1. Introduction
Over the decades, Natural Language Processing (NLP) has become an important field of research with an aim to improve the ability of computer systems to generate and understand human language [
1]. The recent advancements in this field have led to the development of a large language model that exploits Machine Learning (ML) algorithms to generate humanlike language and learn from a humongous volume of textual data [
2]. The Generative Pretrained Transformer (GPT) series, introduced by OpenAI, has received considerable attention in natural language processing [
3]. The advancement of ChatGPT marks a crucial milestone in the field of NLP as it signifies a considerable step toward the construction of sophisticated and state-of-the-art computer systems and it also has the potential to understand and generate natural languages [
4]. Furthermore, it generates prompt responses that are not only contextually appropriate but also coherent in nature, and it is also trained using massive amounts of text data. The capacity of a model to generate text that is similar to human language has a major impact on communication, education, and language learning areas. The large language model that is currently popular, i.e., the ChatGPT system, represents considerable progress in the domain of NLP. BERT, coined by Google, is another significant example of a large language model [
5]. Similar to ChatGPT, BERT can also be finetuned for NLP tasks that involve language translation, Sentimental Analysis (SA), and question–answer tasks and is pretrained using an enormous amount of text data. Though the systems vary in their model architecture and pretraining model, the core functionality of ChatGPT and BERT remains the same [
6]. The advancement of such large language models helps in revolutionizing several industries that involve communication, education, and healthcare by allowing natural and more sophisticated interactions between machines and humans [
7].
However, the highly prevalent adoption of revolutionary AI-based chatbots including ChatGPT highlights the importance of the capability to recognize whether a text has been written by human being or by AI [
8]. This may have serious implications in different fields that involve digital forensics and information security [
9]. For example, in the information security domain, the capability of identifying AI-generated text is essential both to detect and to protect against the malicious usage of AI, namely social engineering attacks or the spread of misinformation and disinformation. To ensure the accuracy and trustworthiness of the data [
10], it is crucial to develop techniques to identify AI-generated texts. This is crucial because such techniques must be utilized in sensitive fields such as finance and banking, political campaigns, customer reviews, and legal documents (customer reviews of movies, restaurants, or products).
In this background, the current study presents the Tunicate Swarm Algorithm with Long Short-Term Memory Recurrent Neural Network (TSA-LSTMRNN) model to detect both human- and ChatGPT-generated text. The purpose of the proposed TSA-LSTMRNN method is to investigate the model’s decision and identify the presence of any particular pattern. In addition to these, the TSA-LSTMRNN technique focuses on designing TF-IDF, word embedding, and count vectorizers for the purpose of feature extraction. For the detection and classification processes, the LSTMRNN model is used. Finally, the TSA is exploited for selecting the parameters for the LSTMRNN approach, which helps in attaining improved detection performance. The simulation performance of the proposed TSA-LSTMRNN technique was investigated using the benchmark datasets.
The rest of the paper is organized as follows.
Section 2 provides information regarding related works, and
Section 3 provides details about the proposed model. Then,
Section 4 presents the analytical results, and
Section 5 concludes the paper.
2. Related Works
Yu et al. [
11] presented a large-scale CHatGPT-writtEn AbsTract dataset (CHEAT) to assist in the advancement of the recognition methods and inspect the possible negative effect of ChatGPT on academia. To be specific, the ChatGPT-written abstract data had a total of 35,304 synthetic abstracts, with Mix, Generation, and Polish as eminent representatives. Liao et al. [
12] presented an ethical AIGC (Artificial Intelligence Generated Content) system in the healthcare sector. In this study, the authors mainly focused on examining the variances between medical texts generated by ChatGPT and those written by human experts. Further, the study also devised ML workflows to potentially distinguish and find medical texts generated by ChatGPT. At first, the authors built a set of datasets with one containing medical texts generated by ChatGPT and another one written by human experts. Eventually, the authors applied and devised ML approaches to ascertain the origin of the generated medical text.
Alamleh et al. [
13] evaluated the performance of ML methods in distinguishing AI-generated text from human-written text. To achieve this objective, the authors gathered responses from computer science students to essay and programming assignments. Then, based on the data, the authors evaluated and trained numerous ML methods such as SVM, LR, NN, RF, and DT. Chen et al. [
14] introduced an innovative method to differentiate human-written and ChatGPT-generated texts with the help of language methods. The authors gathered and released the preprocessed data called OpenGPTText, which contained rephrased content generated utilizing ChatGPT. Pardos and Bhandari [
15] conducted an initial learning gain assessment of ChatGPT by comparing the efficiency of its hints to hints presented by human tutors on two different algebra topics such as intermediate and elementary algebra. Hamed and Yu [
16] displayed how to differentiate ChatGPT-generated publications from their counterparts written by the researchers. By devising a supervised ML approach, the authors demonstrated how to differentiate machine-generated articles from scientist-created articles. The authors developed an algorithmic method that identified the ChatGPT-generated publication with a high precision.
Perkins et al. [
17] explored the academic integrity considerations of students using AI tools, in addition to the Large Language Model (LLM), namely ChatGPT, in formal assessment. The authors evaluated the development of these tools and highlighted the possible ways in which the LLM supports the education of students in digital writing including composition and teaching of writing, the possibilities of co-creation between AI and the humans, enhancing Automated Writing Evaluation (AWE), and supporting EFL learners. Maddigan and Susnjak [
18] presented a new system called Chat2VIS, which makes the maximum use of LLMs and illustrates how the complicated issue of language understanding can be resolved with high potential for prompt engineering, and it results in simple and precise end-wise solutions compared to the existing methods. Based on the prompts presented, Chat2VIS displays that the LLM presents a dependable method for rendering visualizations from natural language questions, even if the queries were underspecified and highly misspecified.
Only a limited number of studies are available in the literature related to the ChatGPT-generated text detection process. Therefore, there exists a need to improve the detection results for ChatGPT-generated texts. Due to a continuous deepening of the model, the number of parameters involved in DL models also increases quickly, which results in model overfitting. At the same time, different hyperparameters have significant impact on the efficiency of the CNN model. Particularly, hyperparameters such as epoch count, batch size, and learning rate selection are essential to attain effectual outcomes. Since the trial-and-error method for hyperparameter tuning is a tedious and an erroneous process, metaheuristic algorithms are applied. Therefore, in this work, the authors employed the TSA for parameter selection of the LSTMRNN model.
3. The Proposed Model
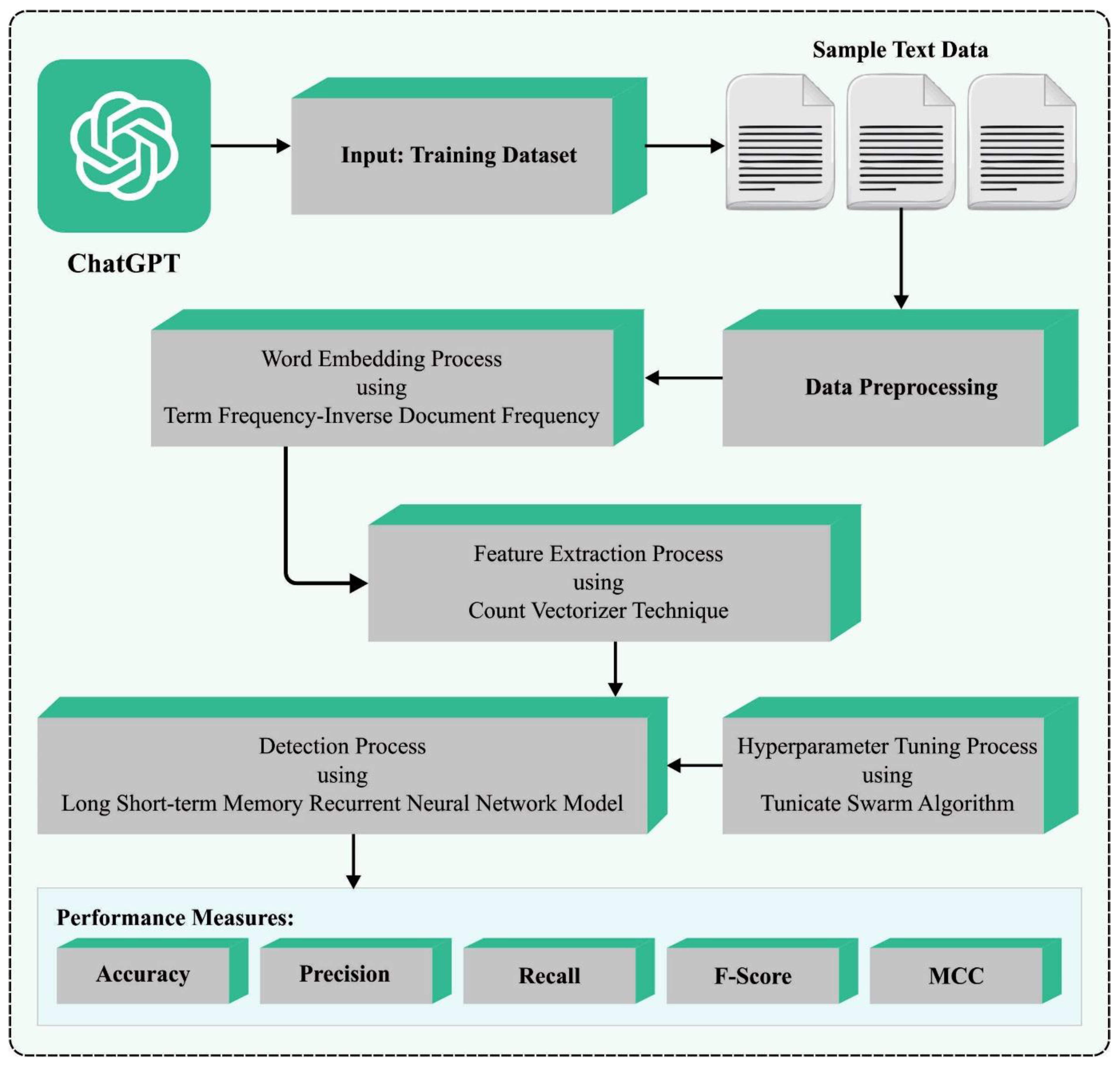
In the current research paper, the authors established an automated human-generated text and ChatGPT-generated text detection model, named the TSA-LSTMRNN model. The objective of the proposed TSA-LSTMRNN technique is to investigate the model’s decision and compute whether any particular pattern can be detected. The model has three stages, namely feature extraction, LSTMRNN classification, and TSA-based parameter tuning.
Figure 1 represents the overall flow of the TSA-LSTMRNN approach.
3.1. Feature Extraction
In this study, TF-IDF is used for the word embedding process, whereas the count vectorizer algorithm is utilized for feature extraction. In data mining, feature extraction is a procedure that contains steps to reduce the data count and make it accessible so as to define huge databases. When it comes to analyzing the mood of a difficult text, the main problem arises from the presence of numerous variables. Generally, to analyze a difficult or huge text, large amounts of memory and processing power are required. This results in the use of the classifier technique, which is more appropriate for trained instances and leads to worse generalizations for novel instances. The researchers mentioned that, in applications containing several features, extraction is the same process as dimensionality reduction. When feature extraction systems are applied to the input data before they are passed onto the classifier system, it is possible to achieve refined outcomes and high classification method accuracy.
In the literature, the count vectorizer feature extraction method has been utilized to cover tweets based on frequent words (count) that occurs in the tweets. Such tweets are then converted into a vector space [
19]. A column matrix denotes the count vectorizer that generates a word matrix, whereas a row matrix corresponds to the text selected from the document. Thereby, the word in that specific text instance is counted. The TF-IDF has a weighted feature for execution boosting and was used for tweet analysis in that study. Here, the length defines the TF of a feature in a single document.
Here,
represents the amount of TF
in document
and
denotes the total amount of terms present in the document. IDF considers that when the text increases in terms of
, it would be highly informative for training the model.
In Equation (2),
denotes the overall number of documents and
shows the number of documents including the
phrase. Once the term
often appears in various documents, the IDF calculates the weight of the phrase
as low. For instance, a stop word has lower IDF values. Lastly, the TF-IDF is determined as follows:
Also, the current study used the word embedding method for feature extraction, namely Glove, pretrained model, FastText, and Word2Vec embedding with 300-D vectors.
3.2. Detection Model Using LSTMRNN
This stage aims to search a DL structure that contains attention layers so as to understand the detection process of human- and ChatGPT-generated texts. Therefore, in the presented LSTMRNN structure, many other processing stages are also involved. The primary one is the convolution of features [
20]. The initial step is used for the extraction of high-level semantic features in word sequences. The LSTMRNN approach also determines the temporal connection among the features and creates the feature vectors.
Furthermore, the semantic meaning of the input text is assumed, and the secondary label sets are created with values allocated to individual data. The RNN approach proceeds with a series of pixels such as
creating Hidden Layers (HLs)
and outcome layers
in a subsequent manner.
At this point, signifies the vector in the hidden unit and the output unit stands for the hidden unit for the pixel series, refers to the weighted vector in the hidden unit to for the sequence time , and and refer to the biases.
Additionally, the LSTM stack is utilized to learn the time series features. On the other hand, the model acquires the issues contained in a single sequence of observation. The method must learn the sequences of past observations to predict the next value in order as given below.
Here, stands for the input gate; implies the forecast from the initial layers; exemplifies the forget gate; offers the data on output; denote the bias vectors; shows the cell state; and implies the weighted matrix. Either the RNN or the LSTM approach is integrated to extract the semantic features in the input tweets.
To be specific, it executes the attention layer so as to enhance the learning of the features as well as the feature weights. The LSTMRNN approach has been utilized to learn a series of sentences and create the weighted features through the attention procedure. Additionally, it also utilizes the secondary labels integrated with the LSTMRNN approach to assist in enhancing the areas of interest from the learning procedure. Therefore,
denotes the input,
denotes the features created in the second layer, and
corresponds to the
layer. The feature value refers to the responses of multi-scale
-grams, for example, unigram
, bigram
, and
-gram
. Moreover, the scale reweighting is utilized to compute the SoftMax distribution of attention weights in which the descriptor is utilized as the dataset and the output weighted element weights are to be reweighed.
In the presented method, the novelty lies in the development of the weighted features by utilizing the attention layer procedure. The presented method recovers the text information in a series mapped by LSTMRNN, whereas the LSTM creates a series of annotations for every input. The vectors utilized are the concatenation of the HLs from the encoded layers. Afterward, the features can be developed using the attention layer model. At the time of the training process, every sample from the training data is passed on to the LSTMRNN approach one time step at a time. The LSTM units process the input, update their internal states, and produce an output at each time step. Then, the outputs are typically used to make the prediction process.
3.3. Hyperparameter Tuning Using TSA
In the current study, the TSA is used to improve the parameter selection process for the LSTMRNN model. The TSA is an optimization technique that is based on the biological behavior of animals, i.e., the foraging behavior of tunicates, marine invertebrates that radiate brighter bioluminescence [
21]. In particular, the TSA draws its motivation from a peculiar behavior of the tunicates in the ocean, i.e., their jet drive and the swarm intelligence of the foraging processes. Under three major constraints, the mathematical modeling of jet propulsion is proposed: following the position of the best agent, preventing conflicts amongst the exploration agents, and remaining near the optimum agents.
Figure 2 depicts the flowchart of the TSA.
To prevent conflicts when finding the best location, the new location of the search agent is evaluated as given below.
Let
be the vector of a new position of the search agent;
refers to the water flow in the ocean;
indicates the gravity force; and
and
denote three randomly generated numbers. The social forces between the agents are kept in a new vector
as given below.
In Equation (18), and correspondingly describe the first and second subordinates, which demonstrate the speed of establishing a social interaction.
It is crucial to follow the present optimum agent in order to gain a better solution. Therefore, after ensuring that no conflicts are present between the neighboring agents in a swarm, the fittest location of the optimum agent is measured as given below.
In Equation (19), denotes the length between a better agent and the food origin, denotes a stochastic value within , shows the optimal location, and the vector has the position of the tunicates at iteration .
In order to ensure that the search agent is still closer to the optimal agent, their locations are calculated using Equation (20):
In Equation (20), indicates the upgraded position of the agents at iteration with respect to the better-scored location
The location of the existing agent is updated based on the position of two agents so as to model the swarming behaviors of the tunicates.
The following steps demonstrate the flow of the original TSA approach:
Step 1: Initialize the population of tunicates
Step 2: Set the maximum number of iterations and the original value for the parameter.
Step 3: Evaluate the fitness value of the exploration agents
Step 4: Explore a better agent in the search space.
Step 5: Upgrade the position of the exploration agent based on Equation (21).
Step 6: Return the newly updated agent to its boundaries.
Step 7: Measure the fitness cost of the updated search agents. In case of a solution superior to the prior solution, update and keep the better solution in Xbest.
Step 8: End the process if the terminating condition is satisfied. Or else, return to steps 5–8.
Step 9: Return the better solution (Xbest).
Fitness choice is a key aspect of the TSA algorithm. An encoded outcome is employed herewith to determine the goodness of a candidate’s performance. At present, the accuracy value is the major condition employed to plan an FF.
Here, and denote true and false positive values, respectively.
4. Results and Discussion
In this section, the results attained from the experimental investigation of the proposed TSA-LSTMRNN approach on human-generated text dataset and ChatGPT-generated text dataset are discussed. The approach was analyzed experimentally under a set of five experiments. Each experiment included a sample set comprising human-generated text and ChatGPT-generated text. The sample texts are given below.
Sample 1:
Sample 2:
Human-generated text: Point your finger at any item on the menu, order it and you won’t be disappointed.
ChatGPT-generated text: No matter what you order from the menu, you won’t be disappointed.
Sample 3:
Sample 4:
Human-generated text: I believe that this place is a great stop for those with a huge belly and hankering for sushi.
ChatGPT-generated text: I believe this place is a great stop for those with a big appetite and a desire for sushi.
Sample 5:
Human-generated text: It was a truly special dining experience that exceeded all of my expectations.
ChatGPT-generated text: I had a great experience at this restaurant and the services are beyond expectations.
The current study used a set of measures to examine the classification outcomes such as accuracy (), precision (), recall (), Mathew Correlation Coefficient (MCC), and F-score ().
Precision measures the proportion of the correctly predicted positive instances of the overall instances that were predicted as positive.
Recall measures the proportion of the positive samples that were correctly classified.
Accuracy measures the proportion of the correctly classified samples (positives and negatives) against the total number of samples (number of samples that were classified).
F-score is a measure that combines the harmonic mean of the precision and recall measures.
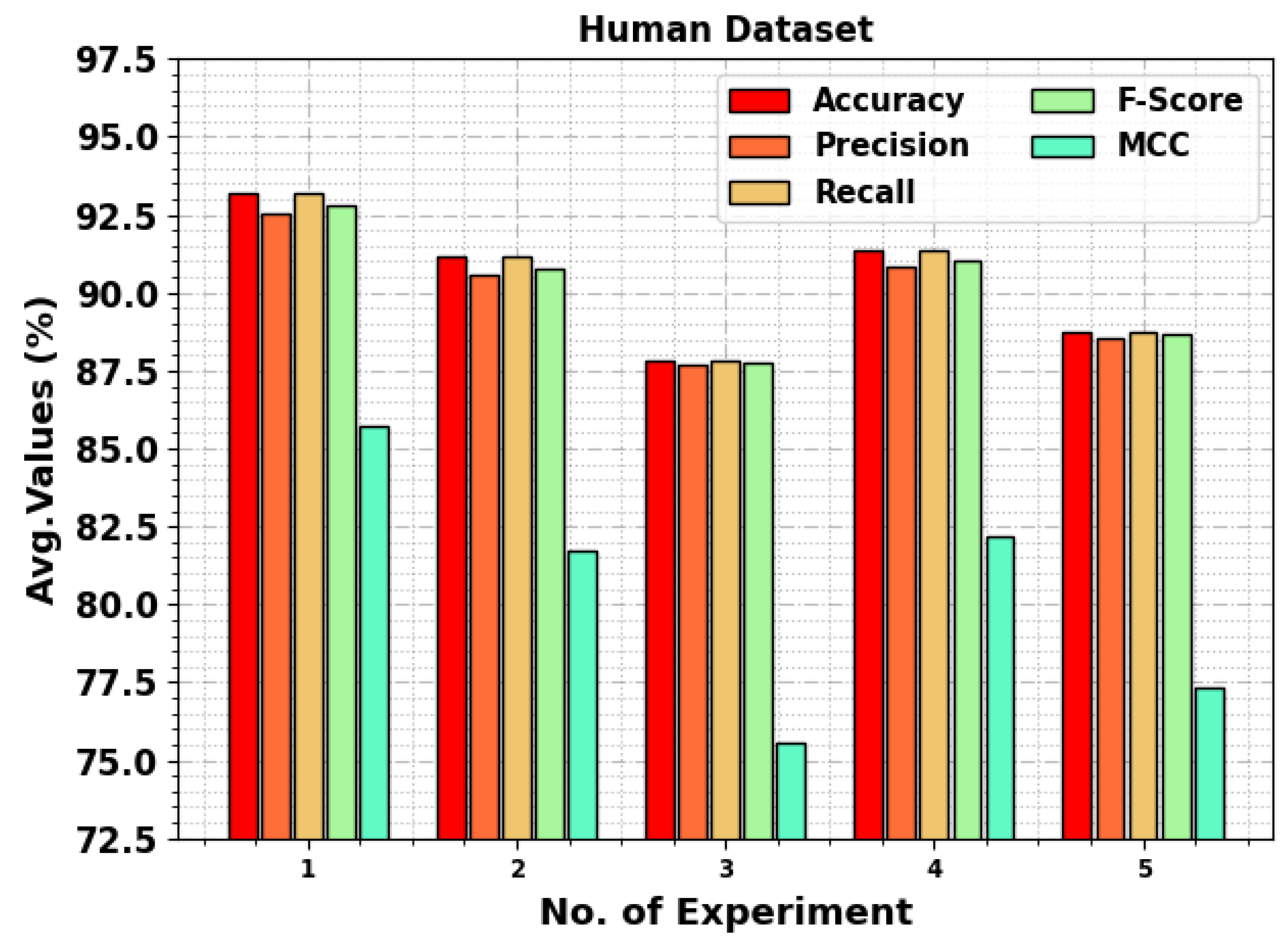
In
Table 1 and
Figure 3, the detection outcomes of the proposed TSA-LSTMRNN technique on the human-generated text dataset are provided. The results indicate that the proposed approach appropriately recognized the human-generated text dataset as positive and negative samples. For instance, in experiment 1, the TSA-LSTMRNN technique attained average
,
,
,
, and MCC values of 93.17%, 92.56%, 93.17%, 92.77%, and 85.72%, respectively. Furthermore, in experiment 2, the TSA-LSTMRNN method reached average
,
,
,
, and MCC values of 93.17%, 90.55%, 91.17%, 90.75%, and 87.71%, respectively. Moreover, in experiment 3, the proposed TSA-LSTMRNN algorithm accomplished average
,
,
,
, and MCC values of 87.83%, 87.71%, 87.83%, 87.77%, and 75.55%, correspondingly. Meanwhile, in experiment 4, the TSA-LSTMRNN system yielded average
,
,
,
, and MCC values of 91.33%, 90.83%, 91.33%, 91.02%, and 82.16%, respectively. Finally, in experiment 5, the TSA-LSTMRNN approach reached average
,
,
,
, and MCC values of 88.75%, 88.57%, 88.75%, 88.65%, and 77.32%, correspondingly.
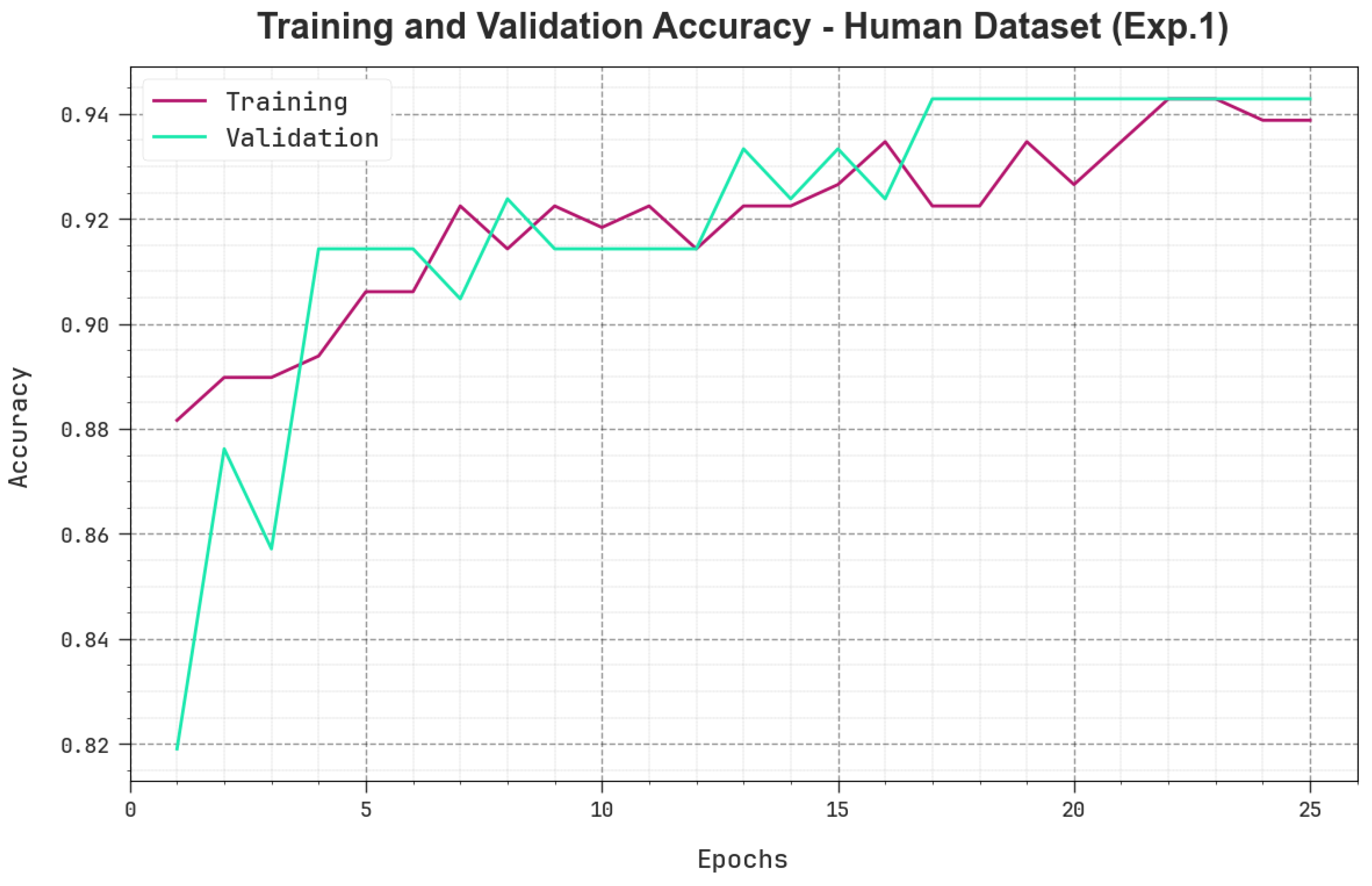
Figure 4 showcases the
values accomplished by the proposed TSA-LSTMRNN technique in training and validation methods on human-generated text database. The results indicate that the TSA-LSTMRNN technique achieved high
values over higher epochs. Also, a maximum validation
that was greater than the training
was achieved, which exhibits that the TSA-LSTMRNN technique establishes its capability on human-generated text databases.
A loss study was conducted for the proposed TSA-LSTMRNN system at the time of training and validation upon the human-generated text database, and the results are revealed in
Figure 5. The results point out that the TSA-LSTMRNN method achieved similar training and validation loss values. It can be understood that the TSA-LSTMRNN technique operates effectively on human-generated text databases.
A brief PR study was conducted on the TSA-LSTMRNN approach using the human-generated text database, and the results are shown in
Figure 6. The outcomes indicate that the TSA-LSTMRNN algorithm enhanced the PR values. In addition to this, it is noticeable that the TSA-LSTMRNN technique can gain superior PR values in both the classes.
Figure 7 shows the results of the ROC analysis accomplished using the TSA-LSTMRNN technique on the human-generated text database. The results describe that the TSA-LSTMRNN approach enhanced the ROC values. Moreover, the TSA-LSTMRNN system extended the ROC values in both the class labels.
In
Table 2 and
Figure 8, the detection outcomes of the TSA-LSTMRNN method on ChatGPT-generated text dataset are provided. The outcomes point out that the proposed TSA-LSTMRNN method properly recognized both positive and negative instances in the ChatGPT-generated text dataset. For instance, in experiment 1, the TSA-LSTMRNN method accomplished average
,
,
,
, and MCC values of 78%, 81.51%, 78%, 78.65%, and 59.41%, correspondingly. Moreover, in experiment 2, the TSA-LSTMRNN technique attained average
,
,
,
, and MCC values of 82.17%, 83.96%, 82.17%, 82.70%, and 66.10%, respectively. Additionally, in experiment 3, the proposed TSA-LSTMRNN methodology achieved average
,
,
,
, and MCC values of 82.42%, 84.34%, 82.42%, 82.97%, and 66.73%, respectively. In the meantime, in experiment 4, the TSA-LSTMRNN system attained average
,
,
,
, and MCC values of 81.58%, 84.19%, 81.58%, 82.24%, and 65.73%, correspondingly. Lastly, in experiment 5, the TSA-LSTMRNN technique yielded average
,
,
,
, and MCC values of 93.83%, 94.52%, 93.83%, 94.12%, and 88.35%, correspondingly.
Figure 9 shows the
curve plotted on the values achieved by the TSA-LSTMRNN technique in both training and validation models using the ChatGPT-generated text database. The outcomes imply that the TSA-LSTMRNN technique attained improved
values over superior epochs. Additionally, the enhanced validation
value exceeded the training
value, indicating that the TSA-LSTMRNN methodology works effectively on the ChatGPT-generated text database.
The loss curve of the TSA-LSTMRNN system, at the time of training and validation, on the ChatGPT-generated text database, is shown in
Figure 10. The outcomes indicate that the TSA-LSTMRNN system realized adjacent training and validation loss values. Thus, it is obvious that the TSA-LSTMRNN system achieves capably on the ChatGPT-generated text database.
Figure 11 shows a brief PR curve of the TSA-LSTMRNN methodology upon the ChatGPT-generated text database. The results indicate that the TSA-LSTMRNN system affects superior values of PR. Afterward, it can be observed that the TSA-LSTMRNN technique obtained enhanced the PR values in both the class labels.
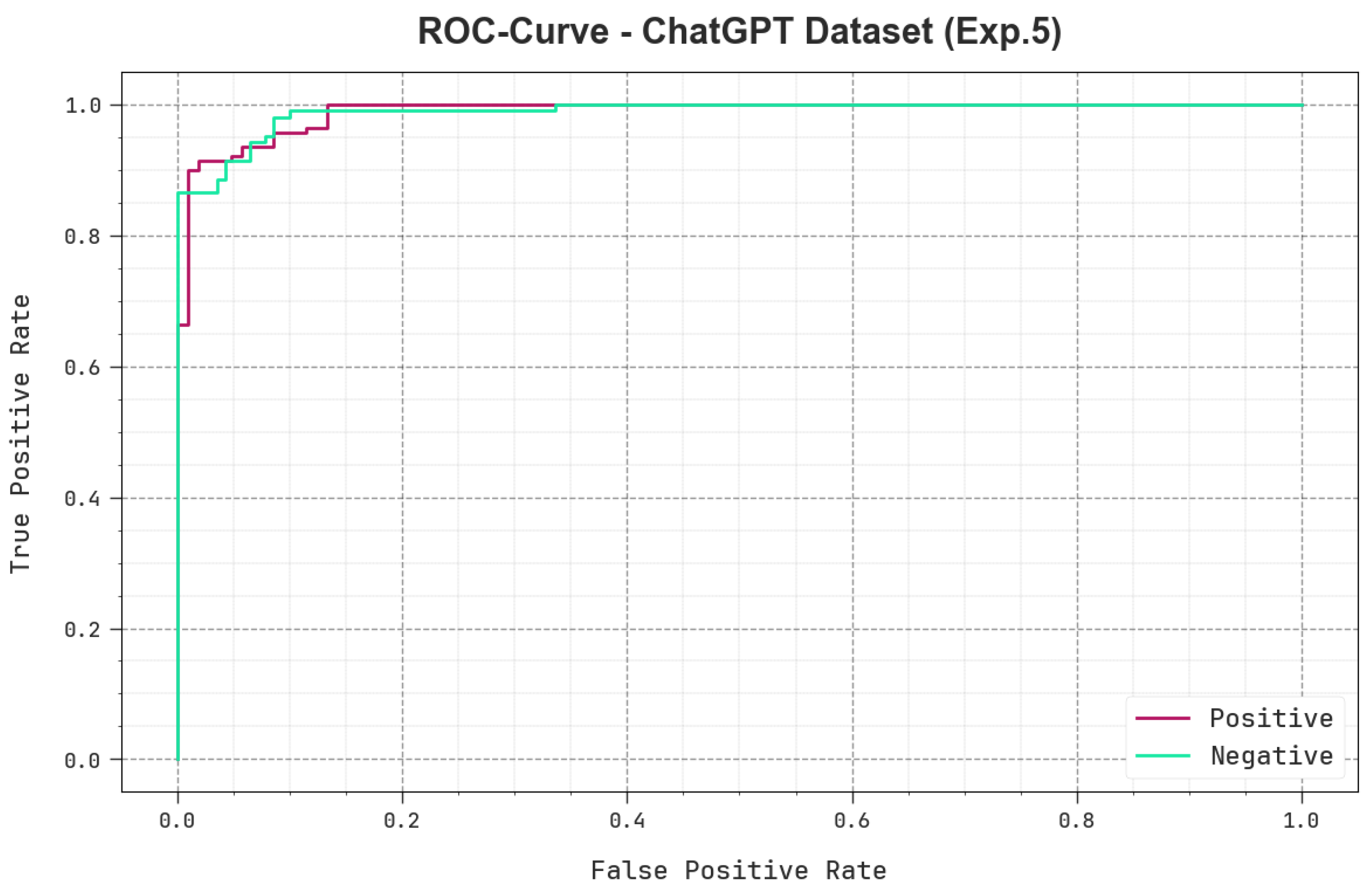
In
Figure 12, an ROC curve of the TSA-LSTMRNN technique is plotted for the ChatGPT-generated text database. The outcomes imply that the TSA-LSTMRNN approach accomplished higher ROC values. Moreover, it is clear that the TSA-LSTMRNN algorithm can yield higher ROC values in both the classes.
In
Table 3, the comprehensive comparison outcomes of the TSA-LSTMRNN system on both human-generated text dataset and the ChatGPT-generated text datasets are provided.
Figure 13 represents the classification outcomes achieved by the proposed TSA-LSTMRNN technique and other ML approaches on human-generated text datasets. The result indicates that both XGBoost and CNN methods obtained the least
values, i.e., 83.86% and 84.08%, correspondingly. Then, the DT and SVM models reported moderately improved
values of 86.70% and 86.72%, respectively. Although the ELM model produced a near-optimal
of 89.80%, the TSA-LSTMRNN algorithm established its supremacy with an increased
of 93.17%.
Figure 14 represents the classification results of the TSA-LSTMRNN approach and of other ML techniques on ChatGPT-generated text dataset. The outcome indicates that both SVM and XGBoost approaches produced the least
values, i.e., 82.30% and 84.96%, correspondingly, followed by the CNN and ELM approaches, which reported moderately improved
values of 86.93% and 86.34%, correspondingly. Though the DT approach accomplished a near-optimal
of 88.01%, the TSA-LSTMRNN method showed its supremacy with an improved
of 93.83%. These results highlight the significant performance of the proposed TSA-LSTMRNN technique.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}