
STAGCN: Spatial–Temporal Attention Graph Convolution Network for Traffic Forecasting

Abstract
:1. Introduction
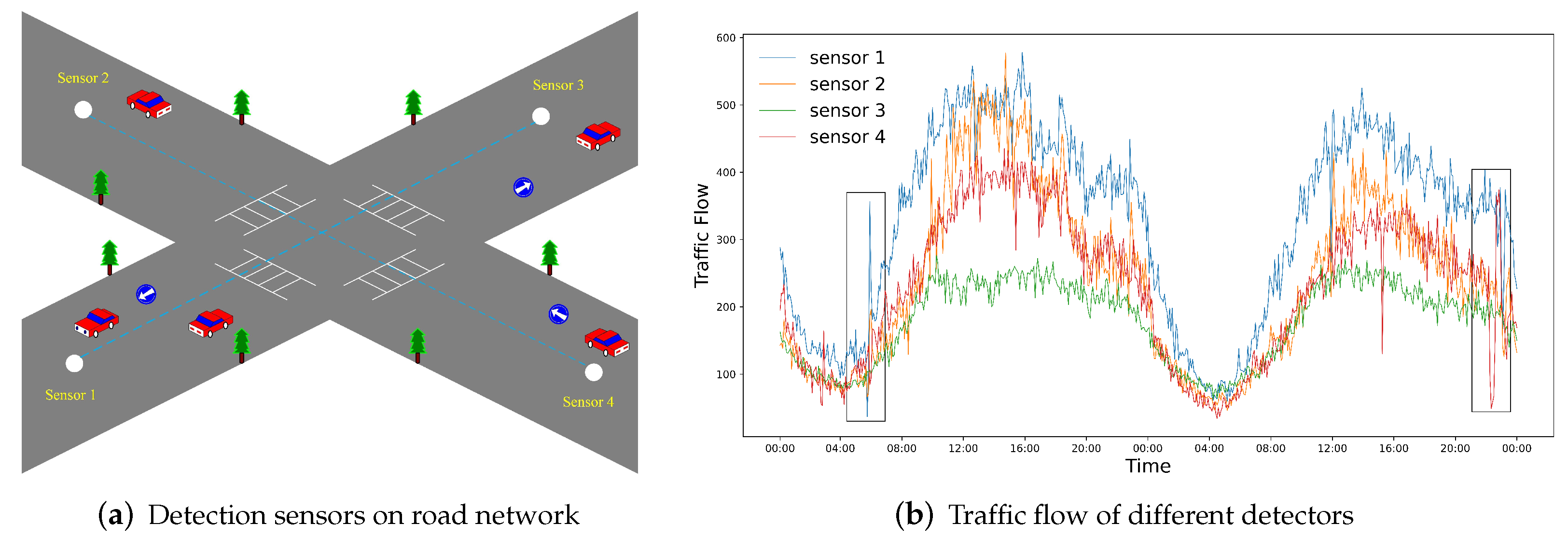
- Global adaptability and local dynamics. Most GCNs only focus on constructing an adaptive graph matrix to capture long-term or global space dependencies in traffic data, while overlooking the fact that the correlation between local nodes is changing significantly over time. As shown in Figure 1, sudden traffic accidents may lead to local changes in spatial correlation among nodes. The primary question is how to keep the balance between global adaptability and local dynamics in an end-to-end work.
- Long-term temporal correlations. Current graph-based methods are ineffective to model long-term temporal dependencies. Existing methods either integrate GCNs into RNNs or CNNs, in which small prediction errors at each time step may be magnified as the prediction interval grows. This type of error forward propagation makes long-term forecasting more challenging.
- We propose a novel graph learning layer to explore the interactions between global space adaptability and local dynamics in traffic networks without any guidance of prior knowledge. The static graph aims to model global adaptability, and the dynamic graph is designed to capture local spatial changes.
- We propose a gated temporal attention module to model long-term temporal dependencies. Furthermore, we design a causal-trend attention mechanism that enables our model to extract causality and local trends in time series.
- Extensive experiments are conducted on four public traffic datasets, and the experimental results show that our method consistently outperforms all baseline methods.
2. Related work
2.1. Traffic Forecasting
2.2. Graph Convolutional Network
2.3. Attention Mechanism
3. Methodology
3.1. Preliminaries
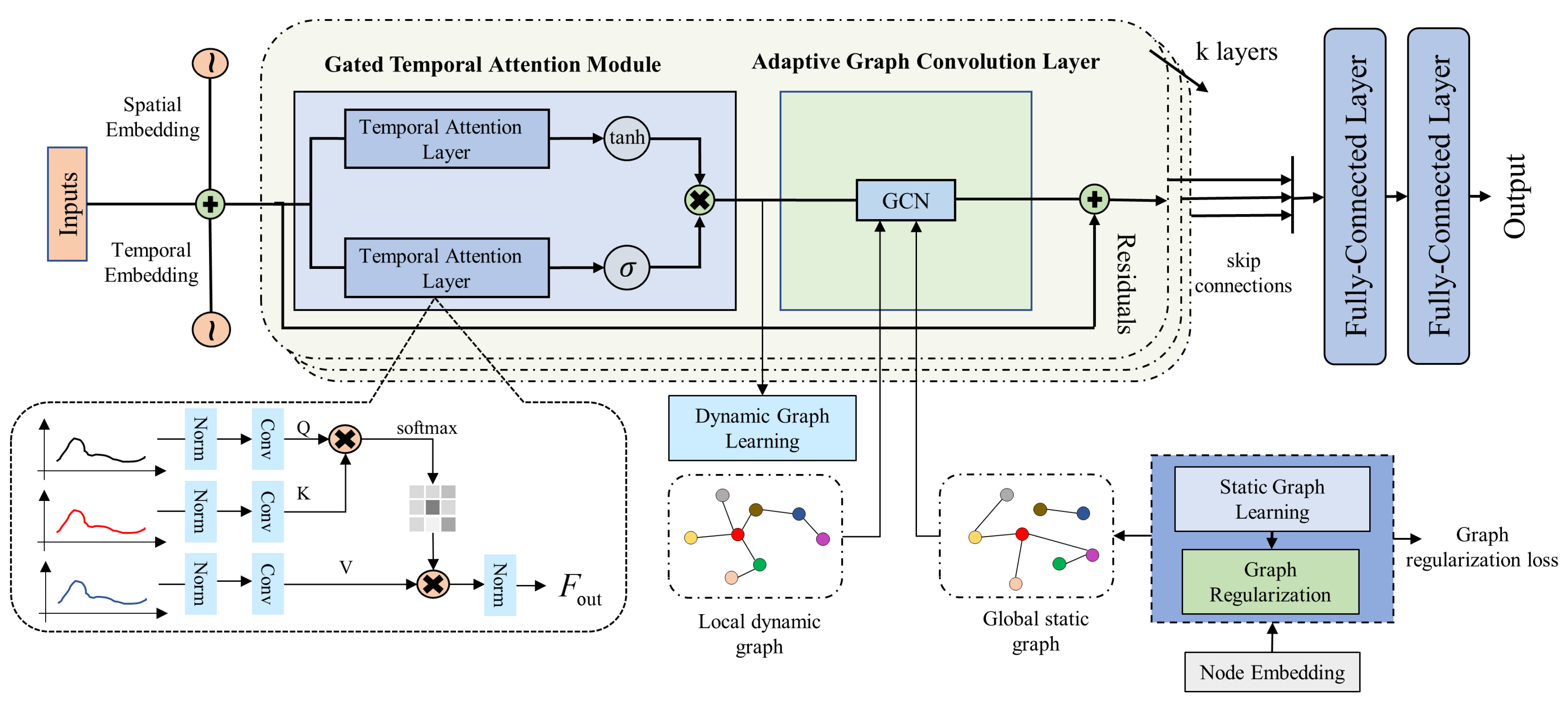
3.2. Framework of STAGCN
3.3. Spatial Static–Dynamic Graph Learning Layer
3.3.1. Static Graph Learning
3.3.2. Dynamic Graph Learning
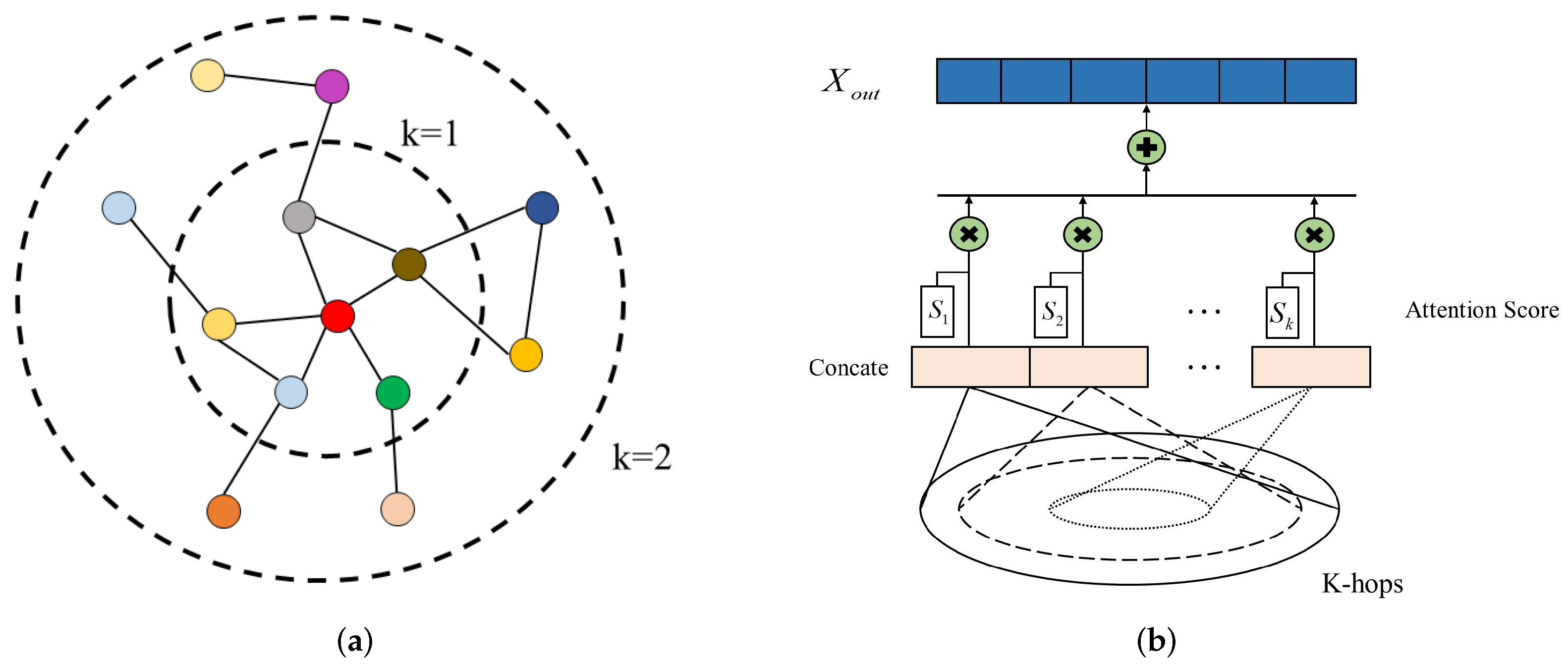
3.4. Adaptive Graph Convolution Module
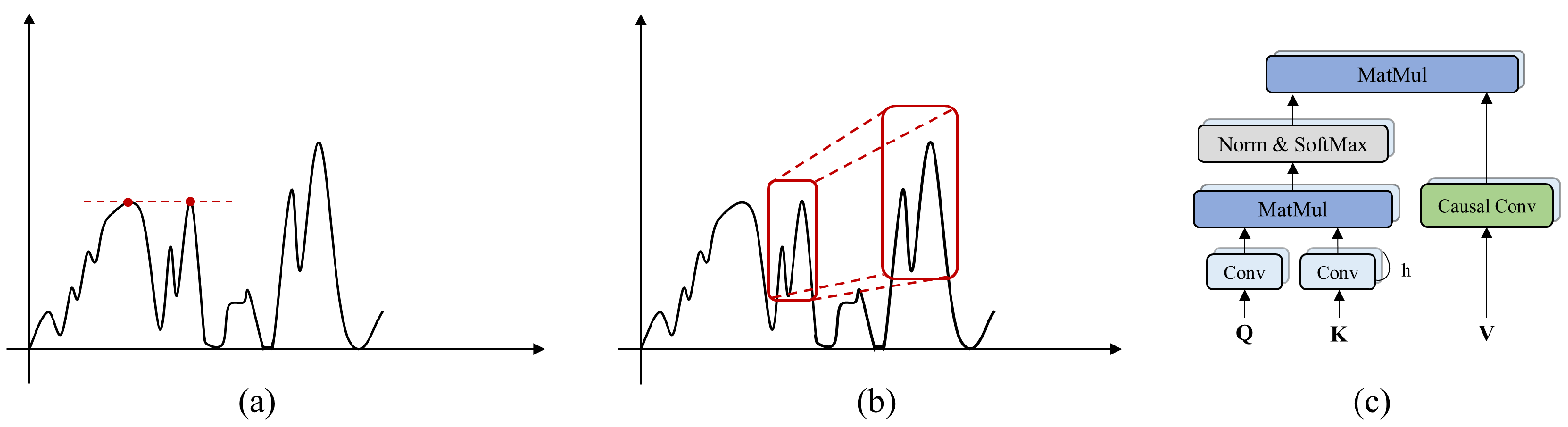
3.5. Gated Temporal Attention Module
3.6. Extra Components
3.6.1. Spatial–Temporal Embedding
3.6.2. Loss Function
4. Experiments
4.1. Datasets
4.2. Experimental Setting
4.3. Baseline Methods
- SVR: Support vector regression [31], which uses a support vector machine for prediction tasks.
- FC-LSTM: LSTM encoder–decoder predictor model, which employs a recurrent neural network with fully connected LSTM hidden units [32].
- DCRNN: Diffusion convolutional recurrent neural network [12], which integrates diffusion graph convolution into gated recurrent units.
- STGCN: Spatio–temporal graph convolutional network [33], which adopts graph convolutional and causal convolutional layers to model spatial and temporal dependencies.
- ASTGCN (r): Attention-based spatial-temporal graph convolutional network [34], which designs a spatiotemporal attention mechanism for traffic forecasting. It ensembles three different components to model the periodicity of traffic data, and we only use its recent input segment for a fair comparison.
- STSGCN: Spatial–temporal synchronous graph convolutional network [14], which captures correlations directly through a localized spatial–temporal graph.
- AGCRN: Adaptive graph convolutional recurrent network [35], which captures the node-specific spatial and temporal dynamics through a generated adaptive graph.
- STFGNN: Spatial–temporal fusion graph neural networks [36], which use the dynamic time warping algorithm (DTW) for graph construction to explore local and global spatial correlations.
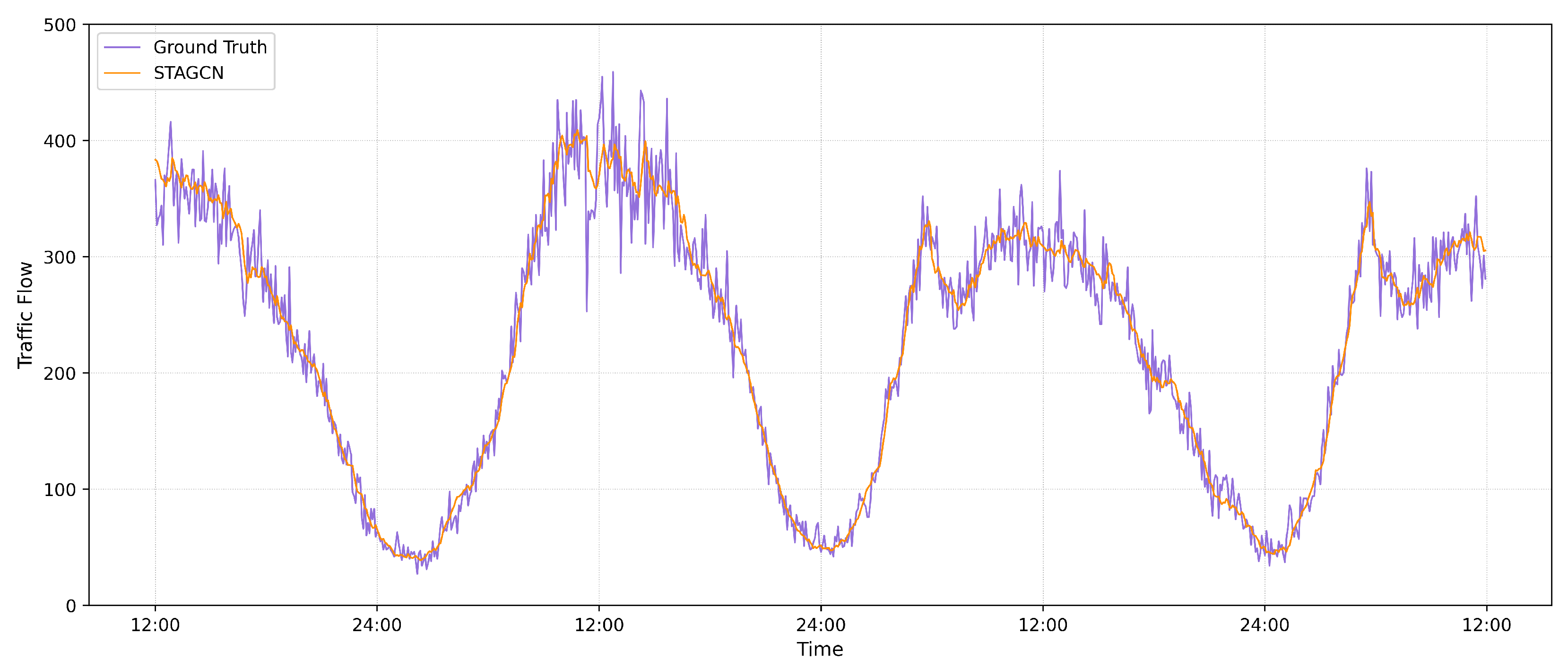
4.4. Experimental Results
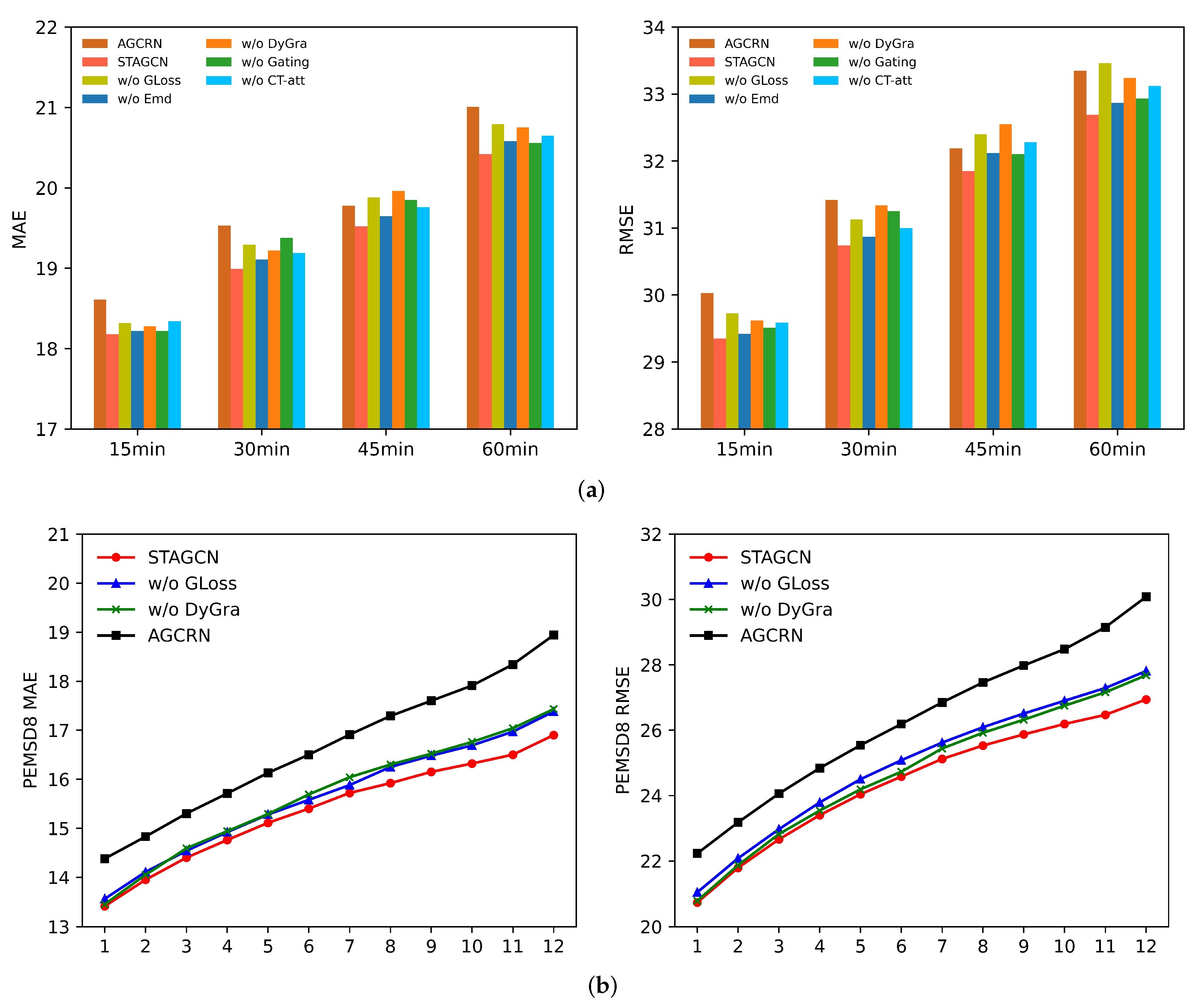
4.5. Ablation Study
- w/o GLoss: STAGCN without graph regularization loss.
- w/o Emb: STAGCN without spatial and temporal embedding.
- w/o DyGra: STAGCN without dynamic graph learning layer. We only use a static graph learning layer to adaptively model spatial correlation.
- w/o Gating: STAGCN without gating mechanism. We pass the output of the temporal attention layer to the next module directly without information selection.
- w/o CT-Att: STAGCN without causal-trend attention. We use traditional multi-head self-attention to replace causal-trend attention without considering local trends.
- As Figure 5a illustrates, removing graph regularization loss diminishes the performance significantly. This is because the graph loss function could optimize the adaptive traffic graph structure and facilitate graph information propagation. If the graph regularization loss function is removed, the learned adaptive graph matrix will not effectively reflect global spatial correlations in the traffic network. The result also indirectly proves that global spatial dependency has significant impacts on prediction performance.
- After removing the dynamic graph learning layer, the performance of our model gradually deteriorates over the 12 prediction time steps, which is evident in RMSE for the PEMS4 dataset and MAE for the PEMS8 dataset. We conjecture that the reason is that the long-term spatial dependencies have changed significantly, and the global graph structure cannot perceive fine-grained local spatial information. Our dynamic graph can capture local changing spatial correlations and overcome this shortcoming.
- STAGCN without the causal-trend attention mechanism performs much worse than STAGCN, demonstrating that modeling the causality and local trends in time series has better prediction performance than the traditional multi-head self-attention mechanism. Furthermore, the spatiotemporal embedding and gated mechanism are also essential, as they can improve the prediction accuracy at each prediction horizon.
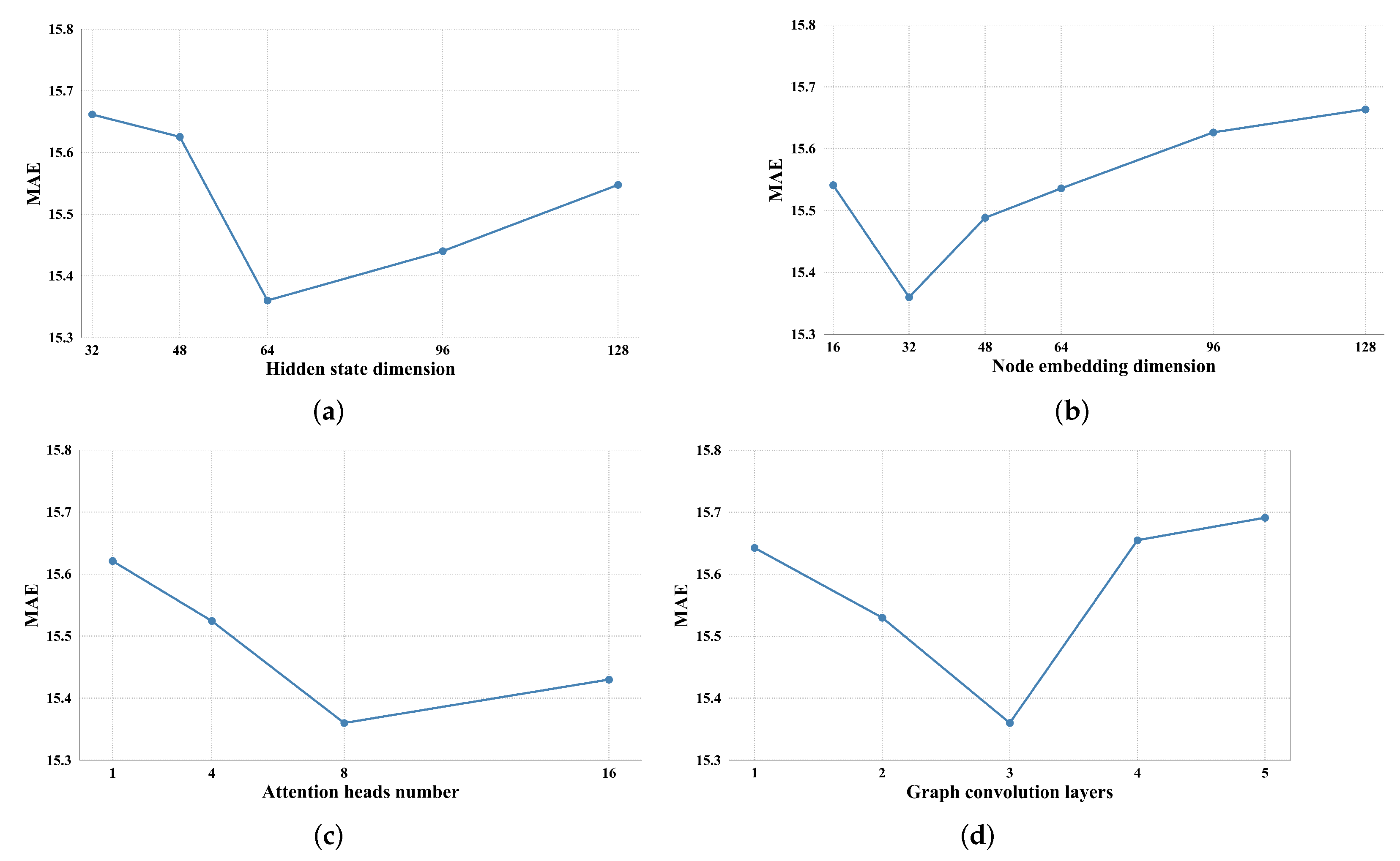
4.6. Parameter Study
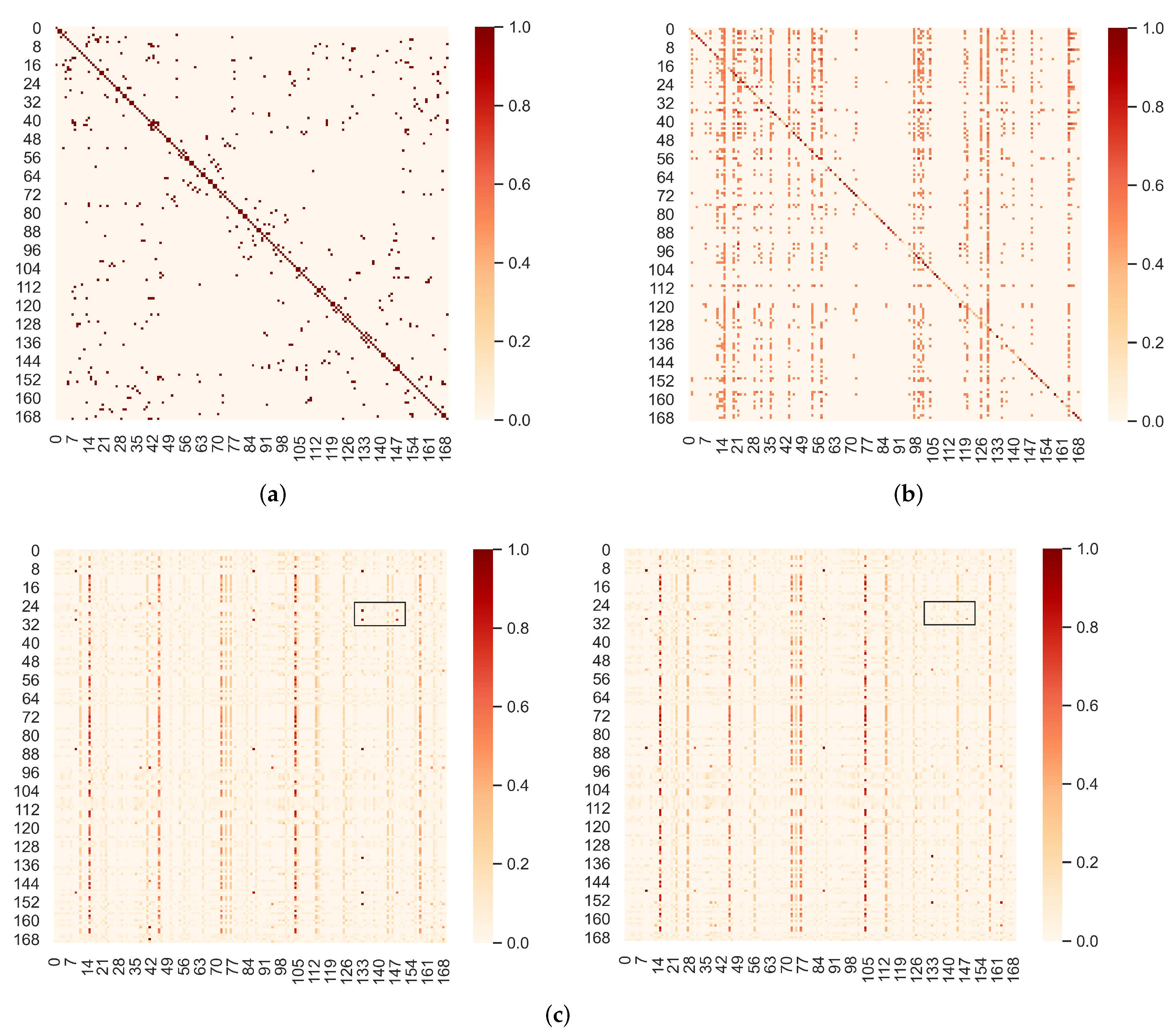
4.7. Effect of Graph Learning Layer
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, R.; Huang, C.; Liu, Y.; Dai, G.; Kong, W. LSGCN: Long Short-Term Traffic Prediction with Graph Convolutional Networks. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; pp. 2355–2361. [Google Scholar]
- Fang, Y.; Qin, Y.; Luo, H.; Zhao, F.; Zeng, L.; Hui, B.; Wang, C. CDGNet: A Cross-Time Dynamic Graph-based Deep Learning Model for Traffic Forecasting. arXiv 2021, arXiv:2112.02736. [Google Scholar]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. Part C Emerg. Technol. 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Chen, Y.; Wu, L.; Zaki, M. Iterative deep graph learning for graph neural networks: Better and robust node embeddings. Adv. Neural Inf. Process. Syst. 2020, 33, 19314–19326. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Dong, H.; Wang, X.; Han, S. Time series prediction based on temporal convolutional network. In Proceedings of the 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 300–305. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3482–3489. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, X.; Zhu, M.; Bo, D.; Cui, P.; Shi, C.; Pei, J. Am-gcn: Adaptive multi-channel graph convolutional networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1243–1253. [Google Scholar]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 914–921. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 5165–5175. [Google Scholar]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery &Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2018, 1050, 4. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9267–9276. [Google Scholar]
- Wang, D.B.; Zhang, M.L.; Li, L. Adaptive graph guided disambiguation for partial label learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27–28 October 2019; pp. 10705–10714. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5589–5598. [Google Scholar]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. Gman: A graph multi-attention network for traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1234–1241. [Google Scholar]
- Li, Z.; Zhang, G.; Xu, L.; Yu, J. Dynamic Graph Learning-Neural Network for Multivariate Time Series Modeling. arXiv 2021, arXiv:2112.03273. [Google Scholar]
- Liu, M.; Gao, H.; Ji, S. Towards deeper graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 338–348. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Guo, S.; Lin, Y.; Wan, H.; Li, X.; Cong, G. Learning dynamics and heterogeneity of spatial-temporal graph data for traffic forecasting. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1996, 9, 155–161. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2014; Volume 27. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 3634–3640. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 922–929. [Google Scholar]
- Bai, L.; Yao, L.; Li, C.; Wang, X.; Wang, C. Adaptive graph convolutional recurrent network for traffic forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17804–17815. [Google Scholar]
- Li, M.; Zhu, Z. Spatial-temporal fusion graph neural networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4189–4196. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Samples | Nodes | Time Range |
|---|---|---|---|
| PEMS03 | 26,208 | 358 | 1 September 2018–30 November 2018 |
| PEMS04 | 16,992 | 307 | 1 January 2018–28 February 2018 |
| PEMS07 | 28,224 | 883 | 1 May 2017–31 August 2017 |
| PEMS08 | 17,856 | 170 | 1 July 2016–31 August 2016 |
| Datasets | Metrics | SVR | FC-LSTM | DCRNN | STGCN | ASTGCN(r) | STSGCN | AGCRN | STFGCN | STAGCN |
|---|---|---|---|---|---|---|---|---|---|---|
| PEMS03 | MAE | 21.97 | 21.33 | 18.18 | 17.49 | 17.69 | 17.48 | 15.98 | 16.77 | 15.40 |
| MAPE(%) | 21.51 | 23.33 | 18.91 | 17.15 | 19.40 | 16.78 | 15.23 | 16.30 | 14.48 | |
| RMSE | 35.29 | 35.11 | 30.31 | 30.12 | 29.66 | 29.21 | 28.25 | 28.34 | 26.23 | |
| PEMS04 | MAE | 28.70 | 27.14 | 24.70 | 22.70 | 22.93 | 21.19 | 19.83 | 19.83 | 19.02 |
| MAPE(%) | 19.20 | 18.20 | 17.12 | 14.59 | 16.56 | 13.90 | 12.97 | 13.02 | 12.46 | |
| RMSE | 44.56 | 41.59 | 38.12 | 35.55 | 35.22 | 33.65 | 32.30 | 31.88 | 30.75 | |
| PEMS07 | MAE | 32.49 | 29.98 | 25.30 | 25.38 | 28.05 | 24.26 | 22.37 | 22.07 | 21.10 |
| MAPE(%) | 14.26 | 13.20 | 11.66 | 11.08 | 13.92 | 10.21 | 9.12 | 9.21 | 8.92 | |
| RMSE | 50.22 | 45.94 | 38.58 | 38.78 | 42.57 | 39.03 | 36.55 | 35.80 | 34.10 | |
| PEMS08 | MAE | 23.25 | 22.20 | 17.86 | 18.02 | 18.61 | 17.13 | 15.95 | 16.64 | 15.36 |
| MAPE(%) | 14.64 | 14.20 | 11.45 | 11.40 | 13.08 | 10.96 | 10.09 | 10.60 | 9.80 | |
| RMSE | 36.16 | 34.06 | 27.83 | 27.83 | 28.16 | 26.80 | 25.22 | 26.22 | 24.32 |
| Methods | Graph Configuration | MAE | MAPE | RMSE |
|---|---|---|---|---|
| Predefined-A | 16.26 | 10.19 | 25.27 | |
| Global-A | 15.73 | 10.07 | 24.94 | |
| Directed-A | 15.52 | 9.94 | 24.86 | |
| Ours | 15.36 | 9.80 | 24.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Deng, L. STAGCN: Spatial–Temporal Attention Graph Convolution Network for Traffic Forecasting. Mathematics 2022, 10, 1599. https://doi.org/10.3390/math10091599
Gu Y, Deng L. STAGCN: Spatial–Temporal Attention Graph Convolution Network for Traffic Forecasting. Mathematics. 2022; 10(9):1599. https://doi.org/10.3390/math10091599
Chicago/Turabian StyleGu, Yafeng, and Li Deng. 2022. "STAGCN: Spatial–Temporal Attention Graph Convolution Network for Traffic Forecasting" Mathematics 10, no. 9: 1599. https://doi.org/10.3390/math10091599