4.3.2. Testing with Synthesized Lens Flare CamVid Database and Synthesized Lens Flare KITTI Databases
- (1)
Ablation Study
- (a)
Performance Comparisons According to Module Combinations
We compared the performance of CAM-FRN by combining the modules proposed in
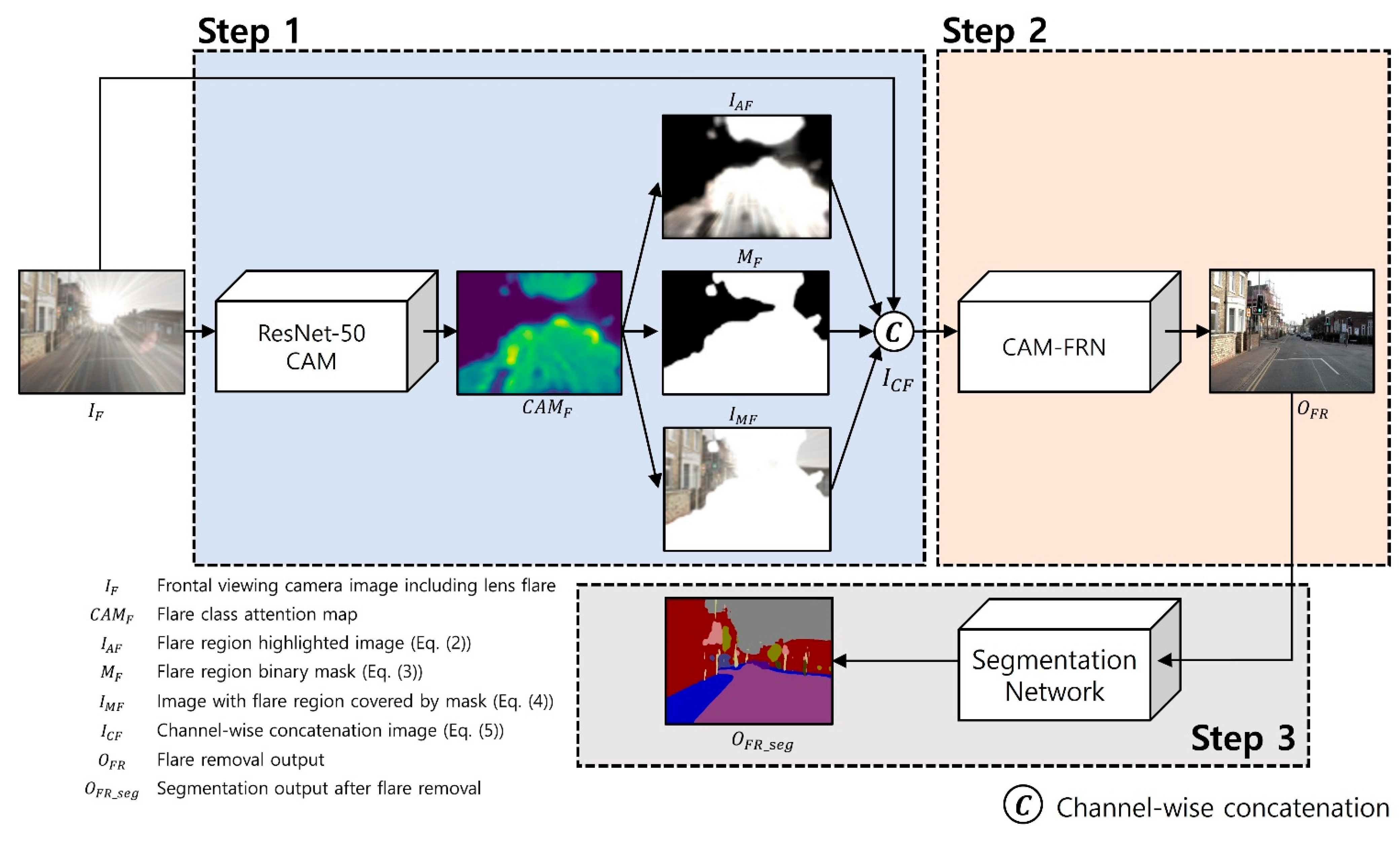
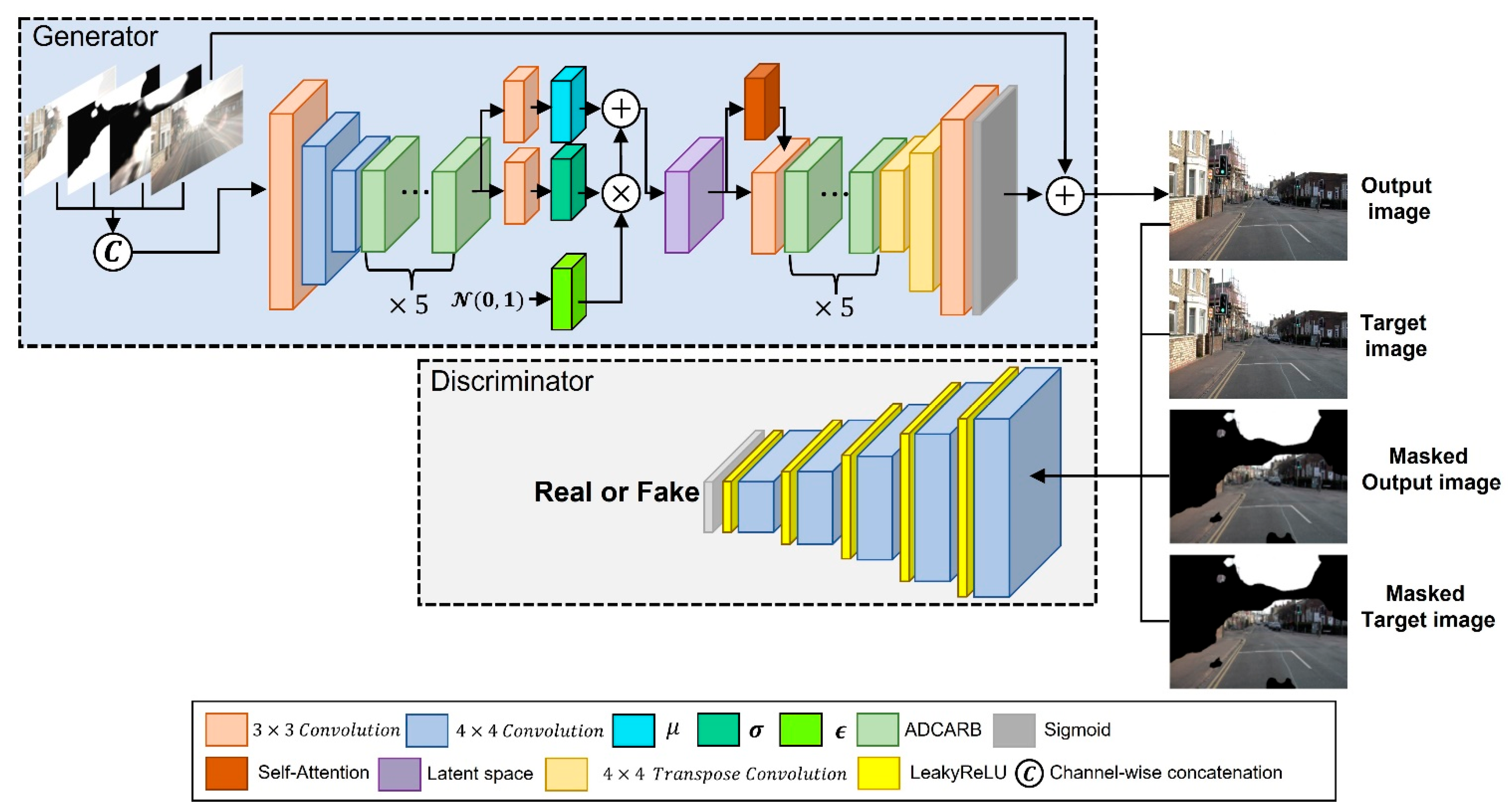
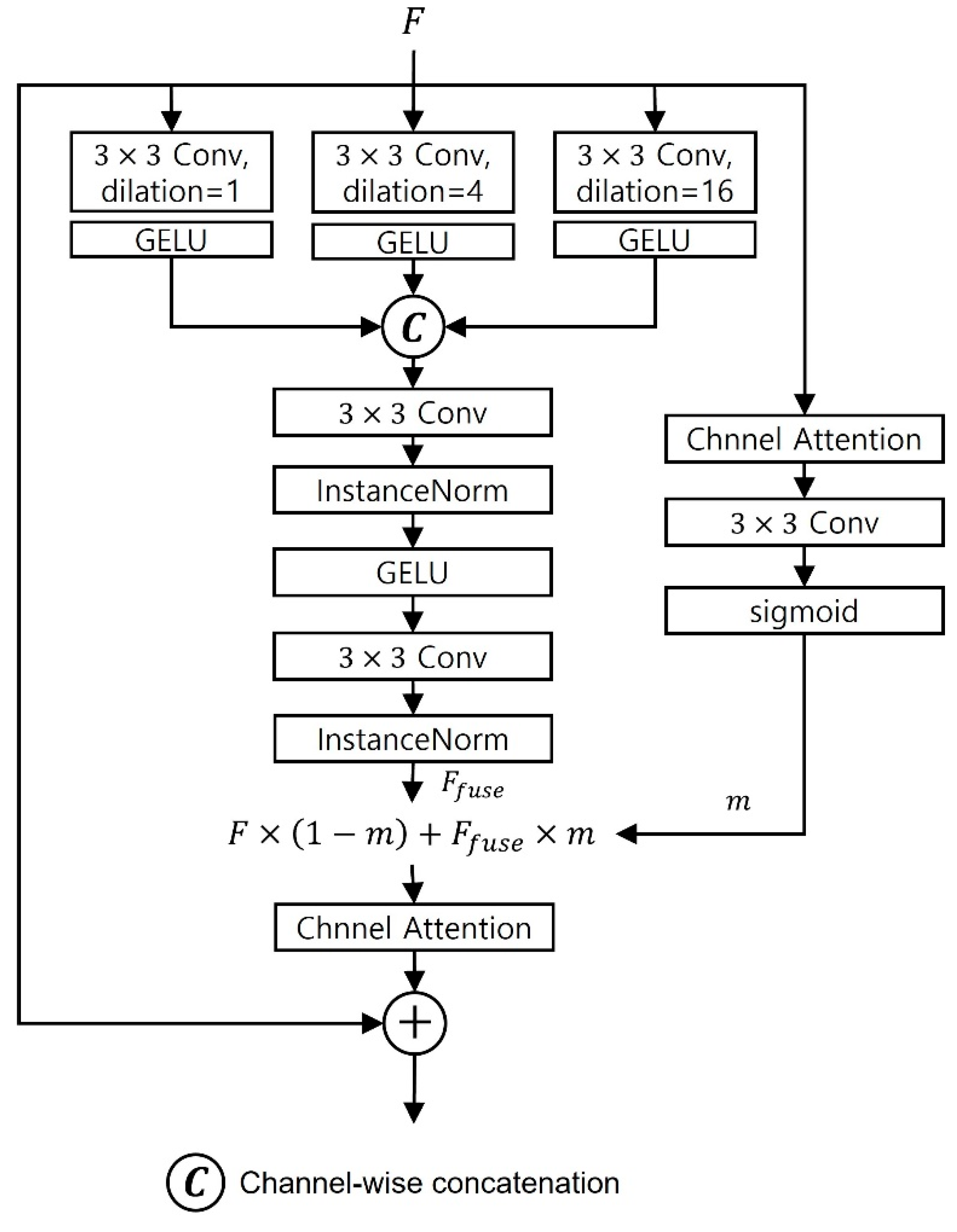
Section 3. We compared the semantic segmentation performance and image restoration performance by applying and not applying the following modules: a module for obtaining additional images using Equations (2)–(4) besides images damaged by a lens flare through CAM that represents the lens flare region in an image. Lastly, the ADCARB module, a self-attention module, fuses latent spaces that have undergone variational inference and applied with self-attention and not applied with self-attention, and sends them to the decoder. If ADCARB is not applied, the residual block used in the existing CycleGAN was applied; if the self-attention module is not applied, the latent space that has been sampled through variational inference is directly sent to the decoder. When the CAM module is not applied, the process of reflecting the mask for the lens flare region, which can be obtained by CAM and additional inputs in the losses, is omitted.
To compare the performance of different module combinations on each dataset, we analyzed the restoration performance with the results shown in
Table 6 and
Table 7.
Table 6 and
Table 7 demonstrate the greatest performance improvement, and the best performance was exhibited for all metrics.
Consequently, we verified two aspects through the ablation study. First, inputs additionally obtained by CAM enabled ADCARB of CAM-FRN to utilize the additional information of flare sufficiently and efficiently. CAM provides additional information about the flare region, which highlights the flare-damaged areas within the feature. This enables ADCARB to effectively extract and restore damaged areas. The evidence for this is as follows: in an ablation study, applying ADCARB and self-attention alone without using CAM resulted in worse performance than applying CAM and ADCARB together. Second, it was experimentally proven that using CAM, ADCARB, and self-attention module together may be effective for posterior distribution inference for restoring clean images.
Next, we input the restored images into the segmentation network and tested them according to the combination of modules. To compare the performance with respect to the combination of the modules, the evaluation metrics of the semantic segmentation performance according to the combination of modules are shown in
Table 8 and
Table 9.
Table 8 and
Table 9 demonstrate the greatest performance improvement; the best performance was exhibited for all metrics. Accordingly, the metrics of object detection performance of semantic segmentation increase along with the restoration performance evaluation metrics according to the combination of modules.
Table 10 and
Table 11 present IoU metrics per class in which IoU metrics of each class were improved according to the restoration performance evaluation metrics, as analyzed in
Table 8 and
Table 9.
Next, we conducted an ablation study for numerically analyzing the semantic segmentation performance for the combination of inputs created with CAM. As shown in
Table 12 and
Table 13, we measured the semantic segmentation performance according to the combination of additional inputs based on class accuracy, pixel accuracy, and mIoU. An image
damaged by a flare was used in all combinations as a default, and we compared the performance of the combinations when the inputs proposed in our method were all used and unused.
According to
Table 12, there was no significant difference in the performance according to the combination of inputs. However, class accuracy, pixel accuracy, and mIoU were the highest when all inputs were used, as we proposed. In particular, when mIoU was increased by 0.13% then when only
was used, and mIoU was 0.03% higher than the combination of
,
, and
which demonstrated the second highest mIoU. And
Table 13 similarly shows that there is no significant difference in performance based on the combination of inputs. However, as suggested, using all inputs resulted in the highest-class accuracy, pixel accuracy, and mIoU. Specifically, mIoU was 0.21% higher than using
alone and 0.12% higher than the combination of
,
, and
.
- (b)
Performance Comparisons with and without Variational Inference
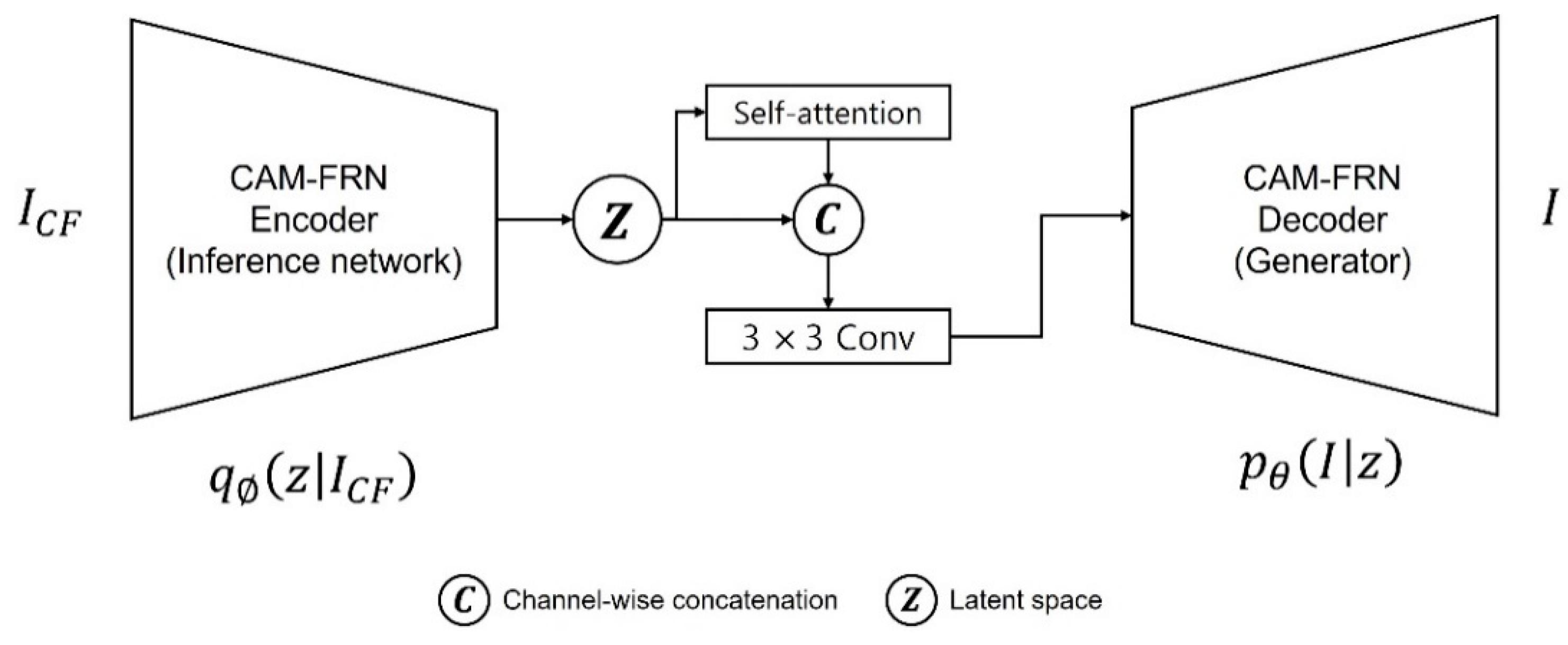
In this section, we conducted an ablation study to verify the effects of adopting variational inference on the performance of our proposed method. The reparameterization trick structure for variational inference was removed between the encoder and decoder of CAM-FRN; then, latent spaces from the encoder that were applied with self-attention and not applied with self-attention were fused to be delivered to the decoder. Additionally, the experiment was conducted using L1 loss and L2 loss, without using the Kullback–Leibler divergence (KL divergence), which was applied to reduce the difference between true posterior distribution and posterior distribution inferred by the inference network, or the reconstruction loss used for variational inference.
Table 14 and
Table 15 present the evaluation metrics of the restoration performance for syn-flare CamVid dataset and syn-flare KITTI dataset. When L1 loss was used in place of variational inference, both datasets showed PSNR and SSIM did not exhibit a noticeable performance difference, but the FID score exhibited a significant difference. The FID score is a metric for evaluating the quality of images generated by the GAN structure, which uses a discriminator to calculate the distance between the distribution of the generated image and the distribution of the ground-truth image. The reason for using variational inference was to generate images that were semantically similar to the ground-truth image as much as possible in the decoder by sampling a significant latent space through the inference of the posterior distribution, which considered the ground-truth image. In other words, we aim to minimize the difference between the inferred posterior distribution
and the true posterior distribution
as shown in Equation (16). Therefore,
Table 14 and
Table 15 show that using variational inference can result in a better performance in terms of the FID score.
When L2 loss is used instead of variant inference, similar results are yielded to the analysis using L1 loss when compared with using variant inference. Similarly, the FID score was significantly reduced when using variant inference, and as discussed above, using variant inference can lead to better performance in terms of FID score.
As shown in
Table 16 and
Table 17, the same performance improvements in semantic segmentation were demonstrated in restoration. We can see that class accuracy, pixel accuracy, and mIoU are highest when using variational inference.
- (c)
Performance Comparisons According to Mask Considering Loss
For the next comparative experiment, we evaluate the semantic segmentation performance and image restoration performance for the two cases of considering the flare region and not considering the flare region in the proposed loss equation. For image-to-image translation, we used content loss [
42] and style loss [
42] based on VGG-19. Content loss and style loss were applied to the result of multiplying a flare region mask to the final output image and to the ground-truth image. Furthermore, the lens flare region was considered for the losses utilizing a discriminator; the image restoration performance was improved by making it difficult for the discriminator to discriminate whether the flare region is ground truth by focusing on the flare region. Accordingly, we expected CAM-FRN to concentrate more on the flare region for removal. We experimentally proved that our hypothesis is valid, as shown in
Table 18,
Table 19,
Table 20 and
Table 21.
Table 18 and
Table 19 are analyzed with respect to the restoration results. When the loss considering a mask is used, PSNR and SSIM were improved, respectively, compared with when not used. Further, the FID score was also significantly decreased. These results demonstrate that considering the lens flare region and the entire image together significantly improves performance. Segmentation performance was also improved along with the restoration performance. According to
Table 20 and
Table 21, when the loss considering a mask was used, class accuracy, pixel accuracy, and mIoU all increased, respectively, compared with when not used.
- (2)
Comparisons of Proposed Method and the State-of-the-Art Methods
We compared our proposed lens flare removal method with the previously proposed methods of Qiao et al. [
23] and Wu et al. [
9]. However, research has been insufficiently conducted owing to the difficulties of a lens flare removal task. Therefore, we additionally adopted several networks that were similar to our research purpose to compare the performance.
The proposed method used a GAN-based learning method utilizing a discriminator, wherein an image with a flare undergoes image-to-image translation to a clean image without flare. Therefore, we compared our proposed model with Pix2Pix [
37] and CycleGAN [
50], which have been commonly proposed for image-to-image translation. Lastly, we compared the performance against FFANet [
22] and MPRNet [
21] proposed for dehazing and deraining, respectively. Dehazing and deraining tasks aim to remove artifacts covering the objects in an image owing to environmental factors, which are similar to the lens flare removal task, which removes artifacts generated in the presence of a strong light source in the surrounding. In particular, hazing was similar to a lens flare artifact generated by light scattering, and veiling glare, which affects contrast within an image and causes the image to become hazy; therefore, we compare our proposed method with the networks designed for dehazing considering they were deemed effective in removing lens flare artifacts. Raining was similar to light streaks that radiated from a light source among various lens flare artifacts. We compared our proposed method with MPRNet, which was considered effective in restoring the image details covered by light streaks.
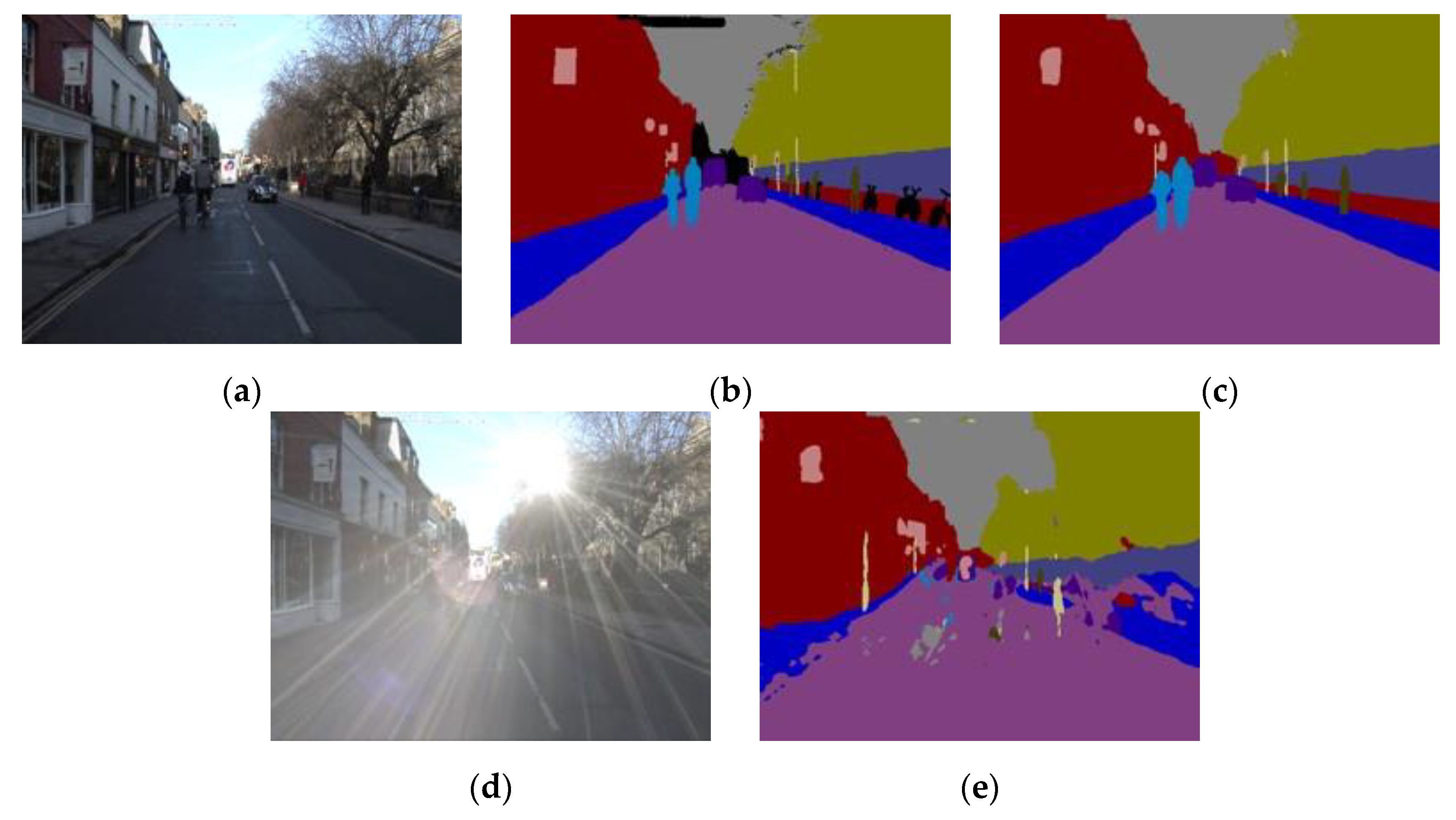
Figure 11 and
Figure 12 show the restoration results of the proposed method and previously explained methods.
The method proposed by Qiao et al. [
23] effectively removes reflection artifacts where the flare region is seen; however, their method was proven ineffective in removing lens flare artifacts generated through the image. As shown in
Figure 11a and
Figure 12a, large regions of a flare within the image were not effectively removed throughout the image, and the restoration result was poorer than our proposed method. The method proposed by Wu et al. [
9] demonstrated a better performance than [
23]; however, lens flare was not completely removed. As shown in
Figure 11b, this method could not restore the details of the boundary between the road and sidewalk, or the details of people riding a bicycle. And in
Figure 12b, the artifacts overlaid on the pedestrian are not completely removed.
Next, we analyzed the restoration results of Pix2Pix and CycleGAN, which were proposed for image-to-image translation. Pix2Pix was far more outstanding than CycleGAN, considering the translation and execution from flare image to clean image and vice versa was not sufficiently trained. Conversely, the restoration results of Pix2Pix were visually more outstanding where the conditions of the ground-truth image were directly given to the discriminator. Compared with the proposed CAM-FRN, the restoration results of Pix2Pix did not adequately restore the details of the boundary between road and sidewalk, and light streaks of flare were remaining.
Lastly, our proposed method was compared with FFANet and MPRNet proposed for dehazing and deraining, respectively. Compared with the previously compared models, these models demonstrated a far more outstanding performance visually. MPRNet was effective in removing light streaks; however, it did not accurately restore the details of roads. FFANet successfully restored the image that became hazy by a flare to a clean original image, but flare artifacts were not perfectly removed. In contrast, our proposed method successfully restored the details of roads while adequately removing flare artifacts with outstanding performance.
Table 22 and
Table 23 present the numerical performance evaluation metrics according to the results of restoring images synthesized with a lens flare of each method. Among various models, the PSNR, SSIM, and FID scores of our proposed model were the best. FFANet demonstrated the second-highest performance, where PSNR and SSIM were similar to our method; however, the FID score was approximately 30 points higher than our proposed method. Based on such results, the distance difference of the feature maps extracted from inception v3 network [
49] was smaller in the proposed CAM-FRN than FFANet, and the result image was closer to the ground-truth image.
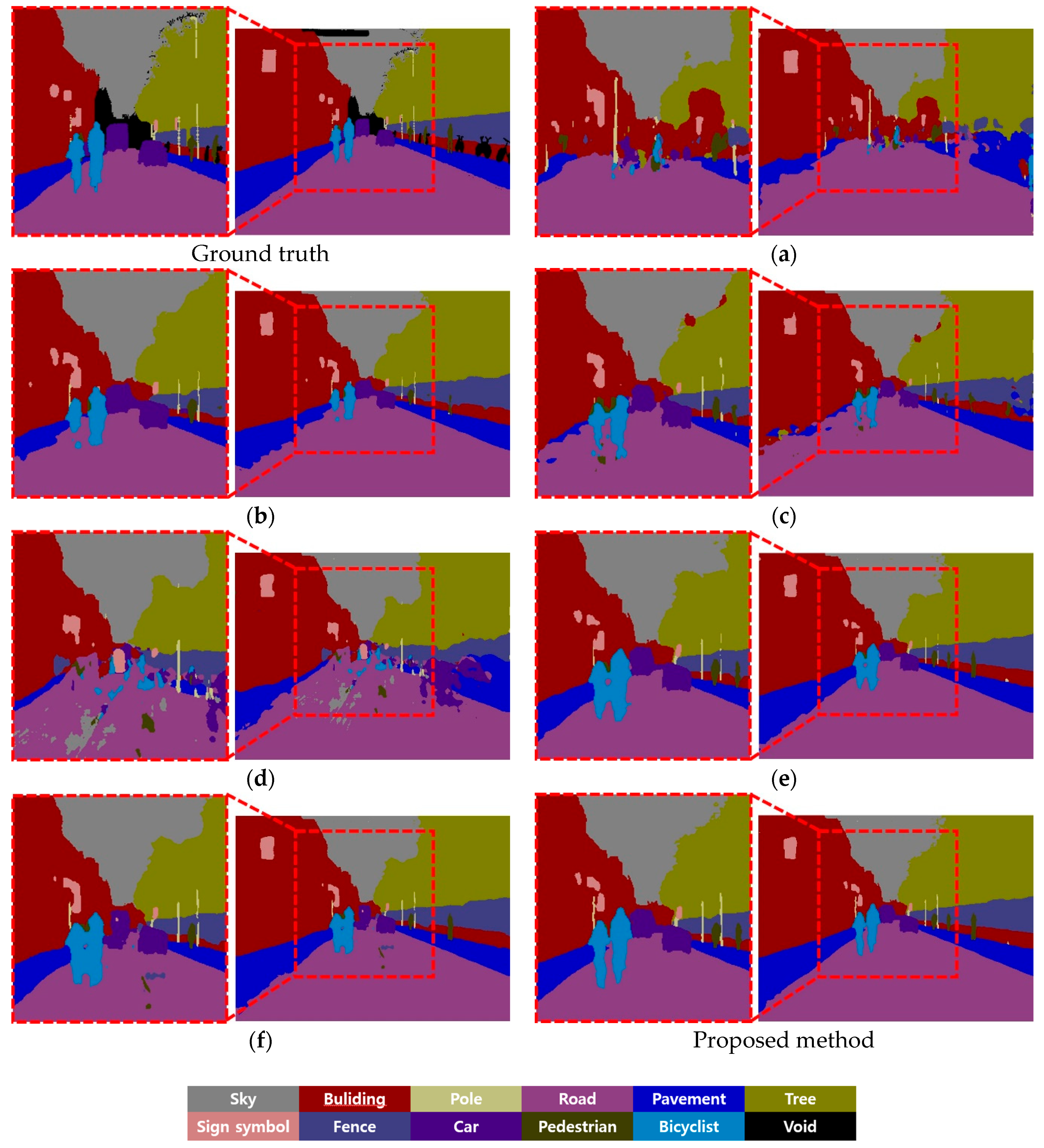
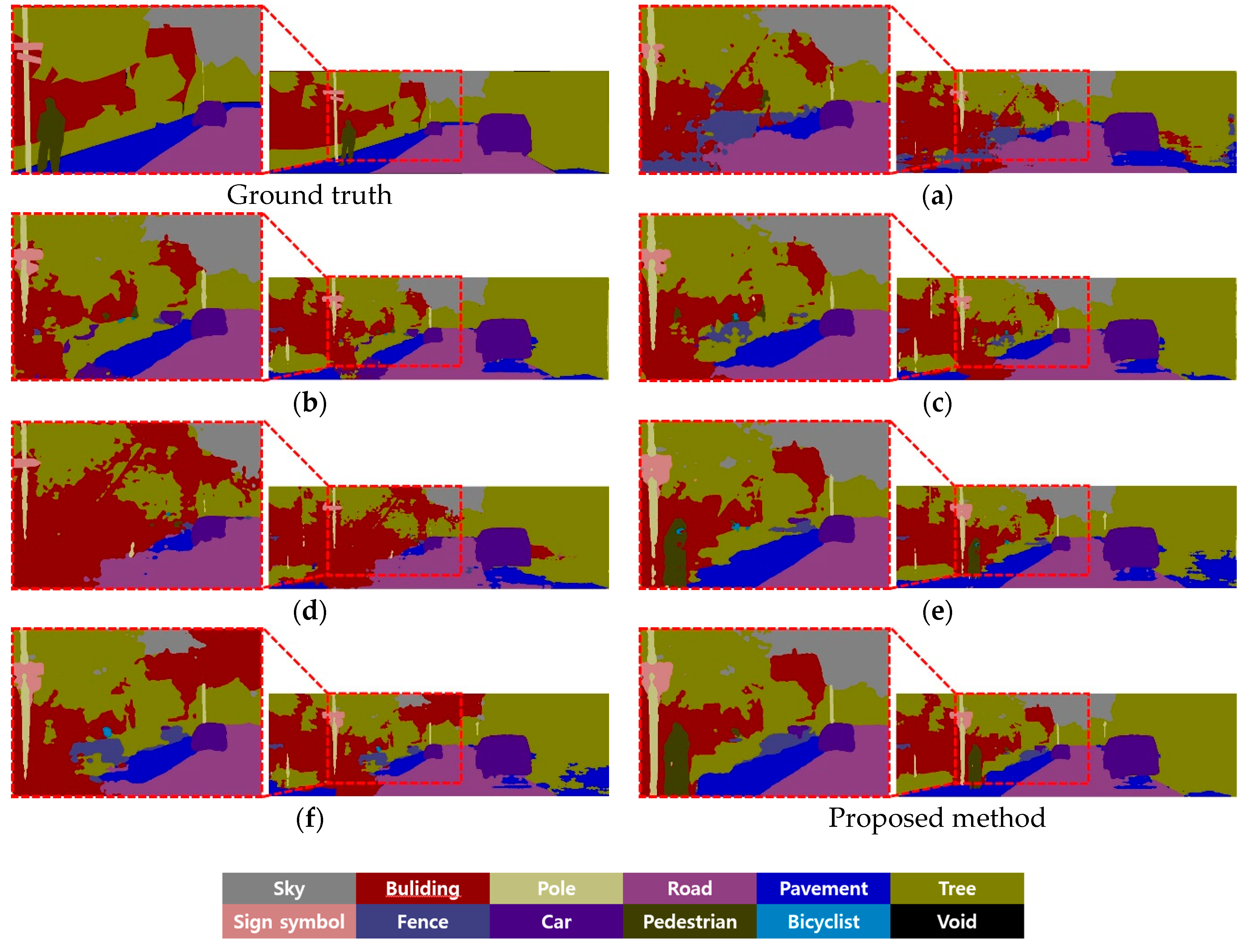
Figure 13 and
Figure 14 show the semantic segmentation test results for the images restored by our proposed method, the previously proposed method for flare removal, image-to-image translation methods, and the methods for dehazing and deraining. Overall, segmentation performance improved tremendously as the restoration performance improved. The method proposed by Qiao et al. [
23] was ineffective in removing lens flare artifacts generated throughout the image, as in the restoration result, thus also exhibiting poor segmentation results. The method proposed by Wu et al. [
9] effectively removed lens flare artifacts generated through the image compared with the method proposed in [
23], but as shown in the segmentation results in
Figure 13b, the details of the road, sidewalk boundary, and the person riding the bike were not properly restored, which contradicts the restoration results in
Figure 11b, and the pedestrian was not detected at all in
Figure 14b.
Next, the segmentation test results were analyzed according to the restoration result of Pix2Pix and CycleGAN, which were proposed for image-to-image translation. The restoration result of Pix2Pix was more outstanding than that of CycleGAN; which is in line with the restoration result, and the segmentation test result of the image restored by Pix2Pix was more outstanding than CycleGAN. However, Pix2Pix could not remove lens flare artifacts perfectly; road or people riding a bicycle were not properly detected depending on the restoration results, as shown in the enlarged part in
Figure 13 and
Figure 14.
Lastly, we compared the segmentation performance of FFANet and MPRNet. The segmentation result of the images restored by FFANet in
Figure 13e and
Figure 14e, visually showed a greater segmentation improvement compared with (a)–(d), which are the results of the previous methods. As presented in
Table 24 and
Table 25, the class accuracy, pixel accuracy, and mIoU were lower than that of the proposed method. Additionally, as shown in the enlarged part in
Figure 13e, the proposed method detected the shape of a bicyclist object more effectively compared with other methods. When the pedestrian class in the enlarged part of
Figure 14e and the enlarged part of the proposed method are compared, the proposed method detected the shape of the pedestrian more effectively. The segmentation result of the images restored by MPRNet in
Figure 13f demonstrated a noticeable performance improvement compared with other methods, as in
Figure 14e; however, the class accuracy, pixel accuracy, and mIoU were 6.49%, 2.99%, and 8.91% lower than that of the proposed method. In the segmentation result of the image restored by MPRNet shown in
Figure 14f, the pedestrian was not detected at all. Class accuracy, pixel accuracy, and mIoU are 5.31%, 4.63%, and 7.3% lower than the proposed method, respectively.
Table 26 and
Table 27 present the IoU of each class in the semantic segmentation result of the images restored by each method. As analyzed above, the proposed method demonstrates the best performance in terms of IoU per class.
Figure 15 shows the results of extracting Grad-CAM for the bicyclist class when the original CamVid image was input in DeepLabV3+ [
7], and when Grad-CAM [
51] for the bicyclist class and the images restored by CAM-FRN and other methods were input in DeepLabV3+. And
Figure 16 shows the results of extracting Grad-CAM for the pedestrian class when the original KITTI image is input in DeepLabV3+ [
7], and when Grad-CAM [
51] for the pedestrian class and the images restored by CAM-FRN and other methods are input in DeepLabV3+. After analyzing each figure, we found that our proposed method is the closest to the original image’s Grad-CAM.
Based on the analysis of the previous ablation study and comparative analysis with existing methods, we can provide the following reasons for the better performance of our proposed method compared with existing methods. Existing methods suffer from the problem of not removing artifacts properly when there are complex flare artifacts or there is a severe level of flare in the input image [
9,
21,
22,
23]. To solve these problems, we used CAM to provide additional information about the flare regions to the network, and reflected it in the loss function to successfully restore the parts covered by flare. Furthermore, we were able to consider composite flare artifacts. By doing so, we could achieve better restoration results compared with other methods, and based on the restoration results, we can see that the performance of our final goal, semantic segmentation, is also better than that of the existing restoration methods.
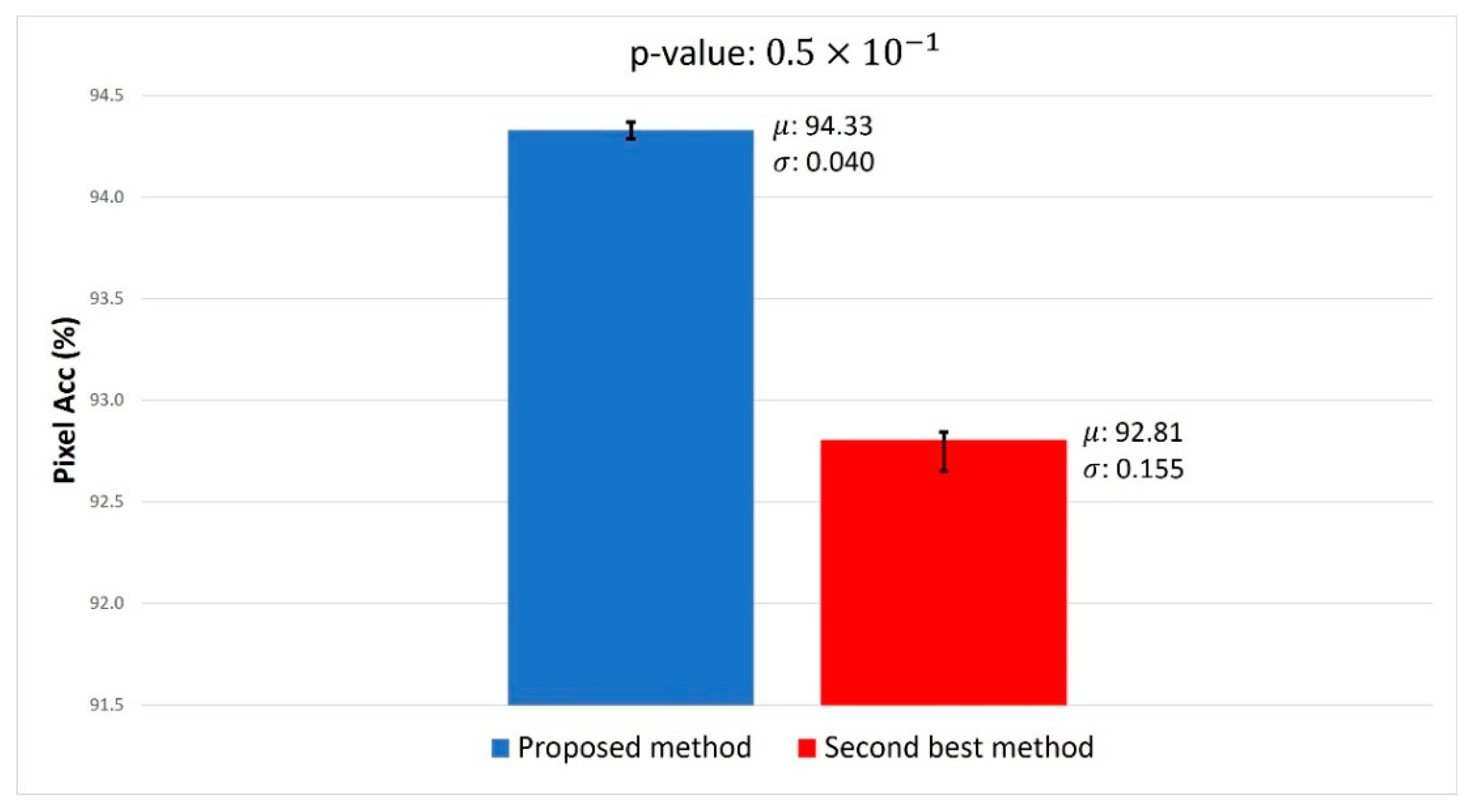
We calculate the
p-values using the values of the proposed method and the second-best method among all semantic segmentation evaluation metrics in
Table 24. We conducted
t-test [
52] and measured Cohen’s d-values [
53] to demonstrate the significance of the performance difference between the two methods. As shown in
Figure 17, the p-value of pixel accuracy is
, which indicates that a null hypothesis is rejected at the confidence interval of 95% and that the two methods have a difference in performance for pixel accuracy at the confidence interval of 95%. Subsequently, we measured Cohen’s
d-value for pixel accuracy, and the result was 6.7363. The criteria for Cohen’s
d-value are divided into 0.2, 0.5, and 0.8, which are distinguished into small, medium, and large effective sizes, respectively. Our Cohen’s d-value is greater than 0.8, which indicates that the performance difference between our method and the second-best method in terms of pixel accuracy is significantly large in the large effective size.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}