 | 10.6 | 4.22 | 9.33 | 4.81 | 0.00 | 0.00 | ||
| 0.75 | 7.42 | 3.18 | 5.97 | 3.13 | 4.81 | 2.83 | 5.19 | 2.97 | 0.00 | 0.00 | ||
| 200 | 0.25 | 0.25 | 2.58 | 1.89 | 2.29 | 1.84 | 3.33 | 2.00 | 2.99 | 1.88 | 0.41 | 0.77 |
| 0.5 | 10.96 | 2.95 | 10.00 | 2.85 | 8.64 | 3.000 | 6.61 | 2.66 | 0.00 | 0.00 | ||
| 0.75 | 10.33 | 3.80 | 10.81 | 3.86 | 9.59 | 3.22 | 8.16 | 2.69 | 0.00 | 0.00 | ||
| 0.50 | 0.25 | 9.88 | 2.81 | 8.57 | 2.48 | 11.51 | 2.56 | 10.24 | 2.65 | 0.00 | 0.00 | |
| 0.5 | 6.33 | 3.24 | 4.15 | 2.01 | 5.37 | 2.26 | 4.49 | 1.95 | 0.03 | 0.15 | ||
| 0.75 | 11.91 | 4.12 | 10.1 | 4.48 | 8.53 | 3.12 | 7.8 | 2.63 | 0.01 | 0.05 | ||
| 0.75 | 0.25 | 11.39 | 5.49 | 7.21 | 3.04 | 12.13 | 4.19 | 9.99 | 3.97 | 0.00 | 0.00 | |
| 0.5 | 11.02 | 4.88 | 7.76 | 3.36 | 11.98 | 4.72 | 9.08 | 3.64 | 0.00 | 0.00 | ||
| 0.75 | 9.08 | 4.53 | 5.87 | 3.34 | 8.30 | 3.05 | 6.20 | 2.62 | 0.01 | 0.13 | ||
| 400 | 0.25 | 0.25 | 1.15 | 1.38 | 1.03 | 1.09 | 1.67 | 1.6 | 1.71 | 1.52 | 2.48 | 1.14 |
| 0.50 | 6.91 | 1.96 | 6.18 | 1.86 | 5.19 | 1.87 | 2.83 | 1.51 | 0.01 | 0.06 | ||
| 0.75 | 10.09 | 3.53 | 10.08 | 3.82 | 7.73 | 2.57 | 6.02 | 2.56 | 0.00 | 0.00 | ||
| 0.50 | 0.25 | 3.92 | 1.94 | 3.21 | 1.67 | 6.20 | 1.82 | 4.67 | 1.55 | 0.06 | 0.32 | |
| 0.50 | 3.63 | 2.21 | 1.44 | 1.21 | 3.92 | 1.63 | 2.35 | 1.38 | 0.29 | 0.59 | ||
| 0.75 | 10.52 | 3.91 | 9.52 | 3.16 | 6.98 | 2.56 | 5.54 | 2.28 | 0.02 | 0.19 | ||
| 0.75 | 0.25 | 8.36 | 3.52 | 6.91 | 3.08 | 12.49 | 3.41 | 9.31 | 3.08 | 0.00 | 0.03 | |
| 0.50 | 9.66 | 4.36 | 6.47 | 2.97 | 11.87 | 3.85 | 8.92 | 3.81 | 0.01 | 0.07 | ||
| 0.75 | 6.71 | 5.30 | 3.49 | 2.95 | 6.16 | 3.34 | 4.09 | 2.59 | 0.37 | 0.74 | ||
| mean | 8.65 | 7.01 | 8.34 | 6.84 | 0.14 | |||||||
| Node | CPU-Time | ||
|---|---|---|---|
| n | w1 | mean | mean |
| 8 | 0.25 | 6385 | 0.0242 |
| 0.50 | 4023 | 0.0117 | |
| 0.75 | 5167 | 0.0124 | |
| w2 | |||
| 0.25 | 1684 | 0.0060 | |
| 0.50 | 2478 | 0.0061 | |
| 0.75 | 11,413 | 0.0362 | |
| w1 | |||
| 10 | 0.25 | 52,248 | 0.1625 |
| 0.50 | 51,725 | 0.1832 | |
| 0.75 | 147,360 | 0.5204 | |
| w2 | |||
| 0.25 | 81,451 | 0.2823 | |
| 0.50 | 43,997 | 0.1530 | |
| 0.75 | 125,884 | 0.4308 | |
| w1 | |||
| 12 | 0.25 | 5,184,789 | 25.1863 |
| 0.50 | 1,534,446 | 7.4038 | |
| 0.75 | 7,121,221 | 34.8778 | |
| w2 | |||
| 0.25 | 3,711,680 | 17.6078 | |
| 0.5 | 1,809,341 | 8.8510 | |
| 0.75 | 8,319,437 | 41.0091 |
| J2LD-pi | J2U-pi | J2V-pi | J2UV-pi | GA | ||
|---|---|---|---|---|---|---|
| n | w1 | mean | mean | mean | mean | mean |
| 8 | 0.25 | 7.00 | 6.52 | 5.12 | 4.68 | 0.01 |
| 0.50 | 6.36 | 6.44 | 5.36 | 4.94 | 0.05 | |
| 0.75 | 5.56 | 5.56 | 5.03 | 4.51 | 0.05 | |
| w2 | ||||||
| 0.25 | 7.18 | 7.11 | 5.96 | 5.27 | 0.04 | |
| 0.50 | 7.15 | 6.75 | 5.69 | 5.21 | 0.04 | |
| 0.75 | 4.59 | 4.66 | 3.86 | 3.66 | 0.03 | |
| w1 | ||||||
| 10 | 0.25 | 7.99 | 8.60 | 6.45 | 5.58 | 0.17 |
| 0.50 | 8.01 | 8.05 | 7.12 | 6.11 | 0.35 | |
| 0.75 | 6.11 | 5.77 | 5.56 | 5.32 | 0.21 | |
| w2 | ||||||
| 0.25 | 6.44 | 6.70 | 6.84 | 5.64 | 0.22 | |
| 0.50 | 8.41 | 8.29 | 6.64 | 6.09 | 0.31 | |
| 0.75 | 7.27 | 7.43 | 5.64 | 5.28 | 0.19 | |
| w1 | ||||||
| 12 | 0.25 | 8.46 | 8.57 | 7.13 | 6.50 | 0.31 |
| 0.50 | 9.08 | 8.31 | 7.96 | 7.35 | 0.60 | |
| 0.75 | 6.52 | 6.37 | 6.38 | 5.72 | 0.50 | |
| w2 | ||||||
| 0.25 | 7.03 | 6.85 | 7.49 | 6.50 | 0.44 | |
| 0.5 | 9.24 | 9.11 | 7.63 | 6.89 | 0.62 | |
| 0.75 | 7.79 | 7.28 | 6.36 | 6.18 | 0.36 | |
| n | ||||||
| 8 | 6.31 | 6.17 | 5.17 | 4.71 | 0.04 | |
| 10 | 7.37 | 7.47 | 6.37 | 5.67 | 0.24 | |
| 12 | 8.02 | 7.75 | 7.16 | 6.52 | 0.47 | |
| mean | 7.23 | 7.13 | 6.23 | 5.64 | 0.25 |
| J2LD-pi | J2U-pi | J2V-pi | J2UV-pi | GA | ||
|---|---|---|---|---|---|---|
| n | w1 | mean | mean | mean | mean | mean |
| 100 | 0.25 | 10.04 | 9.09 | 8.88 | 7.53 | 0.01 |
| 0.50 | 10.7 | 9.17 | 9.76 | 9.00 | 0.00 | |
| 0.75 | 8.96 | 7.18 | 9.17 | 8.07 | 0.00 | |
| w2 | ||||||
| 0.25 | 8.89 | 8.1 | 10.56 | 9.19 | 0.01 | |
| 0.50 | 10.69 | 8.85 | 9.82 | 8.64 | 0.00 | |
| 0.75 | 10.13 | 8.49 | 7.43 | 6.78 | 0.00 | |
| w1 | ||||||
| 200 | 0.25 | 7.96 | 7.7 | 7.19 | 5.92 | 0.14 |
| 0.50 | 9.37 | 7.61 | 8.47 | 7.51 | 0.01 | |
| 0.75 | 10.5 | 6.95 | 10.8 | 8.42 | 0.00 | |
| w2 | ||||||
| 0.25 | 7.95 | 6.02 | 8.99 | 7.74 | 0.14 | |
| 0.50 | 9.44 | 7.3 | 8.66 | 6.73 | 0.01 | |
| 0.75 | 10.44 | 8.93 | 8.81 | 7.39 | 0.01 | |
| w1 | ||||||
| 400 | 0.25 | 0.25 | 6.05 | 5.76 | 4.86 | 3.52 |
| 0.50 | 0.50 | 6.02 | 4.72 | 5.7 | 4.19 | |
| 0.75 | 0.75 | 8.24 | 5.62 | 10.17 | 7.44 | |
| w2 | ||||||
| 0.25 | 0.25 | 4.48 | 3.72 | 6.79 | 5.23 | |
| 0.5 | 0.5 | 6.73 | 4.70 | 6.99 | 4.70 | |
| 0.75 | 0.75 | 9.11 | 7.70 | 6.96 | 5.22 | |
| n | ||||||
| 100 | 9.90 | 8.48 | 9.27 | 8.20 | 0.00 | |
| 200 | 9.28 | 7.42 | 8.82 | 7.28 | 0.05 | |
| 400 | 6.77 | 5.37 | 6.91 | 5.05 | 0.36 | |
| mean | 8.65 | 7.09 | 8.33 | 6.84 | 0.14 |
| Heuristic/Algorithm | No. of Obs./Small n | Rank-Sum (Ri, i = 1, 2,…, 5) | No. of Obs./Large n | Rank-Sum (Ri, i = 1, 2, …, 5) |
|---|---|---|---|---|
| J2LD-pi | 27 | 118 | 27 | 112 |
| J2U-pi | 27 | 117 | 27 | 76 |
| J2V-pi | 27 | 88 | 27 | 108 |
| J2UV-pi | 27 | 55 | 27 | 78 |
| GA | 27 | 27 | 27 | 31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.-Y.; Lin, W.-C.; Chang, Y.-W.; Chung, Y.-H.; Chen, J.-H.; Wu, C.-C. A Two-Machine Learning Date Flow-Shop Scheduling Problem with Heuristics and Population-Based GA to Minimize the Makespan. Mathematics 2023, 11, 4060. https://doi.org/10.3390/math11194060
Xu J-Y, Lin W-C, Chang Y-W, Chung Y-H, Chen J-H, Wu C-C. A Two-Machine Learning Date Flow-Shop Scheduling Problem with Heuristics and Population-Based GA to Minimize the Makespan. Mathematics. 2023; 11(19):4060. https://doi.org/10.3390/math11194060
Chicago/Turabian StyleXu, Jian-You, Win-Chin Lin, Yu-Wei Chang, Yu-Hsiang Chung, Juin-Han Chen, and Chin-Chia Wu. 2023. "A Two-Machine Learning Date Flow-Shop Scheduling Problem with Heuristics and Population-Based GA to Minimize the Makespan" Mathematics 11, no. 19: 4060. https://doi.org/10.3390/math11194060