
XTS: A Hybrid Framework to Detect DNS-Over-HTTPS Tunnels Based on XGBoost and Cooperative Game Theory
 , , ,
, , ,
Abstract
:1. Introduction
- (1)
- We hypothesize that command and control traffic can assumably be detected based on unique connections at the IP level (the source, destination IPs), and that this probably is also the case for packet size factors such as packet length mode, median or mean. Possessing prior efficiency assumptions in terms of XGBoost, we compare its performance to other well-known machine learning models, ultimately selecting the best performer for our specific use case.
- (2)
- We construct a GPU-aware from unfamous but powerful hyperparameters, particularly gpu_hist, an optimized version of the histogram-based tree building algorithm used in XGBoost that leverages the parallel computing power of GPUs to perform computations faster than they are on a CPU. With gpu_hist, XGBoost can build decision trees on large datasets more efficiently, making it the preferred choice for tasks with high-dimensional and large-scale data. It also optimizes memory usage, enabling users to train models on larger datasets that may not fit into CPU memory.
- (3)
- We turn the base model of XGBoost into a cost-sensitive algorithm that has a bias towards the majority class. By increasing the weights of the minority class instances, the algorithm is penalized more for misclassifying those instances, leading to a better balance between the minority and majority classes. This technique, unlike its counterpart sampling methods, is simple but efficient.
- (4)
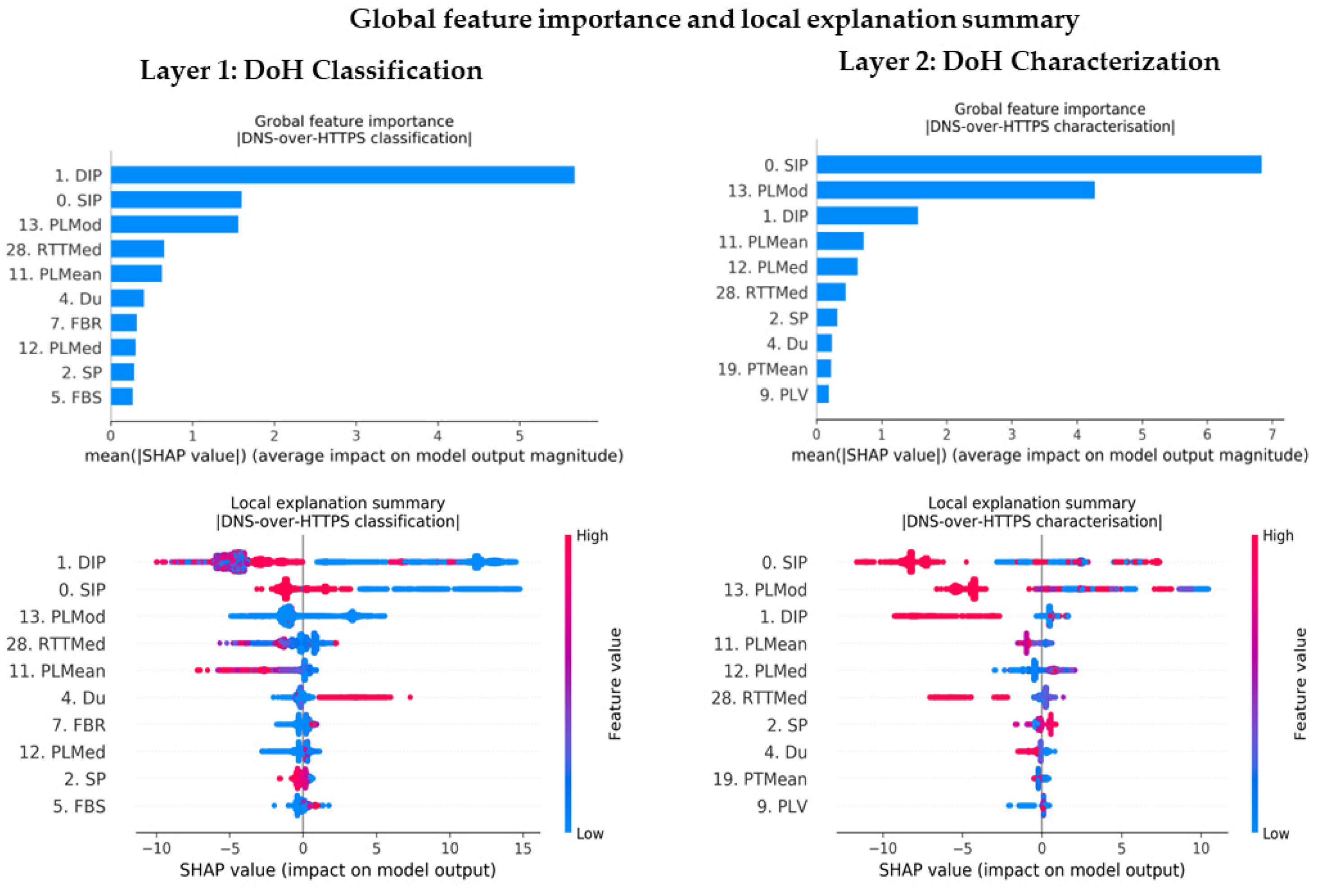
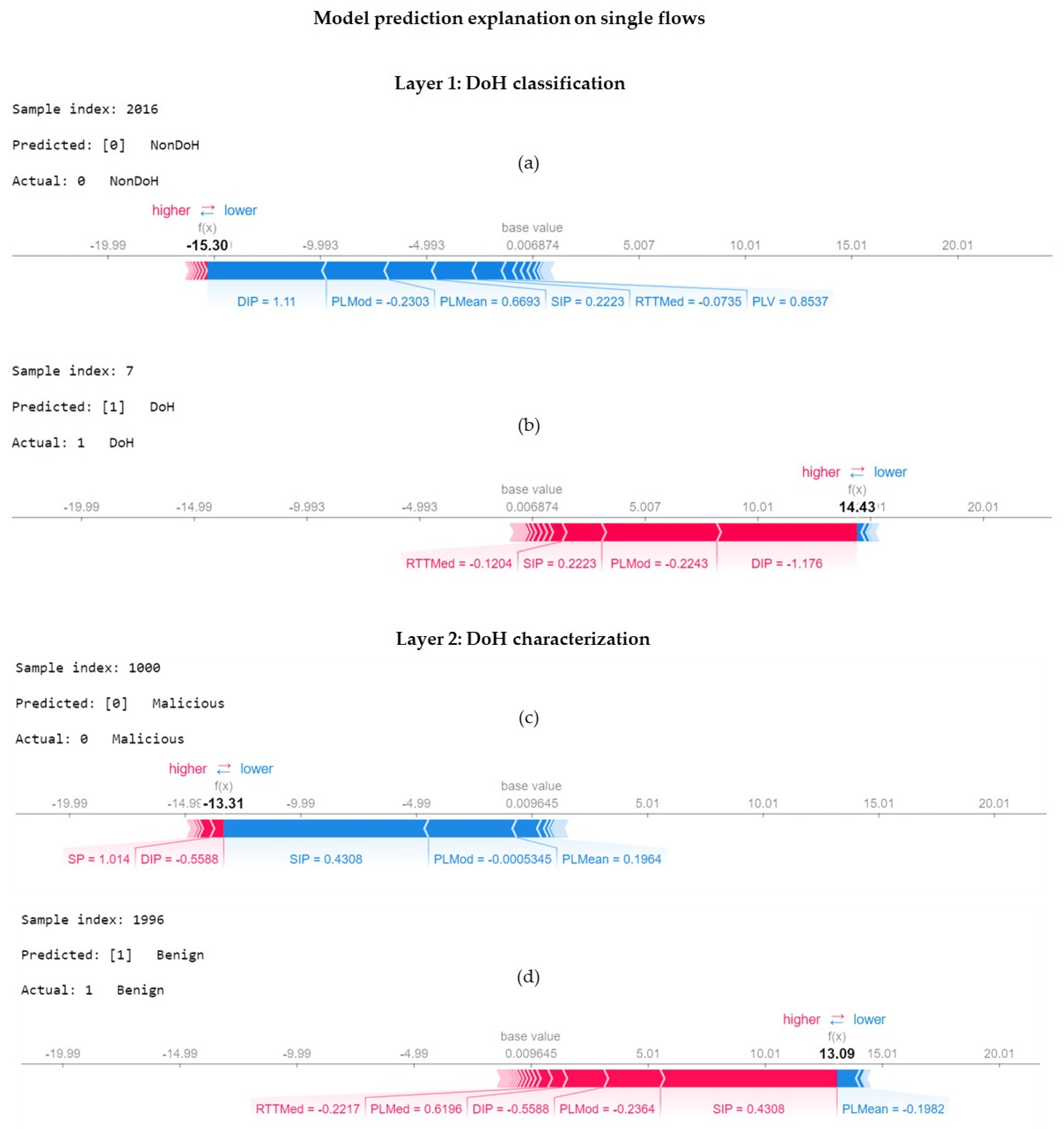
- We use a tree-specific SHAP model to explain in order to learn SHAP values that explain the unique and consistent features making contributions towards predictions. We interpret the results via rich visualization, using SHAP plots at both local and global levels to verify our subjective hypothesis.
- (5)
- Based on the most influential flow features, we create a subset ranging from the most significant feature (MSF) to the least significant feature (LSF) and design a new algorithm to sequentially fit and evaluate f on subsets until the loss function . This helps us to achieve the highest prediction accuracy with a low-dimensional representation. This presumably decreases computational cost.
2. Related Work
2.1. Recent Abuse of DNS
2.2. High-Dimension Features Problems in Machine Learning
2.3. DNS Tunneling Detection with ML Methods
3. Proposed Framework
3.1. Preliminaries
- Cost-Sensitive eXtreme Gradient Boosting—optimized black-box ML model used for classification of HTTPS traffic in this study.
- Tree Explainer—A SHAP (SHapley Additive exPlanations)-based model designed specifically to provide explanations for tree-based models.
- Sequential Forward Evaluation—algorithm designed to evaluate the newly optimized model of the subsets of features selected as a result of the Tree Explainer list of the most significant features.
- XTS: The dubbed term of our framework. X represents collectively the cost-sensitive and GPU-aware eXtreme Gradient Boosting; T is for Tree Explainer; and S is for Sequential Forward Evaluation algorithm, designed in this study.
- CX: The non-cost-sensitive version of XGBoost, trained with CPU-only capability, where C stands for cost-sensitive or, more technically, the parameter “scale_pos_weight” in XGB algorithm.
- gCX: The GPU-aware version of XGB. Where stands for GPU capability activation or, more technically, the string “gpu_hist” for tree method parameter.
- Dataset (X, y) represents any dataset used to train, evaluate, test or explain the models specified above.
- TTT: The time to train a machine learning model.
- TTD: The time to detect—the time taken by the model to predict test examples.
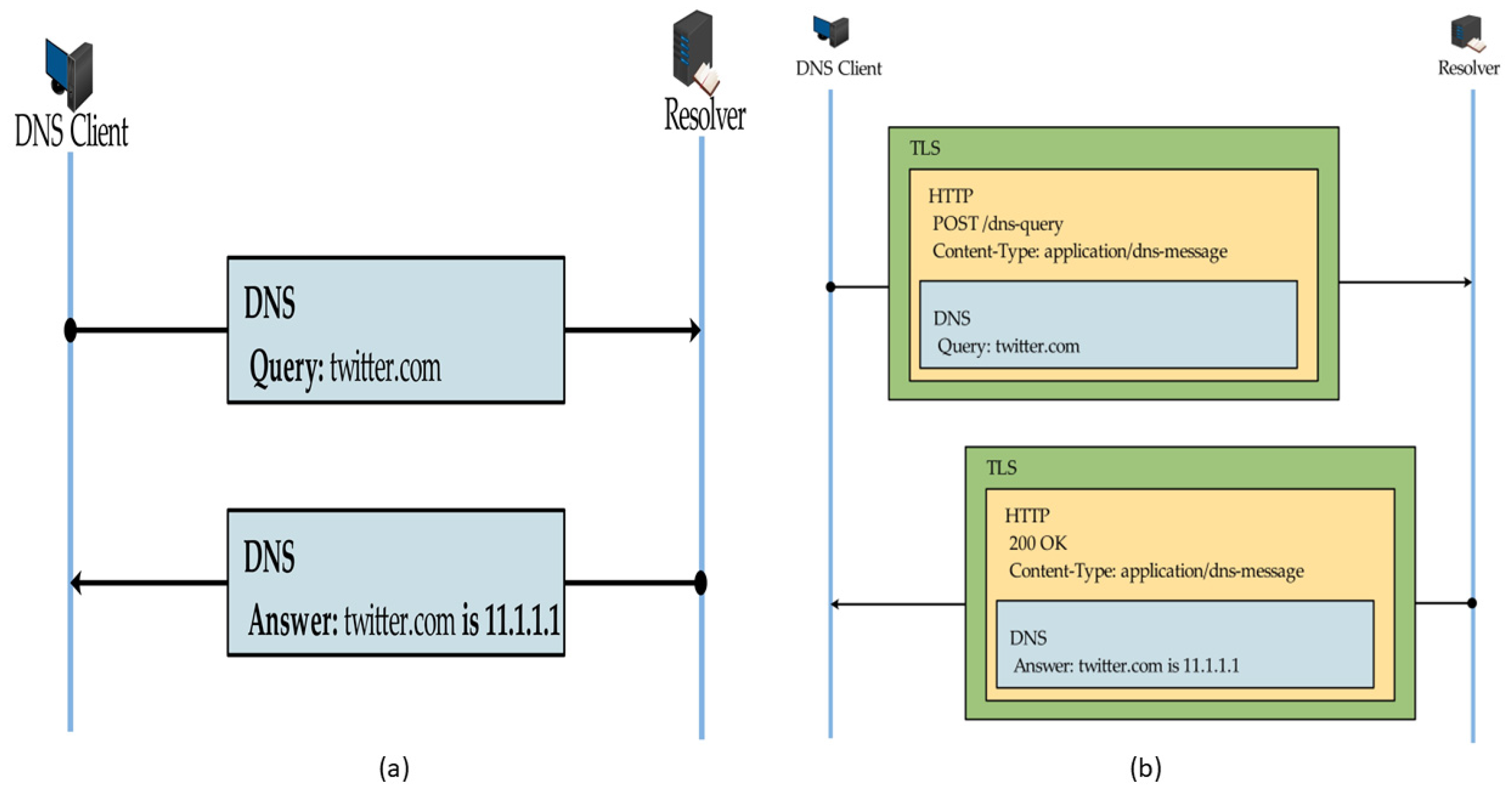
- Layer 1: The task of classifying HTTPS traffic into DNS-over-HTTPS (DoH) and normal web browsing activities (NonDoH). Dataset for this task is denoted as D.
- Layer 2: The task of characterizing DNS-over-HTTPS (DoH). Classifying DoH traffic into malicious or benign DoH. The dataset for this task is denoted as B. It is important to mention that we keep lower traffic samples of benign class in D as is and consider it to be the positive class for detection. Contrary to the commonly practiced methods of making malicious a minority, positive class, we deviate a little in order to prove otherwise.
3.2. Analytical Modeling of DoH Tunnels Using XTS
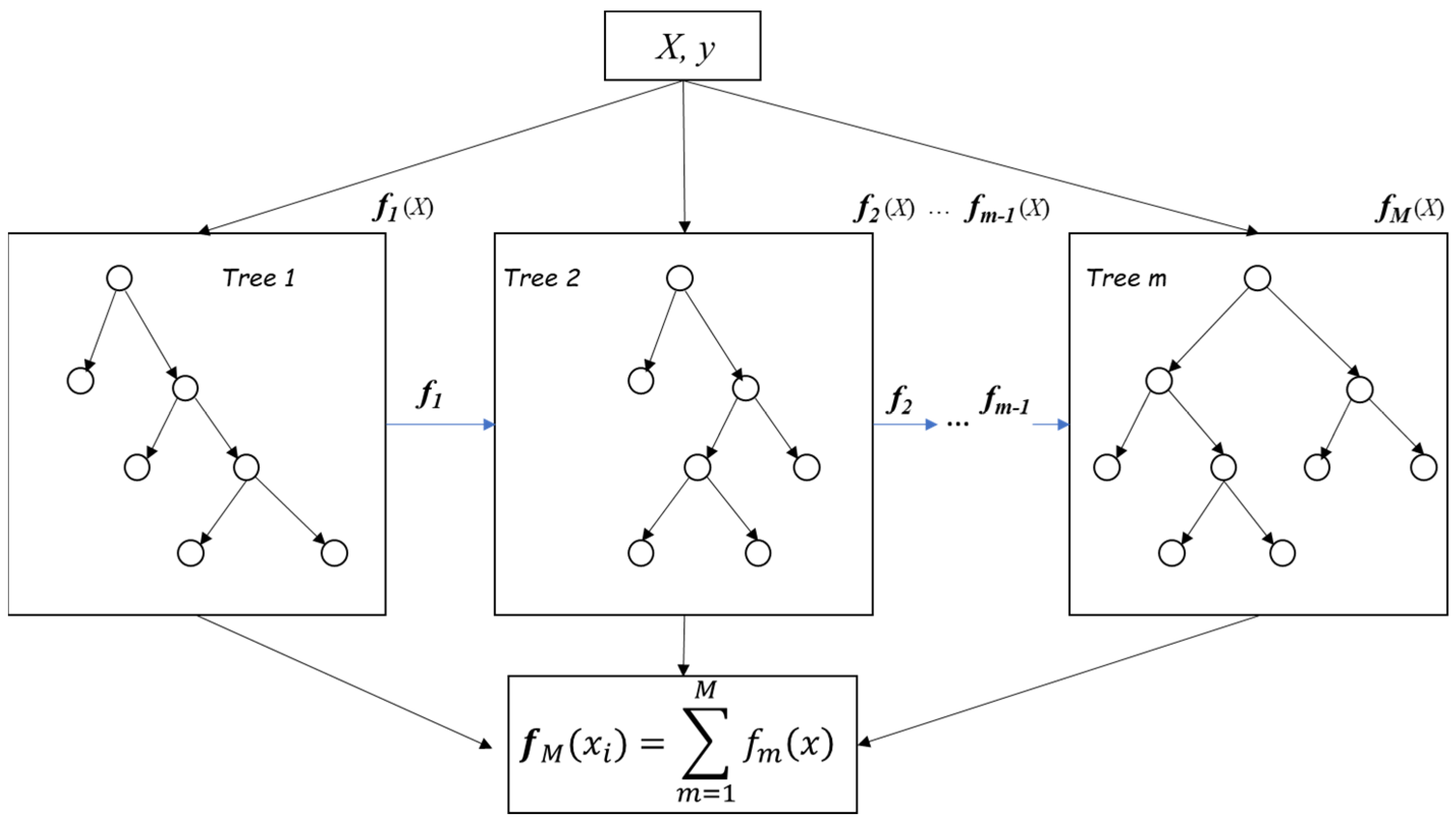
3.2.1. XGB Mathematical Abstract
3.2.2. Dealing with Imbalance Data Using CX
3.2.3. Compared Models’ Computation Time Complexity
3.2.4. Speed Optimization Using gCX
3.2.5. Feature Importance Modeling and Analysis
3.2.6. Low-Dimensional Representation Using SFE
| Algorithm 1: Sequential Forward Evaluation. | |||
| Input: A list of top 10 selected features from the main feature set | |||
| Output: Computational time (, evaluation metrics ( for all subsets | |||
| 1 | Require: Create a subset of selected top features from original feature set | ||
| 2 | Initialize: // initialize features index and time sets to null | ||
| 3 | Procedure () | ||
| 4 | for all do // create a subset for each iteration | ||
| 5 | // add one feature to create a new subset | ||
| 6 | // time before training and validation | ||
| 7 | // train the model | ||
| 8 | // time after training and validation | ||
| 9 | // Time-to-Train (TTT) including validation time | ||
| 10 | append to // add TTT of a subset to training time set | ||
| 11 | //time before testing | ||
| 12 | //test the model | ||
| 13 | //time after testing | ||
| 14 | //Time-to-Detect (TTD) | ||
| 15 | append to // add TTD of a subset to prediction time set | ||
| 16 | record | ||
| 17 | call plot functions () | ||
| 18 | end for | ||
| 20 | end procedure | ||
3.2.7. Model Performance Metrics
- Precision: Precision metric shows, from all the instances that the model predicted as belonging to the positive class (TP + FP), the percentage of those which were actually true positive (TP). In this paper, it refers to how many DoH samples were predicted correctly out of all predicted as DoH and/or how many benign samples were predicted correctly out of all predicted as benign, in layer 1 and layer 2, respectively.
- Recall: Recall metric shows, from all the instances of positive class (TP + FN), the percentage of those which the model predicted correctly. In this paper, it refers to how many DoH or Benign flows were predicted correctly in layer 1 or 2 respectively.
- F1-Score: F1-Score measures the overall average of both Precision and Recall.
- AUCPR: Area Under the (Precision-Recall) Curve also known as Average precision (AP), shows a relationship between the Recall and Precision on a scale between 0 and 1. Equation (13), shows how to compute AP, where and mean the recall and precision at the ith threshold. Unlike AUC-ROC curves which considers the balance between positive and negative classes, AUCPR/AP focuses on how correctly the positive (minority) class is predicted [68]
3.3. Proposed Application Domain
4. Materials and Methods
4.1. Dataset Description
4.2. Experimental Setup
4.2.1. Overview
4.2.2. Data Engineering
4.2.3. Model Selection
5. Results and Discussion
5.1. Prediction vs. Computational Time
5.2. Feature Importance
5.3. Comparison and Discussion
6. Conclusions
7. Challenges and Recommendations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rappaport, T.S.; Xing, Y.; Kanhere, O.; Ju, S.; Madanayake, A.; Mandal, S.; Alkhateeb, A.; Trichopoulos, G.C. Wireless Communications and Applications above 100 GHz: Opportunities and Challenges for 6g and Beyond. IEEE Access 2019, 7, 78729–78757. [Google Scholar] [CrossRef]
- Saad, W.; Bennis, M.; Chen, M.; Dang, S.; Amin, O.; Shihada, B.; Alouini, M.S.; Letaief, K.B.; Chen, W.; Shi, Y.; et al. What Should 6G Be? IEEE Netw. 2020, 3, 134–142. [Google Scholar] [CrossRef]
- Saad, W.; Bennis, M.; Chen, M. A Vision of 6G Wireless Systems: Applications, Trends, Technologies, and Open Research Problems. IEEE Netw. 2020, 34, 134–142. [Google Scholar] [CrossRef]
- Zhao, Q.; Li, Y.; Hei, X.; Yang, M. A Graph-Based Method for IFC Data Merging. Adv. Civ. Eng. 2020, 2020, 8782740. [Google Scholar] [CrossRef]
- Yang, H.; Alphones, A.; Xiong, Z.; Niyato, D.; Zhao, J.; Wu, K. Artificial-Intelligence-Enabled Intelligent 6G Networks. IEEE Netw. 2020, 34, 272–280. [Google Scholar] [CrossRef]
- Xiao, Y.; Shi, G.; Li, Y.; Saad, W.; Poor, H.V. Toward Self-Learning Edge Intelligence in 6G. IEEE Commun. Mag. 2020, 58, 34–40. [Google Scholar] [CrossRef]
- Guo, W. Explainable Artificial Intelligence for 6G: Improving Trust between Human and Machine. IEEE Commun. Mag. 2020, 58, 39–45. [Google Scholar] [CrossRef]
- Bandi, A.; Yalamarthi, S. Towards Artificial Intelligence Empowered Security and Privacy Issues in 6G Communications. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 372–378. [Google Scholar] [CrossRef]
- Moore, A.; Zuev, D.; Crogan, M. Discriminators for Use in Flow-Based Classification; Queen Mary University of London: London, UK, 2005. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2017, 50, 1–45. [Google Scholar] [CrossRef]
- Ang, J.C.; Mirzal, A.; Haron, H.; Hamed, H.N.A. Supervised, Unsupervised, and Semi-Supervised Feature Selection: A Review on Gene Selection. IEEE/ACM Trans. Comput. Biol. Bioinforma. 2016, 13, 971–989. [Google Scholar] [CrossRef]
- Di Mauro, M.; Galatro, G.; Fortino, G.; Liotta, A. Supervised Feature Selection Techniques in Network Intrusion Detection: A Critical Review. Eng. Appl. Artif. Intell. 2021, 101, 104216. [Google Scholar] [CrossRef]
- AlNuaimi, N.; Masud, M.M.; Serhani, M.A.; Zaki, N. Streaming Feature Selection Algorithms for Big Data: A Survey. Appl. Comput. Inform. 2022, 18, 113–135. [Google Scholar] [CrossRef]
- Azhar, M.A.; Thomas, P.A. Comparative Review of Feature Selection and Classification Modeling. In Proceedings of the 2019 International Conference on Advances in Computing, Communication and Control (ICAC3), Mumbai, India, 20–21 December 2019. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Rego-Fernández, D.; Peteiro-Barral, D.; Alonso-Betanzos, A.; Guijarro-Berdiñas, B.; Sánchez-Maroño, N. On the Scalability of Feature Selection Methods on High-Dimensional Data. Knowl. Inf. Syst. 2018, 56, 395–442. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of Feature Selection Algorithm: A Review. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 1060–1073. [Google Scholar] [CrossRef]
- Al Hosni, O.; Starkey, A. Assesing the Stability and Selection Performance of Feature Selection Methods Under Different Data Complexity. Int. Arab J. Inf. Technol. 2022, 19, 442–455. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A Survey on Feature Selection Methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Brownlee, N.; Mills, C.; Ruth, G. RFC2722: Traffic Flow Measurement: Architecture; ACM Digital Library: New York, NY, USA, 1999. [Google Scholar]
- Wang, Z.; Zhou, J.; Hei, X. Network Traffic Anomaly Detection Based on Generative Adversarial Network and Transformer. Lect. Notes Data Eng. Commun. Technol. 2023, 153, 228–235. [Google Scholar] [CrossRef]
- Vu, L.; Bui, C.T.; Nguyen, Q.U. A Deep Learning Based Method for Handling Imbalanced Problem in Network Traffic Classification. In Proceedings of the 8th International Symposium on Information and Communication Technology, Nha Trang, Vietnam, 7–8 December 2017; pp. 333–339. [Google Scholar] [CrossRef]
- Santos, M.S.; Soares, J.P.; Abreu, P.H.; Araujo, H.; Santos, J. Cross-Validation for Imbalanced Datasets: Avoiding Overoptimistic and Overfitting Approaches [Research Frontier]. IEEE Comput. Intell. Mag. 2018, 13, 59–76. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, J.; Wang, Z.; Hei, X. Research on Network Traffic Anomaly Detection for Class Imbalance. In Intelligent Robotics, Proceedings of the Third China Intelligent Robotics Annual Conference, CCF CIRAC 2022, Xi’an, China, 16–18 December 2022; Springer: Singapore, 2023; pp. 135–144. [Google Scholar] [CrossRef]
- Spelmen, V.S.; Porkodi, R. A Review on Handling Imbalanced Data. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT 2018), Coimbatore, India, 1–3 March 2018; Institute of Electrical and Electronics Engineers: Coimbatore, India, 2018; pp. 1–11. [Google Scholar] [CrossRef]
- He, S.; Li, B.; Peng, H.; Xin, J.; Zhang, E. An Effective Cost-Sensitive XGBoost Method for Malicious URLs Detection in Imbalanced Dataset. IEEE Access 2021, 9, 93089–93096. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; Abumallouh, A. Deep and Machine Learning Approaches for Anomaly-Based Intrusion Detection of Imbalanced Network Traffic. IEEE Sens. Lett. 2019, 3, 2018–2021. [Google Scholar] [CrossRef]
- Brownlee, J. Cost-Sensitive. In Imbalanced Classification with Python: Choose Better Metrics, Balance Skewed Classes, and Apply Cost-Sensitive Learning; Martin, S., Sanderson, M., Koshy, A., Cheremskoy, J.H., Eds.; Machine Learning Mastery: Vermont, Australia, 2020; pp. 237–240. [Google Scholar]
- Fouchereau, R. An IDC Info Brief, Securing Anywhere Networking DNS Security for Business Continuity and Resilience 2022 Global DNS Threat Report. 2022. Available online: https://efficientip.com/wp-content/uploads/2022/10/IDC-EUR149048522-EfficientIP-infobrief_FINAL.pdf (accessed on 10 May 2023).
- Durumeric, Z.; Ma, Z.; Springall, D.; Barnes, R.; Sullivan, N.; Bursztein, E.; Bailey, M.; Halderman, J.A.; Paxson, V. The Security Impact of HTTPS Interception; NDSS: New York, NY, USA, 2017. [Google Scholar]
- HTTPS Encryption on the Web. Available online: https://transparencyreport.google.com/https/overview?hl=en (accessed on 27 November 2022).
- Let’s Encrypt Stats. Available online: https://letsencrypt.org/stats/ (accessed on 27 November 2022).
- Nearly Half of Malware Now Use TLS to Conceal Communications–Sophos News. Available online: https://news.sophos.com/en-us/2021/04/21/nearly-half-of-malware-now-use-tls-to-conceal-communications/ (accessed on 24 November 2022).
- Nguyen, A.T.; Park, M. Detection of DoH Tunneling Using Semi-Supervised Learning Method. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022; pp. 450–453. [Google Scholar] [CrossRef]
- Wang, P.A.N.; Chen, X.; Ye, F.; Sun, Z. A Survey of Techniques for Mobile Service Encrypted Traffic Classification Using Deep Learning. IEEE Access 2019, 7, 54024–54033. [Google Scholar] [CrossRef]
- Behnke, M.; Briner, N.; Cullen, D.; Schwerdtfeger, K.; Warren, J.; Basnet, R.; Doleck, T. Feature Engineering and Machine Learning Model Comparison for Malicious Activity Detection in the DNS-Over-HTTPS Protocol. IEEE Access 2021, 9, 129902–129916. [Google Scholar] [CrossRef]
- Venkatesh, B.; Anuradha, J. A Review of Feature Selection and Its Methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Atashgahi, Z.; Sokar, G.; van der Lee, T.; Mocanu, E.; Mocanu, D.C.; Veldhuis, R.; Pechenizkiy, M. Quick and Robust Feature Selection: The Strength of Energy-Efficient Sparse Training for Autoencoders; Springer: New York, NY, USA, 2022; Volume 111, ISBN 0123456789. [Google Scholar]
- Tang, J.; Alelyani, S.; Liu, H. Feature Selection for Classification: A Review. In Data Classification: Algorithms and Applications; Aggarwal, C.C., Ed.; Taylor & Francis Group: New York, NY, USA, 2014; pp. 37–64. ISBN 9780429102639. [Google Scholar]
- Tong, V.; Tran, H.A.; Souihi, S.; Mellouk, A. A Novel QUIC Traffic Classifier Based on Convolutional Neural Networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Yaacoubi, O. The Rise of Encrypted Malware. Netw. Secur. 2019, 2019, 6–9. [Google Scholar] [CrossRef]
- Hjelm, D. A New Needle and Haystack: Detecting DNS over HTTPS Usage; SANS Institute: North Bethesda, MD, USA, 2021. [Google Scholar]
- Piskozub, M.; De Gaspari, F.; Barr-smith, F.; Martinovic, I. MalPhase: Fine-Grained Malware Detection Using Network Flow Data. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security (ASIA CCS ’21), Hong Kong, China, 7–11 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, pp. 774–786. [Google Scholar]
- Singh, A.P.; Singh, M. A Comparative Review of Malware Analysis and Detection in HTTPs Traffic. Int. J. Comput. Digit. Syst. 2021, 10, 111–123. [Google Scholar] [CrossRef]
- Hynek, K.; Vekshin, D.; Luxemburk, J.A.N.; Wasicek, A.; Member, S. Summary of DNS Over HTTPS Abuse. IEEE Access 2022, 10, 54668–54680. [Google Scholar] [CrossRef]
- Cerna, S.; Guyeux, C.; Royer, G.; Chevallier, C.; Plumerel, G. Predicting Fire Brigades Operational Breakdowns: A Real Case Study. Mathematics 2020, 8, 1383. [Google Scholar] [CrossRef]
- Sobolewski, R.A.; Tchakorom, M.; Couturier, R. Gradient Boosting-Based Approach for Short- and Medium-Term Wind Turbine Output Power Prediction. Renew. Energy 2023, 203, 142–160. [Google Scholar] [CrossRef]
- Arcolezi, H.H.; Cerna, S.; Couchot, J.F.; Guyeux, C.; Makhoul, A. Privacy-Preserving Prediction of Victim’s Mortality and Their Need for Transportation to Health Facilities. IEEE Trans. Ind. Inform. 2022, 18, 5592–5599. [Google Scholar] [CrossRef]
- Hashemi, S.K.; Mirtaheri, S.L.; Greco, S. Fraud Detection in Banking Data by Machine Learning Techniques. IEEE Access 2023, 11, 3034–3043. [Google Scholar] [CrossRef]
- Amiri, P.A.D.; Pierre, S. An Ensemble-Based Machine Learning Model for Forecasting Network Traffic in VANET. IEEE Access 2023, 11, 22855–22870. [Google Scholar] [CrossRef]
- Scott, M.; Lundberg, S.-I.L. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 1208–1217. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable Machine-Learning Predictions for the Prevention of Hypoxaemia during Surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Zhong, S.; Fu, X.; Lu, W.; Tang, F.; Lu, Y. An Expressway Driving Stress Prediction Model Based on Vehicle, Road and Environment Features. IEEE Access 2022, 10, 57212–57226. [Google Scholar] [CrossRef]
- Alani, M.M.; Awad, A.I. PAIRED: An Explainable Lightweight Android Malware Detection System. IEEE Access 2022, 10, 73214–73228. [Google Scholar] [CrossRef]
- Li, Z. Extracting Spatial Effects from Machine Learning Model Using Local Interpretation Method: An Example of SHAP and XGBoost. Comput. Environ. Urban Syst. 2022, 96, 101845. [Google Scholar] [CrossRef]
- Banadaki, Y.M. Detecting Malicious DNS over HTTPS Traffic in Domain Name System Using Machine Learning Classifiers. J. Comput. Sci. Appl. 2020, 8, 46–55. [Google Scholar] [CrossRef]
- Jafar, M.T.; Al-fawa, M.; Al-hrahsheh, Z.; Jafar, S.T. Analysis and Investigation of Malicious DNS Queries Using CIRA-CIC-DoHBrw-2020 Dataset. Manch. J. Artif. Intell. Appl. Sci. 2021, 2, 65–70. [Google Scholar]
- Zebin, T.; Rezvy, S.; Luo, Y. An Explainable AI-Based Intrusion Detection System for DNS Over HTTPS (DoH) Attacks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2339–2349. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Mitchell, R.; Adinets, A.; Rao, T.; Frank, E. XGBoost: Scalable GPU Accelerated Learning. arXiv 2018, arXiv:1806.11248. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Tree Methods. Available online: https://xgboost.readthedocs.io/en/stable/treemethod.html (accessed on 26 November 2022).
- Mitchell, R.; Frank, E. Accelerating the XGBoost Algorithm Using GPU Computing. PeerJ Comput. Sci. 2017, 3, e127. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Shapley, L.S. Notes on the N-Person Game–I: Characteristic-Point Solutions of the Four-Person Game; RAND Corporation: Santa Monica, CA, USA, 1951. [Google Scholar]
- Yang, J. Fast TreeSHAP: Accelerating SHAP Value Computation for Trees. arXiv 2021, arXiv:2109.09847. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- DoHBrw 2020 Datasets. Available online: https://www.unb.ca/cic/datasets/dohbrw-2020.html (accessed on 25 November 2022).
- Kryo.Se: Iodine (IP-over-DNS, IPv4 over DNS Tunnel). Available online: https://code.kryo.se/iodine/ (accessed on 26 November 2022).
- GitHub-Alex-Sector/Dns2tcp. Available online: https://github.com/alex-sector/dns2tcp (accessed on 26 November 2022).
- GitHub-Iagox86/Dnscat2. Available online: https://github.com/iagox86/dnscat2 (accessed on 26 November 2022).
- GitHub-Ahlashkari/DoHLyzer: DoHlyzer Is a DNS over HTTPS (DoH) Traffic Flow Generator and Analyzer for Anomaly Detection and Characterization. Available online: https://github.com/ahlashkari/DoHlyzer (accessed on 26 November 2022).
- Kaggle. State of Data Science and Machine Learning 2021. Available online: https://www.kaggle.com/kaggle-survey-2021 (accessed on 26 November 2022).
- Nkurikiyeyezu, K.; Yokokubo, A.; Lopez, G. Effect of Person-Specific Biometrics in Improving Generic Stress Predictive Models. Sensors Mater. 2020, 32, 703. [Google Scholar] [CrossRef]
- Montazerishatoori, M.; Davidson, L.; Kaur, G.; Habibi Lashkari, A. Detection of DoH Tunnels Using Time-Series Classification of Encrypted Traffic. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 63–70. [Google Scholar]
- Ding, S.; Zhang, D.; Ge, J.; Yuan, X.; Du, X. Encrypt DNS Traffic: Automated Feature Learning Method for Detecting DNS Tunnels. In Proceedings of the 2021 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), New York, NY, USA, 30 September–3 October 2021; pp. 352–359. [Google Scholar] [CrossRef]
- Mitchell, R.; Frank, E.; Holmes, G. GPUTreeShap: Massively Parallel Exact Calculation of SHAP Scores for Tree Ensembles. PeerJ Comput. Sci. 2022, 8, e880. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | C (1, 1) = 1 | C (0, 1) = n/p |
| Actual Negative | C (1, 0) = 1 | C (0, 0) = 1 |
| Model | TTT | TTD |
|---|---|---|
| LR | ||
| SVM | ||
| RF | ||
| XGB |
| Category | Feature Name |
|---|---|
| Flow Direction | F1: Source IP, F2: Destination IP, F3: Source Port, F4: Destination Port. |
| Packet Bytes | F5: Duration, F6: Number of flow bytes sent, F7: Rate of flow bytes sent, F8: Number of flow bytes received, F9: Rates of flow bytes received. |
| Packet Length | F10: Mean, F11: Median, F12: Mode, F13: Variance, F14: Standard deviation, F15: Coefficient of variation, F16: Skew from median, F17: Skew from mode. |
| Packet Time | F18: Mean, F19: Median, F20: Mode, F21: Variance, F22: Standard Deviation, F23: Coefficient of variation, F24: Skew from median, F25: Skew from mode |
| Request/response time difference | F26: Mean, F27: Median, F28: Mode, F29: Variance, F30: Standard Deviation, F31: Coefficient of variation, F32: Skew from median, F33: Skew from mode. |
| Layer 1: Classification of HTTPS Traffics | |
|---|---|
| Class | Sample size |
| NonDoH | 897,493 |
| DoH | 269,643 |
| Layer 2: DoH Characterization | |
| Benign DoH | 19,807 |
| Malicious DoH | 249,836 |
| Methods | AUCPR/ROC | F1 | P | R | TTT(s) | TTD(s) | Features |
|---|---|---|---|---|---|---|---|
| Layer 1: Classification of HTTPS into DoH and NonDoH | |||||||
| LSTM [76] | - | 99.3 | 99.3 | 99.3 | - | 0.574 | 3 |
| LGBM [36] * | 99.9 | 99.9 | 99.9 | 99.9 | 87 | 0.08 | 27 |
| Decision tree, random forest [58] * | [98, 1] | - | - | - | [11.9,31.7] | [0.041,0.216] | - |
| XTS (proposed framework) | 99.99 | 99.96 | 99.94 | 99.99 | 1.8 | 0.07 | 3 |
| Layer 2: DoH characterization into Malicious DoH and Benign DoH | |||||||
| LSTM [76] | - | 99.1 | 99.1 | 99.1 | - | 0.502 | 5 |
| LGBM [36] * | 99.9 | 99.9 | 99.9 | 99.9 | 40 | 0.08 | 27 |
| ABG-VAE [77] | - | 99.4 | 99.2 | 99.6 | 12.24 | 1.1 | - |
| Decision tree, random forest [58] * | [1, 1] | - | - | - | [72.24,118.78] | [0.098,0.586] | - |
| XTS (proposed framework) | 1 | 1 | 1 | 1 | 0.7 | 0.016 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Irénée, M.; Wang, Y.; Hei, X.; Song, X.; Turiho, J.C.; Nyesheja, E.M. XTS: A Hybrid Framework to Detect DNS-Over-HTTPS Tunnels Based on XGBoost and Cooperative Game Theory. Mathematics 2023, 11, 2372. https://doi.org/10.3390/math11102372
Irénée M, Wang Y, Hei X, Song X, Turiho JC, Nyesheja EM. XTS: A Hybrid Framework to Detect DNS-Over-HTTPS Tunnels Based on XGBoost and Cooperative Game Theory. Mathematics. 2023; 11(10):2372. https://doi.org/10.3390/math11102372
Chicago/Turabian StyleIrénée, Mungwarakarama, Yichuan Wang, Xinhong Hei, Xin Song, Jean Claude Turiho, and Enan Muhire Nyesheja. 2023. "XTS: A Hybrid Framework to Detect DNS-Over-HTTPS Tunnels Based on XGBoost and Cooperative Game Theory" Mathematics 11, no. 10: 2372. https://doi.org/10.3390/math11102372