

HLEGF: An Effective Hypernetwork Community Detection Algorithm Based on Local Expansion and Global Fusion


Abstract
:1. Introduction
- (1)
- This paper extends the local expansion method to hypergraphs and proposes a hypernetwork community detection algorithm based on local expansion and global fusion, which provides a solution for identifying communities with hypergraph structures;
- (2)
- Based on the local expansion, we consider deleting nodes and hyperedges;
- (3)
- The algorithm establishes connections between sub-hypergraphs through global fusion to improve the relativity of detected communities.
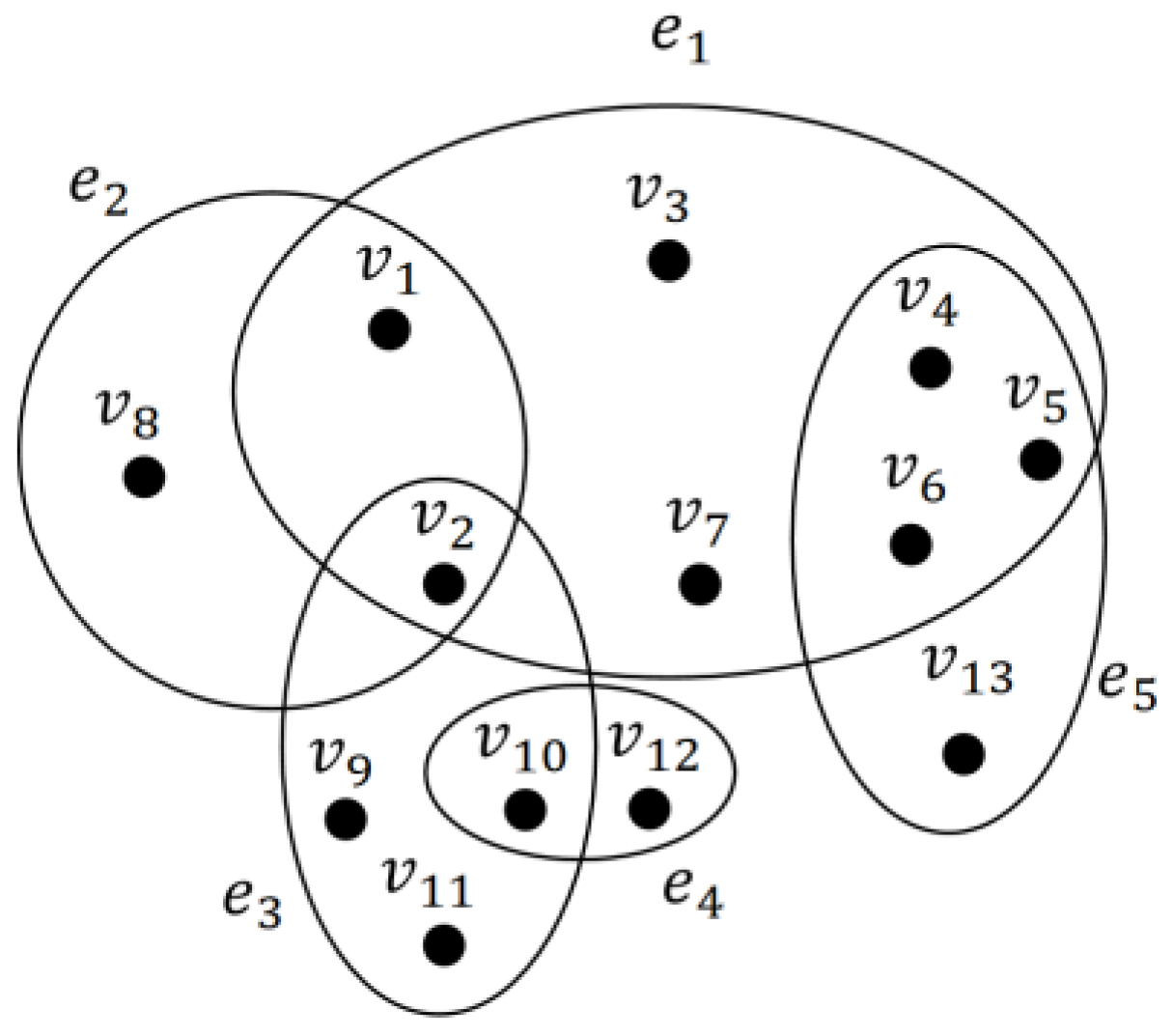
2. Basic Definitions
3. Proposed Method
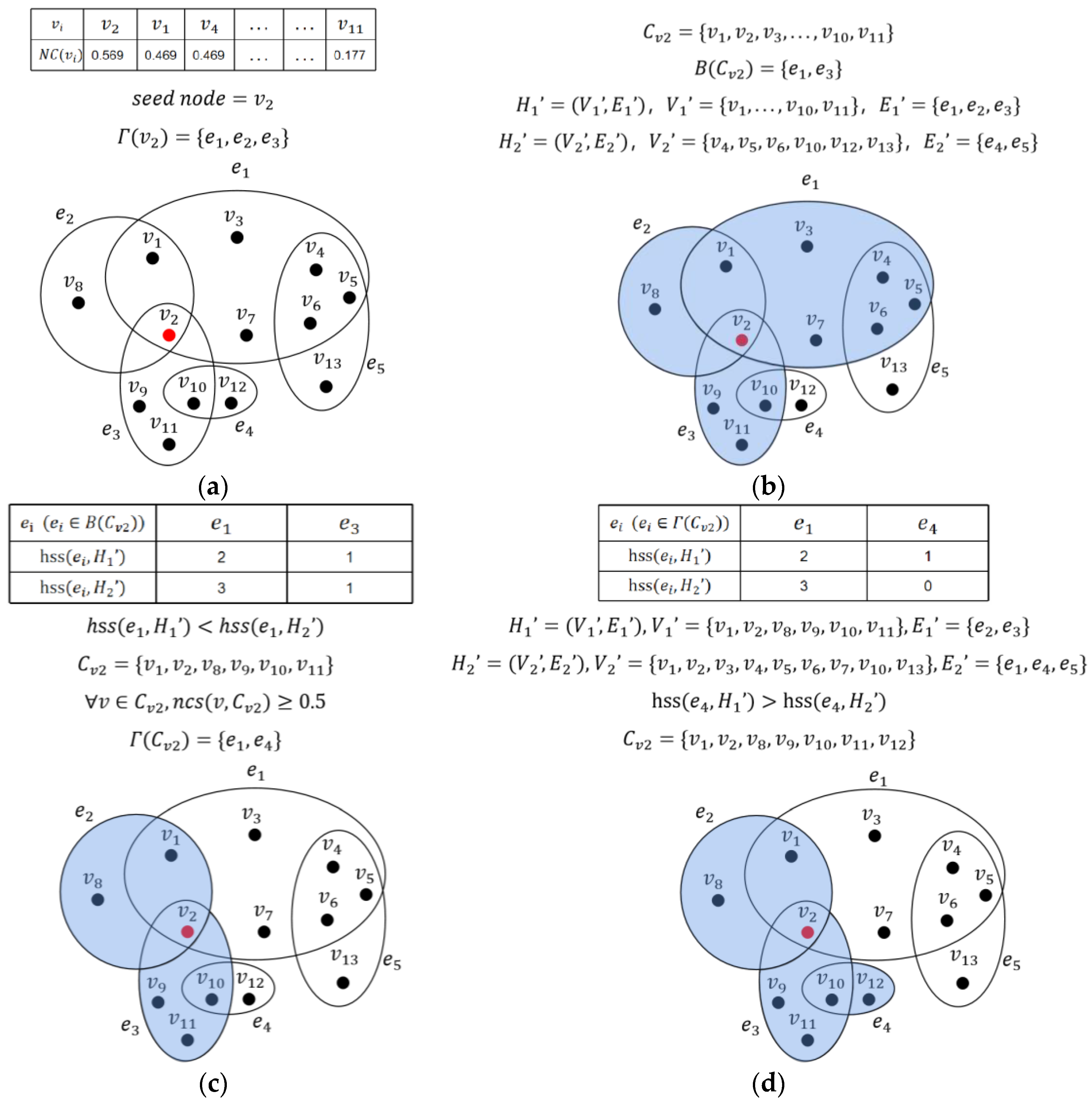
3.1. Local Expansion Process
| Algorithm 1: LE algorithm |
| Start LE |
| Input: Hypergraph , Node set , Hyperedge Set . |
| Output: The sub-hypergraph set . |
| 1: Initialization: |
| 2: Initialize the sub-hypergraph, |
| 3: Initialize the seed node set, |
| 4: Initialize the deleted edges, |
| 5: Initialize an unassigned-node sequence |
| 6: Calculate the centrality of each node based on Definition 3 |
| 7: Local expansion process: |
| 8: While do |
| 9: Seed selection sub-process: |
| 10: Get the seed node with the maximum centrality |
| 11: Get neighborhood of node based on Definition 4 |
| 12: Current community |
| 13: Deletion sub-process: |
| 14: Get community boundary based on Definition 5 |
| 15: the sub-hypergraph consisted of the , namely |
| 16: the sub-hypergraphs outside the , namely |
| 17: While do |
| 18: Update |
| 19: Update |
| 20: End while |
| 21: While do |
| 22: Update |
| 23: End while |
| 24: Expansion sub-process: |
| 25: Get community neighborhood based on Definition 5 |
| 26: Update and |
| 27: While do |
| 28: |
| 29: Update |
| 30: End while |
| 31: Update , , |
| 32: End while |
| 33: hypergraph for every , there is |
| 34: return |
| End LE |
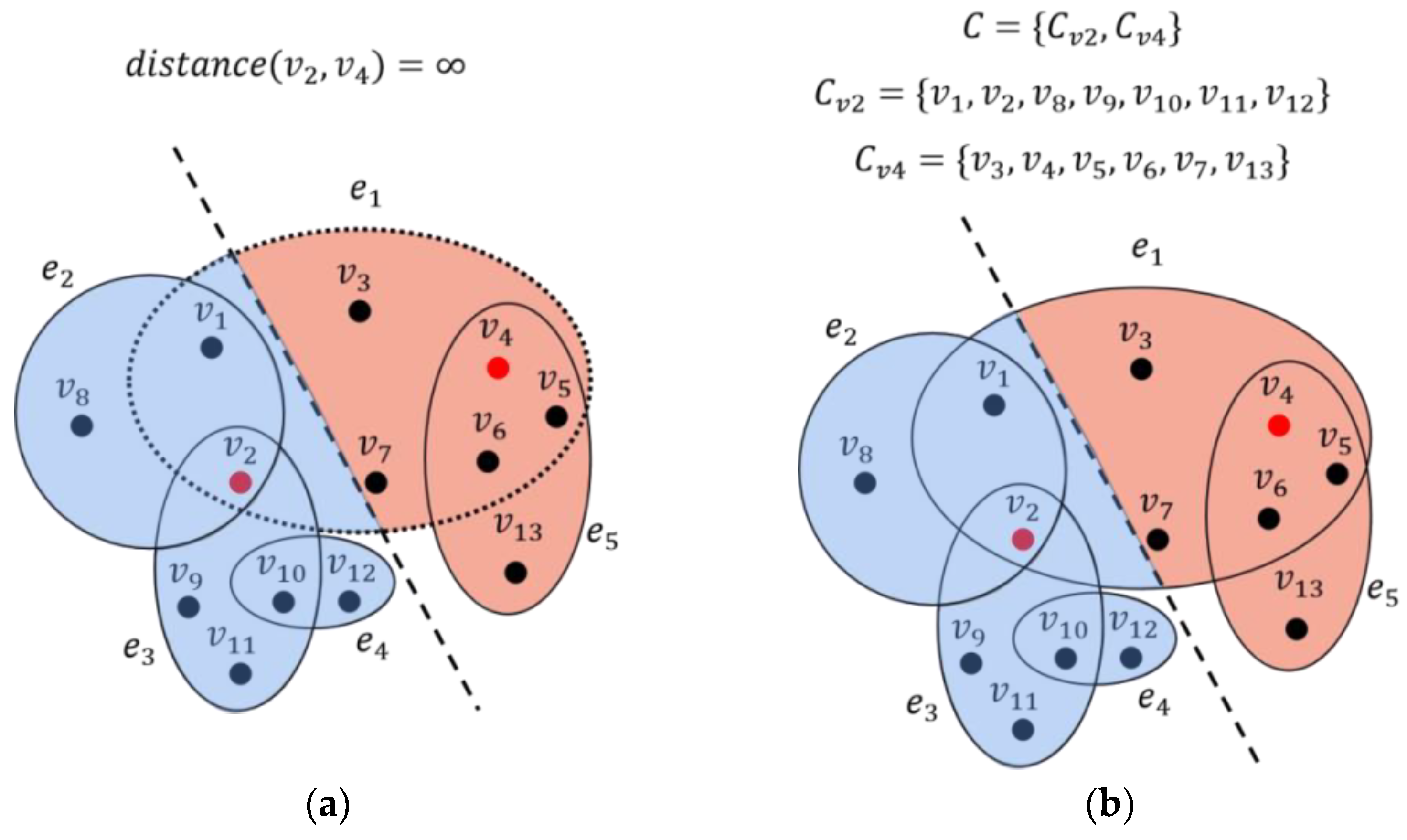
3.2. Global Fusion Process
| Algorithm 2: GF algorithm |
| Start GF |
| Input: Hypergraph and the sub-hypergraphs obtained by the LE process, the threshold . |
| Output: The final communities |
| 1: Sort in increasing order based on the size of different sub-hypergraphs |
| 2: Get the corresponding seed node as SN |
| 3: for in : |
| 4: Get seed node that corresponds to the current sub-hypergraph |
| 5: Get based on from the hypergraph |
| 6: If |
| 7: Merge into |
| 8: |
| 9: |
| 10: End if |
| 11: End for |
| 12: |
| 13: return |
| End GF |
4. Experimental Results and Analysis
4.1. Dataset
4.2. Evaluate Metrics
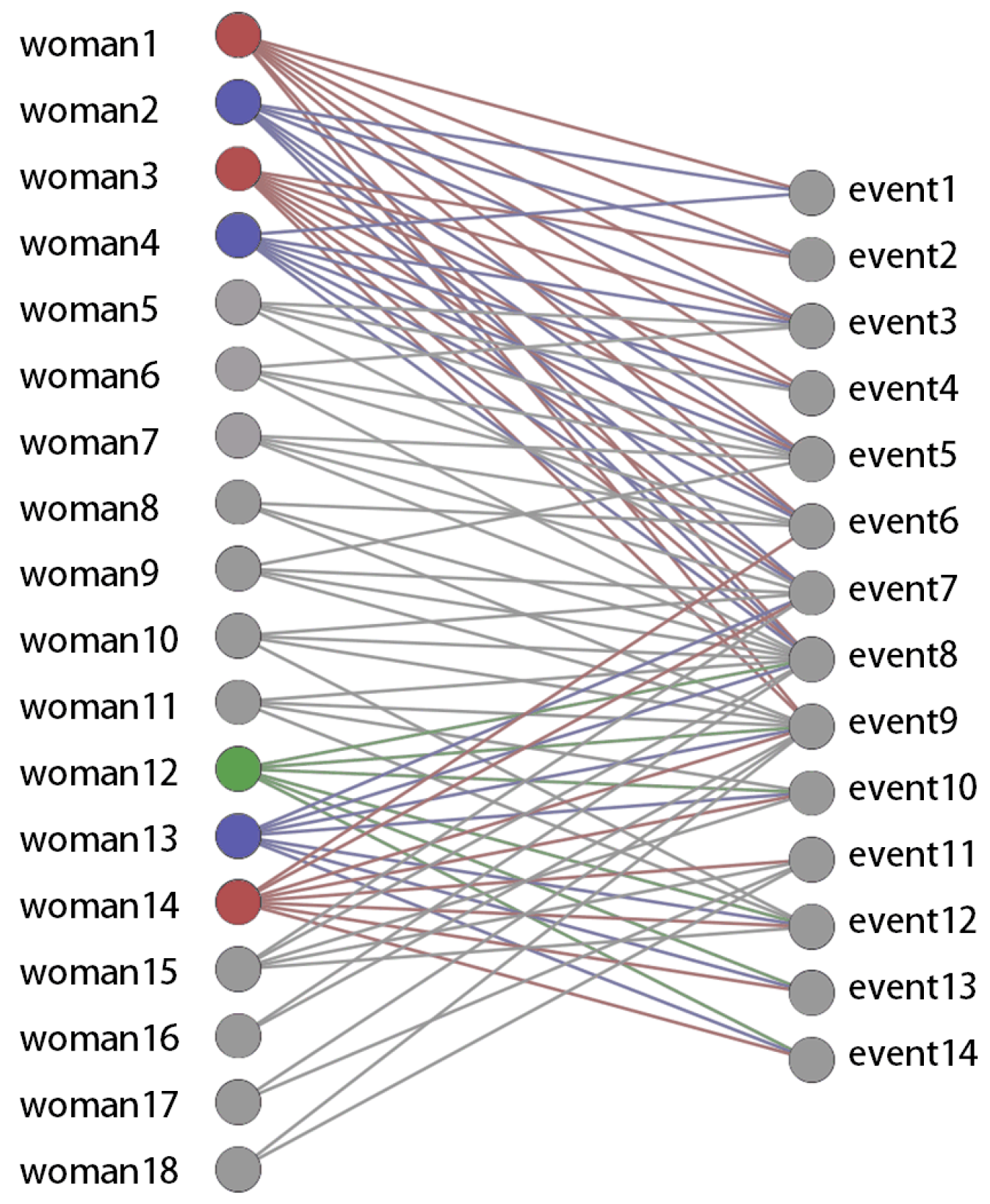
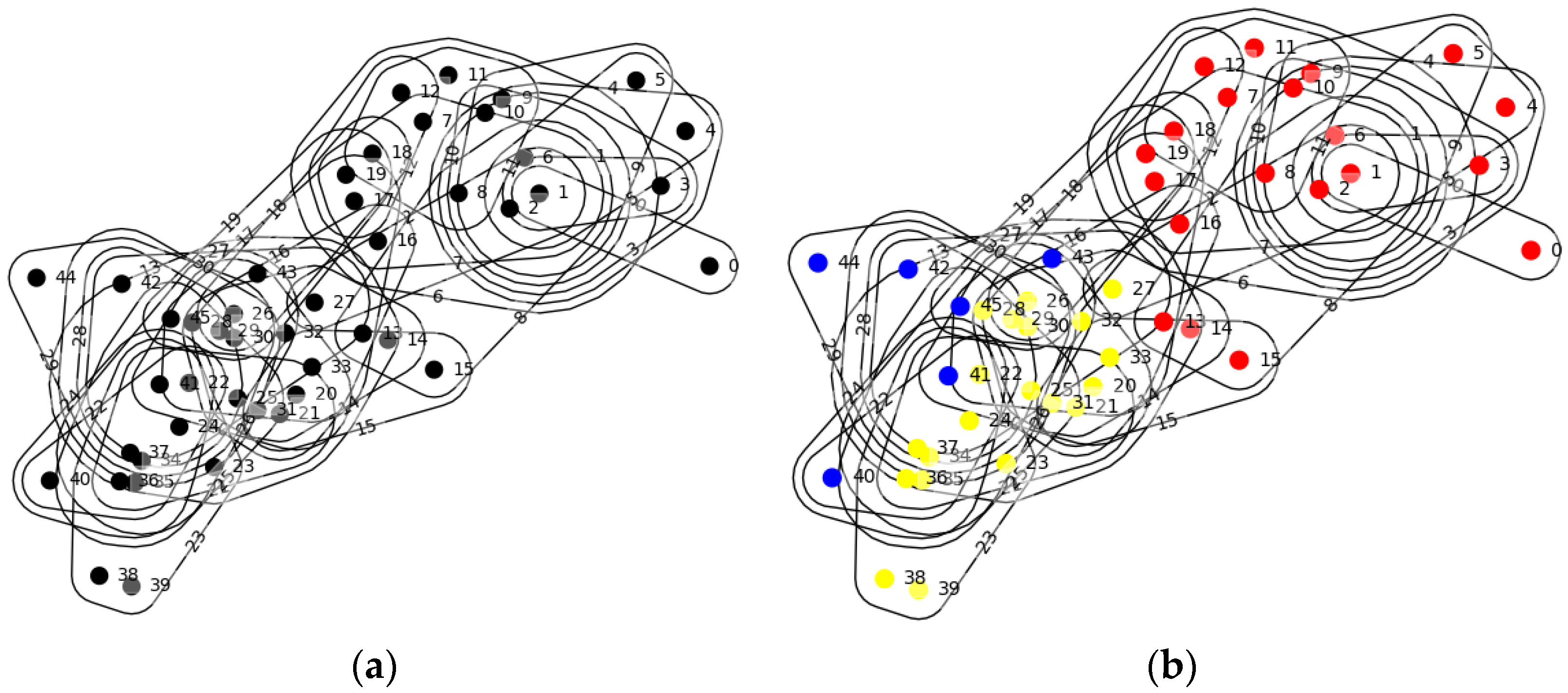
4.3. Southern Women Hypernetwork
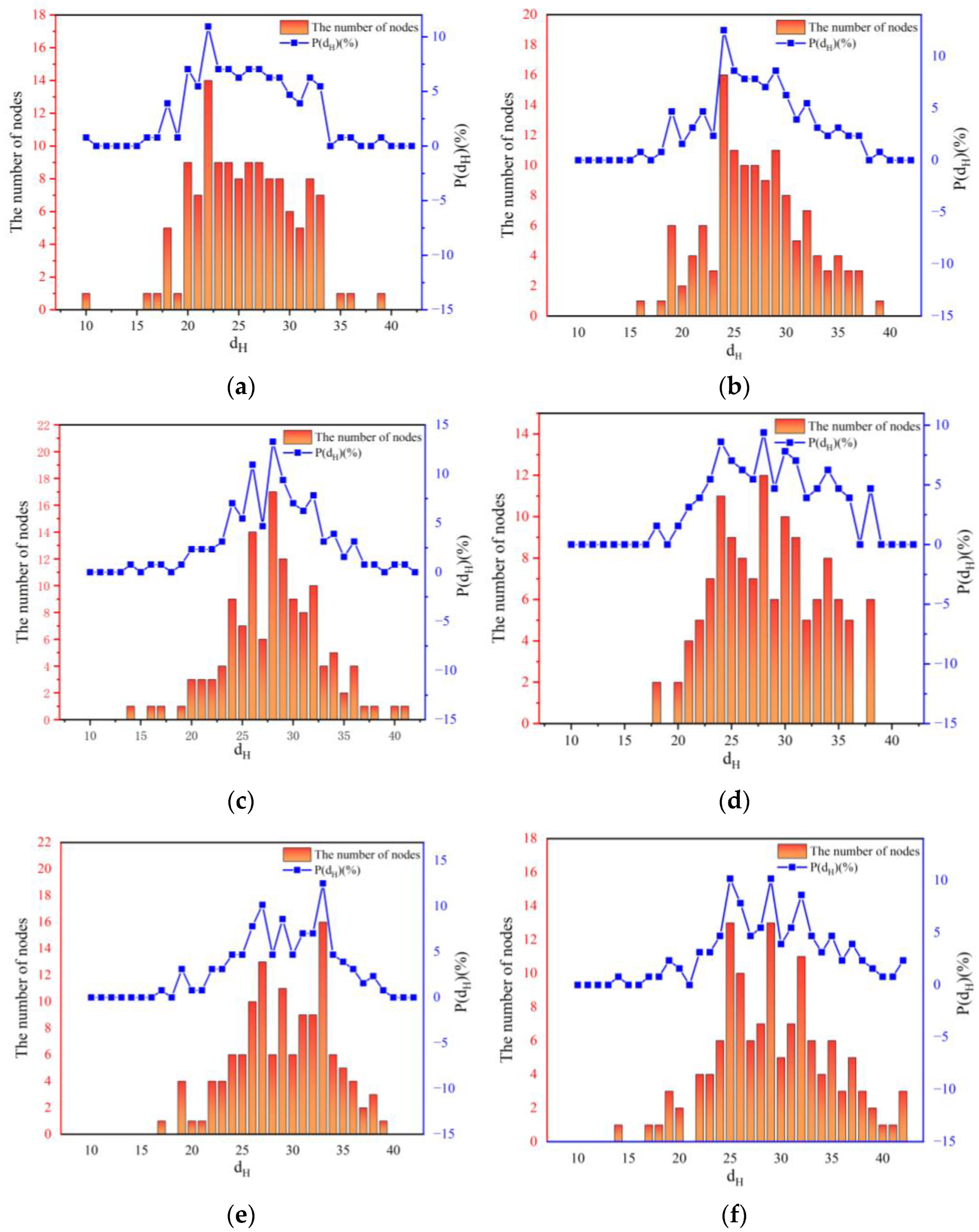
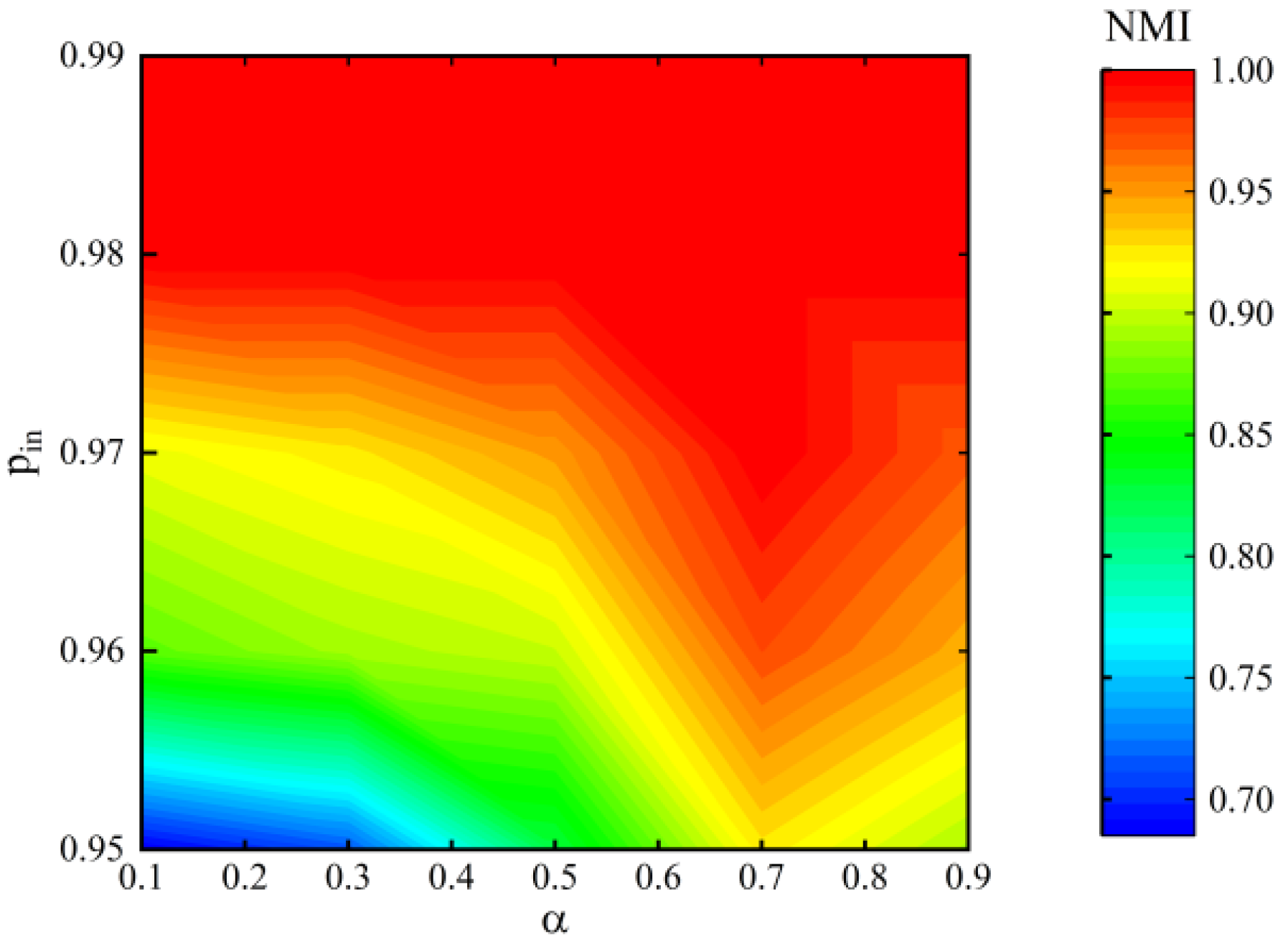
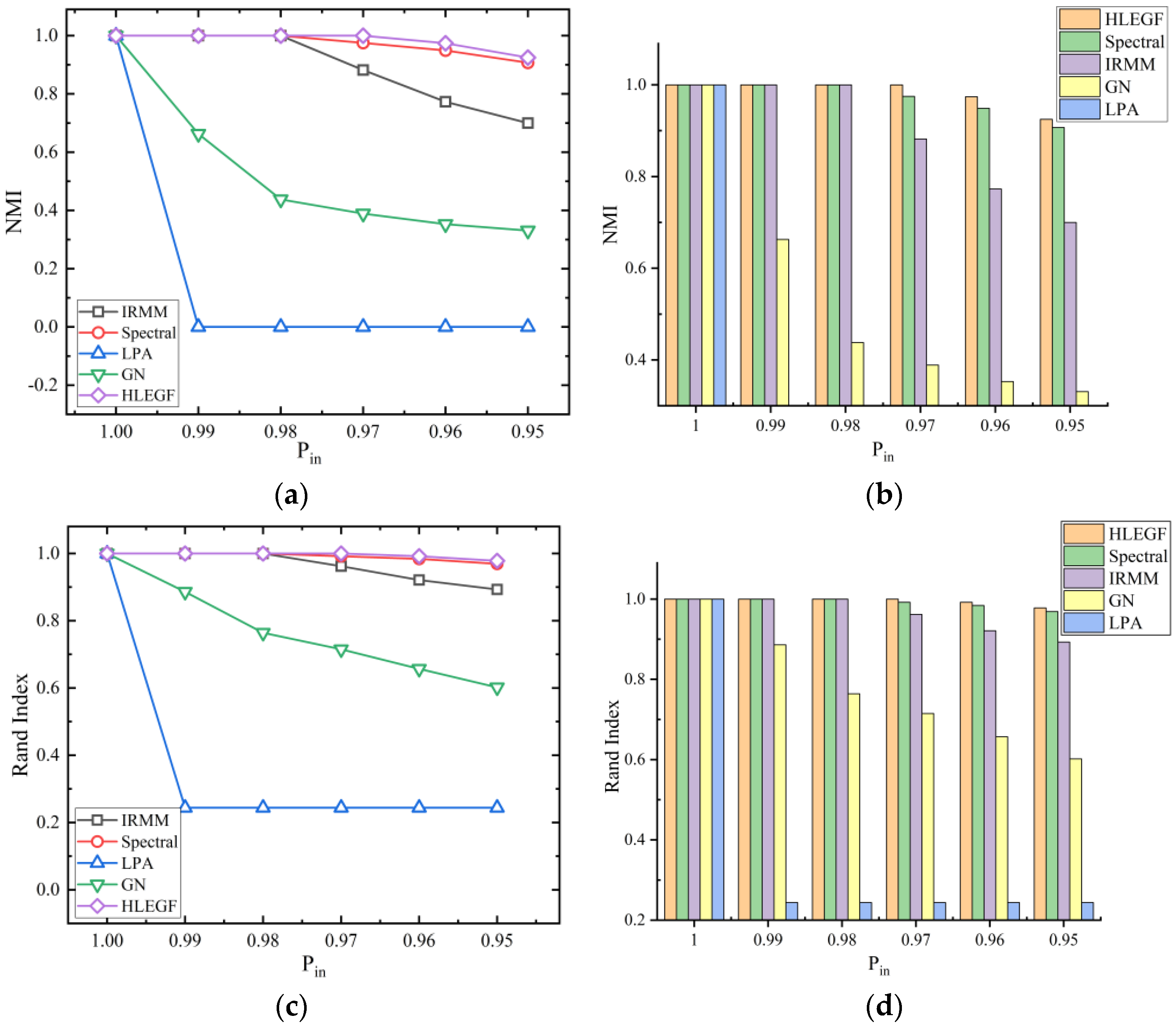
4.4. Random Hypernetwork
4.5. Drug–Targets Hypernetwork
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, S.; Zeng, Z.; Ota, K.; Dong, M.; Wang, T.; Xiong, N.N. An intelligent collaboration trust interconnections system for mobile information control in ubiquitous 5G networks. IEEE Trans. Netw. Sci. Eng. 2020, 8, 347–365. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Estrada, E.; Rodríguez-Velázquez, J.A. Subgraph centrality and clustering in complex hyper-networks. Physica A 2006, 364, 581–594. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Zhao, H.X.; He, J.B.; Li, F.X.; Li, S.L.; Zhang, Z.K. An evolving model for hypergraph-structure-based scientific collaboration networks. Acta Phys. Sin. 2013, 62, 198901. [Google Scholar]
- Irving, D.; Sorrentino, F. Synchronization of dynamical hypernetworks: Dimensionality reduction through simultaneous block-diagonalization of matrices. Phys. Rev. E 2012, 86, 056102. [Google Scholar] [CrossRef] [Green Version]
- Sorrentino, F. Synchronization of hypernetworks of coupled dynamical systems. New J. Phys. 2012, 14, 033035. [Google Scholar] [CrossRef] [Green Version]
- Ghoshal, G.; Zlatić, V.; Caldarelli, G.; Newman, M.E. Random hypergraphs and their applications. Phys. Rev. E 2009, 79, 066118. [Google Scholar] [CrossRef] [Green Version]
- Zlatić, V.; Ghoshal, G.; Caldarelli, G. Hypergraph topological quantities for tagged social networks. Phys. Rev. E 2009, 80, 036118. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Q.; Liu, Z.; Huang, J.; Cheng, G. Community detection in hypernetwork via density-ordered tree partition. Appl. Math. Comput. 2016, 276, 384–393. [Google Scholar] [CrossRef]
- Kamiński, B.; Prałat, P.; Théberge, F. Community detection algorithm using hypergraph modularity. In Proceedings of the International Conference on Complex Networks and Their Applications, Madrid, Spain, 1–3 December 2020; pp. 152–163. [Google Scholar]
- Chodrow, P.S.; Veldt, N.; Benson, A.R. Generative hypergraph clustering: From blockmodels to modularity. Sci Adv. 2021, 7, eabh1303. [Google Scholar] [CrossRef]
- Larremore, D.B.; Clauset, A.; Jacobs, A.Z. Efficiently inferring community structure in bipartite networks. Phys. Rev. E 2014, 90, 012805. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Kwong, S.; Zhou, Y.; Jia, Y.; Gao, W. Nonnegative matrix factorization with mixed hypergraph regularization for community detection. Inf. Sci. 2018, 435, 263–281. [Google Scholar] [CrossRef]
- Carletti, T.; Fanelli, D.; Lambiotte, R. Random walks and community detection in hypergraphs. J. Phys. Complex. 2021, 2, 015011. [Google Scholar] [CrossRef]
- Eriksson, A.; Carletti, T.; Lambiotte, R.; Rojas, A.; Rosvall, M. Flow-Based Community Detection in Hypergraphs. In Higher-Order Systems; Springer International Publishing: Berlin, Germany, 2022; pp. 141–161. [Google Scholar]
- Benson, A.R.; Abebe, R.; Schaub, M.T.; Jadbabaie, A.; Kleinberg, J. Simplicial closure and higher-order link prediction. Proc. Natl. Acad. Sci. USA 2018, 115, E11221–E11230. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Xiong, N.; Chong, N.Y.; Defago, X. A decentralized and adaptive flocking algorithm for autonomous mobile robots. In Proceedings of the 3rd International Conference on Grid and Pervasive Computing, Kunming, China, 25–28 May 2008. [Google Scholar]
- Ding, X.; Zhang, J.; Yang, J. Node-community membership diversifies community structures: An overlapping community detection algorithm based on local expansion and boundary re-checking. Knowl. Based. Syst. 2020, 198, 105935. [Google Scholar] [CrossRef]
- Chhabra, A.; Faraj, M.F.; Schulz, C. Local motif clustering via (hyper) graph partitioning. In Proceedings of the 2023 Symposium on Algorithm Engineering and Experiments (ALENEX), Florence, Italy, 22–23 January 2023. [Google Scholar]
- Guo, K.; He, L.; Chen, Y.; Guo, W.; Zheng, J. A local community detection algorithm based on internal force between nodes. Appl. Intell. 2020, 50, 328–340. [Google Scholar] [CrossRef]
- Ma, H.S.; Li, S.C.; Jian, Z.J.; Kuo, Y.H.; Huang, J.W. Local Community Detection by Local Structure Expansion and Exploring the Local Communities for Target Nodes in Complex Networks. J. Inf. Sci. Eng. 2021, 37, 499–515. [Google Scholar]
- Ding, X.; Zhang, J.; Yang, J. A robust two-stage algorithm for local community detection. Knowl. Based. Syst. 2018, 152, 188–199. [Google Scholar] [CrossRef]
- Ahn, S.; Couture, S.V.; Cuzzocrea, A.; Dam, K.; Grasso, G.M.; Leung, C.K.; McCormick, K.L.; Wodi, B.H. A fuzzy logic based machine learning tool for supporting big data business analytics in complex artificial intelligence environments. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems, New Orleans, LO, USA, 23–26 June 2019; pp. 1–6. [Google Scholar]
- Guo, W.; Wang, Y.; Gan, Y.; Lu, T. Energy efficient and reliable routing in wireless body area networks based on reinforcement learning and fuzzy logic. Wirel. Netw. 2022, 28, 2669–2693. [Google Scholar] [CrossRef]
- Behera, S.K.; Jena, L.; Rath, A.K.; Sethy, P.K. Disease classification and grading of orange using machine learning and fuzzy logic. In Proceedings of the 2018 International Conference on Communication and Signal Processing, Beijing, China, 12–16 August 2018; pp. 678–682. [Google Scholar]
- Boccaletti, S.; Lellis, D.P.; Genio, C.I.; Alfaro-Bittner, K.; Criado, R.; Jalan, S.; Romance, M. The structure and dynamics of networks with higher order interactions. Phys. Rep. 2023, 1018, 1–64. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, A.; Gardner, B.B.; Gardner, M.R. Deep South: A Social Anthropological Study of Caste and Class; University of Chicago Press: Chicago, IL, USA, 2022. [Google Scholar]
- Kumar, T.; Vaidyanathan, S.; Ananthapadmanabhan, H.; Parthasarathy, S.; Ravindran, B. Hypergraph clustering by iteratively reweighted modularity maximization. Appl. Netw. Sci. 2020, 5, 52. [Google Scholar] [CrossRef]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. In Advances in Neural Information Processing Systems 19; MIT Press: Cambridge, MA, USA, 2007; pp. 1601–1608. [Google Scholar]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Date Sources |
|---|---|
| Southern Women Hypernetwork | https://rdrr.io/cran/latentnet/man/davis.html, accessed on 1 December 2022 |
| Random Hypernetwork | https://doi.org/10.1016/j.amc.2015.12.039, accessed on 1 March 2023 |
| Drug-Targets Hypernetwork | https://go.drugbank.com, accessed on 1 February 2022 |
| Algorithm | Final Communities | Rand Index |
|---|---|---|
| LPA | {1–18} | 0.471 |
| GN | {1–18} | 0.471 |
| IRMM | {1–7, 9}, {8, 10–18} | 0.889 |
| Spectral | {1–9}, {10–18} | 1 |
| HLEGF | {1–9}, {10–18} | 1 |
| Ground truth | {1–9}, {10–18} | 1 |
| Node Number | Drug Number | Drug Name | Hyperedge Number | Target Number | Target Name |
|---|---|---|---|---|---|
| 0 | DB00002 | Cetuximab | 0 | P02746 | C1QB_HUMAN |
| 1 | DB14530 | Chromous sulfate | 1 | P29372 | 3MG_HUMAN |
| 2 | DB06404 | Human C1-esterase inhibitor | 2 | P23415 | GLRA1_HUMAN |
| 3 | DB00515 | Cisplatin | 3 | P04731 | MT1A_HUMAN |
| 4 | DB08888 | Ocriplasmin | 4 | P01023 | A2MG_HUMAN |
| ... | ... | ... | ... | ... | |
| 45 | DB01346 | Quinidine barbiturate | 30 | Q01668 | CAC1D_HUMAN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Hu, F.; Chen, R.; Xiong, N. HLEGF: An Effective Hypernetwork Community Detection Algorithm Based on Local Expansion and Global Fusion. Mathematics 2023, 11, 3497. https://doi.org/10.3390/math11163497
Wang F, Hu F, Chen R, Xiong N. HLEGF: An Effective Hypernetwork Community Detection Algorithm Based on Local Expansion and Global Fusion. Mathematics. 2023; 11(16):3497. https://doi.org/10.3390/math11163497
Chicago/Turabian StyleWang, Feng, Feng Hu, Rumeng Chen, and Naixue Xiong. 2023. "HLEGF: An Effective Hypernetwork Community Detection Algorithm Based on Local Expansion and Global Fusion" Mathematics 11, no. 16: 3497. https://doi.org/10.3390/math11163497