1. Introduction
The main aim of this paper is the study of numerical methods that preserve a Lyapunov function of a gradient dynamical system. The solutions, or integral curves, of a gradient system, follow trajectories that are tangent to a scalar function of the states, which is usually known as the Lyapunov function of the system. The flow of a gradient system has a rather simple qualitative behavior, e.g., all isolated minima of the Lyapunov function are asymptotically stable equilibria of the system. Dynamical analysis by Lyapunov’s method is a well-established discipline, and plenty of references abound on the topic [
1,
2,
3,
4]. The Lyapunov function has the remarkable property that it is decreasing along trajectories of the dynamical system. Gradient systems are pervasive, both as models of physical systems and as representations of mathematical algorithms. For example, an ideal pendulum is a conservative system, namely the energy is a constant magnitude, but every actual mechanical system dissipates energy due to friction, until all potential and kinetic energies vanish, thus, energy acts as the Lyapunov function of the system. Remarkably, many mathematical algorithms are formulated in continuous time whose operation is based on the existence of the Lyapunov function, for example, in the fields of optimization, estimation, and control [
5,
6,
7,
8,
9].
Numerical methods for the integration of Ordinary Differential Equations (ODEs) constitute a well-established field [
10], and methods that provide rather accurate solutions for a wide variety of problems have long been known. However, no matter how small the approximation error of a numerical method is, it can lead to a solution that does not portray the qualitative features of the continuous model, when the integration extends through long time periods. A classic example is the Kepler problem [
11], whose approximate solutions by conventional numerical methods do not respect the elliptical orbits describing the motion of the planets, as established by Kepler’s first law. The inability of basic numerical methods to reflect crucial qualitative properties of dynamical systems led to the development of a new approach, namely
Geometric Numerical Integration [
12], which is an active line of research that links the methodology of dynamical systems analysis to the design of numerical methods [
13] that preserve the qualitative properties of the continuous system. In this regard, the main objective is to consider the qualitative characteristics of the trajectories of the dynamical system, for example, energy decreasing, stability, and conservation of the Hamiltonian, among others. The task would then be the design of numerical methods so that the discrete trajectories of the method have the same properties as the exact solutions.
Within the field of Geometric Numerical Integration, there exists a substantial number of results concerning the study of systems with
first integrals [
14,
15,
16]. A differential geometric approach to this topic implies the discretization of Hamiltonian systems [
17], since in a system with a conserved quantity, a symplectic form can always be defined. Among the number of methods defined for this class of systems, symplectic and projection methods have been well studied [
12]. However, when it comes to the conservation of the Lyapunov function of a gradient dynamical system, the choice is limited—to the best of our knowledge—to three categories: discrete gradient methods [
18], projection methods [
19], and particular instances of Runge–Kutta methods [
20]. The inattention to stability issues is striking since the dynamic analysis of ODEs is far from new in the field of numerical analysis. Indeed, the concept of A-stability [
21] amounts to the preservation of the stability of the solution of linear scalar equations as test systems. In this regard, the conservation of the Lyapunov function can be viewed as a generalization of the concept of A-stability in a nonlinear context.
Projection methods [
19] inherit the design of analogous methods for Hamiltonian systems, which are based upon projecting the approximate solution onto the manifold that the trajectories of the exact solutions lie in. Although the formulation of these methods is explicit in principle, they require solving the nonlinear equation that defines the projection at each time step. Moreover, from a conceptual point of view, we think that there is arguably something unsatisfactory in this differential geometric approach, since the Lyapunov function, unlike the Hamiltonian, does not define a manifold, i.e., the distribution of admissible trajectory directions is not integrable. For its part, the application of Runge–Kutta methods to gradient systems [
20] led to proving that some Radau implicit methods, originally proposed for stiff and Hamiltonian systems, are also able to preserve the Lyapunov function under certain conditions and restrictions on the step size. Both projection methods and implicit Runge–Kutta integrators rely on non-constructive theorems, so they cannot guarantee the preservation of the Lyapunov function unless some ad-hoc adjustment of the step size is performed. In summary, although these methods are promising, their implementation is complicated and can lead to a substantial computational cost, so they are not suitable for all situations. It must be emphasized that, rather than advocating against other techniques, our results encourage further attention to discrete gradient methods, at least for particular applications. Nonetheless, some considerations on future lines of research for comparative assessments of all these methods are made in the conclusions.
Discrete gradient methods yield integrators for ODEs, based upon the fact that the equation of a gradient system can be written in linear-gradient form, i.e., as the product of a definite-negative matrix by the gradient of a Lyapunov function. Then, discrete gradient methods can be stated with a simple rationale: define an approximation of the definite-negative matrix and a discrete gradient, which has similar properties to that of the gradient of the Lyapunov function. By construction, these methods lead to an implicitly defined map that, when considered as a discrete dynamical system, preserves the Lyapunov function of the continuous system. Discrete gradient methods for systems with Lyapunov functions have been described mostly as an aside of methods for Hamiltonian systems [
14,
16,
18,
22]. Thus the development of discrete gradient methods for dissipative, rather than conservative, systems is limited, and examples of systematic application to real systems are hardly found in the literature, as far as we know. In previous work, we explored the application of discrete gradient methods to a particular system, namely Hopfield neural networks [
23,
24], which are computational methods used for optimization.
The main novelty of this paper is the contribution towards establishing a general systematic methodology for the development of discrete gradient methods, specifically tailored for systems with a Lyapunov function. After a review of the background about discrete gradient methods in
Section 2, the contribution of this paper begins in
Section 3, where we describe the methodology of implementation of discrete gradient methods, analyzing the order of the obtained method and illustrating its main properties by means of simple examples. Then, in
Section 4, we present some systematic numerical experiments showing the performance of the proposed technique, and comparing its performance to standard Runge–Kutta methods. As a result, some favorable properties of the obtained method are brought to light. Finally, some conclusions and lines for further research are stated in
Section 5.
3. Construction and Analysis of Discrete Gradient Methods
Once the parameters
and
have been set, a particular instance of discrete gradient method results by substituting this parameter choice into Equation (
4). This is a critical design process as there is a wide range of definitions that are compatible with the conditions given by Equations (
3) and (
5). In this section, we aim to contribute a first step toward the analysis of different parameter choices, with no claim to be exhaustive
3.1. Metric Matrix
Our usage of the name
metric matrix to refer to the negative-definite matrix
, derives from the fact that every system in linear-gradient form is indeed a gradient system for some metric [
27]. The matrix
is, in this formulation, the expression in some coordinates of the corresponding metric tensor, with a changed sign.
The range of freedom for choosing the matrix within Definition 3 is very wide. To begin with, the trivial choice is possible, where the dependence on the next step is neglected. A less radical simplification results when dismissing the step size h in the definition of . We adopt this latter assumption throughout this paper, so we often write for this matrix.
Assuming analyticity of the functions included in the matrix
, it can be expanded as a Taylor series:
where the only requisite for matrices of functions
is that the resulting matrix
is negative-definite. Note that writing higher-order terms would require the cumbersome multi-index notation or the introduction of tensors.
We undertook the application of discrete gradient methods to scalar linear ODEs
, mimicking the classical analysis of L-Stability. Such systems are obviously in linear-gradient form by setting constant
and the Lyapunov function
. As explained below, the discrete gradient is unique in the scalar case, and the trivial choice
leads to the well-known, second-order trapezoidal rule. With the aim of determining conditions for achieving higher order, we substituted the expansion in Equation (
6) into a discrete gradient method and compared the result with the expansion of the exact solution
. The result was negative in the sense that no choice of matrices
can provide an order higher than two unless the matrix
is also dependent on the step size
h. In fact, the only second-order method is the trapezoidal rule itself, arising from
, i.e., the trivial choice
. This discouraging result suggests that the search for optimal methods should not be guided exclusively by order conditions in general cases. Contrarily, we think that discrete gradient methods are well suited to particular classes of systems, where the preservation of dynamical properties is aimed rather than order alone.
Keeping the analysis within the one-dimensional case, but now allowing the matrix
of the continuous system to be non-constant, the above expansion leads to the second-order condition:
This result suggests some formulas where the role of the variables
is symmetrical, such as
Interestingly, only based on empirical arguments, we adopted the latter setting in our analysis of Hopfield neural networks [
24].
The rigorous foundation of the analysis of discrete gradient methods according to the choice of the metric matrix is a problem still open, to the best of our knowledge, and an interesting avenue for further research.
3.2. Discrete Gradient
With regard to the discrete gradient, there is a unique discrete gradient for one-dimensional systems, and it is given by
However, in higher dimensions, a wide variety of discrete gradients exist (see [
18] and references therein). Some of the most commonly used include:
The mean value discrete gradient:
The midpoint discrete gradient:
The coordinate increment discrete gradient also called the Itoh–Abe discrete gradient [
28]:
where a particular ordering
of the coordinates of the vector
is assumed.
As mentioned in [
18], both the mean value and the midpoint discrete gradient are second-order approximations to
, whereas the coordinate increment discrete gradient only provides a first-order approximation to the midpoint of the segment between the points
and
. However, it is not clear whether this property translates into a higher-order method or is somehow relevant in practice. The coordinate increment discrete gradient can be interpreted as a piecewise linear path joining
and
, each piece parallel to one of the coordinate axes, rather than along the straight segment
. In this paper, we will focus on the
coordinate increment discrete gradient because it is easier to implement computationally. The mean value discrete gradient requires the computation of
n integrals, whereas the application of the midpoint discrete gradient leads to a rather complicated expression for the method. In contrast, the coordinate increment discrete gradient results in explicit methods for some systems, such as Hopfield neural networks, where the matrix
L is diagonal, and the Lyapunov function is multilinear. Nevertheless, the analysis and comparison of different discrete gradients well deserves more attention.
In the rest of this section, we undertake a study of discrete gradient methods, first by a preliminary order analysis, then by constructing different methods for simple scalar systems (this methodology is inspired by [
29]) and observing that a suitable choice of the matrix
allows in some cases for rewriting the method in explicit form.
3.3. Order Analysis
The order of the obtained numerical method can be studied by the usual systematic procedure [
10]: comparing the Taylor series expansion around
of both the exact solution of the system of differential equations and the approximate solution obtained by the numerical method. Note that the discrete gradient method is consistent by construction [
18], so it achieves at least order one, i.e., the error after a single step is given by
, where
C is the error constant of the method. A straightforward—but tedious—computation yields the error constant of the second order term:
where
is the Jacobian matrix of
f at
:
and
is the Jacobian of
, i.e.,:
so that the condition
would ensure that the obtained discrete gradient method is second order. In principle, a suitable choice of parameters
and
could lead to a higher-order method. When this paper was already in preparation, a systematic analysis of discrete gradient methods was published [
22], although in the somewhat different context of Hamiltonian systems. Adapting this framework to gradient-like systems is an interesting avenue for future research. Nevertheless, it must be emphasized that the search for higher accuracy, without any other consideration, defeats the purpose of structure-preserving methods. In this paper, we will not further pursue the analysis of order and error, focusing on the preservation of the Lyapunov function and stability.
3.4. The Scalar Linear ODE
For the purpose of illustration, in this section, we show the mechanism of obtaining a discrete gradient method as described above. As a case in point, consider the scalar linear homogeneous ODE:
with
. By direct integration, it is straightforward to compute the analytical solution
, which shows that the origin is asymptotically stable whenever
, since
. We can also state that
is a Lyapunov function for this system because:
for all
. To construct a discrete gradient method, the equation is cast into linear-gradient form, thus, obtaining the definitions
,
. Therefore, the discrete gradient is
and, with the trivial choice
, the discrete gradient method results:
Now it is obvious that, in this case, the discrete gradient method turns out to be simply the trapezoidal rule, which is a second-order method. The fact that the trapezoidal rule preserves the stability of scalar linear ODEs for any step size h is already explained by the classical theory of numerical methods for stiff systems since it is well-known that the trapezoidal rule is A-stable, thus, nothing new seems to be provided by the proposal of discrete gradient methods. However, the point is that the choice of the matrix is not unique, so a different definition , possibly depending on and h, would lead to a different method. In addition, if we are not interested in preserving a particular Lyapunov function, but only the qualitative stability of the system, we could choose a different Lyapunov function, thus, leading to a different discrete gradient method.
3.5. The Logistic Equation
Consider next the IVP given by the generalization of the usually called logistic differential equation:
By straightforward integration, the exact solution can be computed:
for any initial condition
, whereas the trivial solution
involves a fixed point. We also choose
to avoid the need to consider unbounded solutions. There are several ways to check that the equilibrium
is asymptotically stable, for example, the Jacobian of the ODE given by Equation (
17) is negative at
or the limit when
of the exact solution given by Equation (
18) is 1.
The construction of a discrete gradient method as in Equation (
4) requires, first, writing the system in linear-gradient form from the knowledge of a Lyapunov function
V; and then choosing the method parameters,
and
, while fulfilling the conditions that guarantee the consistency of the method. Interestingly, even such a simple example as the logistic ODE can lead to completely different discrete gradient methods.
Firstly, observe that the function
fulfills the conditions required by Definition (1) to be a Lyapunov function. In particular, its time derivative is
whenever
. Therefore,
V is a Lyapunov function of Equation (
17) at
that is valid for any initial value
. Then, the ODE can be rewritten in linear-gradient form as in Equation (
2) by defining
, so that the system is expressed as
with
negative-definite for
, as required. Then, the discrete gradient is defined by the unique choice existing in the scalar case:
The last equality of Equation (
21) has been included to point out a plausible interpretation of the discrete gradient as a sort of
midpoint gradient, since it is identical to the gradient of
V, replacing the variable
y with the average
. With regard to the choice of
, there are several consistent options. For simplicity, we adopt the trivial setting
. Therefore, if we substitute the chosen parameters in Equation (
4), the method is obtained:
which after straightforward algebra yields an explicit expression for
z:
In this particular case, the choice of has allowed for obtaining an explicit method. However, the procedure has some generality, at least restricted to one-dimensional ODEs: it can be proved that if the Lyapunov function V is quadratic and the matrix is trivially set to , the discrete gradient method can be cast into explicit form.
Remark 2. (Relation to known methods).
Note that apparently Equation (23) cannot be derived as a conventional Runge–Kutta method (although proving this, in general, would require some work). In contrast, the nonlocal
substitution and the use of the discrete gradient remind us of nonstandard finite difference schemes [30], while providing a systematic methodology for their construction. Consider now the function
as a candidate for the Lyapunov function of the same system, and observe that it fulfills the conditions required by Definition (1). In particular, the time derivative is
whenever
. Therefore
V is a Lyapunov function of Equation (
17) for the stable equilibrium point
, which is valid for any initial value
. Then, the ODE can be rewritten in linear-gradient form as in Equation (
2) by defining
so that the linear gradient form
holds too with these new parameters and
is negative-definite, as required. The one-dimensional discrete gradient has the same form as before, but the Lyapunov function
V is different, to begin with, leading to
With regard to the choice of
, for simplicity we again adopt the trivial setting
. Therefore, if we substitute the chosen parameters in Equation (
4), the new method is obtained:
In this case, we obtain an implicit method. In order to apply Newton’s method to obtain the solutions, we can rewrite the method as a function of
z as shown below:
We have implemented the explicit discrete gradient method (DG-E) given by Equation (
23) and the implicit scheme (DG-I) from Equation (
27). Both are applied to the same logistic ODE, choosing the parameter as
and the initial value
. The resulting trajectories are shown in
Figure 1 for different values of the step size
h. When
h is small enough, all methods provide qualitatively correct solutions, as shown in
Figure 1a. Aside from both discrete gradient methods derived above, the Euler rule has been included for comparison. To have a glimpse at the approximation accuracy achieved by each method, the global error has been computed by subtracting the discrete sequence from the exact solution and averaging over all the computed steps. The obtained results for 20 different values of the step size in the interval
are shown in
Figure 1b, in logarithmic scale. Two straight lines with slopes 1 and 2 are added to ease the comparison. It is clear that both the Euler rule and DG-E are first-order methods. Unexpectedly, DG-I turns out to be a second-order method, even though the construction procedure has been identical. As said above, order analysis of discrete gradient methods is an interesting avenue for further research.
The picture changes radically when the step size is increased, even modestly to
. To begin with, the trajectory computed by the Euler rule blows up to infinity, so it is not represented. Remarkably, the problem is not that of insufficient order: we tested an implicit Runge–Kutta method of order 2 (the basis of the
ode23s function in the
Matlab ODE Suite), and it also produced unbounded solutions. This is a significant finding as methods designed for stiff differential equations are often assumed to reproduce better the qualitative behavior, which is not the case here. Regarding the explicit discrete gradient method DG-E, its trajectory remains bounded, at least within the computed range, but the qualitative behavior is completely wrong, as shown in
Figure 1c. Instead of convergence to the equilibrium, undamped oscillations appear that destroy stability. In contrast, the correct behavior is ultimately achieved by DG-I with the same step size, despite an initial transient, plotted in
Figure 1d.
The apparent contradiction between the proved preservation of the Lyapunov function and the oscillatory solution provided by DG-E is explained by the local nature of the chosen Lyapunov function
. The condition
checked in Equation (
19) only holds for
. This fact is dismissed in the original system since the region
cannot be reached from a positive initial value. However, the discretization does take a step so large that the solution becomes negative. Another approach that offers insight into the different behavior of the discretizations is the analysis of the basins of attraction, i.e., the sets of initial values such that trajectories converge towards the equilibrium. Basins of attraction of ODEs are continuous, so the restriction
for the validity of the first Lyapunov function is irrelevant for the continuous system. In contrast, basins of attraction of discrete dynamical systems, such as the one defined by a numerical method, may be formed by disconnected sets. If the discrete steps of the numerical method drive the system to a region where
is no longer true, the discrete gradient construction does not enforce stability. This suggests the first rule that must guide the construction of discrete gradient methods: find a Lyapunov function for which the requirement
holds universally (except for
, of course), or at least, throughout a domain as large as possible.
4. Numerical Experiments
In this section, we show the result of several numerical experiments designed to show the satisfactory performance of the designed discrete gradient method, assessed in terms of its ability to preserve the qualitative properties of the dynamical system. We are primarily interested in preserving the stability of the system, which will be evidenced by decreasing values of the considered Lyapunov function along solution trajectories of the numerical approximation. As a suitable case study, we first propose the Duffing equation [
19], for which a Lyapunov function is known.
The proposed method is compared with three conventional methods: the explicit Euler rule, a second-order Runge–Kutta method (RK2) that forms the basis of the ode23s function in the Matlab ODE Suite), and a fourth-order Runge–Kutta method (RK4), which the Matlab ode45 function is based upon. Note that ode23s is an implicit method, well suited to stiff equations; thus, it is a strong competitor when the preservation of qualitative features is considered, whereas ode45 is an explicit method design with a higher order of accuracy in mind. To carry out a fair comparison among methods, all experiments are carried out with a fixed step size. Needless to say, our work on the implementation of discrete gradient methods will eventually comprise variable step size mechanisms for error control.
For the sake of brevity, we have left aside a number of methods that could eventually have the same stability properties as discrete gradient methods. We have already mentioned the specialized Runge–Kutta methods that preserve the Lyapunov function [
20], with the shortcoming that these favorable properties can only be proved for small enough step size. It is also worth mentioning the family of Rosenbrock–Wanner schemes [
31], which were proposed mainly in the context of Differential-Algebraic Equations. It has been proved that these methods have favorable stability properties when implemented with complex coefficients [
32]. Of particular interest for our work, is that these methods have been applied to the ODEs that result from the spatial discretization of Partial Differential Equation [
33]. The behavior of all these alternative methods is often strongly dependent on time step-adjusting mechanisms, which we tried to avoid in this work, to keep the exposition as simple as possible.
All experiments have been performed with Matlab installed on a laptop equipped with an Intel Core i5-10210U processor at a base frequency of 1.6 GHz, and 8 GB of RAM. Since our aim was a proof of concept and comparison between different methods, we have not carried out an extensive optimization of either the code or the implementation.
The chosen methods are applied to the Duffing equation that can be written as a first-order system of ODEs
according to:
with
and
. The system has three fixed points:
,
, and
. A straightforward linearization shows that
is a saddle point, whereas
and
are stable equilibria. It is known that a Lyapunov function is defined by
which has (local) minima at
and
, since the gradient vanishes and the Hessian of
V is positive definite at both these points. The gradient of
V is the vector field:
that leads to the energy-decreasing condition:
Then, the system can be cast into the linear-gradient form, i.e.:
which entails the definition of the negative-definite matrix
L:
Our implementation starts by computing the coordinate increment discrete gradient for the particular system given by Equation (
28):
whereas we adopt the simplest approximation
. Then, the discrete gradient method results:
This implicit equation for will be solved by Newton iteration until convergence at each time step.
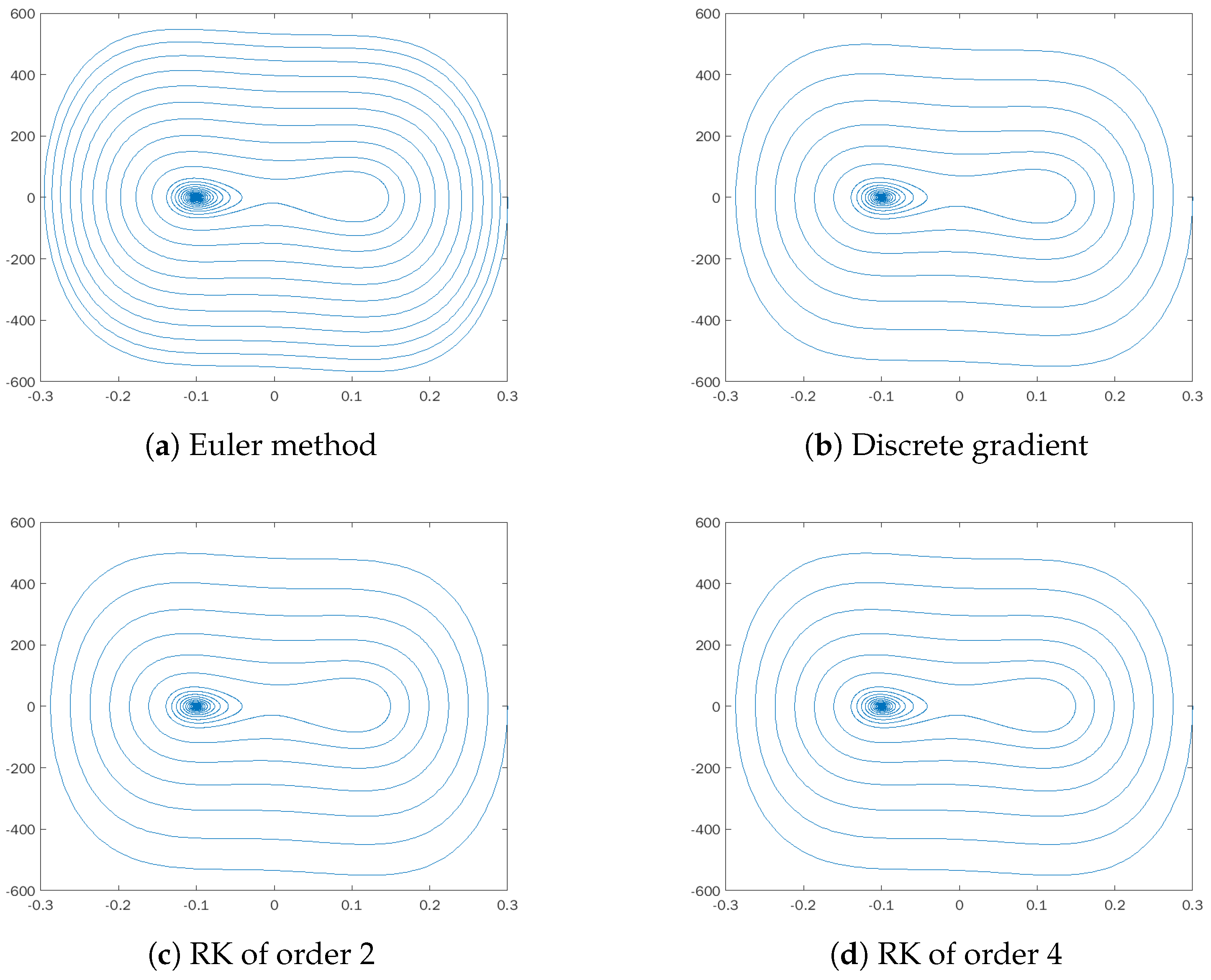
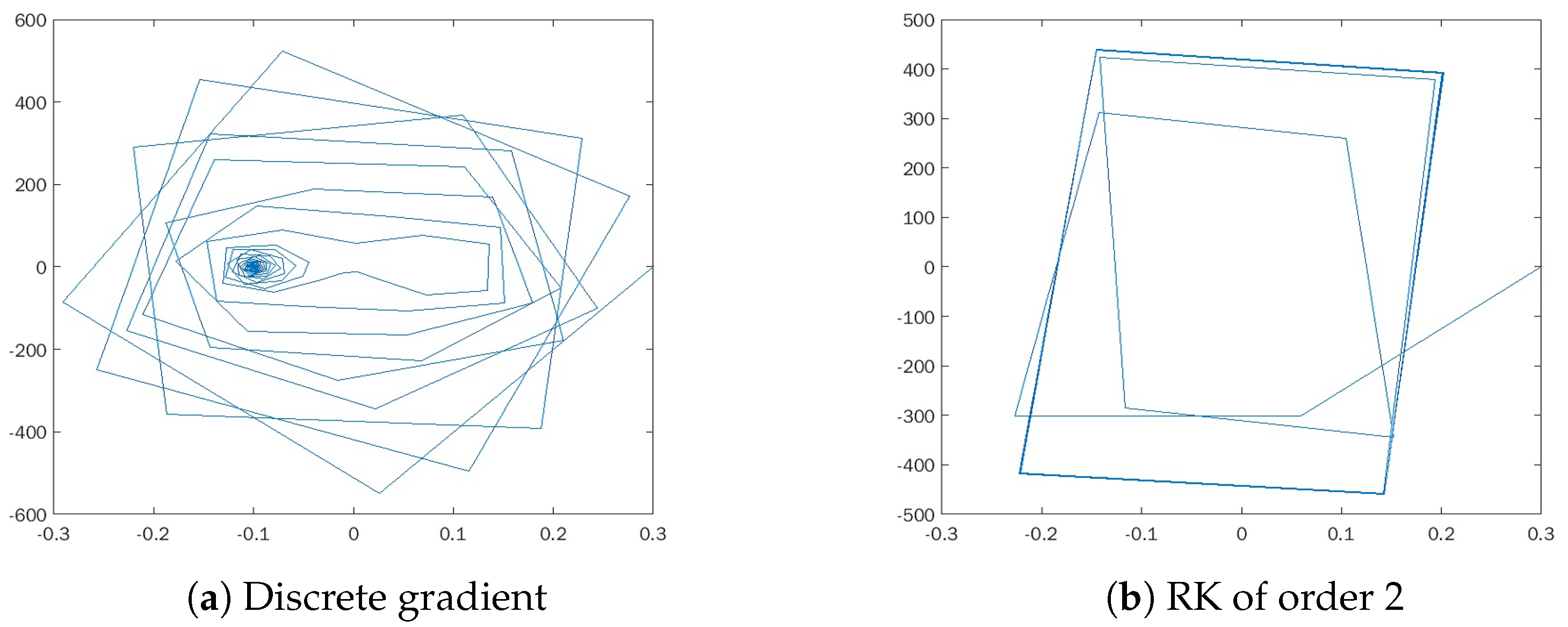
All the experiments have been carried out considering
as the initial point. We have designed three types of experiments. Firstly, we show the phase portrait that is obtained by applying each of the methods for different values of the step size
h and compare it with the exact solution. Contrarily to the simple systems of the previous section, we do not have the benefit of an analytical solution, but we consider that the approximation obtained by Euler’s method with
is exactly up to machine precision. The results of this set of experiments are shown in
Figure 2,
Figure 3 and
Figure 4. It can be seen how the behavior of the discrete gradient method reproduces the phase portrait of the exact solution regardless of the step size. In contrast, Euler’s rule does not converge with step sizes greater than
. As for the Runge–Kutta methods, both the order two and order four schemes fail when working with
. Both explicit methods, Euler and RK4, produce trajectories that blow up towards unbounded values; thus, they are not shown in the figures. This is the case for both methods with
in
Figure 4 and the Euler’s method with
in
Figure 3. Despite Euler’s rule producing a bounded trajectory that converges to the stable equilibrium for a small enough step size, the phase portrait is not correct. It is noticeable in
Figure 2a) that the turns of the trajectory are closer than in other plots, suggesting that the numerical method is introducing a spurious dissipation.
On the other hand, taking into account that the fundamental objective of the designed method is the conservation of the Lyapunov function, we have designed another set of experiments focused on showing the behavior of the Lyapunov function with respect to time.
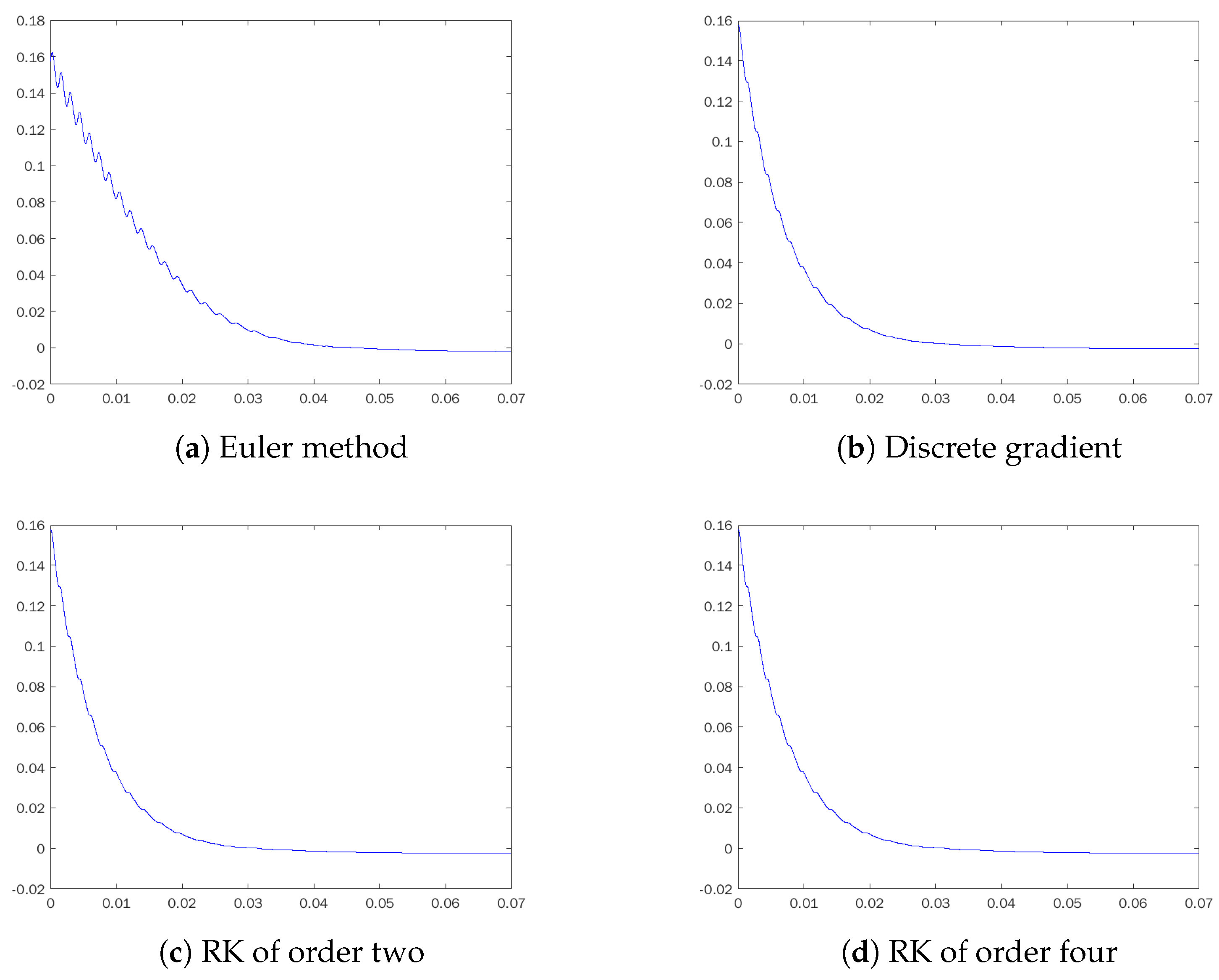
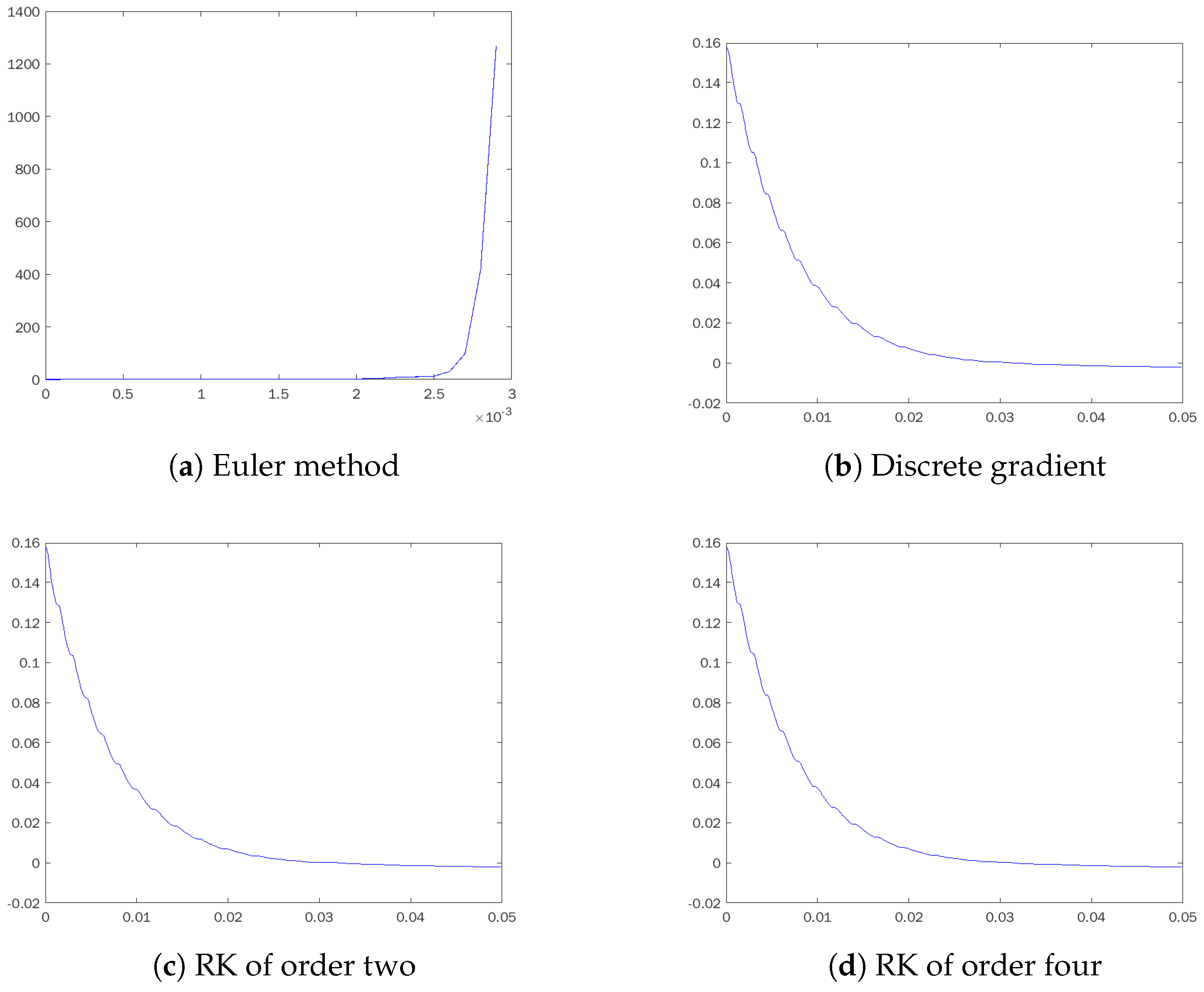
Table 1 shows the values of the maximum increment of
V for each method and each step size used. We also plot in
Figure 5,
Figure 6,
Figure 7 and
Figure 8 the trajectories of the value of
V for different step sizes. In general, it can be seen on the graphs that the Lyapunov function is decreasing along trajectories of the discrete gradient method, as expected by construction. The small positive increments shown in the table are within the range of machine precision, so they are attributed to rounding rather than the numerical method. In contrast, much larger increases in the Lyapunov function are visible in
Figure 6 when using Euler’s method with
, even though for this step size, the trajectories of the solution converge to the equilibrium. For large step sizes such as
, only the implicit RK2 among conventional methods provides bounded trajectories. However, the evolution of
V shown in
Figure 8 reveals, even more clearly than the phase portrait, that the behavior of the system is qualitatively corrupted. Periodic oscillations of
V prove that the system is not approaching equilibrium and the Lyapunov function is no longer decreasing.
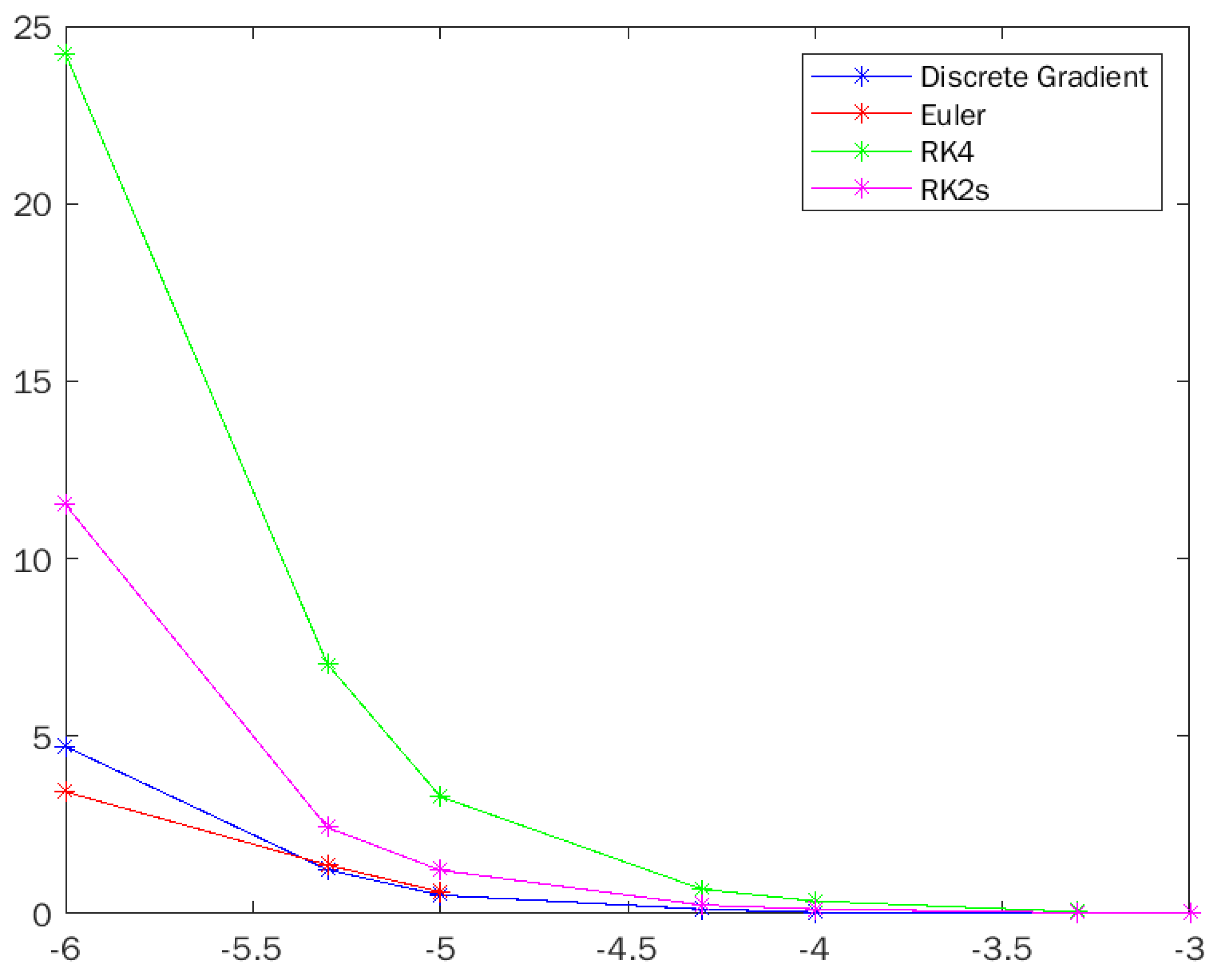
Even when competitor conventional methods converge to a stable equilibrium, the proposed method is favorable in terms of computational cost. This is illustrated in
Figure 9, showing the real computation time for the different step sizes. The computing times are also shown in
Table 1 for each combination of step size and method.
We briefly review the application of discrete gradient methods to a different class of systems, namely those with orbital stability [
25]. In this case, the attractor is not a single point, but a compact subset. Trajectories with initial values within the attractor remain confined to it, which is, thus, termed an invariant set. The Lyapunov function is constant throughout the attractor, whereas its value is higher at any point outside the attractor. As an example of such orbitally stable systems, we propose the following ODE [
34,
35]:
with the Lyapunov function
. We can check that the time derivative of the Lyapunov function is:
and
at the origin and on the circle of unit radius. Consequently, trajectories that start outside the circle approach the circle, whereas trajectories that start inside the circle are attracted to the origin. A continuous trajectory that starts outside cannot traverse the circle, but a discretization step risks
jumping to the interior where the attractor nature of the circle is lost.
It has been shown [
34,
35] that conventional numerical methods produce trajectories that fall into the circle, thus, exhibiting a completely wrong behavior. We have implemented a discrete gradient method for the system in Equation (
33) with the easiest choice
and the coordinate increment discrete gradient. We have set the initial point
. The results are shown in
Figure 10, where a relatively small step size (
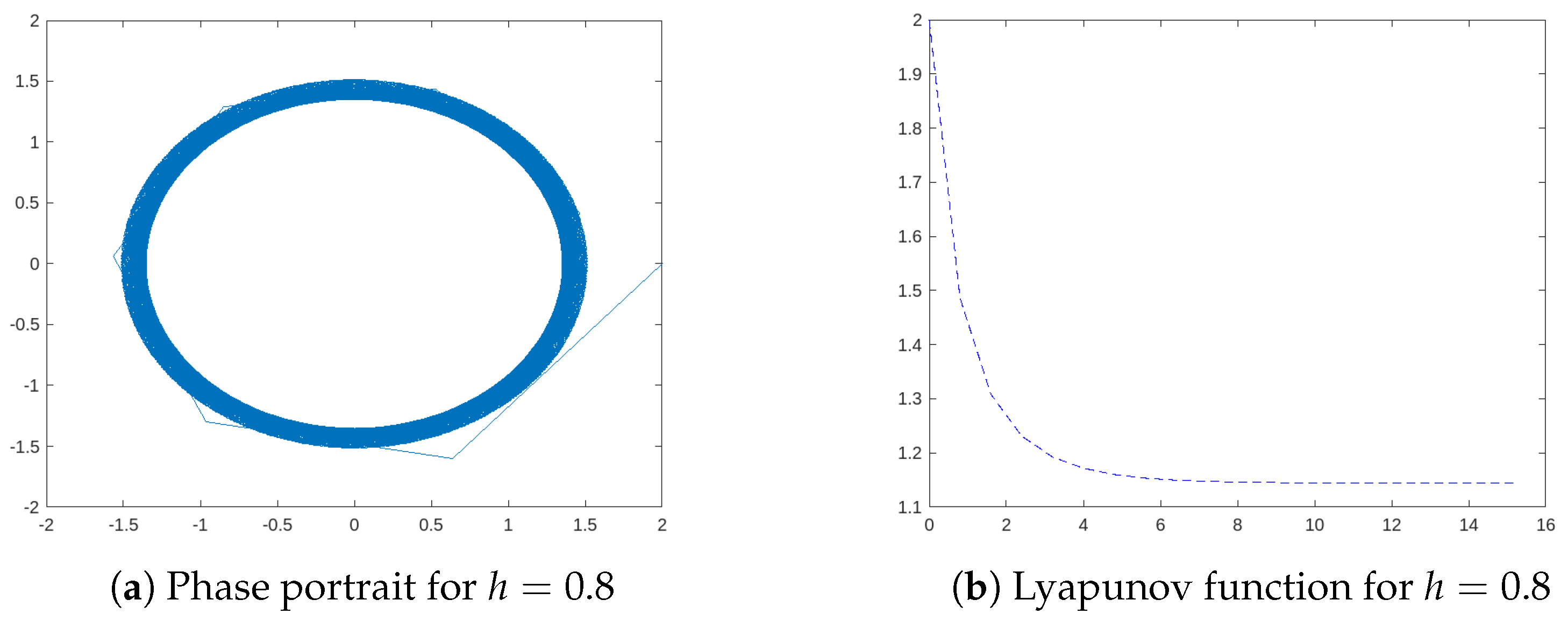
) has been set. It is clear that the trajectory approaches smoothly the circle and gets trapped by it, showing the invariant nature of the attractor. When we implement a large step size
, such large discretization steps cannot reproduce faithfully the circle, as shown in
Figure 11. However, the qualitative behavior is correct, and the trajectory does not fall into the origin, but remains orbiting, thus, reproducing the dynamical properties of the continuous system.
5. Conclusions
We have presented a methodology for the implementation of numerical integrators that preserve a Lyapunov function of a dynamical system, namely discrete gradient methods. The analysis is performed on the proposed method, establishing that it is, in principle, a first-order method, although the second-order term is computed, revealing the conditions for the method parameters under which a second-order method would be obtained. As a proof of concept, a discrete gradient method is applied to the logistic equation, revealing the variety of choices that can lead to different numerical schemes with qualitatively different behaviors. The proposed method has been applied to the integration of the Duffing equation, which is regarded as a suitable test system: different parameter sets lead to oscillatory and stiff systems, whereas the preservation of the Lyapunov function is more important than the accuracy of individual trajectories. Numerical experiments are also carried out to confirm the ability of discrete gradient methods to preserve the Lyapunov function, and the failure of standard Runge–Kutta codes for a wide range of step size values, since Lyapunov function increments occur, thus, stability is lost.
The proposed methodology has a number of shortcomings, first and foremost, the need to know the explicit expression of a Lyapunov function. This is out of the scope of the present work and must be guided by physical considerations. Interestingly, our work proves that different Lyapunov functions for the same system lead to completely different numerical methods. The interaction between results in the context of the application and theoretical results on the methods themselves should lead to further advances in this direction. Another significant limitation is the lack of a general form of the time-stepping formula, which must be derived ad-hoc once given the Lyapunov function. This fact supports the notion that discrete gradient methods will find their role in the integration of particular classes of systems, rather than lead to a commercial code of general applicability.
We are currently engaged in further research to extend the results of this paper in several directions. First, we are developing order conditions to obtain higher-order methods. Preliminary results show that this is possible, at least for order two, by defining the matrix
dependant not only on
and
but also on
h. Another promising line considers composition and splitting techniques. The long-term objective would be to establish a systematic order theory for designing discrete gradient methods of arbitrary orders, in line with the recent paper [
22]. We are also trying to generalize the conditions for obtaining explicit methods, based on the original, implicit formulation.
This work suggests that general-purpose integrators are unable to keep pace with methods specifically designed to preserve the Lyapunov function. Thus we are extending our experiments to compare discrete gradient methods to both projection methods and Radau algorithms. In particular, it has been argued [
20] that Radau methods are favorable due to their superior damping of high frequencies. In our experiments, we have detected that some discrete gradient methods possess an enhanced ability to deal with highly oscillatory systems. This question undoubtedly deserves deeper attention. It also must be taken into account that the results of this paper are a proof of concept, and much more can be done regarding the implementation refinements of discrete gradient methods. The obvious advance is the inclusion of an error control device, which could derive from detecting the lack of convergence of the Newton iteration. An improved discrete gradient method could be a serious competitor in applications where preserving the qualitative dynamical behavior is more important than the stringent accuracy of individual trajectories. For such systems, the integrators that preserve the Lyapunov function for arbitrary step sizes, such as discrete gradient methods, are endorsed as first-line methods by our results.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}