1. Introduction and Statistical Framework
The problem of detecting change points in real data series has attracted attention due to the heterogeneities of real data series. The aim of change point detection and estimation is to partition data sequences into multiple homogeneous segments, and the theories have been applied in a variety of fields such as finance [
1], medicine [
2], the environment [
3], and so on. Traditionally, change point problems are generally described as typical hypothesis testing problems. What most scholars are interested in is testing the null hypothesis that all observations are samples from distributions with equal means, then, deriving the distributions of the statistics (see [
4,
5,
6,
7,
8]). A similar reasoning holds for other change point problems, such as variance change points [
9].
In the past 40 years, new models have continuously been established for more precise descriptions of financial data. Many empirical studies have shown that the phenomenon of heavy tails frequently exists in economic and financial sequences, but most previous studies have been based on finite variance (see Guillaume et al. [
10] and Mittnik and Rachev [
11]), and there have been few simulations using infinite variance processes. In the case of infinite variance, there will be more factors to consider and the problem will be more complex. Qin et al. [
12] proposed a modified ratio test statistic that can effectively detect changes in the second half of the observed values, and established the asymptotic properties under the null and alternative hypotheses. Then, Jin et al. [
13] also proposed a modified ratio statistic to test the possible trend term changes in the sequences and, based on the subsampling method, more accurate critical values were obtained.
In the change point problems of heavy-tailed sequences, due to the influence of extreme values in heavy-tailed sequences, it is generally not possible to directly locate the critical value of the test statistic. Therefore, this paper proposes using multiple resampling methods to approximate the distribution of the original statistic and obtain accurate critical values and power, then comparing and analyzing the performance of these sampling methods.
As for the error terms in some models, many scholars default to the error terms being independently and identically distributed. As Aue and Horváth [
14] commented in a review paper, many methods were initially developed for independent observation. But the concept of simple independent observation models is very narrow, and most real sequences do not satisfy such models. Therefore, we would like to consider more general weakly dependent cases, such as the autoregressive model. The latest research and applications can be found in [
15,
16,
17], and this classic model will not be introduced too much here.
So, this paper discusses the problem of mean changes in time series with heavy-tailed AR(
p) errors. More specifically, observations
, which conform to the following structure:
where
is a constant,
are coefficients, and
is a heavy-tailed sequence.
Remark 1. A heavy-tailed distribution is a special type of distribution in statistics, where the probability of the tail (i.e., extreme case) is greater than that of a normal distribution. This means that in actual observational data, the distribution is more likely to exhibit extreme and far off average values than a normal distribution.
There are two main characteristics of heavy-tailed sequences: firstly, the probability decay rate of the tail is slow; and secondly, the variance of the tail may be infinite. Common heavy-tailed distributions include the Pareto distribution, the Cauchy distribution, the t-distribution, etc. These characteristics will be implied in the assumptions in the next section.
The rest of the paper is arranged as follows: The main ideas for constructing the test statistic are detailed in
Section 2. The main results are presented in
Section 3. A small simulation study under different parameters is provided in
Section 4. A real example is provided in
Section 5.
Section 6 contains the conclusions and outlooks.
2. Main Ideas
Assumption 1. All the characteristic roots of lie outside the unit circle.
Assumption 2. lies in the domain of attraction of a stable law with a heavy-tailed index , and .
Remark 2. Assumptions 1 and 2 guarantee that the heavy-tailed AR(p) sequence is smooth and has infinite variance; they are necessary underlying assumptions.
In addition, Assumption 2 implieswhere andIt is not difficult to find that, by combining Equations (3) and (4), there is a constant such thatwhere is a stable random variable. In addition, it can be verified that in the special cases of and , is a Gaussian and Cauchy distribution, respectively. Here, if we assume that , it implies that in Assumption 2. As a special case, if is an independent and identically distributed sequence, Kokoszka [18] obtained the following:where and are κ-stable and -stable Lévy processes in the space with the Skorohod topology, respectively. It is worth noting that can be rewritten as ; is a slowly changing function. Since the characteristic roots are outside the unit circle, then B–N (Beveridge–Nelson) decomposition can be used to rewrite the partial sum of aswhere , . Remark 3. is a stationary process that can be expressed as:where is a standard Brownian motion. is a uniformly distributed random variable independently and identically distributed on the interval , is an independently and identically distributed random variable sequence with ; . , , ⋯ are the arrival times of the Poisson process with the Lebesgue measure, and are independent of each other. Observation
can be rewritten as
where
is defined by (
1),
is the mean,
is the time point of abrupt change, and
is characteristic function. The null hypothesis for testing the change is
against the alternative hypothesis
Shao [
19] proposed a ratio test to detect the mean change point.
where
.
When dealing with the mean change point problem for heavy-tailed sequences, it is common to choose to intercept some part of the sequence for processing. Often, it is desirable to retain a large portion of the data while effectively minimizing the effect of extreme values. So, the truncated parameters are set to .
The statistic is not actually directly substitutable into the change point model presented in this paper. The reason is the limiting distribution of
is not available under the case of
. To solve this resistance, we suggest using
instead of
and re-establishing the test statistics. Because of the heavy-tail feature of
, the new test statistics are based on the residual error
. The improved ratio tests are as follows:
where
. The process of obtaining
is not difficult. First, use the regression of
on the intercept to calculate the ordinary least squares residual
. Then, repeating the same method, calculate the residual
from the regression of
on
, where
,
. Similarly,
and
can be obtained in
and
, respectively.
4. Simulations
In this section, we conduct some simulations to verify the effectiveness of our ratio test. Due to the representativeness of first-order autoregressive models, we consider a first-order autoregressive model:
where
. Without losing generality, set the significance level
,
. The results are as follows:
Comparing
Figure 1,
Figure 2,
Figure 3 and
Figure 4, it is not difficult to find that
has a relatively stable empirical size and a high empirical power, but when the change point appears in the latter half of the observation sequence the empirical power is not satisfactory.
It is not difficult to find that the heavy-tailed index
is in the limit distribution. Although some scholars have proposed a series of methods to estimate
(see [
21,
22]), their effectiveness is not satisfactory. Therefore, in order to avoid estimating
, we recommend using bootstrap sampling to approximate the limit distribution of the statistic under the null hypothesis, so as to obtain an accurate critical value. The specific steps are as follows:
Step 1. Use the regression of on the intercept to calculate the ordinary least squares (OLS) residual , and then calculate the OLS residual from the regression of on .
Step 2. Compute the centered residuals
and
Step 3. For a fixed number , we extract bootstrap samples from , ⋯, , from , ⋯, , and from , , ⋯, .
Step 4. Constructing the bootstrap statistic:
where
,
, and
.
Step 5. Repeat steps 3 and 4 1000 times, then we obtain a set of statistics .
Step 6. Calculate the -quantile of . If , then reject the null hypothesis.
Remark 4. Choosing a suitable m is very difficult, but Mcmurry et al. [23] provided an ideal choice for controlling the empirical power: . Therefore, it is necessary to use this numerical value for the simulation experiments. As we guessed,
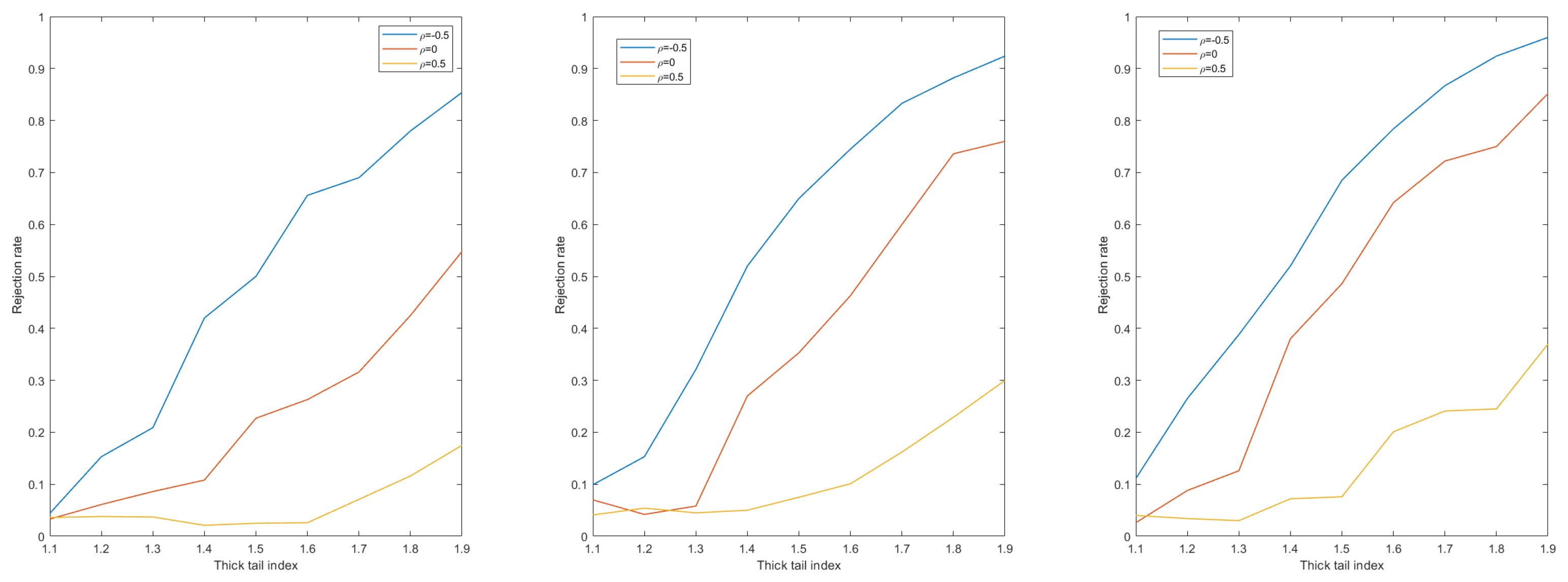
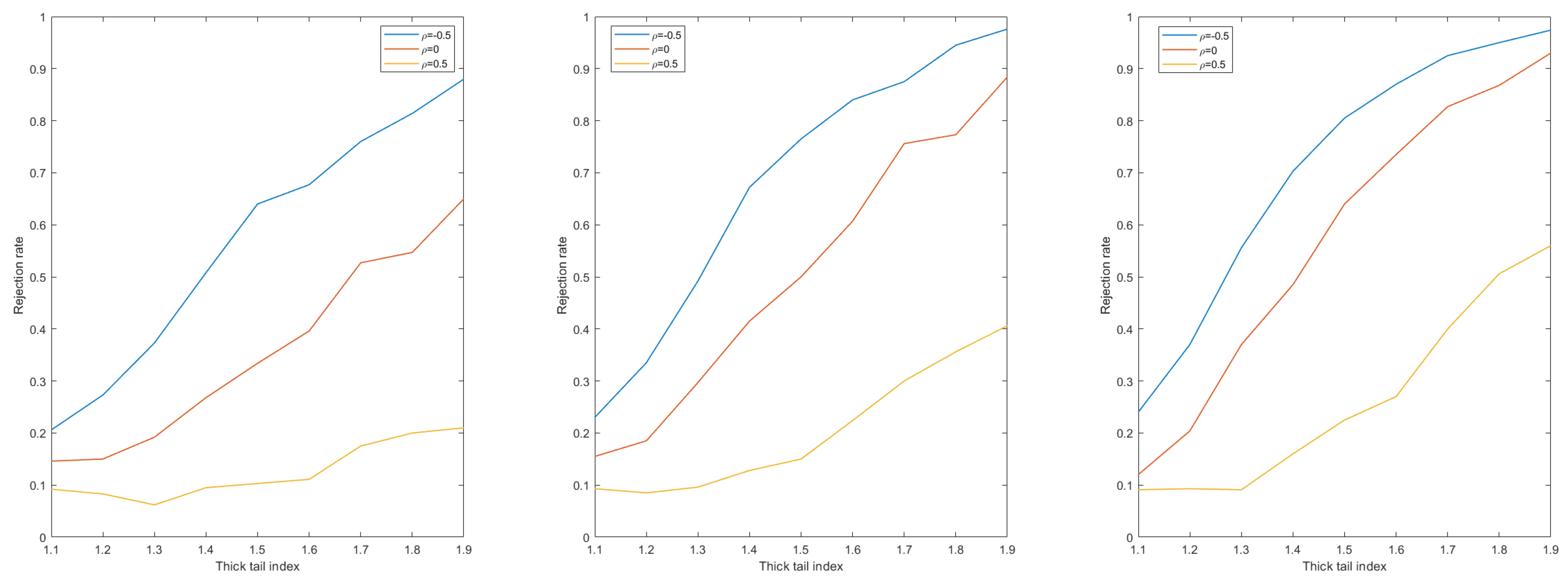
Figure 5 shows a satisfactory result, especially for the case of
, where the increase in empirical power is significant, and this indicates that the position of the change point has a small impact on the newly constructed statistic.
To expand the comparison, the jackknife method is used, the steps of which are as follows.
Step 1. Use the regression of on the intercept to calculate the ordinary least squares (OLS) residual , and then calculate the OLS residual from the regression of on .
Step 2. Compute the centered residuals
and
Step 3. We extract jackknife samples from , ⋯, , from , ⋯, , and from , , ⋯, .
Step 4. Constructing the jackknife statistic:
where
,
, and
.
Step 5. Repeat steps 3 and 4 1000 times, then we obtain a set of statistics .
Step 6. Calculate the -quantile of . If , then reject the null hypothesis.
Similarly, the power of the jackknife statistic can be obtained as shown in
Figure 6.
As a classical sampling method, the limiting distribution of a statistic under the null hypothesis can also be approximated using the subsampling method to obtain more accurate critical values and power, as follows:
Step 1. Use the regression of on the intercept to calculate the ordinary least squares (OLS) residual , and then calculate the OLS residual from the regression of on .
Step 2. Compute the centered residuals .
Step 3. For a fixed number , we extract processes with length b, and satisfy the null hypothesis. For , the l-th process is determined by .
Step 4. We extract
based on
:
where
.
Step 5. is the -quantile of the empirical distributions of the value . When , we reject the null hypothesis.
Combining
Figure 5,
Figure 6 and
Figure 7, it can be seen that there is a large increase in the power by reconstructing the bootstrap statistic, the jackknife statistic, and the subsampling statistic from the original. Combining the comparisons it is easy to see that the bootstrap method has the most significant effect on the increase in power and the jackknife method has the least effect. The reason for this may be because bootstrap sampling is a nonparametric statistical method, the basic idea of which is to obtain more reliable estimates of the statistical properties of the original sample by drawing a large number of subsamples from the original sample and then making statistical inferences on these subsamples. Since the original series may contain extreme values, these extreme values may have an impact on the statistical inference. The bootstrap sampling method is effective in reducing the impact of extreme values, which may occur less frequently when subsamples are drawn.
Since jackknife sampling excludes only one observation per iteration, it may not be effective in reducing the impact of extreme values or “heavy tails” for data with these points. In contrast, bootstrap sampling can better simulate the distribution of the original data by generating a number of random subsets of the original data size (via put-back sampling), especially for non-normally distributed data. The bootstrap method can be applied to any form of statistic, giving it greater flexibility in dealing with more complex statistical problems.
5. Application
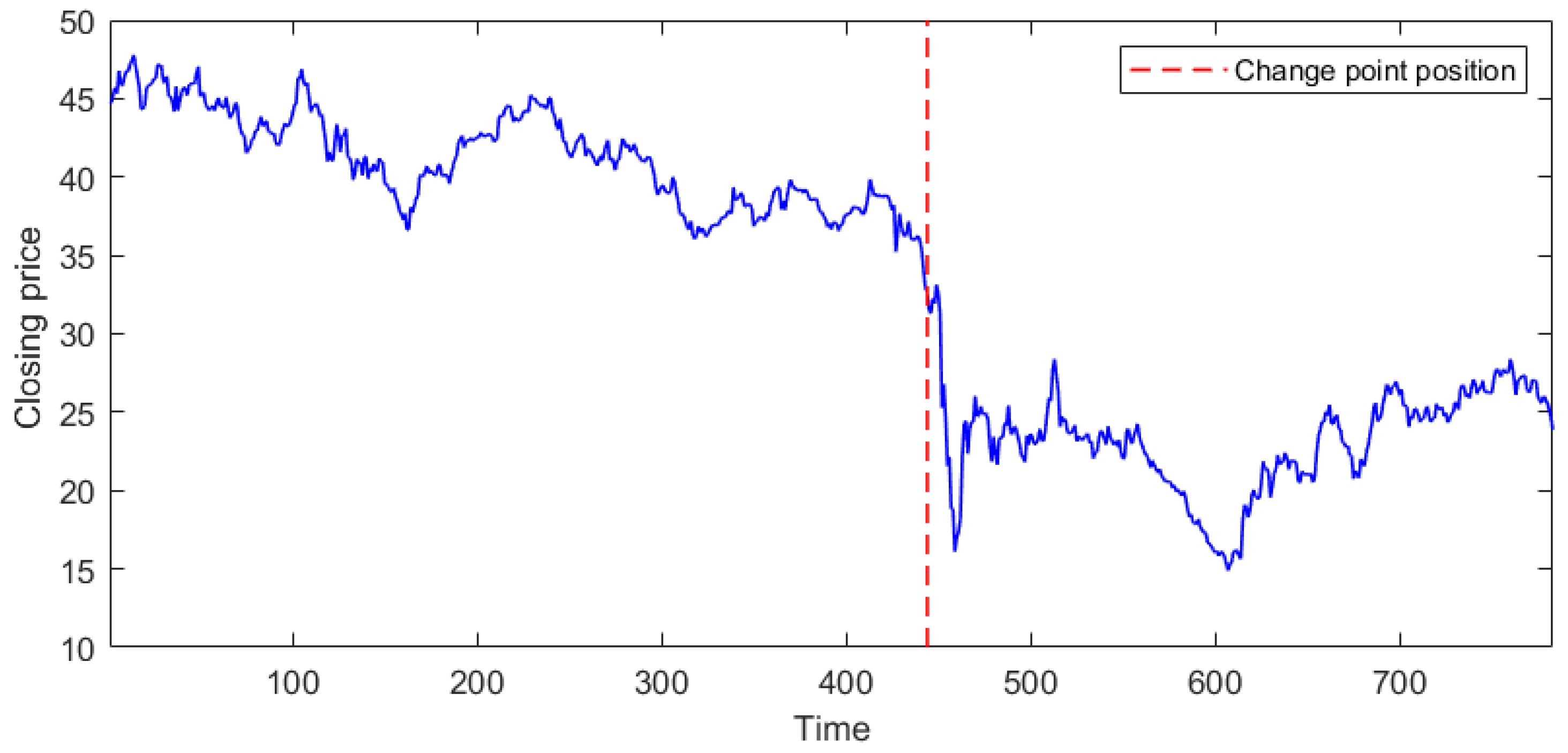
We consider the closing price data of British Petroleum (BP) between February 2019 and July 2021 (783 observations). Upon observation, it is easy to see that there seems to be a point of mean change in this sequence of observations, but it is unscientific to rely on visual perception alone. Therefore, the test statistic needs to be utilized to verify that it has a change point.
According to the description in the previous section, the bootstrap method has the best performance, so we consider using the bootstrap method for this problem.
Based on John [
24], Jin, et al. [
13] believe that the data can be fitted as a heavy-tailed sequence with a tailed index
. Under the premise that the process has infinite variance, we use the ARMA model to fit a causal AR model, and using the Bayesian information criterion, the sample partial autocorrelation function of the AR(1) model is almost zero after a first-order lag, and its autoregressive coefficient is 0.5788. Jin, et al. [
25] proposed a mean change point estimator based on a heavy-tailed sequence and proved the consistency of the estimator. Based on this, we obtain the change position
(see
Figure 8). Then, the entire sequence is divided into two parts (1,444) and (445,783), with mean values
and
, respectively. A mean-corrected sequence is based on
, where
,
,
,
. It is not difficult to find that the heavy-tailed character of the original data has not changed in the corrected sequence.
For the statistic
, we obtain a critical value of 5.9551 (see
Table 1), and the critical value 3.0627 based on bootstrap testing. By replacing with the original data,
can be obtained. As we guessed,
is greater than the critical value obtained based on the bootstrap method, we reject the null hypothesis and believe that there is a change point. But
, that is, in the case of the original statistic, we cannot consider the sequence to have a change point, so this also reflects the superiority of the bootstrap method. Therefore, this is sufficient to demonstrate the good performance of our proposed method.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}