1. Introduction
In statistical theory, there are several lifetime probability models which are used to analyse the uncertainty of the random phenomena in various fields, for example, engineering, medical sciences, financial affairs, etc. The most commonly used lifetime model is exponential distribution. This distribution has a simple mathematical form and constant hazard rate which makes this distribution quite useful in real life testing and reliability problems. However, having constant hazard rate sometimes become a hurdle for analysing some situations. To tackle this issue, different probability models were discussed such as Weibull, gamma, Burr, Lindley distribution, etc. Nowadays, we are seeing problems which are complex in nature and the statistical behaviour of such problem change rapidly. So, in such situations, we must have a general form of distributions which can also transform according to our need. In this direction, various generalized family of distributions are proposed by academicians (see [
1,
2,
3,
4,
5]). Ref. [
6] proposed a logarithm transformation (LT) method for obtaining the new family of distributions. The family of distributions proposed by [
6] has the following cumulative distribution function (cdf):
Proceeding in the same manner, Ref. [
7] generalized the results of [
6] by introducing a shape parameter in the baseline cdf of Equation (
1). The family of distributions proposed by [
7] has the following cdf:
To study the properties of (2), the authors considered
(exponential baseline distribution) and called it generalized logarithm transformation exponential (GLTE) distribution. The pdf and cdf of GLTE distribution are given as
respectively. The reliability function and hazard rate function of GLTE distribution are given as
and
The authors of [
7] have extensively discussed the behaviour of hazard rate function for different values of the parameters. The authors observed that for
GLTE distribution is depicting increasing hazard rate, for
, GLTE distribution is depicting decreasing hazard rate. The authors also emphasized that the distribution has a bathtub hazard rate. These results are depicted in Figure 2 of [
7].
Ref. [
7] considered classical and Bayesian estimation of GLTE distributions of unknown parameters under type-II censoring scheme. To the best of our knowledge, until now no attempt has been made to estimate the parameters and reliability characteristic for GLTE distribution other than the type-II censoring scheme. This is why we have considered progressive type-II censoring scheme for our study which is a generalize form of type-II censoring scheme. Hence, the results of this paper are of more general in nature. In addition to that the GLTE distribution provides a better fit to the considered demographic data (mortality rates) over other lifetime distributions e.g., Weibull, Chen, etc. (see
Section 5). Keeping these points in mind, we have discussed the classical as well as the Bayesian estimation and reliability characteristics for the GLTE distribution under the progressive type-II censored data.
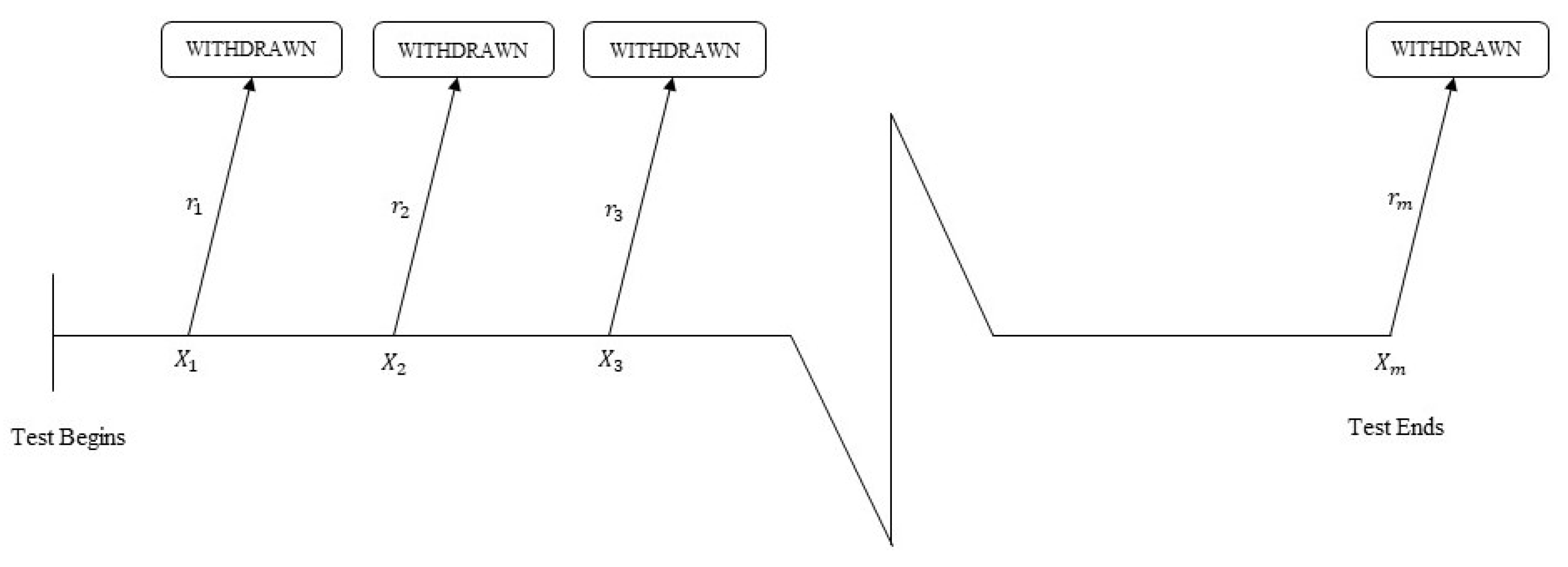
In any life-testing experiment, it is very cumbersome to complete the experiment for a long time period due to time and cost constraints. There are various types of censoring schemes which have been introduced in the literature to reduce the time and cost involved into the experiments. Type-I and Type-II are the most common censoring schemes among the various censoring schemes. The number of observed failures in the type-I censoring scheme is random in nature, whereas the termination time of the experiments is random in the type-II censoring scheme. Surviving units cannot be withdrawn during the experimentation of these two schemes. The main advantage of progressive censoring is that it saves a lot of energy and money due to its ability to drop live units from the experiment in practical failure time experiment. Initially, the progressive censoring scheme was proposed by [
8].
Let
n units are put on test at the same time. If first failure occurs at the time
,
surviving units are randomly removed from the experiment. At the second failure time
,
surviving units are randomly removed from the remaining surviving units. The experiment continues until the
failure time
observed. At this time, the test can be terminated with removing all the surviving units from the experiment. Here,
is a set of observed life-time, referred to as progressively type-II censored sample (see,
Figure 1). In the case of
, this scheme becomes type-II censoring scheme. It is also observed that for
, this scheme transformed into the case of complete sample.
In the last few years, progressive censoring scheme has received considerable attention (see [
9,
10,
11]). Ref. [
12] has made a remarkable contribution to developments, implementations and other dimensions of progressive censoring. The progressive censored data for the Burr model was discussed by [
13]. The Bayesian inference for the Weibull distribution under progressive censoring scheme was discussed by [
14]. The progressive type-II censoring scheme was discussed by [
15] for exponential Weibull model and for the inverted exponential model was discussed by [
16]. The scheme of progressive censoring for the Burr type-XII and Inverse Weibull were proposed by [
17,
18], respectively. Ref. [
19] have developed a method of estimation for xgamma distribution under progressive type-II censoring approach. Ref. [
20] have discussed progressive censoring scheme for lognormal distribution and [
21] have discussed Bayesian inference of Hjorth distribution under the progressive type-II censoring scheme. Recently, Ref. [
22] addressed the problem of Bayesian reliability estimation for the Topp–Leone distribution based on progressive type-II censoring scheme. The authors obtained Bayes estimators using approximation techniques such as Lindley’s approximation, MCMC and Tierney-Kadane method ([
23]).
In this paper, we address the problem of classical and Bayesian estimation of GLTE distribution under the progressive type-II censored data. For the scale parameter, a discrete prior is considered, whereas a conditional gamma prior for the shape parameter is considered. The rest of the paper, we organized as follows: In
Section 2, the Maximum likelihood estimators and asymptotic confidence intervals are obtained for the parameters and the reliability function of GLTE distribution. The Bayes estimators under symmetric, asymmetric loss functions and highest posterior density intervals are obtained in
Section 3. In
Section 4, a simulation study is presented to report the performances of the point and interval estimators. In
Section 5, the mortality data sets of Italy and The Netherlands due to COVID-19 are provided to illustrate the computation of various derived results. Finally, the conclusions appear in
Section 6.
2. Maximum Likelihood Estimation and Asymptotic Confidence Interval
Suppose
is a progressive type-II censored sample from a life test on
n units having the GLTE
distribution with density given in (
1) and
denote the corresponding number of units removed from the test. The likelihood function based on the progressively type-II censored sample is given by
where,
and
; and
and
are given respectively by (
1) and (
2).
Substituting (
1) and (
2), into (
7), the likelihood function is
The log-likelihood function can be written as
and
It is clear that the Equations (
10) and (
11) are of implicit forms and are non-linear in nature, so, MLEs of unknown parameters are tedious to obtain, analytically. Thus, one may use any numerical approximation techniques, such as Newton–Raphson (N-R) method, fixed-point iterations, etc. Here, we used the N-R method to evaluate the MLE of the parameters with the help of R Software. Once the MLEs of the parameters are obtained from Equations (
10) and (
11), the MLE of reliability function is evaluated using the invariance property and is given in (
12)
Further, using the property MLE, we obtained the asymptotic confidence intervals (ACIs) for , and The ACIs are obtained from the diagonal elements of the inverse Fisher information matrix that gives the asymptotic variance for the parameters and respectively. Thus, the confidence interval for , and can be defined respectively, as , where is a standard normal variate.
3. Bayesian Estimation
In this section, we consider both parameters shape as well as scale as unknown for GLTE distribution. To estimate these parameters, we adopt the method proposed by [
24]. Several researchers also used this method (see, [
25,
26]). Here, the scale parameter
is restricted to a finite number of values
with probabilities
respectively, the prior distribution for
is given by
Further, we consider conditional gamma prior for parameter
over
with hyper parameters
and
,
Here, we consider symmetric (squared error) and asymmetric (LINEX and general entropy) loss functions to obtain the Bayes estimators of unknown parameters and reliability function of the distribution. The likelihood function (
8) in terms of continuous parameter
and discrete parameter
is
The joint posterior of
and
is
where,
and
The marginal posterior density of
is obtained by integrating (
15) with respect to
, we get
Combining the likelihood function (
14) and prior density (
13), we obtain the posterior density of
where,
and
3.1. Bayes Estimation under Symmetric Loss Function
Squared Error Loss Function (SELF): In the SELF, the magnitude of underestimation and overestimation are equal. It is also known as Quadratic loss function. In the SELF, Bayes estimator is represented by the posterior mean. The squared error loss function is defined as
where,
is the Bayes estimator of
.
is a decision space and
is parameter space.
The Bayes estimators
and
of parameters
and
, respectively, are
The Bayes estimator
of the reliability function
is
3.2. Bayes Estimation under Asymmetric Loss Function
When the magnitude of overestimation and underestimation are not equal, then we used the asymmetric loss function. In the asymmetric loss function, we consider LINEX loss function and General Entropy loss function.
LINEX Loss function: The LINEX loss function is defined as
The Bayes estimator
of
under the LINEX loss function is
provided,
exists and finite. The Bayes estimators
and
of parameters
and
under LINEX loss function (
18), respectively, are
The Bayes estimators
of the reliability function
is
General Entropy Loss Function: The General Entropy loss function is defined as
The Bayes estimator
of
under GE loss function is
provided,
exists and is finite.
The Bayes estimators
and
of parameters
and
under General Entropy loss function (
19), respectively, are
The Bayes estimator
of the reliability function
is
3.3. Bayesian Credible Interval
In the Bayesian paradigm, parameter
is a random variable and the probability for this parameter
lies within the specified intervals. The highest posterior density (HPD) interval was discussed by [
27]. The HPD interval is the shortest interval among all Bayesian intervals. The HPD interval for parameter
based on the samples from simulation method ie.,
was discussed by [
28] (see [
29,
30]). The algorithm to obtain the HPD interval is as follows
- (i)
In the first step, we generate a random censored data from GLTE distribution using Equation (
4) for some fixed values of the parameters using different censoring schemes.
- (ii)
After this, we use the results of MLEs and Bayes estimators derived in
Section 2 and
Section 3, respectively, to calculate the required estimators (say
) with the help of the generated data in step
(i).
- (iii)
We repeat the steps (i–ii) N times and obtain the N values of the estimators i.e., .
- (iv)
Now we apply the method of [
28] and obtain the Bayes credible interval.
4. Simulation Study
In this section, we perform a simulation study for the GLTE distribution under the progressive type-II censored sample. This simulation study is conducted to measure the performances of various estimators obtained in this article. The algorithm for generation of progressive type-II censored sample was given by [
31]. The algorithm is modified according to our problem and is given as:
Generate m iid random numbers from .
Determine the values of the censored scheme , for .
Set for .
Set , . Then is the progressive type-II censored sample from .
Now, is the progressive type-II censored sample from GLTE distribution.
The performances of estimators are measured by using the criteria of mean square error (MSE) and expected risk (ER). The values of MSEs and ERs are calculated for various configuration of parameters i.e., We have also considered few censoring schemes (C.S.) which are defined
- *
.
- *
.
- *
.
- (1)
Table 1 and
Table 3 show MSEs of the
,
and
for the configuration of
. It can be observed that Bayes estimates of
,
and
show less MSEs in comparison to MLEs. Furthermore, we observe that Bayes estimator under LINEX loss function for
performs better among other Bayes estimators. In terms of
, all Bayes estimators perform approximately the same with small MSEs.
- (2)
Table 2 and
Table 4 show MSEs of the
,
and
for the configuration of
. It is observed that Bayes estimates of
,
and
show less MSEs in comparison to MLEs. Moreover, we observe that Bayes estimator under LINEX loss function performs better among other Bayes estimators. In terms of
, all estimators perform approximately the same with small MSEs.
- (3)
Table 5 and
Table 7 report ERs of various Bayes estimators for parameters (
) = (1,1.5), respectively. From Tables, we observe that Bayes estimator for LINEX loss function at
exhibits lowest MSEs among other Bayes estimators. In terms of
, all estimators perform approximately the same with small MSEs.
- (4)
Table 6 and
Table 8 report ERs of various Bayes estimators for parameters (
) = (1.2,1.5), respectively. We can observe that Bayes estimator for LINEX loss function at
and for GE loss function at
exhibits lower ERs among other Bayes estimates for the parameters
and
, respectively. In terms of
, all estimators perform approximately the same with small MSEs, but Bayes estimators seem to perform slightly better.
- (5)
Table 9 and
Table 10 show the average length of ACIs and HPD intervals of parameters
,
and
, respectively. It is observed that the average lengths of the intervals decreases when the different choices of
increases for both classical and Bayesian estimation. We also observe that HPD intervals of the estimators under LINEX loss function are mostly better among other estimators.
From
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, we conclude that, for different choices of the parameters (
) =
, the Bayes estimator under asymmetric loss function i.e., LINEX loss function shows less MSEs and ERs. Hence, it performs better than other estimators. It is worth mentioning here that for very few cases, the Bayes estimator under GE loss function performs better in terms of ERs. In terms of
, we observe that the MLEs and Bayes estimators perform approximately the same. On the other hand, when we consider the performances of reliability estimates in term of ERs, we see that Bayes estimators under asymmetric loss functions exhibit lower values in comparison to symmetric loss function and MLE. The censoring scheme
performs better among all the censoring schemes (
and
). All the above observations are made for increasing values of
n and
5. Real Data
In this section, we consider the mortality data sets of Italy and The Netherlands due to COVID-19. The COVID-19 (coronavirus disease) was declared as a pandemic by World Health Organization (WHO) in 2020. It is the third-highest cause of deaths in 2020, as revealed by the US Centers for Disease Control and Prevention (CDC). The mortality rate was calculated through the ratio of number of deaths and total number of cases (reported cases per 100,000). The mortality rate due to COVID-19 increased by 15.9% from 2019 (see,
https://www.pharmaceutical-technology.com/comment/covid-19-cause-death-2020/ (accessed on 26 January 2022)). Here, these two COVID-19 data sets represent the mortality rates for 59 days and 30 days of Italy and The Netherlands, respectively (see,
https://covid19.who.int/ (accessed on 26 January 2022)). The mortality rates of Italy recorded from 27 February to 27 April 2020 is given in
Table 11.
Table 12 represents the mortality rates of The Netherlands recorded from 31 March to 30 April 2020 (also see [
32]).
In the terms of suitable fitting of the distribution, the GLTE distribution is compared with other related distributions such as exponential distribution, Weibull distribution, and Chen distribution (see
Table 13 and
Table 14). The considered real data set was measured on the basis of -Log L which is the negative of the logarithmic value of likelihood, and Kolmogorov–Smirnov (K-S) test statistic for the distribution selection criterion. We also used Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). The AIC and BIC are defined as
where
k = Number of parameters,
n = Sample size and
= value of the maximum likelihood for the considered distribution. The K-S test statistic
D is defined as
where,
= Empirical distribution function. From
Table 13 and
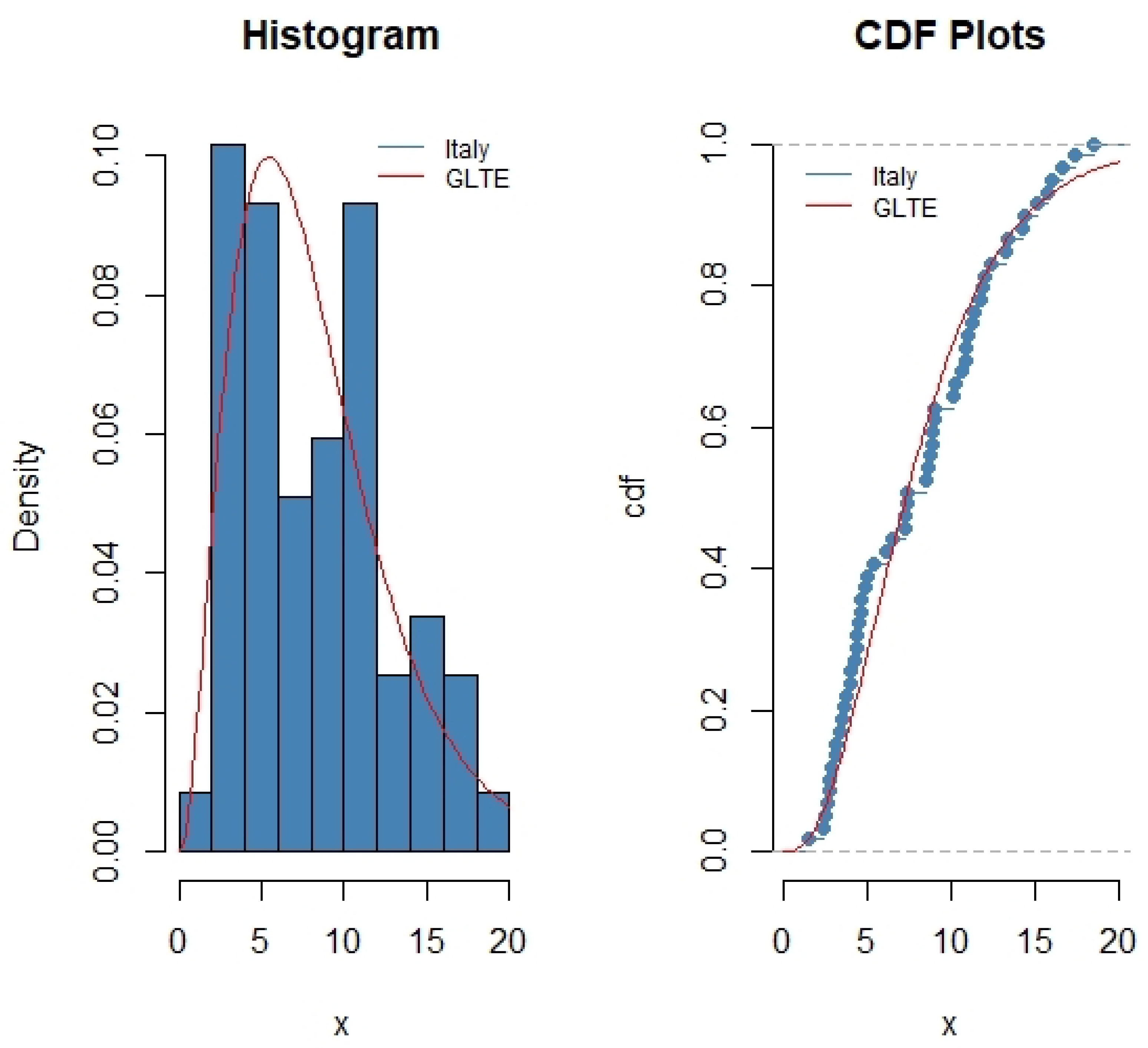
Table 14, we observe that the value of AIC, BIC and -Log L of the GLTE distribution is minimum among other distributions. The minimum value of AIC, BIC and -Log L shows that the GLTE distribution better fits for the considered real data sets rather than the other distributions. We observe that Italy’s mortality rates for 59 days supports GLTE distribution with the K-S distance as
and
p-value as
for
and
(see
Figure 2). The Netherlands’s mortality rates for 30 days also supports GLTE distribution with the K-S distance as
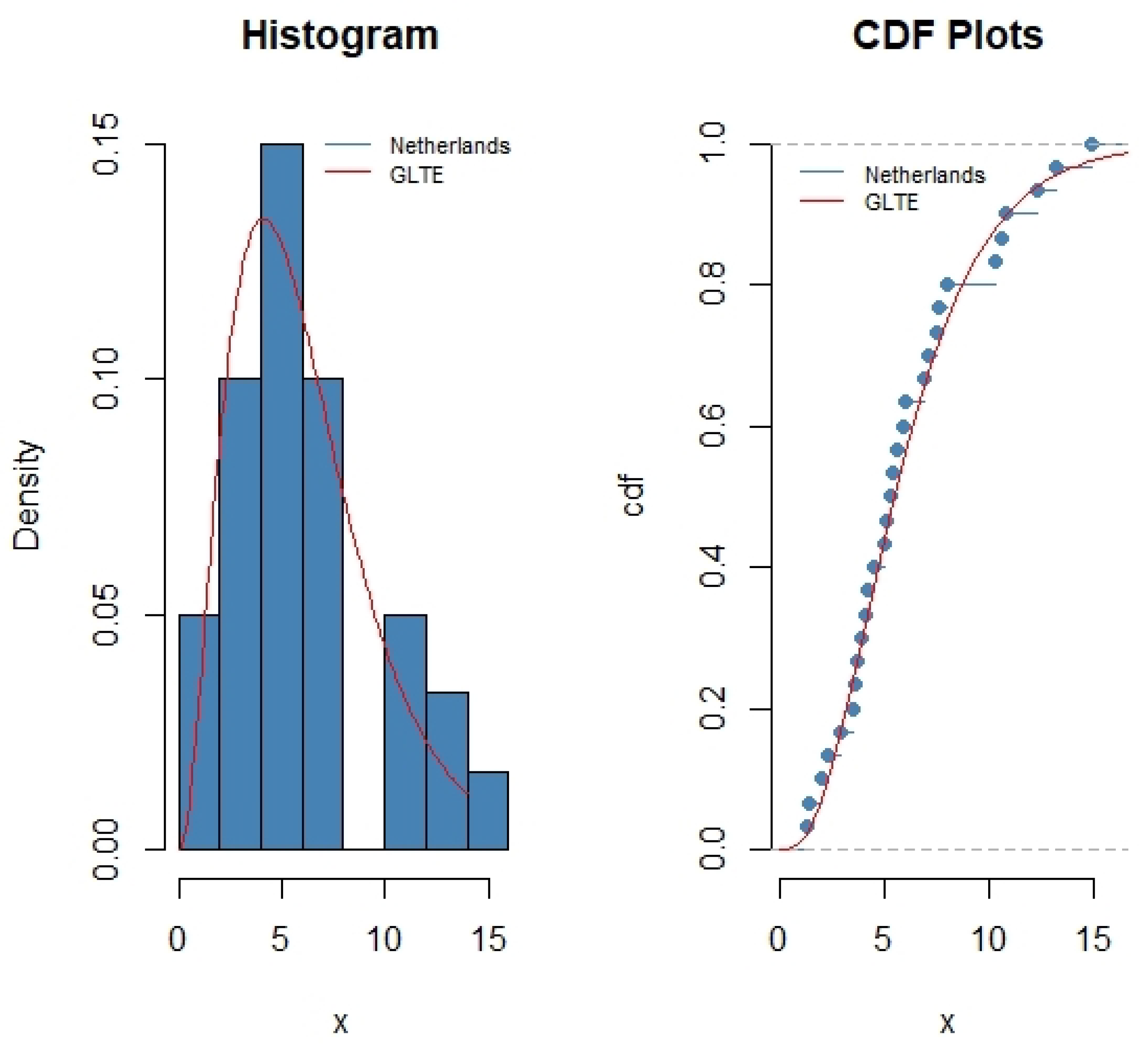
and
p-value as
for
and
(see
Figure 3).
Now, we consider censoring schemes which are used in the simulation study to generate progressive type-II censored samples from the data set of 59 days of mortality rates of Italy of size and . For the data set of 30 days of mortality rates of The Netherlands of size and for the same censoring schemes.
For both the data sets of COVID-19, we calculate the Bayes estimators under symmetric and asymmetric loss functions. For asymmetric loss function, we consider
in LINEX loss function and
in GE loss functions. The calculated Bayes estimates of
and
as
are given in
Table 15 and
Table 16.
6. Conclusions
In this paper, we consider the classical and Bayesian estimation of the unknown parameters and reliability function of the GLTE distribution when the data are progressively type-II censored. The MLEs and Bayes estimators of the parameters and reliability function are obtained. The Bayes estimators were computed using discrete prior for scale parameter and a conditional gamma prior for the shape parameter. We used symmetric (squared error) and asymmetric (LINEX, General Entropy) loss functions to compute the MSEs and ERs. We also address the problem of interval estimation under classical and Bayesian scheme and we derived asymptotic confidence and highest posterior density intervals. The simulation study was done for the different choices of parameter combinations to report the performances of the various estimators, along with the different sample sizes and censoring schemes.
The significance of GLTE distribution over other lifetime distributions such as Weibull, exponential and Chen are discussed in this paper. For this purpose, we considered two real data sets reporting mortality rates of two countries i.e., The Netherlands and Italy. We used the Akaike information and Bayesian information criteria to show the comparison among the probability distributions. The dominance of GLTE distribution over other probability distributions is discussed for the considered data sets of this study. From the simulation study, it is observed that Bayes estimator under LINEX loss function is performing better in most of the cases. It is also worth mentioning that the censoring scheme works quite well among other schemes considered in this study. So, in real-life situation we should incline our study towards the asymmetric loss function i.e., LINEX and censoring scheme . All the results and conclusions are based on the problem which is considered in this study.


 ,
, 



{kind=link}
{kind=link}
{kind=link}