
Reservoir Characterization and Productivity Forecast Based on Knowledge Interaction Neural Network

 , ,
, ,
Abstract
:1. Introduction
2. Methods
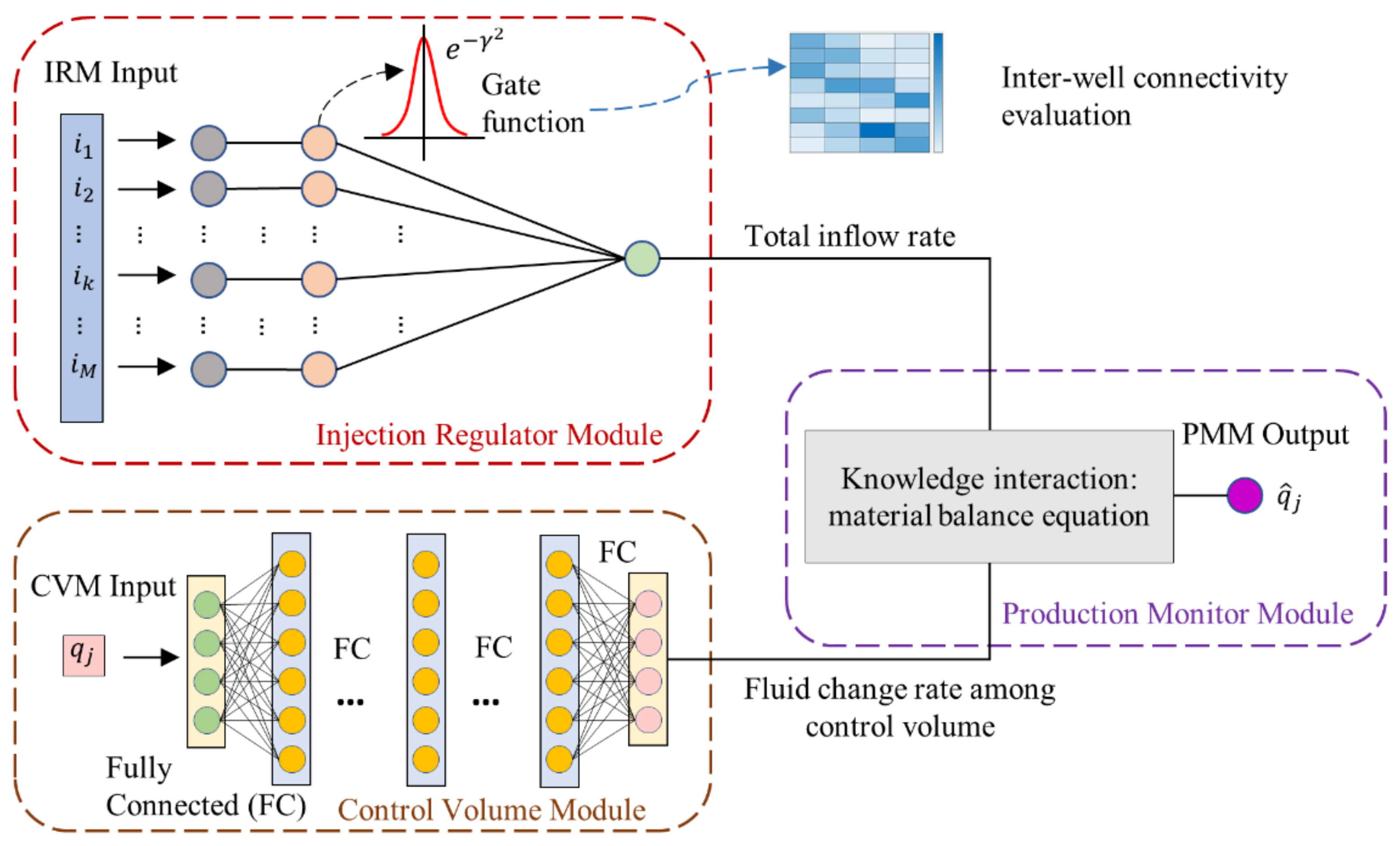
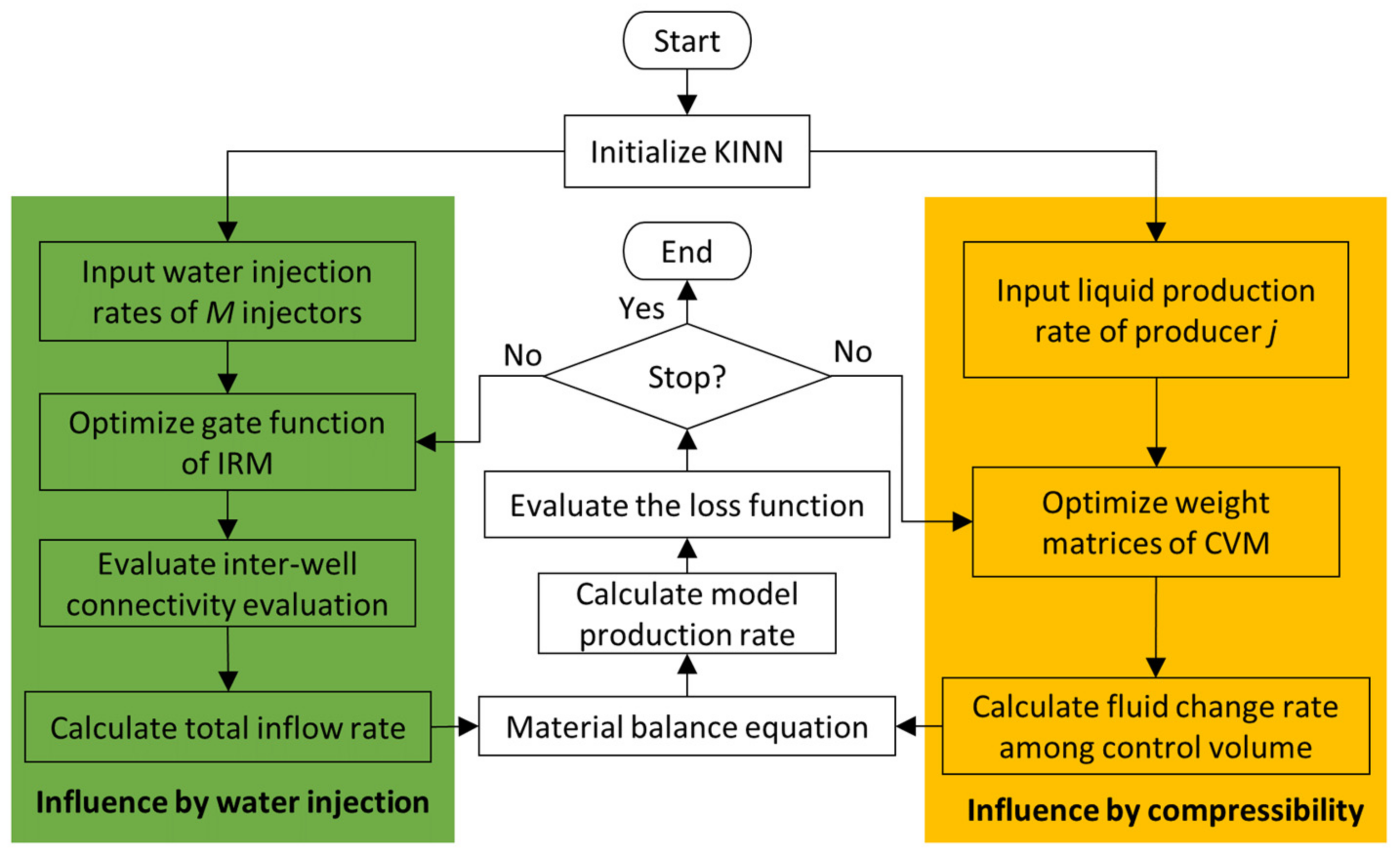
3. Knowledge Interaction Neural Network (KINN)
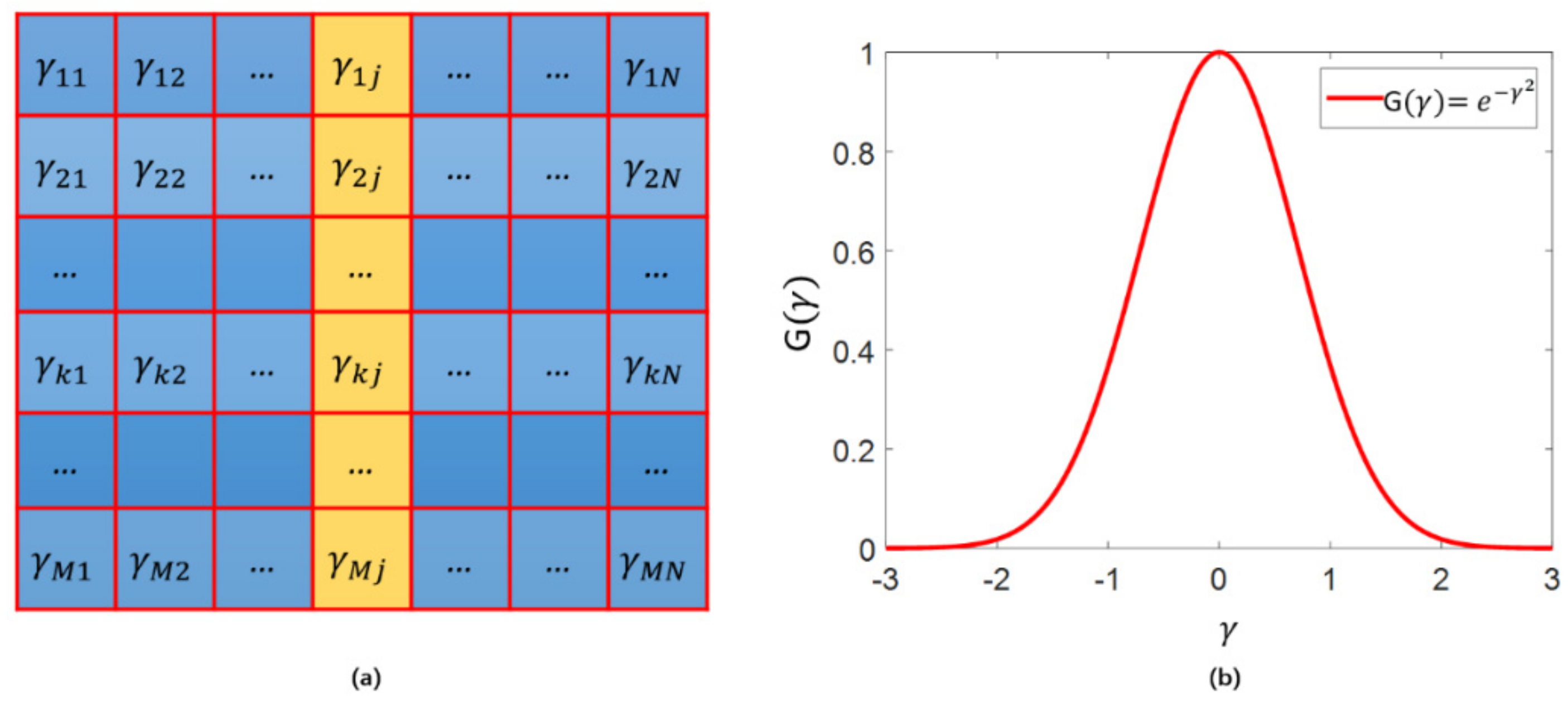
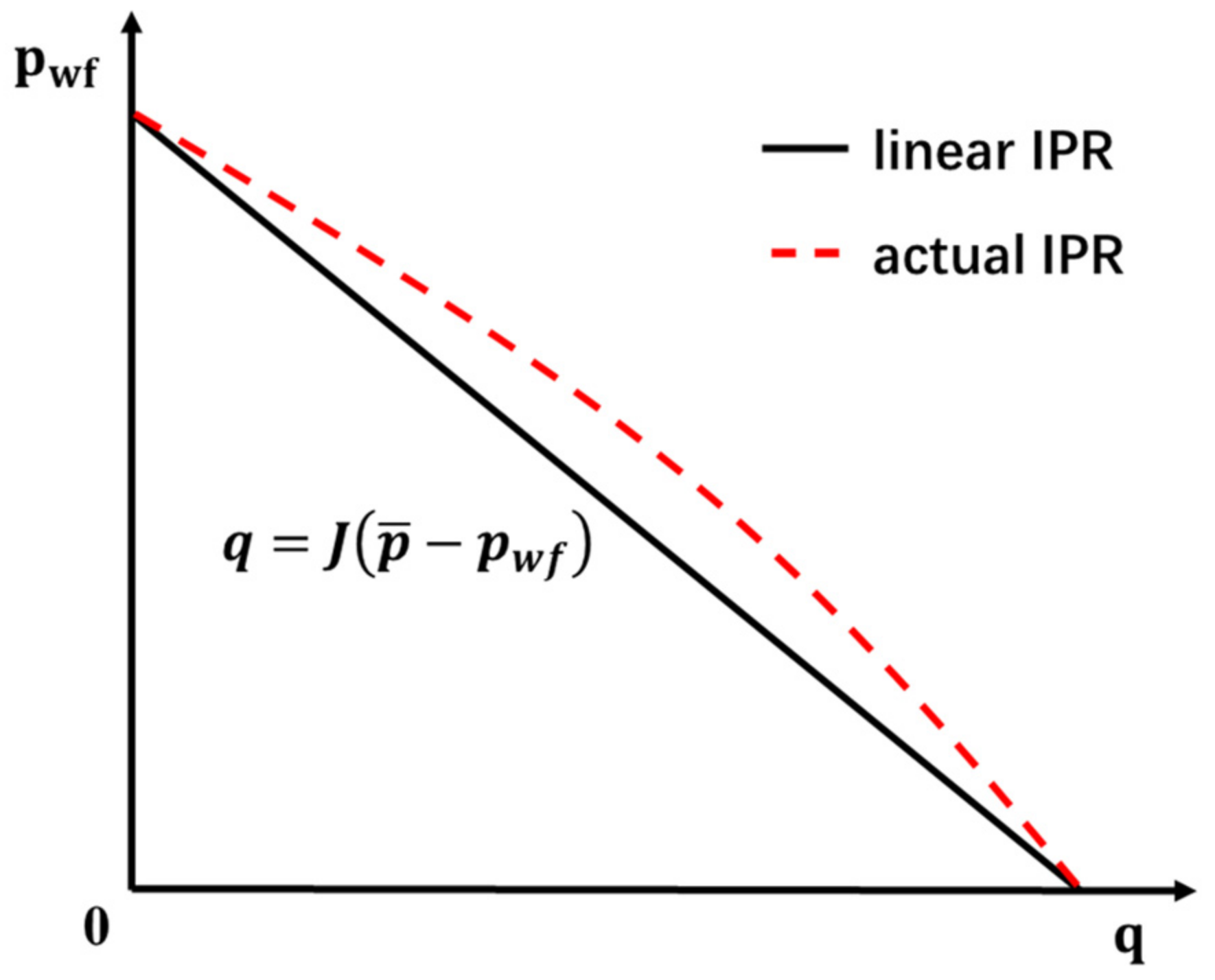
3.1. Injection Regulator Module (IRM)
3.2. Control Volume Module (CVM)
3.3. Production Monitor Module (PMM)
3.4. Reservoir Characterization and Productivity Prediction
| Algorithm 1: Knowledge Interaction Neural Network (KINN) | |
| Input: I, WWIR for M injectors, and Q, WLPR for N producers | |
| Output: | |
| / *** start KINN training *** / | |
| 1 | Initialization: Compute using database I and Q by Equations (6) and (7), and initialize the parameters of ANN in CVM |
| 2 | For = 1 to N do |
| 3 | While convergence tolerance is not met |
4 5 | / *** IRM calculation *** / Select the column, , in as the independent variable of gate function; Calculate the output of IRM, , with and I, using Equation (5) |
6 | / *** CVM calculation *** / Calculate the output of CVM, , with , using Equation (13) |
7 | / *** PMM calculation *** / Calculate the output of PMM,, using Equation (14) |
8 9 10 11 | / *** parameters update *** / Evaluate the loss function using Equation (15) Update and weight matrices of CVM via gradient descent algorithm End While End For / *** end KINN training *** / |
4. Results
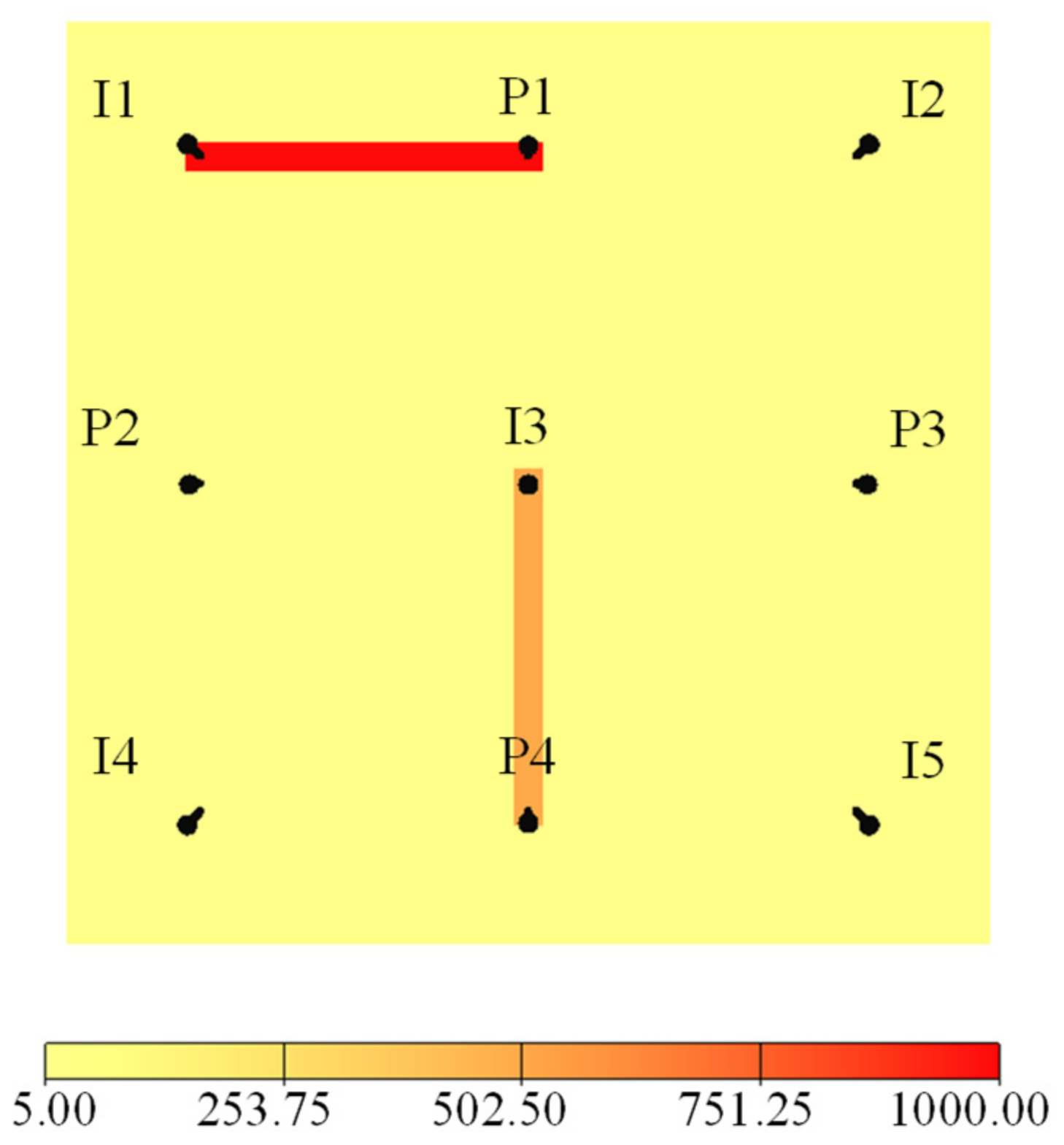
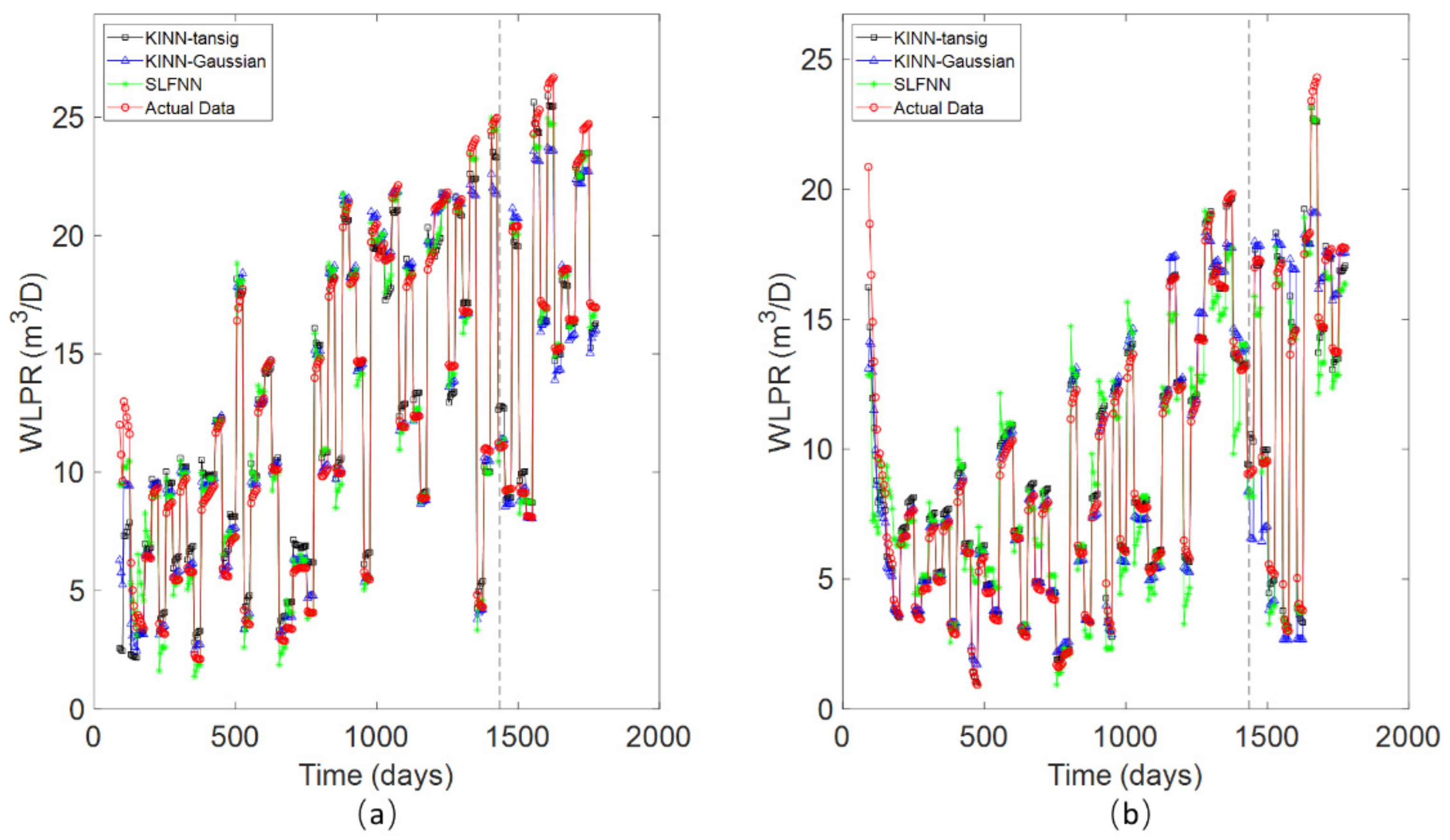
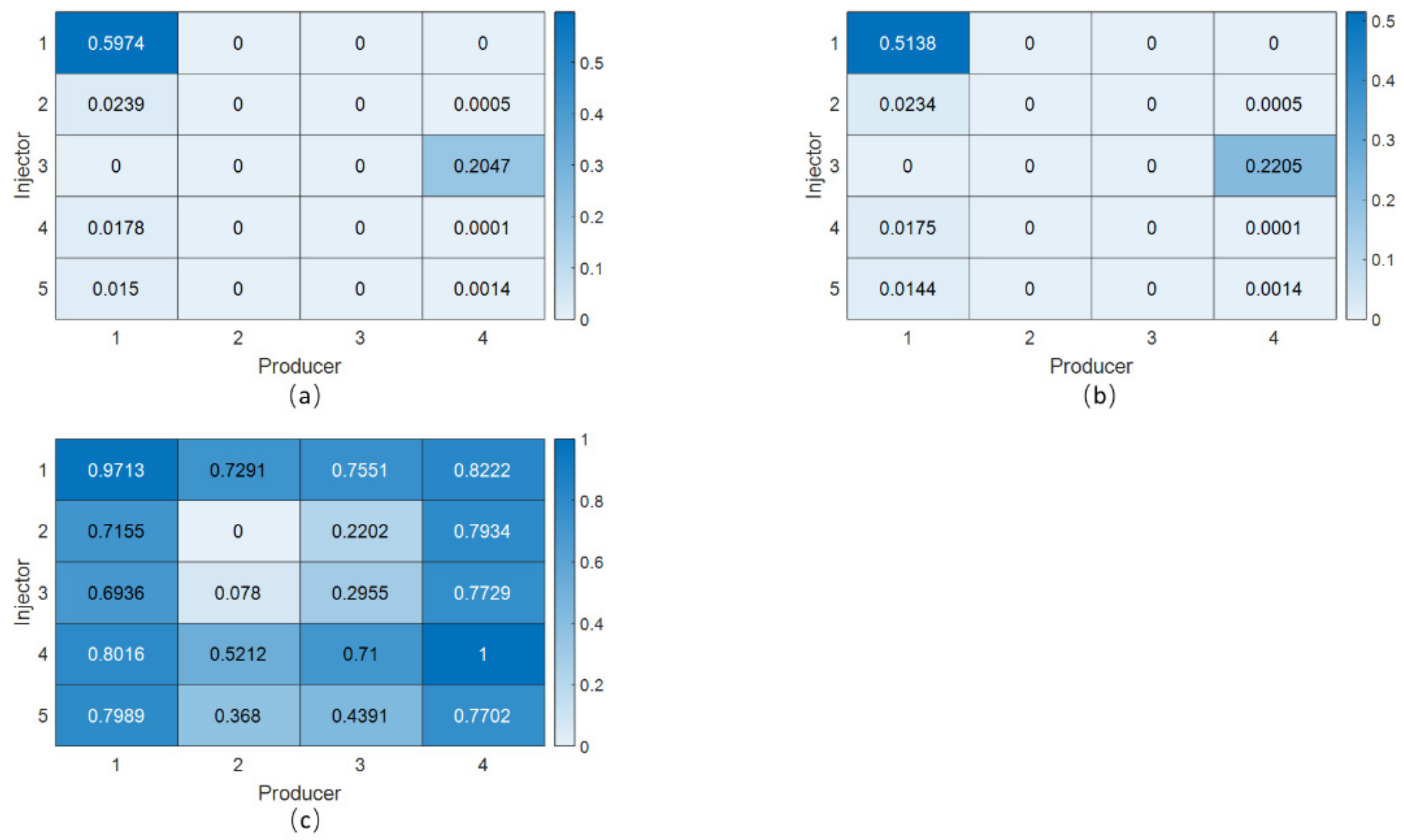
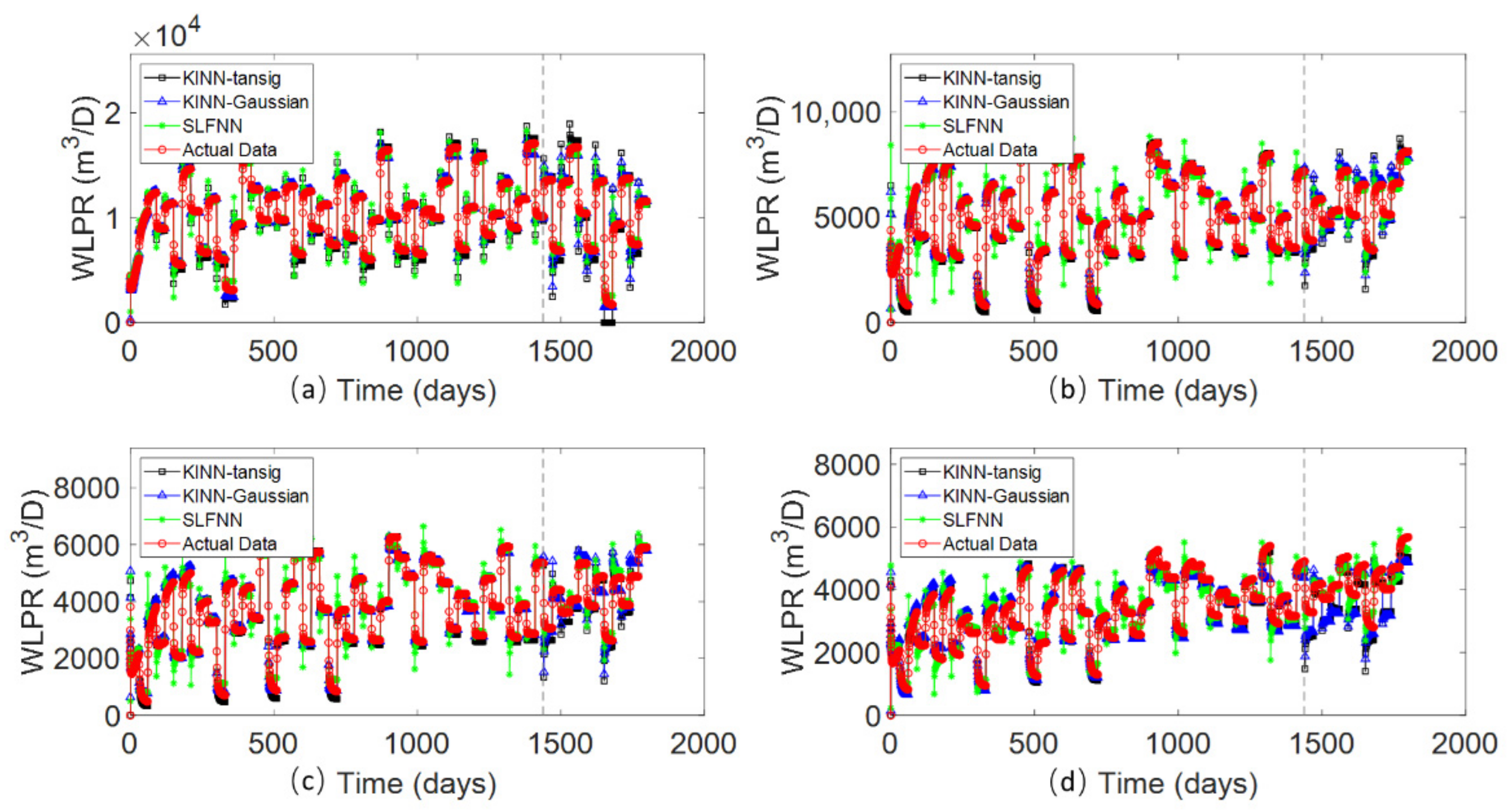
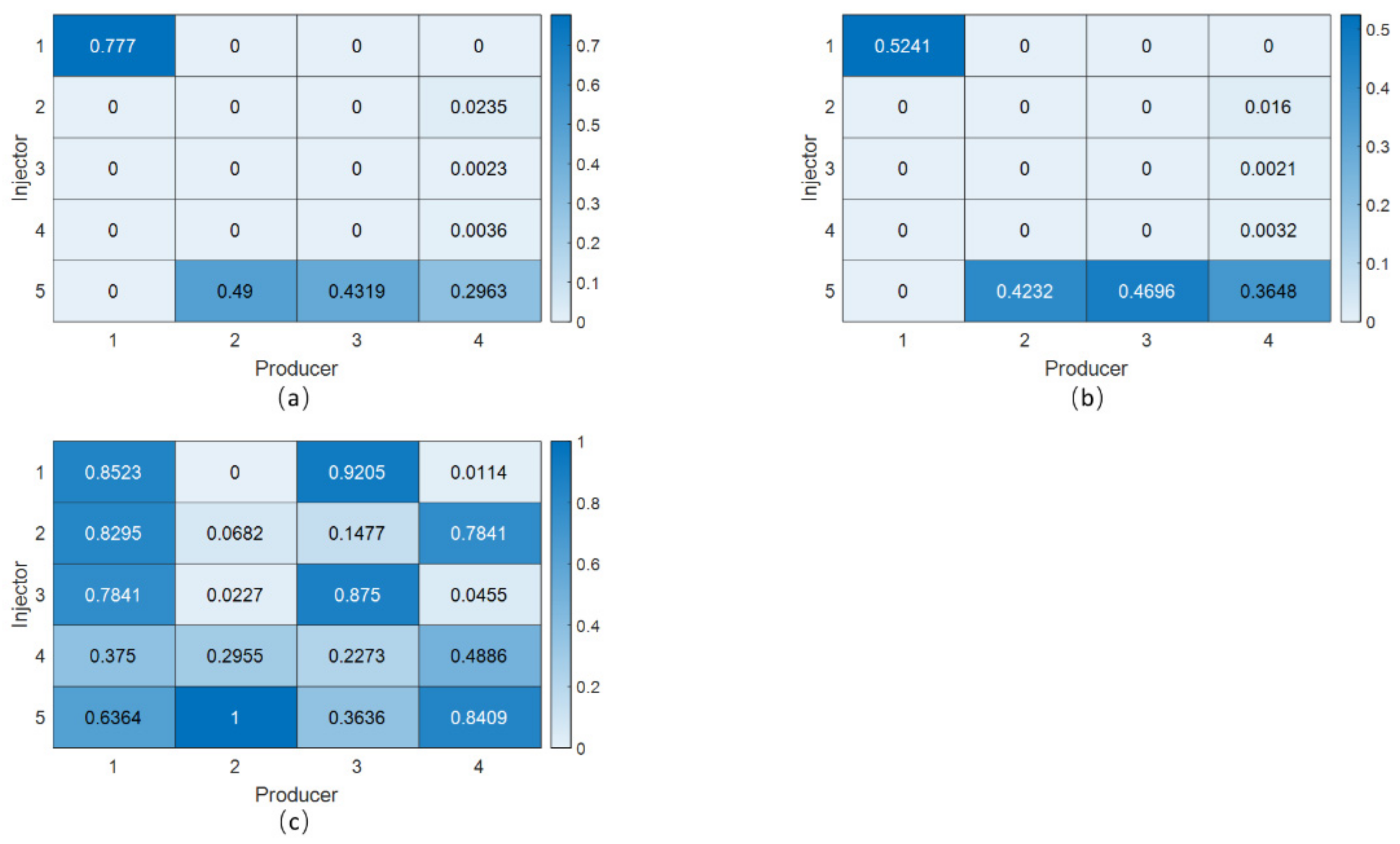
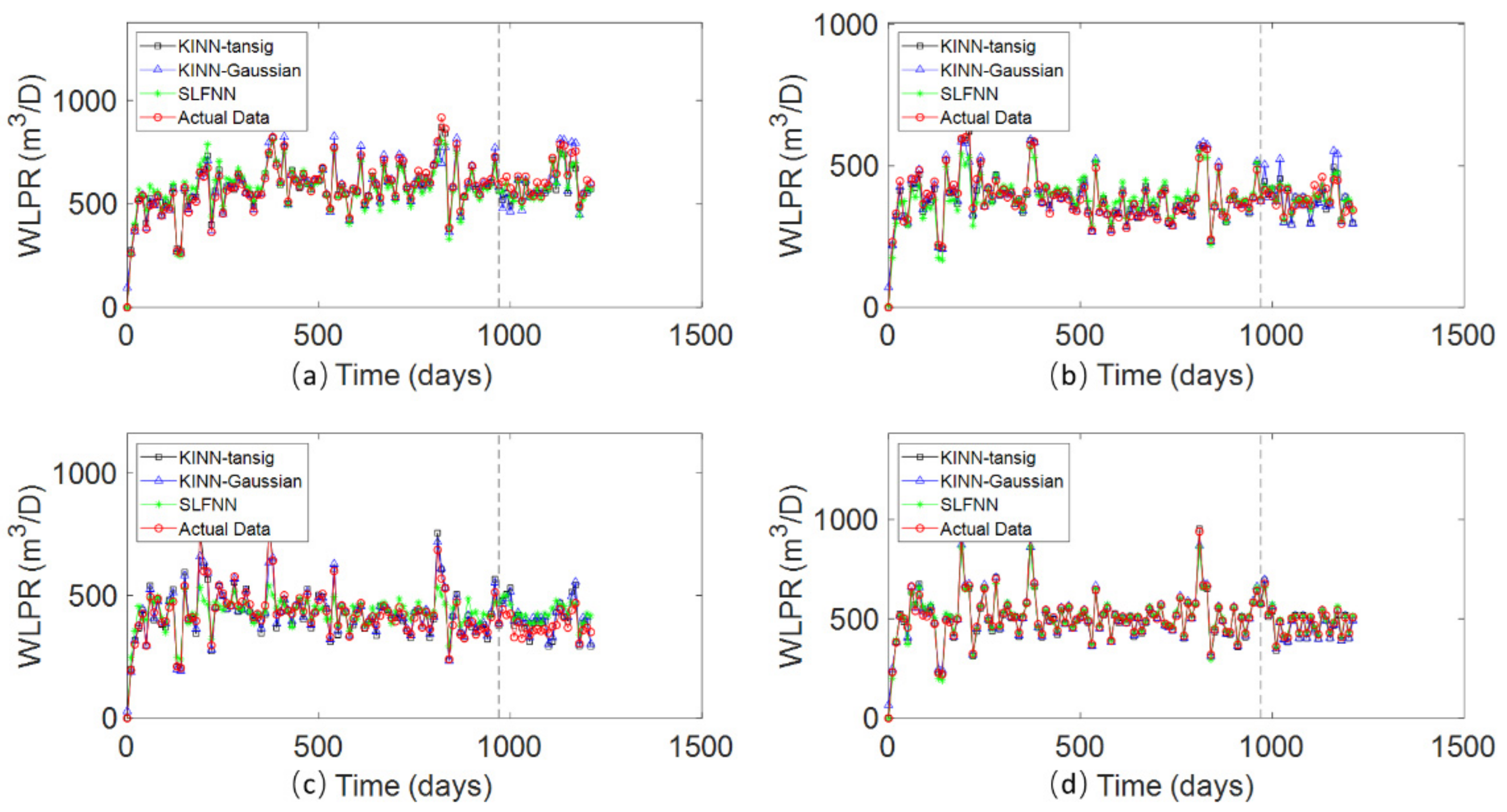
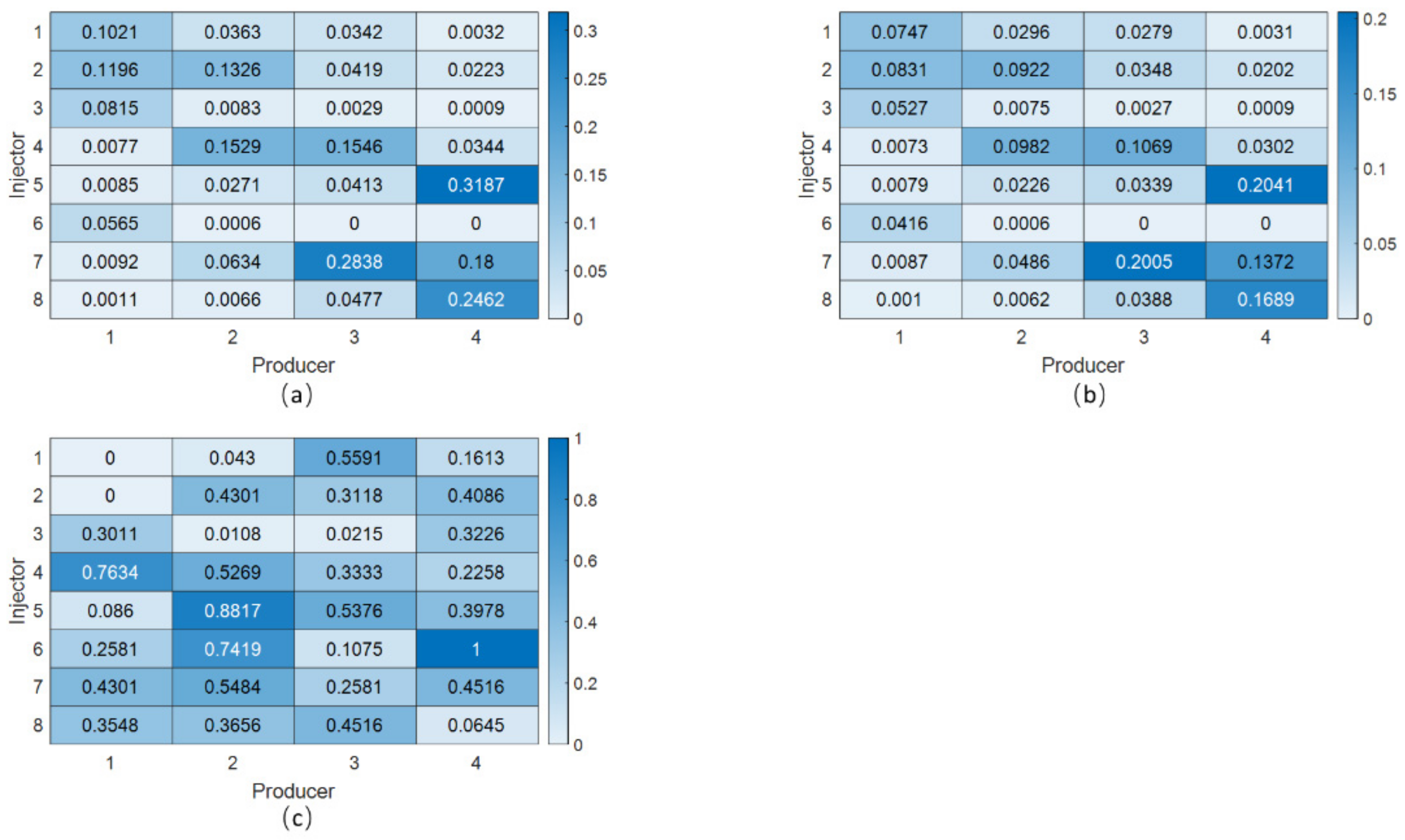
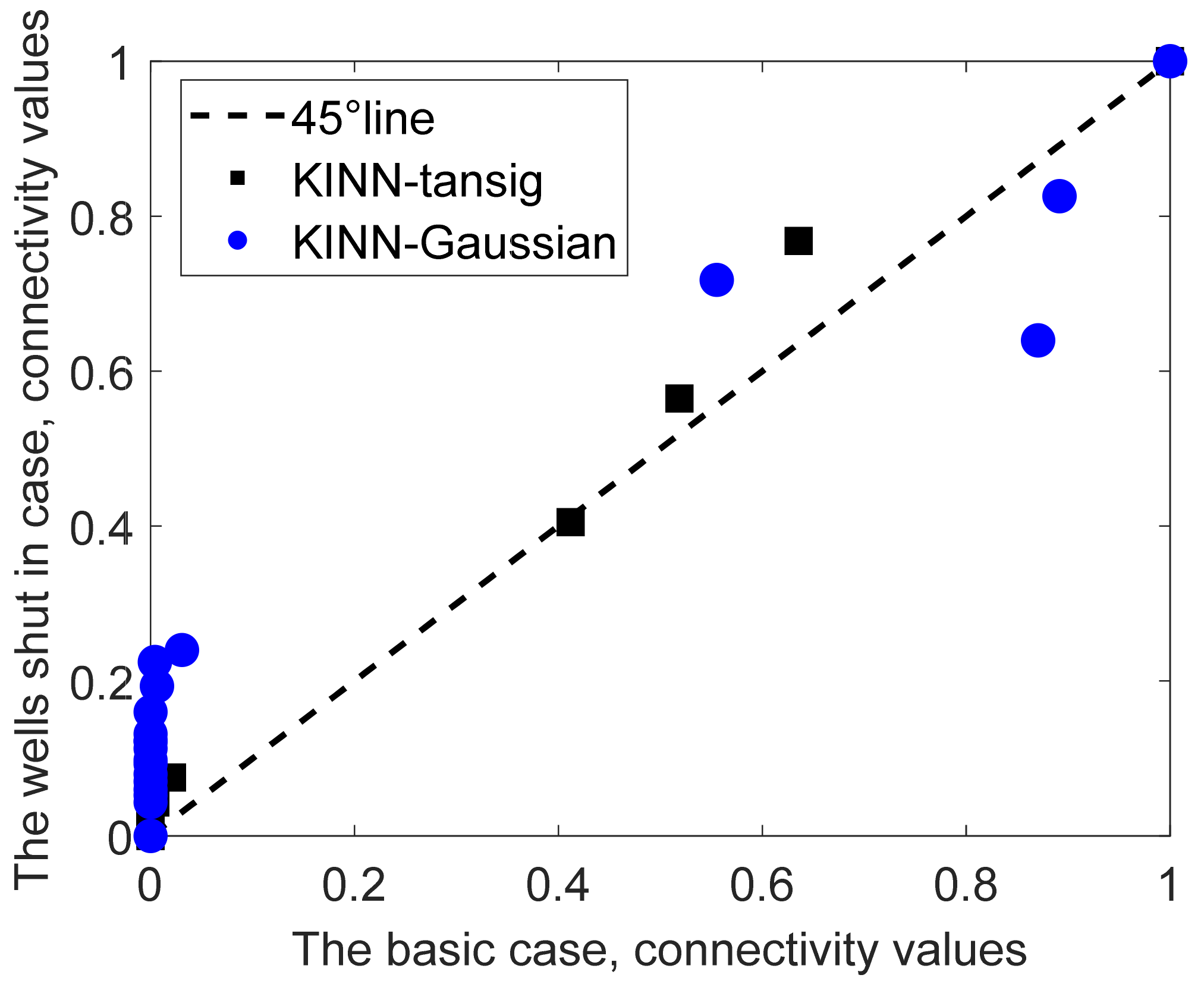
4.1. The Streak Reservoir Case
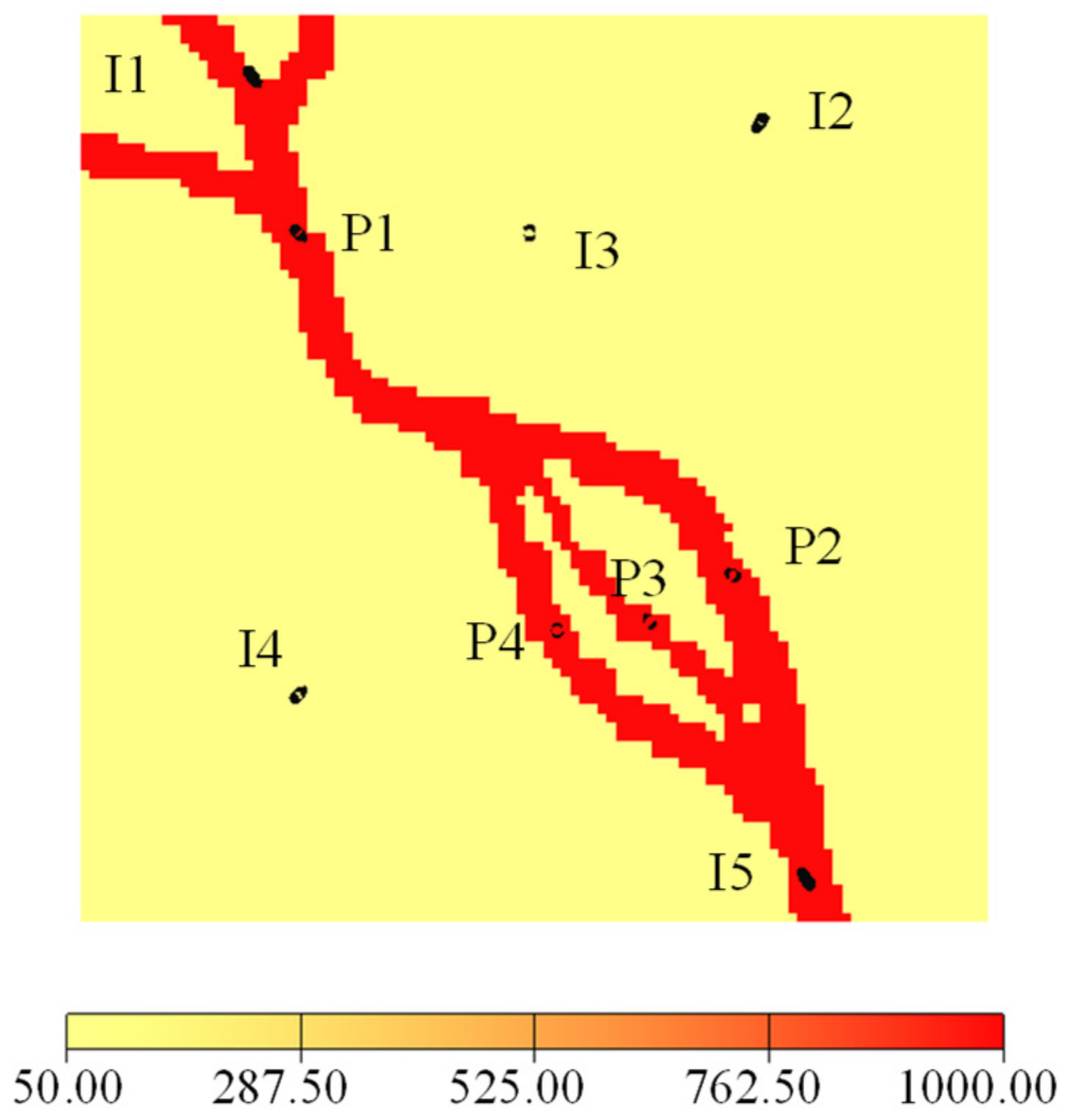
4.2. The Braided River Reservoir Case
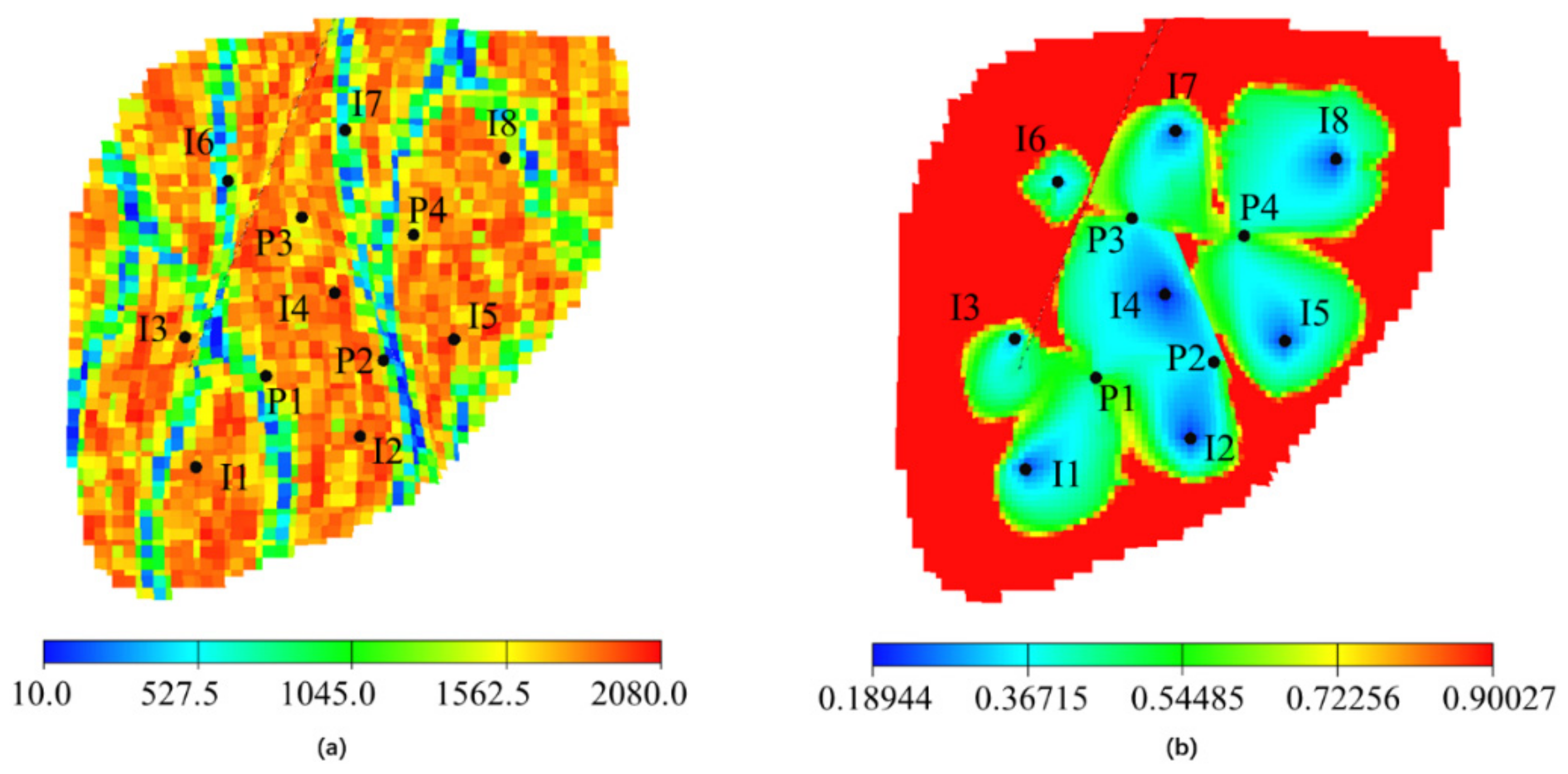
4.3. Egg Reservoir Case
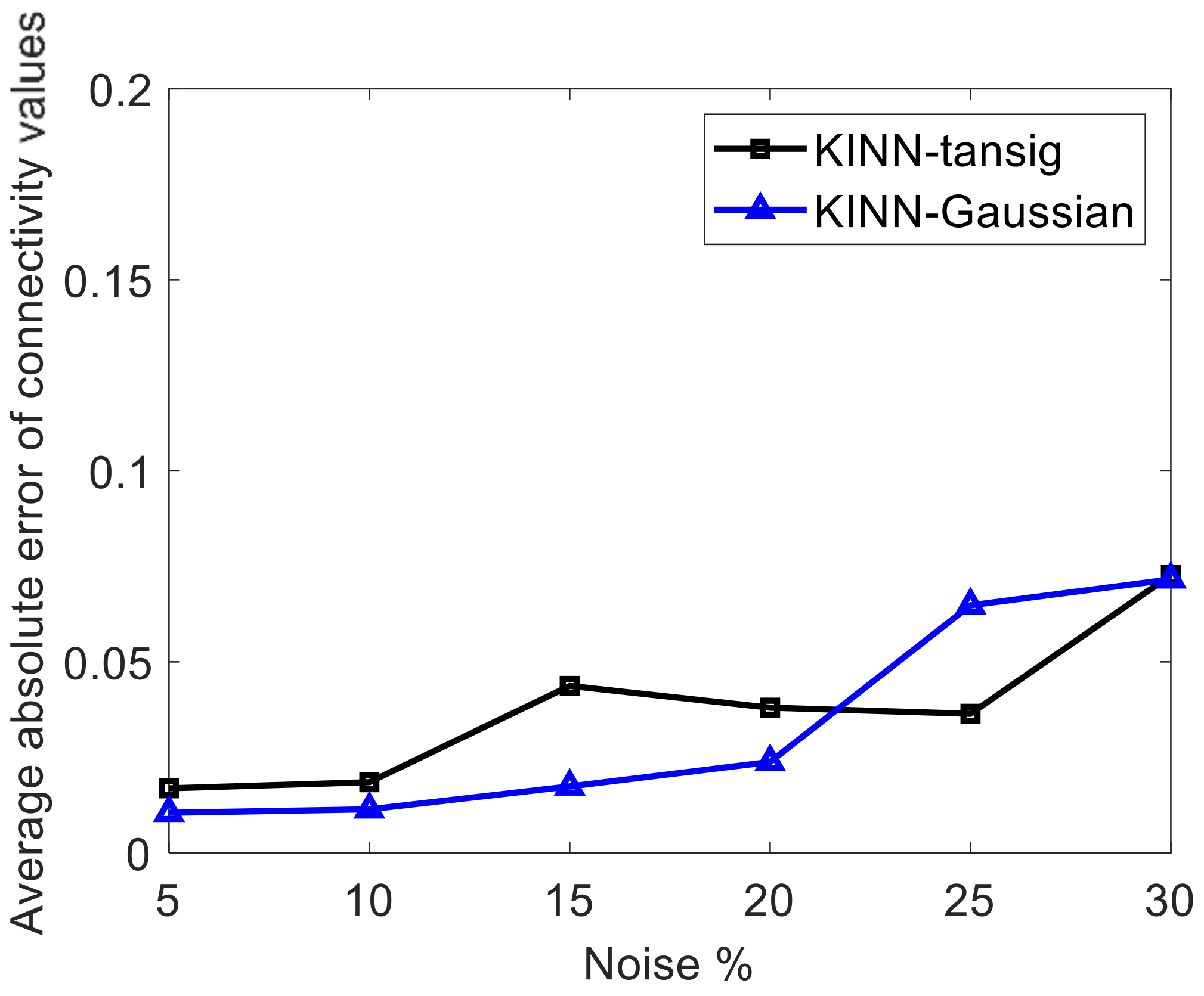
4.4. Sensitivity to Noise
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Nomenclature | Explanations |
| Ct | total compressibility, bar−1 |
| ik | water injection rate, m3/Day |
| J | productivity index, m3/Day/bar |
| M | number of injectors |
| N | number of producers |
| n | time-like variable |
| average reservoir pressure, bar | |
| pwf | bottom hole pressure, bar |
| estimated production rate, m3/Day | |
| qj | liquid production rate, m3/Day |
| t | time step, Day |
| drainage pore volume, m3/Day | |
| λkj | inter-well connectivity value |
| γkj | independent variable of inter-well connectivity of intelligent connectivity model |
| Pearson correlation coefficient | |
| i | time constant of capacitance resistance model, Day |
| comprehensive injection rate, m3/ day | |
| k | injector index |
| j | producer index |
References
- Hashan, M.; Jahan, L.N.; Zaman, T.U.; Imtiaz, S.; Hossain, M.E. Modelling of fluid flow through porous media using memory approach: A review. Math. Comput. Simul. 2020, 177, 643–673. [Google Scholar] [CrossRef]
- Mozolevski, I.; Murad, M.A.; Schuh, L.A. High order discontinuous Galerkin method for reduced flow models in fractured porous media. Math. Comput. Simul. 2021, 190, 1317–1341. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, K.; Zhang, L.; Yao, C.; Yao, J.; Wang, H.; Jian, W.; Yan, Y. Data-Driven Niching Differential Evolution with Adaptive Parameters Control for History Matching and Uncertainty Quantification. SPE J. 2021, 26, 993–1010. [Google Scholar] [CrossRef]
- Xu, X.; Wang, C.; Zhou, P. GVRP considered oil-gas recovery in refined oil distribution: From an environmental perspective. Int. J. Prod. Econ. 2021, 235, 108078. [Google Scholar] [CrossRef]
- Xu, X.; Lin, Z.; Li, X.; Shang, C.; Shen, Q. Multi-objective robust optimisation model for MDVRPLS in refined oil distribution. Int. J. Prod. Res. 2021, 5, 1–21. [Google Scholar] [CrossRef]
- Yin, F.; Xue, X.; Zhang, C.; Zhang, K.; Han, J.; Liu, B.; Wang, J.; Yao, J. Multifidelity Genetic Transfer: An Efficient Framework for Production Optimization. SPE J. 2021, 26, 1614–1635. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, J.; Ma, X.; Yao, C.; Zhang, L.; Yang, Y.; Wang, J.; Yao, J.; Zhao, H. History Matching of Naturally Fractured Reservoirs Using a Deep Sparse Autoencoder. SPE J. 2021, 26, 1700–1721. [Google Scholar] [CrossRef]
- Xu, X.; Lin, Z.; Zhu, J. DVRP with limited supply and variable neighborhood region in refined oil distribution. Ann. Oper. Res. 2022, 309, 663–687. [Google Scholar] [CrossRef]
- Heffer, K.J.; Fox, R.J.; McGill, C.A.; Koutsabeloulis, N.C. Novel Techniques Show Links between Reservoir Flow Directionality, Earth Stress, Fault Structure and Geomechanical Changes in Mature Waterfloods. SPE J. 1997, 2, 91–98. [Google Scholar] [CrossRef]
- Tian, C.; Horne, R.N. Inferring Interwell Connectivity Using Production Data. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dubai, United Arab Emirates, 26–28 September 2016. [Google Scholar] [CrossRef]
- Unal, E.; Siddiqui, F.; Rezaei, A.; Eltaleb, I.; Kabir, S.; Soliman, M.Y.; Dindoruk, B. Use of Wavelet Transform and Signal Processing Techniques for Inferring Interwell Connectivity in Waterflooding Operations. In Proceedings of the SPE Annual Technical Conference and Exhibition, Calgary, AB, Canada, 30 September–2 October 2019. [Google Scholar] [CrossRef]
- Wang, Y.; Kabir, C.S.; Reza, Z. Inferring Well Connectivity in Waterfloods Using Novel Signal Processing Techniques. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dallas, TX, USA, 24–26 September 2018. [Google Scholar] [CrossRef]
- Panda, M.N.; Chopra, A.K. An Integrated Approach to Estimate Well Interactions. In Proceedings of the SPE India Oil and Gas Conference and Exhibition, Society of Petroleum Engineers, New Delhi, India, 17–19 February 1998; p. SPE-39563-MS. [Google Scholar]
- Artun, E. Characterizing interwell connectivity in waterflooded reservoirs using data-driven and reduced-physics models: A comparative study. Neural Comput. Appl. 2017, 28, 1729–1743. [Google Scholar] [CrossRef]
- Jensen, J. Comment on “Characterizing interwell connectivity in waterflooded reservoirs using data-driven and reduced-physics models: A comparative study” by E. Artun. Neural Comput. Appl. 2016, 28, 1745–1746. [Google Scholar] [CrossRef] [Green Version]
- Yousef, A.A.; Gentil, P.H.; Jensen, J.L.; Lake, L.W. A Capacitance Model To Infer Interwell Connectivity From Production and Injection Rate Fluctuations. SPE Reserv. Eval. Eng. 2006, 9, 630–646. [Google Scholar] [CrossRef]
- Albertoni, A.; Lake, L.W. Inferring interwell connectivity only from well-rate fluctuations in waterfloods. SPE Reserv. Eval. Eng. 2003, 6, 6–16. [Google Scholar] [CrossRef]
- Lake, L.W.; Liang, X.; Edgar, T.F.; Al-Yousef, A.; Sayarpour, M.; Weber, D. Optimization Of Oil Production Based On A Capacitance Model Of Production And Injection Rates. In Proceedings of the Hydrocarbon Economics and Evaluation Symposium, Dallas, TX, USA, 1–3 April 2007. [Google Scholar]
- Sayarpour, M.; Zuluaga, E.; Kabir, C.S.; Lake, L.W. The use of capacitance–resistance models for rapid estimation of waterflood performance and optimization. J. Pet. Sci. Eng. 2009, 69, 227–238. [Google Scholar] [CrossRef]
- Sayarpour, M. Development and Application of Capacitance-Resistive Models to Water/CO₂ Floods; University of Texas at Austin: Austin, TX, USA, 2008. [Google Scholar]
- Mamghaderi, A.; Bastami, A.; Pourafshary, P. Optimization of Waterflooding Performance in a Layered Reservoir Using a Combination of Capacitance-Resistive Model and Genetic Algorithm Method. J. Energy Resour. Technol. 2012, 135, 013102–013110. [Google Scholar] [CrossRef]
- Zhao, H.; Kang, Z.; Zhang, X.; Sun, H.; Cao, L.; Reynolds, A.C. INSIM: A Data-Driven Model for History Matching and Prediction for Waterflooding Monitoring and Management with a Field Application. In Proceedings of the SPE Reservoir Simulation Symposium, Houston, TX, USA, 23–25 February 2015. [Google Scholar]
- Guo, Z.; Reynolds, A.C. INSIM-FT in three-dimensions with gravity. J. Comput. Phys. 2019, 380, 143–169. [Google Scholar] [CrossRef]
- Guo, Z.; Reynolds, A.C. INSIM-FT-3D: A Three-Dimensional Data-Driven Model for History Matching and Waterflooding Optimization. In Proceedings of the SPE Reservoir Simulation Conference, Society of Petroleum Engineers, Galveston, TX, USA, 10–11 April 2019; p. SPE-193841-MS. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, L.; Guo, Z.; Zhang, Q.; Liu, W.; Kang, X. Flow-Path Tracking Strategy in a Data-Driven Interwell Numerical Simulation Model for Waterflooding History Matching and Performance Prediction with Infill Wells. SPE J. 2020, 25, 1007–1025. [Google Scholar] [CrossRef]
- Kansao, R.; Yrigoyen, A.; Haris, Z.; Saputelli, L. Waterflood Performance Diagnosis and Optimization Using Data-Driven Predictive Analytical Techniques from Capacitance Resistance Models CRM. In Proceedings of the SPE Europec Featured at 79th EAGE Conference and Exhibition, Paris, France, 12–15 June 2017. [Google Scholar] [CrossRef]
- Olenchikov, D.; Posvyanskii, D. Application of CRM-Like Models for Express Forecasting and Optimizing Field Development. In Proceedings of the SPE Russian Petroleum Technology Conference, Moscow, Russia, 22–24 October 2019. [Google Scholar]
- Nguyen, A.P.; Lasdon, L.S.; Lake, L.W.; Edgar, T.F. Capacitance Resistive Model Application to Optimize Waterflood in a West Texas Field. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 30 October–2 November 2011. [Google Scholar]
- Guo, Z.; Reynolds, A.; Zhao, H. Waterflooding optimization with the INSIM-FT data-driven model. Comput. Geosci. 2018, 22, 745–761. [Google Scholar] [CrossRef]
- Chen, B.; Pawar, R.J. Characterization of CO2 storage and enhanced oil recovery in residual oil zones. Energy 2019, 183, 291–304. [Google Scholar] [CrossRef]
- Alimohammadi, H.; Rahmanifard, H.; Chen, N. Multivariate Time Series Modelling Approach for Production Forecasting in Unconventional Resources. In Proceedings of the SPE Annual Technical Conference and Exhibition, Virtual. 26–29 October 2020. [Google Scholar] [CrossRef]
- Chen, B.; Harp, D.R.; Lin, Y.; Keating, E.H.; Pawar, R.J. Geologic CO2 sequestration monitoring design: A machine learning and uncertainty quantification based approach. Appl. Energy 2018, 225, 332–345. [Google Scholar] [CrossRef]
- Li, Y.; Wang, G.; McLellan, B.; Chen, S.-Y.; Zhang, Q. Study of the impacts of upstream natural gas market reform in China on infrastructure deployment and social welfare using an SVM-based rolling horizon stochastic game analysis. Pet. Sci. 2018, 15, 898–911. [Google Scholar] [CrossRef] [Green Version]
- Boret, S.E.B.; Marin, O.R. Development of Surrogate models for CSI probabilistic production forecast of a heavy oil field. Math. Comput. Simul. 2019, 164, 63–77. [Google Scholar] [CrossRef]
- Fumagalli, A.; Zonca, S.; Formaggia, L. Advances in computation of local problems for a flow-based upscaling in fractured reservoirs. Math. Comput. Simul. 2017, 137, 299–324. [Google Scholar] [CrossRef]
- Xu, X.; Hao, J.; Zheng, Y. Multi-objective Artificial Bee Colony Algorithm for Multi-stage Resource Leveling Problem in Sharing Logistics Network. Comput. Ind. Eng. 2020, 142, 106338. [Google Scholar] [CrossRef]
- Huang, D.S. Radial Basis Probabilistic Neural Networks: Model and Application. Int. J. Pattern Recognit. Artif. Intell. 1999, 13, 1083–1101. [Google Scholar] [CrossRef]
- Huang, D.; Du, J. A Constructive Hybrid Structure Optimization Methodology for Radial Basis Probabilistic Neural Networks. IEEE Trans. Neural Netw. 2008, 19, 2099–2115. [Google Scholar] [CrossRef]
- Karpatne, A.; Watkins, W.; Read, J.; Kumar, V. Physics-guided Neural Networks (PGNN): An Application in Lake Temperature Modeling. arXiv 2017, arXiv:1710.11431. [Google Scholar]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Tartakovsky, A.M.; Marrero, C.O.; Perdikaris, P.; Tartakovsky, G.D.; Barajas-Solano, D. Physics-Informed Deep Neural Networks for Learning Parameters and Constitutive Relationships in Subsurface Flow Problems. Water Resour. Res. 2020, 56, e2019WR026731. [Google Scholar] [CrossRef]
- Dehghani, H.; Zilian, A. A hybrid MGA-MSGD ANN training approach for approximate solution of linear elliptic PDEs. Math. Comput. Simul. 2021, 190, 398–417. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, D.; Chang, H.; Li, H. Deep learning of subsurface flow via theory-guided neural network. J. Hydrol. 2020, 584, 124700. [Google Scholar] [CrossRef] [Green Version]
- Csiszár, O.; Csiszár, G.; Dombi, J. Interpretable neural networks based on continuous-valued logic and multicriteria decision operators. Knowl.-Based Syst. 2020, 199, 105972. [Google Scholar] [CrossRef]
- Huang, C.; Xu, H.; Xu, Y.; Dai, P.; Xia, L.; Lu, M.; Bo, L.; Xing, H.; Lai, X.; Ye, Y. Knowledge-aware Coupled Graph Neural Network for Social Recommendation. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), Virtual. 2–9 February 2021. [Google Scholar] [CrossRef]
- Zandvliet, M.J.; Bosgra, O.H.; Jansen, J.-D.; Van den Hof, P.; Kraaijevanger, J.B.F.M. Bang-bang control and singular arcs in reservoir flooding. J. Pet. Sci. Eng. 2007, 58, 186–200. [Google Scholar] [CrossRef]
- Khan, Z.; Chaudhary, N.I.; Zubair, S. Fractional stochastic gradient descent for recommender systems. Electron. Mark. 2019, 29, 275–285. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | KINN-Tansig | KINN-Gaussian |
|---|---|---|
| Learning rate | 0.05 | 0.05 |
| Number of hidden layers in CVM | 3 | 3 |
| Number of neurons of each layer in CVM | [1, 10, 1] | [1, 10, 1] |
| Activation function in CVM | tansig function | Gaussian kernel function |
| Initialization range of weights in CVM | [0, 0.25] | [0, 0.25] |
| Initialization method of γ in IRM | Pearson Correlation | Pearson Correlation |
| Optimization algorithm | Gradient descent method | Gradient descent method |
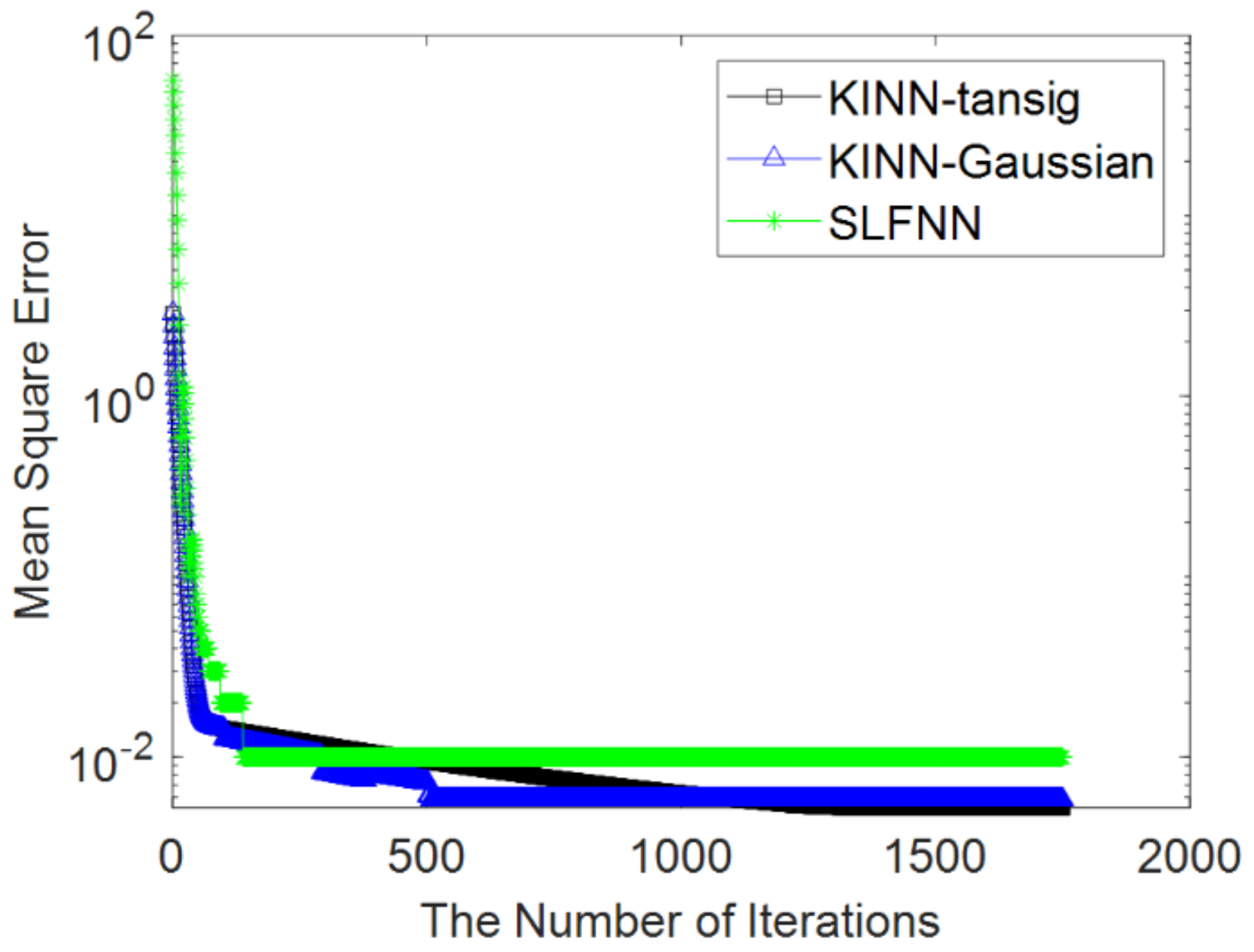
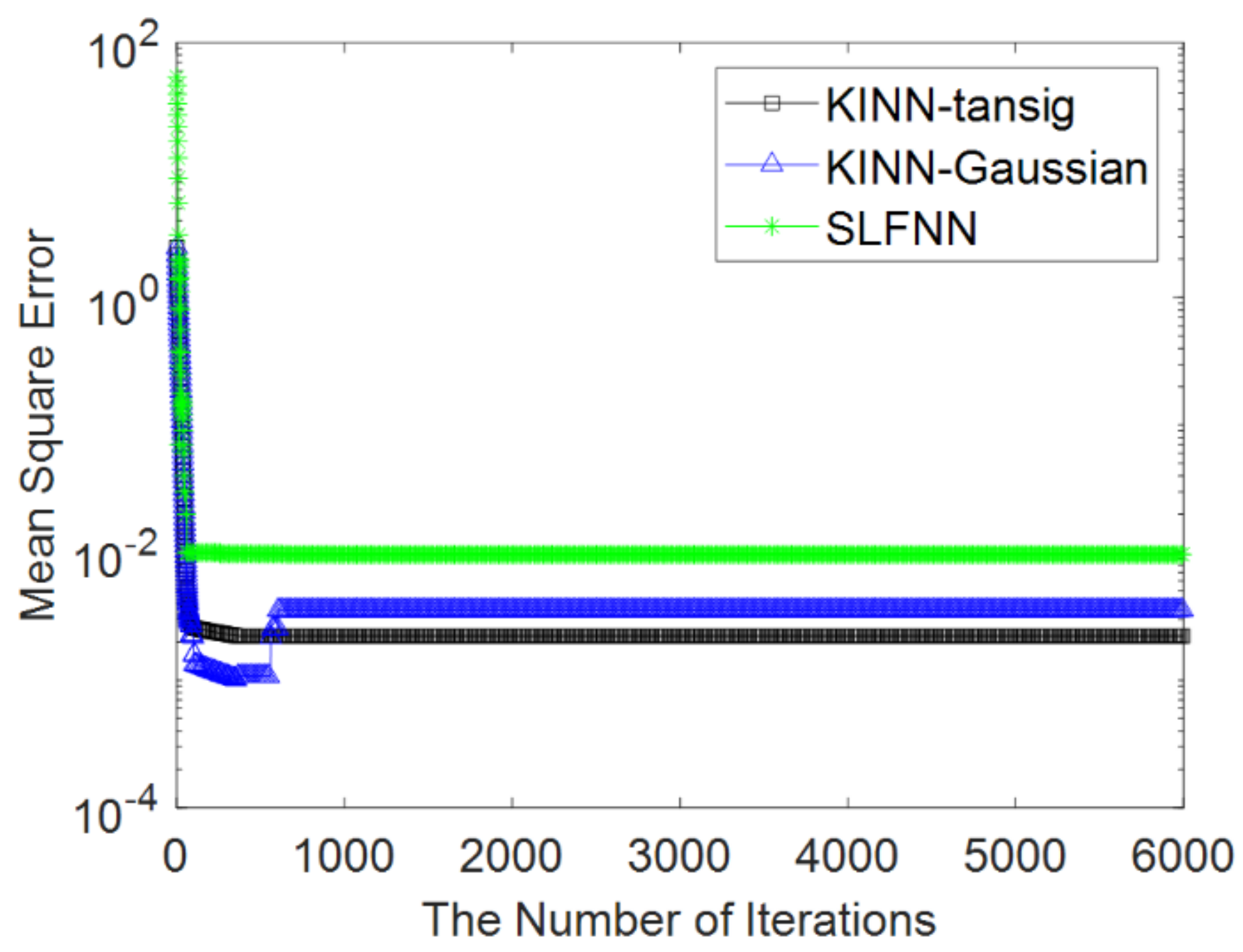
| Convergence error (MSE) |
| Properties | Value |
|---|---|
| Model Size | 31 × 31 × 1 |
| Depth | 2000 m |
| Initial pressure | 2000 psi |
| Porosity | 0.18 |
| Initial water saturation | 0.3 |
| Density of oil | 900 kg/m3 |
| Viscosity of oil | 2.0 cp |
| Oil compressibility | 5.0 × 10−6 bar−1 |
| Methods | KINN-Tansig | KINN-Gaussian | SLFNN |
|---|---|---|---|
| Computation time (training and testing) | 0.3702 s | 2.3393 s | 1.2737 s |
| Error of history matching (training error) | 0.0046 | 0.0047 | 0.0976 |
| Error of prediction (testing error) | 0.0223 | 0.0256 | 0.1832 |
| Methods | KINN-Tansig | KINN-Gaussian | SLFNN |
|---|---|---|---|
| Computation time (training and testing) | 0.7417 s | 3.4679 s | 2.4602 s |
| Error of history matching (training error) | 0.0052 | 0.0058 | 0.0104 |
| Error of prediction (testing error) | 0.0071 | 0.0065 | 0.0142 |
| Properties | Value |
|---|---|
| Model Size | 100 × 99 × 1 |
| Depth | 4000 m |
| Initial pressure | 5765 psi |
| Porosity | 0.2 |
| Initial water saturation | 0.1 |
| Density of oil | 900 kg/m3 |
| Viscosity of oil | 2.0 cp |
| Oil compressibility | 1.0 × 10−5 bar −1 |
| KINN-Tansig | KINN-Gaussian | SLFNN | |
|---|---|---|---|
| Computation time (training and testing) | 0.1282 s | 0.8539 s | 0.3361 s |
| Error of history matching (training error) | 0.0022 | 0.0035 | 0.0097 |
| Error of prediction (testing error) | 0.0171 | 0.0263 | 0.0426 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Zhang, H.; Zhang, K.; Wang, J.; Cui, S.; Han, J.; Zhang, L.; Yao, J. Reservoir Characterization and Productivity Forecast Based on Knowledge Interaction Neural Network. Mathematics 2022, 10, 1614. https://doi.org/10.3390/math10091614
Jiang Y, Zhang H, Zhang K, Wang J, Cui S, Han J, Zhang L, Yao J. Reservoir Characterization and Productivity Forecast Based on Knowledge Interaction Neural Network. Mathematics. 2022; 10(9):1614. https://doi.org/10.3390/math10091614
Chicago/Turabian StyleJiang, Yunqi, Huaqing Zhang, Kai Zhang, Jian Wang, Shiti Cui, Jianfa Han, Liming Zhang, and Jun Yao. 2022. "Reservoir Characterization and Productivity Forecast Based on Knowledge Interaction Neural Network" Mathematics 10, no. 9: 1614. https://doi.org/10.3390/math10091614