
Determination of Significant Parameters on the Basis of Methods of Mathematical Statistics, and Boolean and Fuzzy Logic


Abstract
:1. Introduction
- high time and resource costs of processing unneeded data;
- lack of understanding of which attributes influenced the decision.
2. Overview of Related Research
3. Classification Methods Based on Mathematical Statistics, Fuzzy and Boolean Logic3
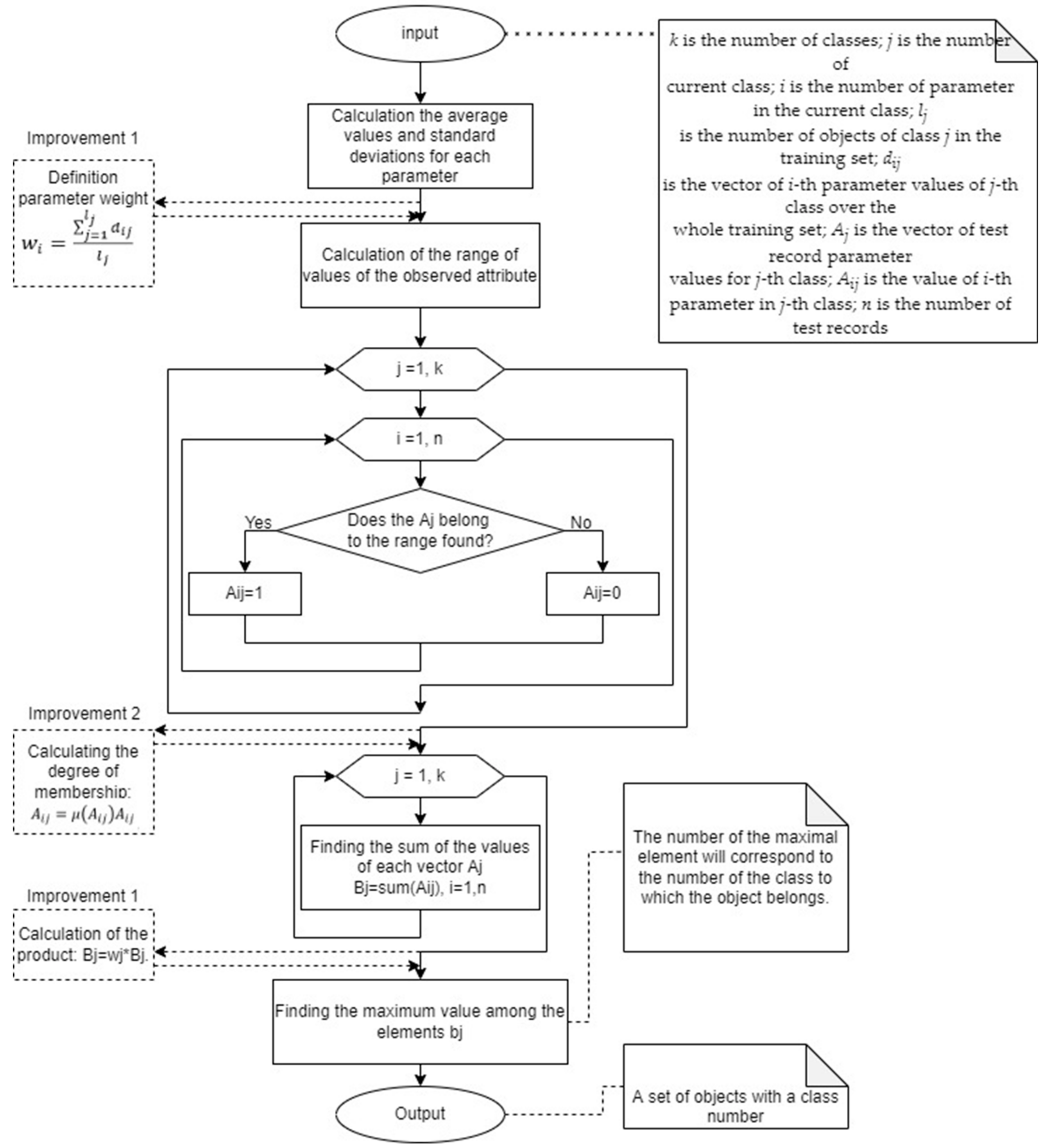
3.1. Classification by Means of Mathematical Statistics
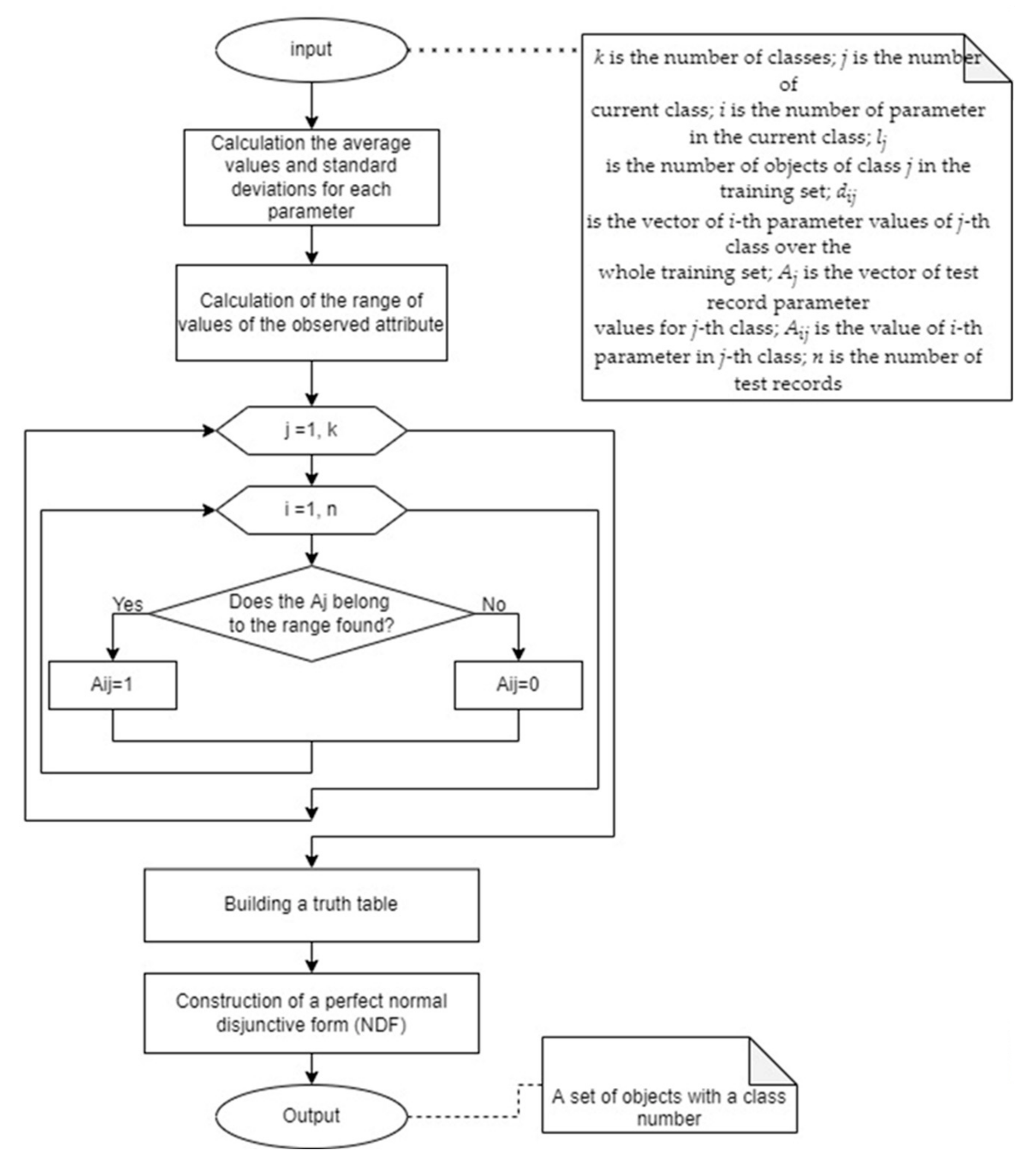
3.2. Classification Based on Boolean Logic
- 1.
- Divide the whole set into sub-sets for each of the N classes.
- 2.
- Calculate average values, SD, and value ranges for each parameter, for each of N classes (Section 2).
- 3.
- Construct tables of “0” and “1” based on values falling within the ranges found (Section 2).
- 4.
- Construct a truth table based on the number of parameters. Write “1” to the values of the functions (for each class a different function) on those rows of the table which correspond to the rows from the obtained tables of item 3, not taking into account the duplicates.
- 5.
- Construct a perfect normal disjunctive form (NDF) using the truth table obtained.
4. Input Data for Testing Methods
5. Testing the Classification Approach Based on Mathematical Statistics
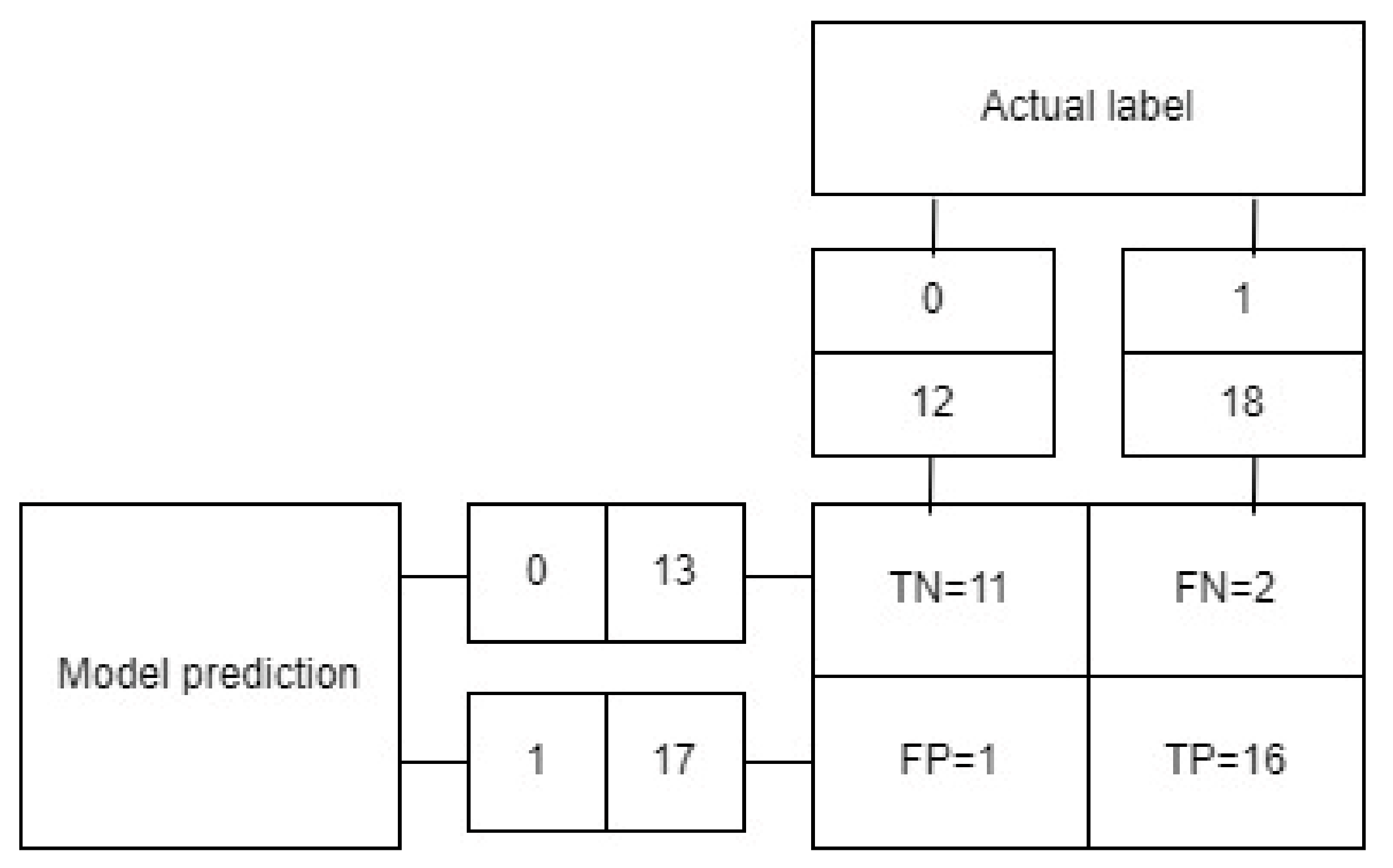
5.1. Testing on the Mobile Phone Data Set
5.2. Testing an Approach Based on a Set of Heart Disease Data
5.3. Testing an Approach Based on Boolean Logic
- Too cumbersome notation of the resulting function with a large number of parameters, and a quadratic dependence of the size of the truth table, which with a large enough number of parameters (such as images) can occupy a lot of memory.
- If in the first method under uncertainty the result can be obtained that the object with different probability belongs to three or more classes, in this method, it is always only one or two classes.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, M.; He, T.; Lee, C. Technologies toward next generation human machine interfaces: From machine learning enhanced tactile sensing to neuromorphic sensory systems. Appl. Phys. Rev. 2020, 7, 031305. [Google Scholar] [CrossRef]
- Classification Problem. Available online: https://wiki.loginom.ru/articles/classification-problem.html (accessed on 19 December 2021).
- Horn, W. AI in medicine on its way from knowledge-intensive to data-intensive systems. Artif. Intell. Med. 2001, 23, 5–12. [Google Scholar] [CrossRef]
- Blasiak, A.; Khong, J.; Kee, T. CURATE.AI: Optimizing Personalized Medicine with Artificial Intelligence. SLAS Technol. 2020, 25, 95–105. [Google Scholar] [CrossRef] [PubMed]
- Jimenez, F.; Martinez, C.; Marzano, E.; Palma, J.; Sanchez, G.; Sciavicco, G. Multi-objective evolutionary feature selection for fuzzy classification. IEEE Trans. Fuzzy Syst. 2019, 27, 1085–1099. [Google Scholar] [CrossRef]
- Guzman, J.C.; Miramontes, I.; Melin, P.; Prado-Arechiga, G. Optimal genetic design of type-1 and interval type-2 fuzzy systems for blood pressure level classification. Axioms 2019, 8, 8. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Hu, J.; Liu, Y.; Chen, X. Doctor Recommendation Based on an Intuitionistic Normal Cloud Model Considering Patient Preferences. Cogn. Comput. 2020, 12, 460–478. [Google Scholar]
- Castillo, O.; Cervantes, L.; Soria, J.; Sanchez, M.; Castro, J.R. A Generalized Type-2 Fuzzy Granular Approach with Applications to Aerospace. Inf. Sci. 2016, 354, 165–177. [Google Scholar] [CrossRef]
- Ontiveros-Robles, E.; Melin, P.; Castillo, O. Comparative analysis of noise robustness of type 2 fuzzy logic controllers. Kybernetika 2018, 54, 175–201. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Hu, J.; Sun, R.; Chen, X. Medical tourism estinations prioritization using group decision making method with neutrosophic fuzzy preference relations. Sci. Iran. 2018, 25, 3744–3764. [Google Scholar] [CrossRef] [Green Version]
- Cazarez-Castro, N.R.; Aguilar, L.T.; Castillo, O. Designing Type-1 and Type-2 Fuzzy Logic Controllers via Fuzzy Lyapunov Synthesis for nonsmooth mechanical systems. Eng. Appl. Artif. Intell. 2012, 25, 971–979. [Google Scholar] [CrossRef]
- Liang, X.; Teng, F.; Sun, Y. Multiple Group Decision Making for Selecting Emergency Alternatives: A Novel Method Based on the LDWPA Operator and LD-MABAC. Int. J. Environ. Res. Public Health 2020, 17, 2945. [Google Scholar] [CrossRef] [PubMed]
- Ekong, B.; Ifiok, I.; Udoeka, I.; Anamfiok, J. Integrated Fuzzy based Decision Support System for the Management of Human Disease. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 1–7. [Google Scholar] [CrossRef]
- Hu, J.; Chen, P.; Yang, Y. An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care. Mathematics 2019, 7, 140. [Google Scholar] [CrossRef] [Green Version]
- Benchara, F.; Youssfi, M. A New Distributed Type-2 Fuzzy Logic Method for Efficient Data Science Models of Medical Informatics. Adv. Fuzzy Syst. 2020, 2020, 6539123. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Groumpos, P.P.; Apostolopoulos, D.J. Advanced fuzzy cognitive maps: State-space and rule-based methodology for coronary artery disease detection. Biomed. Phys. Eng. Express 2021, 7, 045007. [Google Scholar] [CrossRef] [PubMed]
- Shichkina, Y.; Irishina, Y.; Stanevich, E.; Salgueiro, A. The main aspects of creating a system of data mining on the status of patients with Parkinson’s disease. Procedia Comput. Sci. 2021, 186, 161–168. [Google Scholar] [CrossRef]
- Giordani, P.; Perna, S.; Bianchi, A.; Pizzulli, A.; Tripodi, S.; Matricardi, P. A study of longitudinal mobile health data through fuzzy clustering methods for functional data: The case of allergic rhinoconjunctivitis in childhood. PLoS ONE 2020, 15, e0242197. [Google Scholar] [CrossRef] [PubMed]
- Kostarev, S.N.; Tatarnikova, N.A.; Kochetova, O.V.; Sereda, T.G. Development of a sequence automaton for recognition of deviations indicators in diagnosis of natural systems. In Proceedings of the Publishing IOP Conference Series: Earth and Environmental Science, IV International Scientific Conference: AGRITECH-IV-2020: Agribusiness, Environmental Engineering and Biotechnologies, Krasnoyarsk, Russian, 8–20 November 2020. [Google Scholar]
- Wolf, B.; Slate, E.; Hill, E. Ordinal Logic Regression: A classifier for discovering combinations of binary markers for ordinal outcomes. Comput. Stat. Data Anal. 2015, 82, 152–163. [Google Scholar] [CrossRef] [Green Version]
- Jung, H.; Leem, S. Fuzzy set-based generalized multifactor dimensionality reduction analysis of gene-gene interactions. In Proceedings of the 28th International Conference on Genome Informatics: Medical Genomics, Berlin, Germany, 20 April 2018. [Google Scholar] [CrossRef]
- Bellavia, A.; Rotem, R.; Dickerson, A.; Hansen, J. The Use of Logic Regression in Epidemiologic Studies to Investigate Multiple Binary Exposures: An Example of Occupation History and Amyotrophic Lateral Sclerosis. Epidemiol. Methods 2020, 9, 20190032. [Google Scholar] [CrossRef] [PubMed]
- Castro, F.; Nebot, A.; Mugica, F. On the extraction of decision support rules from fuzzy predictive models. Appl. Soft Comput. 2011, 11, 3463–3475. [Google Scholar] [CrossRef]
- Heart Disease UCI. Available online: https://www.kaggle.com/ (accessed on 20 May 2021).




{kind=link}
{kind=link}
{kind=link}
| Speed of Typing | Deletion Rate | Accuracy of Key Hitting | Number T9 | Class |
|---|---|---|---|---|
| 115 | 8 | 56 | 32 | A |
| 119 | 1 | 62 | 12 | B |
| 116 | 9 | 59 | 37 | A |
| 111 | 16 | 54 | 34 | D |
| 113 | 17 | 60 | 40 | D |
| 124 | 6 | 85 | 35 | B |
| 127 | 17 | 85 | 90 | C |
| 114 | 18 | 64 | 44 | D |
| 128 | 19 | 88 | 95 | C |
| 124 | 6 | 86 | 36 | B |
| 127 | 25 | 100 | 95 | D |
| 125 | 7 | 88 | 38 | B |
| 115 | 19 | 69 | 49 | D |
| 116 | 19 | 72 | 52 | D |
| 117 | 9 | 61 | 39 | A |
| Speed of Typing | Deletion Rate | Accuracy of Key Hitting | Number T9 | Class |
|---|---|---|---|---|
| 123 | 10 | 70 | 69 | C |
| 120 | 12 | 86 | 66 | C |
| 124 | 8 | 100 | 93 | C |
| 127 | 12 | 89 | 73 | C |
| Age | Sex | Cp | Trestbps | Chol | Fbs | Restecg | Thalach | Exang | Oldpeak | Slope | Ca | Thal | Target |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 63 | 1 | 3 | 145 | 233 | 1 | 0 | 150 | 0 | 2.30 | 0 | 0 | 1 | 1 |
| 37 | 1 | 2 | 130 | 250 | 0 | 1 | 187 | 0 | 3.50 | 0 | 0 | 2 | 1 |
| 56 | 1 | 1 | 120 | 236 | 0 | 1 | 178 | 0 | 0.80 | 2 | 0 | 2 | 1 |
| 57 | 0 | 0 | 120 | 354 | 0 | 1 | 163 | 1 | 0.60 | 2 | 0 | 2 | 1 |
| 57 | 1 | 0 | 140 | 192 | 0 | 1 | 148 | 0 | 0.40 | 1 | 0 | 1 | 1 |
| 56 | 0 | 1 | 140 | 294 | 0 | 0 | 153 | 0 | 1.30 | 1 | 0 | 2 | 1 |
| 44 | 1 | 1 | 120 | 263 | 0 | 1 | 173 | 0 | 0.00 | 2 | 0 | 3 | 1 |
| 52 | 1 | 2 | 178 | 199 | 1 | 1 | 162 | 0 | 0.50 | 2 | 0 | 3 | 1 |
| 57 | 1 | 2 | 150 | 168 | 0 | 1 | 174 | 0 | 1.60 | 2 | 0 | 2 | 1 |
| 54 | 1 | 0 | 140 | 239 | 0 | 1 | 160 | 0 | 1.20 | 2 | 0 | 2 | 1 |
| 48 | 1 | 1 | 130 | 266 | 0 | 1 | 171 | 0 | 0.60 | 2 | 0 | 2 | 1 |
| 64 | 1 | 3 | 110 | 211 | 0 | 0 | 144 | 1 | 1.80 | 1 | 0 | 2 | 1 |
| Class | Speed of Typing | Deletion Rate | Accuracy of KEY Hitting | Number T9 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AV | SD | VR | AV | SD | VR | AV | SD | VR | AV | SD | VR | |
| A | 2.384 | 119.611 | (117.227–121.995) | 0.833 | 9.833 | (9–10.666) | 6.455 | 69 | (62.545–75.455) | 8.043 | 48.611 | (40.568–56.654) |
| B | 2.071 | 123.1 | (121.029–125.171) | 2.071 | 5.10 | (3.029–7.717) | 9.615 | 80.55 | (70.935–90.165) | 9.935 | 30.70 | (20.765–40.635) |
| C | 4.011 | 123.263 | (119.252–127.274) | 6.783 | 10.789 | (4.006–17.572) | 14.567 | 70.10 | (55.533–84.667) | 20.432 | 71.684 | (51.252–92.116) |
| D | 3.776 | 117.947 | (114.171–121.723) | 6.783 | 19.947 | (13.164–26.73) | 12.59 | 79.263 | (66.673–91.853) | 14.745 | 60.053 | (45.308–74.798) |
| Record Number | Number of Units | Output | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| 1 | 2 | 2 | 4 | 2 | C |
| 2 | 1 | 2 | 3 | 3 | C with a probability of 0.5 or D with a probability of 0.5 |
| 3 | 0 | 2 | 2 | 0 | B with a probability of 0.5 or C with a probability of 0.5 |
| 4 | 0 | 1 | 3 | 1 | C |
| Record Number | Number of Units | Output | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| 1 | 2 | 2 | 4 | 2 | C |
| 2 | 1 | 2 | 4 | 2 | C |
| 3 | 0 | 2 | 2 | 0 | B with a probability of 0.5 or C with a probability of 0.5 |
| 4 | 0 | 1 | 3 | 1 | C |
| Class A | |||
|---|---|---|---|
| Speed of Typing | Deletion Rate | Accuracy of Key Hitting | Number T9 |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 |
| 55% | 72% | 66% | 66% |
| Class | Speed of Typing | Deletion Rate | Accuracy of Key Hitting | Number T9 |
|---|---|---|---|---|
| A | 55% | 72% | 66% | 66% |
| B | 70% | 70% | 70% | 70% |
| C | 63% | 100% | 63% | 68% |
| D | 63% | 63% | 63% | 68% |
| Record Number | Number of Units | Output | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| 1 | 0.345 | 0.35 | 0.6425 | 0.3275 | C |
| 2 | 0 | 0.35 | 0.6425 | 0.3275 | C |
| 3 | 0 | 0.175 | 0.3275 | 0.25 | C |
| 4 | 0 | 0.175 | 0.485 | 0.3275 | C |
| Class | Border | Age | Sex | Cp | Trestbps | Chol | Fbs | Restecg | Thalach | Exang | Oldpeak | Slope | Ca | Thal |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | bottom | 48.6 | 0.43 | −0.4 | 115.5 | 205 | −0.208 | −0.118 | 115.7 | 0.01 | 0.281 | 0.6 | 0.145 | 1.9 |
| 0 | upper | 64.3 | 1.20 | 1.4 | 153.4 | 302 | 0.520 | 0.970 | 162.1 | 1.01 | 2.887 | 1.7 | 2.265 | 3.2 |
| 1 | bottom | 42.8 | 0.08 | 0.4 | 113.4 | 186.5 | −0.208 | 0.060 | 139.1 | −0.20 | −0.209 | 0.99 | −0.512 | 1.6 |
| 1 | upper | 61.8 | 1.07 | 2.4 | 145.5 | 295.4 | 0.513 | 1.080 | 178.2 | 0.50 | 1.377 | 2.2 | 1.201 | 2.6 |
| Class | Age | Sex | Cp | Trestbps | Chol | Fbs | Restecg | Thalach | Exang | Oldpeak | Slope | Ca | Thal |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.680 | 0.820 | 0.828 | 0.721 | 0.697 | 0.844 | 0.598 | 0.664 | 0.516 | 0.623 | 0.664 | 0.541 | 0.934 |
| 1 | 0.623 | 0.576 | 0.662 | 0.689 | 0.762 | 0.848 | 0.556 | 0.709 | 0.854 | 0.815 | 0.947 | 0.921 | 0.775 |
| Record Number | The Sum of the Products of Weights | Output | |
|---|---|---|---|
| 0 | 1 | ||
| 1 | 8 | 6 | 0 |
| 2 | 8 | 10 | 1 |
| 3 | 6 | 11 | 1 |
| 4 | 10 | 11 | 1 |
| 5 | 13 | 7 | 0 |
| 6 | 9 | 7 | 0 |
| 7 | 9 | 4 | 0 |
| Record Number | The Sum of the Products of Weights | Output | |
|---|---|---|---|
| 0 | 1 | ||
| 1 | 0.443 | 0.329 | 0 |
| 2 | 0.458 | 0.599 | 1 |
| 3 | 0.373 | 0.650 | 1 |
| 4 | 0.575 | 0.638 | 1 |
| 5 | 0.702 | 0.396 | 0 |
| 6 | 0.497 | 0.400 | 0 |
| 7 | 0.447 | 0.234 | 0 |
| The Proposed Method | Improving the Method by Adding Weights | Improving the Method by Applying Fuzzy Logic | k-Means | k-Medoids | |
|---|---|---|---|---|---|
| Data set 1 | 0.75 | 1 | 1 | 0.75 | 1 |
| Data set 2 | 0.9 | 0.77 | 0.91 | 0.89 | 0.91 |
| Record Number | The Result of a Normal Form | Output | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| 1 | 0 | 0 | 1 | 0 | C |
| 2 | 0 | 0 | 1 | 0 | C |
| 3 | 0 | 0 | 1 | 0 | C |
| 4 | 0 | 0 | 1 | 0 | C |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shichkina, Y.; Petrov, M.; Roza, F. Determination of Significant Parameters on the Basis of Methods of Mathematical Statistics, and Boolean and Fuzzy Logic. Mathematics 2022, 10, 1133. https://doi.org/10.3390/math10071133
Shichkina Y, Petrov M, Roza F. Determination of Significant Parameters on the Basis of Methods of Mathematical Statistics, and Boolean and Fuzzy Logic. Mathematics. 2022; 10(7):1133. https://doi.org/10.3390/math10071133
Chicago/Turabian StyleShichkina, Yulia, Mikhail Petrov, and Fatkieva Roza. 2022. "Determination of Significant Parameters on the Basis of Methods of Mathematical Statistics, and Boolean and Fuzzy Logic" Mathematics 10, no. 7: 1133. https://doi.org/10.3390/math10071133