

A Maximally Split and Adaptive Relaxed Alternating Direction Method of Multipliers for Regularized Extreme Learning Machines

Abstract
:1. Introduction
- (1)
- Improving Global Convergence: To improve the global convergence of the algorithm, a non-monotonic Wolfe-type strategy is introduced into the memory gradient method. The global optimal solution is achieved by combining the iteration information of current and past multiple function points.
- (2)
- Solving Sub-problem: To improve the convergence speed of the algorithm, the Barzilai–Borwein spectral gradient method is optimized by adding step-size selection constraints to simplify the computational complexity of the MS-RADMM sub-problems.
2. Fundamentals of the RELM and the ADMM
2.1. RELM Method
2.2. ADMM for Convex Optimization
3. Maximally Split and Adaptive Relaxed ADMM
3.1. Maximally Split and Relaxed ADMM
3.2. Scalars MS-ARADMM
3.2.1. Spectral Adaptive Step-Size Rule
3.2.2. Estimation of Step-Size
3.2.3. Parameter Update Rules
4. RELM Based on the Scalars MS-ARADMM
4.1. Scalars MS-RADMM for RELM
4.2. Learning Algorithm for MS-ARADMM-Based RELM
| Algorithm 1: MS-ARADMM-based RELM |
Data: the training dataset x, the number of hidden nodes L, regularization parameter , and the number of iterations I Result: the optimal output weight matrix
|
5. Simulation Experiment and Result Analysis
5.1. Performance Analysis of Adaptive Parameter Selection Methods
5.2. Convergence Analysis
5.2.1. Comparison of Convergence of MS-ARADMM and RB-ADMM
5.2.2. Comparison of Convergence of MS-ARADMM and MS-AADMM
5.2.3. Convergence Rate Comparison
5.3. Parallelism Analysis
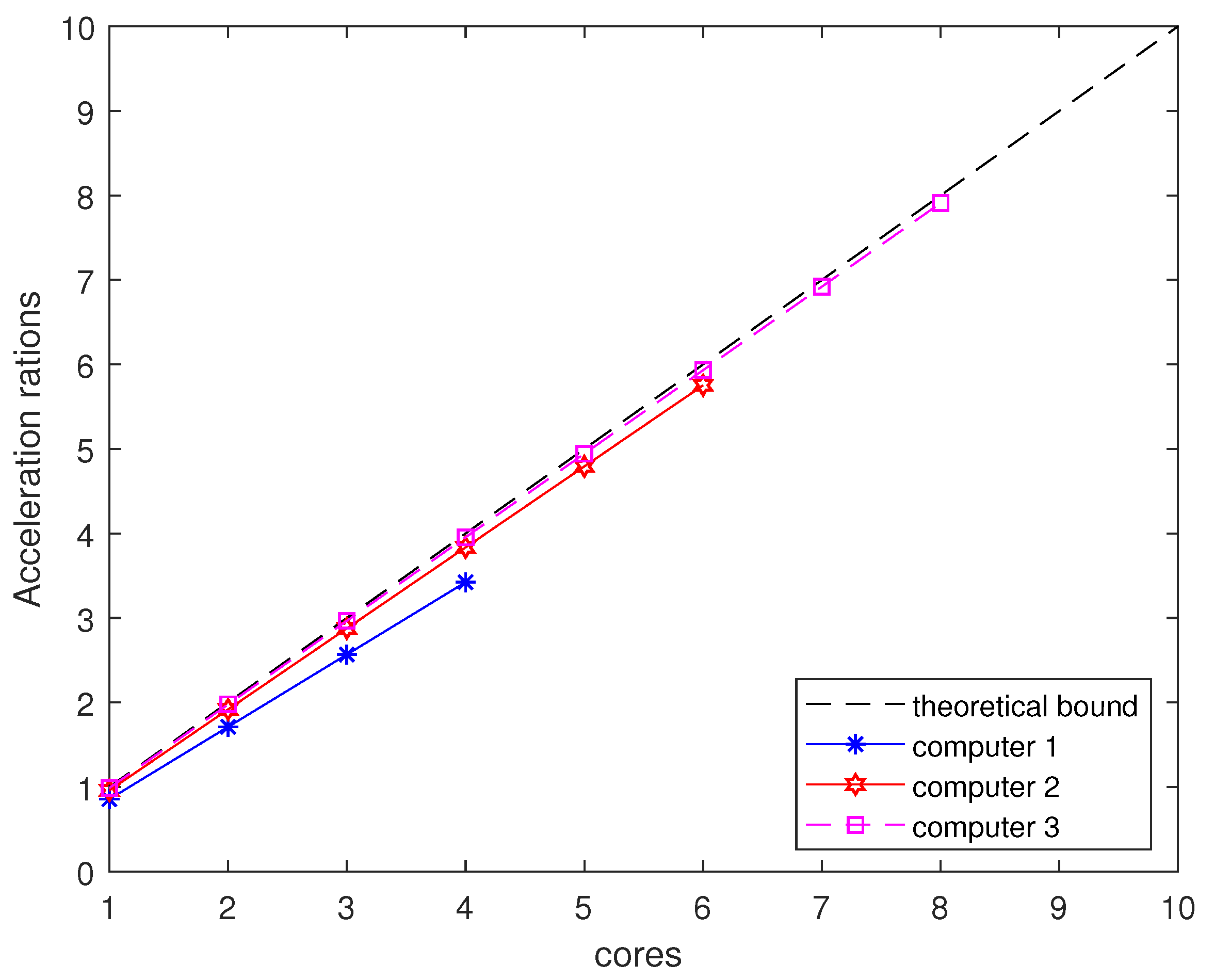
5.3.1. Parallel Implementation on Multicore Computers
5.3.2. Parallel Implementation on GPU
5.4. Accuracy Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.F.; Chen, B.D.; Wang, S.Y. Mixture Correntropy-Based Kernel Extreme Learning Machines. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 811–825. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Zheng, Q.; Chen, L. Regularized extreme learning machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Shi, X.; Kang, Q.; An, J. Novel L1 Regularized Extreme Learning Machine for Soft-Sensing of an Industrial Process. IEEE Trans. Ind. Inform. 2022, 18, 1009–1017. [Google Scholar] [CrossRef]
- Wang, Y.; Dou, Y.; Liu, X. PR-ELM: Parallel regularized extreme learning machine based on cluster. Neurocomputing 2016, 173, 1073–1081. [Google Scholar] [CrossRef]
- Liu, P.; Wang, X.; Huang, Y. Research on Parallelization of Extreme Learning Machine Algorithm Based on Spark. Comput. Sci. 2017, 44, 33–37. [Google Scholar]
- Chen, C.; Li, K.; Ouyang, A. GPU-accelerated parallel hierarchical extreme learning machine on Flink for big data. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2740–2753. [Google Scholar] [CrossRef]
- Duan, M.; Li, K.; Liao, X. A parallel multi classification algorithm for big data using an extreme learning machine. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2337–2351. [Google Scholar] [CrossRef]
- Nagata, T.; Nonomura, T.; Nakai, K.; Yamada, K.; Saito, Y.; Ono, S. Data-Driven Sparse Sensor Selection Based on A-Optimal Design of Experiment with ADMM. IEEE Sens. J. 2021, 21, 15248–15257. [Google Scholar] [CrossRef]
- Li, Q.; Chen, B.; Yang, M. Improved Two-Step Constrained Total Least-Squares TDOA Localization Algorithm Based on the Alternating Direction Method of Multipliers. IEEE Sens. J. 2020, 20, 13666–13673. [Google Scholar] [CrossRef]
- Wang, H.; Feng, R.; Han, Z.F. ADMM-based algorithm for training fault tolerant RBF networks and selecting centers. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3870–3878. [Google Scholar]
- Wei, Y.; Li, Y.; Ding, Z. SAR Parametric Super-Resolution Image Reconstruction Methods Based on ADMM and Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10197–10212. [Google Scholar] [CrossRef]
- Wang, H.; Gao, Y.; Shi, Y. Group-based alternating direction method of multipliers for distributed linear classification. IEEE Trans. Cybern. 2017, 47, 3568–3582. [Google Scholar] [CrossRef]
- Luo, M.; Zhang, L.; Liu, J. Distributed extreme learning machine with alternating direction method of multiplier. Neurocomputing 2017, 261, 164–170. [Google Scholar] [CrossRef]
- Bai, T.; Li, S.; Zou, Y. Distributed MPC for Reconfigurable Architecture Systems via Alternating Direction Method of Multipliers. IEEE/CAA J. Autom. Sin. 2021, 8, 1336–1344. [Google Scholar] [CrossRef]
- Xu, J.; Chen, X.; Hu, S. Low-bit Quantization of Recurrent Neural Network Language Models Using Alternating Direction Methods of Multipliers. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7939–7943. [Google Scholar]
- Chen, C.; He, B.; Ye, Y.; Yuan, X. The direct extension of ADMM for multi-block convex minimization problems is not necessarily convergent. Math. Program. 2016, 155, 57–79. [Google Scholar] [CrossRef]
- Guo, K.; Han, D.; Wang, D.Z.; Wu, T. Convergence of ADMM for multi-block nonconvex separable optimization models. Front. Math. China 2017, 12, 1139–1162. [Google Scholar] [CrossRef]
- Han, D.; Yuan, X.; Zhang, W.; Cai, X. An ADM-based splitting method for separable convex programming. Comput. Optim. Appl. 2013, 54, 343–369. [Google Scholar] [CrossRef]
- Li, M.; Sun, D.; Toh, K.C. A convergent 3-block semi-proximal ADMM for convex minimization problems with one strongly convex block. Asia-Pac. J. Oper. Res. 2015, 32, 1550024. [Google Scholar] [CrossRef] [Green Version]
- Lai, X.; Cao, J.; Zhao, R. A Relaxed ADMM Algorithm for WLS Design of Linear-Phase 2D FIR Filters. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5. [Google Scholar]
- Lai, X.; Cao, J.; Huang, X. A Maximally Split and Relaxed ADMM for Regularized Extreme Learning Machines. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1899–1913. [Google Scholar] [CrossRef]
- Su, Y.; Xu, J.; Qin, H. Kernel Extreme Learning Machine Based on Alternating Direction Multiplier Method of Binary Splitting Operator. J. Electron. Inf. Technol. 2021, 43, 2586–2593. [Google Scholar]
- Ma, M.; Lai, X.; Meng, H. The Maximum Partition Relaxation ADMM Algorithm of Two-dimensional FIR Filter Constrained Least Square Design. Electron. J. 2020, 48, 510–517. [Google Scholar]
- Hou, X.; Lai, X.; Cao, J. A Maximally Split Generalized ADMM for Regularized Extreme Learning Machines. Electron. J. 2021, 49, 625–630. [Google Scholar]
- Qing, Y.; Zeng, Y.; Li, Y. Deep and wide feature based extreme learning machine for image classification. Neurocomputing 2020, 412, 426–436. [Google Scholar] [CrossRef]
- Li, R.; Wang, C.; Zhang, H. Using Wavelet Packet Denoising and a Regularized ELM Algorithm Based on the LOO Approach for Transient Electromagnetic Inversion. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Er, M.J.; Shao, Z.; Wang, N. A fast and effective Extreme learning machine algorithm without tuning. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 770–777. [Google Scholar]
- Zhao, Y.; Wang, K. Fast cross validation for regularized extreme learning machine. J. Syst. Eng. Electron. 2014, 25, 895–900. [Google Scholar] [CrossRef]
- Yan, S.; Yang, M. Alternating Direction Method of Multipliers with variable stepsize for Partially Parallel MR Image reconstruction. In Proceedings of the 36th Chinese Control Conference, Dalian, China, 26–28 July 2017. [Google Scholar]
- Song, H.; Zhang, B.; Wang, M. A Fast Phase Optimization Approach of Distributed Scatterer for Multitemporal SAR Data Based on Gauss-Seidel Method. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sun, K.; Sun, X.A. A Two-Level ADMM Algorithm for AC OPF with Global Convergence Guarantees. IEEE Trans. Power Syst. 2021, 36, 5271–5281. [Google Scholar] [CrossRef]
- Yang, L.; Luo, J.; Xu, Y. A Distributed Dual Consensus ADMM Based on Partition for DC-DOPF with Carbon Emission Trading. IEEE Trans. Ind. Inform. 2019, 16, 1858–1872. [Google Scholar] [CrossRef]
- Huang, S.; Wu, Q.; Bao, W.; Hatziargyriou, N.D.; Ding, L.; Rong, F. Hierarchical Optimal Control for Synthetic Inertial Response of Wind Farm Based on Alternating Direction Method of Multipliers. IEEE Trans. Sustain. Energy 2021, 12, 25–35. [Google Scholar] [CrossRef]
- Luo, X.; Zhong, Y.; Wang, Z. An Alternating-Direction-Method of Multipliers-Incorporated Approach to Symmetric Non-Negative Latent Factor Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 16, 1–15. [Google Scholar] [CrossRef]
- Bastianello, N.; Carli, R.; Schenato, L. Asynchronous Distributed Optimization Over Lossy Networks via Relaxed ADMM: Stability and Linear Convergence. IEEE Trans. Autom. Control 2021, 66, 2620–2635. [Google Scholar] [CrossRef]
- Liang, X.; Li, Z.; Huang, W. Relaxed Alternating Direction Method of Multipliers for Hedging Communication Packet Loss in Integrated Electrical and Heating System. J. Mod. Power Syst. Clean Energy 2020, 8, 874–883. [Google Scholar] [CrossRef]
- Erseghe, T. New Results on the Local Linear Convergence of ADMM: A Joint Approach. IEEE Trans. Autom. Control 2021, 8, 5096–5111. [Google Scholar] [CrossRef]
- Xu, Z.; Figueiredo, M.; Goldstein, T. Adaptive ADMM with Spectral Penalty Parameter Selection. AISTATS 2017, 1, 1–7. [Google Scholar]
- Zhang, Z.H.; Shi, Z.H.J.; Wang, C.H.Y. A new memory gradient method and its convergence. Math. Econ. 2006, 23, 421–425. [Google Scholar]
- Xu, Z.; Figueiredo, M.A.T.; Yuan, X. Adaptive Relaxed ADMM: Convergence Theory and Practical Implementation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yu, T.; Liu, X.W.; Dai, Y.H. A Minibatch Proximal Stochastic Recursive Gradient Algorithm Using a Trust-Region-Like Scheme and Barzilai-Borwein Stepsizes. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4627–4638. [Google Scholar] [CrossRef] [PubMed]
- Du, K.-L.; Swamy, M.N.S.; Wang, Z.-Q.; Mow, W.H. Matrix Factorization Techniques in Machine Learning, Signal Processing, and Statistics. Mathematics 2023, 11, 2674. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Attributes | Number of Training Samples | Number of Testing Samples | Number of Classes |
|---|---|---|---|---|
| Gisette | 5000 | 5600 | 1400 | 2 |
| USPS | 256 | 7439 | 1859 | 10 |
| Magic | 10 | 15,216 | 3804 | 2 |
| BASEHOCK | 4862 | 1595 | 438 | 2 |
| Pendigits | 16 | 8794 | 2198 | 10 |
| Optical-Digits | 64 | 4496 | 1124 | 10 |
| Statlog | 36 | 5148 | 1287 | 6 |
| PCMAC | 3289 | 1555 | 388 | 2 |
| Termination Condition (Error) | Iterations | |||
|---|---|---|---|---|
| MBBH | NABBH | MTBBH | Proposed | |
| 1 × 10 | 134 | 114 | 117 | 78 |
| 1 × 10 | 182 | 154 | 126 | 95 |
| 1 × 10 | 201 | 178 | 135 | 115 |
| 1 × 10 | 274 | 230 | 176 | 146 |
| 1 × 10 | 306 | 270 | 243 | 194 |
| Dataset | RB-ADMM | MS-AADMM | MS-ARADMM | |||
|---|---|---|---|---|---|---|
| Time(s) | Number of Iterations | Time(s) | Number of Iterations | Time(s) | Number of Iterations | |
| Gisette | 737.5244 | 912 | 33.4513 | 39 | 5.9518 | 7 |
| USPS | 2621.8914 | 546 | 152.5741 | 31 | 33.9495 | 5 |
| BASEHOCK | 332.8139 | 1674 | 9.0221 | 41 | 1.5389 | 7 |
| Magic | 1156.6178 | 674 | 46.0599 | 25 | 12.9115 | 7 |
| Pendigits | 3912.3798 | 742 | 176.3753 | 33 | 37.3298 | 17 |
| Optical-Digits | 1825.9015 | 538 | 139.2235 | 41 | 24.5017 | 35 |
| Statlog | 1626.4322 | 704 | 92.0177 | 39 | 16.4330 | 11 |
| PCMAC | 353.2414 | 1753 | 3.3102 | 15 | 1.9676 | 9 |
| Dataset | Number of Categories | MS-ARADMM Compared to RB-ADMM | MS-ARADMM Compared to MS-AADMM |
|---|---|---|---|
| Gisette | 2 | 99.2324 | 82.0512 |
| Magic | 2 | 99.5818 | 82.9268 |
| BASEHOCK | 2 | 99.4865 | 72 |
| PCMAC | 2 | 98.9614 | 40 |
| statlog | 6 | 98.4375 | 71.7948 |
| USPS | 10 | 99.0842 | 83.8709 |
| Pendigits | 10 | 97.7088 | 48.4848 |
| Optical-Digits | 10 | 93.4944 | 14.6341 |
| Dataset | MI-Based RELM | MS-ARADMM-Based RELM | ||||
|---|---|---|---|---|---|---|
| CPU | GPU | Acceleration Ratio | CPU | GPU | Acceleration Ratio | |
| Gisette | 51.5313 | 9.885 | 5.2131 | 6.3520 | 0.715 | 8.8839 |
| USPS | 50.1406 | 10.487 | 4.7812 | 61.1283 | 2.589 | 23.6108 |
| BASEHOCK | 29.9844 | 5.544 | 5.4084 | 1.2750 | 0.107 | 11.9159 |
| Magic | 78.7500 | 13.093 | 6.0170 | 29.0134 | 1.537 | 18.8766 |
| Pendigits | 54.7188 | 9.226 | 5.9309 | 115.0015 | 3.043 | 37.7921 |
| Optical-Digits | 36.2344 | 6.559 | 5.5244 | 44.7947 | 1.881 | 23.8143 |
| Statlog | 38.5156 | 8.756 | 4.3988 | 34.5882 | 0.675 | 51.2418 |
| PCMAC | 27.9688 | 5.103 | 5.4809 | 2.7872 | 0.230 | 12.1183 |
| Dataset | MI-Based | MS-AADMM | MS-ARADMM | |||
|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | |
| Gisette | 99.1607 | 95.5714 | 99.6071 | 96.2143 | 99.1607 | 96.0714 |
| USPS | 97.9161 | 97.0430 | 98.0774 | 96.5591 | 98.0371 | 96.9054 |
| BASEHOCK | 90.5867 | 90.2133 | 89.5859 | 90.1303 | 91.0915 | 90.4111 |
| Magic | 81.9203 | 81.8612 | 81.7889 | 81.7560 | 81.7757 | 81.7297 |
| Pendigits | 96.7023 | 96.6788 | 96.5658 | 96.6968 | 96.5203 | 96.8148 |
| Optical-Digits | 98.8657 | 98.3986 | 98.7989 | 97.8648 | 98.8434 | 97.9537 |
| Statlog | 85.8197 | 82.5174 | 85.6255 | 82.7506 | 85.7031 | 82.5951 |
| PCMAC | 99.4852 | 91.5167 | 99.3565 | 91.5167 | 99.7426 | 91.4602 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Huo, S.; Xiong, X.; Wang, K.; Liu, B. A Maximally Split and Adaptive Relaxed Alternating Direction Method of Multipliers for Regularized Extreme Learning Machines. Mathematics 2023, 11, 3198. https://doi.org/10.3390/math11143198
Wang Z, Huo S, Xiong X, Wang K, Liu B. A Maximally Split and Adaptive Relaxed Alternating Direction Method of Multipliers for Regularized Extreme Learning Machines. Mathematics. 2023; 11(14):3198. https://doi.org/10.3390/math11143198
Chicago/Turabian StyleWang, Zhangquan, Shanshan Huo, Xinlong Xiong, Ke Wang, and Banteng Liu. 2023. "A Maximally Split and Adaptive Relaxed Alternating Direction Method of Multipliers for Regularized Extreme Learning Machines" Mathematics 11, no. 14: 3198. https://doi.org/10.3390/math11143198