
Link Prediction Based on Heterogeneous Social Intimacy and Its Application in Social Influencer Integrated Marketing
 , ,
, ,
Abstract
:1. Introduction
2. Link Prediction Research Status
2.1. Link Prediction
2.2. Combined Link Prediction
2.3. Heterogeneous Link Prediction
3. Building Social Influencers for Integrated Marketing Based on Friends Recommendations
3.1. Integrated Marketing within a Brand Community
3.2. SIHI Aimed at Friend Recommendations
3.2.1. SIHI Based on the Node’s Own Characteristics
3.2.2. SIHI Based on Nodes and Common Neighbors
3.2.3. SIHI Based on Nodes and Community Neighbors
4. CHLPA
4.1. Network Features for Filtering SIHI
4.1.1. Node Density
4.1.2. Node Centrality
4.2. GBDT
| Algorithm 1. The proposed CHLPA algorithm. |
| Input: a set of no-direction network Output: a set of combined indexes for node pairs Function CHLPA For node pairs (x,y) in non-edges Node Density Node Centrality GBDT choosing the suitable indexes Return a set of combined indexes |
5. Experimental Design and Result Analysis
5.1. Experimental Design
5.2. Algorithm Performance Analysis
5.3. Establishing Friend Relationships Based on Hill-Climbing Algorithm
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, D.H.; Brusilovsky, P. How to Measure Information Similarity in Online Social Networks: A Case Study of Citeulike. Inf. Sci. 2017, 418, 46–60. [Google Scholar] [CrossRef] [Green Version]
- Muniz, A.M., Jr.; O’Guinn, T.C. Brand Community. J. Consum. Res. 2001, 27, 412–432. [Google Scholar] [CrossRef] [Green Version]
- Horne, B.D.; Nevo, D.; Adalı, S. Recognizing Experts on Social Media: A Heuristics-Based Approach. ACM SIGMIS Database 2019, 50, 66–84. [Google Scholar] [CrossRef] [Green Version]
- Bakshy, E.; Hofman, J.M.; Mason, W.A.; Watts, D.J. Everyone’s an Influencer: Quantifying Influence on Twitter. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 65–74. [Google Scholar]
- Palazón, M.; Sicilia, M.; López, M. The Influence of “Facebook Friends” on the Intention to Join Brand Pages. J. Prod. Brand Manag. 2015, 24, 563–577. [Google Scholar] [CrossRef]
- Choi, Y.K.; Seo, Y.; Yoon, S. E-WOM Messaging on Social Media: Social Ties, Temporal Distance, and Message Concreteness. Internet Res. 2017, 27, 516–532. [Google Scholar] [CrossRef]
- Renton, M.; Simmonds, H. Like is a Verb: Exploring Tie Strength and Casual Brand Use Effects on Brand Attitudes and Consumer Online Goal Achievement. J. Prod. Brand Manag. 2017, 26, 610–621. [Google Scholar] [CrossRef]
- Whittler, T.E.; Spira, J.S. Model’s Race: A Peripheral Cue in Advertising Messages? J. Consum. Psychol. 2002, 12, 291–301. [Google Scholar] [CrossRef]
- Voyer, P.A.; Ranaweera, C. The Impact of Word of Mouth on Service Purchase Decisions: Examining Risk and the Interaction of Tie Strength and Involvement. J. Serv. Theory Pract. 2015, 25, 274–293. [Google Scholar]
- Lee, J.N. A Study on the Impact of Brand Community Interaction Model on Brand Loyalty: Focusing on Chinese Online Brand Community. Korean Corp. Manag. Rev. 2012, 46, 93–113. [Google Scholar]
- Wilson, H.N.; Macdonald, E.K.; Baxendale, S. What Really Makes Customers Buy a Product. Harv. Bus. Rev. 2015, 93, 1–11. [Google Scholar]
- Ghalmane, Z.; Cherifi, C.; Cherifi, H.; El Hassouni, M. Exploring Hubs and Overlapping Nodes Interactions in Modular Complex Networks. IEEE Access 2020, 8, 79650–79683. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link Prediction in Complex Networks: A Survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Barber, R.; Gupta, M.; Aggarwal, C.C.; Han, J. Co-Author Relationship Prediction in Heterogeneous Bibliographic Networks. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining, Kaohsiung, Taiwan, 25–27 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 121–128. [Google Scholar]
- He, Y.; Liu, J.N.K.; Hu, Y.; Kao, B.; Lee, W.-C.; Chen, A.L.P.; Chen, M.-S. OWA Operator-Based Link Prediction Ensemble for Social Network. Expert Syst. Appl. 2015, 42, 21–50. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Liu, M.; Tang, X.; Qian, C. Link Prediction Based on Community Information and Its Parallelization. IEEE Access 2019, 7, 62633–62645. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, X.; Wang, H.; Liu, Y.; Liu, Y. 3-HBP: A Three-Level Hidden Bayesian Link Prediction Model in Social Networks. IEEE Trans. Comput. Soc. Syst. 2018, 5, 430–443. [Google Scholar] [CrossRef]
- Bütün, E.; Kaya, M. A Pattern-Based Supervised Link Prediction in Directed Complex Networks. Phys. A Stat. Mech. Its Appl. 2019, 525, 1136–1145. [Google Scholar] [CrossRef]
- Zhan, Q.; Zhang, J.; Philip, S.Y.; Jin, Q.; Yang, Y.; Yu, Y. Discover Tipping Users for Cross Network Influencing. In Proceedings of the 2016 IEEE 17th International Conference on Information Reuse and Integration (IRI), Pittsburgh, PA, USA, 28–30 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 67–76. [Google Scholar]
- Dewi, F.K.; Yudhoatmojo, S.B.; Budi, I. Identification of Opinion Leader on Rumor Spreading in Online Social Network Twitter Using Edge Weighting and Centrality Measure Weighting. In Proceedings of the 2017 Twelfth International Conference on Digital Information Management (ICDIM), Fukuoka, Japan, 12–14 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 313–318. [Google Scholar]
- Dai, W.; Shang, Y. Edge-Concerned Embedding for Multiplex Heterogeneous Network. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 17–20 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 584–589. [Google Scholar]
- Shi, S.; Li, Y.; Wen, Y.; Li, J.; Gao, J. Adding the Sentiment Attribute of Nodes to Improve Link Prediction in Social Networks. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1263–1269. [Google Scholar]
- Mohdeb, D.; Boubetra, A.; Charikhi, M. WMPLP: A Model for Link Prediction in Heterogeneous Social Networks. In Proceedings of the 2014 4th International Symposium ISKO-Maghreb: Concepts and Tools for Knowledge Management (ISKO-Maghreb), Tetouan, Morocco, 22–24 October 2014; pp. 1–4. [Google Scholar]
- Cao, B.; Kong, X.; Philip, S.Y. Collective Prediction of Multiple Types of Links in Heterogeneous Information Networks. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 50–59. [Google Scholar]
- Li, S.; Wang, Z.; Zhang, B.; Zhu, B.; Wen, Z.; Yu, Z. The Research of “Products Rapidly Attracting Users” Based on the Fully Integrated Link Prediction Algorithm. Mathematics 2022, 10, 2424. [Google Scholar] [CrossRef]
- Wang, H.; Yin, G.; Zhou, L.; Shao, Z. Influence Maximization Algorithm in Social Networks Based on Three Degrees of Influence Rule. In Proceedings of the International Conference on Cloud Computing and Security, Nanjing, China, 8–10 June 2018; Springer: Cham, Switzerland, 2018; pp. 567–578. [Google Scholar]
- Li, S.; Song, X.; Lu, H.; Huang, J.; Zhang, H. Friend Recommendation for Cross Marketing in Online Brand Community Based on Intelligent Attention Allocation Link Prediction Algorithm. Expert Syst. Appl. 2020, 139, 112839. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, C.; Zhang, X.; He, Q.; Fan, Y. An Up-to-Date Comparison of State-of-the-Art Classification Algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Lü, L.; Jin, C.-H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [Green Version]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical organization of modularity in metabolic networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leicht, E.A.; Holme, P.; Newman, M.E.J. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y.-C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Yuliansyah, H.; Othman, Z.A.; Bakar, A.A. A new link prediction method to alleviate the cold-start problem based on extending common neighbor and degree centrality. Phys. A Stat. Mech. Its Appl. 2023, 616, 128546. [Google Scholar] [CrossRef]
- Ahmad, I.; Akhtar, M.U.; Noor, S.; Shahnaz, A. Missing link prediction using common neighbor and centrality based parameterized algorithm. Sci. Rep. 2020, 10, 364. [Google Scholar] [CrossRef] [Green Version]





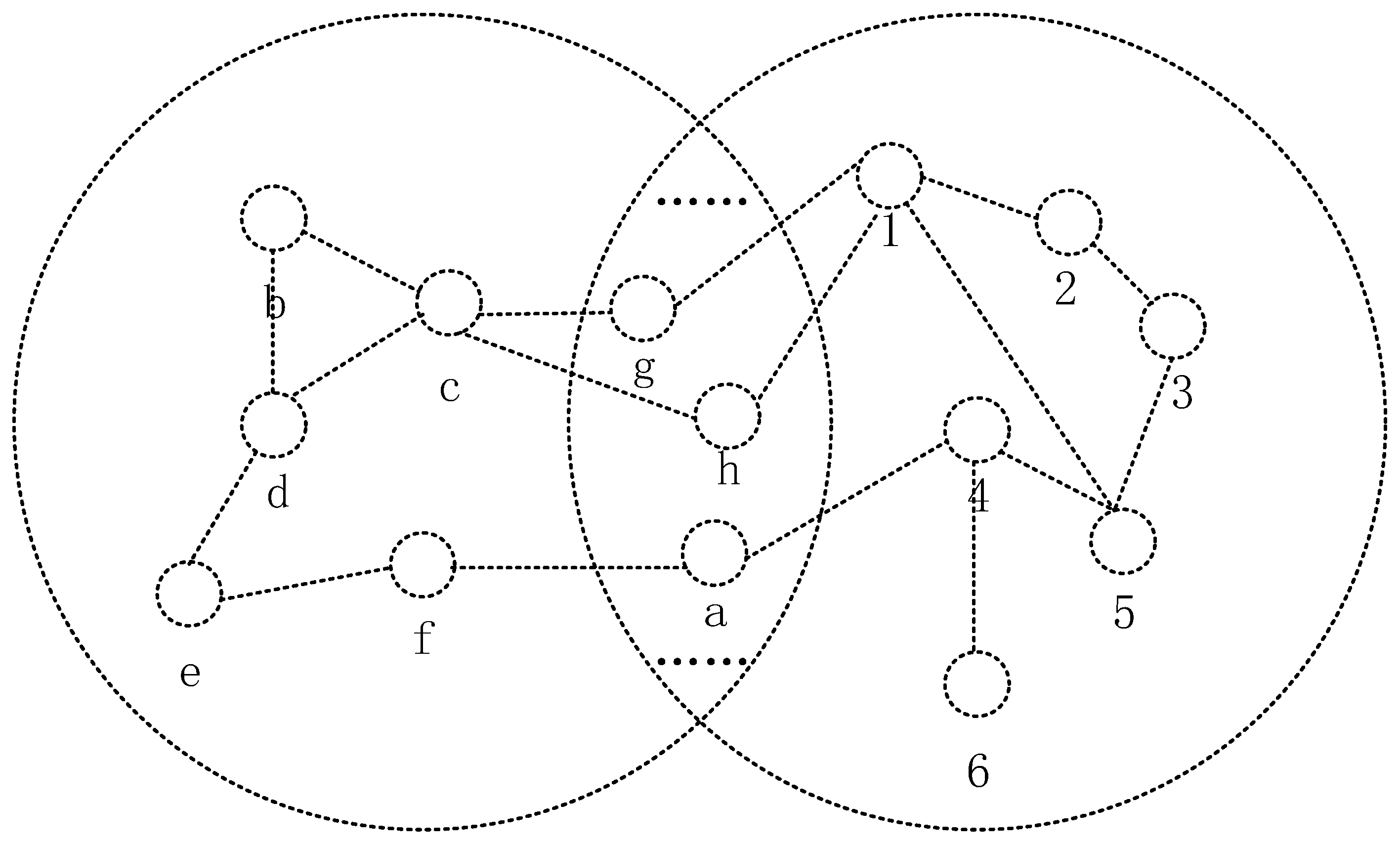{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Formula |
|---|---|
| M1 | |
| M2 |
| Algorithm | Formula |
|---|---|
| M3 | |
| M4 | |
| M5 | |
| M6 |
| Algorithm | Formula |
|---|---|
| M7 | |
| M8 | |
| M9 | |
| M10 |
| Dataset | Statistical Indicators | MIN | AVERAGE | MAX |
|---|---|---|---|---|
| Google Plus | average path length | 1.4503 | 2.0078 | 2.5968 |
| network diameter | 2.000 | 4.4583 | 7.000 | |
| mean node degree centrality | 5.824 | 23.2574 | 56.557 | |
| average node betweenness centrality | 8.105 | 258.9533 | 1054.731 | |
| mean eigenvector centrality | 0.856 | 2.3905 | 4.720 | |
| average path length | 1.1209 | 1.9739 | 2.8883 | |
| network diameter | 2.0000 | 4.4810 | 8.0000 | |
| mean node degree centrality | 2.8889 | 24.6438 | 92.4426 | |
| average node betweenness centrality | 1.5714 | 118.6830 | 378.5911 | |
| mean eigenvector centrality | 0.8953 | 2.7602 | 6.7377 | |
| Celegans | average path length | 2.7375 | ||
| network diameter | 8.0000 | |||
| mean node degree centrality | 27.3552 | |||
| average node betweenness centrality | 2121.5237 | |||
| mean eigenvector centrality | 1.2455 | |||
| Algorithm | Formula | Reference |
|---|---|---|
| CN | [30] | |
| Salton | [31] | |
| Jaccard | [32] | |
| Sorenson | [30] | |
| Hub Promoted Index (HPI) | [33] | |
| Hub Depressed Index (HDI) | [33] | |
| LHN | [34] | |
| Adamic/Adar (AA) | [35] | |
| Resource Allocation (RA) | [36] | |
| DGLP | [37] | |
| CCPA | () + (1 − ) | [38] |
| Algorithm | Google Plus | Celegans | |
|---|---|---|---|
| M1 | 0.8057 | 0.7263 | 0.8321 |
| M2 | 0.8059 | 0.7265 | 0.8316 |
| M3 | 0.6710 | 0.7056 | 0.7453 |
| M4 | 0.6719 | 0.7066 | 0.7460 |
| M5 | 0.6708 | 0.7067 | 0.7455 |
| M6 | 0.6734 | 0.7062 | 0.7443 |
| M7 | 0.6317 | 0.6035 | 0.7710 |
| M8 | 0.6338 | 0.6026 | 0.7719 |
| M9 | 0.5017 | 0.2696 | 0.6048 |
| M10 | 0.6656 | 0.7062 | 0.7496 |
| MAA | 0.8515 | 0.8839 | 0.8868 |
| DGLP | 0.6895 | 0.6828 | 0.7100 |
| CCPA | 0.7231 | 0.5328 | 0.8241 |
| Algorithm | Average AUC | Algorithm | Average AUC |
|---|---|---|---|
| CN | 0.7987 | HDI | 0.6330 |
| Salton | 0.6599 | LHN | 0.4562 |
| Jaccard | 0.6480 | AA | 0.8081 |
| Sorenson | 0.6489 | RA | 0.8123 |
| HPI | 0.6956 | DGLP | 0.6895 |
| CCPA | 0.7231 | MAA0 | 0.8174 |
| Network Code | Number of Nodes | Number of Circles | Target User ID | Algorithm | Number of Friends after Each Iteration | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | |||||
| 114124942936679476879 | 34 | 2 | 101889975950769 | Hill-Climbing Algorithm Based on Node Degree | 1 | 11 | 23 | |||
| Hill-Climbing Algorithm Based on Node Degree Centrality | 1 | 18 | 25 | |||||||
| Hill-Climbing Algorithm Based on Node Betweenness Centrality | 1 | 17 | 27 | |||||||
| Hill-Climbing Algorithm Based on Node Closeness Centrality | 1 | 21 | 33 | |||||||
| 104917160754181459072 | 132 | 6 | 111043623176980 | Hill-Climbing Algorithm Based on Node Degree | 1 | 16 | 29 | 48 | 79 | 103 |
| Hill-Climbing Algorithm Based on Node Degree Centrality | 1 | 16 | 35 | 57 | 79 | 102 | ||||
| Hill-Climbing Algorithm Based on Node Betweenness Centrality | 1 | 20 | 36 | 59 | 84 | 104 | ||||
| Hill-Climbing Algorithm Based on Node Closeness Centrality | 1 | 34 | 56 | 87 | 103 | 116 | ||||
| 112573107772208475213 | 202 | 14 | 115716197313320 | Hill-Climbing Algorithm Based on Node Degree | 1 | 48 | 79 | 102 | 148 | 179 |
| Hill-Climbing Algorithm Based on Node Degree Centrality | 1 | 35 | 667 | 99 | 105 | 132 | ||||
| Hill-Climbing Algorithm Based on Node Betweenness Centrality | 1 | 45 | 79 | 106 | 124 | 158 | ||||
| Hill-Climbing Algorithm Based on Node Closeness Centrality | 1 | 67 | 89 | 102 | 142 | 198 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zhu, H.; Wen, Z.; Li, J.; Zang, Y.; Zhang, J.; Yan, Z.; Wei, Y. Link Prediction Based on Heterogeneous Social Intimacy and Its Application in Social Influencer Integrated Marketing. Mathematics 2023, 11, 3023. https://doi.org/10.3390/math11133023
Li S, Zhu H, Wen Z, Li J, Zang Y, Zhang J, Yan Z, Wei Y. Link Prediction Based on Heterogeneous Social Intimacy and Its Application in Social Influencer Integrated Marketing. Mathematics. 2023; 11(13):3023. https://doi.org/10.3390/math11133023
Chicago/Turabian StyleLi, Shugang, He Zhu, Zhifang Wen, Jiayi Li, Yuning Zang, Jiayi Zhang, Ziqian Yan, and Yanfang Wei. 2023. "Link Prediction Based on Heterogeneous Social Intimacy and Its Application in Social Influencer Integrated Marketing" Mathematics 11, no. 13: 3023. https://doi.org/10.3390/math11133023