
Roadmap Optimization: Multi-Annual Project Portfolio Selection Method


Abstract
:1. Introduction
2. Literature
- X—
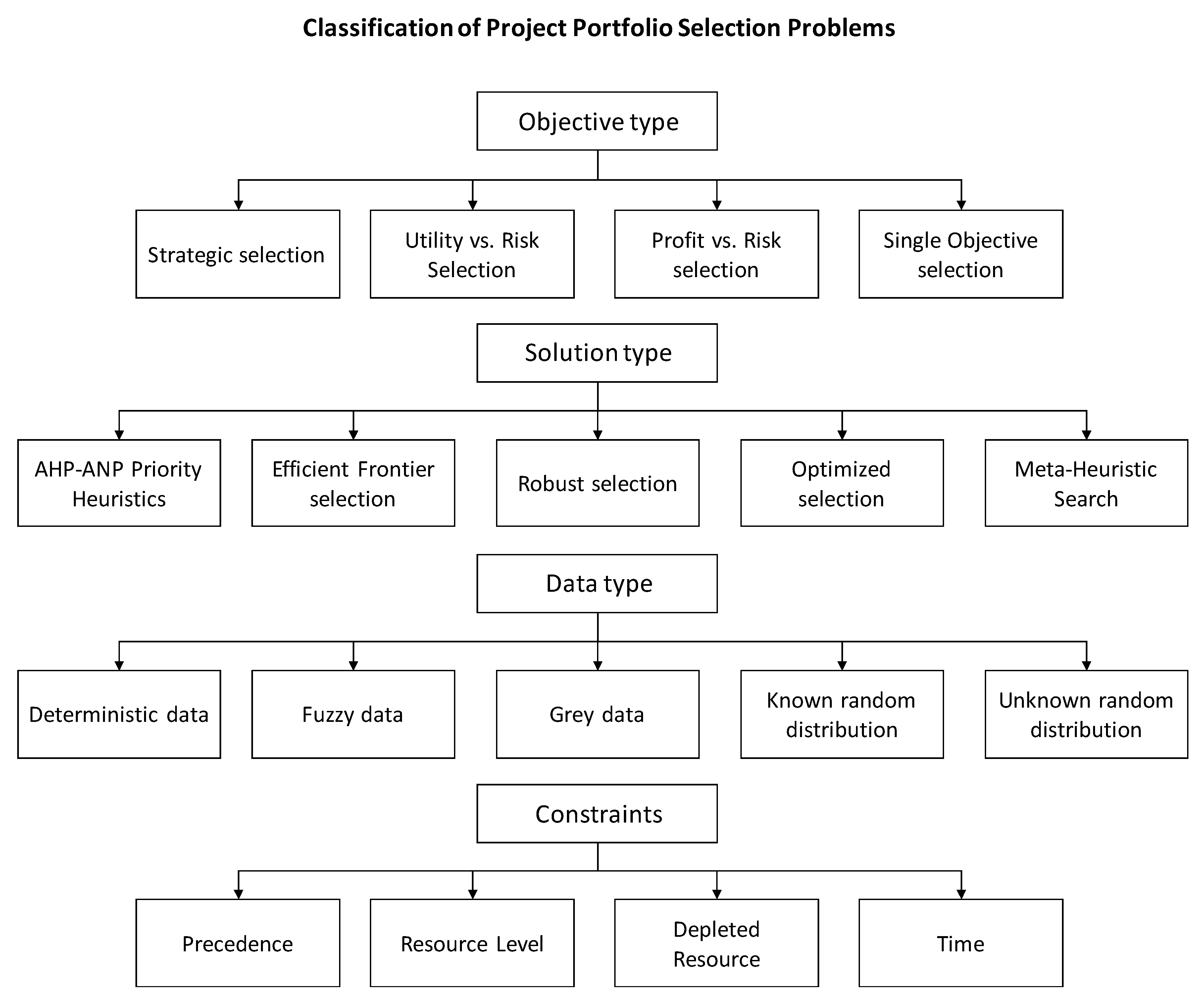
- Objective type: single-attribute selection, multiple-attribute selection, fitness function, profit vs. risk selection, utility vs risk selection, and strategic selection;
- Y—
- Solution type: optimized selection, robust selection, efficient frontier, AHP/ANP, and priority-based;
- Z—
- Data type: deterministic data, fuzzy data, and stochastic data;
- W—
- Constraint characteristics: a combination of letters that testify for the existence of the characteristic constraint as follows: P = precedence constraints, RL = resource-level constraints, DR = depleted resource constraints, and T = time constraints.
3. Problem Description
- Resource availability: Each project requires a specific level of various resources. The assumption is that there cannot be a breach of the available level of each resource.
- Precedence: As part of the R&D project, the company acquires new capabilities that can be exploited for future projects.
3.1. Problem Assumptions
- Each project has a specific value to the company. This value can be measured in the same units (typically profit, measured in dollars).
- The value of the project to the company depreciates as a function of time; that is, each year can be assigned a corresponding coefficient that expresses the depreciated value. (For example, a project assigned to year 1 has a value of 100. The same project assigned to year 2 has a value of 80. If assigned to year 3, it has an even lower value, etc.).
- All relevant resources are renewable (e.g., work hours). For each year, there are new levels of resources available. The amount of a resource that was not consumed in year n cannot be used in year n + 1.
- Each project has given levels of resources needed for its completion (e.g., programmer hours or QA hours).
- Technical precedence dependencies exist between the projects. Thus, project x can be performed based on the technology performed for project y.
3.2. Problem Notations
3.3. Problem Formulation
4. Problem Complexity and Exact Solution
4.1. Complexity
- Set the horizon (number of years) to 2. Thus, the projects are either assigned to the first year (i.e., inserted to the “knapsack”) or to the second one (left out).
- Set the second year’s value to zero ().
4.2. Branch and Bound Algorithm
- A lower bound (LB): Any feasible solution can provide an LB. The algorithm can start with either a solution produced by the metaheuristic algorithm or a simple heuristic solution.
- An upper bound (UB): This is an efficient way to assess the maximal potential of a partial solution (i.e., branch) of the tree. The UB can serve as a convenient heuristic precedence rule (i.e., a rule to decide which branch to further develop first).
- A branching method: This is a way to create the net branches.
4.2.1. Initial Solution
- For each resource type ():
- 1.1
- Calculate for each project the ratio of the project value to its resource requirement; that is, , where denotes the value that can be obtained from one unit of the resource by performing the project.
- 1.2
- For each project, calculate its total impact. The impact is calculated by aggregating the project’s value and the values of all its successors (direct and indirect). For example, for project 1, the impact is (since projects 5, 7, and 8 are successors to project 1).
- 1.3
- Sort the projects in descending order by the total impact.
- 1.4
- Schedule the projects according to the order obtained in Step 1.3. Each project should be scheduled for the first available year.
- 1.5
- Calculate the total value obtained from the schedule of Step 1.4 .
- The solution is set to be .
4.2.2. Branching
- There exists a resource type () for which
- For every subset of , denoted by (i.e., and not ) and for every resource type (), the following is true:
4.2.3. Bounding Rule
- Simply calculable: The rule should provide the result with a low complexity algorithm (otherwise, it provides no benefit).
- Low UB: To trim the tree as much as possible, the UB should be as low as possible.
- For each resource type (), the following should be performed:
- 1.1
- Ignore all resource requirements (other than resource ) and precedence constraints.
- 1.2
- The remaining problem is the multiple knapsacks problem. Solve the problem accordingly.
- 1.3
- As the multiple knapsacks problem is an NP-complete problem, when a project is scheduled to start in year and finish in year , calculate the obtained value of the project proportional to the year it was scheduled for.
- 1.4
- Calculate the total values of the projects (each according to its year) .
- Calculate the overall bound .
5. Metaheuristic Search
- Representation of the solution space (i.e., the “antibodies”);
- An initial set of solutions.
- A procedure to create valid mutations in the antibodies (i.e., mutations creating new solutions that are included in the solution space).
5.1. Vector Representation
- For to , do the following:
- 1.1
- If (i.e., has not been scheduled yet):Run procedure “FindYear” with parameter .
- 1.2
- If (i.e., has already been scheduled):Continue.
- For to , do the following (without loss of generality, as it is assumed that if project depends on project , then ):
- 1.1
- If and (project depends on project , and project has not been scheduled), run procedure “SCHEDULE” with parameter .
- 1.2
- Otherwlse (either project does not depend on project or project has already been scheduled), continue.
- Find the first year in which can be scheduled (has enough available resources and does not violate dependencies), and set .
- Return
5.2. Initial Solution Generation
- A matrix with dimensions was created;
- For i = 1 to do the following:
- 2.1
- Set .
- 2.2
- Set (random number from the unit uniform distribution).
- 3
- Sort in ascending order according to the second column.
- 4
- The first column of is an initial solution vector ().
6. Mutation Generation
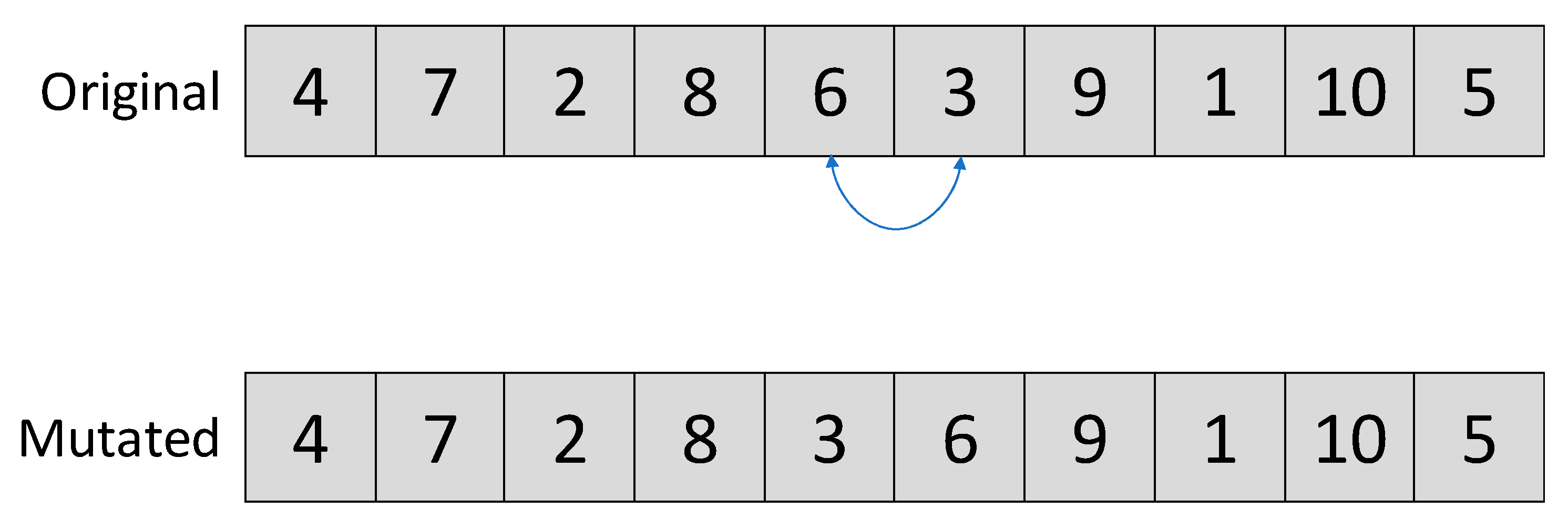
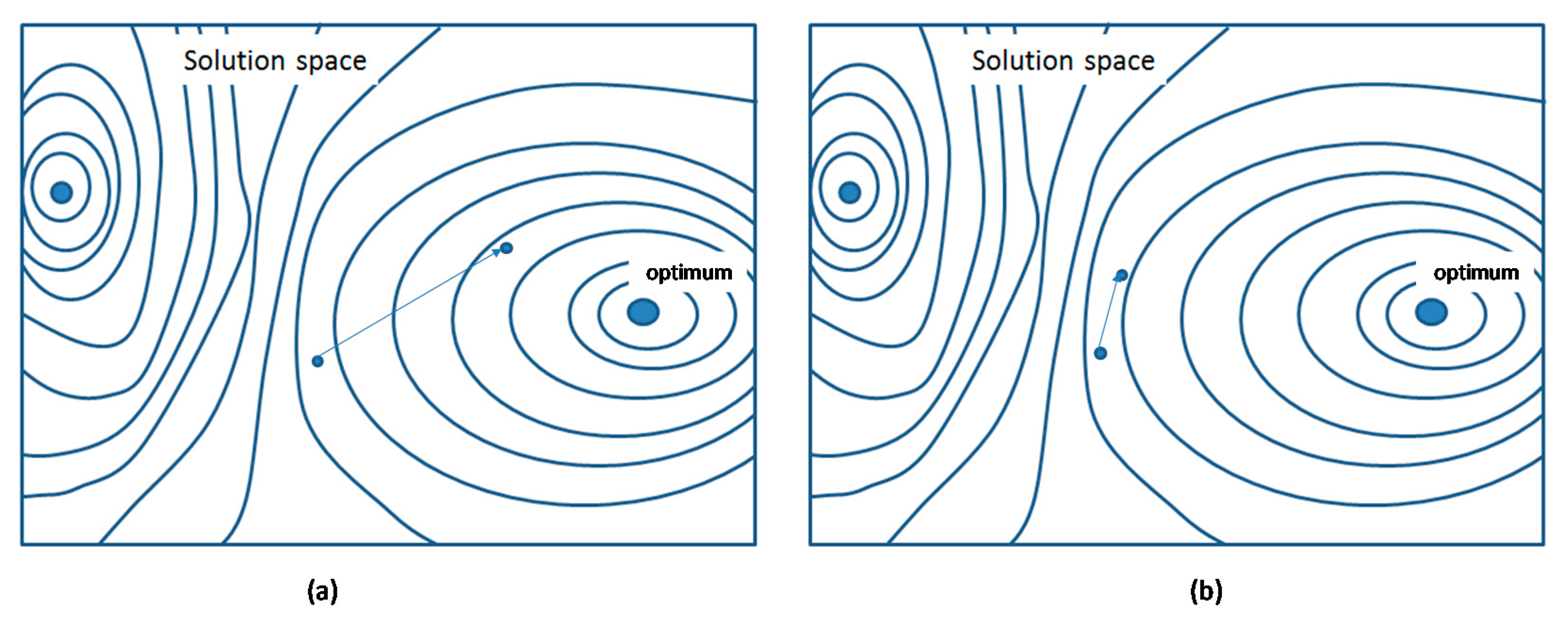
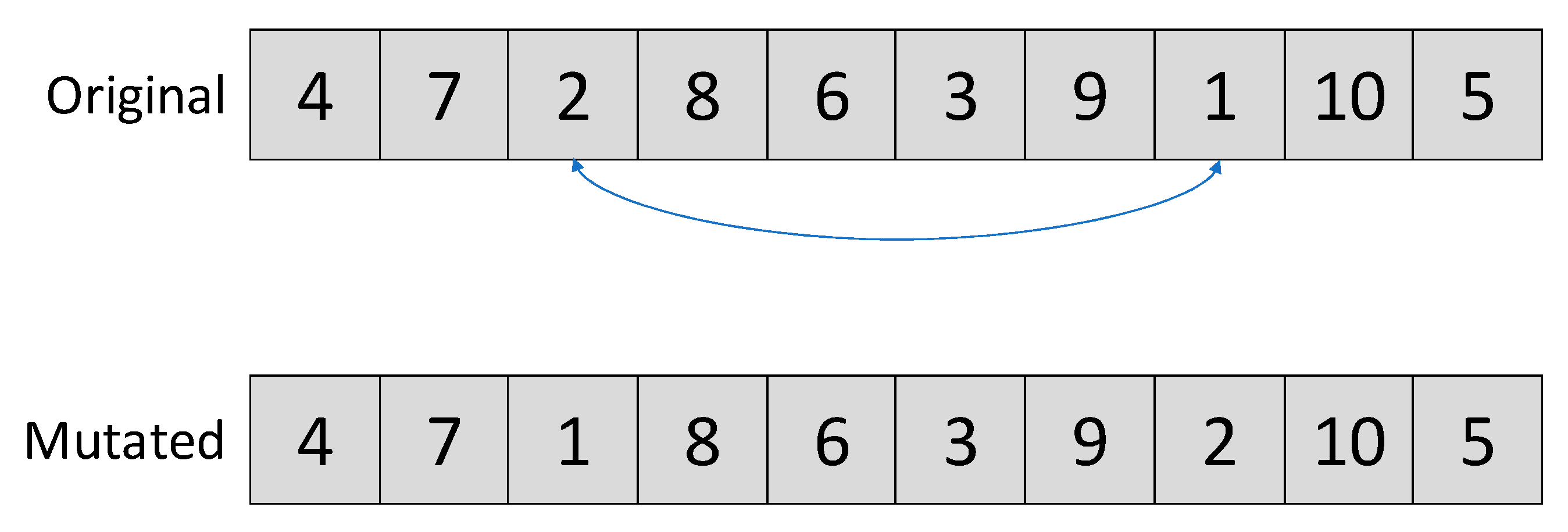
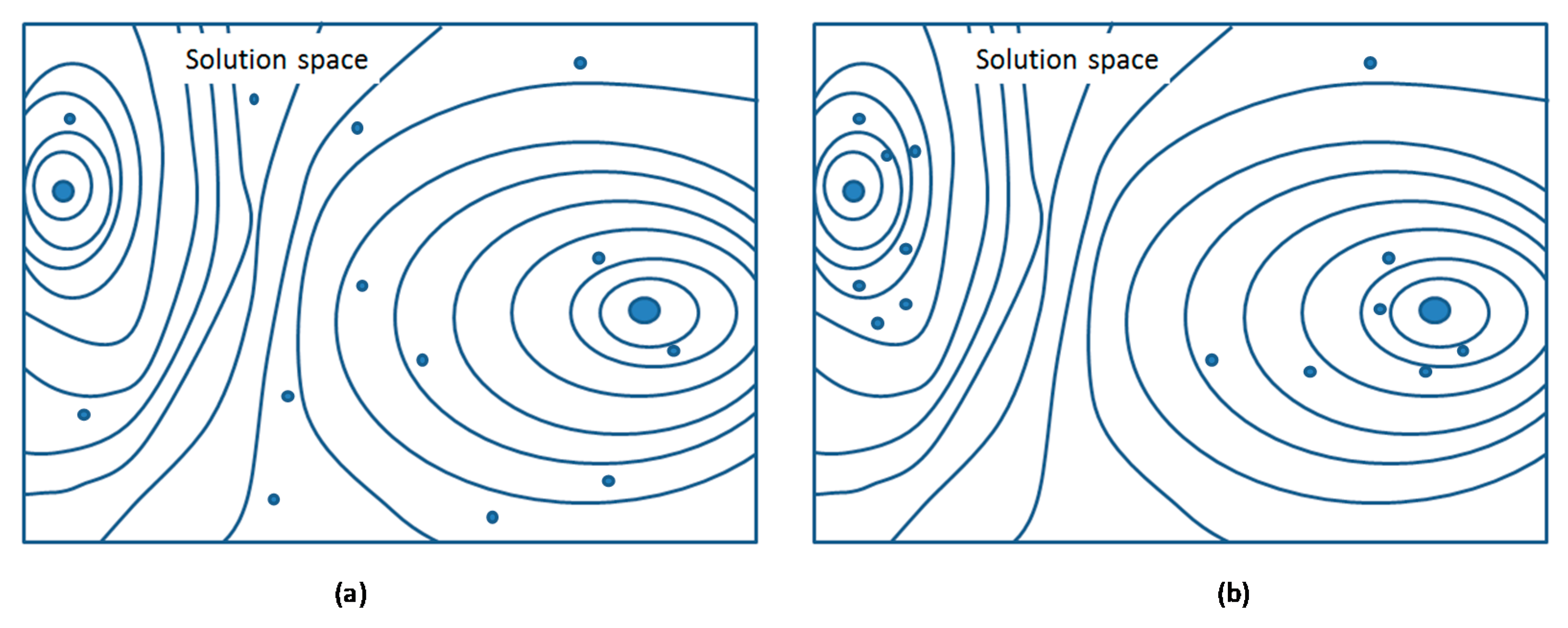
6.1. Minor Mutations
6.2. Major Mutations
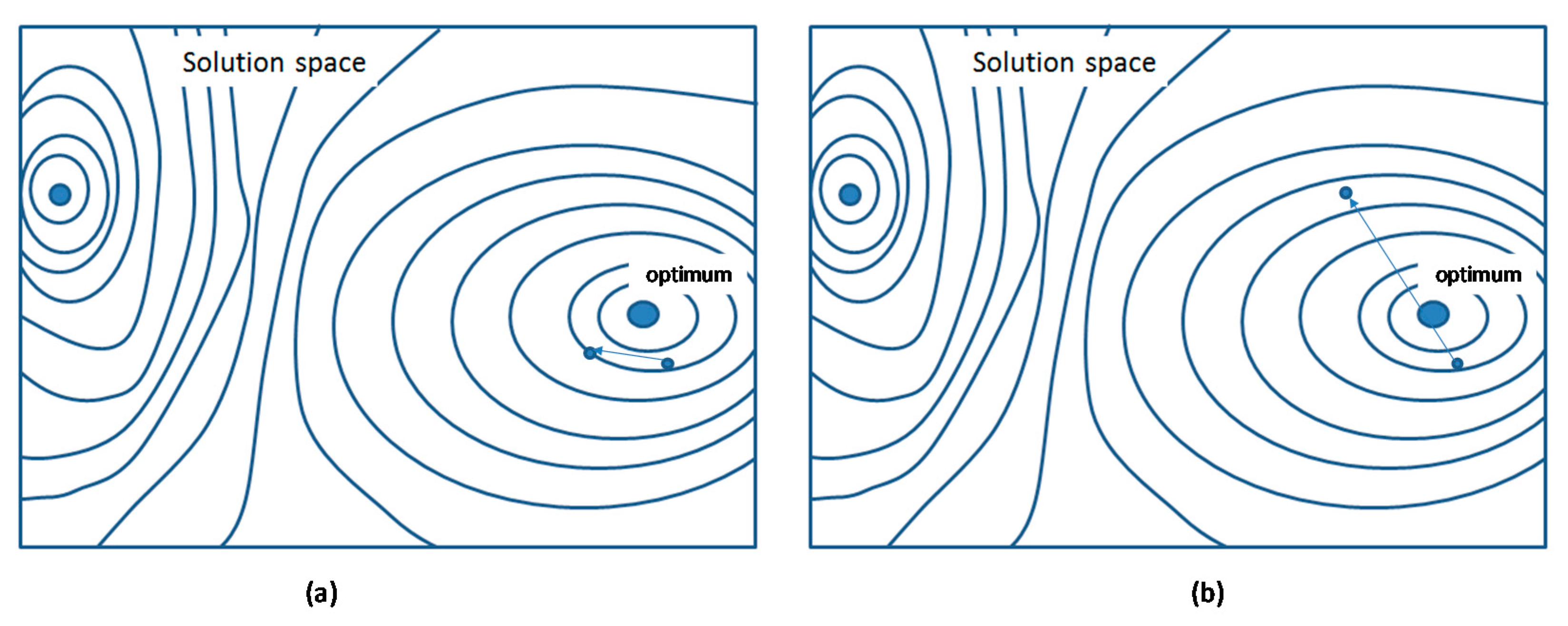
6.3. Oriented Mutations
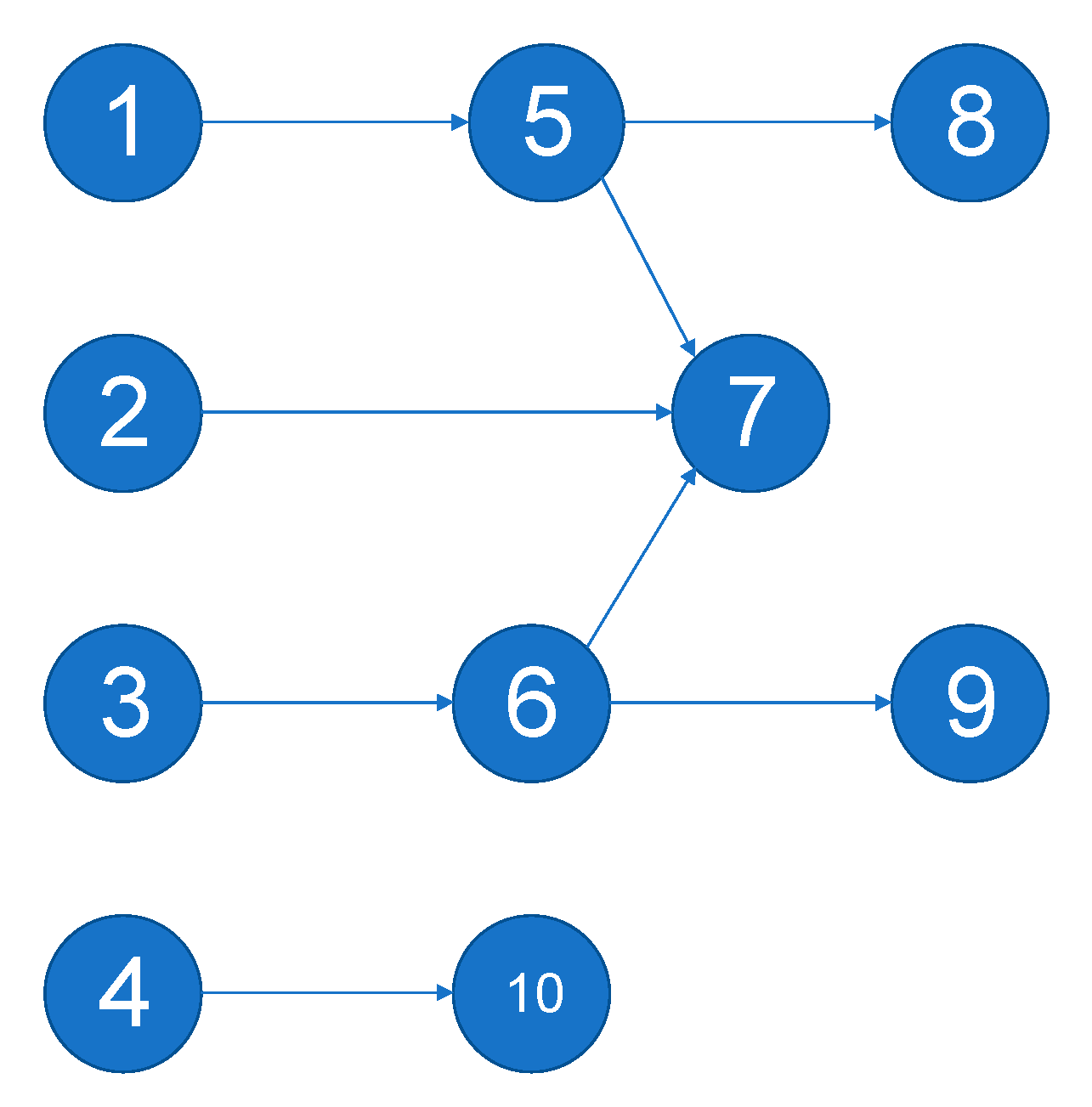
- Dependent projects: In the example depicted in Figure 4, Projects 5 and 6 have a common dependent in Project 7. This means that it will not be possible to gain the value of Project 7, even if Project 5 is expedited. There is a need to complete Projects 6 and 2 as well. Any small mutation expediting just one of these projects will leave the others untouched and fail to yield a major gain in value. Furthermore, any mutation that causes one of these projects to be postponed will yield a major reduction in the total value. A mutation involving all three projects may enable the expedition of the lucrative Project 7. The proposed similarity measure is (based on [65])where the latter is simply the number of projects that depend on both project and divided by the number of projects that depend on either of the two. For example, , since only Project 7 depends on both projects, and there are 3 projects that depend on either 5 or 6.
- Mutual dependencies: When two projects depend on the same (or nearly the same) projects, expediting both together causes only a little more impact on the entire schedule than expediting only one (i.e., “two for almost the same price”). Therefore, the second similarity is calculated as follows:
- Resource requirements: Obviously, all projects compete for the same resource pool. Therefore, the third similarity is based on the measure of the level of common resources required by both projects. Two projects that require totally different resources do not compete at all. Projects that compete for the same resource, in which the resource itself is in abundance, will result in a minimal competition. If, however, both have high requirements for a low-level resource, then they are in head-to-head competition. Therefore, the third similarity can be calculated as the ratio between the required combined resources and the availability of these resources:
- This similarity measure differs from and . First, it measures dissimilarity. Second, the value of depends on the number of resources (). The larger the value of , the larger the value of . This poses a problem for the implementation of the CLONALG method. Therefore, the similarity measure () will be calculated as follows:
- Randomly choose a project ;
- Create an empty set of projects ;
- For each project where , do the following:
- 3.1
- Generate a random number ;
- 3.2
- If , then add project to .
- Randomly choose a location for project ;
- Move all members of the set to location (while maintaining the inner order of ).
6.4. Mixed Mutations
- 3
- For each project where , do the following:
- 3.1
- Generate a random number ;
- 3.2
- If , then add project to .
7. Computational Results
7.1. Database
- Size: The number of projects varied between 20 and 120 projects (20, 40, 60, and 80 projects);
- Connectivity: The number of precedence connections can vary between zero (i.e., no project depends on any other one) and full connectivity (i.e., all projects can be presented as Project 1 precedes Project 2, which precedes Project 3, and so on). The problems were divided into three categories: high, low, and medium connectivity;
- Resources: For each type of resource, its scarcity can be measured by the ratio between the total demand (of all projects) and its annual availability. The resource scarcity has a strong connection to the planning horizon (the scarcer the resource, the more years are needed to complete the entire set of projects). As the number of years for the entire project was set to five, the scarcest resource was set to require seven times the annual resource level. The total number of resources varied between 1 and 3.
7.2. Experiment Design
- Ratio to optimal solution: For smaller problems (i.e., sets of 20 projects), an optimal solution was found using B&B;
- Ratio to best-known solution: For each instance, the best value was found, and for each method, the ratio between its solution and the best solution was calculated.
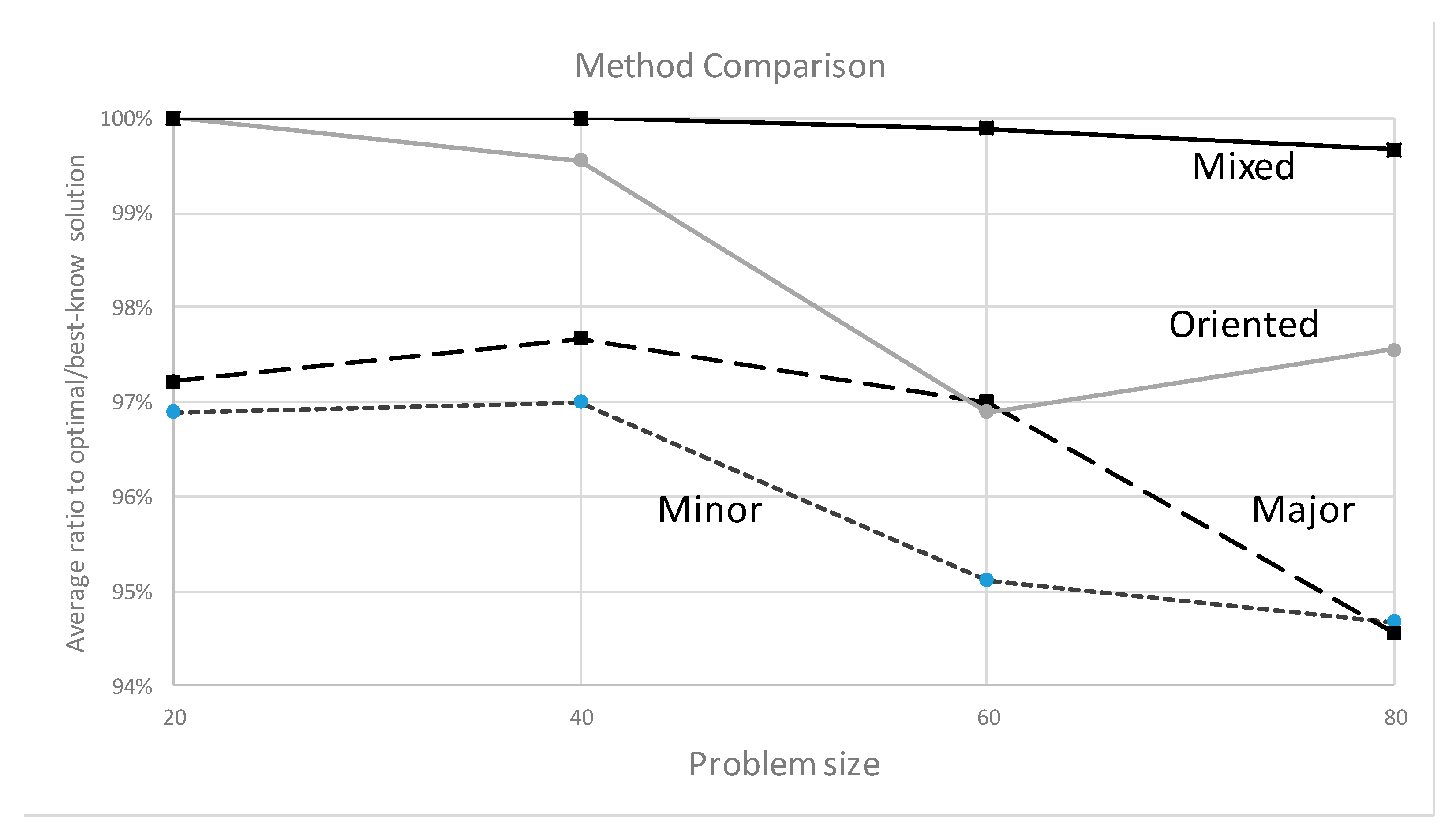
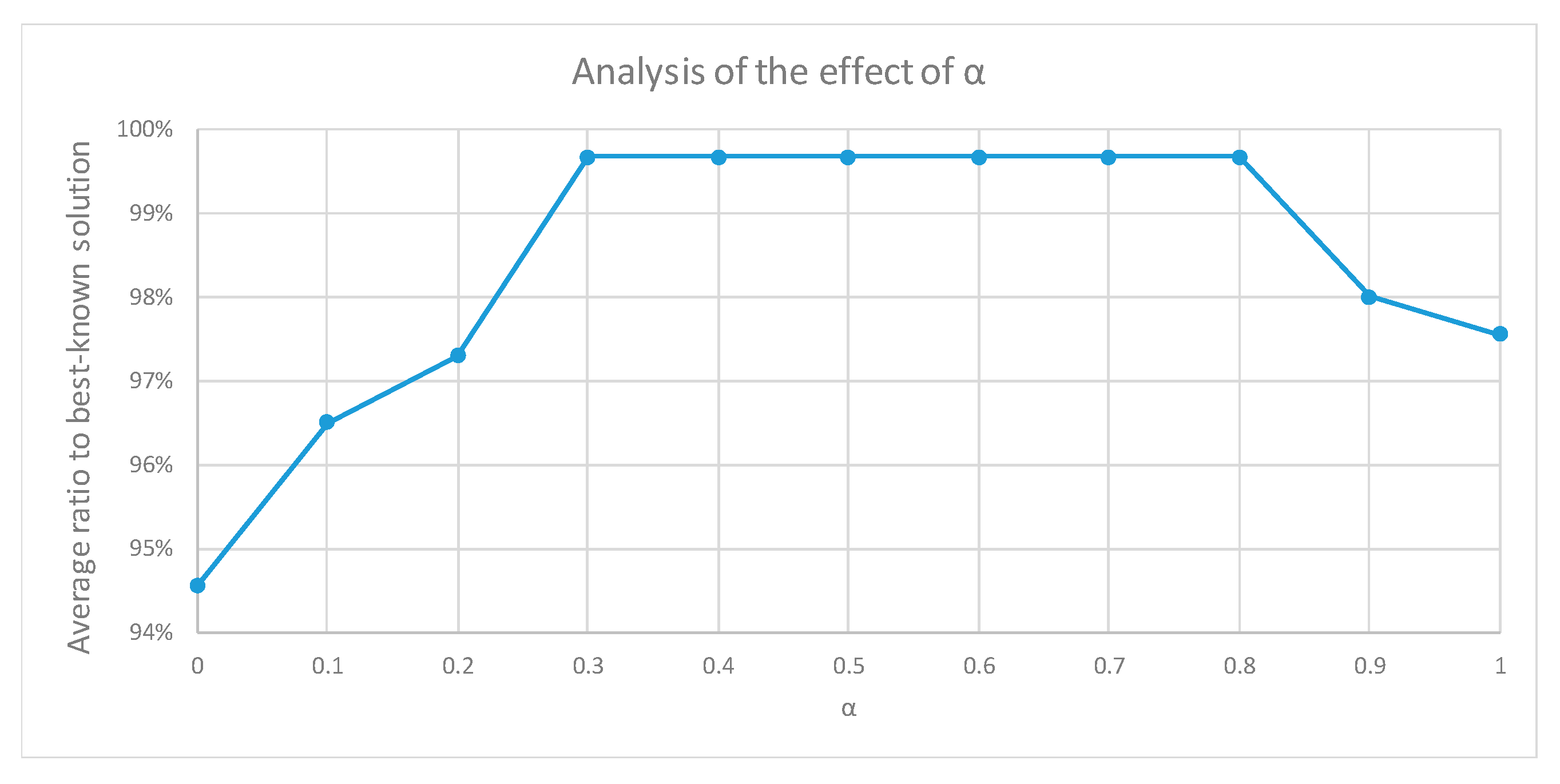
7.3. Initial Results
8. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Problem Example
Appendix A.1. Projects
Appendix A.2. Resources

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Resource Requirement | Project | Resource Requirement |
|---|---|---|---|
| 1 | 2 | 6 | 3 |
| 2 | 3 | 7 | 2 |
| 3 | 1 | 8 | 2 |
| 4 | 3 | 9 | 3 |
| 5 | 2 | 10 | 1 |
Appendix A.3. Planning Horizon
Appendix A.4. Projects’ Values
| Project | Value | Project | Value |
|---|---|---|---|
| 1 | 1 | 6 | 2 |
| 2 | 1 | 7 | 8 |
| 3 | 1 | 8 | 2 |
| 4 | 1 | 9 | 2 |
| 5 | 1 | 10 | 3 |
Appendix A.5. Objective Function
Appendix A.6. Single Completion Year Constraints
Appendix A.7. Precedence Constraints
Appendix A.8. Resource Requirements
Appendix A.9. Resource Consumption Constraints
Appendix A.10. Resource Limitations
Appendix A.11. Precedence Constraints
References
- Tavana, M.; Keramatpour, M.; Santos-Arteaga, F.J.; Ghorbaniane, E. A fuzzy hybrid project portfolio selection method using Data Envelopment Analysis, TOPSIS and Integer Programming. Expert Syst. Appl. 2015, 42, 8432–8444. [Google Scholar] [CrossRef]
- Gutiérrez, E.; Magnusson, M. Dealing with legitimacy: A key challenge for Project Portfolio Management decision makers. Int. J. Proj. Manag. 2014, 32, 30–39. [Google Scholar] [CrossRef]
- Jonas, D. Empowering project portfolio managers: How management involvement impacts project portfolio management performance. Int. J. Proj. Manag. 2010, 28, 818–831. [Google Scholar] [CrossRef]
- Killen, C.; Hunt, R. Dynamic capability through project portfolio management in service and manufacturing industries. Int. J. Manag. Proj. Bus. 2010, 3, 157–169. [Google Scholar] [CrossRef] [Green Version]
- Meskendahl, S. The influence of business strategy on project portfolio management and its success—a conceptual framework. Int. J. Proj. Manag. 2010, 28, 807–817. [Google Scholar] [CrossRef]
- Lechler, T.G.; Thomas, J.L. Examining new product development project termination decision quality at the portfolio level: Consequences of dysfunctional executive advocacy. Int. J. Proj. Manag. 2015, 33, 1452–1463. [Google Scholar] [CrossRef]
- Martinsuo, M. Project portfolio management in practice and in context. Int. J. Proj. Manag. 2013, 31, 794–803. [Google Scholar] [CrossRef]
- Pendharkar, P.C. A decision-making framework for justifying a portfolio of IT projects. Int. J. Proj. Manag. 2014, 32, 625–639. [Google Scholar] [CrossRef]
- Dutra, C.C.; Ribeiro, J.L.D.; de Carvalho, M.M. An economic–probabilistic model for project selection and prioritization. Int. J. Proj. Manag. 2014, 32, 1042–1055. [Google Scholar] [CrossRef]
- Meade, L.M.; Presley, A. R&D project selection using the analytic network process. IEEE Trans. Eng. Manag. 2002, 49, 59–66. [Google Scholar]
- Jafarzadeh, M.; Tareghian, H.R.; Rahbarnia, F.; Ghanbari, R. Optima lselection of project portfolios using reinvestment strategy within a flexible time horizon. Eur. J. Oper. Res. 2015, 243, 658–664. [Google Scholar] [CrossRef]
- Frey, T.; Buxmann, P. IT Project Portfolio Management—A Structured Literature Review. In Proceedings of the 20th European Conference on Information Systems, Barcelona, Spain, 10–13 June 2012. [Google Scholar]
- Weissenberger-Eibl, M.A.; Teufel, B. Organizational politics in new product development project selection. Eur. J. Innov. Manag. 2011, 14, 51–73. [Google Scholar] [CrossRef]
- Padhy, R. Six Sigma project selections: A critical review. Int. J. Lean Six Sigma 2017, 8, 244–258. [Google Scholar] [CrossRef]
- Condé, G.C.P.; Mauro, L.M. Six sigma project generation and selection: Literature review and feature based method proposition. Prod. Plan. Control. 2020, 31, 1303–1312. [Google Scholar] [CrossRef]
- Danesh, D.; Ryan, M.J.; Abbasi, A. Multi-criteria decision-making methods for project portfolio management: A literature review. Int. J. Manag. Decis. Mak. 2018, 17, 75–94. [Google Scholar] [CrossRef]
- Mohagheghi, V.; Mousavi, S.M.; Antuchevičienė, J.; Mojtahedi, M. Project portfolio selection problems: A review of models, uncertainty approaches, solution techniques, and case studies. Technol. Econ. Dev. Econ. 2019, 25, 1380–1412. [Google Scholar] [CrossRef]
- Hall, N.G.; Long, D.Z.; Qi, J.; Sim, M. Managing underperformance risk in project portfolio selection. Oper. Res. 2015, 63, 660–675. [Google Scholar] [CrossRef] [Green Version]
- Tofighian, A.A.; Naderi, B. Modeling and solving the project selection and scheduling. Comput. Ind. Eng. 2015, 83, 30–38. [Google Scholar] [CrossRef]
- Gutjahr, W.J.; Reiter, P. Bi-objective project portfolio selection and staff assignment under uncertainty. Optimization 2010, 59, 417–445. [Google Scholar] [CrossRef]
- Ghapanchi, A.H.; Tavana, M.; Khakbaz, M.H.; Low, G. A methodology for selecting portfolios of projects with interactions and under uncertainty. Int. J. Proj. Manag. 2012, 30, 791–803. [Google Scholar] [CrossRef]
- Mutavdzic, M.; Maybee, B. An extension of portfolio theory in selecting projects to construct a preferred portfolio of petroleum assets. J. Pet. Sci. Eng. 2015, 133, 518–528. [Google Scholar] [CrossRef]
- Arratia, N.M.; Lόpez, F.; Schaeffer, S.E.; Cruz-Reyes, L. Static R&D project portfolio selection in public organizations. Decis. Support Syst. 2016, 84, 53–63. [Google Scholar]
- Kalashnikov, V.; Benita, F.; López-Ramos, F.; Hernández-Luna, A. Bi-objective project portfolio selection in Lean Six Sigma. Int. J. Prod. Econ. 2017, 186, 81–88. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, L.; Li, S.; Chen, Z.; Cheng, Y. Balancing strategic contributions and financial returns: A project portfolio selection model under uncertainty. Soft Comput. 2018, 22, 5547–5559. [Google Scholar] [CrossRef]
- Carazo, A.F.; Gómez, T.; Molina, J.; Hernández-Díaz, A.G.; Guerrero, F.M.; Caballero, R. Solving a comprehensive model for multiobjective project portfolio selection. Comput. Oper. Res. 2010, 37, 630–639. [Google Scholar] [CrossRef]
- Kremmel, T.; Kubalík, J.; Biffl, S. Software project portfolio optimization with advanced multiobjective evolutionary algorithms. Appl. Soft Comput. 2011, 11, 1416–1426. [Google Scholar] [CrossRef]
- Liesiö, J.; Punkka, A. Baseline value specification and sensitivity analysis in multiattribute project portfolio selection. Eur. J. Oper. Res. 2014, 237, 946–956. [Google Scholar] [CrossRef]
- Hassanzadeh, F.; Nemati, H.; Sun, M. Robust optimization for interactive multiobjective programming with imprecise information applied to R&D project portfolio selection. Eur. J. Oper. Res. 2014, 238, 41–53. [Google Scholar]
- Shou, Y.; Xiang, W.; Li, Y.; Yao, W. A multiagent evolutionary algorithm for the resource-constrained project portfolio selection and scheduling problem. Math. Probl. Eng. 2014, 2014, 302684. [Google Scholar] [CrossRef] [Green Version]
- Dehouche, N. Non-profit project portfolio evaluation and selection: A multi-criteria approach. Int. J. Appl. Manag. Sci. 2015, 7, 338–363. [Google Scholar] [CrossRef]
- Fliedner, T.; Liesiö, J. Adjustable robustness for multi-attribute project portfolio selection. Eur. J. Oper. Res. 2016, 252, 931–946. [Google Scholar] [CrossRef]
- Perez, F.; Gomez, T. Multiobjective project portfolio selection with fuzzy constraints. Ann. Oper. Res. 2016, 245, 7–29. [Google Scholar] [CrossRef]
- Danesh, D.; Ryan, M.J.; Abbasi, A. A systematic comparison of multi-criteria decision making methods for the improvement of project portfolio management in complex organisations. Int. J. Manag. Decis. Mak. 2017, 16, 280–320. [Google Scholar]
- Ehsani, E.; Kazemi, N.; Olugu, E.U.; Grosse, E.H.; Schwindl, K. Applying fuzzy multi-objective linear programming to a project management decision with nonlinear fuzzy membership functions. Neural Comput. Appl. 2017, 28, 2193–2206. [Google Scholar] [CrossRef]
- El-Kholany, M.M.; Abdelsalam, H.M. Multi-objective binary cuckoo search for constrained project portfolio selection under uncertainty. Eur. J. Ind. Eng. 2017, 11, 818–853. [Google Scholar] [CrossRef]
- Liu, F.; Chen, Y.W.; Yang, J.B.; Xu, D.L.; Liu, W. Solving multiple-criteria R&D project selection problems with a data-driven evidential reasoning rule. Int. J. Proj. Manag. 2019, 37, 87–97. [Google Scholar]
- Pérez, F.; Gómez, T.; Caballero, R.; Liern, V. Project portfolio selection and planning with fuzzy constraints. Technol. Forecast. Soc. Chang. 2018, 131, 117–129. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.-K. Distributionally robust fuzzy project portfolio optimization problem with interactive returns. Appl. Soft Comput. 2017, 56, 655–668. [Google Scholar] [CrossRef]
- Takami, M.A.; Sheikh, R.; Sana, S.S. A Hesitant Fuzzy Set Theory Based Approach for Project Portfolio Selection with Interactions under Uncertainty. J. Inf. Sci. Eng. 2018, 34, 65–79. [Google Scholar]
- Naderi, B. The project portfolio selection and scheduling problem: Mathematical model and algorithms. J. Optim. Ind. Eng. 2013, 6, 65–72. [Google Scholar]
- Wang, B.; Song, Y. Reinvestment Strategy-Based Project Portfolio Selection and Scheduling with Time-Dependent Budget Limit Considering Time Value of Capital. In Proceedings of the 2015 International Conference on Electrical and Information Technologies for Rail Transportation, Zhuzhou, China, 17–19 October 2015; Springer: Berlin/Heidelberg, Germany, 2016; pp. 373–381. [Google Scholar]
- Martínez-Vega, D.A.; Cruz-Reyes, L.; Rangel-Valdez, N.; Santillán, C.G.; Sánchez-Solís, P.; Villafuerte, M.P. Project portfolio selection with scheduling: An evolutionary approach. Int. J. Comb. Optim. Probl. Inform. 2019, 10, 25–31. [Google Scholar]
- Killen, C.P.; Jugdev, K.; Drouin, N.; Petit, Y. Advancing project and portfolio management research: Applying strategic management theories. Int. J. Proj. Manag. 2012, 30, 525–538. [Google Scholar] [CrossRef]
- Jeng, D.J.-F.; Huang, K.-H. Strategic project portfolio selection for national research institutes. J. Bus. Res. 2015, 68, 2305–2311. [Google Scholar] [CrossRef]
- Kopmann, J.; Kock, A.; Killen, C.P.; Gemünden, H.G. The role of project portfolio management in fostering both deliberate and emergent strategy. Int. J. Proj. Manag. 2017, 35, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, M.G.; el Arbi, F.; Ahlemann, F. Successful project portfolio management beyond project selection techniques: Understanding the role of structural alignment. Int. J. Proj. Manag. 2015, 33, 126–139. [Google Scholar] [CrossRef]
- Hoof, V.; Broeckx, F. Specification of Queuing Models: An Alternative Notation. Int. J. Model. Simul. 1982, 2, 67–70. [Google Scholar] [CrossRef]
- Pajares, J.; López, A. New Methodological Approaches to Project Portfolio Management: The Role of Interactions within Projects and Portfolios. Procedia—Soc. Behav. Sci. 2014, 119, 645–652. [Google Scholar] [CrossRef] [Green Version]
- Shariatmadari, M.; Nahavandi, N.; Zegordi, S.H.; Mohammad, H.S. Integrated resource management for simultaneous project selection and scheduling. Comput. Ind. Eng. 2017, 109, 39–47. [Google Scholar] [CrossRef]
- Li, X.; Fang, S.-C.; Tian, Y.; Guo, X. Expanded model of the project portfolio selection problem with divisibility, time profile factors and cardinality constraints. J. Oper. Res. Soc. 2015, 66, 1132–1139. [Google Scholar] [CrossRef]
- Rafiee, M.; Kianfar, F.; Farhadkhani, M. A multistage stochastic programming approach in project selection and scheduling. Int. J. Adv. Manuf. Technol. 2014, 70, 2125–2137. [Google Scholar] [CrossRef]
- Sefair, J.A.; Méndez, C.Y.; Babat, O.; Medaglia, A.L.; Zuluaga, L.F. Linear solution schemes for Mean-SemiVariance Project portfolio selection problems: An application in the oil and gas industry. Omega 2018, 68, 39–48. [Google Scholar] [CrossRef]
- Samphaiboon, N.; Yamada, T. Heuristic and exact algorithms for the precedence-constrained knapsack problem. J. Optim. Theory Appl. 2000, 105, 659–676. [Google Scholar] [CrossRef]
- de Castro, L.; von Zuben, F.J. The Clonal Selection Algorithm with Engineering Applications. In Proceedings of the Workshop on Artificial Immune Systems and Their Applications, Las Vegas, NV, USA, 8–12 July 2000. [Google Scholar]
- Swain, R.K.; Barisal, A.K.; Hota, P.K.; Chakrabarti, R. Short-term hydrothermal scheduling using clonal selection algorithm. Int. J. Electr. Power Energy Syst. 2011, 33, 647–656. [Google Scholar] [CrossRef]
- Attwater, J.; Holliger, P. The cooperative gene. Nature 2012, 491, 48–49. [Google Scholar] [CrossRef] [PubMed]
- Bohl, K.; Hummert, S.; Werner, S.; Basanta, D.; Deutsch, A.; Schuster, S.; Theißen, G.; Schroeter, A. Evolutionary game theory: Molecules as players. Mol. BioSyst. 2014, 10, 3066–3074. [Google Scholar] [CrossRef] [Green Version]
- Furubayashi, T.; Ueda, K.; Bansho, Y.; Motooka, D.; Nakamura, S.; Mizuuchi, R.; Ichihashi, N. Emergence and diversification of a host-parasite RNA ecosystem through Darwinian evolution. Elife 2020, 9, e56038. [Google Scholar] [CrossRef]
- Seifoddini, H.; Wolfe, P.M. Application of the similarity coefficient method in group technology. IIE Trans. 1986, 18, 271–277. [Google Scholar] [CrossRef]
- Selim, H.M.; Askin, R.G.; Vakharia, A.J. Cell formation in group technology: Review, evaluation and directions for future research. Comput. Ind. Eng. 1998, 34, 3–20. [Google Scholar] [CrossRef]
- Lu, P.; Zhang, Z. Critical nodes identification in complex networks via similarity coefficient. Mod. Phys. Lett. B 2022, 36, 2150620. [Google Scholar] [CrossRef]
- Wu, L.; Shen, Y.; Niu, B.; Li, L.; Yang, C.; Feng, Y. Similarity coefficient-based cell formation method considering operation sequence with repeated operations. Eng. Optim. 2021, 22, 1–15. [Google Scholar] [CrossRef]
- Yang, Z.; Qiao, T.; Ren, J.; Yuen, P.; Zhao, H.; Sun, G.; Marshall, S.; Benediktsson, J.A. Joint bilateral filtering and spectral similarity-based sparse representation: A generic framework for effective feature extraction and data classification in hyperspectral imaging. Pattern Recognit. 2018, 77, 316–328. [Google Scholar]
- Erlich, Z.; Gelbard, R.; Spiegler, I. Data Mining by Means of Binary Representation: A Model for Similarity and Clustering. Inf. Syst. Front. 2002, 4, 187–197. [Google Scholar] [CrossRef]
- Lozano, M.; García-Martínez, C. Hybrid metaheuristics with evolutionary algorithms specializing in intensification and diversification: Overview and progress report. Comput. Oper. Res. 2010, 37, 481–497. [Google Scholar] [CrossRef]
- Scheibenpflug, A.; Wagner, S. An Analysis of the Intensification and Diversification Behavior of Different Operators for Genetic Algorithms. In Proceedings of the 14th International Conference on Computer Aided Systems Theory, Las Palmas, Spain, 10–15 February 2013. [Google Scholar]









| Reference | Objective Type | Solution Type | Data Type | Constraints Combination | |
|---|---|---|---|---|---|
| 1 | [33] | Multi-objective | Efficient frontier | Fuzzy | P, RL, DR, T |
| 2 | [49] | Strategic selection | None | Deterministic | P, RL, DR, T |
| 3 | [50] | Single-objective selection | Optimized | Deterministic | P, RL, DR, T |
| 4 | [51] | Single-objective selection | Optimized | Deterministic | P, RL, DR, T |
| 5 | [52] | Single-objective selection | Optimized | Known random distribution | P, RL, DR, T |
| 6 | [53] | Profit vs. risk selection | Optimized | Known random distribution | None |
| 7 | [32] | Multi-objective | Robust selection | Deterministic | P, RL, DR, T |
| Notation | Definition |
|---|---|
| A vector of all the depreciation values of the years. is the value of year . | |
| A matrix containing the available resources at each year in the planning horizon. is the level of resource at year . | |
| A matrix containing the required resources for each project. is the requirement of resource of project . | |
| A vector of all the contributions (values) of the projects. is the value of project . | |
| A matrix containing technical dependencies. has the following values: | |
| Decision variable matrix. has the following values: | |
| Total portfolio value. | |
| Auxiliary variables, denoting the years the project is in process. | |
| Auxiliary decision variables denoting the level of resources used by a project in any given year. | |
| Number of projects in the examined portfolio. | |
| Planning horizon (number of years). | |
| R | Number of resource types. |
| Genotype vector. | |
| Indices: —Year index. —Resource index. —Project index. |
| Connectivity | Resources | Minor | Major | Oriented | Mixed |
|---|---|---|---|---|---|
| Low | 1 | 1 | 1 | 1 | 1 |
| 2 | 0.94 | 0.94 | 1 | 1 | |
| 3 | 0.93 | 0.96 | 1 | 1 | |
| Med | 1 | 1 | 1 | 1 | 1 |
| 2 | 0.96 | 1 | 1 | 1 | |
| 3 | 0.93 | 0.94 | 1 | 1 | |
| High | 1 | 1 | 1 | 1 | 1 |
| 2 | 0.96 | 0.96 | 1 | 1 | |
| 3 | 1 | 0.95 | 1 | 1 |
| Problem Size | Connectivity | Resources | Minor | Major | Oriented | Mixed |
|---|---|---|---|---|---|---|
| 40 | Low | 1 | 1 | 1 | 1 | 1 |
| 2 | 0.94 | 0.96 | 1 | 1 | ||
| 3 | 0.93 | 0.93 | 0.96 | 1 | ||
| Med | 1 | 1 | 1 | 1 | 1 | |
| 2 | 0.96 | 1 | 1 | 1 | ||
| 3 | 0.94 | 0.94 | 1 | 1 | ||
| High | 1 | 1 | 1 | 1 | 1 | |
| 2 | 0.96 | 0.96 | 1 | 1 | ||
| 3 | 1 | 1 | 1 | 1 | ||
| 60 | Low | 1 | 0.95 | 1 | 1 | 1 |
| 2 | 0.99 | 0.98 | 0.96 | 1 | ||
| 3 | 0.91 | 0.95 | 0.96 | 1 | ||
| Med | 1 | 0.97 | 1 | 1 | 1 | |
| 2 | 0.91 | 1 | 0.94 | 0.99 | ||
| 3 | 0.99 | 0.97 | 0.95 | 1 | ||
| High | 1 | 0.96 | 0.96 | 0.93 | 1 | |
| 2 | 0.95 | 0.97 | 1 | 1 | ||
| 3 | 0.93 | 0.9 | 0.98 | 1 | ||
| 80 | Low | 1 | 0.91 | 0.92 | 1 | 1 |
| 2 | 1 | 0.93 | 0.97 | 1 | ||
| 3 | 0.99 | 0.94 | 0.96 | 0.99 | ||
| Med | 1 | 0.9 | 0.96 | 0.97 | 1 | |
| 2 | 0.93 | 0.96 | 1 | 1 | ||
| 3 | 0.94 | 0.96 | 0.96 | 1 | ||
| High | 1 | 0.97 | 0.91 | 0.99 | 1 | |
| 2 | 0.91 | 0.99 | 0.97 | 1 | ||
| 3 | 0.97 | 0.94 | 0.96 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Etgar, R.; Cohen, Y. Roadmap Optimization: Multi-Annual Project Portfolio Selection Method. Mathematics 2022, 10, 1601. https://doi.org/10.3390/math10091601
Etgar R, Cohen Y. Roadmap Optimization: Multi-Annual Project Portfolio Selection Method. Mathematics. 2022; 10(9):1601. https://doi.org/10.3390/math10091601
Chicago/Turabian StyleEtgar, Ran, and Yuval Cohen. 2022. "Roadmap Optimization: Multi-Annual Project Portfolio Selection Method" Mathematics 10, no. 9: 1601. https://doi.org/10.3390/math10091601