
Leveraging Minimum Nodes for Optimum Key Player Identification in Complex Networks: A Deep Reinforcement Learning Strategy with Structured Reward Shaping

Abstract
:1. Introduction
2. Preliminaries
2.1. Accumulated Normalize Connectivity (ANC)
2.2. Solution Length Ratio (SLR)
2.3. Pareto Frontier
- (1)
- For all objectives , , the score of on is less than or equal to the score of on ;
- (2)
- There exists at least one objective , , such that the score of on is strictly less than the score of on .
3. Model of MiniKey
3.1. Encoding Process of MiniKey
| Algorithm 1: Encoding process of MiniKey |
| Input: Graph , node features , depth , learnable weight parameters Output: Node embedding , 1. Add a virtual node , which connects all nodes in 2. Initialize , 3. FOR to 4. FOR 5. 6. 7. END FOR 8. 9. END FOR 10. |
3.2. Decoding Process of MiniKey
3.3. Training Algorithm of MiniKey
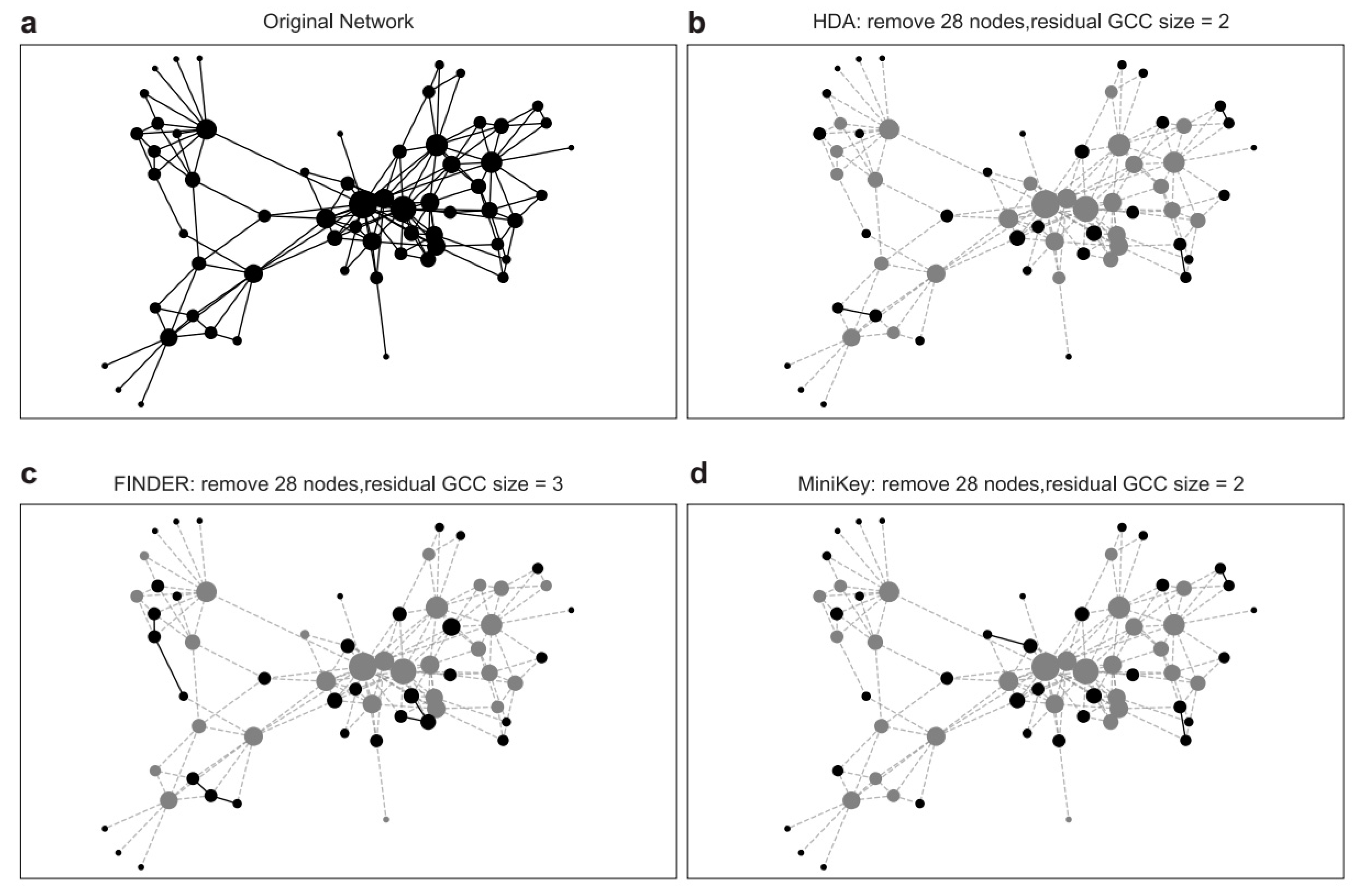
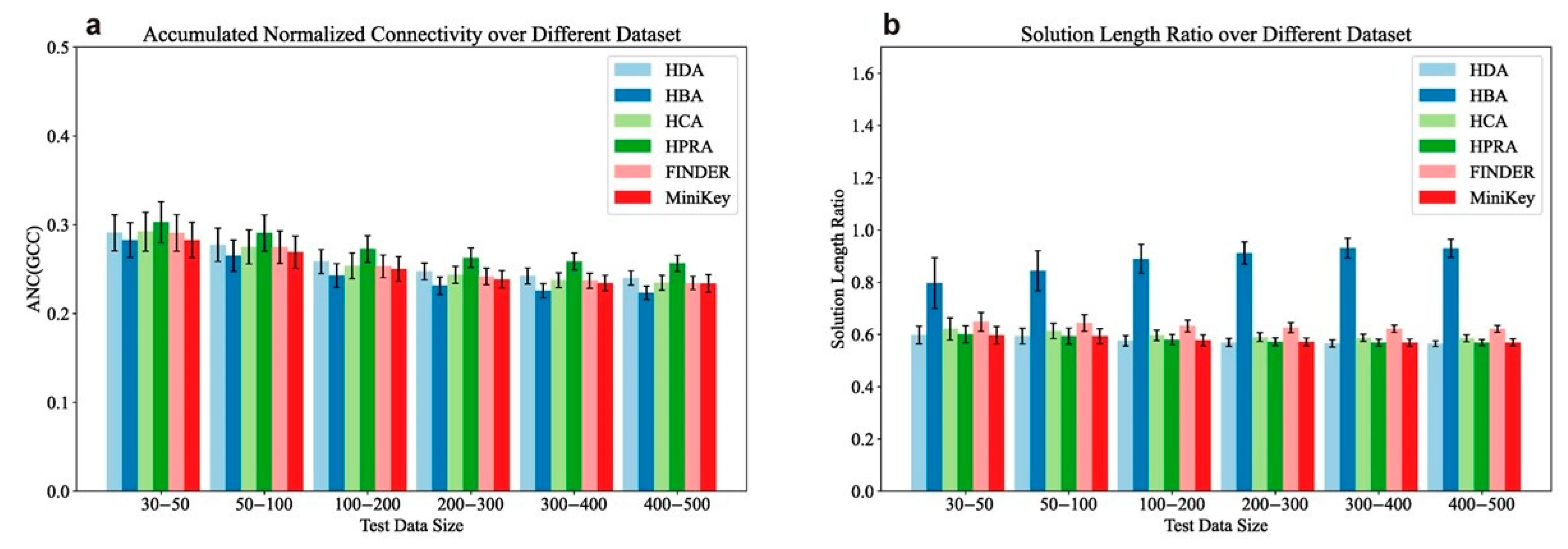
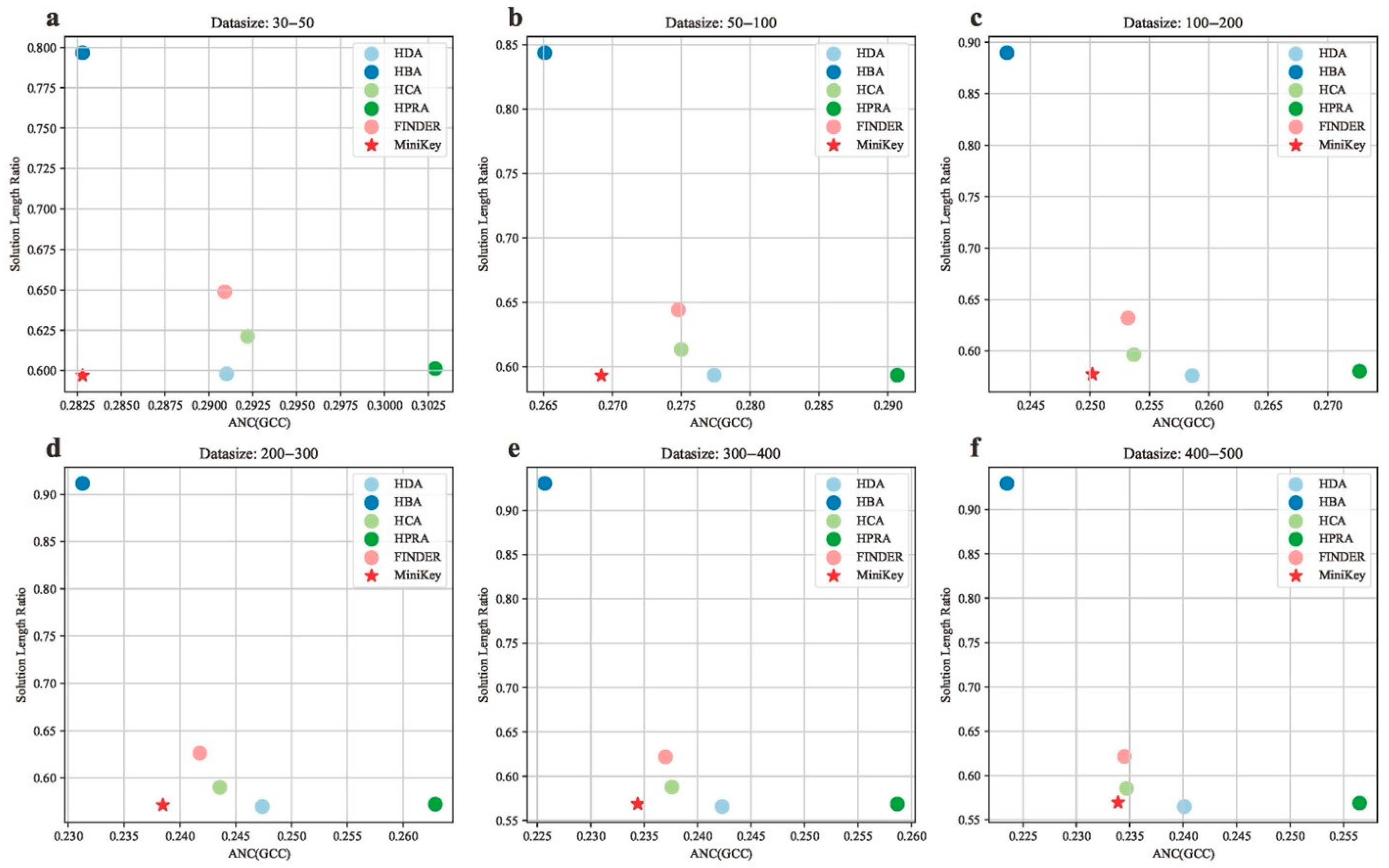
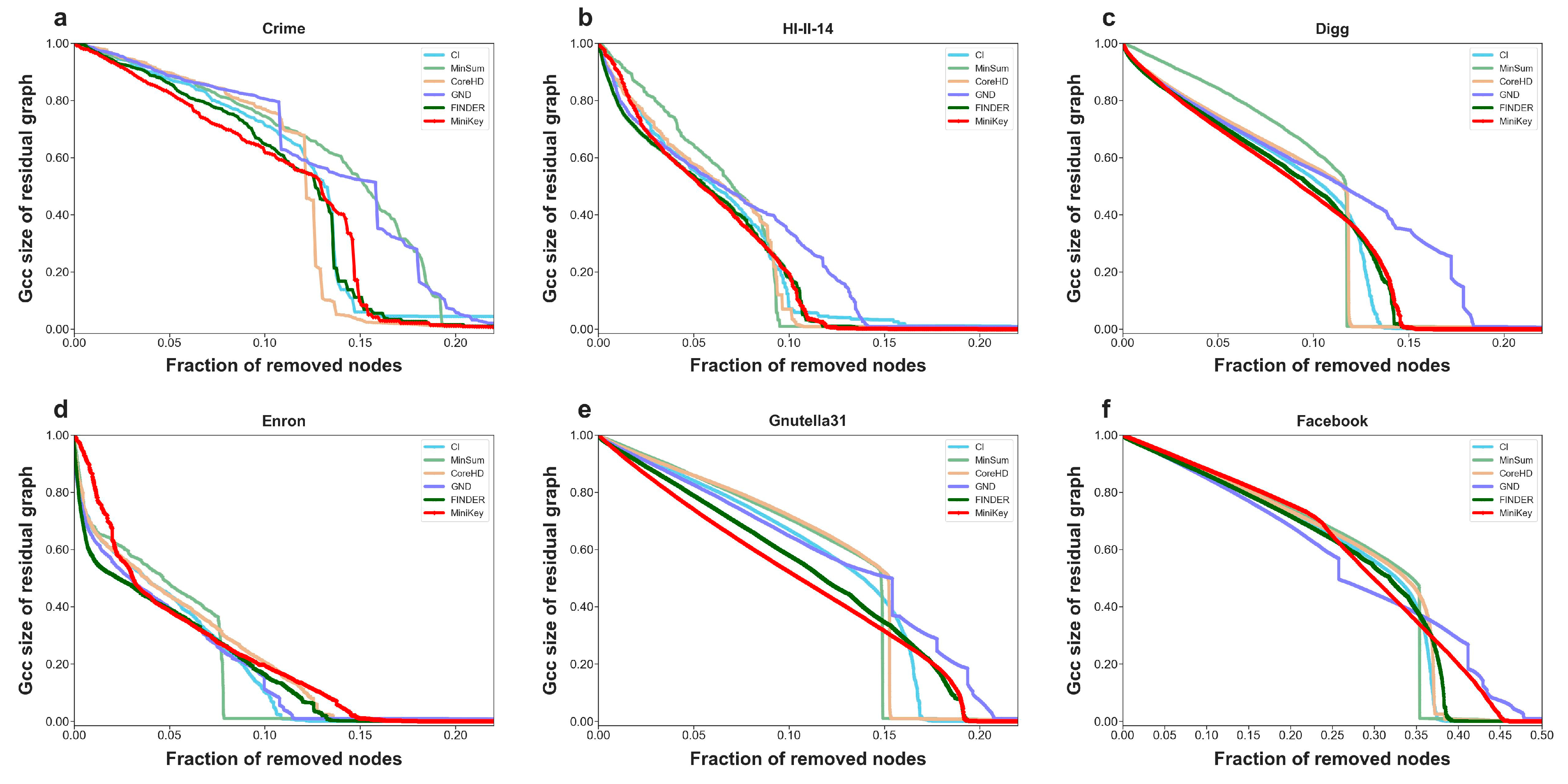
4. Results
4.1. Results on Synthetic Graphs
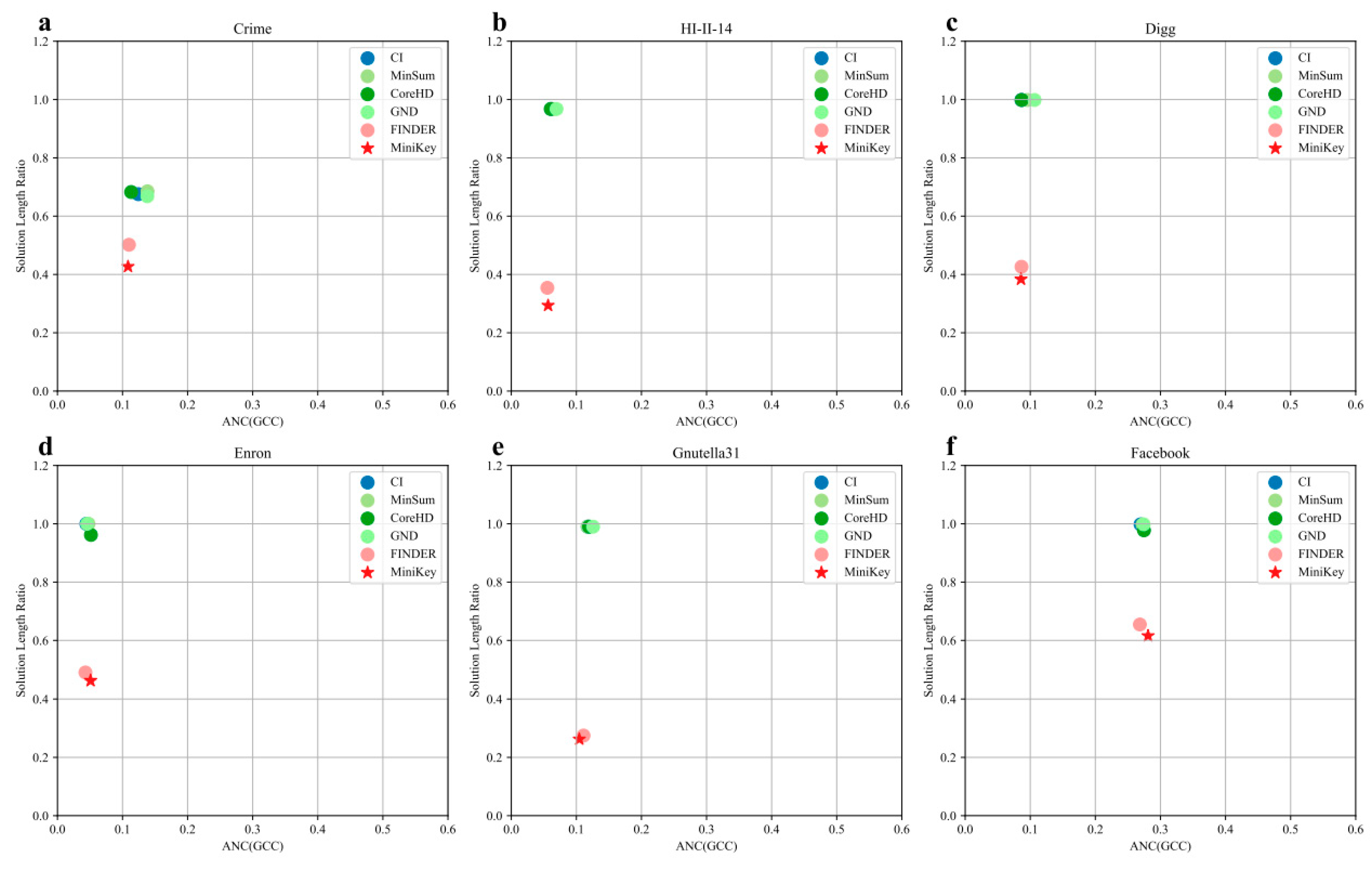
4.2. Results on Real-World Networks
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Morone, F.; Makse, H.A. Influence Maximization in Complex Networks through Optimal Percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef]
- Lü, L.; Chen, D.; Ren, X.-L.; Zhang, Q.-M.; Zhang, Y.-C.; Zhou, T. Vital Nodes Identification in Complex Networks. Phys. Rep. 2016, 650, 1–63. [Google Scholar] [CrossRef]
- Lalou, M.; Tahraoui, M.A.; Kheddouci, H. The Critical Node Detection Problem in Networks: A Survey. Comput. Sci. Rev. 2018, 28, 92–117. [Google Scholar] [CrossRef]
- Borgatti, S.P. Identifying Sets of Key Players in a Social Network. Comput. Math. Organ. Theory 2006, 12, 21–34. [Google Scholar] [CrossRef]
- Pastor-Satorras, R.; Vespignanj, A. Epidemic Spreading in Scale-Free Networks. In The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2011; pp. 493–496. [Google Scholar]
- Kuntz, I.D. Structure-Based Strategies for Drug Design and Discovery. Science 1992, 257, 1078–1082. [Google Scholar] [CrossRef] [PubMed]
- Leskovec, J.; Adamic, L.A.; Huberman, B.A. The Dynamics of Viral Marketing. In Proceedings of the 7th ACM Conference on Electronic Commerce, Ann Arbor, MI, USA, 11–15 June 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Bright, D.; Greenhill, C.; Britz, T.; Ritter, A.; Morselli, C. Criminal Network Vulnerabilities and Adaptations. Glob. Crime 2017, 18, 424–441. [Google Scholar] [CrossRef]
- Chen, L.; Wang, C.; Zeng, C.; Wang, L.; Liu, H.; Chen, J. A Novel Method of Heterogeneous Combat Network Disintegration Based on Deep Reinforcement Learning. Front. Phys. 2022, 10, 1021245. [Google Scholar] [CrossRef]
- Walteros, J.L.; Veremyev, A.; Pardalos, P.M.; Pasiliao, E.L. Detecting Critical Node Structures on Graphs: A Mathematical Programming Approach. Networks 2018, 73, 48–88. [Google Scholar] [CrossRef]
- Ventresca, M.; Aleman, D. A Derandomized Approximation Algorithm for the Critical Node Detection Problem. Comput. Oper. Res. 2014, 43, 261–270. [Google Scholar] [CrossRef]
- Hooshmand, F.; Mirarabrazi, F.; MirHassani, S.A. Efficient Benders Decomposition for Distance-Based Critical Node Detection Problem. Omega 2020, 93, 102037. [Google Scholar] [CrossRef]
- Albert, R.; Jeong, H.; Barabási, A.-L. Error and Attack Tolerance of Complex Networks. Nature 2000, 406, 378–382. [Google Scholar] [CrossRef]
- Carmi, S.; Havlin, S.; Kirkpatrick, S.; Shavitt, Y.; Shir, E. A Model of Internet Topology Using K-Shell Decomposition. Proc. Natl. Acad. Sci. USA 2007, 104, 11150–11154. [Google Scholar] [CrossRef]
- Wandelt, S.; Sun, X.; Feng, D.; Zanin, M.; Havlin, S. A Comparative Analysis of Approaches to Network-Dismantling. Sci. Rep. 2018, 8, 13513. [Google Scholar] [CrossRef]
- Qin, J.; Xu, J.J.; Hu, D.; Sageman, M.; Chen, H. Analyzing Terrorist Networks: A Case Study of the Global Salafi Jihad Network. In Intelligence and Security Informatics; Springer: Berlin/Heidelberg, Germany, 2005; pp. 287–304. [Google Scholar]
- Aringhieri, R.; Grosso, A.; Hosteins, P.; Scatamacchia, R. VNS Solutions for the Critical Node Problem. Electron. Notes Discret. Math. 2015, 47, 37–44. [Google Scholar] [CrossRef]
- Mahdavi Pajouh, F.; Boginski, V.; Pasiliao, E.L. Minimum Vertex Blocker Clique Problem. Networks 2014, 64, 48–64. [Google Scholar] [CrossRef]
- Zhou, H.-J. Spin Glass Approach to the Feedback Vertex Set Problem. Eur. Phys. J. B 2013, 86, 455. [Google Scholar] [CrossRef]
- Qin, S.-M.; Ren, X.-L.; Lü, L.-Y. Efficient Network Dismantling via Node Explosive Percolation. Commun. Theor. Phys. 2019, 71, 764. [Google Scholar] [CrossRef]
- Šimon, M.; Dirgová Luptáková, I.; Huraj, L.; Hosťovecký, M.; Pospíchal, J. Combined Heuristic Attack Strategy on Complex Networks. Math. Probl. Eng. 2017, 2017, 6108563. [Google Scholar] [CrossRef]
- Fan, C.; Zeng, L.; Feng, Y.; Xiu, B.; Huang, J.; Liu, Z. Revisiting the Power of Reinsertion for Optimal Targets of Network Attack. J. Cloud Comput. 2020, 9, 24. [Google Scholar] [CrossRef]
- Ren, X.-L.; Gleinig, N.; Helbing, D.; Antulov-Fantulin, N. Generalized Network Dismantling. Proc. Natl. Acad. Sci. USA 2019, 116, 6554–6559. [Google Scholar] [CrossRef]
- Deng, Y.; Wu, J.; Tan, Y. Optimal Attack Strategy of Complex Networks Based on Tabu Search. Phys. A Stat. Mech. Its Appl. 2016, 442, 74–81. [Google Scholar] [CrossRef]
- Zhou, Y.; Hao, J.-K.; Fu, Z.-H.; Wang, Z.; Lai, X. Variable Population Memetic Search: A Case Study on the Critical Node Problem. IEEE Trans. Evol. Comput. 2021, 25, 187–200. [Google Scholar] [CrossRef]
- Arulselvan, A.; Commander, C.W.; Elefteriadou, L.; Pardalos, P.M. Detecting Critical Nodes in Sparse Graphs. Comput. Oper. Res. 2009, 36, 2193–2200. [Google Scholar] [CrossRef]
- Lozano, M.; García-Martínez, C.; Rodríguez, F.J.; Trujillo, H.M. Optimizing Network Attacks by Artificial Bee Colony. Inf. Sci. 2017, 377, 30–50. [Google Scholar] [CrossRef]
- Khalil, E.; Dai, H.; Zhang, Y.; Dilkina, B.; Song, L. Learning Combinatorial Optimization Algorithms over Graphs. In Advances in Neural Information Processing Systems 30 (NIPS 2017); NIPS: Grenada, Spain, 2017. [Google Scholar]
- Fan, C.; Shen, M.; Nussinov, Z.; Liu, Z.; Sun, Y.; Liu, Y.-Y. Searching for Spin Glass Ground States through Deep Reinforcement Learning. Nat. Commun. 2023, 14, 725. [Google Scholar] [CrossRef]
- Fan, C.; Zeng, L.; Sun, Y.; Liu, Y.-Y. Finding Key Players in Complex Networks through Deep Reinforcement Learning. Nat. Mach. Intell. 2020, 2, 317–324. [Google Scholar] [CrossRef] [PubMed]
- Braunstein, A.; Dall’Asta, L.; Semerjian, G.; Zdeborová, L. Network Dismantling. Proc. Natl. Acad. Sci. USA 2016, 113, 12368–12373. [Google Scholar] [CrossRef]
- Sarker, S.; Veremyev, A.; Boginski, V.; Arvind, S. Critical Nodes in River Networks. Sci Rep. 2019, 9, 11178. [Google Scholar] [CrossRef]
- Holme, P.; Kim, B.J.; Yoon, C.N.; Han, S.K. Attack Vulnerability of Complex Networks. Phys. Rev. E 2002, 65, 056109. [Google Scholar] [CrossRef]
- Dinur, I.; Safra, S. On the Hardness of Approximating Vertex Cover. Ann. Math. 2005, 162, 439–485. [Google Scholar] [CrossRef]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems 30 (NIPS 2017); NIPS: Grenada, Spain, 2017. [Google Scholar]
- Liu, C.; Xu, X.; Hu, D. Multiobjective Reinforcement Learning: A Comprehensive Overview. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 385–398. [Google Scholar] [CrossRef]
- Van Moffaert, K.; Nowé, A. Multi-objective reinforcement learning using sets of pareto dominating policies. J. Mach. Learn. Res. 2014, 15, 3483–3512. [Google Scholar]
- Zdeborová, L.; Zhang, P.; Zhou, H.-J. Fast and Simple Decycling and Dismantling of Networks. Sci. Rep. 2016, 6, 37954. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Bavelas, A. Communication Patterns in Task-Oriented Groups. J. Acoust. Soc. Am. 1950, 22, 725–730. [Google Scholar] [CrossRef]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection; SNAP: Santa Monica, CA, USA, 2014. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Pei, H.; Wei, B.; Chang, K.; Lei, Y.; Yang, B. Geom-GCN: Geometric Graph Convolutional Networks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics/Dataset | Crime | HI-II-14 | Digg | Enron | Gnutella31 | |
|---|---|---|---|---|---|---|
| Node Number | 829 | 4165 | 29,652 | 33,696 | 62,561 | 63,392 |
| Edge Number | 1473 | 13,087 | 84,781 | 180,811 | 147,878 | 816,831 |
| Maximum Degree | 25 | 286 | 310 | 1383 | 95 | 1098 |
| Average Degree | 3.55 | 6.28 | 5.72 | 10.73 | 4.73 | 25.77 |
| Diameter | 10 | 11 | 12 | 11 | 11 | 15 |
| Clustering Coefficient | 0.0058 | 0.0444 | 0.0054 | 0.5092 | 0.0055 | 0.2218 |
| Assortativity | −0.1645 | −0.2016 | 0.0027 | −0.1165 | −0.0927 | 0.1768 |
| Method/Dataset | Crime | HI-II-14 | Digg | Enron | Gnutella31 | |
|---|---|---|---|---|---|---|
| CI | 0.1243 | 0.0616 | 0.0866 | 0.0445 | 0.1174 | 0.2695 |
| MinSum | 0.1383 | 0.0652 | 0.0952 | 0.0477 | 0.1173 | 0.2725 |
| CoreHD | 0.1133 | 0.0606 | 0.0868 | 0.0514 | 0.1197 | 0.2747 |
| GND | 0.1381 | 0.0694 | 0.1066 | 0.0456 | 0.1257 | 0.2742 |
| FINDER | 0.1099 | 0.0554 | 0.0866 | 0.0430 | 0.1110 | 0.2684 |
| MiniKey | 0.1085 | 0.0566 | 0.0858 | 0.0509 | 0.1045 | 0.2810 |
| Method/Dataset | Crime | HI-II-14 | Digg | Enron | Gnutella31 | |
|---|---|---|---|---|---|---|
| CI | 0.6755 | 0.9676 | 0.9985 | 1.0000 | 0.9901 | 0.9980 |
| MinSum | 0.6852 | 0.9676 | 0.9984 | 1.0000 | 0.9901 | 0.9976 |
| CoreHD | 0.6828 | 0.9676 | 0.9985 | 0.9619 | 0.9901 | 0.9776 |
| GND | 0.6683 | 0.9676 | 0.9985 | 1.0000 | 0.9901 | 0.9980 |
| FINDER | 0.5018 | 0.3541 | 0.4263 | 0.4901 | 0.2748 | 0.6547 |
| MiniKey | 0.4270 | 0.2936 | 0.3836 | 0.4626 | 0.2624 | 0.6157 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, L.; Fan, C.; Chen, C. Leveraging Minimum Nodes for Optimum Key Player Identification in Complex Networks: A Deep Reinforcement Learning Strategy with Structured Reward Shaping. Mathematics 2023, 11, 3690. https://doi.org/10.3390/math11173690
Zeng L, Fan C, Chen C. Leveraging Minimum Nodes for Optimum Key Player Identification in Complex Networks: A Deep Reinforcement Learning Strategy with Structured Reward Shaping. Mathematics. 2023; 11(17):3690. https://doi.org/10.3390/math11173690
Chicago/Turabian StyleZeng, Li, Changjun Fan, and Chao Chen. 2023. "Leveraging Minimum Nodes for Optimum Key Player Identification in Complex Networks: A Deep Reinforcement Learning Strategy with Structured Reward Shaping" Mathematics 11, no. 17: 3690. https://doi.org/10.3390/math11173690